四川汇烁面试总结
自我介绍+项目介绍、
目录
1.jdk和jre的区别?
2.一段代码的执行流程?
3.接口与抽象类的区别?
4.ArrayList与LinkList的区别?
5.对HashMap的理解?
6.常见的异常?
7.throw 和 throws 有什么区别?
8.try catch finally 每个里面都有return 执行流程?
9.线程池五个线程,交替打印0---100?
10.数据库索引的作用?
11.数据库一条数据只允许一个用户修改,怎么实现?
12.redis的数据会存到硬盘上吗?
13.redis缓存雪崩的解决方案?
14.说一下SpringBoot启动流程?
15.说一下SpringMvc的执行流程?
16.写sql时候的注意事项?
17.MQ怎么保证消息不丢失?
1.jdk和jre的区别?
- JDK:Java开发工具包,主要用于Java程序的开发。它不仅包含了JRE的全部内容,还提供了编译Java程序所需的工具,如
javac编译器和java命令等。 - JRE:Java运行时环境,主要用于运行Java程序。它包含了Java虚拟机(JVM)和运行Java程序所需的核心类库,但不包含开发工具。
2.一段代码的执行流程?
-
编写代码
-
编译代码:使用Java编译器(
javac命令)将源代码编译成字节码。这个过程会检查语法错误,并生成一个或多个.class文件,这些文件包含了Java虚拟机(JVM)可以理解的指令。 -
运行时环境准备:确保系统中安装了Java运行时环境(JRE)或Java开发工具包(JDK),因为它们包含了运行Java程序所需的Java虚拟机(JVM)。
-
加载字节码:JVM的类加载器(ClassLoader)负责加载
.class文件到内存中。 -
验证字节码:JVM的验证器确保加载的字节码是安全和有效的,没有违反JVM规范。
-
准备和解析:JVM准备阶段会为类变量分配内存,并设置默认初始值。解析阶段中,JVM将字节码中的符号引用转换为直接引用。
-
初始化:静态变量和静态代码块被执行,类变量被初始化为指定的初始值。
-
执行主方法:JVM通过反射机制调用包含
main方法的类的实例,并执行main方法,这是程序的入口点。 -
运行字节码:JVM的执行引擎根据字节码执行程序。字节码可以是解释执行,也可以是即时编译(JIT)成机器码后执行。
-
垃圾回收:在程序运行过程中,JVM的垃圾回收器会自动回收不再使用的内存。
-
程序结束:当
main方法执行完毕,或者通过System.exit()显式退出时,程序结束。 -
卸载类:当一个类的所有实例都不再被使用,且没有静态引用时,JVM的类加载器会卸载这个类。
3.接口与抽象类的区别?
-
定义:
- 接口:是一个完全抽象的概念,可以包含抽象方法和默认方法(Java 8及以上版本),但不能包含任何实现细节。
- 抽象类:可以包含抽象方法和具体方法,允许包含实现细节。
-
实现:
- 接口:一个类可以实现多个接口,使用
implements关键字。 - 抽象类:一个类只能继承一个抽象类,使用
extends关键字。 -
构造方法:
- 接口:不能包含构造方法。
- 抽象类:可以包含构造方法。
- 接口:一个类可以实现多个接口,使用
-
变量默认值:
- 接口:在Java 8之前,接口中的变量只能是
public static final的常量。从Java 8开始,接口可以包含默认方法和静态方法。 - 抽象类:可以包含任何类型的变量和方法。
- 接口:在Java 8之前,接口中的变量只能是
-
访问修饰符:
- 接口:默认情况下,接口中的所有方法都是
public的,所有变量都是public static final的。 - 抽象类:可以有多种访问修饰符,如
public,protected,private等。
- 接口:默认情况下,接口中的所有方法都是
-
多继承:
- 接口:支持多继承,一个类可以实现多个接口,有助于解决多重继承的问题。
- 抽象类:不支持多继承,一个类只能继承一个抽象类。
-
使用场景:
- 接口:用于定义一组行为规范,通常用于定义能力或者行为的契约。
- 抽象类:用于表示一个不完整的类,它可能包含部分实现,通常用于共享代码。
-
方法体:
- 接口:在Java 8之前,接口中的方法不能有实现。从Java 8开始,接口可以有默认方法和静态方法。
- 抽象类:可以包含抽象方法和具体方法。
-
初始化:
- 接口:不能被实例化,不能直接创建对象。
- 抽象类:可以被实例化,但通常不这样做,因为它是不完整的。
-
私有方法:
- 接口:Java 9开始支持私有方法和私有静态方法。
- 抽象类:可以包含私有方法。
4.ArrayList与LinkList的区别?
-
内部实现:
- ArrayList:基于动态数组实现,这意味着它维护了一个元素数组,可以快速随机访问任何位置的元素。
- LinkedList:基于双向链表实现,链表中的每个元素都包含对前一个和后一个元素的引用。
-
性能特点:
- ArrayList:
- 优点:提供快速的随机访问,即O(1)时间复杂度的
get操作。 - 缺点:在列表末尾添加元素是O(1),但在列表中间插入或删除元素时,可能需要O(n)时间复杂度,因为需要移动后续所有元素。
- 优点:提供快速的随机访问,即O(1)时间复杂度的
- LinkedList:
- 优点:在列表的任何位置插入或删除元素都非常快速,通常是O(1)时间复杂度,只需要改变相邻元素的链接。
- 缺点:随机访问元素较慢,因为需要从头开始遍历链表,所以是O(n)时间复杂度。
- ArrayList:
-
内存使用:
- ArrayList:通常使用较少的内存,因为它是连续存储。
- LinkedList:每个元素都需要额外的内存来存储对前后元素的引用,因此内存使用相对较高。
-
线程安全:
- 两者都不是线程安全的。如果需要线程安全,可以使用
Collections.synchronizedList()方法包装它们,或者使用Vector(类似于ArrayList)和Stack。
- 两者都不是线程安全的。如果需要线程安全,可以使用
-
使用场景:
- ArrayList:当你需要频繁随机访问列表中的元素时,使用
ArrayList更合适。 - LinkedList:当你需要频繁在列表中间插入或删除元素时,使用
LinkedList更合适。
- ArrayList:当你需要频繁随机访问列表中的元素时,使用
-
实现细节:
- ArrayList:实现了
RandomAccess接口,这表明它可以快速随机访问元素。 - LinkedList:实现了
Deque接口,这意味着它可以用作双端队列。
- ArrayList:实现了
-
迭代器:
- ArrayList:迭代器实现为基于索引的迭代,通常更快。
- LinkedList:迭代器实现为基于节点的迭代,可能稍慢。
-
失败快速:
- ArrayList:在迭代过程中,如果列表被修改(除了通过迭代器自身的
