【RAG论文】文档树:如何提升长上下文、非连续文档、跨文档主题时的检索效果
- RAPTOR Recursive Abstractive Processing for Tree-Organized Retrieval
- ICLR 2024 Stanford
- https://arxiv.org/pdf/2401.18059
RAPTOR(Recursive Abstractive Processing for Tree-Organized Retrieval)是一种创建新的检索增强型语言模型,它通过嵌入、聚类和摘要文本模块来构建一个从底层到高层具有不同摘要层的树状结构。这种方法允許模型在推理时从这棵树中检索信息,实现跨文本的不同抽象层的整合。RAPTOR的相关性创新在于它构建了文本摘要的方法,以不同尺度检索上下文的能力,并在多个任务上展示超越传统检索增强语言模型的性能。
研究问题
当前问题:在传统的 RAG 中,系统通常会依赖于检索短文本块。但当处理需要理解长篇上下文的文档时,简单的将文档切割或仅处理其上下文显然不够,在非连续文档、跨文档主题和分散型主题内容时效果不佳。
研究动机:RAPTOR本意是针对目前基于分块的向量检索限制了对上下文的整体信息获取与理解,从而采用了一种构造“从下至上不同级别的摘要树“的优化方法(试想下,很多问题是需要对整个甚至多个文档知识进行理解后才能回答,仅有top_K的分块是不够的?)。
研究内容
研究内容:递归抽象处理树组织检索(Recursive Abstractive Processing for Tree Organized Retrieval)是一种全新且强大的技术,用于以全面的方式对大型语言模型(LLM)进行索引和检索。它采用自下而上的方法,通过对文本段(块)进行聚类和总结,形成一个层级的树状结构。
论文效果:在使用时,RAPTOR能够从这棵树中检索信息,有效整合长篇文档中的信息,覆盖不同的抽象层次。通过实验发现这种递归摘要的检索方式在多个任务上都优于传统的检索增强方法。特别是在需要复杂推理的问答任务上,结合RAPTOR和GPT-4的使用将QuALITY基准测试的性能提高了20%。
研究方法
RAPTOR基于向量Embeddings递归地对文本块进行聚类,并生成这些聚类的文本摘要,从下向上构建树。聚集在一起的节点是兄弟姐妹;父节点包含该集群的文本摘要。具体的方法如下:
- 文本分割
- 文本向量表示
- 文本聚类
- 文本摘要
- 创建树节点
- 递归分聚类以及摘要
- 文档检索
文本切割
将检索语料库拆分为100个tokens的短的连续的chunk,类似于传统方法
保持句子完整,即使超过100个tokens,以保持连贯性
文本向量表示
嵌入文本块使用SBERT获得密集的向量表示
SBERT——一个基于BERT的编码器(multi-qa-mpnet-base-cos-v1)对这些文本进行向量化。这些块及其相应的SBERT向量形成了RAPTOR树结构的叶节点。
文本聚类
- 采用软聚类使用高斯混合模型和UMAP降维
- 更改UMAP参数以识别全局和本地集群
- 采用贝叶斯信息准则进行模型选择,确定最优聚类数量
论文聚类方法是使用软聚类(soft clustering),其中节点可以属于多个聚类,而不需要固定数量的聚类。
高斯混合模型(GMMs):GMMs假设数据点是从几个高斯分布的混合中生成的。给定N个文本段的集合,每个文本段表示为一个维密集向量嵌入,文本向量x给定其在第k个高斯分布中的可能性为:
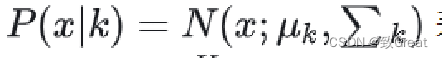
总概率分布是一个加权组合
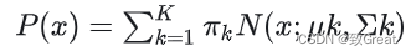
UMAP:Uniform Manifold Approximation and Projection (UMAP),一种用于降维的流形学习技术。向量的高维性对传统GMMs构成挑战,因为距离度量在高维空间中用于测量相似性时可能表现不佳。为了缓解这一点,本文使用了Uniform Manifold Approximation and Projection (UMAP),一种用于降维的流形学习技术。UMAP中的最近邻参数n_neighbors决定了保留局部和全局结构之间的平衡,作者用算法变化n_neighbors来创建一个层次化的聚类结构:它首先识别全局聚类,然后在这些全局聚类中进行局部聚类。
贝叶斯信息准则(BIC)
