十种常用数据分析模型
1-线性回归(Linear Regression)
场景:预测商品销售额
- 优点:简单易用,结果易于解释
- 缺点:假设线性关系,容易受到异常值影响
- 概念:建立自变量和因变量之间线性关系的模型。
- 公式:[ y = b_0 + b_1x_1 + b_2x_2 + ... + b_nx_n ]
代码示例:
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error# 假设我们有一个包含商品销售数据的DataFrame
data = pd.DataFrame({'item_sku_id': [100000350860, 100000350861, 100000350862, 100000350863],'before_prefr_unit_price': [1499.0, 1599.0, 1399.0, 1299.0],'after_prefr_unit_price': [1099.0, 1199.0, 999.0, 899.0],'sale_qtty': [50, 60, 55, 65]
})# 特征和目标变量
X = data[['before_prefr_unit_price', 'after_prefr_unit_price']]
y = data['sale_qtty']# 分割数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 训练模型
model = LinearRegression()
model.fit(X_train, y_train)# 预测
y_pred = model.predict(X_test)# 评估模型
mse = mean_squared_error(y_test, y_pred)
print(f'Mean Squared Error: {mse}')结果与判断:
通过模型预测销售量,评估误差可以帮助改进定价策略。
2-逻辑回归(Logistic Regression)
场景:预测订单是否有效
- 优点:适用于二分类问题,解释性强
- 缺点:不适用于多分类或连续型结果预测
- 概念:用于处理二分类问题,输出值在0到1之间。
- 公式:[ P(Y=1|X) = \frac{1}{1 + e^{-(b_0 + b_1x_1 + b_2x_2 + ... + b_nx_n)}} ]
代码示例:
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, confusion_matrix# 数据
data = pd.DataFrame({'user_actual_pay_amount': [976.0, 978.99, 979.0, 800.0, 850.0],'total_offer_amount': [400.0, 400.0, 400.0, 200.0, 250.0],'sale_ord_valid_flag': [1, 1, 1, 0, 0]
})X = data[['user_actual_pay_amount', 'total_offer_amount']]
y = data['sale_ord_valid_flag']# 分割数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 训练模型
model = LogisticRegression()
model.fit(X_train, y_train)# 预测
y_pred = model.predict(X_test)# 评估模型
accuracy = accuracy_score(y_test, y_pred)
cm = confusion_matrix(y_test, y_pred)
print(f'Accuracy: {accuracy}')
print(f'Confusion Matrix: \\n{cm}')结果与判断:
通过预测订单有效性,可以优化订单审核流程,减少无效订单的产生。
3-决策树(Decision Tree)
场景:根据用户行为特征分类用户等级
- 优点:易于理解和解释,可以处理非线性关系
- 缺点:容易过拟合
- 概念:通过一系列规则对数据进行分类或预测。
- 公式:决策树根据特征值进行分裂,并构建一棵树状结构来表示决策过程。
代码示例:
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import classification_report# 数据
data = pd.DataFrame({'user_actual_pay_amount': [976.0, 978.99, 979.0, 800.0, 850.0, 900.0],'total_offer_amount': [400.0, 400.0, 400.0, 200.0, 250.0, 300.0],'user_lv_cd': [10, 10, 10, 0, 0, 1]
})X = data[['user_actual_pay_amount', 'total_offer_amount']]
y = data['user_lv_cd']# 分割数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 训练模型
model = DecisionTreeClassifier()
model.fit(X_train, y_train)# 预测
y_pred = model.predict(X_test)# 评估模型
report = classification_report(y_test, y_pred)
print(f'Classification Report: \\n{report}')结果与判断:
分类用户等级,帮助精准营销和个性化推荐。
4-随机森林(Random Forest)
场景:预测用户实际支付金额
- 优点:降低过拟合,处理高维数据
- 缺点:训练时间长,结果不易解释
- 概念:由多个决策树组成的集成学习模型。
- 公式:通过投票方式聚合多个决策树的预测结果来提高预测准确度。
代码示例:
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import r2_score# 数据
data = pd.DataFrame({'item_sku_id': [100000350860, 100000350861, 100000350862, 100000350863],'before_prefr_unit_price': [1499.0, 1599.0, 1399.0, 1299.0],'after_prefr_unit_price': [1099.0, 1199.0, 999.0, 899.0],'user_actual_pay_amount': [976.0, 978.99, 979.0, 875.0]
})X = data[['before_prefr_unit_price', 'after_prefr_unit_price']]
y = data['user_actual_pay_amount']# 分割数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 训练模型
model = RandomForestRegressor(n_estimators=100)
model.fit(X_train, y_train)# 预测
y_pred = model.predict(X_test)# 评估模型
r2 = r2_score(y_test, y_pred)
print(f'R2 Score: {r2}')结果与判断:
预测用户支付金额,优化促销策略和定价。
5-支持向量机(SVM)
场景:分类订单是否取消
- 优点:有效处理高维数据,适合小样本
- 缺点:训练时间长,参数调优复杂
- 概念:用于分类和回归的监督学习模型。
- 公式:通过找到最大边距超平面来划分不同类别数据点
代码示例:
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score# 数据
