kafka单机安装及性能测试
kafka单机安装及性能测试
Apache Kafka是一个分布式流处理平台,最初由LinkedIn开发,并于2011年开源,随后成为Apache项目。Kafka的核心概念包括发布-订阅消息系统、持久化日志和流处理平台。它主要用于构建实时数据管道和流处理应用,广泛应用于日志聚合、数据传输、实时监控和分析等场景。Kafka具有高吞吐量、低延迟、扩展性强和容错性高等特点。
1. Kafka安装
安装kafka2.7.0:
下载地址:https://kafka.apache.org/downloads
# 下载
$ wget https://archive.apache.org/dist/kafka/2.7.0/kafka_2.13-2.7.0.tgz
$ tar xf kafka_2.13-2.7.0.tgz
$ sudo mv kafka_2.13-2.7.0/ /usr/local/kafka2.7.0/
# 修改zookeeper.properties的配置文件。修改dataDir的参数配置,其他的配置默认不变。dataDir=/usr/local/kafka2.7.0/zookeeper
$ sudo vi /usr/local/kafka2.7.0/config/zookeeper.properties$ sudo mkdir -p /usr/local/kafka2.7.0/zookeeper/
$ sudo mkdir -p /usr/local/kafka2.7.0/logs/
# 修改server.properties的配置文件。修改listeners、host.name、log.dirs、zookeeper.connect、create.topics.enable和delete.topic.enble的参数配置,没有的配置添加,其他的配置默认不变。
$ sudo vi /usr/local/kafka2.7.0/config/server.properties
######## Socket Server Settings ########
listeners=PLAINTEXT://172.16.0.9:9092
host.name=172.16.0.9
########### Log Basics ###########
log.dirs=/usr/local/kafka2.7.0/logs
########## Zookeeper ###########
zookeeper.connect=172.16.0.9:2181
########## Group Coordinator Settings #########
auto.create.topics.enable=false
delete.topic.enable=true# 启动Kafka,使用root用户操作。分为两步,先启动zookeeper,再启动Kafka。
[root@xx]# nohup /usr/local/kafka2.7.0/bin/zookeeper-server-start.sh /usr/local/kafka2.7.0/config/zookeeper.properties > /usr/local/kafka2.7.0/zookeeper-run.log 2>&1 &
[root@xx]# sleep 10
[root@xx]# nohup /usr/local/kafka2.7.0/bin/kafka-server-start.sh /usr/local/kafka2.7.0/config/server.properties > /usr/local/kafka2.7.0/kafka-run.log 2>&1 &# 验证。jps查询输出如下择表示启动成功
# jps
101981 Kafka
101420 QuorumPeerMain #zookeeper
102575 Jps
2. Kafka性能测试
使用kafka自带的性能测试脚本,发起写入MQ消息和消费MQ消息的请求。根据不同数量级的消息写入和消息消费测试结果,评估kafka处理消息的能力。
2.1 Kafka写入消息压力测试
对kafka节点进行MQ消息服务的压力测试,关注Kafka消息写入的延迟时间是否满足需求。
# 脚本命令位于/usr/local/kafka2.7.0/bin
# 创建topic,单机环境replication-factor设置为1。上述server.properties中的auto.create.topics.enable设置为true可以自动创建主题。
$ sudo ./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 4 --topic test_perf
# 删除topic:sudo ./kafka-topics.sh --delete --topic test_perf --zookeeper localhost:2181
# 查询topic:sudo ./kafka-topics.sh --list --zookeeper localhost:2181# 指定吞吐量测试时延
$ sudo ./kafka-producer-perf-test.sh --topic test_perf --num-records 100000 --record-size 1000 --throughput 2000 --producer-props bootstrap.servers=172.16.0.9:9092
100000 records sent, 1999.760029 records/sec (1.91 MB/sec), 1.13 ms avg latency, 448.00 ms max latency, 0 ms 50th, 1 ms 95th, 17 ms 99th, 83 ms 99.9th.$ sudo ./kafka-producer-perf-test.sh --topic test_perf --num-records 1000000 --record-size 1000 --throughput 5000 --producer-props bootstrap.servers=172.16.0.9:9092