remove或add),会快速失败。 - LinkedList:迭代器也支持快速失败,但链表结构可能在修改时更稳定。
- ArrayList:在迭代过程中,如果列表被修改(除了通过迭代器自身的
总结来说,选择ArrayList还是LinkedList取决于你的具体需求,特别是列表操作的类型和频率。如果需要频繁访问元素,ArrayList是更好的选择;如果需要频繁插入或删除元素,尤其是在列表中间,LinkedList可能更合适。
5.对HashMap的理解?
1. **数组和链表/红黑树**:
- `HashMap`内部使用一个数组(通常是`Node<K,V>[]`类型的数组)来存储键值对(`Entry`对象)。
- 当发生哈希冲突时(即两个或多个键具有相同的哈希码),`HashMap`会使用链表来解决冲突。从Java 8开始,当链表的长度超过一定阈值(TREEIFY_THRESHOLD,默认为8)时,链表会转换成红黑树,以提高搜索效率。
2. **哈希函数**:
- `HashMap`使用键对象的`hashCode()`方法来计算哈希码,然后通过哈希码来确定键值对在数组中的位置。
3. **容量和加载因子**:
- `HashMap`有一个容量(capacity)的概念,即内部数组的大小。
- 加载因子(load factor)是一个衡量`HashMap`满的程度的参数,它是一个介于0和1之间的浮点数,默认值为0.75。当实际存储的键值对数量超过数组容量与加载因子的乘积时,`HashMap`会进行扩容。
4. **扩容**:
- 当键值对的数量达到阈值时,`HashMap`会创建一个容量更大的新数组(通常是原数组大小的两倍),并将原数组中的所有键值对重新映射(rehash)到新数组中。这个过程称为再散列(rehashing)。
5. **再散列**:
- 在扩容时,`HashMap`会遍历旧数组中的所有键值对,使用新的哈希函数重新计算它们在新数组中的位置。
- 这个过程是昂贵的,因为它涉及到遍历和复制所有键值对。
6. **树化**:
- 当链表的长度超过TREEIFY_THRESHOLD时,链表会转换成红黑树。这个转换可以减少查找、插入和删除操作的时间复杂度,从O(n)降低到O(log n)。
7. **哈希碰撞**:
- 当两个键具有相同的哈希码,并且在数组中映射到同一位置时,会发生哈希碰撞。
- `HashMap`通过链表或红黑树来解决哈希碰撞。
8. **null键和null值**:
- `HashMap`允许一个null键和多个null值。
9. **并发问题**:
- `HashMap`不是线程安全的。如果需要线程安全的HashMap,可以使用`Collections.synchronizedMap()`方法包装它,或者使用`ConcurrentHashMap`。
10. **迭代器**:
- `HashMap`的迭代器是快速失败的,这意味着在迭代过程中如果检测到`HashMap`被修改,迭代器会立即抛出`ConcurrentModificationException`。
6.常见的异常?
在Java中,异常是程序运行时发生的错误。Java异常处理机制允许程序在发生错误时采取相应的措施,而不是直接崩溃。Java的异常分为两大类:受检异常(checked exceptions)和非受检异常(unchecked exceptions)。
### 受检异常(Checked Exceptions)
受检异常是编译时检查的异常,必须通过`try-catch`块或`throws`子句处理。这些异常通常是可预见的,并且可以恢复。
- **IOException**:当发生I/O错误时抛出,如文件读写错误。
- **SQLException**:数据库操作中发生错误时抛出。
- **FileNotFoundException**:尝试访问不存在的文件时抛出。
- **MalformedURLException**:URL格式不正确时抛出。
- **IndexOutOfBoundsException**:访问数组或集合时索引超出范围时抛出。
- **NumberFormatException**:尝试将字符串转换为数字,但字符串不是适当的格式时抛出。
### 非受检异常(Unchecked Exceptions)
非受检异常是在编译时不强制处理的异常,通常是编程错误导致的。
#### 运行时异常(Runtime Exceptions)
运行时异常是非受检异常的一种,通常由编程错误引起。
- **NullPointerException**:尝试使用了一个未被初始化(null)的对象时抛出。
- **IllegalArgumentException**:方法接收到无效参数时抛出。
- **IllegalStateException**:对象的状态不满足请求的操作时抛出。
- **ArrayStoreException**:尝试将错误类型的对象存储到一个对象数组中时抛出。
- **ClassCastException**:尝试将对象强制转换为不是实例的子类时抛出。
- **ArithmeticException**:算术运算错误时抛出,如除以零。
- **NumberFormatException**:字符串转换为数字格式不正确时抛出。
#### 错误(Errors)
错误是非受检异常的另一种,通常表示严重的程序问题,程序通常无法恢复。
- **OutOfMemoryError**:没有足够的内存时抛出。
- **StackOverflowError**:递归调用太深,导致栈溢出时抛出。
- **VirtualMachineError**:虚拟机严重错误,如内存不足。
- **AssertionError**:断言失败时抛出。
### 其他常见异常
- **Exception**:所有受检异常的超类。
- **RuntimeException**:所有运行时异常的超类。
7.throw 和 throws 有什么区别?
1. **throw**:
- `throw`关键字用于在代码中手动抛出一个异常。
- 它可以用来抛出任何类型的异常,包括检查型异常(checked exceptions)和非检查型异常(unchecked exceptions)。
- `throw`后面通常跟一个异常对象,这个对象是`Throwable`类或其子类的实例。
- `throw`可以在Java代码的任何地方使用,包括方法体内部。
示例:
```java
throw new IllegalArgumentException("参数不合法");
```
2. **throws**:
- `throws`关键字用于在方法签名中声明该方法可能会抛出的异常。
- 它后面跟着的是异常类型,用于告诉调用者该方法可能会抛出的异常类型,调用者需要对这些异常进行处理。
- `throws`只能用于方法签名中,不能用于代码块内部。
- 使用`throws`声明的异常是编译时检查的,意味着调用者必须处理这些异常,要么通过`try-catch`块捕获它们,要么进一步使用`throws`声明传递给上层调用者。
示例:
```java
