[每日一练]按日期分组销售产品的最优解法
该题目来自于力扣的pandas题库,链接如下:
1484. 按日期分组销售产品 - 力扣(LeetCode)
题目要求:
表 Activities:
+-------------+---------+ | 列名 | 类型 | +-------------+---------+ | sell_date | date | | product | varchar | +-------------+---------+ 该表没有主键(具有唯一值的列)。它可能包含重复项。 此表的每一行都包含产品名称和在市场上销售的日期。
编写解决方案找出每个日期、销售的不同产品的数量及其名称。
每个日期的销售产品名称应按词典序排列。
返回按 sell_date 排序的结果表。
结果表结果格式如下例所示。
示例 1:
输入:
Activities 表:
+------------+-------------+
| sell_date | product |
+------------+-------------+
| 2020-05-30 | Headphone |
| 2020-06-01 | Pencil |
| 2020-06-02 | Mask |
| 2020-05-30 | Basketball |
| 2020-06-01 | Bible |
| 2020-06-02 | Mask |
| 2020-05-30 | T-Shirt |
+------------+-------------+
输出:
+------------+----------+------------------------------+
| sell_date | num_sold | products |
+------------+----------+------------------------------+
| 2020-05-30 | 3 | Basketball,Headphone,T-shirt |
| 2020-06-01 | 2 | Bible,Pencil |
| 2020-06-02 | 1 | Mask |
+------------+----------+------------------------------+
解释:
对于2020-05-30,出售的物品是 (Headphone, Basketball, T-shirt),按词典序排列,并用逗号 ',' 分隔。
对于2020-06-01,出售的物品是 (Pencil, Bible),按词典序排列,并用逗号分隔。
对于2020-06-02,出售的物品是 (Mask),只需返回该物品名。代码实现:
我本人能力有限,做出的答案执行效率太低,这里我们直接看官方的执行速度最快的代码吧。非原创。
import pandas as pddef categorize_products(activities: pd.DataFrame) -> pd.DataFrame:#这里使用特殊参数as_index不要让sell_date变为索引,省去了reset_index()的代码,对总体的数据进行分组grouped_df = activities.groupby('sell_date',as_index=False)#直接利用聚合函数来进行新列的建立df = grouped_df.agg(num_sold=('product','nunique'),products=('product',lambda x:','.join(sorted(set(x)))))return df.sort_values(by=['sell_date'])这个代码主要在于groupby函数,agg函数,lambda函数的用法
代码及特殊参数解释:
--首先在对全体函数进行分组时,groupby函数使用了一个重要的参数
- as_index = True / False
代表是否把分组的键值设立为索引,默认是True。我们在之前编辑数据时,总是在分组聚合后使用reset_index()函数进行索引的重置,是因为分组聚合后的数据比较复杂,使用这个代码比较保险,而当对整个数据进行分组时,可以直接使用as_index参数,可以提高执行速度,精简代码。
--先进行分组在对数据进行聚合,这样做会将每个日期下的产品按照分组聚合到同一个格子里,但是同时保留了每个产品的信息。
--其次,在新建列并对数据进行编辑聚合时,可以直接使用agg聚合函数,方便且快捷。
- agg函数使用形式:
- agg(min_data=('sale_date',min),max_data=('sale_date',max)
- .agg({'A': 'sum', 'B': 'mean', 'C': 'max'})
这里我们使用第一个使用形式。
--关于lambda函数的强大的遍历效果
我们在聚合函数内建立了products列后,要把表格中的数据都分组放在一个空间力,并对它们进行去重和按照词典排序,数据很多,使用lambda函数可以很快的遍历求解
#代码
df = grouped_df.agg(products=('product',lambda x:','.join(sorted(set(x)))))- lambda函数使用方法:
- [ 捕获列表 ] (参数) -> 返回类型 {}
对product列的每个数据之间加入“,”分隔,由于已经分好组了,所以直接给数据传入set函数来去重,传入sorted函数进行字母排序。
--额外思考:
这个代码对于时间列的使用仅仅是用来分组,所以不需要将该列通过:to_datetime()转换为时间类型。但在我们面对大型数据时,还是建议提前对时间类进行清洗。
相关文章:

[每日一练]按日期分组销售产品的最优解法
该题目来自于力扣的pandas题库,链接如下: 1484. 按日期分组销售产品 - 力扣(LeetCode) 题目要求: 表 Activities: ---------------------- | 列名 | 类型 | ---------------------- | sell_…...
免费wordpress中文主题
免费大图wordpress主题 首页是一张大图的免费wordpress主题模板。简洁实用,易上手。 https://www.jianzhanpress.com/?p5857 免费WP模板下载 顶部左侧导航条的免费WP模板,后台简洁,新手也可以下载使用。 https://www.jianzhanpress.com/…...
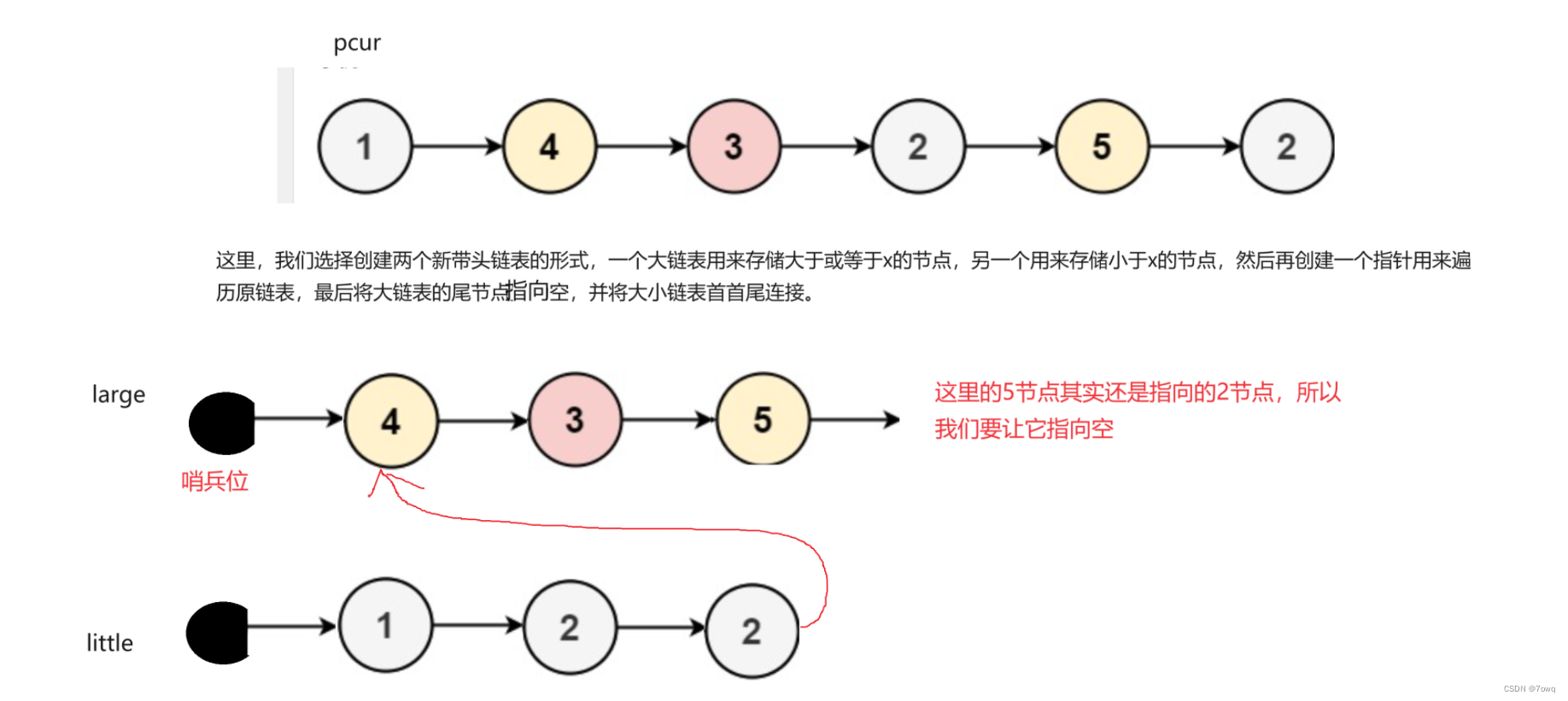
单链表经典算法题理解
目录 1. 前言: 2. 移除链表元素 3. 反转链表 4. 合并两个有序链表 5. 链表的中间节点 6. 环形链表的约瑟夫问题 7. 分割链表 1. 前言: 当我们学习了单链表之后,我能可以尝试的刷一下题了,以下分享一下几道题的解法 2. 移…...

