十种常用数据分析方法
-
描述性统计分析(Descriptive Statistics)
-
使用场景:用来总结数据的基本特征,如平均值、中位数、标准差等。
-
优势:简单易懂,快速总结数据。
-
劣势:无法深入挖掘数据的潜在关系。
-
模拟数据及示例代码:
import pandas as pd import numpy as np# 生成模拟数据 data = {"user_log_acct": ["linfbi007", "13601089905_p", "jd_UbSjKwFGOfbv"] * 100,"parent_sale_ord_id": np.random.randint(100000000000, 200000000000, size=300),"sale_ord_id": np.random.randint(100000000000, 200000000000, size=300),"sale_ord_tm": pd.date_range(start="2023-01-01", periods=300, freq="H").tolist(),"item_sku_id": np.random.randint(100000000, 200000000, size=300),"item_name": ["冰箱", "洗衣机", "电视"] * 100,"brandname": ["新飞", "海尔", "小米"] * 100,"sale_qtty": np.random.randint(1, 5, size=300),"item_first_cate_name": ["家用电器"] * 300,"item_second_cate_name": ["大家电"] * 300,"item_third_cate_name": ["冰箱", "洗衣机", "电视"] * 100,"before_prefr_unit_price": np.random.uniform(1000, 2000, size=300),"after_prefr_unit_price": np.random.uniform(800, 1500, size=300),"user_actual_pay_amount": np.random.uniform(700, 1400, size=300),"sale_ord_valid_flag": [1] * 300,"cancel_flag": [0] * 300,"check_account_tm": pd.date_range(start="2023-01-01", periods=300, freq="H").tolist(),"total_offer_amount": np.random.uniform(100, 500, size=300),"self_ord_flag": [1, 0] * 150,"user_site_city_id": np.random.randint(1, 100, size=300),"user_site_province_id": np.random.randint(1, 30, size=300),"user_lv_cd": [0, 1, 2] * 100 }df = pd.DataFrame(data)# 描述性统计分析 desc_stats = df.describe() print(desc_stats)
结果: 描述性统计结果包括每个数值字段的计数、平均值、标准差、最小值、25%分位数、50%分位数、75%分位数和最大值。通过这些数据,可以初步了解数据的分布情况。
判断:识别出用户实际支付金额的均值和标准差,帮助定价策略。了解各个商品类别的销量分布情况,便于库存管理。
-
-
数据可视化(Data Visualization)
- 使用场景:通过图表展示数据,发现趋势和模式。
- 优势:直观易懂,便于发现数据中的规律。
- 劣势:图表的准确性和美观度受数据和设计影响。
- 模拟数据及示例代码:
import matplotlib.pyplot as plt# 销售数量分布图 plt.figure(figsize=(10, 6)) df['sale_qtty'].hist(bins=20) plt.title('Sales Quantity Distribution') plt.xlabel('Quantity') plt.ylabel('Frequency') plt.show()
-
结果: 通过绘制销售数量的直方图,可以看到不同销售数量的频率分布,判断出哪些销售量区间是最常见的。
-
判断:确定销售数量的常见区间,便于营销策略的制定。识别异常销售量,分析其原因。
-
相关性分析(Correlation Analysis)
- 使用场景:分析两个或多个变量之间的线性关系。
- 优势:揭示变量间的关系,便于进一步建模。
- 劣势:仅限于线性关系,无法捕捉非线性关系。
- 模拟数据及示例代码:
# 相关性分析 correlation_matrix = df.corr() print(correlation_matrix)
结果: 生成变量之间的相关系数矩阵,了解每对变量之间的相关程度。
判断:
- 确定价格和销量之间的关系,优化定价策略。
- 识别促销活动对实际支付金额的影响,调整促销方案。
-
假设检验(Hypothesis Testing)
- 使用场景:验证假设,判断样本数据是否支持某个假设。
- 优势:提供统计依据,支持决策。
- 劣势:需要设定显著性水平,结果受样本量影响。
- 模拟数据及示例代码:
from scipy import stats# 检验用户实际支付金额的均值是否为1000 t_stat, p_value = stats.ttest_1samp(df['user_actual_pay_amount'], 1000) print(f"T-statistic: {t_stat}, P-value: {p_value}")
结果: 计算T统计量和P值,通过P值判断是否拒绝原假设。
判断:
- 如果P值小于显著性水平(如0.05),则拒绝原假设,说明用户实际支付金额显著不同于1000。
- 帮助优化定价策略。
-
回归分析(Regression Analysis)
