比较kube-proxy模式:iptables还是IPVS?
kube-proxy是任何 Kubernetes 部署中的关键组件。它的作用是将流向服务(通过集群 IP 和节点端口)的流量负载均衡到正确的后端pod。kube-proxy可以运行在三种模式之一,每种模式都使用不同的数据平面技术来实现:userspace、iptables 或 IPVS。
userspace 模式非常旧且慢,绝对不推荐!但是,应该如何权衡选择 iptables 还是 IPVS 模式呢?在本文中,我们将比较这两种模式,在实际的微服务环境中衡量它们的性能,并解释在何种情况下你可能会选择其中一种。
首先,我们将简要介绍这两种模式的背景,然后深入测试和结果……
背景:iptables 代理模式
iptables 是一个 Linux 内核功能,旨在成为一个高效的防火墙,具有足够的灵活性来处理各种常见的数据包操作和过滤需求。它允许将灵活的规则序列附加到内核数据包处理管道中的各个钩子上。在 iptables 模式下,kube-proxy将规则附加到 “NAT pre-routing” 钩子上,以实现其 NAT 和负载均衡功能。这种方式可行,简单,使用成熟的内核功能,并且与其他使用 iptables 进行过滤的程序(例如 Calico)能够很好地兼容。
然而,kube-proxy 编程 iptables 规则的方式意味着它名义上是一个 O(n) 风格的算法,其中 n 大致与集群规模成正比(更准确地说,是与服务的数量和每个服务背后的后端 pod 数量成正比)。
背景:IPVS 代理模式
IPVS 是一个专门为负载均衡设计的 Linux 内核功能。在 IPVS 模式下,kube-proxy通过编程 IPVS 负载均衡器来代替使用 iptables。它同样使用成熟的内核功能,且 IPVS 专为负载均衡大量服务而设计;它拥有优化的 API 和查找例程,而不是一系列顺序规则。
结果是,在 IPVS 模式下,kube-proxy 的连接处理具有名义上的 O(1) 计算复杂度。换句话说,在大多数情况下,它的连接处理性能将保持恒定,而不受集群规模的影响。
此外,作为一个专用的负载均衡器,IPVS 拥有多种不同的调度算法,如轮询、最短期望延迟、最少连接数和各种哈希方法。相比之下,iptables 中的 kube-proxy 使用的是随机的等成本选择算法。
IPVS 的一个潜在缺点是,通过 IPVS 处理的数据包在 iptables 过滤钩子中的路径与正常情况下的数据包非常不同。如果计划将 IPVS 与其他使用 iptables 的程序一起使用,则需要研究它们是否能够预期地协同工作。(别担心,Calico 早在很久以前就已经与 IPVS kube-proxy 兼容了!)
性能比较
好的,从名义上来说,kube-proxy在 iptables 模式下的连接处理是 O(n) 复杂度,而在 IPVS 模式下是 O(1) 复杂度。但在实际微服务环境中,这意味着什么呢?
在大多数情况下,涉及应用程序和微服务时,kube-proxy性能有两个关键属性可能是您关心的:
- 对往返响应时间的影响:当一个微服务向另一个微服务发出 API 调用时,平均而言第一个微服务发送请求并从第二个微服务接收响应需要多长时间?
- 对总 CPU 使用率的影响:在运行微服务时,包括用户空间和内核/系统使用在内的主机总 CPU 使用率是多少?这包括了支持微服务所需的所有进程,包括 kube-proxy。
为了说明这一点,我们在一个专用节点上运行了一个“客户端”微服务 pod,每秒生成 1000 个请求,发送到由 10 个“服务器”微服务 pod 支持的 Kubernetes 服务。然后,我们在 iptables 和 IPVS 模式下,在客户端节点上测量了性能,使用了各种数量的 Kubernetes 服务,每个服务有 10 个 pod 支持,最多达到 10,000 个服务(即 100,000 个服务后端)。对于微服务,我们使用golang编写的简单测试工具作为我们的客户端微服务,并使用标准NGINX作为服务器微服务的后端pods。
往返响应时间
在考虑往返响应时间时,理解连接和请求之间的区别非常重要。通常,大多数微服务将使用持久连接或“keepalive”连接,这意味着每个连接会在多个请求之间重复使用,而不是每个请求都需要新建一个连接。这一点很重要,因为大多数新连接都需要在网络上进行三次握手(这需要时间),并且在 Linux 网络栈内进行更多处理(这也需要一点时间和 CPU 资源)。
为了说明这些差异,我们在有和没有 keepalive 连接的情况下进行了测试。对于 keepalive 连接,我们使用了 NGINX 的默认配置,该配置会将每个连接保持活跃状态以供最多 100 个请求重复使用。请参见下图,注意响应时间越低越好。

