mysql中InnoDB的统计数据
大家好。我们知道,mysql中存在许多的统计数据,比如通过SHOW TABLE STATUS 可以看到关于表的统计数据,通过SHOW INDEX可以看到关于索引的统计数据,那么这些统计数据是怎么来的呢?它们是以什么方式收集的呢?今天我们来说说InnoDB 存储引擎的统计数据收集策略。
一、统计数据的存储方式
InnoDB 提供了两种存储统计数据的方式:
永久性统计数据: 这种统计数据存储在磁盘上,服务器重启之后这些统计数据还在。
非永久性统计数据: 这种统计数据存储在内存中,当服务器关闭时这些统计数据就会被清除掉,等到服务器重启之后,在某些场景下会重新收集这些统计数据。
MySQL 通过系统变量innodb_stats_persistent来控制到底采用哪种方式去存储统计数据。在MySQL 5.6.6之前,innodb_stats_persistent 的值默认是OFF ,也就是说 nnoDB 的统计数据默认是存储到内存的,之后的版本中innodb_stats_persistent的值默认是ON ,也就是统计数据默认被存储到磁盘中。
InnoDB 默认是以表为单位来收集和存储统计数据的,所以我们可以把某些表的统计数据存储在磁盘上,把另一些表的统计数据存储在内存中。我们可以在创建和修改表的时候通过指定STATS_PERSISTENT属性来指明该表的统计数据存储方式:
CREATE TABLE 表名 (...) Engine=InnoDB, STATS_PERSISTENT = (1|0);
ALTER TABLE 表名 Engine=InnoDB, STATS_PERSISTENT = (1|0);
当STATS_PERSISTENT=1时,该表的统计数据存储到磁盘上,当 STATS_PERSISTENT=0时,该表的统计数据临时的存储到内存中。如果我们在创建表时未指定STATS_PERSISTENT属性,那默认采用系统变量innodb_stats_persistent 的值作为该属性的值。
二、永久性统计数据
永久性统计数据存放到磁盘上时,实际上是存储到下面这两个表里:

可以看到,这两个表都位于mysql 系统数据库下边,其中:
innodb_table_stats 存储了关于表的统计数据,每一条记录对应着一个表的统计数据。
innodb_index_stats 存储了关于索引的统计数据,每一条记录对应着一个索引的一个统计项的统计数据。
下面我们看一下这两个表里边都有什么以及表里的数据是如何生成的。
1、innodb_table_stats

上图就是innodb_table_stats表里存放的数据,下面我们以single_table 表的统计信息为例介绍一下几个重要统计信息项:
n_rows 的值是9446,表明single_table表中大约有9446条记录,注意这个数据是估计值(实际是10000条)。
clustered_index_size 的值是97,表明single_table表的聚簇索引占用97个页面,这个值是也是一个估计值。
sum_of_other_index_sizes 的值是68,表明single_table表的其他索引一共占用68个页面,这个值是也是一个估计值。
1. n_rows统计项的收集
InnoDB 统计一个表中有多少行记录的方式是这样的:按照一定算法选取几个叶子节点页面,计算每个页面中主键值记录数量,然后计算平均一个页面中主键值的记录数量乘以全部叶子节点的数量就算是该表的n_rows值。所以n_rows值是一个估计值,并不是真正的记录数。
可以看出来这个n_rows 值精确与否取决于统计时采样的页面数量,MySQL通过一个名为innodb_stats_persistent_sample_pages的系统变量来控制使用永久性统计数据时计算统计数据时采样的页面数量。该值设置的越大,统计出的n_rows值越精确,但是统计耗时也就最久;该值设置的越小,统计出的n_rows值越不精确,但是统计耗时特别少。该系统变量的默认值是20。
我们也可以单独设置某个表的采样页面的数量,设置方式就是在创建或修改表的时候通过指定STATS_SAMPLE_PAGES属性来指明该表的统计 数据存储方式:
CREATE TABLE 表名 (...) Engine=InnoDB, STATS_SAMPLE_PAGES = 具体的采样页面数量;
ALTER TABLE 表名 Engine=InnoDB, STATS_SAMPLE_PAGES = 具体的采样页面数量;
如果我们在创建表的语句中并没有指定STATS_SAMPLE_PAGES 属性的话,将默认使用系统变量 innodb_stats_persistent_sample_pages的值作为该属性的值。
2. clustered_index_size和sum_of_other_index_sizes统计项的收集
这两个统计项的收集过程如下:
-
从数据字典里找到表的各个索引对应的根页面位置。系统表SYS_INDEXES里存储了各个索引对应的根页面信息。
-
从根页面的Page Header里找到叶子节点段和非叶子节点段对应的 Segment Header。在每个索引的根页面的Page Header部分都有两个字段:
PAGE_BTR_SEG_LEAF: 表示B+树叶子段的Segment Header信息。
PAGE_BTR_SEG_TOP: 表示B+树非叶子段的Segment Header信息。
下面是Segment Header结构示意图:

-
从叶子节点段和非叶子节点段的Segment Header中找到这两个段对应的INODE Entry结构。 下面是INODE Entry结构示意图:
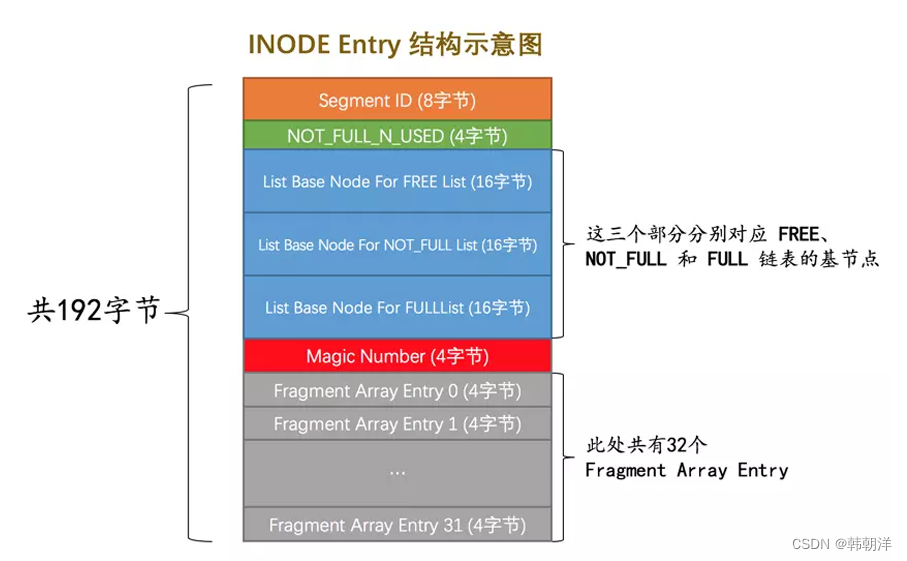
-
从对应的INODE Entry结构中可以找到该段对应所有零散的页面地址以及FREE 、NOT_FULL 、FULL链表的基节点。下面是链表的基节点结构示意图:
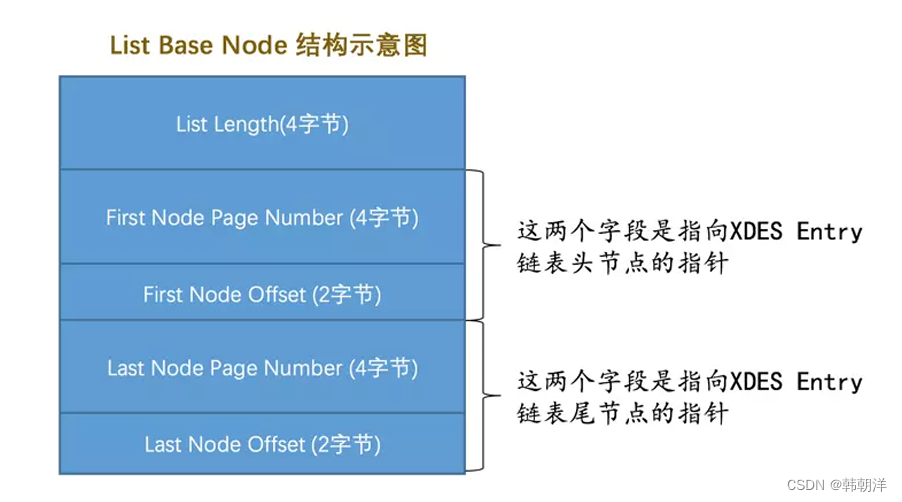
-
直接统计零散的页面有多少个,然后从FREE 、NOT_FULL 、FULL三个链表的List Length字段中读出该段占用的区的大小,每个区占用64 个页,所以就可以统计出整个段占用的页面。
通过上述5个步骤可以统计出索引的某个段占用的页面数量。分别计算聚簇索引的叶子节点段和非叶子节点段占用的页面数,它们的和就是clustered_index_size的值,按照同样的套路把其余索引占用的页面数都算出来,加起来之后就是sum_of_other_index_sizes的值。
注意:一个段的数据在非常多时(超过32个页面),会以区为单位来申请空间,以区为单位申请空间中有一些页可能并没有使用,但是在统计clustered_index_size和sum_of_other_index_sizes时都把它们算进去了,所以说聚簇索引和其他的索引占用的页面数可能比这两个值要小。
2、innodb_index_stats