如果局部聚类的组合上下文超过了摘要模型的token阈值,本文的算法会在聚类内递归应用聚类,确保上下文保持在token阈值内。为了确定最优聚类数量,该算法使用贝叶斯信息准则(BIC)进行模型选择。
BIC不仅惩罚模型复杂性,还奖励拟合优度(goodness of fit)。
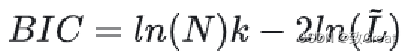
给定GMM的BIC是 ,其中N 是文本段(或数据点)的数量,k 是模型参数的数量,L 是模型的似然函数的最大化值。在GMM的上下文中,参数数量k是输入向量的维度和聚类数量的函数。
文本摘要
使用LLM来总结每个簇(cluster)中所有chunks
生成捕获关键信息的简明摘要
实验中使用gpt-3.5-turbo来生成摘要。
尽管摘要模型通常产生可靠的摘要,但是会有大约4%的摘要包含轻微的幻觉。这些幻觉没有传播到父节点,并且对问答任务没有可辨别的影响。
创建节点
聚类块+相应的摘要=新的树节点,生成的总结构成了树的节点,高层次的节点提供了更抽象的概括。
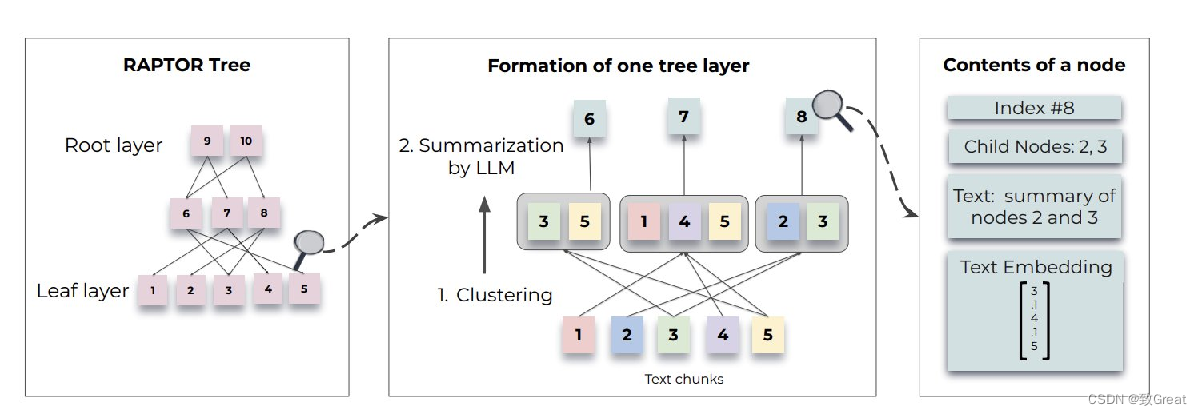
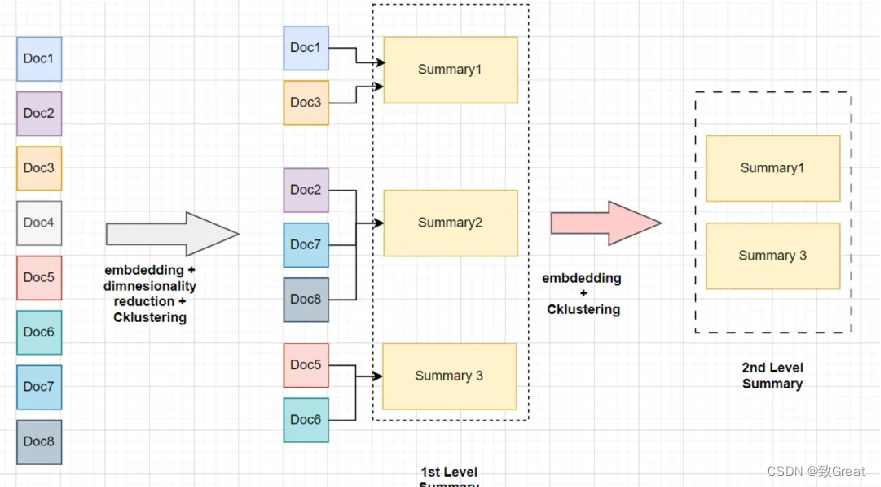
递归分聚类以及摘要
重复 steps 2-5: 重新嵌入摘要,集群节点,生成更高级别的摘要
从下向上形成多层树
直到聚类不可行
检索方法
两种方法:树遍历(自上而下一层一层)或折叠树(扁平视图)
对于每一个,计算查询和节点之间的余弦相似度,以找到最相关的
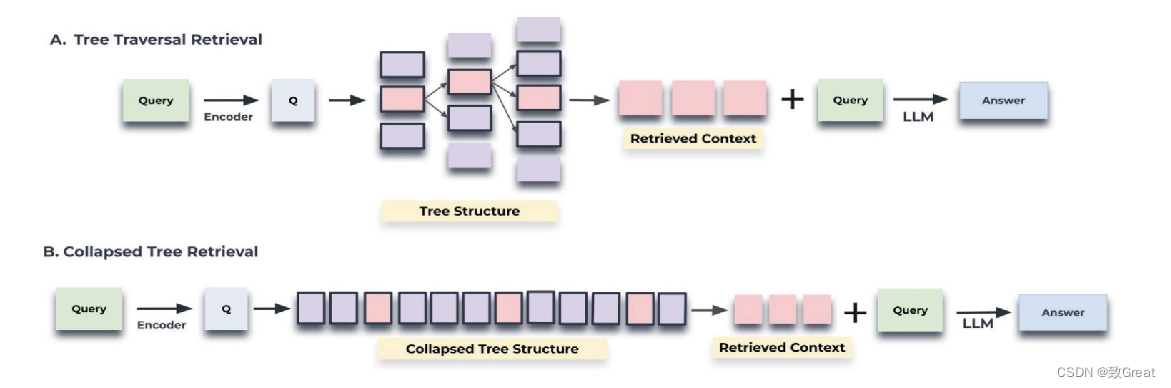
树遍历和折叠树检索机制的示意图。树遍历从树的根层开始,并基于与查询向量的余弦相似性检索顶部k(在这里,是top-1)个节点。在每个层级,它从上一层的top-k的子节点中检索top-k个节点。折叠树将树折叠为单个层级,并基于与查询向量的余弦相似性检索节点,直到达到阈值标记数为止。折叠树方法通过同时考虑树中的所有节点,提供了一种更简单的寻找相关信息的方式,这种方法将多层树压缩为单一层,使所有节点处于同一层级进行比较
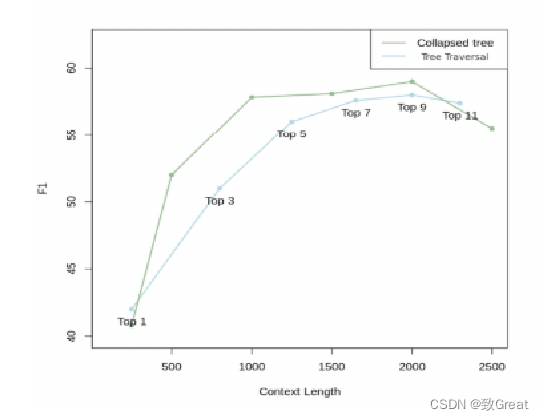
实验在QASPER数据集的20个story上测试了这两种方法(详见图3),树折叠方法表现更佳
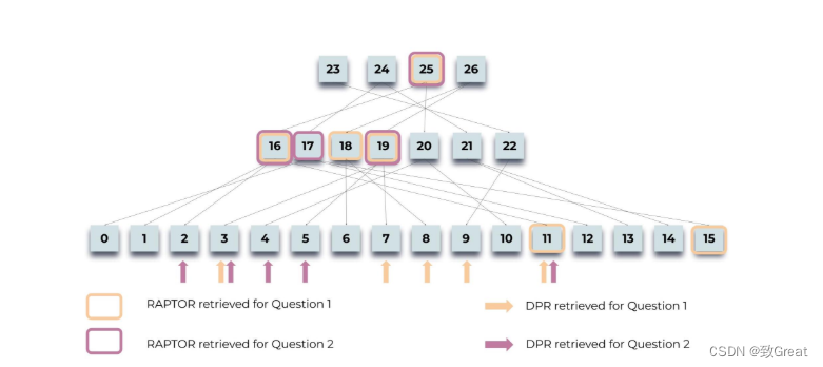
查询过程:展示RAPTOR如何检索关于灰姑娘故事的两个问题的信息:“故事的中心主题是什么?”和“灰姑娘是如何找到一个幸福结局的?”。突出显示的节点表示RAPTOR的选择,而箭头指向DPR的叶子节点。值得注意的是,RAPTOR的上下文通常包含由DPR检索的信息,直接或在较高层的摘要中。
实验结果
RAPTOR的性能通过三个问答数据集进行评估:NarrativeQA、QASPER和QuALITY。
- NarrativeQA包含基于书籍全文和电影剧本的问答对,要求对整个叙事有全面理解。
- QASPER涵盖1,585篇NLP论文中的5,049个问题,探索全文中嵌入的信息。
- QuALITY包含多项选择问题,每个问题都有约5,000个token的上下文段落,评估在中等长度文档上的检索系统性能。
各数据集使用标准的BLEU、ROUGE、METEOR和F1评估指标,并在QuALITY的HARD子集上报告准确率,该子集包含大多数人类注释者在限时设置中回答错误的问题。
实验结果表明,当RAPTOR与任何检索器结合使用时,在所有数据集上始终优于各自的检索器。
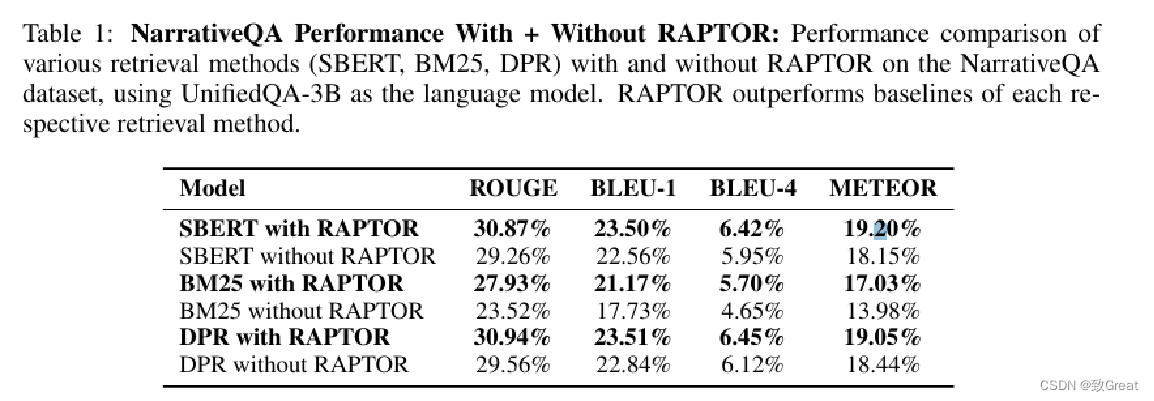
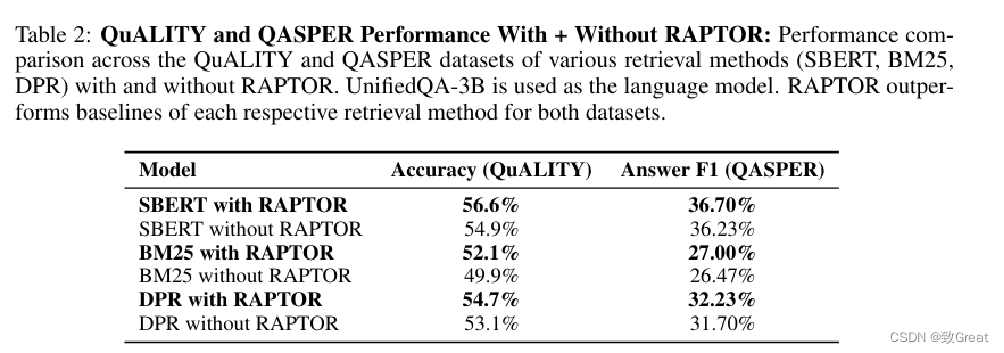
QASPER 数据集上基于不同语言模型(GPT-3、GPT-4、UnifiedQA 3B)及多种检索方法的 F-1 分数对比分析。
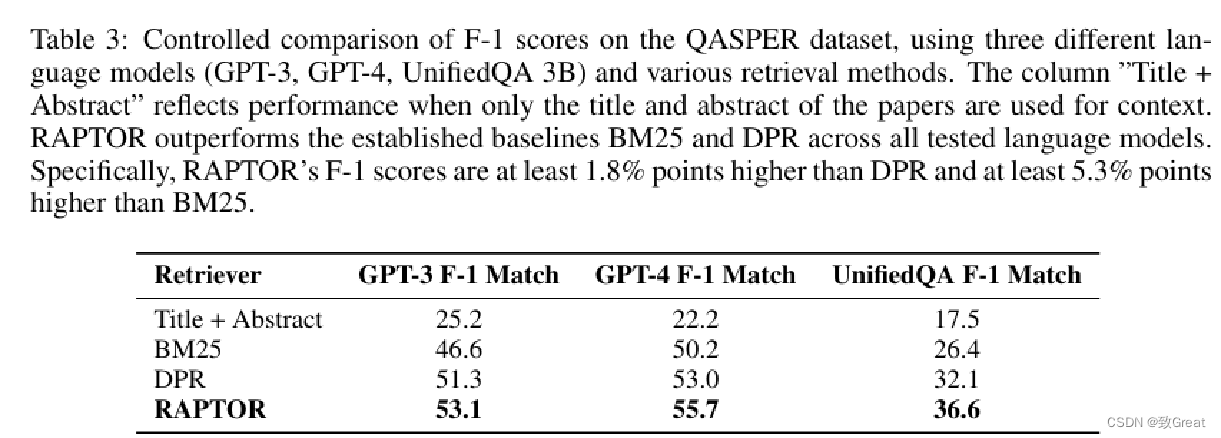
表 4: 在 QuALITY 开发数据集上,针对两种不同的语言模型(GPT-3、UnifiedQA 3B)使用不同检索方法的准确性对比。RAPTOR 在准确度上至少领先传统方法 BM25 和 DPR 2.0%。
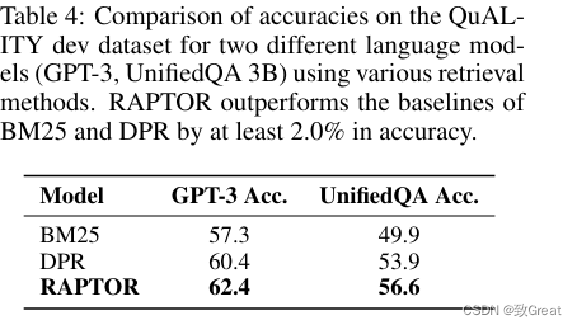
表 5: 在 QASPER 数据集上,各模型 F-1 匹配得分的对比结果。

