Postgresql源码(134)优化器针对volatile函数的排序优化分析
相关
《Postgresql源码(133)优化器动态规划生成连接路径的实例分析》
上一篇对路径的生成进行了分析,通过make_one_rel最终拿到了一个带着路径的RelOptInfo。本篇针对带volatile函数的排序场景继续分析subquery_planner的后续流程。
subquery_plannergrouping_plannerquery_plannermake_one_rel <<< 上一篇// 后续流程 <<< 本篇
总结速查
一句话总结:带有volatile的投影列会被SORT算子忽略,达到先排序在投影计算volatile的效果。
grouping_planner→make_one_rel层层生成path,每个path都会带pathtarget(不一定是SQL中最后需要的target列表),一般都是层层继承上来的。make_one_rel生成的最终path中,会忽略volatile函数列,交给外层grouping_planner函数处理,所以生成的path中的pathtarget都是看不到volatile函数列的。- 这里一个关键逻辑就path中的
pathtarget和make_sort_input_target计算出来列表的是不是一样的- 如果是一样的就不加投影节点,等后面加sort时(create_ordered_paths)先加sort在加投影,计算顺序就是先排序,在拿排序阶段投影(计算random函数)
- 如果不一样就直接加投影节点,后面sort会加到投影上面,计算顺序就是先投影(计算random函数),再排序。
path中的pathtarget会忽略volatile函数。make_sort_input_target中的volatile函数正常也会被忽略掉(实例3),除非volatile函数就是排序列(实例4)。
最终效果是,投影列有volatile函数的SQL(函数非排序列),sort节点会忽略这类函数的执行,sort结束后,在投影节点使用sort的结果集来计算这类函数。
实例3:
1 实例:简单join
drop table student;
create table student(sno int primary key, sname varchar(10), ssex int);
insert into student values(1, 'stu1', 0);
insert into student values(2, 'stu2', 1);
insert into student values(3, 'stu3', 1);
insert into student values(4, 'stu4', 0);drop table course;
create table course(cno int primary key, cname varchar(10), tno int);
insert into course values(20, 'meth', 10);
insert into course values(21, 'english', 11);drop table teacher;
create table teacher(tno int primary key, tname varchar(10), tsex int);
insert into teacher values(10, 'te1', 1);
insert into teacher values(11, 'te2', 0);drop table score;
create table score (sno int, cno int, degree int);
create index idx_score_sno on score(sno);
insert into score values (1, 20, 100);
insert into score values (1, 21, 89);
insert into score values (2, 20, 99);
insert into score values (2, 21, 90);
insert into score values (3, 20, 87);
insert into score values (3, 21, 20);
insert into score values (4, 20, 60);
insert into score values (4, 21, 70);explain
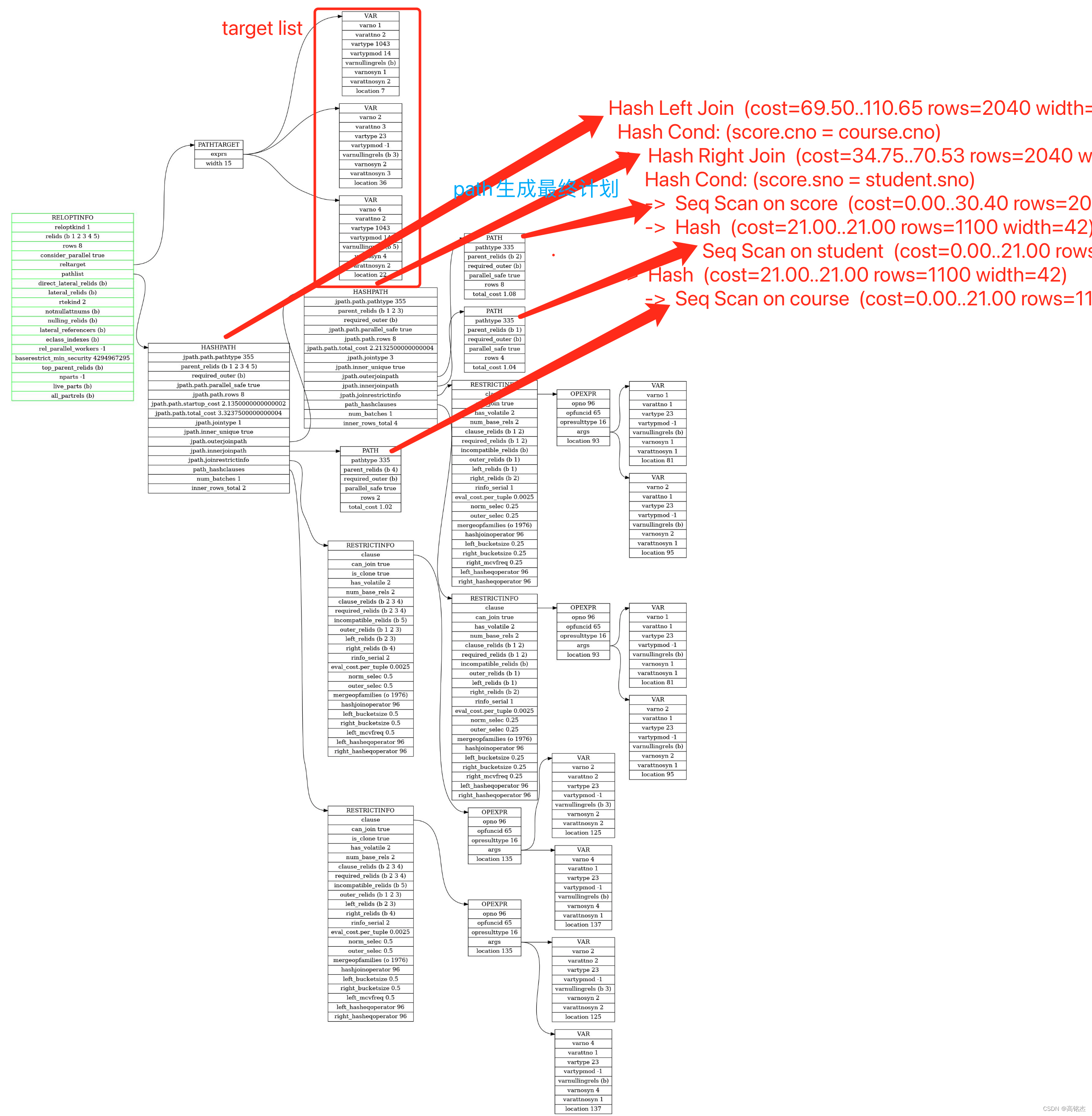
SELECT STUDENT.sname, COURSE.cname, SCORE.degree
FROM STUDENT
LEFT JOIN SCORE ON STUDENT.sno = SCORE.sno
LEFT JOIN COURSE ON SCORE.cno = COURSE.cno;QUERY PLAN
------------------------------------------------------------------------------Hash Left Join (cost=69.50..110.65 rows=2040 width=80)Hash Cond: (score.cno = course.cno)-> Hash Right Join (cost=34.75..70.53 rows=2040 width=46)Hash Cond: (score.sno = student.sno)-> Seq Scan on score (cost=0.00..30.40 rows=2040 width=12)-> Hash (cost=21.00..21.00 rows=1100 width=42)-> Seq Scan on student (cost=0.00..21.00 rows=1100 width=42)-> Hash (cost=21.00..21.00 rows=1100 width=42)-> Seq Scan on course (cost=0.00..21.00 rows=1100 width=42)
1.1 subquery_planner→grouping_planner
grouping_plannercurrent_rel = query_planner(root, standard_qp_callback, &qp_extra);
- current_rel:
final_target = create_pathtarget(root, root->processed_tlist);
- 得到final_target
- final_target->exprs->elements[0] : {varno = 1, varattno = 2, vartype = 1043}
STUDENT.sname - final_target->exprs->elements[1] : {varno = 4, varattno = 2, vartype = 1043}
COURSE.cname - final_target->exprs->elements[2] : {varno = 2, varattno = 3, vartype = 23}
SCORE.degree
- final_target->exprs->elements[0] : {varno = 1, varattno = 2, vartype = 1043}
if (parse->sortClause)make_sort_input_targetif (activeWindows)...if (have_grouping)...if (parse->hasTargetSRFs)...
- apply_scanjoin_target_to_paths创建投影节点
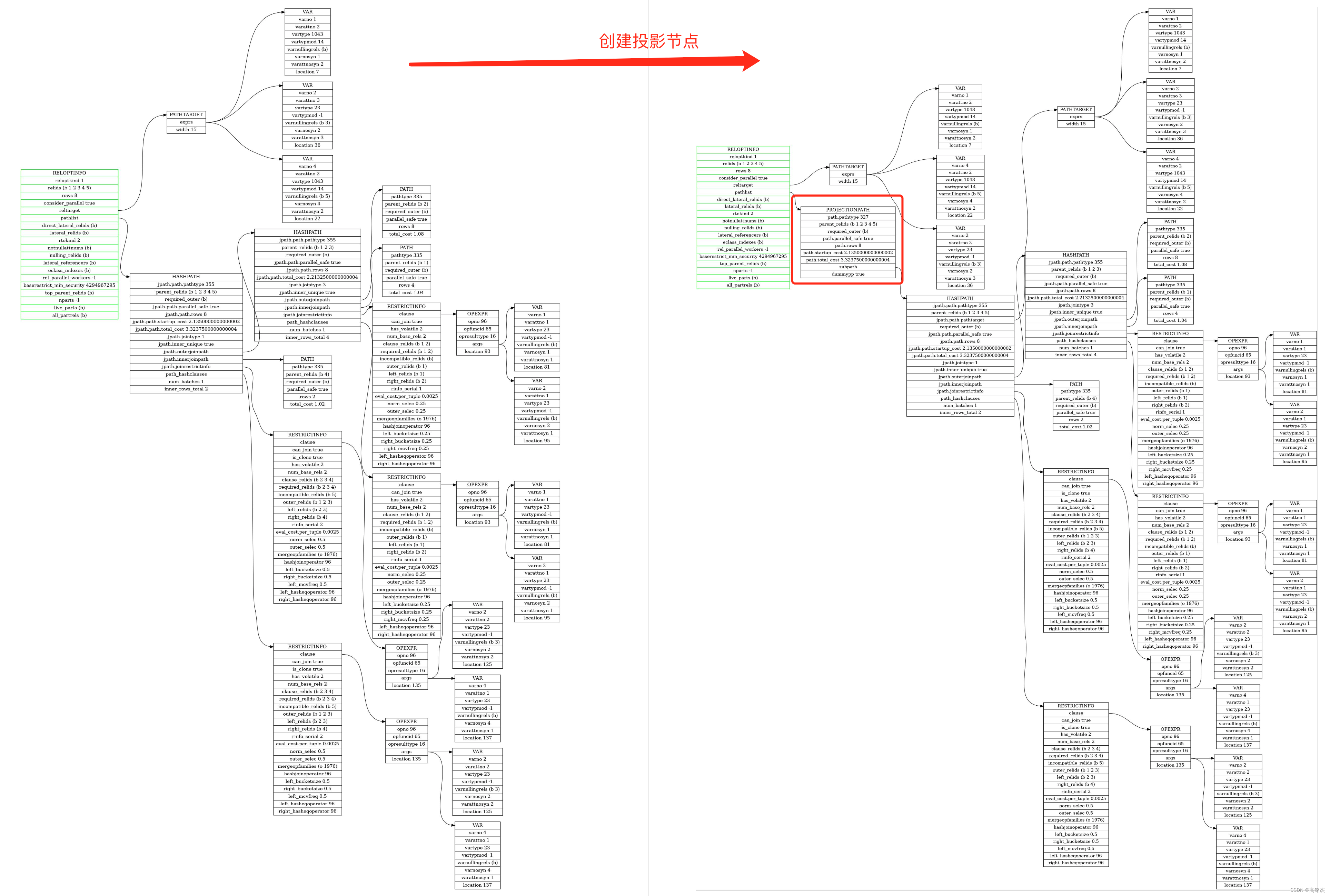
/* Apply scan/join target. */scanjoin_target_same_exprs = list_length(scanjoin_targets) == 1&& equal(scanjoin_target->exprs, current_rel->reltarget->exprs);apply_scanjoin_target_to_paths(root, current_rel, scanjoin_targets,scanjoin_targets_contain_srfs,scanjoin_target_parallel_safe,scanjoin_target_same_exprs);
- 继续
if (have_grouping)...if (activeWindows)...if (parse->distinctClause)...if (parse->sortClause)create_ordered_paths
- 创建空的最顶层节点
final_rel = fetch_upper_rel(root, UPPERREL_FINAL, NULL);
- 遍历current_rel中所有的path,用add_path加入到最顶层节点中。
- 其中limit、rowclock的场景需要特殊处理下。
foreach(lc, current_rel->pathlist)if (parse->rowMarks)create_lockrows_pathif (limit_needed(parse))create_limit_pathadd_path(final_rel, path);
grouping_planner函数执行结束,最后拼接的final_rel在upper_rels里面记录:
pathlist最上层是投影节点:

1.2 standard_planner→subquery_planner
subquery_planner中后续处理流程:
| 计划生成步骤 | 作用 |
|---|---|
| root = subquery_planner | 优化器入口,返回PlannerInfo,里面记录了一个最终的RelOptInfo相当于一张逻辑表,每个ROI都记录了多个path,表示不同的计算路径 |
| final_rel = fetch_upper_rel | 拿到最终的RelOptInfo |
| best_path = get_cheapest_fractional_path | 在RelOptInfo中选择一个最优的path |
| top_plan = create_plan→create_plan_recurse | 根据最优path生成计划 |
2 实例:【简单join】【排序非投影列】【投影列无函数】
drop table student;
create table student(sno int primary key, sname varchar(10), ssex int);
insert into student values(1, 'stu1', 0);
insert into student values(2, 'stu2', 1);
insert into student values(3, 'stu3', 1);
insert into student values(4, 'stu4', 0);drop table course;
create table course(cno int primary key, cname varchar(10), tno int);
insert into course values(20, 'meth', 10);
insert into course values(21, 'english', 11);drop table teacher;
create table teacher(tno int primary key, tname varchar(10), tsex int);
insert into teacher values(10, 'te1', 1);
insert into teacher values(11, 'te2', 0);drop table score;
create table score (sno int, cno int, degree int);
create index idx_score_sno on score(sno);
insert into score values (1, 20, 100);
insert into score values (1, 21, 89);
insert into score values (2, 20, 99);
insert into score values (2, 21, 90);
insert into score values (3, 20, 87);
insert into score values (3, 21, 20);
insert into score values (4, 20, 60);
insert into score values (4, 21, 70);explain verbose
SELECT STUDENT.sname, COURSE.cname, SCORE.degree
FROM STUDENT
LEFT JOIN SCORE ON STUDENT.sno = SCORE.sno
LEFT JOIN COURSE ON SCORE.cno = COURSE.cno
ORDER BY COURSE.cno;QUERY PLAN
--------------------------------------------------------------------------------------Sort (cost=3.44..3.46 rows=8 width=19)Output: student.sname, course.cname, score.degree, course.cnoSort Key: course.cno-> Hash Left Join (cost=2.14..3.32 rows=8 width=19)Output: student.sname, course.cname, score.degree, course.cnoInner Unique: trueHash Cond: (score.cno = course.cno)-> Hash Right Join (cost=1.09..2.21 rows=8 width=13)Output: student.sname, score.degree, score.cnoInner Unique: trueHash Cond: (score.sno = student.sno)-> Seq Scan on public.score (cost=0.00..1.08 rows=8 width=12)Output: score.sno, score.cno, score.degree-> Hash (cost=1.04..1.04 rows=4 width=9)Output: student.sname, student.sno-> Seq Scan on public.student (cost=0.00..1.04 rows=4 width=9)Output: student.sname, student.sno-> Hash (cost=1.02..1.02 rows=2 width=10)Output: course.cname, course.cno-> Seq Scan on public.course (cost=0.00..1.02 rows=2 width=10)Output: course.cname, course.cno
2.1 grouping_planner
grouping_plannercurrent_rel = query_planner(root, standard_qp_callback, &qp_extra);final_target = create_pathtarget(root, root->processed_tlist);if (parse->sortClause)sort_input_target = make_sort_input_target(root, final_target, &have_postponed_srfs);
make_sort_input_target函数的作用:
- 排序列可能不在最终的投影列里面,需要特殊处理下。
- 易变函数和成本很高的函数需要再投影列中识别出来,先排序,在计算。
- 因为1:sort limit场景可以少算一些。
- 因为2:易变函数每次算都可能不一样,先排序好了再算有利于结果集稳定,例如current_timestamp这种,期望是排序后给出的每一样的时间都是递增的,如果先排序在计算就能得到这种效果。
生成的final_target和sort_input_target相同,因为没看到srf函数、易变函数。
| final_target同sort_input_target | Var | 指向列 | sortgrouprefs |
|---|---|---|---|
| final_target->exprs->elements[0] | varno = 1, varattno = 2, vartype = 1043 | STUDENT.sname | 0 |
| final_target->exprs->elements[1] | varno = 4, varattno = 2, vartype = 1043 | COURSE.cname | 0 |
| final_target->exprs->elements[2] | varno = 2, varattno = 3, vartype = 23 | SCORE.degree | 0 |
| final_target->exprs->elements[3] | varno = 4, varattno = 1, vartype = 23 | COURSE.cno | 1 |
grouping_planner继续执行,开始生成排序path:
...if (parse->sortClause)current_rel = create_ordered_paths(root,current_rel,final_target,final_target_parallel_safe,have_postponed_srfs ? -1.0 :limit_tuples);
grouping_planner→create_ordered_paths
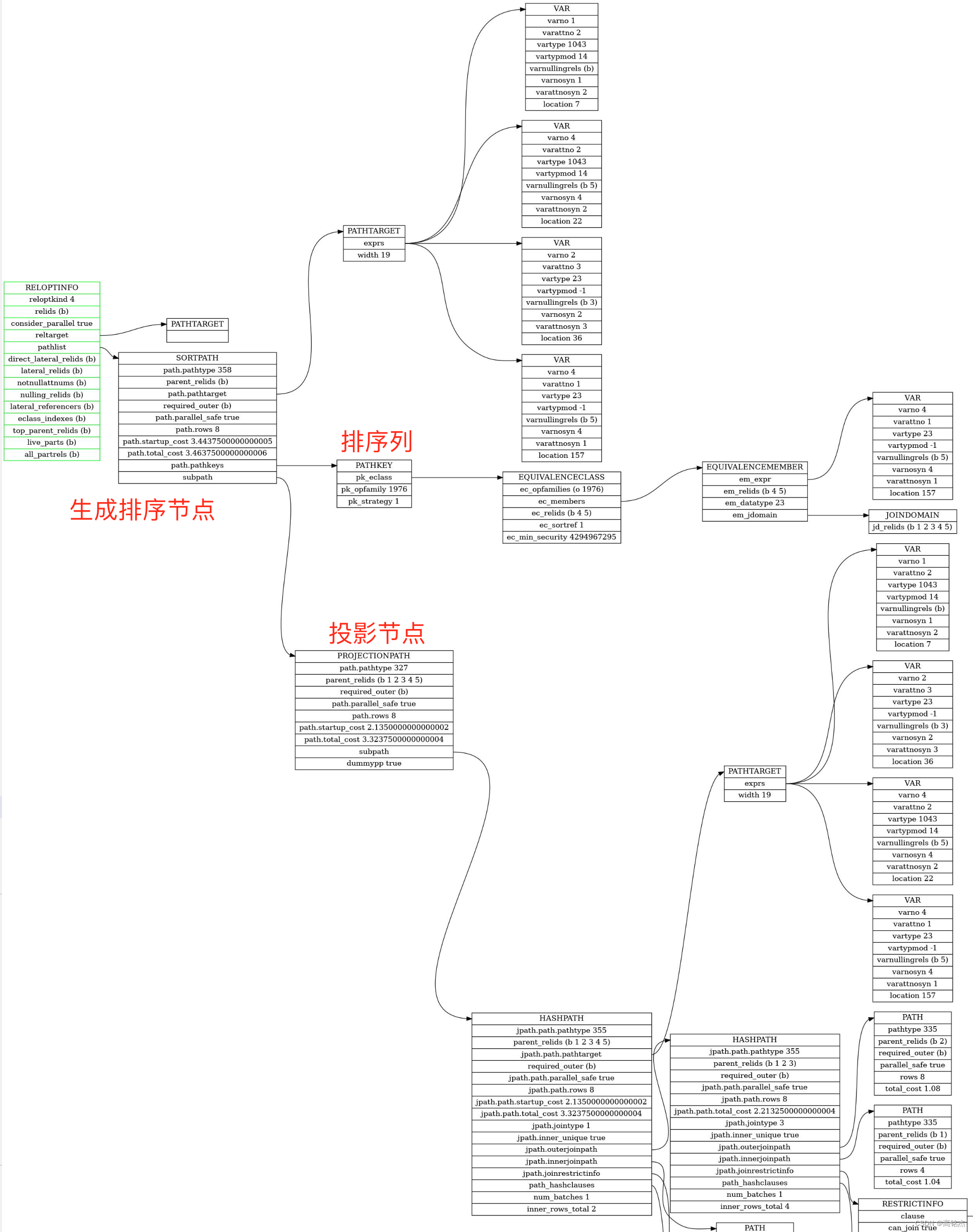
create_ordered_paths// 创建一个排序节点ordered_rel = fetch_upper_rel(root, UPPERREL_ORDERED, NULL);// 拿到path入口,目前顶层是T_ProjectionPath,就一个节点foreach(lc, input_rel->pathlist)// 判断input_path->pathkeys是不是有序的?// 因为现在计划树是hashjoin,每一列都是无序的,所以input_path->pathkeys是空的,需要排序is_sorted = pathkeys_count_contained_in(root->sort_pathkeys, input_path->pathkeys, &presorted_keys);if (is_sorted)sorted_path = input_path;elsesorted_path = (Path *) create_sort_path(root,ordered_rel,input_path,root->sort_pathkeys,limit_tuples);- 输入的path顶层节点是project本来没有带pathkeys信息,这里创建一个sort节点放在上面,加入pathkey信息。