- 使用场景:预测变量之间的关系,用于预测和因果分析。
- 优势:能量化多个因素的影响,进行预测。
- 劣势:需要满足一定假设,复杂模型需要更多计算资源。
- 模拟数据及示例代码:
import statsmodels.api as sm# 线性回归分析 X = df[['before_prefr_unit_price', 'total_offer_amount', 'sale_qtty']] y = df['user_actual_pay_amount'] X = sm.add_constant(X) model = sm.OLS(y, X).fit() print(model.summary())
结果: 生成回归分析的详细报告,包括系数、标准误、P值等。
判断:
- 识别主要影响用户支付金额的因素,优化营销策略。
- 通过模型进行销售预测,改进库存管理。
-
聚类分析(Clustering Analysis)
- 使用场景:将数据分组,发现数据中的自然分类。
- 优势:便于发现潜在的用户群体或商品类别。
- 劣势:需要确定聚类数,结果解释较为复杂。
- 模拟数据及示例代码:
from sklearn.cluster import KMeans# 聚类分析 kmeans = KMeans(n_clusters=3) df['cluster'] = kmeans.fit_predict(df[['before_prefr_unit_price', 'total_offer_amount', 'sale_qtty']]) print(df['cluster'].value_counts())
结果: 每个聚类的样本数量分布,了解数据的聚类情况。
判断:
- 识别不同用户群体,进行精准营销。
- 分类商品,优化推荐系统。
-
时间序列分析(Time Series Analysis)
- 使用场景:分析时间序列数据的趋势和季节性变化。
- 优势:预测未来趋势,进行库存和资源规划。
- 劣势:模型复杂,需要较长时间序列数据。
- 模拟数据及示例代码:
from statsmodels.tsa.seasonal import seasonal_decompose# 时间序列分析 df.set_index('sale_ord_tm', inplace=True) result = seasonal_decompose(df['user_actual_pay_amount'], model='additive', period=24) result.plot() plt.show()
结果: 分解时间序列,得到趋势、季节性和残差成分。
判断:
- 识别销售趋势,调整营销策略。
- 预测季节性变化,优化库存管理。
-
频繁项集和关联规则挖掘(Association Rule Mining)
- 使用场景:发现商品之间的购买关联,提高交叉销售。
- 优势:揭示商品间的潜在关系,提升销售额。
- 劣势:规则数量庞大,需筛选有意义的规则。
- 模拟数据及示例代码:
from mlxtend.frequent_patterns import apriori, association_rules# 生成模拟购物篮数据 basket = df.groupby(['sale_ord_id', 'item_name']).size().unstack().reset_index().fillna(0).set_index('sale_ord_id')# 频繁项集 frequent_itemsets = apriori(basket, min_support=0.1, use_colnames=True) rules = association_rules(frequent_itemsets, metric="lift", min_threshold=1) print(rules.head())
结果: 生成关联规则,包括支持度、置信度和提升度。
判断:
- 识别经常一起购买的商品,优化商品组合。
- 提升交叉销售策略,提高销售额。
-
分类分析(Classification Analysis)
- 使用场景:对用户或商品进行分类,用于精准营销或风险评估。
- 优势:便于预测新样本的类别,优化策略。
- 劣势:需大量标记数据,复杂模型需更多计算资源。
- 模拟数据及示例代码:
from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import classification_report# 分类分析 X = df[['before_prefr_unit_price', 'total_offer_amount', 'sale_qtty']] y = df['user_lv_cd'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42) clf = RandomForestClassifier() clf.fit(X_train, y_train) y_pred = clf.predict(X_test) print(classification_report(y_test, y_pred))
结果: 生成分类报告,包括精确度、召回率和F1分数。
判断:
- 识别用户等级,进行精准营销。
- 评估商品风险,优化库存策略。
-
异常检测(Anomaly Detection)
- 使用场景:检测异常交易或行为,防范风险。
- 优势:发现异常情况,防止损失。
- 劣势:模型复杂,需调整参数。
- 模拟数据及示例代码:
from sklearn.ensemble import IsolationForest# 异常检测 iso_forest = IsolationForest(contamination=0.1) df['anomaly'] = iso_forest.fit_predict(df[['user_actual_pay_amount', 'sale_qtty']]) print(df['anomaly'].value_counts())
结果: 识别出异常样本的数量和分布。
判断: 发现异常交易,防范欺诈行为。识别异常用户行为,进行风险控制。
相关文章:

十种常用数据分析方法
描述性统计分析(Descriptive Statistics) 使用场景:用来总结数据的基本特征,如平均值、中位数、标准差等。 优势:简单易懂,快速总结数据。 劣势:无法深入挖掘数据的潜在关系。 模拟数据及示例…...
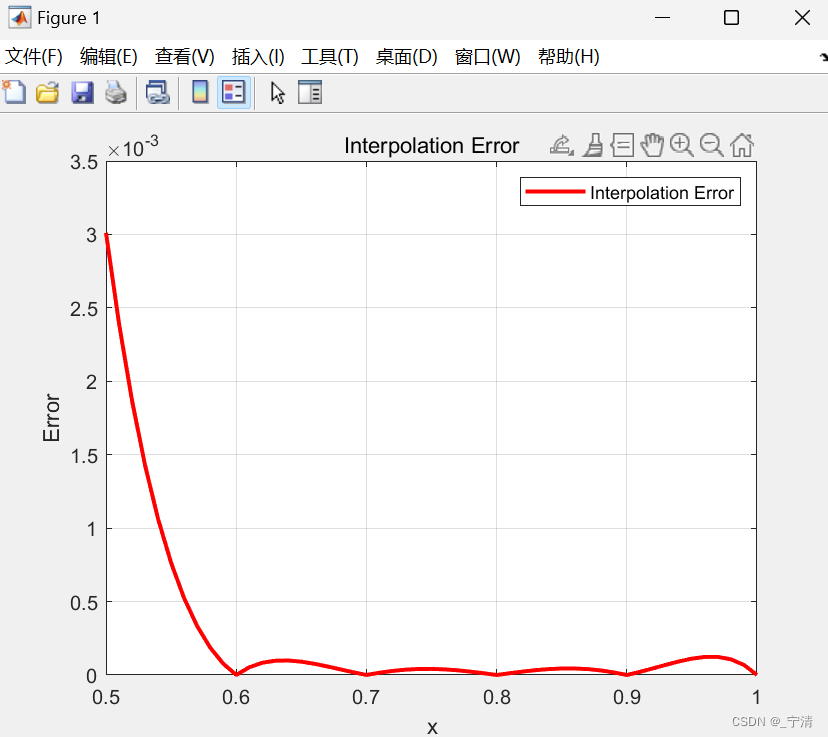
拉格朗日插值及牛顿差商方法的实现(Matlab)
一、问题描述 拉格朗日插值及牛顿差商方法的实现。 二、实验目的 掌握拉格朗日插值和牛顿差商方法的原理,能够编写代码实现两种方法;能够分析多项式插值中的误差。 三、实验内容及要求 利用拉格朗日插值及牛顿差商方法估计1980 年的人口,并…...