1000000 records sent, 4999.725015 records/sec (4.77 MB/sec), 0.51 ms avg latency, 481.00 ms max latency, 0 ms 50th, 1 ms 95th, 2 ms 99th, 53 ms 99.9th$ sudo ./kafka-producer-perf-test.sh --topic test_perf --num-records 10000000 --record-size 1000 --throughput 5000 --producer-props bootstrap.servers=172.16.0.9:9092
10000000 records sent, 4999.985000 records/sec (4.77 MB/sec), 0.35 ms avg latency, 424.00 ms max latency, 0 ms 50th, 1 ms 95th, 1 ms 99th, 5 ms 99.9th.# throughput设置0-1,测试producer的最大吞吐量。
# 优化参数:compression.type=snappy,使用snappy算法压缩消息。
$ sudo ./kafka-producer-perf-test.sh --topic test_perf --num-records 10000000 --record-size 1000 --throughput -1 --producer-props bootstrap.servers=172.16.0.9:9092 batch_size=563840 linger_ms=30000 acks=0 compression_type=snappy
[2024-03-28 16:57:00,757] WARN The configuration 'batch_size' was supplied but isn't a known config. (org.apache.kafka.clients.producer.ProducerConfig)
[2024-03-28 16:57:00,757] WARN The configuration 'compression_type' was supplied but isn't a known config. (org.apache.kafka.clients.producer.ProducerConfig)
[2024-03-28 16:57:00,757] WARN The configuration 'linger_ms' was supplied but isn't a known config. (org.apache.kafka.clients.producer.ProducerConfig)
577921 records sent, 115584.2 records/sec (110.23 MB/sec), 239.9 ms avg latency, 491.0 ms max latency.
646464 records sent, 128854.7 records/sec (122.89 MB/sec), 247.7 ms avg latency, 604.0 ms max latency.
313216 records sent, 62418.5 records/sec (59.53 MB/sec), 514.5 ms avg latency, 854.0 ms max latency.
206016 records sent, 41137.4 records/sec (39.23 MB/sec), 724.7 ms avg latency, 1781.0 ms max latency.
...
301184 records sent, 59949.0 records/sec (57.17 MB/sec), 545.7 ms avg latency, 725.0 ms max latency.
10000000 records sent, 62655.463870 records/sec (59.75 MB/sec), 494.30 ms avg latency, 5370.00 ms max latency, 506 ms 50th, 775 ms 95th, 1149 ms 99th, 5221 ms 99.9th.
结果解析:
以写入100w条MQ消息为例,每秒平均向kafka写入了4.77MB的数据,平均4999.725条消息/秒,每次写入的平均延迟为0.51毫秒,最大的延迟为481毫秒。
producer优化思路与优化参数
- 优化思路
- 适当调大 batch.size和 linger.ms:这两个参数是配合起来使用的,目的就是缓存更多的数据,减少客户端发起请求的次数。这两个参数根据实际情况调整,注意要适量。
- 关闭数据发送确认机制:适用于对数据完整性要求不高的场景,比如日志,丢几条无所谓那种
- 指定数据发送时的压缩算法:默认不压缩,可选压缩算法gzip,snappy,lz4,zstd等
- 推荐一组优化参数
- batch_size=563840: 默认值是 16384
- linger_ms=30000: 默认值是 0
- acks=0: 默认值是 1
- compression_type=“gzip”: 默认值是 None
结果汇总:
| 设置消息总数(单位:w) | 设置单个消息大小(单位:字节) | 设置每秒发送消息数 | 实际写入消息数/秒 | 95%的消息延迟(单位:ms) |
|---|---|---|---|---|
| 10 | 1000 | 2000 | 1999.76 | 1ms |
| 100 | 1000 | 5000 | 4999.72 | 1ms |
| 1000 | 1000 | 5000 | 4999.96 | 1ms |
2.2 Kafka消费消息压力测试
对Kafka节点进行MQ消息处理的压力测试,验证Kafka的消息处理能力。
# 消费10w消息压测结果。先写入10w消息,然后消费
$ sudo ./kafka-producer-perf-test.sh --topic test_perf --num-records 100000 --record-size 1000 --throughput 2000 --producer-props bootstrap.servers=172.16.0.9:9092