图表显示了两个关键点:
- 在超过 1,000 个服务(10,000 个后端 pod)之前,iptables 和 IPVS 之间的平均往返响应时间差异微不足道。
- 平均往返响应时间的差异仅在不使用 keepalive 连接时才明显。也就是说,当每个请求都使用新连接时,差异才会显现。
对于 iptables 和 IPVS 模式,kube-proxy 的响应时间开销与建立连接有关,而不是与连接上的数据包或请求数量有关。这是因为 Linux 使用连接跟踪(conntrack),能够非常高效地将数据包匹配到现有连接。如果数据包在 conntrack 中被匹配到,就不需要通过 kube-proxy 的 iptables 或 IPVS 规则来决定如何处理它。
值得注意的是,在这个例子中,“服务器”微服务使用的是 NGINX pod 提供一个小的静态响应体。许多微服务需要做的工作远不止这些,这将导致相应更高的响应时间,这意味着 kube-proxy 处理的时间差在这种图表中将占据更小的百分比。
最后有一个奇怪现象需要解释:为什么在 10,000 个服务时,非 keepalive 连接的响应时间在 IPVS 模式下变得更慢,即使 IPVS 中新连接的处理复杂度是 O(1)?要真正深入了解这一点,我们需要进行更多的挖掘,但其中一个因素是整个系统由于主机上增加的 CPU 使用而变得更慢。这也引出了下一个话题。
总CPU使用率
为了说明总 CPU 使用率,下面的图表集中在不使用持久/keepalive 连接的最坏情况下,此时 kube-proxy 连接处理的开销影响最大。