【InternLM实战营第二期笔记】02:大模型全链路开源体系与趣味demo
文章目录 00 环境设置01 部署一个 chat 小模型作业一 02 Lagent 运行 InternLM2-chat-7B运行一个工具调用解方程 03 浦语灵笔2进阶作业 第二节课程视频与文档: https://www.bilibili.com/video/BV1AH4y1H78d/ https://github.com/InternLM/Tutorial/blob/camp2/hell…...
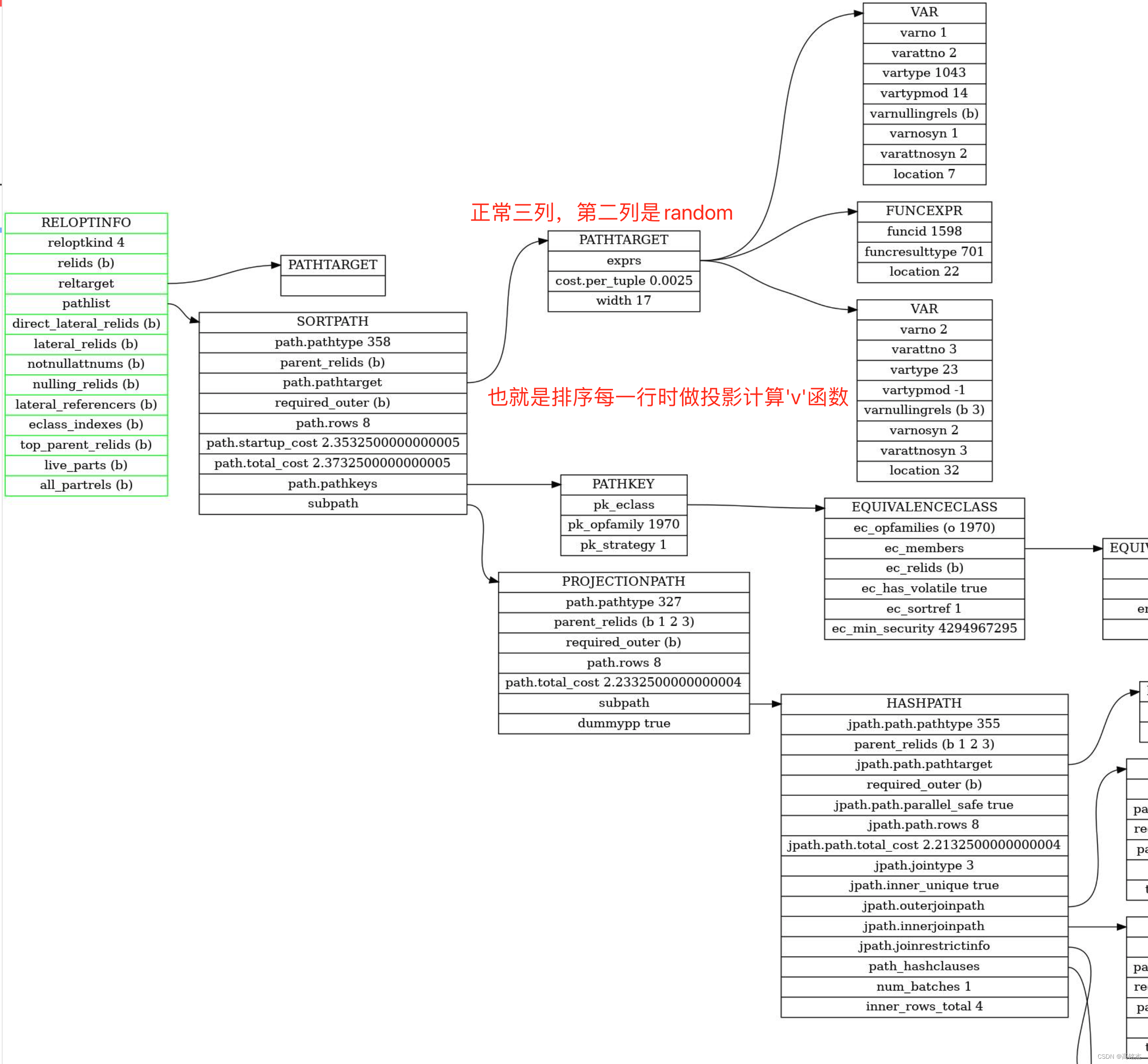
Postgresql源码(134)优化器针对volatile函数的排序优化分析
相关 《Postgresql源码(133)优化器动态规划生成连接路径的实例分析》 上一篇对路径的生成进行了分析,通过make_one_rel最终拿到了一个带着路径的RelOptInfo。本篇针对带volatile函数的排序场景继续分析subquery_planner的后续流程。 subquer…...