- 但生成的sortpath没看到排序列的信息?
- 排序信息在基类path的pathkeys中。
sorted_path =
{ path = { type = T_SortPath, pathtype = T_Sort, parent = 0x2334030, pathtarget = 0x2333ef0, param_info = 0x0, parallel_aware = false, parallel_safe = true, parallel_workers = 0, rows = 8, startup_cost = 3.4437500000000005, total_cost = 3.4637500000000006, pathkeys = 0x232e018}, subpath = 0x2333a00}
T_PathKey每个pathkey(排序列)都对应了一个T_EquivalenceClass,T_EquivalenceClass中记录了排序的具体信息。
{ type = T_PathKey, pk_eclass = 0x232bf88, pk_opfamily = 1976, pk_strategy = 1, pk_nulls_first = false}
T_EquivalenceClass中的ec_members记录了排序列信息Var{varno = 4, varattno = 1}
{ type = T_EquivalenceClass, ec_opfamilies = 0x232ddf8, // List{ 1976 }ec_collation = 0, ec_members = 0x232df48, // List { EquivalenceMember }// EquivalenceMember{// type = T_EquivalenceMember, // em_expr = 0x232de68, Var{varno = 4, varattno = 1}// em_relids = 0x232de48, // em_is_const = false, // em_is_child = false, // em_datatype = 23, // em_jdomain = 0x2329158, em_parent = 0x0}ec_sources = 0x0, ec_derives = 0x0, ec_relids = 0x232df28,ec_has_const = false, ec_has_volatile = false, ec_broken = false, ec_sortref = 1, ec_min_security = 4294967295, ec_max_security = 0, ec_merged = 0x0}
生成排序节点后的计划:
- sort节点的target是四列,虽然sql只写了三列,但有一列是排序需要的,也会加到pathtarget中。
3 实例:【简单join】【排序非投影列】【投影列中有volatile函数】
drop table student;
create table student(sno int primary key, sname varchar(10), ssex int);
insert into student values(1, 'stu1', 0);
insert into student values(2, 'stu2', 1);
insert into student values(3, 'stu3', 1);
insert into student values(4, 'stu4', 0);drop table course;
create table course(cno int primary key, cname varchar(10), tno int);
insert into course values(20, 'meth', 10);
insert into course values(21, 'english', 11);drop table teacher;
create table teacher(tno int primary key, tname varchar(10), tsex int);
insert into teacher values(10, 'te1', 1);
insert into teacher values(11, 'te2', 0);drop table score;
create table score (sno int, cno int, degree int);
create index idx_score_sno on score(sno);
insert into score values (1, 20, 100);
insert into score values (1, 21, 89);
insert into score values (2, 20, 99);
insert into score values (2, 21, 90);
insert into score values (3, 20, 87);
insert into score values (3, 21, 20);
insert into score values (4, 20, 60);
insert into score values (4, 21, 70);explain verbose
SELECT STUDENT.sname, random(), SCORE.degree
FROM STUDENT
LEFT JOIN SCORE ON STUDENT.sno = SCORE.sno
LEFT JOIN COURSE ON SCORE.cno = COURSE.cno
ORDER BY COURSE.cno;QUERY PLAN
--------------------------------------------------------------------------------------------Result (cost=3.44..3.56 rows=8 width=21)Output: student.sname, random(), score.degree, course.cno-> Sort (cost=3.44..3.46 rows=8 width=13)Output: student.sname, score.degree, course.cnoSort Key: course.cno-> Hash Left Join (cost=2.14..3.32 rows=8 width=13)Output: student.sname, score.degree, course.cnoInner Unique: trueHash Cond: (score.cno = course.cno)-> Hash Right Join (cost=1.09..2.21 rows=8 width=13)Output: student.sname, score.degree, score.cnoInner Unique: trueHash Cond: (score.sno = student.sno)-> Seq Scan on public.score (cost=0.00..1.08 rows=8 width=12)Output: score.sno, score.cno, score.degree-> Hash (cost=1.04..1.04 rows=4 width=9)Output: student.sname, student.sno-> Seq Scan on public.student (cost=0.00..1.04 rows=4 width=9)Output: student.sname, student.sno-> Hash (cost=1.02..1.02 rows=2 width=4)Output: course.cno-> Seq Scan on public.course (cost=0.00..1.02 rows=2 width=4)Output: course.cno
3.1 grouping_planner→make_one_rel生成的RelOptInfo→reltarget
make_one_rel前:
准备连接的RelOptInfo在simple_rel_array数组中,这里关注下三个RelOptInfo的reltarget:
(gdb) plist root->simple_rel_array[1]->reltarget->exprs
$67 = 2
$68 = {ptr_value = 0x3083218, int_value = 50868760, oid_value = 50868760, xid_value = 50868760}
$69 = {ptr_value = 0x30ab8b8, int_value = 51034296, oid_value = 51034296, xid_value = 51034296}
(gdb) p root->simple_rte_array[1]->relid
$70 = 16564
| root→simple_rel_array[i] | simple_rel_array[i]→reltarget->exprs | relid |
|---|---|---|
| 1 | varno = 1, varattno = 2, vartype = 1043 | 16564 student.sname |