public void myMethod() throws IOException {
// 方法体可能会抛出IOException
}
```
总结区别:
- `throw`是抛出异常的动作,而`throws`是方法声明可能会抛出的异常类型。
- `throw`用于代码块中,而`throws`用于方法签名中。
- `throw`抛出的是一个具体的异常实例,`throws`声明的是异常的类型。
- `throws`关键字后面跟的是可能会被抛出的异常列表,用逗号分隔。
8.try catch finally 每个里面都有return 执行流程?
### try 块中的 return
如果在`try`块中执行了`return`语句,那么:
- 会立即终止`try`块的执行,并返回`return`语句指定的值。
- `catch`和`finally`块将不会被执行。
### catch 块中的 return
如果在`catch`块中执行了`return`语句,那么:
- 会立即终止当前`catch`块的执行,并返回`return`语句指定的值。
- 如果有其他的`catch`块,它们将继续执行。
- `finally`块将执行,无论`catch`块中是否有`return`。
### finally 块中的 return
如果在`finally`块中执行了`return`语句,那么:
- 这通常被认为是不好的实践,因为它会覆盖`try`和`catch`块中的`return`语句。
- `finally`块的`return`将立即终止方法的执行,并返回`return`语句指定的值。
- 这意味着即使`try`或`catch`块中有`return`,`finally`块中的`return`也会覆盖它们。
请注意,通常不推荐在`finally`块中使用`return`,因为它会使代码的执行流程变得难以理解和预测,而且可能会隐藏错误。
9.线程池五个线程,交替打印0---100?
public class AlternatePrinting {private final Semaphore semaphore = new Semaphore(1);private final AtomicInteger number = new AtomicInteger(0);public void printNumbers() {for (int i = 0; i < 20; i++) { // 0到19,每个线程打印20个数字try {semaphore.acquire();if (number.get() < 100) {int currentNumber = number.incrementAndGet();System.out.println(Thread.currentThread().getName() + " prints " + currentNumber);}semaphore.release();} catch (InterruptedException e) {Thread.currentThread().interrupt();}}}public static void main(String[] args) {ExecutorService executorService = Executors.newFixedThreadPool(5);AlternatePrinting alternatePrinting = new AlternatePrinting();// 提交任务到线程池,每个线程打印0到19的数字20次for (int i = 0; i < 5; i++) {executorService.submit(alternatePrinting::printNumbers);}// 关闭线程池executorService.shutdown();}
}在这个例子中,我们使用了一个Semaphore来控制对共享资源(即打印操作)的访问。初始时,Semaphore的许可数量为1,这意味着一次只有一个线程可以执行打印操作。
我们还使用了一个AtomicInteger来控制打印的数字,以确保在多线程环境中数字能够正确地从0递增到100。
每个线程在打印前尝试获取Semaphore的许可,如果成功,则通过AtomicInteger获取下一个要打印的数字,并将其打印出来。打印完成后,线程释放Semaphore的许可,允许其他线程继续执行。
10.数据库索引的作用?
数据结构是B+数 非叶子节点不存储数据,存储指向叶子结点的索引。如果查询的非聚集索引,会进行一次回表查询。
11.数据库一条数据只允许一个用户修改,怎么实现?
加乐观锁,分布式锁。
12.redis的数据会存到硬盘上吗?
Redis的数据可以并且通常会被持久化存储到硬盘上。Redis提供了几种不同的数据持久化选项,以确保即使在服务器崩溃或重启的情况下数据也不会丢失。以下是Redis支持的几种主要持久化方式:
-
RDB持久化 (Redis Database):
- 这种形式的持久化会在指定的时间间隔内生成数据集的时间点快照。
- 通过配置
save <seconds> <changes>可以在Redis.conf配置文件中设置自动保存的规则。 - RDB持久化是通过创建进程的方式来完成的,它会将内存中的数据保存到一个
.rdb文件中。
-
AOF持久化 (Append Only File):
- AOF持久化记录每次写操作命令,并将其追加到文件末尾。
- 这提供了更好的数据安全性,因为它减少了在故障情况下可能丢失的数据量。
- 可以通过配置
appendonly yes在Redis.conf中启用AOF持久化。 - AOF文件以纯文本形式存储,并且可以被手动编辑或通过Redis的
LOAD命令加载。
-
RDB和AOF的组合:
- 可以同时使用RDB和AOF持久化,以获得两者的优点。
- 例如,可以使用RDB来获得更紧凑的备份文件,并使用AOF来提供更细粒度的数据恢复。
-
虚拟内存 (VM):
- Redis的虚拟内存功能不是持久化机制,但它允许Redis将部分数据交换到磁盘,以减少内存的使用。
- 这不是真正的持久化,因为数据交换到磁盘上的数据不是持久的,且在Redis重启后不会恢复。
-
磁盘快照:
- 在某些部署环境中,可能还会使用外部工具来创建Redis数据的磁盘快照。
-
复制:
- 虽然不是持久化机制,但Redis的复制功能可以用来创建数据的热备份,主节点的数据变更会实时复制到从节点。
使用哪种持久化方式取决于具体的应用场景和需求。例如,如果数据安全性是首要考虑因素,可能会选择AOF持久化;如果需要定期的数据备份,可能会选择RDB持久化。在实际部署中,通常会根据需要选择一种或多种持久化策略。
13.redis缓存雪崩的解决方案?
Redis缓存雪崩是指由于大量缓存数据在相近时间内同时过期,导致大量请求直接打到数据库上,从而对数据库造成巨大压力,甚至引起数据库宕机的现象。
-
多级缓存机制:
- 使用本地缓存和分布式缓存相结合的方式。当分布式缓存失效时,本地缓存可以作为一个备份,减少对数据库的直接压力。