DES加密算法笔记
【DES加密算法|密码学|信息安全】https://www.bilibili.com/video/BV1KQ4y127AT?vd_source7ad69e0c2be65c96d9584e19b0202113 根据此视频学习 DES是对称密码中的分组加密算法 (分组加密对应流加密算法) 流加密算法就是一个字节一个字节加密 分组加…...

C语⾔:内存函数
1. memcpy使⽤和模拟实现(对内存块的复制,不在乎类型) void * memcpy ( void * destination, const void * source, size_t num ); • 函数memcpy从source的位置开始向后复制num个字节的数据到destination指向的内存位置。 • 这个函数在遇…...
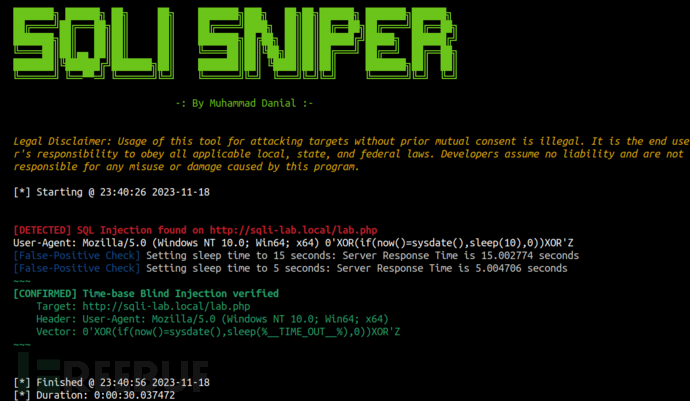
SqliSniper:针对HTTP Header的基于时间SQL盲注模糊测试工具
关于SqliSniper SqliSniper是一款基于Python开发的强大工具,该工具旨在检测HTTP请求Header中潜在的基于时间的SQL盲注问题。 该工具支持通过多线程形式快速扫描和识别目标应用程序中的潜在漏洞,可以大幅增强安全评估过程,同时确保了速度和效…...

3W 1.5KVDC 隔离 宽范围输入,双隔离双输出 DC/DC 电源模块——TPD-3W系列
TPD-3W系列产品是专门针对线路板上分布式电源系统中需要产生一组与输入电源隔离的双隔离双电源的应用场合而设计。该产品适用于:1)输入电源的电压变化范围≤2:1 ;2)输入输出之间要求隔离≤1500VDC;3&#x…...
[java基础揉碎]文件IO流
目录 文件 什么是文件 文件流编辑 常用的文件操作 创建文件方式一 创建文件方式二 创建文件方式三 tip:为什么new file 了还有执行createNewFile?new File的时候其实是在内存中创建了文件对象, 还没有在磁盘中, 当执行createNewFile的时候才是往磁盘中写入编辑 …...
)
[面经] 西山居非正式面试(C++)
前言 这次面试是我第一次面试,而且我也并没有做好准备,应该说几乎就是临场发挥,面试的时间与我推测的相差太大,几乎就是做完简历的下一天就马上去面试了,有不少地方自己没能很好的答出,故做此记录。 关于…...
SOLIDWORKS教育版代理商应该如何选择?
SOLIDWORKS作为目前流行的三维设计软件在工程设计,制造和建筑中有着广泛的应用前景。教育版SOLIDWORKS软件是学生及教育机构学习教学的理想平台。 下面介绍几个挑选SOLIDWORKS教育版代理的关键要素: 1、专业知识与经验:代理商应掌握SOLIDWORKS等软件的丰…...
翻译《Use FILE_SHARE_DELETE in your shell extension》
在写 《翻译《The Old New Thing》- What did MakeProcInstance do?》 文章时,了解到了 Michael Geary ,他也有不少优秀的技术文章,现翻译一篇关于文件操作的细节的文章 原文 Use FILE_SHARE_DELETE in your shell extension | mg.tohttps:…...