RAPTOR 与 UnifiedQA 3B 搭配使用时,不仅超越了 BM25 和 DPR 等检索方法,还在 METEOR 指标中创下了新的最高水平
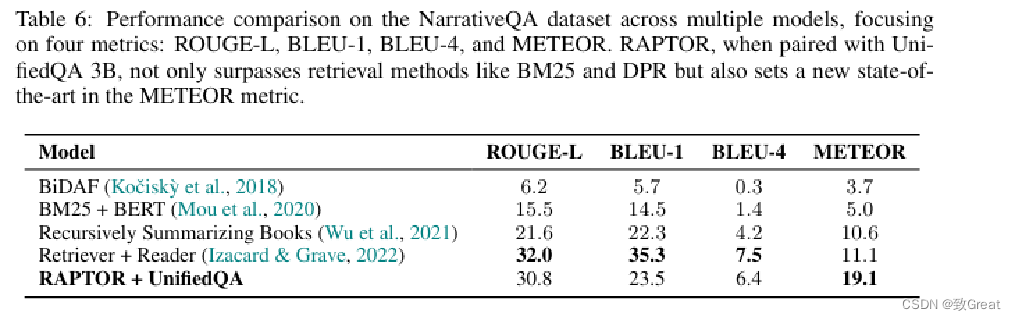
在需要复杂推理的问答任务上,结合RAPTOR和GPT-4的使用将QuALITY基准测试的性能提高了20%。
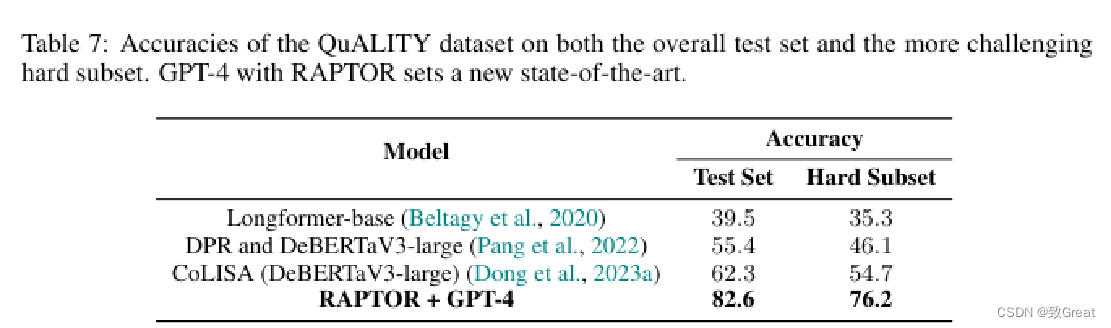
表 8:RAPTOR 在 QuALITY 数据集中查询 Story 1 的不同树层时的性能。列表示不同的起点(最高层),行表示查询的不同层数。