| 1 | varno = 1, varattno = 1, vartype = 23 | 16564 student.sno |
| 2 | varno = 2, varattno = 3, vartype = 23 | 16579 score.degree |
| 2 | varno = 2, varattno = 1, vartype = 23 | 16579 score.cno |
| 2 | varno = 2, varattno = 2, vartype = 23 | 16579 score.sno |
| 4 | varno = 4, varattno = 1, vartype = 23 | 16569 course.cno |
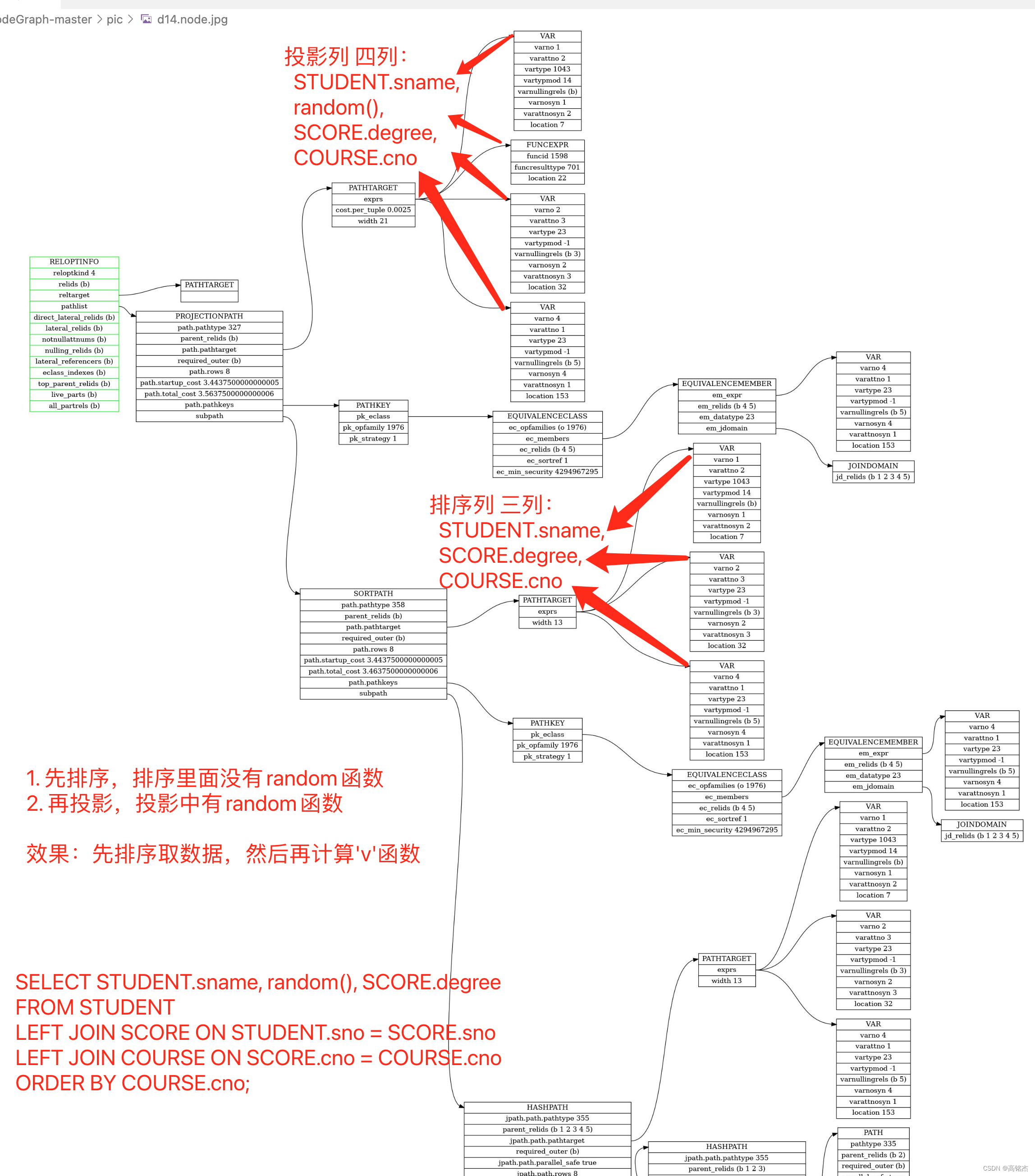
SELECT STUDENT.sname, random(), SCORE.degree
FROM STUDENT
LEFT JOIN SCORE ON STUDENT.sno = SCORE.sno
LEFT JOIN COURSE ON SCORE.cno = COURSE.cno
ORDER BY COURSE.cno;
make_one_rel生成后:
| final_rel->reltarget->exprs | 列 | |
|---|---|---|
| 1 | varno = 1, varattno = 2, vartype = 1043 | 投影第1列:STUDENT.sname |
| 2 | varno = 2, varattno = 3, vartype = 23 | 投影第3列:SCORE.degree |
| 3 | varno = 4, varattno = 1, vartype = 23 | 排序列:COURSE.cno |
3.2 grouping_planner→make_sort_input_target规律v函数生成排序target
final_target = create_pathtarget(root, root->processed_tlist);拿到的final_target:
| final_target | Var / FuncExpr | 指向列 | sortgrouprefs |
|---|---|---|---|
| final_target->exprs->elements[0] | varno = 1, varattno = 2, vartype = 1043 | STUDENT.sname | 0 |
| final_target->exprs->elements[1] | funcid = 1598, funcresulttype = 701 | random() | 0 |
| final_target->exprs->elements[2] | varno = 2, varattno = 3, vartype = 23 | SCORE.degree | 0 |
| final_target->exprs->elements[3] | varno = 4, varattno = 1, vartype = 23 | COURSE.cno | 1 |
make_sort_input_target拿到的sort_input_target,过滤掉了random列:
| sort_input_target | Var / FuncExpr | 指向列 | sortgrouprefs |
|---|---|---|---|
| sort_input_target->exprs->elements[0] | varno = 1, varattno = 2, vartype = 1043 | STUDENT.sname | 0 |
| sort_input_target->exprs->elements[1] | varno = 2, varattno = 3, vartype = 23 | SCORE.degree | 0 |
| sort_input_target->exprs->elements[2] | varno = 4, varattno = 1, vartype = 23 | COURSE.cno | 1 |
实例2中,apply_scanjoin_target_to_paths会先挂投影节点,后面的create_ordered_paths在创建顶层的排序节点,为什么这里的投影节点在最上层?因为有volatile函数在,需要先排序,在到投影节点上计算random函数
3.3 grouping_planner→apply_scanjoin_target_to_paths
final_target = create_pathtarget(root, root->processed_tlist);...sort_input_target = make_sort_input_target(...);...grouping_target = sort_input_target;...scanjoin_target = grouping_target;...scanjoin_targets = list_make1(scanjoin_target);...scanjoin_target_same_exprs = list_length(scanjoin_targets) == 1&& equal(scanjoin_target->exprs, current_rel->reltarget->exprs);...// 1 确定没有SRF list_length(scanjoin_targets) == 1// 2 这里make_one_rel出来的current_rel和上面make_sort_input_target计算出来的投影列一样,都过滤掉了v函数,剩下三列// scanjoin_target_same_exprs == truescanjoin_target_same_exprs = list_length(scanjoin_targets) == 1&& equal(scanjoin_target->exprs, current_rel->reltarget->exprs);apply_scanjoin_target_to_paths(root, current_rel, scanjoin_targets,scanjoin_targets_contain_srfs,scanjoin_target_parallel_safe,
注意:
- scanjoin_target->exprs:表示最终结果需要的targetlist。
- current_rel->reltarget->exprs:表示当前生成path中带的targetlist。
- 生成path的路径需要和scanjoin_target一致,所以进入下面函数判断是否生成投影节点。
- 如果相同,scanjoin_target_same_exprs==true,则不生成投影节点。
- 如果不同,scanjoin_target_same_exprs==false,则调用create_projection_path传入scanjoin_target,生成投影节点。
在apply_scanjoin_target_to_paths中:
apply_scanjoin_target_to_paths......foreach(lc, rel->pathlist){Path *subpath = (Path *) lfirst(lc);if (tlist_same_exprs)// scanjoin_target->sortgrouprefs = [0, 0, 1] 表示第三列是排序列// 因为现在的scanjoin_target(同sort_input_target)中只有三列,投影列1、3和排序列,参考上面sort_input_target表格。subpath->pathtarget->sortgrouprefs = scanjoin_target->sortgrouprefs;else{Path *newpath;newpath = (Path *) create_projection_path(root, rel, subpath,scanjoin_target);lfirst(lc) = newpath;}}
3.4 grouping_planner→create_ordered_paths
继续成成排序node:
grouping_planner...if (parse->sortClause)current_rel = create_ordered_paths(root,current_rel,final_target,final_target_parallel_safe,have_postponed_srfs ? -1.0 :limit_tuples);
- create_ordered_paths最重要的入参就是final_target,保存了全部的列信息和排序列的位置sortgrouprefs。
- 注意前面生成path中的reltarget已经过滤了random列,但这里没有过滤,需要全量的信息。
| final_target | Var / FuncExpr | 指向列 | sortgrouprefs |
|---|---|---|---|
| final_target->exprs->elements[0] | varno = 1, varattno = 2, vartype = 1043 | STUDENT.sname | 0 |
| final_target->exprs->elements[1] | funcid = 1598, funcresulttype = 701 | random() | 0 |
| final_target->exprs->elements[2] | varno = 2, varattno = 3, vartype = 23 | SCORE.degree | 0 |