使用Python发送电子邮件
大家好,当我们需要迅速、方便地与他人沟通时,电子邮件是无疑是一种不可或缺的通信工具。无论是在个人生活中还是工作场合,电子邮件都是我们日常生活中的重要组成部分。它不仅能够传递文字信息,还可以发送附件、链接和嵌入式多媒体…...
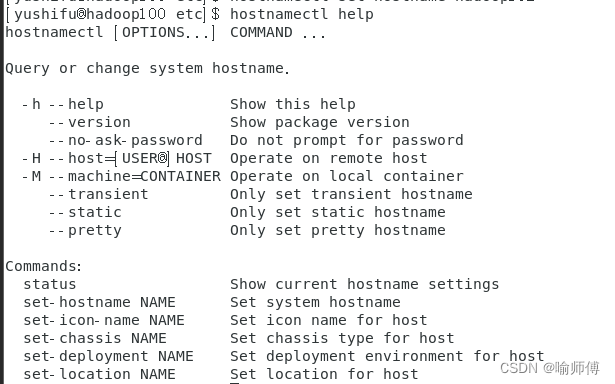
Linux-CentOS7-解决vim修改不了主机名称(无法打开并写入文件)
Linux-CentOS7-修改主机名称 修改之后使用强制保存退出也不行。 解决办法: 使用hostnamectl命令进行修改 查看系统主机名和信息: hostnamectl这条命令会显示当前系统的主机名、操作系统信息、内核版本、架构信息等相关信息。 修改系统主机名࿱…...
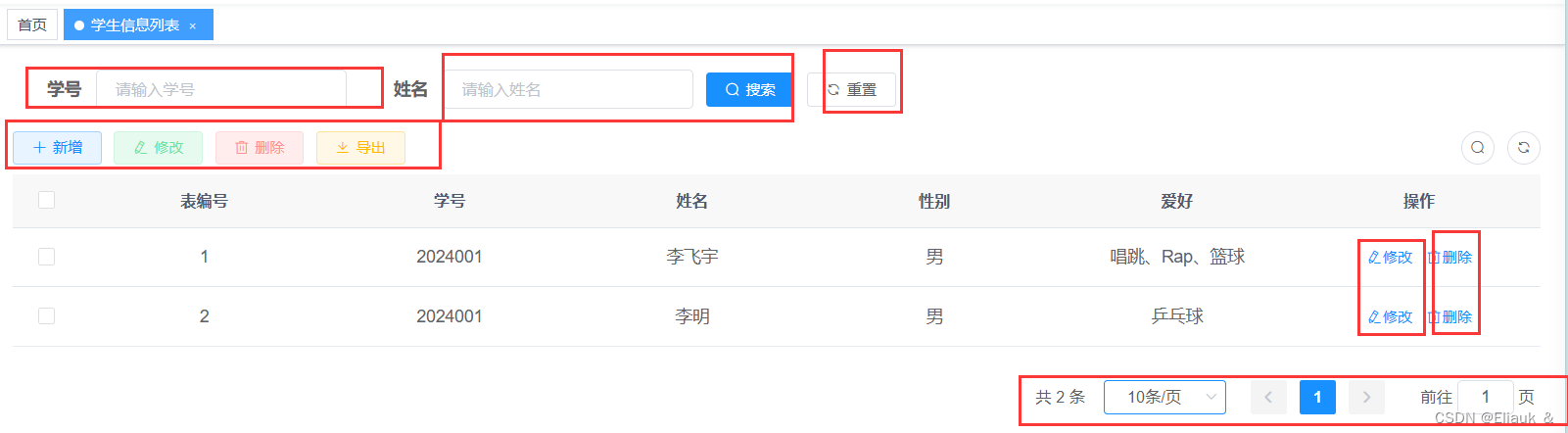
【RuoYi】使用代码生成器完成CRUD操作
一、前言 前面,介绍了如何下载和启动我们的RuoYi框架。为了让小伙伴们认识到ruoyi的强大,那么这篇博客就介绍一下如何使用ruoyi的代码生成器,自动生成前端页面以及后端的对应数据库表的CRUD操作!!!真的很强…...

七个很酷的GenAI LLM技术性面试问题
不同于互联网上随处可见的传统问题库,这些问题需要跳出常规思维。 大语言模型(LLM)在数据科学、生成式人工智能(GenAI)和人工智能领域越来越重要。这些复杂的算法提升了人类的技能,并在诸多行业中推动了效率和创新性的提升,成为企业保持竞争…...

SARscape雷达图像处理软件简介
合成孔径雷达(SAR)拥有独特的技术魅力和优势,渐成为国际上的研究热点之一,其应用领域越来越广泛。SAR数据可以全天候对研究区域进行量测、分析以及获取目标信息。高级雷达图像处理工具SARscape,能让您轻松将原始SAR数据…...

开源博客项目Blog .NET Core源码学习(23:App.Hosting项目结构分析-11)
本文学习并分析App.Hosting项目中后台管理页面的标签管理页面、轮播图维护页面。 标签管理页面 标签管理页面用于显示、检索、新建、编辑、删除标签数据,以便在前台页面的首页及文章专栏等页面显示标签数据。标签管理页面附带一新建及编辑页面,以支撑新…...