data = pd.DataFrame({'user_actual_pay_amount': [976.0, 978.99, 979.0, 800.0, 850.0, 900.0],'total_offer_amount': [400.0, 400.0, 400.0, 200.0, 250.0, 300.0],'cancel_flag': [0, 0, 0, 1, 1, 1]
})X = data[['user_actual_pay_amount', 'total_offer_amount']]
y = data['cancel_flag']# 分割数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 训练模型
model = SVC()
model.fit(X_train, y_train)# 预测
y_pred = model.predict(X_test)# 评估模型
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy}')结果与判断:
预测订单是否取消,优化库存管理。
6-K-均值聚类(K-Means Clustering)
场景:用户行为数据聚类分析
- 优点:易于实现和解释
- 缺点:需要预先定义聚类数,不适用于非球形数据
- 概念:将数据点划分为K个类别的无监督学习算法。
- 公式:最小化每个聚类中数据点与该聚类中心的距离的平方和。
代码示例:
from sklearn.cluster import KMeans# 数据
data = pd.DataFrame({'user_actual_pay_amount': [976.0, 978.99, 979.0, 800.0, 850.0, 900.0],'total_offer_amount': [400.0, 400.0, 400.0, 200.0, 250.0, 300.0]
})X = data[['user_actual_pay_amount', 'total_offer_amount']]# 训练模型
kmeans = KMeans(n_clusters=2)
kmeans.fit(X)# 聚类结果
data['cluster'] = kmeans.labels_
print(data)
结果与判断:
聚类用户行为数据,识别用户群体,制定个性化营销策略。
7-主成分分析(PCA)
场景:降维处理用户行为数据
- 优点:降低数据维度,去除冗余信息
- 缺点:解释性差,可能丢失有用信息
- 概念:降维技术,用于发现数据中的主要特征。
- 公式:通过线性变换将原始数据映射到低维空间,使得数据在新空间中的方差最大化。
代码示例:
from sklearn.decomposition import PCA# 数据
data = pd.DataFrame({'user_actual_pay_amount': [976.0, 978.99, 979.0, 800.0, 850.0, 900.0],'total_offer_amount': [400.0, 400.0, 400.0, 200.0, 250.0, 300.0]
})X = data[['user_actual_pay_amount', 'total_offer_amount']]# 降维处理
pca = PCA(n_components=1)
principalComponents = pca.fit_transform(X)
data['principal_component'] = principalComponents
print(data)结果与判断:
降维处理后,数据可视化更容易,识别主成分,简化模型。
8-时间序列分析(Time Series Analysis)
场景:销售数据时间序列预测
- 优点:适用于时间相关数据,预测未来趋势
- 缺点:需要时间顺序数据,复杂性高
- 概念:研究时间序列数据的模式、趋势和周期性,并用于预测未来值。
- 公式:时间序列模型可以包括自回归模型(AR)、移动平均模型(MA)、自回归移动平均模型(ARMA)、自回归积分移动平均模型(ARIMA)等。
代码示例:
import pandas as pd
from statsmodels.tsa.arima.model import ARIMA# 数据
data = pd.Series([976, 978.99, 979, 800, 850, 900], index=pd.date_range(start='2020-01-01', periods=6, freq='M'))# 训练模型
model = ARIMA(data, order=(1, 1, 1))
model_fit = model.fit()# 预测
forecast = model_fit.forecast(steps=3)[0]
print(f'Forecast: {forecast}')结果与判断:
预测未来销售趋势,帮助库存管理和销售计划。
9-关联规则分析(Association Rule Learning)
场景:购物篮分析
- 优点:发现项间关联规则,适合市场篮子分析
- 缺点:计算复杂度高,规则解释性差
- 概念:用于发现数据集中的物品之间的关联关系,常用于购物篮分析和市场篮分析。
- 公式:关联规则通常表示为“A ➞ B”的形式,其中A和B是物品集合,相关性通过支持度和置信度来衡量。
代码示例:
from mlxtend.frequent_patterns import apriori, association_rules# 数据
data = pd.DataFrame({'milk': [1, 1, 0, 0, 1],'bread': [1, 1, 1, 0, 1],'butter': [0, 1, 1, 0, 1]
})# 频繁项集
frequent_itemsets = apriori(data, min_support=0.6, use_colnames=True)
# 关联规则
rules = association_rules(frequent_itemsets, metric="lift", min_threshold=1)
print(rules)
结果与判断:
发现商品间的关联规则,优化商品组合销售和促销策略。
10-XGBoost
场景:提升模型的预测精度
- 优点:处理大规模数据,预测精度高
- 缺点:模型复杂,计算资源消耗大
- 概念:集成学习方法,通过训练多个弱分类器并加权组合得到一个强分类器。
- 公式:使用加权投票来提高分类准确率,弱分类器的误差率会影响其权重。
代码示例:
import xgboost as xgb
from sklearn.metrics import mean_squared_error# 数据
data = pd.DataFrame({'item_sku_id': [100000350860, 100000350861, 100000350862, 100000350863],'before_prefr_unit_price': [1499.0, 1599.0, 1399.0, 1299.0],'after_prefr_unit_price': [1099.0, 1199.0, 999.0, 899.0],'user_actual_pay_amount': [976.0, 978.99, 979.0, 875.0]
})X = data[['before_prefr_unit_price', 'after_prefr_unit_price']]
y = data['user_actual_pay_amount']# 分割数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 训练模型
model = xgb.XGBRegressor(objective ='reg:squarederror')
model.fit(X_train, y_train)# 预测
y_pred = model.predict(X_test)# 评估模型
mse = mean_squared_error(y_test, y_pred)
print(f'Mean Squared Error: {mse}')
结果与判断:
通过提升模型的预测精度,优化业务决策和营销策略。
(交个朋友/技术接单/ai办公/性价比资源)