我们依旧以single_table表为例,上图是single_table表在innodb_index_stats中存储的记录信息。下面我们来看一下如何查看这些信息:
- 先查看index_name列,这个列说明该记录是哪个索引的统计信息。我们可以看出来,PRIMARY索引(也就是主键)占了3条记录,idx_key_part索引占了6条记录。
- 针对index_name列相同的记录, stat_name表示针对该索引的统计项名称, stat_value 展示的是该索引在该统计项上的值,stat_description指的是来描述该统计项的含义的。
我们来具体看一下一个索引都有哪些统计项:
n_leaf_pages:表示该索引的叶子节点占用多少页面。
size:表示该索引共占用多少页面。
n_diff_pfx NN:表示对应的索引列不重复的值有多少。
这里的NN 可以被替换为01、02、03… 这样的数字。比如对于 idx_key_part 来说:
n_diff_pfx01表示的是统计key_part1这单单一个列不重复的值有多少。
n_diff_pfx02表示的是统计key_part1、key_part2这两个列组合起来不重复的值有多少。
n_diff_pfx03 表示的是统计key_part1、key_part2、key_part3 这三个列组合起来不重复的值有多少。
n_diff_pfx04 表示的是统计key_part1、key_part2、key_part3、id 这四个列组合起来不重复的值有多少。
注意:对于普通的二级索引,并不能保证它的索引列值是唯一的,此时只有在索引列上加上主键值才可以区分两条索引列值都一样的二级索引记录。
- 在计算某些索引列中包含多少不重复值时,需要对一些叶子节点页面进行采样,sample_size列就表明了采样的页面数量是多少。
对于有多个列的联合索引来说,采样的页面数量是:innodb_stats_persistent_sample_pages × 索引列的个数。当需要采样的页面数量大于该索引的叶子节点数量的话,就直接采用全表扫描来统计索引列的不重复值数量了。所以不同索引对应的sample_size列的值可能是不同的。
3、定期更新统计数据
随着我们不断的对表进行增删改操作,表中的数据也一直在变化,这时innodb_table_stats和innodb_index_stats表里的统计数据也会跟着变。MySQL提供了两种更新统计数据的方式:
开启innodb_stats_auto_recalc: 系统变量innodb_stats_auto_recalc决定着服务器是否自动重新计算统计数据,它的默认值是ON(开启)。每个表都维护了一个变量,该变量记录着对该表进行增删改的记录条数,如果发生变动的记录数量超过了表大小的10%,并且自动重新计算统计数据的功能是打开的,那么服务器会重新进行一次统计数据的计算,并且更新innodb_table_stats 和 innodb_index_stats 表。不过自动重新计算统计数据 的过程是异步发生的,也就是即使表中变动的记录数超过了10%,自动重新计算统计数据也不会立即发生, 可能会延迟几秒才会进行计算。
InnoDB 默认是以表为单位来收集和存储统计数据的,我们可以单独为某个表设置是否自动重新计算统计数的属性,设置方式就是在创建或修改表的时候通过指定STATS_AUTO_RECALC属性来指明该表的统计数据存储方式:
CREATE TABLE 表名 (...) Engine=InnoDB, STATS_AUTO_RECALC = (1|0);
ALTER TABLE 表名 Engine=InnoDB, STATS_AUTO_RECALC = (1|0);
当STATS_AUTO_RECALC=1时,表明我们想让该表自动重新计算统计数据,当STATS_PERSISTENT=0时,表明不想让该表自动重新计算统计数据。如果我们在创建表时未指定STATS_AUTO_RECALC属性,那默认采用系统 变量innodb_stats_auto_recalc 的值作为该属性的值。
手动调用ANALYZE TABLE语句来更新统计信息: 如果innodb_stats_auto_recalc系统变量的值为OFF,我们也可以手动调用 ANALYZE TABLE语句来重新计算统计数据,ANALYZE TABLE语句会立即重新计算统计数据,也就是这个过程是同步的。
4、 手动更新innodb_table_stats和innodb_index_stats表
其实innodb_table_stats和innodb_index_stats表就相当于一个普通的表一样,我们能对它们做增删改查操作。这也就意味着我们可以手动更新某个表或者索引的统计数据。比如说我们想把single_table 表关于行数的 统计数据更改一下可以这么做:
步骤一:更新innodb_table_stats 表。
UPDATE innodb_table_stats SET n_rows = 1 WHERE table_name = 'single_table
步骤二:让MySQL 查询优化器重新加载我们更改过的数据。
更新完innodb_table_stats只是单纯的修改了一个表的数据,需要运行下边的命令让MySQL查询优化器重新加载我们更改过的数据:
FLUSH TABLE single_table;
三、非永久性统计数据
当我们把系统变量innodb_stats_persistent的值设置为OFF时,创建的表的统计数据默认就都是非永久性的了,或者我们直接在创建表或修改表时设置STATS_PERSISTENT属性的值为0,那么该表的统计数据就是非永久性的了。
与永久性的统计数据不同,非永久性的统计数据采样的页面数量是由innodb_stats_transient_sample_pages控制的,这个系统变量的默认值是8。
最近的MySQL版本都不怎么使用这种基于内存的非永久性统计数据这里我们了解即可。
四、innodb_stats_method的使用
我们知道,索引列不重复的值的数量对于MySQL查询优化器十分重要,因为通过它可以计算出在索引列中平均一个值重复多少行,它的应用场景主要有两个:
1. 单表查询中单点区间太多
SELECT * FROM tbl_name WHERE key IN ('xx1', 'xx2', ..., 'xxn');
当上述sql中IN里的参数数量过多时,采用index dive的方式直接访问 B+树索引去统计每个单点区间对应的记录的数量就太耗费性能了,所以直接依赖统计数据中的平均一个值重复多少行来计算单点区间对应的记录数量。
2. 连接查询时,如果有涉及两个表的等值匹配连接条件,该连接条件对应的被驱动表中的列又拥有索引时,则可以使用ref 访问方法来对被驱动表进行查询
SELECT * FROM t1 JOIN t2 ON t1.column = t2.key WHERE ...;
在真正执行对t2表的查询前,t1.comumn 的值是不确定的,所以也不能通过index dive的方式直接访问B+树索引去统计每个单点区间对应的记录的数量,只能依赖统计数据中的平均一个值重复多少行来计算单点区间对应的记录数量。
下面我们思考一下:在统计索引列不重复的值的数量时,如果索引列中出现NULL值怎么办?例如下面这列:
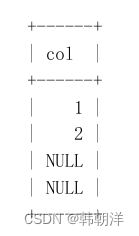
此时计算这个col 列中不重复的值的数量就有下边的分歧:
- 有的人认为NULL值代表一个未确定的值,在统计索引列不重复的值的数量时,应该把NULL值当作 一个独立的值,所以col列的不重复的值的数量就是:4(分别是1、2、NULL、NULL这四个值)。
- 有的人认为其实NULL值在业务上就是代表没有,所有的NULL值代表的意义是一样的,所以col列不重复的值的数量就是:3(分别是1、2、NULL这三个值)。
- 有的人认为这NULL 完全没有意义,所以在统计索引列不重复的值的数量时压根儿不能把它们算进来,所以col 列不重复的值的数量就是:2(分别是1、2这两个值)。
MySQL提供了一个名为innodb_stats_method 的系统变量,这个系统变量有三个候选值:
nulls_equal: 认为所有NULL值都是相等的。这个值也是 innodb_stats_method的默认值。如果某个索引列中NULL 值特别多的话,这种统计方式会让优化器认为某个列中平均一个值重复次数特别多,所以倾向于不使用索引进行访问。
nulls_unequal: 认为所有 NULL 值都是不相等的。如果某个索引列中NULL 值特别多的话,这种统计方式会让优化器认为某个列中平均一个值重复次数特别少,所以倾向于使用索引进行访问。
nulls_ignored: 直接把 NULL 值忽略掉。
好了,到这里我们就讲完了,今天主要讲了InnoDB的统计数据是如何产生的,大家有什么想法欢迎留言讨论。也希望大家能给作者点个关注,谢谢大家!最后依旧是请各位老板有钱的捧个人场,没钱的也捧个人场,谢谢各位老板!
相关文章:
mysql中InnoDB的统计数据
大家好。我们知道,mysql中存在许多的统计数据,比如通过SHOW TABLE STATUS 可以看到关于表的统计数据,通过SHOW INDEX可以看到关于索引的统计数据,那么这些统计数据是怎么来的呢?它们是以什么方式收集的呢?今…...