图表显示了两个关键点:
- 在超过 1,000 个服务(10,000 个后端 pod)之前,iptables 和 IPVS 之间的 CPU 使用率差异相对不显著。
- 在 10,000 个服务(100,000 个后端 pod)时,iptables 的 CPU 增加约为一个内核的 35%,而 IPVS 增加约为一个内核的 8%。
有两个主要因素影响这种 CPU 使用模式。
第一个因素是,默认情况下,kube-proxy 每 30 秒重新编程一次内核中的所有服务。这解释了为什么即使 IPVS 的新连接处理名义上是 O(1) 复杂度,IPVS 模式下的 CPU 也会略有增加。此外,较早版本内核中重新编程 iptables 的 API 速度比现在慢得多。因此,如果您在 iptables 模式下使用旧版内核,CPU 增长将比图表中显示的更高。
第二个因素是 kube-proxy 使用 iptables 或 IPVS 处理新连接所需的时间。对于 iptables,这在名义上是 O(n) 复杂度。在大量服务的情况下,这对 CPU 使用有显著影响。例如,在 10,000 个服务(100,000 个后端 pod)时,iptables 每个新连接执行约 20,000 条规则。不过,请记住,在这个图表中,我们展示的是每个请求都使用新连接的最坏情况。如果我们使用 NGINX 默认的每个连接 100 次 keepalive 请求,那么 kube-proxy 的 iptables 规则执行频率将减少 100 倍,从而大大降低使用 iptables 而非 IPVS 的 CPU 影响,接近一个内核的 2%。
值得注意的是,在这个例子中,“客户端”微服务简单地丢弃了从“服务器”微服务接收到的每个响应。一个实际的微服务需要做的工作远不止这些,这将增加图表中的基础 CPU 使用率,但不会改变与服务数量相关的 CPU 增加的绝对值。
结论
在显著超过 1,000 个服务的规模下,kube-proxy 的 IPVS 模式可以提供一些不错的性能提升。具体效果可能有所不同,但一般来说,对于使用持久“keepalive”连接风格的微服务,且运行在现代内核上的情况下,这些性能提升可能相对有限。对于不使用持久连接的微服务,或者在较旧内核上运行时,切换到 IPVS 模式可能会带来显著的收益。
除了性能方面的考虑外,如果您需要比 kube-proxy 的 iptables 模式的随机负载均衡更复杂的负载均衡调度算法,也应该考虑使用 IPVS 模式。
如果您不确定 IPVS 是否会对您有利,那么坚持使用 kube-proxy 的 iptables 模式。它已经经过大量的生产环境验证,尽管并不完美,但可以说它作为默认选择是有原因的。
比较 kube-proxy 和 Calico 对 iptables 的使用
在本文中,我们看到 kube-proxy 使用 iptables 在非常大规模时会导致性能影响。我有时会被问到,为什么 Calico 没有遇到同样的挑战。答案是 Calico 对 iptables 的使用与 kube-proxy 有显著不同。kube-proxy 使用了一条非常长的规则链,其长度大致与集群规模成正比,而 Calico 使用的是非常短且优化的规则链,并广泛使用 ipsets,其查找时间复杂度为 O(1),不受其大小影响。
为了更好地理解这一点,下面的图表显示了在集群中的节点平均托管 30 个 pod,且集群中的每个 pod 平均适用 3 个网络策略的情况下,每个连接由 kube-proxy 和 Calico 执行的 iptables 规则的平均数量。
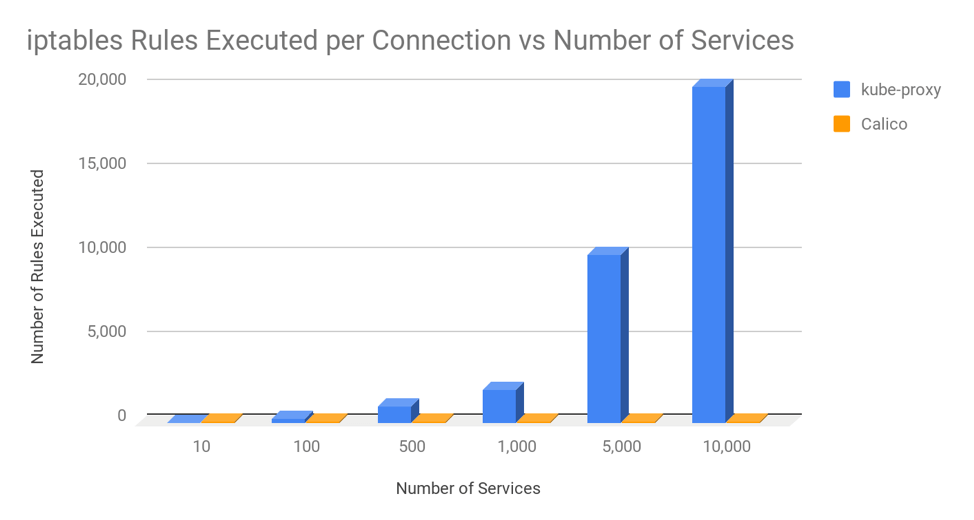
即使在完全扩展的集群中运行,拥有 10,000 个服务和 100,000 个后端 pod 时,Calico 每个连接执行的 iptables 规则数量大致与 kube-proxy 在拥有 20 个服务和 200 个后端 pod 时执行的规则数量相同。换句话说,Calico 对 iptables 的使用是可扩展的!
相关文章:
比较kube-proxy模式:iptables还是IPVS?
kube-proxy是任何 Kubernetes 部署中的关键组件。它的作用是将流向服务(通过集群 IP 和节点端口)的流量负载均衡到正确的后端pod。kube-proxy可以运行在三种模式之一,每种模式都使用不同的数据平面技术来实现:userspace、iptables…...