检索效率
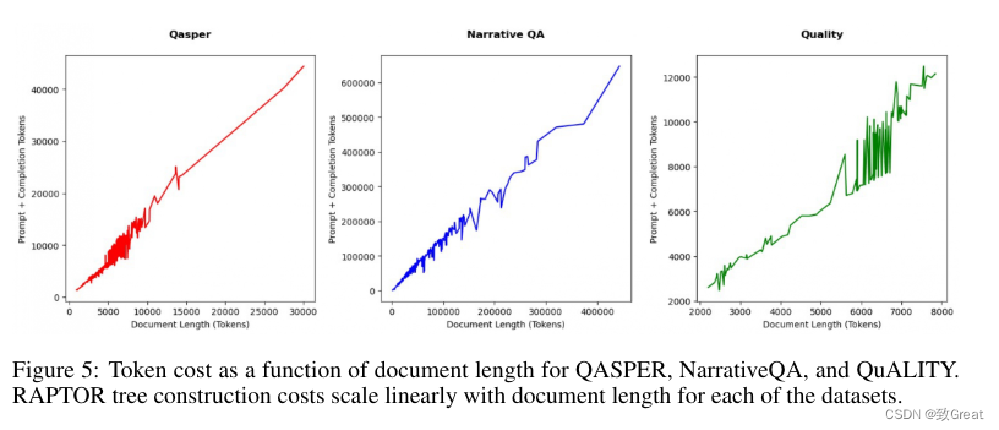
Token成本是 QASPER、NarrativeQA 和 QuALITY 文档长度的函数。
RAPTOR 树构建成本与每个数据集的文档长度成线性比例。
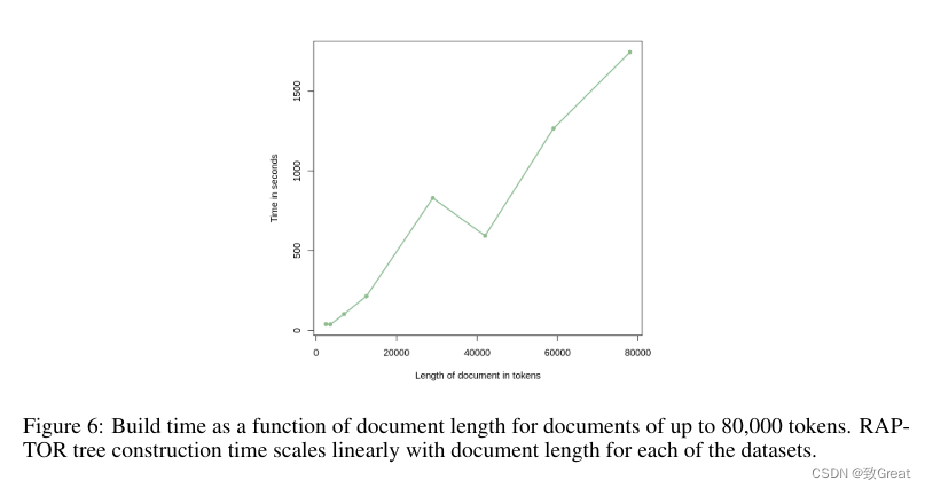
对于最多包含 80,000 个Tokens的文档,构建时间是文档长度的函数。对于每个数据集,RAPTOR 树的构建时间与文档长度成线性比例
聚类实验
表 9 显示了消融研究的结果。该消融研究的结果清楚地表明,与基于新近度的树方法相比,使用 RAPTOR 的聚类机制可以提高准确率。这一发现证实了我们的假设,即 RAPTOR 中的聚类策略在捕获同类内容进行总结方面更有效,从而提高了整体检索性能。