$ sudo ./kafka-consumer-perf-test.sh --broker-list 172.16.0.9:9092 --topic test_perf --fetch-size 1048576 --messages 100000
start.time, end.time, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec, rebalance.time.ms, fetch.time.ms, fetch.MB.sec, fetch.nMsg.sec
2024-03-27 14:14:36:989, 2024-03-27 14:14:38:053, 95.3674, 89.6310, 100000, 93984.9624, 1711520077451, -1711520076387, -0.0000, -0.0001# 消费100w消息压测结果。先写入100w消息,然后消费
$ sudo ./kafka-producer-perf-test.sh --topic test_perf --num-records 1000000 --record-size 1000 --throughput 5000 --producer-props bootstrap.servers=172.16.0.9:9092
$ sudo ./kafka-consumer-perf-test.sh --broker-list 172.16.0.9:9092 --topic test_perf --fetch-size 1048576 --messages 1000000 --threads 1
start.time, end.time, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec, rebalance.time.ms, fetch.time.ms, fetch.MB.sec, fetch.nMsg.sec
2024-03-27 14:20:11:235, 2024-03-27 14:20:14:554, 953.8040, 287.3769, 1000136, 301336.5472, 1711520411703, -1711520408384, -0.0000, -0.0006# 消费1000w消息压测结果。先写入1000w消息,然后消费
$ sudo ./kafka-producer-perf-test.sh --topic test_perf --num-records 10000000 --record-size 1000 --throughput 5000 --producer-props bootstrap.servers=172.16.0.9:9092
$ sudo ./kafka-consumer-perf-test.sh --broker-list 172.16.0.9:9092 --topic test_perf --fetch-size 1048576 --messages 10000000 --threads 1
start.time, end.time, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec, rebalance.time.ms, fetch.time.ms, fetch.MB.sec, fetch.nMsg.sec
2024-03-27 14:56:24:937, 2024-03-27 14:59:01:601, 9536.7823, 60.8741, 10000041, 63831.1354, 1716562585422, -1716562428758, -0.0000, -0.0058
结果解析:
以本例中消费100w条MQ消息为例总共消费了953.8M的数据,每秒消费数据大小为287.377M,总共消费了1000136条消息,每秒消费301336.547条消息。
参数解释:
-
start.time:测试开始的时间,通常以时间戳形式表示,标志着性能测试或监控的开始时刻。
-
end.time:测试结束的时间,通常以时间戳形式表示,标志着性能测试或监控的结束时刻。
-
data.consumed.in.MB:在测试期间消费者从Kafka主题中消费的数据总量,以MB(兆字节)为单位。这个参数表示消费者在指定时间段内消费了多少数据。
-
MB.sec:每秒消费的数据量,以MB(兆字节)为单位。它表示消费者的吞吐量,即每秒能够消费的数据量。
-
data.consumed.in.nMsg:在测试期间消费者从Kafka主题中消费的消息总数。这个参数表示消费者在指定时间段内消费了多少条消息。
-
nMsg.sec:每秒消费的消息数。它表示消费者的吞吐量,即每秒能够消费的消息数量。
-
rebalance.time.ms:在测试期间由于消费者组重新平衡所花费的总时间,以毫秒为单位。消费者组重新平衡是指消费者组内的消费者发生变动(如新增或移除消费者)时,Kafka需要重新分配分区给各个消费者的过程。
-
fetch.time.ms:在测试期间用于从Kafka获取消息的总时间,以毫秒为单位。这个参数表示消费者花在从Kafka拉取消息上的总时间。
-
fetch.MB.sec:每秒从Kafka获取的数据量,以MB(兆字节)为单位。这个参数表示消费者在拉取消息时的吞吐量。
-
fetch.nMsg.sec:每秒从Kafka获取的消息数。这个参数表示消费者在拉取消息时的吞吐量。
这些参数可以帮助评估Kafka消费者在不同负载下的性能,找出可能的瓶颈,并进行相应的优化。
结果汇总:
| 消费消息总数(单位:w) | 共消费数据(单位:M) | 每秒消费数据(单位:M) | 每秒消费消息数 | 消费耗时(单位:s) |
|---|---|---|---|---|
| 10 | 95.367 | 1089.631 | 93984.9624 | 1.064 |
| 100 | 953.8 | 287.3769 | 301336.5472 | 3.319 |
| 1000 | 9536.7823 | 60.8741 | 63831.1354 | 156.664 |
参考:
- Kafka压力测试(自带测试脚本)(单机版)
- 如何做 Kafka 的性能测试
相关文章:

kafka单机安装及性能测试
kafka单机安装及性能测试 Apache Kafka是一个分布式流处理平台,最初由LinkedIn开发,并于2011年开源,随后成为Apache项目。Kafka的核心概念包括发布-订阅消息系统、持久化日志和流处理平台。它主要用于构建实时数据管道和流处理应用ÿ…...
2024.05.29学习记录
1、css面经复习 2、代码随想录二刷 3、rosebush upload组件初步完成...
)
6.10 Libbpf-bootstrap(一,简介)
写在前面 在看完前面的介绍,是不是感觉看了也就看了。但是,如果想要像BCC那样使用libbpf编写BPF程序,该怎么开始呢? 那么这就需要libbpf-bootstrap了。 libbpf-bootstrap是官方推荐的一个范式,就像我们写PPT的模版。简单来说可以简化我们的BPF开发流程,它可以帮助我们…...

2.1.2 基于配置方式使用MyBatis
文章目录 实战目标实战步骤1. 创建Maven项目2. 添加项目依赖3. 创建用户实体类4. 创建用户映射器配置文件5. 创建MyBatis配置文件6. 创建日志属性文件7. 测试用户操作8. 运行测试方法 预期结果实战方法结论 实战目标 本实战的目标是演示如何使用MyBatis框架来操作数据库。通过…...