P459 包装类Wrapper
包装类的分类 1)针对八种基本数据类型相应的引用类型——包装类。 2)有了类的特点,就可以调用类中的方法。 Boolean包装类 Character包装类 其余六种Number类型的包装类 包装类和基本数据类型的相互转换 public class Integer01 {publi…...
Kong网关的负载均衡
安装java环境 查询 java安装包 196 yum list java* 安装java8197 yum install -y java-1.8.0-openjdk.x86_64 检验java8是否安装成功。198 java -version2个tomcat准备 另外一个tomcat区别在于:配置文件。conf/server.xml 启动tomcat [rootlocalhost bin]# ./…...

这是一个逗号
还不太能是句号,随想录这两个月算是给我一个学算法的开头,感慨还是挺多的,但是语文功底很差,就接着写流水账吧。 高考前想报计算机,但是那年是先报志愿后考试,家里人劝我选择更稳一点的985,又说…...
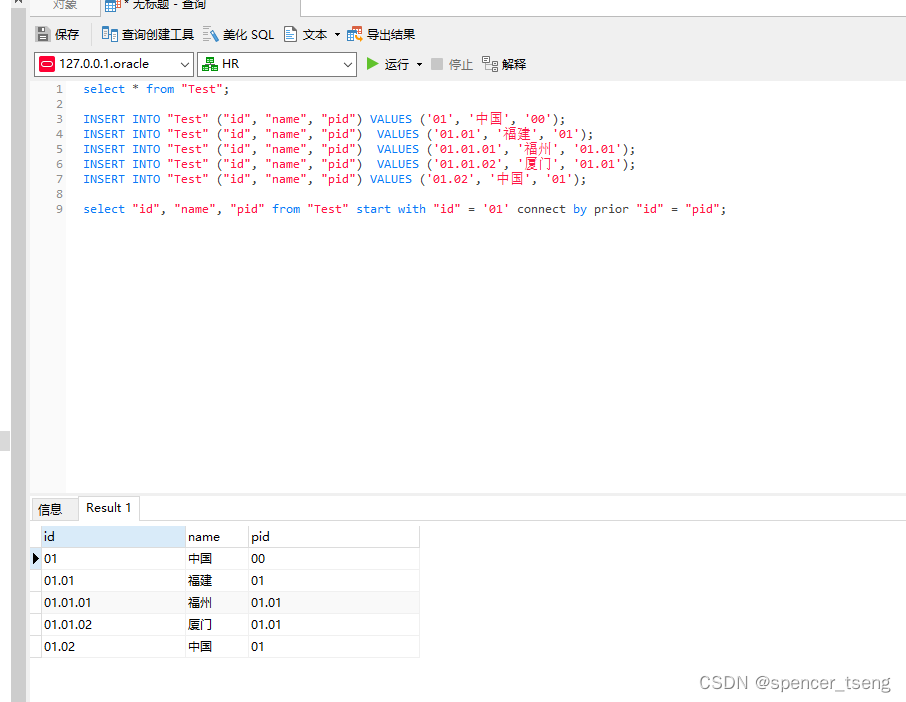
oracle tree
select * from "Test"; INSERT INTO "Test" ("id", "name", "pid") VALUES (01, 中国, 00); INSERT INTO "Test" ("id", "name", "pid") VALUES (01.01, 福建, 01); INSERT INTO…...