相关文章:
十种常用数据分析模型
1-线性回归(Linear Regression) 场景:预测商品销售额 优点:简单易用,结果易于解释缺点:假设线性关系,容易受到异常值影响概念:建立自变量和因变量之间线性关系的模型。公式&#x…...

salesforce 公式字段 判断一个字段是否在某个多选列表中
在 Salesforce 中,你可以使用公式字段来判断一个字段的值是否在一个多选列表中。这通常涉及使用包含特定值的函数和一些字符串操作。以下是一个常见的方法: 假设你有一个多选列表字段 Multi_Select_Field__c,你想检查这个字段是否包含某个值…...
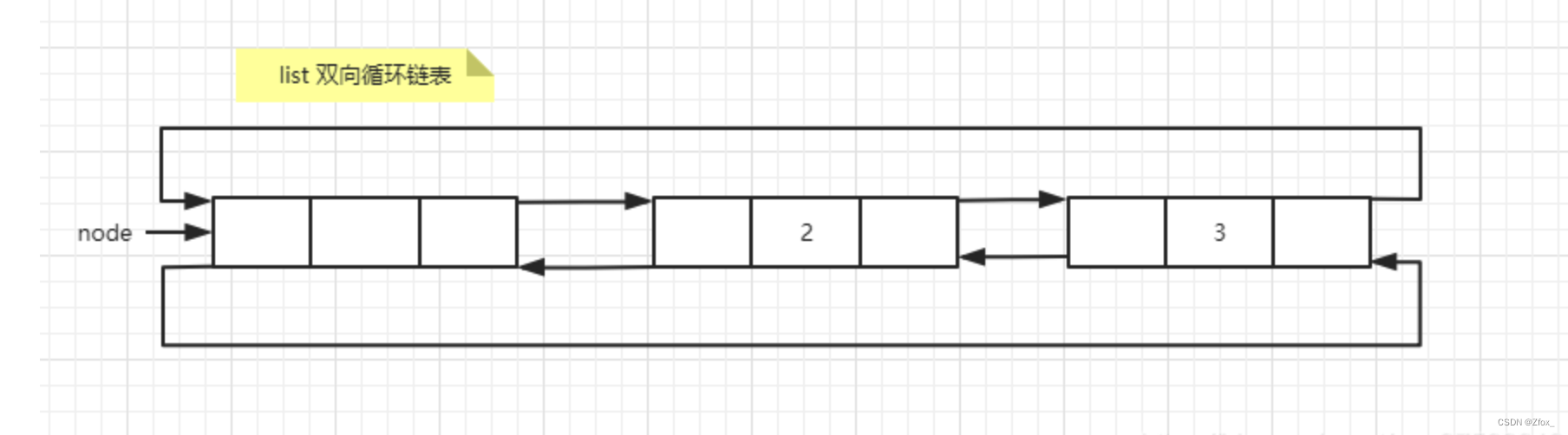
C++STL容器系列(三)list的详细用法和底层实现
目录 一:介绍二:list的创建和方法创建list方法 三:list的具体用法3.1 push_back、pop_back、push_front、pop_front3.2 insert() 和 erase()3.3 splice 函数 四:list容器底层实现4.1 list 容器节点结构5.2 list容器迭代器的底层实…...