使用NuScenes数据集生成ROS Bag文件:深度学习与机器人操作的桥梁
在自动驾驶、机器人导航及环境感知的研究中,高质量的数据集是推动算法发展的关键。NuScenes数据集作为一项开源的多模态自动驾驶数据集,提供了丰富的雷达、激光雷达(LiDAR)、摄像头等多种传感器数据,是进行多传感器融合…...

氢燃料电池汽车行业发展
文章目录 前言 市场分布 整车销售 发动机配套 氢气供应 发展动能 参考文献 前言 见《氢燃料电池技术综述》 见《燃料电池工作原理详解》 见《燃料电池发电系统详解》 见《燃料电池电动汽车详解》 市场分布 纵观全球的燃料电池汽车市场,截至2022年底ÿ…...
Linux服务器配置ssh证书登录
1、ssh证书登录介绍 Linux服务器ssh登录有密码登录和证书登录两种。如果使用密码登录,容易遭受密码泄露或者暴力破解,我们可以使用ssh证书登录并禁止使用密码登录,ssh证书登录通过公钥和私钥来完成整个连接过程,公钥保存在服务器…...
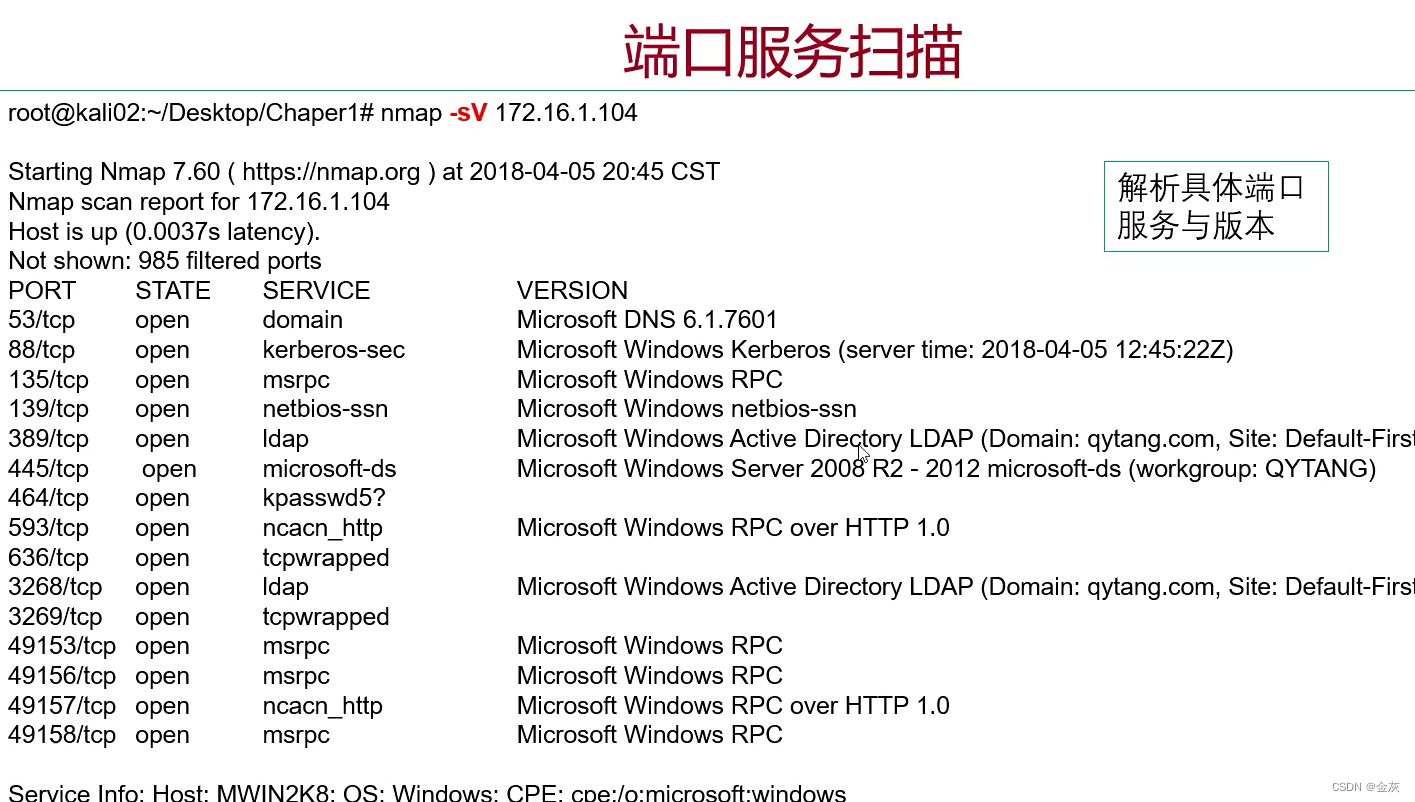
端口扫描利器--nmap
目录 普通扫描 几种指定目标的方法 TCP/UDP扫描 端口服务扫描 综合扫描 普通扫描 基于端口连接并响应(真实) nmap -sn 网段(0/24)-sn 几种指定目标的方法 单个IP扫描 IP范围扫描 扫描文件里的IP 扫描网段,(排除某IP) 扫描网段(排除某清单IP) TCP/UDP扫描 -sS …...