react-beautiful-dnd 横纵排序demo
简单导入就可以看到效果 1. 安装依赖 npm i react-beautiful-dnd 2. 纵向排序 import React, { useState } from react; import { DragDropContext, Droppable, Draggable } from react-beautiful-dnd;// 纵向排序 const reorder (list, startIndex, endIndex) > {con…...
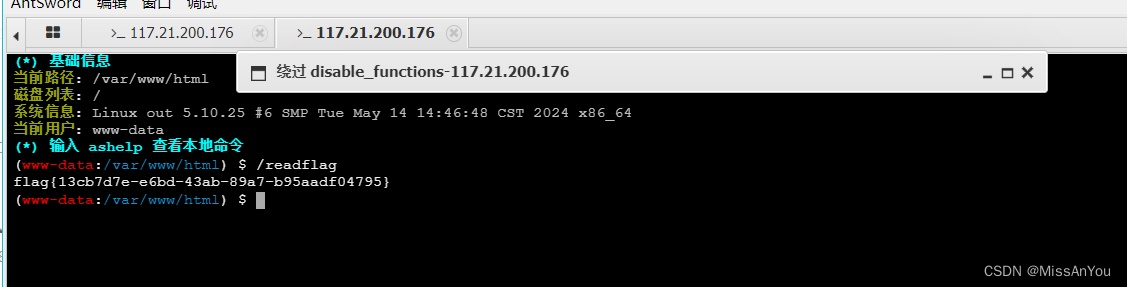
web练习
[CISCN 2022 初赛]ezpop ThinkPHP V6.0.12LTS 反序列化漏洞 漏洞分析 ThinkPHP6.0.12LTS反序列漏洞分析 - FreeBuf网络安全行业门户 解题过程 ThinkPHP V6.0.12LTS反序列化的链子可以找到,找到反序列化的入口就行 反序列化的入口在index.php/index/test 链子 …...
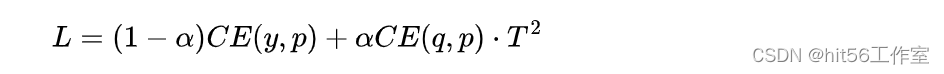
模型蒸馏笔记
文章目录 一、什么是模型蒸馏二、如何蒸馏三、常见问题3.1 四、参考文献 一、什么是模型蒸馏 Hinton在NIPS2014提出了知识蒸馏(Knowledge Distillation)的概念,旨在把一个大模型或者多个模型ensemble学到的知识迁移到另一个轻量级单模型上&a…...
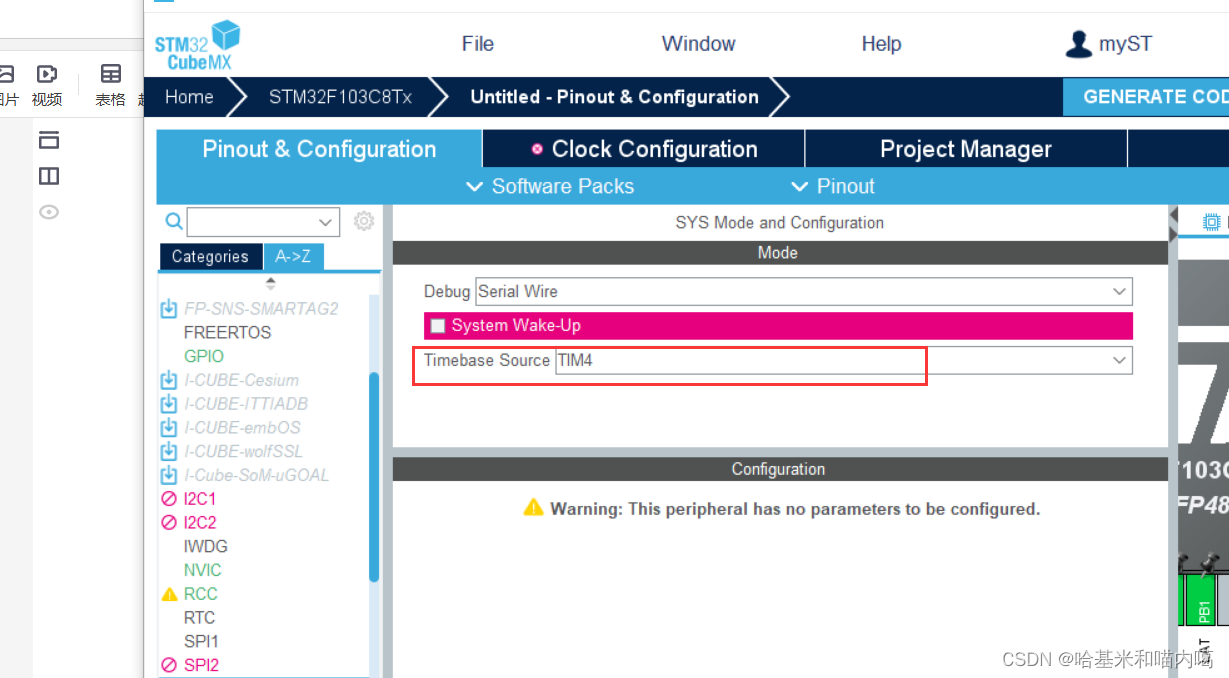
HAL库使用FreeRTOS实时操作系统时配置时基源(TimeBase Source)
需要另外的定时器,用systic的时候生成项目会有警告 https://blog.51cto.com/u_16213579/10967728...

如何让你的网站能通过域名访问
背景 当我们租一台云服务器,并在上面运行了一个Web服务,我们可以使用云服务器的公网IP地址进行访问,如下: 本文主要记录如何 实现让自己的网站可以通过域名访问。 买域名 可以登录腾讯云等主流公有云平台的,购买域名…...

Spring Boot + Spring Security + JWT 从零开始
Spring Boot + Spring Security + JWT 从零开始 这篇笔记中,我们将学习如何从头开始设置一个带有Spring Security的Spring Boot应用程序,它连接到一个LDAP身份验证的Spring Security身份验证提供程序,这将是即将出现的,这个连接和工作都是开箱即用的。 实际上,设置这个非…...