-
预加载和预热缓存:
- 在缓存即将过期前,后台异步更新缓存数据,这样可以避免大量请求同时击中数据库。
-
动态调整缓存策略:
- 根据系统负载和业务重要性动态调整缓存失效时间和限流策略。
-
设置随机过期时间:
- 避免大量缓存在同一时间过期,通过设置随机的过期时间来分散请求。
-
使用缓存标记策略:
- 在标记失效时更新数据缓存,确保缓存的数据是最新的。
-
实施多级缓存策略:
- 如一级缓存失效时由二级缓存更新。
-
增加自动化监控:
- 确保能在问题发生前及时发现异常。
-
限流和降级:
- 在系统负载较高时,通过限流和降级措施来保护后端服务。
-
缓存数据的过期时间设置随机:
- 防止同一时间大量数据过期现象发生。
-
超热数据使用永久key:
- 对于非常热点的数据,可以设置为永不过期。
-
定期维护(自动+人工):
- 对即将过期数据做访问量分析,确认是否延时,配合访问量统计,做热点数据的延时。
-
加锁机制:
- 当缓存中没有数据,第1个进入的线程,获取锁并从数据库去取数据,其他并行进入的线程会等待,这样就防止都去数据库重复取数据,重复往缓存中更新数据情况出现。
通过这些策略,可以有效地预防和应对缓存雪崩,增强系统的稳定性和可靠性。
14.说一下SpringBoot启动流程?
Spring Boot的启动流程是一系列初始化和配置步骤,旨在准备应用程序运行环境并使其准备好处理请求。以下是Spring Boot启动流程的概述:
1. **初始化SpringApplication**:
- 创建`SpringApplication`实例,它负责启动Spring Boot应用程序。
2. **运行SpringApplication**:
- 调用`SpringApplication.run()`方法开始启动过程。
3. **加载应用配置**:
- 加载`application.properties`或`application.yml`等配置文件中的属性。
4. **执行Banner**:
- 打印启动时的Banner(如果有定义)。
5. **创建并配置ApplicationContext**:
- 创建Spring应用上下文`ApplicationContext`,它是Spring框架的核心,负责管理Bean的生命周期和依赖关系。
6. **执行Bean定义**:
- 通过`@ComponentScan`指定的包路径扫描组件,自动注册`@Component`、`@Service`、`@Repository`、`@Controller`等注解的类作为Bean。
7. **加载起步依赖**:
- 加载`spring-boot-starter`起步依赖中定义的库和配置。
8. **自动配置类的应用**:
- 根据类路径中的库、配置文件和`@EnableAutoConfiguration`注解,Spring Boot会尝试自动配置应用程序。
9. **注册并执行所有的`CommandLineRunner`和`ApplicationRunner`**:
- 在Spring应用上下文准备好之后,执行所有的`CommandLineRunner`和`ApplicationRunner`接口实现类,这些接口允许你在应用程序启动后执行自定义代码。
10. **注册所有的Servlet、Filter和ServletListener**:
- 如果应用程序是一个Web应用程序,Spring Boot会自动注册所有的Servlet、Filter和ServletListener。
11. **初始化Tomcat/Jetty等内嵌服务器**:
- 如果应用程序是一个Web应用程序,Spring Boot会初始化内嵌的Tomcat或Jetty服务器。
12. **监听端口**:
- 内嵌服务器开始监听端口,等待外部请求。
13. **应用程序完全启动**:
- 所有上述步骤完成后,应用程序完全启动,并准备好接收和处理请求。
15.说一下SpringMvc的执行流程?
-
客户端发送请求: 用户通过浏览器或客户端工具发送HTTP请求到服务器。
-
请求到达DispatcherServlet: HttpServletRequest对象封装了客户端的原始请求,所有进入的请求首先到达中央调度器
DispatcherServlet。 -
请求映射:
DispatcherServlet根据请求的URL查找相应的处理器映射(Handler Mapping)。处理器映射负责将请求映射到对应的处理器(Controller)。 -
执行Controller: 找到映射的Controller后,
DispatcherServlet调用Controller中的方法来处理请求。 -
返回ModelAndView: Controller执行完成后,通常会返回一个
ModelAndView对象,其中包含模型数据(Model)和视图名称(View)。 -
视图解析:
DispatcherServlet使用视图解析器(View Resolver)来解析ModelAndView中的逻辑视图名称,以确定具体的视图实现。 -
渲染视图: 视图解析器返回具体的视图对象后,
DispatcherServlet将模型数据传递给视图,并渲染最终的视图。 -
返回响应: 渲染完成后,
DispatcherServlet将视图转换为HTTP响应并发送回客户端。 -
更新Web页面: 客户端浏览器接收到响应后,根据响应内容更新Web页面。
在整个流程中,Spring MVC提供了多个扩展点,允许开发者插入自己的逻辑,例如:
- 拦截器(Interceptors):可以在请求处理前后执行自定义逻辑。
- 异常处理器(Exception Handlers):可以捕获和处理Controller中抛出的异常。
- 数据转换器(Converters):用于自动转换请求参数到Java对象。
- 数据验证器(Validators):用于验证用户输入的数据。
Spring MVC的执行流程是高度可定制的,开发者可以根据需要配置和扩展框架的各种组件。这种灵活性使得Spring MVC成为构建现代Web应用程序的流行选择。
16.写sql时候的注意事项?
尽量使用到索引,避免索引失效,如果接口查询慢,用慢查询日志和explain来定位慢SQL,优化性能。
17.MQ怎么保证消息不丢失?
-
持久化存储:
- 消息队列通常提供持久化选项,将消息存储在磁盘上而不仅仅是内存中。这样即使系统崩溃,消息也不会丢失。
-
消息确认(Acknowledgements):
- 消费者在成功处理消息后发送一个确认回执给MQ。只有在收到确认后,MQ才会认为消息已被成功消费并将其从队列中移除。
-
重试机制:
- 如果消费者处理消息失败,MQ可以配置为自动重试,将消息重新放入队列中,等待再次消费。
-
死信队列(Dead Letter Queues):
- 对于无法处理的消息,可以发送到一个特殊的队列(死信队列),而不是简单地丢弃,这样可以进行问题排查和消息恢复。
相关文章:

四川汇烁面试总结
自我介绍项目介绍、 目录 1.jdk和jre的区别? 2.一段代码的执行流程? 3.接口与抽象类的区别? 4.ArrayList与LinkList的区别? 5.对HashMap的理解? 6.常见的异常? 7.throw 和 throws 有什么区别? 8.…...
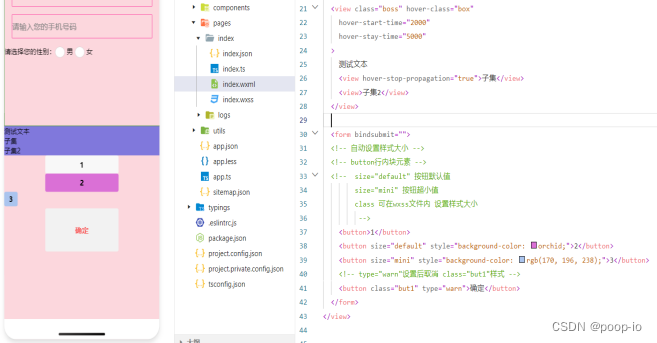
【小程序 按钮 表单 】
按钮 代码演示 xxx.wxml <view class"boss" hover-class"box"hover-start-time"2000"hover-stay-time"5000">测试文本<view hover-stop-propagation"true">子集</view><view>子集2</view>…...