CSS:浮动
▐ 文档流: 由于网页默认是一个二维平面,当我们在网页中一行行摆放标签时,块标签会独占一行,行标签则只占自身大小,这种情况下要实现网页布局就很麻烦了,所以我们就需要通过一些方法来改变这种默认的布局方…...

SQL 语言:嵌入式 SQL 和动态 SQL
文章目录 基本概述嵌入式 SQL动态 SQL总结 基本概述 嵌入式SQL和动态SQL是两种在应用程序中嵌入和使用SQL语句的方法。它们都允许开发人员在编程语言中编写SQL语句,以便在应用程序中执行数据库操作。然而,这两种方法在实现方式、性能和灵活性方面存在一…...

Java Object类方法介绍
Object作为顶级类,所有的类都实现了该类的方法,包括数组。 查询Java文档: 1、object.eauqls(): 其作用与 有些类似。 : 是一个比较运算符,而不是一个方法。 ①可以判断基本类型,也可以判断引用类型。 ②若…...
2024 京麟ctf -MazeCodeV1
文章目录 检查代码思路一个字节的指令注意附上S1uM4i佬们的exp https://www.ctfiot.com/184181.html 检查 代码 __int64 __fastcall check_solve(char *a1) {__int64 result; // rax__int64 v2; // rax__int64 index_step; // rax__int64 v4; // rax__int64 v5; // rax__int64…...
计算机网络基础 - 计算机网络和因特网(1)
计算机网络基础 计算机网络和因特网什么是 Internet?具体构造的的角度服务角度网络结构 网络边缘网络核心电路交换分组交换概述排队时延和分组丢失转发表和路由选择协议按照有无网络层的连接 分组交换 VS 电路交换 接入网DSL 因特网接入电缆因特网接入光纤到户 FTTH无线接入网…...

自学动态规划——零钱兑换
零钱兑换 322. 零钱兑换 - 力扣(LeetCode) 注意几个关键的地方: 因为每次都是找min,所以我们不能将所有元素都初始化为0,不然最后结果一定是0,这里我设置为0x3f3f3f3f,表示无解。当amount0的…...

kafka单机安装及性能测试
kafka单机安装及性能测试 Apache Kafka是一个分布式流处理平台,最初由LinkedIn开发,并于2011年开源,随后成为Apache项目。Kafka的核心概念包括发布-订阅消息系统、持久化日志和流处理平台。它主要用于构建实时数据管道和流处理应用ÿ…...
2024.05.29学习记录
1、css面经复习 2、代码随想录二刷 3、rosebush upload组件初步完成...
)
6.10 Libbpf-bootstrap(一,简介)
写在前面 在看完前面的介绍,是不是感觉看了也就看了。但是,如果想要像BCC那样使用libbpf编写BPF程序,该怎么开始呢? 那么这就需要libbpf-bootstrap了。 libbpf-bootstrap是官方推荐的一个范式,就像我们写PPT的模版。简单来说可以简化我们的BPF开发流程,它可以帮助我们…...

2.1.2 基于配置方式使用MyBatis
文章目录 实战目标实战步骤1. 创建Maven项目2. 添加项目依赖3. 创建用户实体类4. 创建用户映射器配置文件5. 创建MyBatis配置文件6. 创建日志属性文件7. 测试用户操作8. 运行测试方法 预期结果实战方法结论 实战目标 本实战的目标是演示如何使用MyBatis框架来操作数据库。通过…...