【busybox记录】【shell指令】rmdir
目录 内容来源: 【GUN】【rmdir】指令介绍 【busybox】【rmdir】指令介绍 【linux】【rmdir】指令介绍 使用示例: 删除空目录 - 默认 删除dirname下的所有空目录,包括因删除其他目录而变为空的目录 常用组合指令: 指令不…...
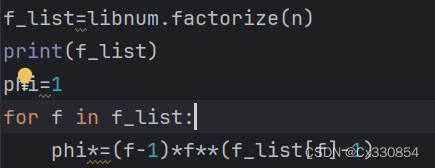
[LitCTF 2023]yafu (中级) (素数分解)
题目: from Crypto.Util.number import * from secret import flagm bytes_to_long(flag) n 1 for i in range(15):n *getPrime(32) e 65537 c pow(m,e,n) print(fn {n}) print(fc {c})n 152412082177688498871800101395902107678314310182046454156816957…...

MySQL alter 语句
ALTER TABLE user ADD COLUMN cdkey varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NULL DEFAULT NULL COMMENT CD-Key, ADD COLUMN erp_userid varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NULL DEFAULT NULL COMMENT ERP用户ID, ADD UNIQUE INDEX un…...
python)
列表推导式(解析式)python
Python中的列表推导式(list comprehension)是一种简洁且强大的语法,用于创建新的列表。它允许你通过对现有列表中的元素进行操作或筛选来快速生成新列表。以下是列表推导式的基本语法和一些示例: 基本语法: new_list…...
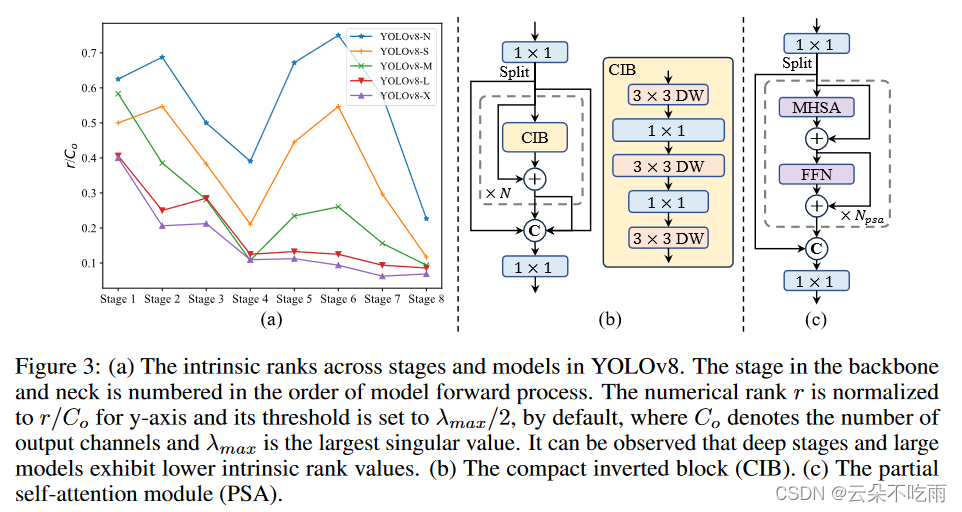
YOLO-10更快、更强
YOLO-10简介 主要贡献: 无NMS的一致双分配 YOLOv10提出了一种通过双标签分配而不用非极大值抑制NMS的策略。这种方法结合了一对多和一对一分配策略的优势,提高了效率并保持了性能。 高效的网络设计 轻量化分类头:在不显著影响性能的情况下&a…...

新火种AI|寻求合作伙伴,展开豪赌,推出神秘AI项目...苹果能否突破AI困境?
作者:小岩 编辑:彩云 2024年,伴随着AI技术的多次爆火,不仅各大科技巨头纷纷进入AI赛道展开角力,诸多智能手机厂商也纷纷加紧布局相关技术,推出众多AI手机。作为手机领域的龙头老大,苹果自然是…...

MFC工控项目实例一主菜单制作
1、本项目用在WIN10下安装的vc6.0兼容版实现。创建项目名为SEAL_PRESSURE的MFC对话框。在项目res文件下添加相关256色ico格式图片。 2、项目名称:密封压力试验机 主菜单名称: 系统参数 SYS_DATA 系统测试 SYS_TEST 选择型号 TYP_CHOICE 开始试验 TES_STA…...