IEEE Latex模版踩雷避坑指南
参考文献 原Latex模版 \begin{thebibliography}{1} \bibliographystyle{IEEEtran}\bibitem{ref1} {\it{Mathematics Into Type}}. American Mathematical Society. [Online]. Available: https://www.ams.org/arc/styleguide/mit-2.pdf\bibitem{ref2} T. W. Chaundy, P. R. Ba…...
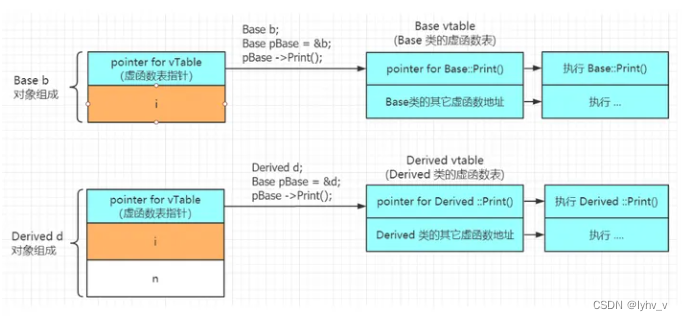
【C++】类与对象——多态详解
目录 一、多态的定义 二、重载、覆盖(重写)、隐藏(重定义)的对比 三、析构函数重写 四、C11 override 和 final 1. final 2. override 五、抽象类 六、多态的原理 一、多态的定义 多态是在不同继承关系的类对象,去调用同一函数,产生了不同的行为…...

WordPress建网站公司 建易WordPress建站
建易WordPress建网站公司是一家专业从事WordPress网站建设、网站维护、网站托管、运营推广和搜索引擎优化(SEO)等服务的公司。建易WordPress建网站公司提供多种服务,包括模板建站和定制网站,并且明码标价,价格透明,竭诚为全国各地…...