使用NuScenes数据集生成ROS Bag文件:深度学习与机器人操作的桥梁
在自动驾驶、机器人导航及环境感知的研究中,高质量的数据集是推动算法发展的关键。NuScenes数据集作为一项开源的多模态自动驾驶数据集,提供了丰富的雷达、激光雷达(LiDAR)、摄像头等多种传感器数据,是进行多传感器融合…...

氢燃料电池汽车行业发展
文章目录 前言 市场分布 整车销售 发动机配套 氢气供应 发展动能 参考文献 前言 见《氢燃料电池技术综述》 见《燃料电池工作原理详解》 见《燃料电池发电系统详解》 见《燃料电池电动汽车详解》 市场分布 纵观全球的燃料电池汽车市场,截至2022年底ÿ…...
Linux服务器配置ssh证书登录
1、ssh证书登录介绍 Linux服务器ssh登录有密码登录和证书登录两种。如果使用密码登录,容易遭受密码泄露或者暴力破解,我们可以使用ssh证书登录并禁止使用密码登录,ssh证书登录通过公钥和私钥来完成整个连接过程,公钥保存在服务器…...
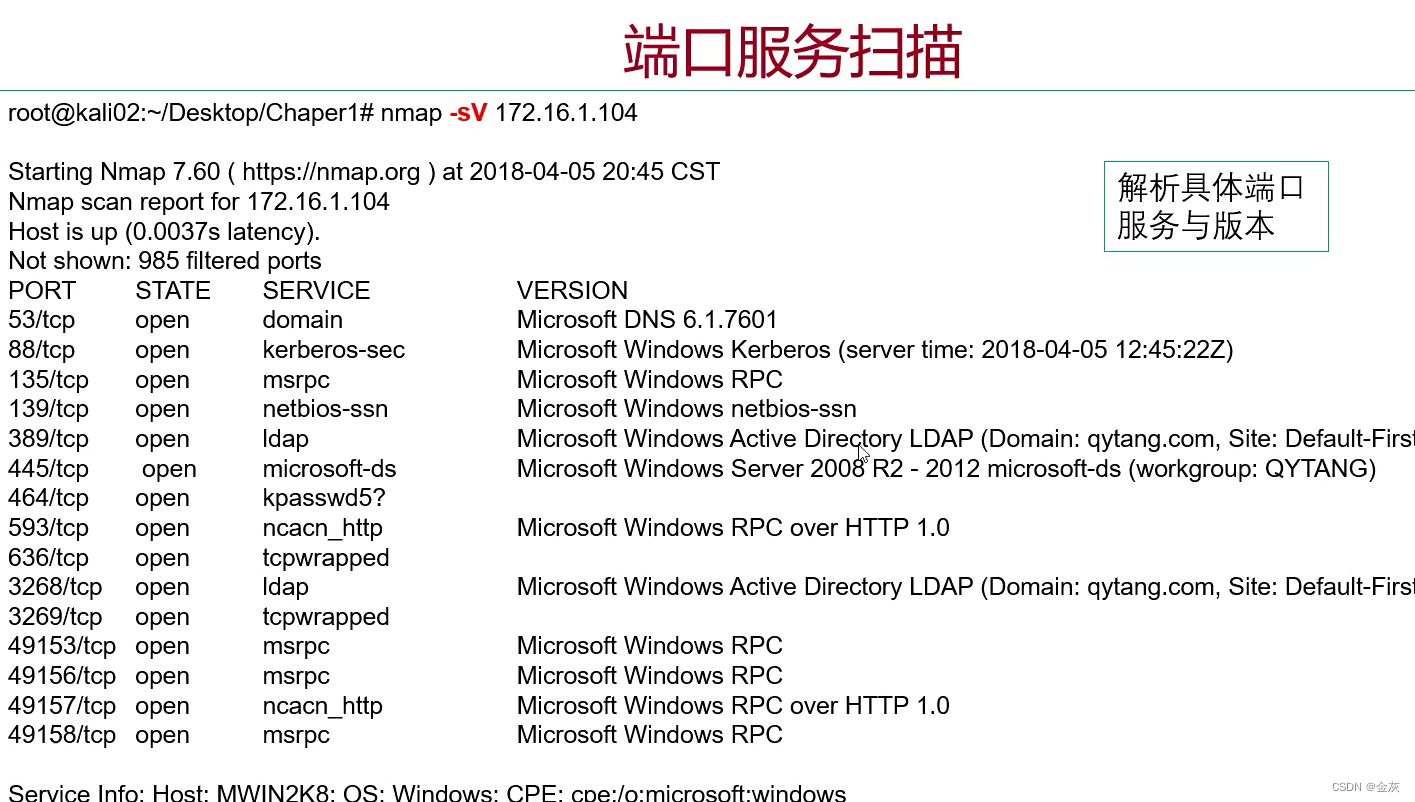
端口扫描利器--nmap
目录 普通扫描 几种指定目标的方法 TCP/UDP扫描 端口服务扫描 综合扫描 普通扫描 基于端口连接并响应(真实) nmap -sn 网段(0/24)-sn 几种指定目标的方法 单个IP扫描 IP范围扫描 扫描文件里的IP 扫描网段,(排除某IP) 扫描网段(排除某清单IP) TCP/UDP扫描 -sS …...