React基础知识笔记
Reat简介 React:用于构建用户界面的 JavaScript 库。由 Facebook 开发且开源。是一个将视图渲染为html视图的开源库 第一章:React入门 相关js库 react.development.js :React 核心库react-dom.development.js :提供 DOM 操作的…...

筛选的艺术:数组元素的精确提取
新书上架~👇全国包邮奥~ python实用小工具开发教程http://pythontoolsteach.com/3 欢迎关注我👆,收藏下次不迷路┗|`O′|┛ 嗷~~ 目录 一、筛选的基本概念 二、筛选的实际应用案例 1. 筛选能被三整除的元素 2. 筛选小于特定值…...

SQLServer2022新特性JSON_PATH_EXISTS测试输入 JSON 字符串中是否存在指定的 SQL/JSON 路径
SQLServer2022新特性JSON_PATH_EXISTS测试输入 JSON 字符串中是否存在指定的 SQL/JSON 路径 参考官方文档 https://learn.microsoft.com/en-us/sql/t-sql/functions/json-path-exists-transact-sql?viewsql-server-ver16 1、本文内容 语法参数返回值示例相关内容 适用于&a…...
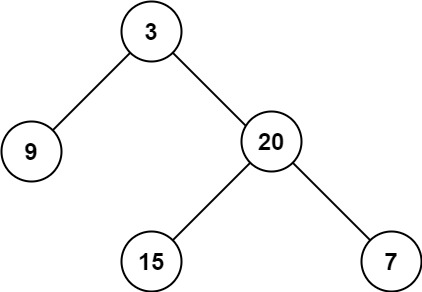
力扣:104. 二叉树的最大深度
104. 二叉树的最大深度 给定一个二叉树 root ,返回其最大深度。 二叉树的 最大深度 是指从根节点到最远叶子节点的最长路径上的节点数。 示例 1: 输入:root [3,9,20,null,null,15,7] 输出:3示例 2: 输入:…...
分支结构)
嵌入式0基础开始学习 ⅠC语言(3)分支结构
C语言程序设计结构 分三种 顺序结构: 一条一条指令执行。 int a,b; a 3; b 4; 分支结构(选择结构):…...