| final_target->exprs->elements[3] | varno = 4, varattno = 1, vartype = 23 | COURSE.cno | 1 |
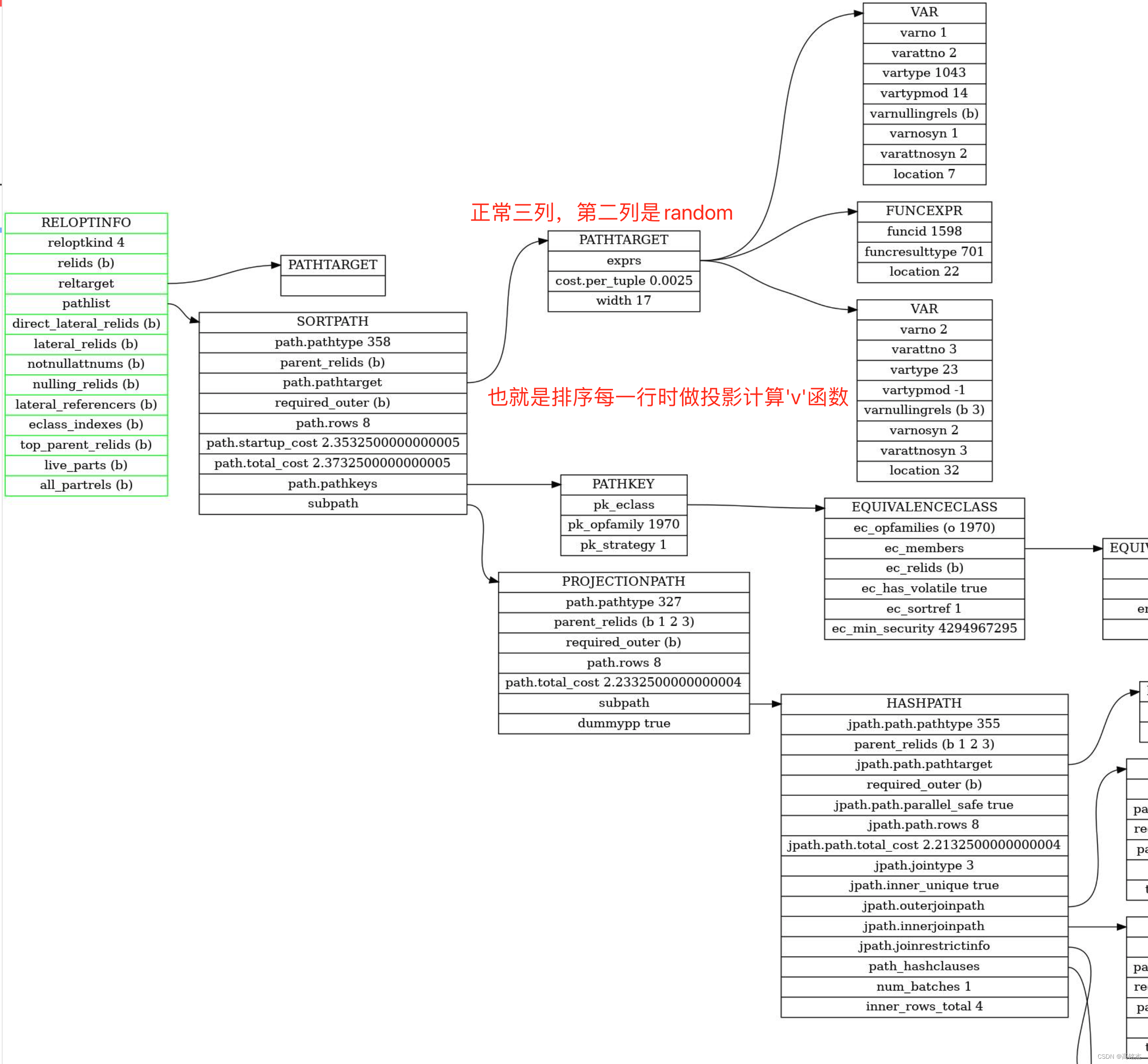
- 注意:这里create_sort_path为hashjoin节点上面加了一层sort节点,sort节点的pathtarget继承了hash节点的pathtarget,也就是三列(没有random函数列)。
- 注意:这里的target是上面表格中的final_target,也就是四列(带random函数)。
- 加了sort节点后,发现这里不相同,所以开始增加投影列apply_projection_to_path。
create_ordered_pathsordered_rel = fetch_upper_rel(root, UPPERREL_ORDERED, NULL);foreach(lc, input_rel->pathlist)is_sorted = pathkeys_count_contained_inif (is_sorted)sorted_path = input_path;elsesorted_path = (Path *) create_sort_path(...)// 生成sorted_path// {type = T_SortPath, pathtype = T_Sort, pathtarget = 三列 }if (sorted_path->pathtarget != target)sorted_path = apply_projection_to_path(root, ordered_rel, sorted_path, target);// 生成投影列// {type = T_ProjectionPath, pathtype = T_Result, pathtarget = 四列 }
最终生成PATH:
SELECT STUDENT.sname, random(), SCORE.degree
FROM STUDENT
LEFT JOIN SCORE ON STUDENT.sno = SCORE.sno
LEFT JOIN COURSE ON SCORE.cno = COURSE.cno
ORDER BY COURSE.cno;
最终效果:
4 实例:【简单join】【排序volatile函数】【投影列中有volatile函数】
drop table student;
create table student(sno int primary key, sname varchar(10), ssex int);
insert into student values(1, 'stu1', 0);
insert into student values(2, 'stu2', 1);
insert into student values(3, 'stu3', 1);
insert into student values(4, 'stu4', 0);drop table course;
create table course(cno int primary key, cname varchar(10), tno int);
insert into course values(20, 'meth', 10);
insert into course values(21, 'english', 11);drop table teacher;
create table teacher(tno int primary key, tname varchar(10), tsex int);
insert into teacher values(10, 'te1', 1);
insert into teacher values(11, 'te2', 0);drop table score;
create table score (sno int, cno int, degree int);
create index idx_score_sno on score(sno);
insert into score values (1, 20, 100);
insert into score values (1, 21, 89);
insert into score values (2, 20, 99);
insert into score values (2, 21, 90);
insert into score values (3, 20, 87);
insert into score values (3, 21, 20);
insert into score values (4, 20, 60);
insert into score values (4, 21, 70);explain verbose
SELECT STUDENT.sname, random(), SCORE.degree
FROM STUDENT
LEFT JOIN SCORE ON STUDENT.sno = SCORE.sno
LEFT JOIN COURSE ON SCORE.cno = COURSE.cno
ORDER BY random();QUERY PLAN
--------------------------------------------------------------------------------Sort (cost=2.35..2.37 rows=8 width=17)Output: student.sname, (random()), score.degreeSort Key: (random())-> Hash Right Join (cost=1.09..2.23 rows=8 width=17)Output: student.sname, random(), score.degreeInner Unique: trueHash Cond: (score.sno = student.sno)-> Seq Scan on public.score (cost=0.00..1.08 rows=8 width=12)Output: score.sno, score.cno, score.degree-> Hash (cost=1.04..1.04 rows=4 width=9)Output: student.sname, student.sno-> Seq Scan on public.student (cost=0.00..1.04 rows=4 width=9)Output: student.sname, student.sno
4.1 make_one_rel结果
第一步:拿到RelOptInfo
current_rel = query_planner(root, standard_qp_callback, &qp_extra);
current_rel->reltarget中忽略了random函数:
{ type = T_PathTarget, exprs = {Var{varno = 1, varattno = 2, vartype = 1043}, // STUDENT.snameVar{varno = 2, varattno = 3, vartype = 23} // SCORE.degree}, sortgrouprefs = 0x0 }
4.2 拿到final_target
final_target = create_pathtarget(root, root->processed_tlist);
{type = T_PathTarget, exprs = {Var{varno = 1, varattno = 2, vartype = 1043}, // STUDENT.snameFuncExpr {xpr = {type = T_FuncExpr}, funcid = 1598}, // random()Var{varno = 2, varattno = 3, vartype = 23} // SCORE.degree}, sortgrouprefs = [0, 1, 0]
}
4.3 构造排序target:make_sort_input_target
sort_input_target = make_sort_input_target(root, final_target, &have_postponed_srfs);
{type = T_PathTarget,exprs = {Var{varno = 1, varattno = 2, vartype = 1043}, // STUDENT.snameFuncExpr {xpr = {type = T_FuncExpr}, funcid = 1598}, // random()Var{varno = 2, varattno = 3, vartype = 23} // SCORE.degree}, sortgrouprefs = [0, 1, 0]
}
4.4 apply_scanjoin_target_to_paths增加投影
apply_scanjoin_target_to_paths执行后,增加投影节点:
{ path = {type = T_ProjectionPath, pathtype = T_Result }
4.5 create_ordered_paths后增加排序节点在最顶层
{ path = {type = T_SortPath, pathtype = T_Sort }
相关文章:
Postgresql源码(134)优化器针对volatile函数的排序优化分析
相关 《Postgresql源码(133)优化器动态规划生成连接路径的实例分析》 上一篇对路径的生成进行了分析,通过make_one_rel最终拿到了一个带着路径的RelOptInfo。本篇针对带volatile函数的排序场景继续分析subquery_planner的后续流程。 subquer…...