STM32的时钟介绍
目录 前言1. 简介1.1 时钟是用来做什么的1.2 时钟产生的方式 2. 时钟树的组成2.1 时钟源2.1.1 内部时钟2.1.2 外部时钟 2.2 PLL锁相环2.3 SYSCLK2.4 AHB和HCLK2.5 APB和PCLK2.6 总结 3. STM32时钟的如何进行工作4.我的疑问4.1 使用MSI和HSI有什么区别吗?4.2 MSI的频…...

FindBI学习总结
大数据分析BI工具:用户只需简单拖拽便能制作出丰富多样的数据可视化信息 关注点: 快速入门、数据加工、构建图表和分析数据、数据分析进阶 1、界面介绍 目录–仪表板–数据准备 仪表板目录–预览区域 快速上手: 1、数据准备2、制作仪表板3、分…...
k8s——Pod详解
一、Pod基础概念 1.1 Pod定义 Pod是kubernetes中最小的资源管理组件,Pod也是最小化运行容器化应用的资源对象。一个Pod代表着集群中运行的一个进程。kubernetes中其他大多数组件都是围绕着Pod来进行支撑和扩展Pod功能的,例如,用于管理Pod运行…...

Visual Studio 的调试
目录 引言 一、调试的基本功能 设置断点 启动调试 检查变量 逐步执行代码 调用堆栈 使用即时窗口 二、调试技巧 条件断点 日志断点 数据断点 异常调试 三、调试高级功能 远程调试 多线程调试 内存调试 性能调试 诊断工具 四、调试策略与最佳实践 系统化的…...

mysql语句大全及用法
MySQL是一种广泛使用的开源关系型数据库管理系统,它支持标准的SQL(Structured Query Language)语言,用于数据库的查询和操作。以下是一些基本的MySQL语句及其用法的概述: 连接MySQL数据库 mysql -h主机地址 -P端口号…...

如何找出真正的交易信号?Anzo Capital昂首资本总结7个
匕首是一种新兴的价格走势形态,虽然不常见,但具有较高的统计可靠性。它通常预示着趋势的持续发展。该模式涉及到同时参考两个不同的时间周期进行交易,一个是短期,另一个是长期,比如一周时间框架与一天时间框架、一天时…...

JavaScript-内存分配
内存空间 内存分为栈和堆 栈:由操作系统自动释放存放的变量值和函数值等。简单数据类型存放在栈中 栈会由低到高先入后出 堆:存储引用类型 (对象) 对象会先将数据存放在堆里面,堆的地址放在栈里面...

理论知识.质数打表
啊,哈喽,小伙伴们大家好。我是#张亿,今天呐,学的是理论知识.质数打表 为什么需要质数打表 我们已经学习了如何判断一个数是不是质数了,但是还不够。假设要判断很多很多个数是不是质数的时候,之前的学习的…...
FFMPEG+ANativeWinodow渲染播放视频
前言 学习音视频开发,入门基本都得学FFMPEG,按照目前互联网上流传的学习路线,FFMPEGANativeWinodow渲染播放视频属于是第一关卡的Boss,简单但是关键。这几天写了个简单的demo,可以比较稳定进行渲染播放,便…...