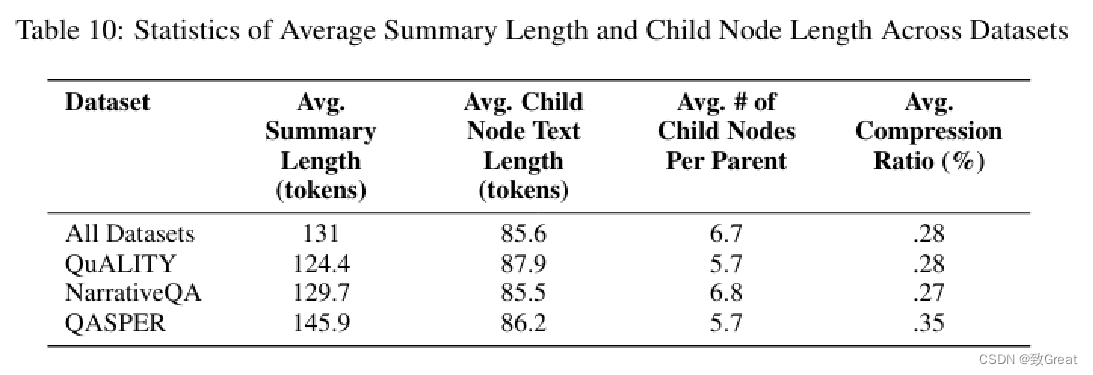
数据集统计和压缩率
表明压缩率为 72%。平均摘要长度为 131 个标记,平均子节点长度为 86 个标记。
摘要提示