设计模式21——命令模式
写文章的初心主要是用来帮助自己快速的回忆这个模式该怎么用,主要是下面的UML图可以起到大作用,在你学习过一遍以后可能会遗忘,忘记了不要紧,只要看一眼UML图就能想起来了。同时也请大家多多指教。 命令模式(Command&…...
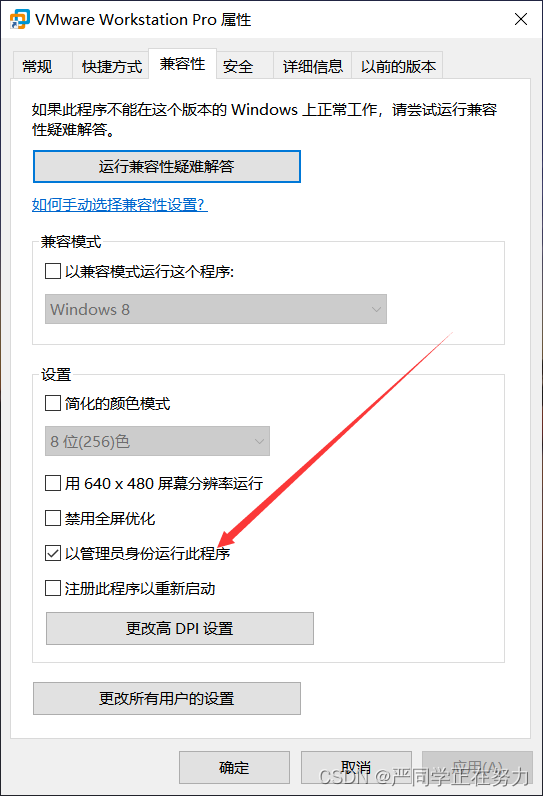
虚拟机报错:VMX 进程已提前退出。VMware Workstation 无法连接到虚拟机。
解决报错:VMware Workstation 无法连接到虚拟机。请确保您有权运行该程序、访问该程序使用的所有目录以及访问所有临时文件目录。 VMX 进程已提前退出。 解决方案:右键桌面图标进入VMware Workstation Pro的属性设置,兼容性–勾选“以管理员…...
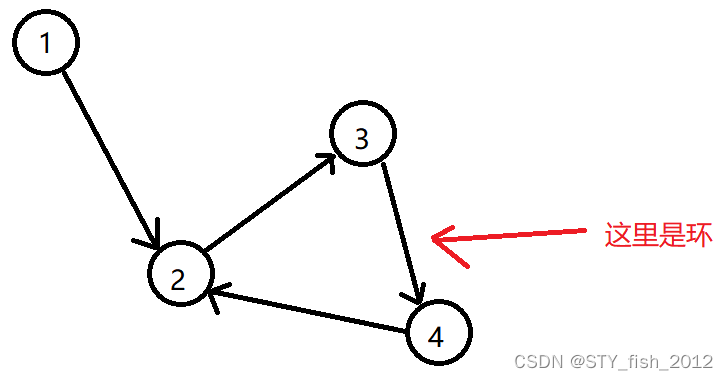
P2341 受欢迎的牛
题目描述 每一头牛的愿望就是变成一头最受欢迎的牛。现在有 N 头牛,给你 M 对整数,表示牛 A 认为牛 B 受欢迎。这种关系是具有传递性的,如果 A 认为 B 受欢迎,B 认为 C 受欢迎,那么牛 A 也认为牛 C 受欢迎。你的任务是…...
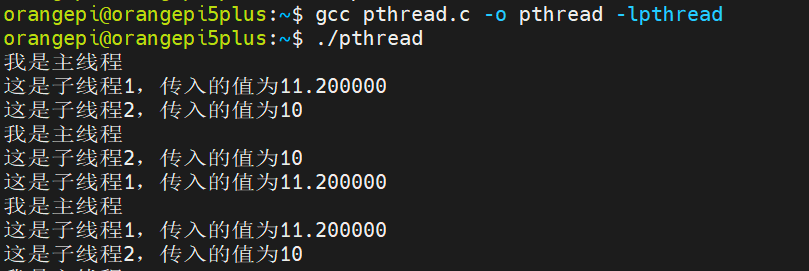
Linux系统编程(五)多线程
目录 一、基本知识点二、线程的编译三、 线程相关函数1. 线程的创建2. 线程的退出3. 线程的等待补充 四、综合举例 一、基本知识点 线程(Thread)是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。一个标准…...

HTTP Basic Access Authentication Schema
HTTP Basic Access Authentication Schema 背景介绍流程安全缺陷参考 背景 本文内容大多基于网上其他参考文章及资料整理后所得,并非原创,目的是为了需要时方便查看。 介绍 HTTP Basic Access Authentication Schema,HTTP 基本访问认证模式…...

#职场发展#其他
一闪论文是目前市场上一款非常靠谱的论文写作工具,不仅可以帮助用户快速完成论文撰写,还能对文章进行查重降重,确保内容原创性。从用户的角度来看,一闪论文确实是一个非常方便、实用的工具,能够大大提高写作效率&#…...

【Text2SQL 论文】评估 ChatGPT 的 zero-shot Text2SQL 能力
论文:A comprehensive evaluation of ChatGPT’s zero-shot Text-to-SQL capability ⭐⭐⭐⭐ arXiv:2303.13547 这篇论文呢综合评估了 ChatGPT 在 zero-shot Text2SQL 任务上的表现。 dataset 使用了 Spider、Spider-SYN、Spider-DK、Spider-Realistic、Spider-CG…...