MySQL正则替换整个单词
\b 是正则表达式规定的一个特殊代码(好吧,某些人叫它元字符,metacharacter),代表着单词的开头或结尾,也就是单词的分界处。虽然通常英文的单词是由空格,标点符号或者换行来分隔的,但…...

Java设计模式:享元模式实现高效对象共享与内存优化(十一)
码到三十五 : 个人主页 目录 一、引言二、享元设计模式的概念1. 对象状态的划分2. 共享机制 三、享元设计模式的组成四、享元设计模式的工作原理五、享元模式的使用六、享元设计模式的优点和适用场景结语 [参见]: Java设计模式:核心概述&…...

景源畅信电商:抖音开店步骤是什么?
随着社交媒体的兴起,抖音已经成为一个不可忽视的电商平台。许多人都希望通过抖音开店来实现自己的创业梦想。那么,抖音开店的具体步骤是什么呢?接下来,我们将详细阐述这一问题。 一、明确回答问题抖音开店的步骤主要包括:注册账号…...
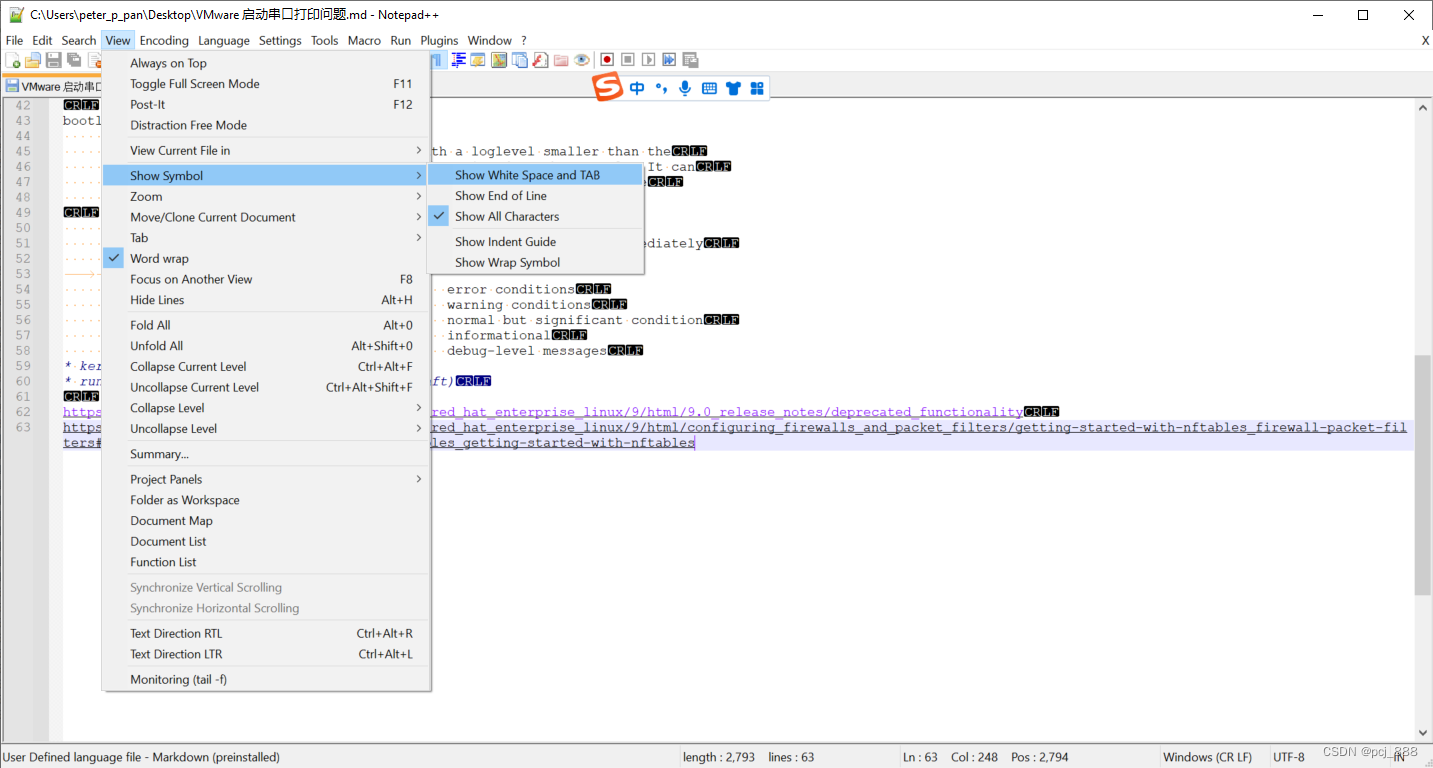
Notepad++不显示CRLF的方法
View -> Show Symbol -> 去掉勾选 Show All Characters...