高铁Wifi是如何接入的?
使用PC端的朋友,请将页面缩小到最小比例,阅读最佳! 在飞驰的高铁上,除了窗外一闪而过的风景,你是否好奇过,高铁Wifi信号如何连接的呢? 远动的火车可不能连接光纤吧,难道是连接的卫星…...
gitlab之docker-compose汉化离线安装
目录 概述离线资源docker-compose结束 概述 gitlab可以去 hub 上拉取最新版本,在此我选择汉化 gitlab ,版本 11.x 离线资源 想自制离线安装镜像,请稳步参考 docker镜像的导入导出 ,无兴趣的直接使用在此提供离线资源 百度网盘(链…...

【算法】dd爱转转
✨题目链接: dd爱旋转 ✨题目描述 读入一个n∗n的矩阵,对于一个矩阵有以下两种操作 1:顺时针旋180 2:关于行镜像 如 变成 给出q个操作,输出操作完的矩阵 ✨输入描述: 第一行一个数n(1≤n≤1000),表示矩阵大小 接下来n行ÿ…...
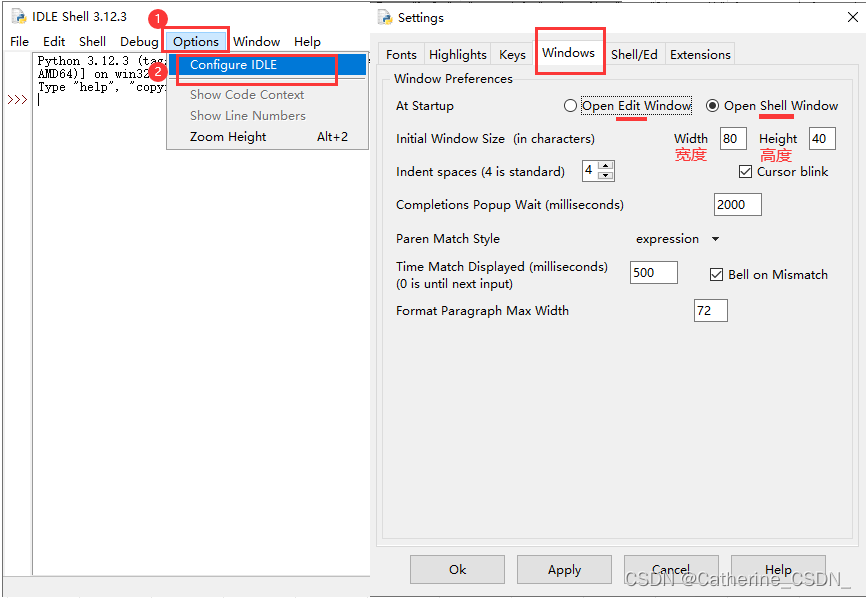
Python3 笔记:IDLE的几个基本设置
1、设置字体: Options > Configure IDLE > Fonts 2、设置文字颜色(设置高亮): Options > Configure IDLE > Highlights 3、设置背景颜色: Options > Configure IDLE > Highlights 4、设置窗口&a…...