LiveTalking 部署踩坑笔记
目录 版本特点: tts方案: musetalk方案 一、先确认:1985 端口有没有在监听 Windows: Linux: 报错:SyntaxError: ( was never closed 版本特点: 日常开发 / 测试 / 本地实时 Demo → Wav2…...

开源推荐系统项目数据管理实战:从零构建高质量训练数据集
开源推荐系统项目数据管理实战:从零构建高质量训练数据集 【免费下载链接】fun-rec 推荐系统入门教程,在线阅读地址:https://datawhalechina.github.io/fun-rec/ 项目地址: https://gitcode.com/datawhalechina/fun-rec 你是否曾满怀热…...
)
告别osgQt!用osgQOpenGLWidget在Qt6中轻松加载OsgEarth三维地球(附完整代码)
现代Qt6与OsgEarth集成实战:osgQOpenGLWidget替代方案详解 如果你正在使用Qt6开发三维地理可视化应用,却苦于找不到合适的OpenSceneGraph(OSG)集成方案,这篇文章将为你提供一条清晰的迁移路径。随着Qt和OSG版本的迭代,传统的osgQt…...

从ChatGPT到文心一言:揭秘大语言模型背后的Decoder-only架构设计
从ChatGPT到文心一言:大语言模型的Decoder-only架构设计哲学 当ChatGPT在2022年末掀起全球AI对话风暴时,一个关键设计选择引起了技术界的广泛讨论:为什么这些最先进的大语言模型都选择了纯Decoder架构?这背后隐藏着怎样的技术哲学…...

【大英赛】2009-2026年大英赛ABCD类历年真题、样卷、听力音频及答案PDF电子版
2026年大英赛将于4月12日9:00—11:00举行,开始倒计时啦!小编整理了最新的2009-2026年大学生英语竞赛(大英赛NECCS)ABCD类历年真题、样卷、听力音频及答案解析,PDF电子版,可下载打印! 资料下载&a…...

解锁Claude无限潜能:技能生态系统的构建艺术
解锁Claude无限潜能:技能生态系统的构建艺术 【免费下载链接】awesome-claude-skills A curated list of awesome Claude Skills, resources, and tools for customizing Claude AI workflows 项目地址: https://gitcode.com/GitHub_Trending/aw/awesome-claude-s…...

3步突破显卡限制:如何让AMD/Intel显卡实现DLSS级画质?
3步突破显卡限制:如何让AMD/Intel显卡实现DLSS级画质? 【免费下载链接】OptiScaler OptiScaler bridges upscaling/frame gen across GPUs. Supports DLSS2/XeSS/FSR2 inputs, replaces native upscalers, enables FSR3 FG on non-FG titles. Supports N…...

终极指南:Czkawka开源文件管理工具,5分钟解决存储空间不足难题
终极指南:Czkawka开源文件管理工具,5分钟解决存储空间不足难题 【免费下载链接】czkawka Multi functional app to find duplicates, empty folders, similar images etc. 项目地址: https://gitcode.com/GitHub_Trending/cz/czkawka 你是否经常遇…...

电视盒子变身高性能服务器:Armbian系统终极刷机指南
电视盒子变身高性能服务器:Armbian系统终极刷机指南 【免费下载链接】amlogic-s9xxx-armbian Supports running Armbian on Amlogic, Allwinner, and Rockchip devices. Support a311d, s922x, s905x3, s905x2, s912, s905d, s905x, s905w, s905, s905l, rk3588, rk…...

2025.12晶晨S905L3S-L3SB安卓9通刷实战:当贝桌面加持,解锁多品牌盒子新玩法
1. 晶晨S905L3S-L3SB通刷包的前世今生 第一次听说晶晨S905L3S-L3SB芯片能通刷时,我正对着家里三台不同品牌的电视盒子发愁。这些盒子有的来自运营商赠送,有的是二手市场淘来的,虽然硬件配置相近,但系统体验天差地别。直到发现这个…...