前端开发工程师——AngularJS
一.表达式和语句 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta http-equiv"X-UA-Compatible" content"IEedge"><meta name"viewport" content"widthdevice-w…...

【AI算法岗面试八股面经【超全整理】——概率论】
AI算法岗面试八股面经【超全整理】 概率论信息论机器学习CVNLP 目录 1、古典概型、几何概型2、条件概率、全概率公式、贝叶斯公式3、先验概率、后验概率4、离散型随机变量的常见分布5、连续型随机变量的常见分别6、数学期望、方差7、协方差、相关系数8、独立、互斥、不相关9.大…...
vue3 使用vant
使用前提: vite创建的vue3项目 vanthttps://vant-ui.github.io/vant/#/zh-CN/home npm i vant 引入样式: main.js import vant/lib/index.css vant封装 import { showLoadingToast,closeToast,showDialog,showConfirmDialog } from vant;export func…...

网络请求客户端WebClient的使用
在 Spring 5 之前,如果我们想要调用其他系统提供的 HTTP 服务,通常可以使用 Spring 提供的 RestTemplate 来访问,不过由于 RestTemplate 是 Spring 3 中引入的同步阻塞式 HTTP 客户端,因此存在一定性能瓶颈。根据 Spring 官方文档…...
unity制作app(9)--拍照 相册 上传照片
1.传输照片(任何较大的数据)都需要扩展服务器的内存空间。 2.还需要base64编码 2.1客户端发送位置的编码 2.2服务器接收部分的代码...
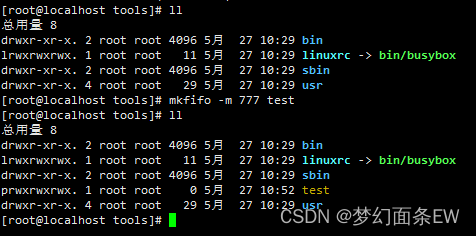
【busybox记录】【shell指令】mkfifo
目录 内容来源: 【GUN】【mkfifo】指令介绍 【busybox】【mkfifo】指令介绍 【linux】【mkfifo】指令介绍 使用示例: 创建管道文件 - 创建的时候同时指定文件权限 常用组合指令: 指令不常用/组合用法还需继续挖掘: 内容来…...

使用Jmeter进行性能测试的基本操作方法
🔥 交流讨论:欢迎加入我们一起学习! 🔥 资源分享:耗时200小时精选的「软件测试」资料包 🔥 教程推荐:火遍全网的《软件测试》教程 📢欢迎点赞 👍 收藏 ⭐留言 …...

Linux学习笔记(epoll,IO多路复用)
Linux learning note 1、epoll的使用场景2、epoll的使用方法和内部原理2.1、创建epoll2.2、使用epoll监听和处理事件 3、示例 1、epoll的使用场景 epoll的英文全称是extend poll,顾名思义是poll的升级版。常见的IO复用技术有select,poll,epo…...

STM32定时器及输出PWM完成呼吸灯
文章目录 一、STM32定时器原理1、基本定时器2、通用定时器(1)时钟源(2)预分频器PSC(3)计数器CNT(4)自动装载寄存器ARR 3、高级定时器 二、PWM工作原理三、控制LED以2s的频率周期性地…...