Mysql:存储过程练习
create table stu( id int(3) primary key auto_increment, name varchar(20) not null, grade float, gender char(2)); insert into stu(name,grade,gender) values(tom,60,男),(jack,70,男),(rose,90,女),(lucy,100,…...

详解Java ThreadLocal
个人博客 详解Java ThreadLocal | iwts’s blog Java ThreadLocal ThreadLocal提供了线程内存储变量的能力,这些变量不同之处在于每一个线程读取的变量是对应的互相独立的。通过get和set方法就可以得到当前线程对应的值。 TreadLocal存储模型 ThreadLocal的静态…...

Unable to parse response body for Response{requestLine=PUT
1 异常信息: Caused by: java.lang.RuntimeException: Unable to parse response body for Response{requestLinePUT /an_path_statistic_log/_doc/11?timeout1m HTTP/1.1, hosthttp://192.168.3.60:9200, responseHTTP/1.1 200 OK}at org.springframework.data.e…...
)
GitHub的原理及应用详解(六)
本系列文章简介: GitHub是一个基于Git版本控制系统的代码托管平台,为开发者提供了一个方便的协作和版本管理的工具。它广泛应用于软件开发项目中,包括但不限于代码托管、协作开发、版本控制、错误追踪、持续集成等方面。 GitHub的原理可以简单…...
基于PHP+MySQL组合开发的微信小程序分销商城源码系统 分销商城+积分商城+多商户 功能强大 带完整的安装代码包以及搭建教程
系统概述 在当今数字化商业时代,拥有一个强大而多功能的分销商城系统对于企业的发展至关重要。本文将重点介绍基于 PHPMySQL 组合开发的微信小程序分销商城源码系统,它融合了分销商城、积分商城和多商户等功能,不仅功能强大,还提…...
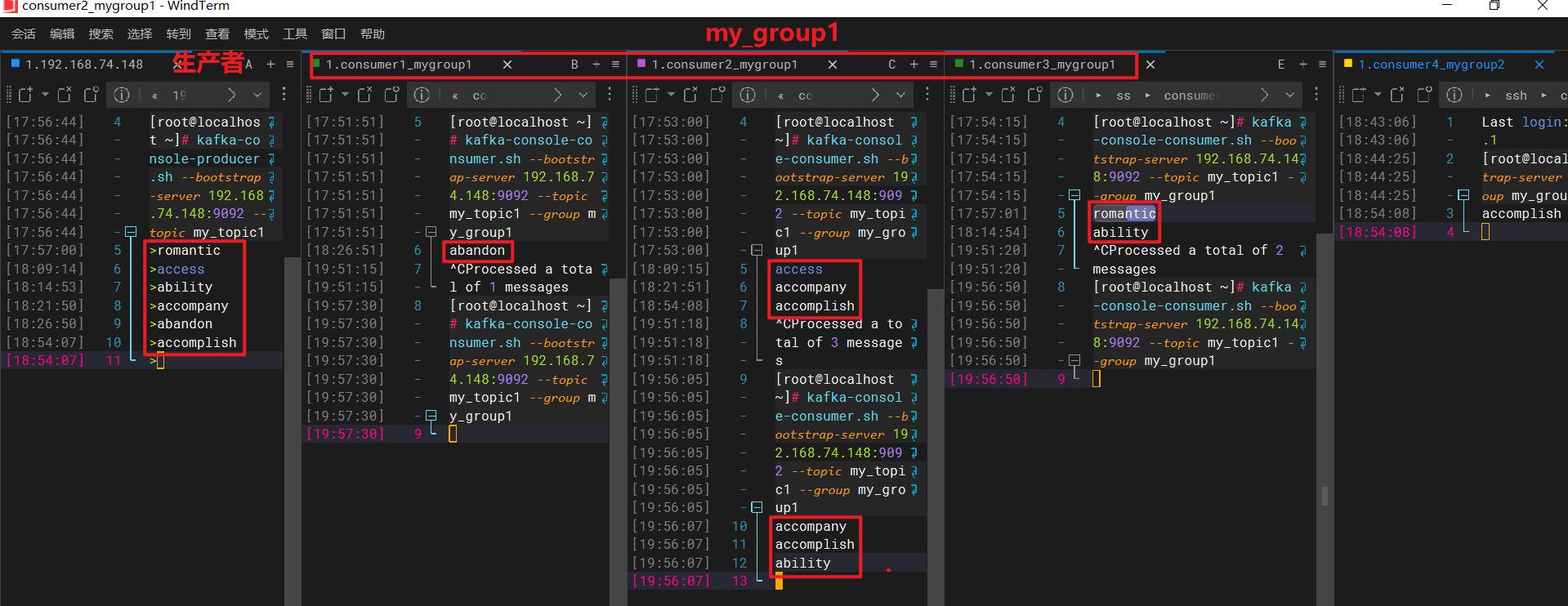
kafka-消费者组偏移量重置
文章目录 1、消费者组偏移量重置1.1、列出所有的消费者组1.2、查看 my_group1 组的详细信息1.3、获取 kafka-consumer-groups.sh 的帮助信息1.4、 偏移量重置1.5、再次查看 my_group1 组的详细信息 1、消费者组偏移量重置 1.1、列出所有的消费者组 [rootlocalhost ~]# kafka-…...

一书读懂Python全栈安全,剑指网络空间安全
写在前面 通过阅读《Python全栈安全/网络空间安全丛书》,您将能够全面而深入地理解Python全栈安全的广阔领域,从基础概念到高级应用无一遗漏。本书不仅详细解析了Python在网络安全、后端开发、数据分析及自动化等全栈领域的安全实践,还紧密贴…...

原生js实现拖拽改变元素顺序
代码展示如下: <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>Document</title>…...

以果决其行,只为文化的传承
从他们每一个人的身上,我们看到传神的东西,就是他们都能用结果,去指引自己前进的方向,这正是我要解读倪海厦老师的原因,看倪海厦2012年已经去世,到现在已经十几年时间了,但是我们看现在自学中医…...