RAPTOR方案的优点
- 在不同层次的多个级别上构建了语义表示并实施嵌入,提高了检索的召回能力
- 可以有效且高效的回答不同层次的问题,有的问题在低阶节点解决,有的则由高阶节点来完成
- 适合需要多个文档的理解才能回答的输入问题,因此对于综合性的问题有更好的支持
参考资料
- https://luxiangdong.com/2024/02/07/kym/
- https://developer.volcengine.com/articles/7370376932045062195
- https://mp.weixin.qq.com/s/KqJt4-Yhab5chi8YJglMiw
相关文章:
【RAG论文】文档树:如何提升长上下文、非连续文档、跨文档主题时的检索效果
RAPTOR Recursive Abstractive Processing for Tree-Organized RetrievalICLR 2024 Stanfordhttps://arxiv.org/pdf/2401.18059 RAPTOR(Recursive Abstractive Processing for Tree-Organized Retrieval)是一种创建新的检索增强型语言模型,它…...

【前端每日基础】day27——小程序开发
小程序开发详细介绍 基本概念 小程序:小程序是一种无需下载安装即可使用的应用。用户通过微信搜索或扫描二维码即可打开小程序。小程序具有触手可及、用完即走、体验良好的特点。 组成部分: WXML:用于描述页面的结构。 WXSS:用于…...

【C语言】指针速览
指针速览 指针1.野指针与空指针2. 空类型指针 void *3. 指针常量4. 常量指针5. 指向常量的指针常量6. 指针操作数组6.1 数组名作为函数参数 7. 多级指针8. 函数指针8.1 函数指针数组 最后 指针 指针就是内存的字节单元编号地址,指针变量就是存放地址的变量。 1.野…...

Java基础学习:深入解析Java中的位运算符
在Java中,位运算符用于对整数类型的值进行位运算。以下是Java中的位运算符: 位与(&):两位都为1时,结果为1,否则为0。 位或(|):两位中有1个为1,结果为1。 位非(~):位的反&#…...

9.Redis之list类型
list相当于链表、数据表 1.list类型基本介绍 列表中的元素是有序的"有序"的含义,要根据上下文区分~~有的时候,谈到有序,指的是"升序","降序”有的时候,谈到的有序,指的是, 顺序很关键~~如果把元素位置颠倒,顺序调换.此时得到的新的 List 和之前的 Li…...
Git 的安装和使用
一、Git 的下载和安装 目录 一、Git 的下载和安装 1. git 的下载 2. 安装 二、Git 的基本使用-操作本地仓库 1 初始化仓库 1)创建一个空目录 2)git init 2 把文件添加到版本库 1)创建文件 2)git add . 3)g…...
大模型时代的具身智能系列专题(五)
stanford宋舒然团队 宋舒然是斯坦福大学的助理教授。在此之前,他曾是哥伦比亚大学的助理教授,是Columbia Artificial Intelligence and Robotics Lab的负责人。他的研究聚焦于计算机视觉和机器人技术。本科毕业于香港科技大学。 主题相关作品 diffusio…...
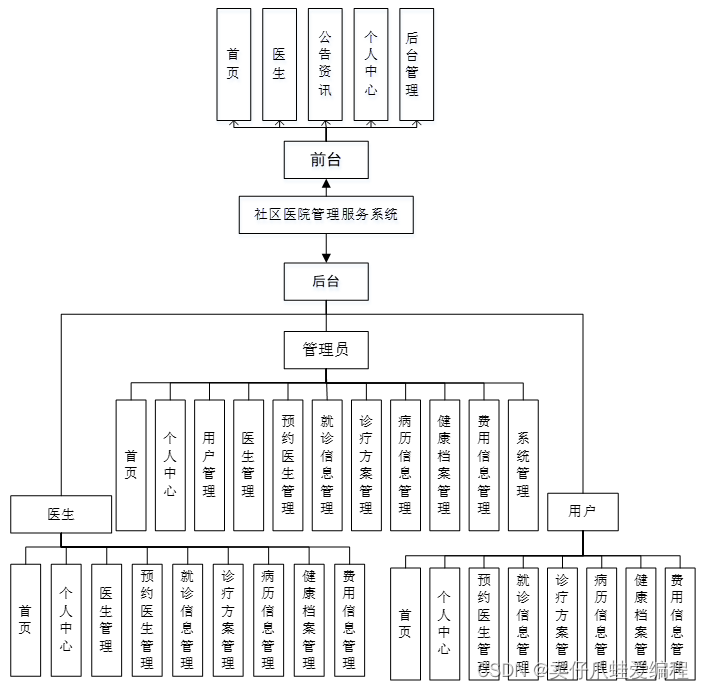
基于springboot+vue的社区医院管理服务系统
开发语言:Java框架:springbootJDK版本:JDK1.8服务器:tomcat7数据库:mysql 5.7(一定要5.7版本)数据库工具:Navicat11开发软件:eclipse/myeclipse/ideaMaven包:…...

车载电子电器架构 —— 智能座舱标准化意义
车载电子电器架构 —— 智能座舱标准化意义 我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 屏蔽力是信息过载时代一个人的特殊竞争力,任何消…...

Compose在xml中使用滑动冲突处理
一、背景 在现有Android项目中使用Compose可能存在滑动冲突问题,例如 SmartRefreshLayoutCoordinatorLayoutComposeView(ComposeView这里又是一个LazyColumn) 二、解决方案 官方介绍:https://developer.android.google.cn/develop/ui/compose/touch-inp…...
微信网页版登录插件v1.1.1
说到如今的微信客户端,大家肯定会有很多提不完的意见或者建议。比如这几年体积越来越大,如果使用频率比较高,那占用空间就更离谱了。系统迷见过很多人电脑C盘空间爆满,都是由于微信PC版造成的。 而且,它还加了很多乱七…...

华为实训课笔记 2024
华为实训 5/205/215/225/235/275/28 5/20 5/21 5/22 5/23 5/27 5/28...