使用AXI MIG/Proc Sys Reset
使用AXI MIG/Proc Sys Reset 重要!仅当您的设计中包含AXI MIG时,才执行以下步骤。 AXI-MIG的连接接口 1.选择在/mig_7series_0/S_AXI上运行连接自动化。 2.选择/micblaze_0(缓存)或/micblaze _0(Periph)选项…...

Android基础-Kotlin语言的作用及优缺点
一、Kotlin语言的作用 Kotlin是一种由JetBrains公司开发的现代化静态类型编程语言,自其诞生以来,便在多个领域展现出了强大的应用潜力。其主要作用可以概括为以下几点: Android应用开发:Kotlin作为Android开发的官方推荐语言&am…...

手机投屏技巧:手机怎么投屏到电脑显示屏上?精选6招解决!
手机怎么投屏到电脑显示屏上?出于一些不同的原因,大多数人都希望能将手机投屏到电脑上。其中一个常见的原因是,大家经常会希望在笔记本电脑上共享图片,而无需上传或者登录微信进行文件传输。以及希望不依靠投影仪,就能…...
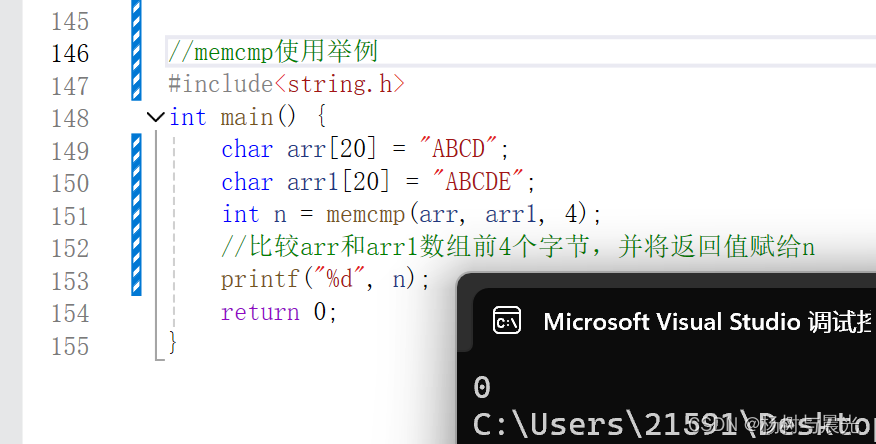
内存函数<C语言>
前言 前面两篇文章介绍了字符串函数,不过它们都只能用来处理字符串,C语言中也内置了一些内存函数来对不同类型的数据进行处理,本文将介绍:memcpy()使用以及模拟实现,memmove()使用以及模拟实现,memset()使用…...
)
华为校招机试 - LRU模拟(20240515)
题目描述 LRU(Least Recently Used)缓存算法是一种常用于管理缓存的策略,其目标是保留最近使用过的数据,而淘汰最久未被使用的数据。 实现简单的LRU缓存算法,支持查询、插入、删除操作。 最久未被使用定义:查询、插入和删除操作均为一次访问操作,每个元素均有一个最后…...

AI预测福彩3D采取888=3策略+和值012路一缩定乾坤测试5月29日预测第5弹
今天继续基于8883的大底,使用尽可能少的条件进行缩号,同时,同样准备两套方案,一套是我自己的条件进行缩号,另外一套是8883的大底结合2码不定位奖号预测二次缩水来杀号。好了,直接上结果吧~ 首先&…...

03_前端三大件CSS
文章目录 CSS用于页面元素美化1.CSS引入1.1style方式1.2写入head中,通过写style然后进行标签选择器加载样式1.3外部样式表 2.CSS样式选择器2.1 元素选择器2.2 id选择器2.3 class选择器 3.CSS布局相关3.1 CSS浮动背景:先设计一些盒子因此,引出…...