代码随想录-Day22
235. 二叉搜索树的最近公共祖先 方法一:两次遍历 class Solution {public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {List<TreeNode> path_p getPath(root, p);List<TreeNode> path_q getPath(root, q);TreeNode anc…...

uniapp项目 使用vue-plugin-hiprint静默打印功能
插件地址:https://toscode.mulanos.cn/gyy155/vue-plugin-hiprint h5项目使用插件的静默打印功能 1.下载vue-plugin-hiprint和jquery npm install vue-plugin-hiprint npm install jquery --save2.在mian.js引入插件和jqerry //引入vue-plugin-hiprint import { h…...

Zabbix 6.0部署避坑指南:为什么你的Ubuntu安装总卡在数据库初始化这一步?
Zabbix 6.0部署避坑指南:为什么你的Ubuntu安装总卡在数据库初始化这一步? 如果你正在Ubuntu上部署Zabbix 6.0,却反复在数据库初始化这一步失败,这篇文章就是为你准备的。不同于常规的安装教程,我们将聚焦于那些看似简…...

解锁智能OCR新范式:Pix2Text多模态内容识别技术全解析
解锁智能OCR新范式:Pix2Text多模态内容识别技术全解析 【免费下载链接】Pix2Text Pix In, Latex & Text Out. Recognize Chinese, English Texts, and Math Formulas from Images. 项目地址: https://gitcode.com/gh_mirrors/pi/Pix2Text Pix2Text是一款…...

如何让foobar2000界面脱胎换骨?3大设计理念打造个性化音乐体验
如何让foobar2000界面脱胎换骨?3大设计理念打造个性化音乐体验 【免费下载链接】foobox-cn DUI 配置 for foobar2000 项目地址: https://gitcode.com/GitHub_Trending/fo/foobox-cn 副标题:从安装到定制:零基础也能掌握的foobox-cn美化…...

超轻量级OpenClaw与LaTeX结合:学术文档自动化处理
超轻量级OpenClaw与LaTeX结合:学术文档自动化处理 科研工作者每天需要处理大量的文献整理、公式编辑和文档排版工作,传统手动方式耗时且容易出错。本文将展示如何用超轻量级OpenClaw实现学术文档的自动化处理,让LaTeX文档编写变得轻松高效。 …...

MiniCPM-V-2_6嵌入式AI应用实战:STM32F103C8T6边缘推理集成
MiniCPM-V-2_6嵌入式AI应用实战:STM32F103C8T6边缘推理集成 最近几年,AI模型越来越“小”,开始往各种硬件设备里钻。你可能听说过在手机、树莓派上跑AI,但有没有想过,在一块只有指甲盖大小、主频72MHz、内存才20KB的S…...

AI读脸术多国面孔适配:跨种族识别优化部署实战
AI读脸术多国面孔适配:跨种族识别优化部署实战 1. 引言 你有没有遇到过这样的情况:一个在亚洲人脸识别上表现不错的AI模型,拿到一张欧洲人或非洲人的照片时,识别结果就开始"犯迷糊"了?性别判断出错&#x…...
帮你搞定数据分析)
别再只会用高德百度了!这7种专业地图(附GIS工具推荐)帮你搞定数据分析
7种专业地图与GIS工具实战指南:从用户分布到物流优化的全场景解决方案 打开手机地图应用查看路线,可能是大多数人对地理数据的唯一接触。但当你需要分析千万级用户的区域活跃度、规划全国物流网络或评估新店选址时,高德百度提供的标准化地图就…...

AUTOSAR SPI配置进阶:如何为你的车载传感器设计高效可靠的通信序列?
AUTOSAR SPI配置进阶:车载传感器通信序列设计实战指南 在智能驾驶系统开发中,SPI总线作为连接毫米波雷达、IMU等关键传感器的神经末梢,其通信效率直接影响着环境感知的实时性。传统配置手册往往止步于基础参数说明,而本文将带您深…...

从理论到实践:LSTM与Qwen1.5-1.8B GPTQ在时序预测任务中的对比
从理论到实践:LSTM与Qwen1.5-1.8B GPTQ在时序预测任务中的对比 最近在折腾时间序列预测,发现一个挺有意思的现象。大家一提到时序预测,脑子里蹦出来的第一个词可能就是LSTM,这几乎成了这个领域的“标配”。但另一边,以…...

ncmdumpGUI:一站式NCM音乐格式转换解决方案,轻松搞定加密音乐跨设备播放
ncmdumpGUI:一站式NCM音乐格式转换解决方案,轻松搞定加密音乐跨设备播放 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 清晨的音乐烦恼…...