HTML静态网页成品作业(HTML+CSS)——宠物狗介绍网页(3个页面)
🎉不定期分享源码,关注不丢失哦 文章目录 一、作品介绍二、作品演示三、代码目录四、网站代码HTML部分代码 五、源码获取 一、作品介绍 🏷️本套采用HTMLCSS,未使用Javacsript代码,共有3个页面。 二、作品演示 三、代…...
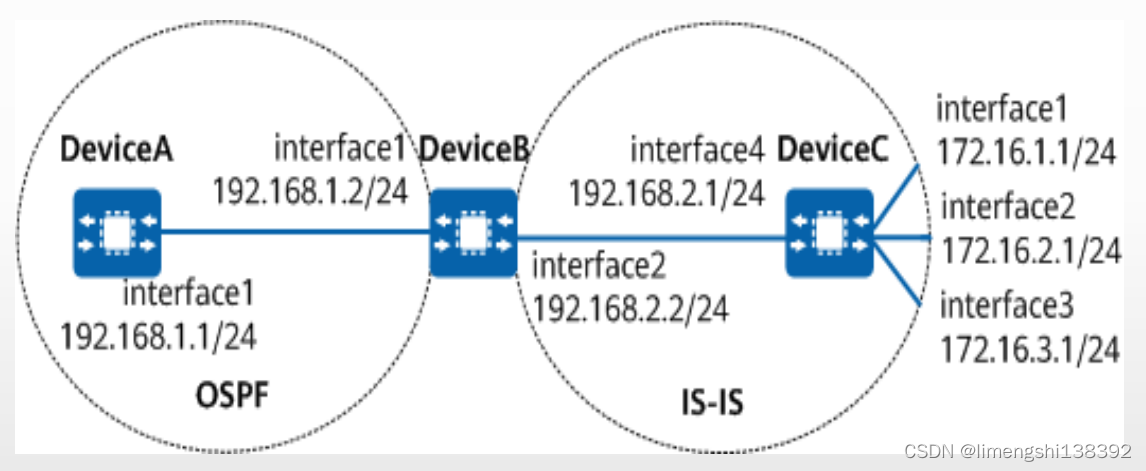
网络模型-路由策略
一、路由策略 路由策略(Routing Policy)作用于路由,主要实现了路由过滤和路由属性设置等功能,它通过改变路由属性(包括可达性)来改变网络流量所经过的路径。目的:设备在发布、接收和引入路由信息时,根据实际组网需要实施一些策略,…...
-锁和事务模型)
【MySQL精通之路】InnoDB(7)-锁和事务模型
1.InnoDB锁 【MySQL精通之路】InnoDB(7)-锁和事务模型(1)-锁-CSDN博客 2.InnoDB事务模型 【MySQL精通之路】InnoDB(7)-锁和事务模型(2)-事务模型-CSDN博客 3.InnoDB中不同SQL语句设置的锁 4.幻影行 5.InnoDB中的死锁 5.1InnoDB死锁示例 5.2死锁检测 …...
深度学习创新点不大但有效果,可以发论文吗?
深度学习中创新点比较小,但有效果,可以发论文吗?当然可以发,但如果想让编辑和审稿人眼前一亮,投中更高区位的论文,写作永远都是重要的。 那么怎样“讲故事”才能让论文更有吸引力?我总结了三点…...

【ARM Cache 系列文章 7.1 – ARMv8/v9 MMU 页表配置详细介绍 02 】
文章目录 Translation table descriptorTable descriptor format页面粒度和地址长度粒度(Granules)48位和52位地址TCR_ELx.DSVTCR_EL2.DSFEAT_LPA块描述符|页描述符紧接上篇文章【ARM Cache 系列文章 7 – ARMv8/v9 MMU 页表配置 01 】 Translation table descriptor</...

Mysql搭建主从同步,docker方式(一主一从)
服务器:两台Centos9 用Docker搭建主从 使用Docker拉取MySQL镜像 确保两台服务器都安装好了docker 安装docker请查看:Centos安装docker 1.两台服务器都先拉取mysql镜像 docker pull mysql 2.我这里是在 /opt/docker/mysql 下创建mysql的文件夹用来存…...
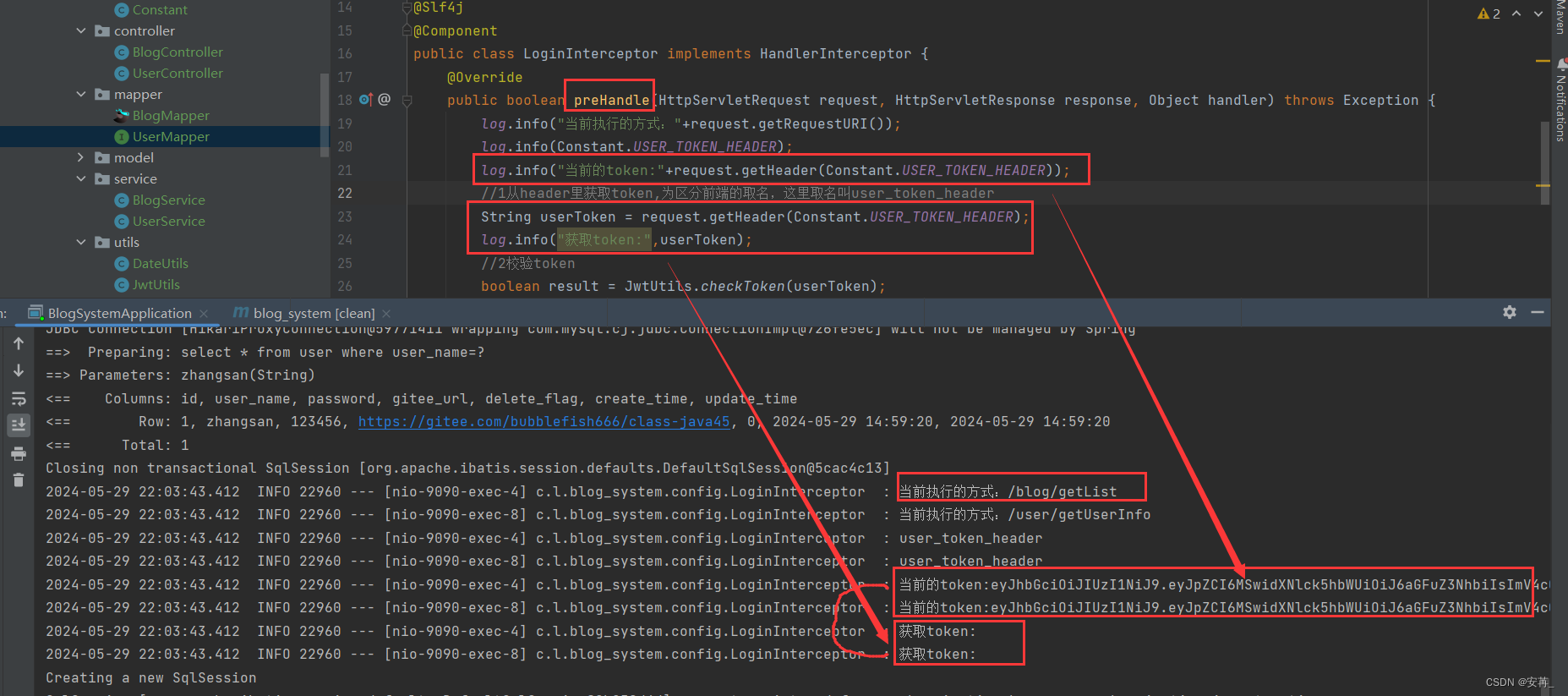
【已解决】使用token登录机制,token获取不到,blog_list.html界面加载不出来
Bug产生 今天使用token完成用户登录信息的存储的时候被卡了大半天。 因为登录的功能写的已经很多了,所以今天就没有写一点验一点,而是在写完获取博客列表功功能,验证完它的后端后,了解完令牌的基本使用以及Jwt的基本使用方式——…...