一.ffmpeg 将内存中的H264跟PCM 数据流合成多媒体文件
在有一些嵌入式平台中,H264数据流一般来自芯片内部的硬编码器, AAC音频数据则是通过采集PCM进行软编码,但是如何对它实时进行封装多媒体文件 ,参考ffmpeg example,花了一些时间终于实现了该功能。 流程图如下…...

C++ (week5):Linux系统编程3:线程
文章目录 三、线程1.线程的基本概念①线程相关概念②我的理解 2.线程的基本操作 (API)(1)获取线程的标识:pthread_self(2)创建线程:pthread_create()(3)终止线程①pthread_exit():当前线程终止,子线程主动退出②pthread_cancel()&…...

并发编程小记---5.17
final类型的特点:final 变量:赋值后不能改(引用地址不可变)final 方法:不能被子类重写final 类:不能被继承引用类型:Java 数据类型就两种:基本数据类型:byte short int l…...

观察使用Token Plan套餐前后月度AI调用成本的变化趋势
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察使用Token Plan套餐前后月度AI调用成本的变化趋势 对于频繁调用大模型API的开发者或团队而言,成本的可预测性与可控…...

记一次 mac openClaw gateway 启动未正常关闭导致的问题
openclaw 目前是一个比较火的 AI 工具,因为其高权限带来了一系列的风险和安全隐患按照官方步骤删除后,因open claw 的 gateway 没有正常关闭,导致端口一直在后台运行如果您也遇到类似的问题,可在 mac 终端执行如下命令进行关闭1.先…...

中兴光猫深度管理终极指南:一键开启工厂模式与永久Telnet服务
中兴光猫深度管理终极指南:一键开启工厂模式与永久Telnet服务 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 在当今家庭和企业网络中,中兴光猫设备扮演着至关重…...

别再只用箱线图了!用R语言ggplot2绘制高颜值小提琴图,让你的SCI图表更专业
科研数据可视化进阶:用R语言打造专业级小提琴图 在生物医学领域的科研论文中,数据可视化是展示研究成果的关键环节。许多研究者习惯性地使用箱线图来呈现数据分布,却忽略了这种传统方法可能掩盖的重要信息细节。当面对复杂的数据分布模式时&…...
)
车道线检测入门:从CULane数据集结构到模型训练(PyTorch实战)
车道线检测实战:从CULane数据集解析到PyTorch模型训练全流程 1. 理解CULane数据集的核心价值 车道线检测作为自动驾驶感知层的关键技术,其性能高度依赖高质量的数据集。CULane凭借其复杂城市道路场景和精细标注,已成为该领域的基准测试集之一…...

高级磁盘空间管理:WinDirStat深度配置与自动化清理指南
高级磁盘空间管理:WinDirStat深度配置与自动化清理指南 【免费下载链接】windirstat WinDirStat is a disk usage statistics viewer and cleanup tool for Microsoft Windows 项目地址: https://gitcode.com/gh_mirrors/wi/windirstat 在当今数据爆炸的时代…...

地平线旭日X3派边缘AI开发板深度体验:从开箱到模型部署实战
1. 项目概述:当“地平线”升起时,我们看到了什么?最近几年,如果你关注边缘计算、机器人或者智能驾驶,那么“地平线”这个名字你一定不陌生。它早已不是那个遥远的天际线,而是成为了国内AI芯片领域一个响当当…...

Mi-Create:零基础打造小米手表个性表盘的终极可视化神器
Mi-Create:零基础打造小米手表个性表盘的终极可视化神器 【免费下载链接】Mi-Create Unofficial watchface creator for Xiaomi wearables ~2021 and above 项目地址: https://gitcode.com/gh_mirrors/mi/Mi-Create 你是否厌倦了小米手表上那些千篇一律的官方…...

生态数据分析避坑指南:你的Mantel检验结果可靠吗?聊聊距离算法选择与共线性控制
生态数据分析避坑指南:你的Mantel检验结果可靠吗?聊聊距离算法选择与共线性控制 生态数据分析中,Mantel检验作为一种常用的空间相关性分析方法,被广泛应用于物种分布与环境因子关系的研究。然而,许多研究者在实际操作中…...