DES加密算法笔记
【DES加密算法|密码学|信息安全】https://www.bilibili.com/video/BV1KQ4y127AT?vd_source7ad69e0c2be65c96d9584e19b0202113 根据此视频学习 DES是对称密码中的分组加密算法 (分组加密对应流加密算法) 流加密算法就是一个字节一个字节加密 分组加…...

C语⾔:内存函数
1. memcpy使⽤和模拟实现(对内存块的复制,不在乎类型) void * memcpy ( void * destination, const void * source, size_t num ); • 函数memcpy从source的位置开始向后复制num个字节的数据到destination指向的内存位置。 • 这个函数在遇…...
SqliSniper:针对HTTP Header的基于时间SQL盲注模糊测试工具
关于SqliSniper SqliSniper是一款基于Python开发的强大工具,该工具旨在检测HTTP请求Header中潜在的基于时间的SQL盲注问题。 该工具支持通过多线程形式快速扫描和识别目标应用程序中的潜在漏洞,可以大幅增强安全评估过程,同时确保了速度和效…...

3W 1.5KVDC 隔离 宽范围输入,双隔离双输出 DC/DC 电源模块——TPD-3W系列
TPD-3W系列产品是专门针对线路板上分布式电源系统中需要产生一组与输入电源隔离的双隔离双电源的应用场合而设计。该产品适用于:1)输入电源的电压变化范围≤2:1 ;2)输入输出之间要求隔离≤1500VDC;3&#x…...
[java基础揉碎]文件IO流
目录 文件 什么是文件 文件流编辑 常用的文件操作 创建文件方式一 创建文件方式二 创建文件方式三 tip:为什么new file 了还有执行createNewFile?new File的时候其实是在内存中创建了文件对象, 还没有在磁盘中, 当执行createNewFile的时候才是往磁盘中写入编辑 …...
)
[面经] 西山居非正式面试(C++)
前言 这次面试是我第一次面试,而且我也并没有做好准备,应该说几乎就是临场发挥,面试的时间与我推测的相差太大,几乎就是做完简历的下一天就马上去面试了,有不少地方自己没能很好的答出,故做此记录。 关于…...
SOLIDWORKS教育版代理商应该如何选择?
SOLIDWORKS作为目前流行的三维设计软件在工程设计,制造和建筑中有着广泛的应用前景。教育版SOLIDWORKS软件是学生及教育机构学习教学的理想平台。 下面介绍几个挑选SOLIDWORKS教育版代理的关键要素: 1、专业知识与经验:代理商应掌握SOLIDWORKS等软件的丰…...
翻译《Use FILE_SHARE_DELETE in your shell extension》
在写 《翻译《The Old New Thing》- What did MakeProcInstance do?》 文章时,了解到了 Michael Geary ,他也有不少优秀的技术文章,现翻译一篇关于文件操作的细节的文章 原文 Use FILE_SHARE_DELETE in your shell extension | mg.tohttps:…...