React基础知识笔记
Reat简介 React:用于构建用户界面的 JavaScript 库。由 Facebook 开发且开源。是一个将视图渲染为html视图的开源库 第一章:React入门 相关js库 react.development.js :React 核心库react-dom.development.js :提供 DOM 操作的…...

筛选的艺术:数组元素的精确提取
新书上架~👇全国包邮奥~ python实用小工具开发教程http://pythontoolsteach.com/3 欢迎关注我👆,收藏下次不迷路┗|`O′|┛ 嗷~~ 目录 一、筛选的基本概念 二、筛选的实际应用案例 1. 筛选能被三整除的元素 2. 筛选小于特定值…...

SQLServer2022新特性JSON_PATH_EXISTS测试输入 JSON 字符串中是否存在指定的 SQL/JSON 路径
SQLServer2022新特性JSON_PATH_EXISTS测试输入 JSON 字符串中是否存在指定的 SQL/JSON 路径 参考官方文档 https://learn.microsoft.com/en-us/sql/t-sql/functions/json-path-exists-transact-sql?viewsql-server-ver16 1、本文内容 语法参数返回值示例相关内容 适用于&a…...
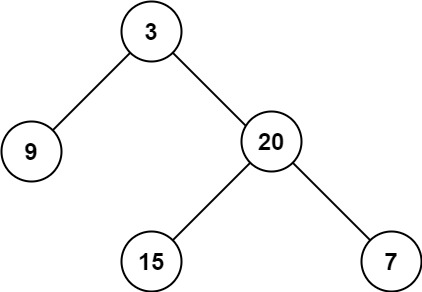
力扣:104. 二叉树的最大深度
104. 二叉树的最大深度 给定一个二叉树 root ,返回其最大深度。 二叉树的 最大深度 是指从根节点到最远叶子节点的最长路径上的节点数。 示例 1: 输入:root [3,9,20,null,null,15,7] 输出:3示例 2: 输入:…...
分支结构)
嵌入式0基础开始学习 ⅠC语言(3)分支结构
C语言程序设计结构 分三种 顺序结构: 一条一条指令执行。 int a,b; a 3; b 4; 分支结构(选择结构):…...