Flutter 中的 SizedOverflowBox 小部件:全面指南
Flutter 中的 SizedOverflowBox 小部件:全面指南 在 Flutter 的布局世界中,SizedOverflowBox 是一个相对独特的小部件,它允许子组件溢出其父组件的界限,同时保持父组件的尺寸不变。这在某些特定的布局场景下非常有用,…...

图像视频智能抹除修复解决方案,适应性强,应用广泛
行车录制、现场拍摄等过程中,往往会出现一些难以避免的瑕疵——遮挡物、无关人员、甚至是意外的光线变化,这些都可能影响到视频与图像的质量,降低其观赏性和专业性。 美摄科技,作为行业领先的图像视频智能处理专家,深…...
)
20240521(代码整洁和测试入门学习)
测试: 1.测试工程师、测试工具开发工程师、自动化测试工程师。 python: 1、发展背景和优势; 2、开始多需的工具 interpreter(解释器) refactor(重构) 2、变量和注释的基础语法 3、输入输出 i 1 for i in range(1, 11): print(i, end ) 不换行打印…...

git中忽略文件的配置
git中忽略文件的配置 一、在项目根目录下创建.gitignore文件二、配置规则如果在配置之前已经提交过文件了,要删除提交过的,如何修改,参考下面的 一、在项目根目录下创建.gitignore文件 .DS_Store node_modules/ /dist# local env files .env…...

如何进行前端职业规划
目录 找准自身定位 未来发展方向 扬长避短很有效 你的出处并不能代表什么 将目标放长放远 职业发展中面临的选择 全栈 or 纯前端? ToB or ToC 赚钱 or 个人成长? 分析每个阶段的需求 为什么不可以一边赚钱一边做喜欢的事情呢 我们还没离开校园的时候,就已经知道要…...

RT-Thread线程管理实战技巧与常见问题解析
1. RT-Thread线程管理实战指南在嵌入式系统开发中,线程管理是RTOS(实时操作系统)最核心的功能之一。作为一名长期使用RT-Thread的开发者,我发现很多初学者在掌握了线程理论后,在实际应用中仍然会遇到各种问题。本文将深…...

别再手动记数据了!用MATLAB脚本自动读取串口,5分钟搞定数据采集
别再手动记数据了!用MATLAB脚本自动读取串口,5分钟搞定数据采集 还在用串口助手手动记录数据?每次实验都要盯着屏幕抄写数值,不仅效率低下,还容易出错。想象一下:当你正在进行长达数小时的温度监测实验&…...

抖音内容下载技术方案:多策略架构与智能下载引擎实现
抖音内容下载技术方案:多策略架构与智能下载引擎实现 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback suppor…...

芯片工程师如何从AI那里“榨出“隐性知识?
大语言模型里藏着很多东西,但大部分人只用到了表面。这些模型在训练时吃进去的不只是教科书和官方文档,还有大量的技术博客、论坛讨论、开源代码、甚至是一些没公开发表的技术报告。这些知识以一种隐性的方式存在于模型参数中,不会主动跳出来…...

OpenClaw自动化测试:Qwen3.5-9B-AWQ-4bit驱动UI截图比对
OpenClaw自动化测试:Qwen3.5-9B-AWQ-4bit驱动UI截图比对 1. 为什么需要自动化UI测试 作为个人开发者,每次前端代码修改后最头疼的就是手动检查各个页面的UI变化。传统做法要么是人工逐页比对,要么依赖复杂的测试框架配置。直到我发现OpenCl…...

土地利用变化分析实战:用Python处理40年CNLUCC数据集
土地利用变化分析实战:用Python处理40年CNLUCC数据集 1972年至今的中国土地利用变化数据,如同一部记录国土变迁的"生态相册"。对于区域规划师、生态研究者而言,这套CNLUCC数据集的价值不亚于考古学家手中的碳14检测仪。本文将带您用…...

YOLOv8与YOLOv11网络结构对比:从yolov8.yaml到yolo11.yaml的演进与优化
YOLOv8与YOLOv11网络结构深度对比:从架构设计到性能优化 在计算机视觉领域,目标检测技术一直是研究热点,而YOLO(You Only Look Once)系列作为其中的佼佼者,以其高效的实时检测能力广受关注。本文将深入剖析YOLOv8与YOLOv11的网络结…...

intv_ai_mk11应用场景:研发团队用其自动生成Git Commit Message规范模板
研发团队如何用intv_ai_mk11自动生成Git Commit Message规范模板 1. 研发团队的Commit Message痛点 每个研发团队都面临过这样的困境:代码提交信息五花八门,格式混乱。有的同事写"修复bug",有的写"改了东西"࿰…...

Windows系统优化终极指南:用Win11Debloat免费快速提升性能
Windows系统优化终极指南:用Win11Debloat免费快速提升性能 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter an…...

数据库运维与数据安全:备份恢复、日志分析与故障排查
下面的内容大家根据实际情况,公司的业务还有重点择机选择,不是所有的蓝翔都有挖掘机 如果说之前的索引优化是“飙车”,那么今天的主题就是“系安全带”和“买保险”。 在运维的世界里,没有“如果”,只有“万一”。当…...