使用Python发送电子邮件
大家好,当我们需要迅速、方便地与他人沟通时,电子邮件是无疑是一种不可或缺的通信工具。无论是在个人生活中还是工作场合,电子邮件都是我们日常生活中的重要组成部分。它不仅能够传递文字信息,还可以发送附件、链接和嵌入式多媒体…...
Linux-CentOS7-解决vim修改不了主机名称(无法打开并写入文件)
Linux-CentOS7-修改主机名称 修改之后使用强制保存退出也不行。 解决办法: 使用hostnamectl命令进行修改 查看系统主机名和信息: hostnamectl这条命令会显示当前系统的主机名、操作系统信息、内核版本、架构信息等相关信息。 修改系统主机名࿱…...
【RuoYi】使用代码生成器完成CRUD操作
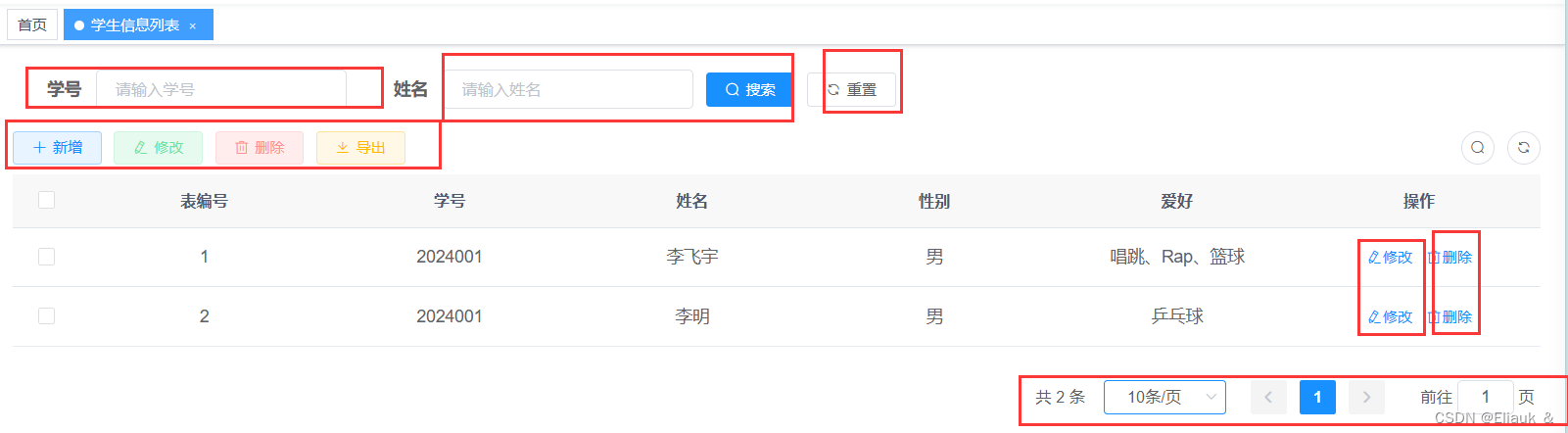
一、前言 前面,介绍了如何下载和启动我们的RuoYi框架。为了让小伙伴们认识到ruoyi的强大,那么这篇博客就介绍一下如何使用ruoyi的代码生成器,自动生成前端页面以及后端的对应数据库表的CRUD操作!!!真的很强…...