pg_dump备份报错:Only syssso can access this table
文章目录环境症状问题原因解决方案环境 系统平台:N/A 版本:4.5.8 症状 使用pg_dump对数据库进行备份时报错: pg_dump:error:query failed:ERROR: Only syssso can access this table. pg_dump:error:query was: SELECT label, provider, …...
与绕过思路)
从POC到EXP:深入拆解CVE-2025-0282利用链中的三大‘拦路虎’(NX/PIE、虚函数、内存释放)与绕过思路
从POC到EXP:深入拆解CVE-2025-0282利用链中的三大‘拦路虎’(NX/PIE、虚函数、内存释放)与绕过思路 现代漏洞利用已演变为攻防双方在二进制层面的精密博弈。当安全研究员发现一个栈溢出漏洞时,真正的挑战往往始于漏洞验证之后——…...

从真题到实战:拆解CCF-GESP C++三级核心考点与避坑指南
1. 数据编码:从ASCII到UTF-8的实战解析 在CCF-GESP C三级考试中,数据编码是必考的核心知识点。很多同学第一次接触这个概念时容易懵圈——不就是存个字符吗,怎么还有这么多门道?其实理解编码就像学外语,ASCII是基础英语…...

3分钟彻底搞定Axure RP汉化:免费中文语言包完整指南
3分钟彻底搞定Axure RP汉化:免费中文语言包完整指南 【免费下载链接】axure-cn Chinese language file for Axure RP. Axure RP 简体中文语言包,不定期更新。支持 Axure 9、Axure 10。 项目地址: https://gitcode.com/gh_mirrors/ax/axure-cn 还在…...
)
别再只用#if DEBUG了!C#预处理器指令的5个实战妙用(含#warning、#pragma避坑)
别再只用#if DEBUG了!C#预处理器指令的5个实战妙用(含#warning、#pragma避坑) 在C#开发中,预处理器指令往往被简化为#if DEBUG的单一用途,这就像只把瑞士军刀当作开瓶器使用。实际上,这套工具能在代码质量管…...

3大技术突破重构macOS鼠标体验:Mac Mouse Fix深度解析
3大技术突破重构macOS鼠标体验:Mac Mouse Fix深度解析 【免费下载链接】mac-mouse-fix Mac Mouse Fix - Make Your $10 Mouse Better Than an Apple Trackpad! 项目地址: https://gitcode.com/GitHub_Trending/ma/mac-mouse-fix 核心痛点分析:mac…...

PID调参翻车实录:STM32驱动编码电机时,P值过大为何电机啸叫还振荡?
PID调参实战:STM32编码电机啸叫与振荡问题深度解析 当你在深夜实验室里第一次听到电机发出刺耳的啸叫声,同时观察到示波器上速度曲线像过山车一样上下震荡时,那种既困惑又兴奋的感觉,相信每个做过电机控制的工程师都深有体会。这不…...

3D Face HRN效果验证:使用MeshLab量化评估3D重建PSNR与SSIM指标
3D Face HRN效果验证:使用MeshLab量化评估3D重建PSNR与SSIM指标 1. 项目背景与验证意义 3D人脸重建技术近年来取得了显著进展,但如何客观评估重建质量一直是个关键问题。传统的主观视觉评估方法存在明显局限性——不同观察者可能有不同的判断标准&…...

【优选算法篇】拓扑排序——逻辑先后与任务依赖的终极拆解
文章目录逻辑的枷锁:在依赖网中寻找出路零、 拓扑排序:打破逻辑混乱的“秩序之光”一、 课程表 I & II:经典拓扑排序 (Medium)1.1 题目描述1.2 算法思路:依赖关系的剥离1.3 C 代码实战 (以课程表 II 为例)二、 火星词典&#…...

BetterNCM Installer:3步完成网易云音乐插件框架安装
BetterNCM Installer:3步完成网易云音乐插件框架安装 【免费下载链接】BetterNCM-Installer 一键安装 Better 系软件 项目地址: https://gitcode.com/gh_mirrors/be/BetterNCM-Installer BetterNCM Installer 是一个专为网易云音乐PC版客户端设计的插件管理器…...