十种常用数据分析模型
1-线性回归(Linear Regression) 场景:预测商品销售额 优点:简单易用,结果易于解释缺点:假设线性关系,容易受到异常值影响概念:建立自变量和因变量之间线性关系的模型。公式&#x…...

零代码操作!FUTURE POLICE亮色界面详解:从上传到下载SRT全流程
零代码操作!FUTURE POLICE亮色界面详解:从上传到下载SRT全流程 1. 认识FUTURE POLICE:高精度字幕对齐工具 你是否遇到过这样的困扰?精心制作的视频字幕总是与语音不同步,手动调整时间轴既耗时又费力。FUTURE POLICE正…...

python高校大学生家教平台的设计与开发
目录需求分析与功能规划技术栈选型数据库设计关键功能实现测试与部署持续迭代项目技术支持源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作需求分析与功能规划 明确平台核心需求,包括用户角色划分(学生、教师、管理员…...
实战案例版)
小龙虾使用手册(蓝皮书)实战案例版
扫描下载文档详情页: https://www.didaidea.com/wenku/16656.html...

【深度解析】CODrone:如何用高分辨率多视角数据重塑无人机旋转目标检测基准
1. CODrone数据集为何能重新定义旋转目标检测标准 当无人机在城市上空盘旋时,它看到的不是我们熟悉的平视视角。倾斜的建筑物、变形的车辆轮廓、微小的行人身影——这些才是无人机视觉感知的真实挑战。传统数据集用"上帝视角"的俯拍图像训练出的算法&…...

春节不用愁对联:春联生成模型实战,3步生成专属春联
春节不用愁对联:春联生成模型实战,3步生成专属春联 1. 传统年味遇上AI科技 每到春节,家家户户贴春联是延续千年的传统习俗。一副好春联既要对仗工整,又要寓意吉祥,还要符合自家特色,这让不少人为之头疼。…...

告别调参玄学:在GID遥感数据集上优化DeeplabV3+的5个实战技巧
告别调参玄学:在GID遥感数据集上优化DeeplabV3的5个实战技巧 遥感影像分割一直是计算机视觉领域的难点任务,尤其是面对GID这类包含复杂地物边界和多尺度目标的数据集时。许多研究者在初步跑通DeeplabV3模型后,往往会陷入mIoU指标停滞不前的困…...

保姆级教程:在RTX 5090上跑通CosyVoice2语音合成,并集成vLLM加速
在RTX 5090上部署CosyVoice2语音合成:从环境配置到vLLM加速实战 当你刚拿到Nvidia RTX 5090显卡时,最兴奋的莫过于用它来跑最新的AI模型。CosyVoice2作为当前最先进的语音合成框架之一,结合vLLM的推理加速能力,能在RTX 5090上实现…...
Java 企业级应用:基于 SpringBoot 集成 Pixel Dream Workshop 构建内容中台
Java 企业级应用:基于 SpringBoot 集成 Pixel Dream Workshop 构建内容中台 1. 企业内容中台的业务场景与挑战 现代企业面临内容生产的三大痛点:创意产出效率低、设计资源不足、多平台适配成本高。以电商行业为例,一个中型电商平台每月需要…...

Ollama部署LFM2.5-1.2B-Thinking:轻量模型在边缘设备上的真实性能报告
Ollama部署LFM2.5-1.2B-Thinking:轻量模型在边缘设备上的真实性能报告 1. 模型介绍:专为边缘设备设计的智能助手 LFM2.5-1.2B-Thinking是一个专门为设备端部署优化的文本生成模型,它在LFM2架构基础上进行了深度改进。这个模型最大的特点就是…...

导师严选!盘点2026年最强的的降AI率网站
轻松降低论文AI率在2026年已不再是天方夜谭。以下是2026年最炸裂、实测效果显著的降AI率网站神器,覆盖AI痕迹消除、文本改写润色、降重优化、学术合规检测四大核心场景,帮你稳妥搞定毕业论文。 一、全流程王者:一站式搞定论文全链路 这类工具…...