七个很酷的GenAI LLM技术性面试问题
不同于互联网上随处可见的传统问题库,这些问题需要跳出常规思维。 大语言模型(LLM)在数据科学、生成式人工智能(GenAI)和人工智能领域越来越重要。这些复杂的算法提升了人类的技能,并在诸多行业中推动了效率和创新性的提升,成为企业保持竞争…...

SARscape雷达图像处理软件简介
合成孔径雷达(SAR)拥有独特的技术魅力和优势,渐成为国际上的研究热点之一,其应用领域越来越广泛。SAR数据可以全天候对研究区域进行量测、分析以及获取目标信息。高级雷达图像处理工具SARscape,能让您轻松将原始SAR数据…...

开源博客项目Blog .NET Core源码学习(23:App.Hosting项目结构分析-11)
本文学习并分析App.Hosting项目中后台管理页面的标签管理页面、轮播图维护页面。 标签管理页面 标签管理页面用于显示、检索、新建、编辑、删除标签数据,以便在前台页面的首页及文章专栏等页面显示标签数据。标签管理页面附带一新建及编辑页面,以支撑新…...

一.ffmpeg 将内存中的H264跟PCM 数据流合成多媒体文件
在有一些嵌入式平台中,H264数据流一般来自芯片内部的硬编码器, AAC音频数据则是通过采集PCM进行软编码,但是如何对它实时进行封装多媒体文件 ,参考ffmpeg example,花了一些时间终于实现了该功能。 流程图如下…...

C++ (week5):Linux系统编程3:线程
文章目录 三、线程1.线程的基本概念①线程相关概念②我的理解 2.线程的基本操作 (API)(1)获取线程的标识:pthread_self(2)创建线程:pthread_create()(3)终止线程①pthread_exit():当前线程终止,子线程主动退出②pthread_cancel()&…...
二叉树习题精讲-相同的树
相同的树 100. 相同的树 - 力扣(LeetCode)https://leetcode.cn/problems/same-tree/description/ /*** Definition for a binary tree node.* struct TreeNode {* int val;* struct TreeNode *left;* struct TreeNode *right;* };*/ bool i…...

「架构」模型驱动架构设计方法及其运用
本文通过一个实际的软件项目案例,深入探讨了模型驱动架构(MDA)在软件开发全过程中的应用。MDA是一种以模型为中心的设计方法,它通过分离计算、数据和业务逻辑,提高了软件的可维护性、可扩展性和可移植性。文章将从需求分析、架构设计、实现与测试三个阶段出发,分析MDA的应…...

基于 React + Nest 全栈开发的后台系统
Xmw Admin 基于 React Nest 全栈开发的后台系统 🪴 项目简介 🎯 前端技术栈: React、Ant Design、Umi、TypeScript🎯 后端技术栈: Nest.js、Sequelize、Redis、Mysql😝 线上预览: https://r…...

LeetCode 找到最终的安全状态题解
LeetCode 找到最终的安全状态题解 题目描述 给定一个有向图,找到所有安全节点。安全节点是永远不会走向环的节点。 示例: 输入:graph [[1,2],[2,3],[5],[0],[5],[],[]]输出:[2,4,5,6] 解题思路 方法:拓扑排序 思路&am…...

2026年AI求职必看:掌握这3类岗位核心技能,年薪百万不是梦!收藏备用
本文分析了AI行业招聘市场的两极分化现象,并深入拆解了算法工程师、大模型应用开发、AI产品经理三类热门岗位的真实招聘要求和面试准备重点。文章指出,企业对AI人才的要求已从"会调模型"转向"能落地产品",复合型人才需求…...

Keil MDK中EVR选项缺失的解决方案与原理
1. 问题现象解析:EVR选项缺失的典型表现 在Keil MDK开发环境中使用Event Recorder(事件记录器)时,开发者常会遇到一个令人困惑的现象:按照官方文档配置printf重定向到EVR时,STDOUT的下拉菜单中本该出现的&q…...
)
毕设救星:手把手教你用Android Studio和OkHttp3搞定OneNET新版API数据获取(附完整Java代码)
物联网毕设实战:Android Studio对接OneNET新版API全流程解析 在物联网相关专业的毕业设计中,如何快速构建一个能实际运行的设备数据监控APP往往是让本科生头疼的难题。本文将手把手带你完成从零开始的完整开发流程,重点解决三个核心痛点&…...

用Logisim从零搭建一个8位求补器:手把手教你理解补码的硬件实现
用Logisim从零搭建一个8位求补器:手把手教你理解补码的硬件实现 数字电路设计中最精妙的概念之一,莫过于补码表示法。它不仅解决了计算机中正负数的统一表示问题,还让加减法运算可以用同一套电路完成。但你是否好奇过,这个看似简单…...

别再只调参了!深入pix2pixHD的多尺度鉴别器与实例地图,解决你的图像合成‘塑料感’难题
突破图像合成瓶颈:pix2pixHD多尺度鉴别器与实例地图的实战精要 当你在深夜调试生成对抗网络,屏幕上的合成图像却始终带着难以消除的"塑料感"——表面过于光滑、边缘模糊、纹理缺乏层次。这种挫败感或许正是促使你点开本文的原因。作为GAN领域的…...

从KITTI的pkl文件到模型输入:OpenPCDet数据流水线内部运作全揭秘
从KITTI的pkl文件到模型输入:OpenPCDet数据流水线内部运作全揭秘 在3D目标检测领域,KITTI数据集作为行业标杆,其数据处理流程的复杂性往往成为算法落地的第一道门槛。OpenPCDet框架通过精心设计的预处理系统,将原始传感器数据转化…...

C AI 编程助手:助力开发者高效编程
C AI 编程助手:助力开发者高效编程 引言 随着人工智能技术的飞速发展,编程领域也迎来了新的变革。C AI 编程助手作为一种新兴的智能编程工具,旨在帮助开发者提高编程效率,降低开发成本。本文将详细介绍C AI 编程助手的功能、优势以及应用场景,帮助开发者更好地了解这一创…...

从设计到验证:如何用ADS的HB2TonePAE_FPswp模板快速评估你的PA线性度?
射频功放线性度评估实战:ADS高级仿真模板深度解析 在射频功率放大器(PA)的设计流程中,线性度评估往往是最耗时的环节之一。传统方法需要工程师手动搭建测试平台,不仅效率低下,还容易引入人为误差。Keysight ADS软件内置的HB2ToneP…...

终极指南:如何快速免费解决GBK到UTF-8编码转换难题
终极指南:如何快速免费解决GBK到UTF-8编码转换难题 【免费下载链接】GBKtoUTF-8 To transcode text files from GBK to UTF-8 项目地址: https://gitcode.com/gh_mirrors/gb/GBKtoUTF-8 还在为乱码文件而烦恼吗?GBKtoUTF-8是一款专为中文文本编码…...