【Linux 网络编程】网络的基础知识详解!
文章目录 1. 计算机网络背景2. 认识 "协议" 1. 计算机网络背景 网络互联: 多台计算机连接在一起, 完成数据共享; 🍎局域网(LAN----Local Area Network): 计算机数量更多了, 通过交换机和路由器连接。 🍎 广域网WAN: 将…...

MCP 会不会成为 AI 系统的“新中间件”?
一、为什么人们开始把 MCP 和“中间件”类比?(Why Do People Start Comparing MCP to “Middleware”?)1、MCP 出现的位置非常“熟悉”(MCP Appears in a Very Familiar Position)当人们第一次在企业架构中引入 MCP 时…...

【以太网帧格式】
以太网帧格式一、顺序二、分析一、顺序 前导码 | 帧开始定界符 | 目的MAC | 源MAC | 类型(长度) | 数据字段 | 帧校验序列FCS3 (以太网帧最小帧长:64 字节,最大帧长:1518 字节。) 二、分析 1…...

Allegro 17.4约束管理器实战:从基础规则到高速PCB设计优化
1. Allegro约束管理器入门指南 刚接触Allegro 17.4的工程师经常会问:为什么我的PCB设计总是出现DRC报错?为什么高速信号总是不稳定?其实问题的关键往往在于约束管理器的使用。作为Cadence Allegro的核心功能模块,约束管理器就像PC…...

突破方舟生存进化技术壁垒的智能管理工具
突破方舟生存进化技术壁垒的智能管理工具 【免费下载链接】TEKLauncher Launcher for ARK: Survival Evolved 项目地址: https://gitcode.com/gh_mirrors/te/TEKLauncher 你是否曾因MOD安装顺序错误导致游戏频繁崩溃?是否在搭建私人服务器时被端口配置弄得晕…...

Java调用C/C++/Rust的5种方式:FFI vs JNI vs JNA vs JNR vs Panama——2024权威对比评测
第一章:Java外部函数接口概述与技术演进脉络Java外部函数接口(Foreign Function & Memory API),即Project Panama的核心成果,是Java平台为高效、安全地与本地代码(如C/C库)及非堆内存交互而…...

DeerFlow免费开源:字节跳动出品,个人研究者的强大AI工具
DeerFlow免费开源:字节跳动出品,个人研究者的强大AI工具 1. 项目概述 DeerFlow是由字节跳动公司开源的一款深度研究辅助工具,基于LangStack技术框架开发。这个项目通过整合语言模型、网络搜索和Python代码执行等能力,为个人研究…...

太阳能家用电池电源市场:预计到2032年将达到98.8亿美元
在全球能源转型与地缘政治风险交织的背景下,家庭能源自主性需求正催生一个高速增长的细分市场。据 恒州诚思(YH Research) 《全球太阳能家用电池电源市场报告2026-2032》预测,2032年该市场规模将达98.8亿美元,2026-203…...

告别重复造轮子:用快马ai一键生成arm7标准外设驱动,效率提升50%
作为一名嵌入式开发者,我经常需要和ARM7这类微控制器打交道。每次新项目启动,最头疼的就是那些重复性的外设驱动编写工作——尤其是定时器中断这种基础功能,虽然逻辑简单,但写起来特别耗时。最近发现InsCode(快马)平台的AI生成功能…...

为什么自动驾驶地铁离不开形式化方法?从法国B方法到上海15号线的实战解析
数学如何为自动驾驶地铁筑起安全屏障:从B方法到工业级验证的深度实践 当一列无人驾驶的地铁以80公里时速穿越隧道时,系统每毫秒需要处理200传感器信号、执行30余项控制决策。巴黎地铁14号线自1998年开通以来保持零重大事故记录,上海15号线全自…...

突破平台限制:res-downloader高效捕获网络资源的全方位解决方案
突破平台限制:res-downloader高效捕获网络资源的全方位解决方案 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader 在…...