海外仓管理系统费用解析:如何选择高性价比的海外仓系统
海外仓作为链接国内商家和海外市场的重要环节,其重要性自然是不言而喻的。 对于众多中小型海外仓来说,如何在保证服务质量的同时降低运营成本,就成了大家关注的焦点。今天我们就从海外仓管理系统的费用这个角度,来帮助大家分析一…...
深度探秘:以一次文件打开操作为例)
Linux内核安全钩子(Hook)深度探秘:以一次文件打开操作为例
Linux内核安全钩子(Hook)深度探秘:以一次文件打开操作为例 当我们在终端输入cat /etc/shadow时,系统背后究竟发生了什么?这个看似简单的操作,实际上触发了一系列精妙的安全检查机制。本文将带您深入Linux内…...
!STM32F407启动配置避坑指南:堆栈、时钟与BOOT模式)
别只盯着main()!STM32F407启动配置避坑指南:堆栈、时钟与BOOT模式
STM32F407启动配置实战:堆栈优化、时钟校准与BOOT模式避坑手册 引言 当你的STM32项目从简单的LED闪烁升级到复杂多任务系统时,是否遇到过这些"灵异现象":程序运行几天后突然死机、RTOS任务切换时触发HardFault、使用malloc分配内存…...
)
告别离线语音包:用Google Cloud Text-to-Speech API为你的App注入更自然的人声(附Android集成代码)
云端语音合成技术实战:为移动应用注入自然语音的完整方案 在移动应用开发中,语音合成(TTS)技术正成为提升用户体验的关键要素。传统离线语音引擎往往面临发音生硬、语调单一和语种支持有限的问题,而现代云端语音合成API则提供了接近真人、富有…...

构建现代化网络拓扑可视化的完整解决方案
构建现代化网络拓扑可视化的完整解决方案 【免费下载链接】easy-topo vuesvgelement-ui 快捷画出网络拓扑图 项目地址: https://gitcode.com/gh_mirrors/ea/easy-topo 在数字化转型浪潮中,网络架构日益复杂,传统的手绘拓扑图已无法满足现代运维需…...

2026最权威的六大AI写作工具推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 在学术研究链路里,DeepSeek能够为论文撰写给予全流程辅助支持,从梳理…...

工程师创意竞赛全流程策划:从社区激活到公平投票的实战指南
1. 项目概述:一场别开生面的工程师创意竞赛又到了二月底,这意味着我们年初启动的那个“独轮车”图片配文竞赛,终于要进入最激动人心的投票环节了。我记得很清楚,那是2012年2月初,编辑部觉得冬天太沉闷,想找…...

OpenAEON:从AI Agent到自主认知引擎的架构解析与实战
1. 项目概述:从“智能助手”到“自主认知引擎”的跃迁 如果你和我一样,在AI Agent领域摸爬滚打了几年,从早期的简单聊天机器人框架,到后来的工具调用(Function Calling)和RAG(检索增强生成&…...

音频算法调试利器:用Android App实时绘制EQ/DRC曲线,告别Matlab依赖
移动端音频算法调试革命:Android实时EQ/DRC可视化工具开发实战 在音频算法开发领域,调试环节长期被桌面级工具垄断,工程师们不得不忍受开发板与工作站之间的频繁切换。这种工作模式不仅效率低下,更无法满足现代音频产品快速迭代的…...

AI产品技能库:将顶尖产品智慧注入Claude Code的实战指南
1. 项目概述:当AI助手遇上产品大师的智慧如果你是一名产品经理、创业者,或者任何需要与产品打交道的人,最近可能已经感受到了AI助手带来的效率革命。无论是用Claude Code写代码,还是用ChatGPT梳理思路,这些工具正在成为…...

Docker部署RabbitMQ后,你的admin账号真的能连上吗?一个权限配置的深度踩坑实录
Docker部署RabbitMQ后admin账号连接失败的深度排查指南 当你用Docker快速部署了RabbitMQ,创建了admin用户,甚至能通过Web界面登录,却在代码中遭遇ACCESS_REFUSED错误时,那种挫败感我深有体会。这不是简单的密码错误问题࿰…...