通过LLM多轮对话生成单元测试用例
通过LLM多轮对话生成单元测试用例
- 代码
在采用 随机生成pytorch算子测试序列且保证算子参数合法 这种方法之前,曾通过本文的方法生成算子组合测试用例。目前所测LLM生成的代码均会出现BUG,且多次交互后仍不能解决.也许随着LLM的更新,这个问题会得到解决.记录备用。
代码
import re
import os
import logging
import random
import numpy as np
import os
import re
import traceback
import subprocess
import tempfile
import copy
import requests
import jsonimport os
os.environ['MKL_THREADING_LAYER'] = 'GNU'
os.environ['MKL_SERVICE_FORCE_INTEL'] = '1'os.environ["QIANFAN_AK"] = ""
os.environ["QIANFAN_SK"] = ""
os.environ['DASHSCOPE_API_KEY'] = 'sk-'
os.environ['MOONSHOT_API_KEY']="sk-"
os.environ['SPARKAI_APP_ID'] = ''
os.environ['SPARKAI_API_SECRET'] = ''
os.environ['SPARKAI_API_KEY'] = ''
os.environ['SPARKAI_DOMAIN'] = 'generalv3.5'
os.environ['ZhipuAI_API_KEY'] = ''
os.environ['YI_API_KEY']=""logger = logging.getLogger('llm_logger')
logger.setLevel(logging.DEBUG) # 设置日志级别# 创建一个handler,用于写入日志文件
log_file = 'llm_opt.log'
file_handler = logging.FileHandler(log_file)
file_handler.setLevel(logging.DEBUG)# 创建一个handler,用于将日志输出到控制台
console_handler = logging.StreamHandler()
console_handler.setLevel(logging.DEBUG)# 设置日志格式
formatter = logging.Formatter('%(message)s')
file_handler.setFormatter(formatter)
console_handler.setFormatter(formatter)# 将handlers添加到logger
logger.addHandler(file_handler)
logger.addHandler(console_handler)system_prompt="你是一位pytorch专家,现在需要编写各种测试程序,挖掘算子的潜在BUG"question =f'''
背景描述:
1.为了测试pytorch不同算子组合时的精度是否正常,需要构建module级别的测试用例
2.尤其需要关注unsqueeze,repeat,permute,transpose,reshape,expand,view等维度变换算子的各种组合
3.以及在这些组合之后添加其它io或计算类的算子如(contiguous,matmul,mul,concat等)需求:
1.你一次生成一个测试用例(pytorch module及测例),只包含cpu计算
2.之后,我会从的回复中提取出python代码,执行并将结果反馈给你
3.你根据我的反馈,预测性地生成下一个测试用例
4.我们通过多次交互,最大程度地挖掘出潜在的BUG约束:
1.所有测试用例的代码放在一个```python ```中,方便提取
2.为了防止shape不匹配,建议在forward中计算shape,并根据当前的shape合理地设置下一个算子的参数
3.你每次提供的代码都必须是完整的,不要添加任何注释
4.测试代码只输出成功、失败或抛异常,不需要输出任何多余信息
5.特别需要注意矩阵乘维度是否匹配如果你明白我的意思,请直接输出第一个测试用例
'''def extract_and_run_python_code(markdown_text):pattern = re.compile(r'```python\n([^```].*?)\n```', re.DOTALL)code_blocks = pattern.findall(markdown_text)if len(code_blocks)==0:return "没有找到Python代码块。"results = []for code in code_blocks:try:with tempfile.NamedTemporaryFile(delete=False, suffix=".py") as temp_file:temp_file.write(code.encode())temp_filename = temp_file.nameresult = subprocess.run(['python3', temp_filename], capture_output=True, text=True) output=f"{result.stderr}{result.stdout}"results.append(output)except Exception as e:error_message = f"error:{traceback.format_exc()}"results.append(error_message) finally:os.remove(temp_filename)return "".join(results)class LLMInfer(object):def __init__(self, system_prompt,question,history_len=5):self.system_prompt=system_promptself.question=question self.history_len=history_len def infer(self,user_input=None):pass def reset(self):passclass dashscope_llm(LLMInfer):def __init__(self, system_prompt, question):super().__init__(system_prompt, question)import dashscopedashscope.api_key=os.environ['DASHSCOPE_API_KEY'] self.history=[]self.history.append({'role': 'system', 'content': self.system_prompt})self.history.append({'role': 'user', 'content': self.question}) def reset(self):if len(self.history)>self.history_len:self.history=self.history[:2] + self.history[-3:]def infer(self,user_input=None):from dashscope import Generationfrom http import HTTPStatus if user_input:self.history.append({'role': 'user', 'content': user_input})response = Generation.call(model="qwen-plus", messages=self.history,result_format='message')if response.status_code == HTTPStatus.OK:role=response.output.choices[0]['message']['role']content=response.output.choices[0]['message']['content']self.history.append({'role': role,'content': content})return contentelse:return Noneclass moonshot_llm(LLMInfer):def __init__(self, system_prompt, question):super().__init__(system_prompt, question)'''pip install --upgrade 'openai>=1.0''''from openai import OpenAIself.client = OpenAI(api_key = os.environ['MOONSHOT_API_KEY'],base_url = "https://api.moonshot.cn/v1",)self.history=[]self.history.append({'role': 'system', 'content': self.system_prompt})self.history.append({'role': 'user', 'content': self.question}) def reset(self):if len(self.history)>self.history_len:self.history=self.history[:2] + self.history[-3:]def infer(self,user_input=None): if user_input:self.history.append({'role': 'user', 'content': user_input})completion = self.client.chat.completions.create(model="moonshot-v1-128k",messages=self.history,temperature=0.3,top_p=0.1)role="assistant"content=completion.choices[0].message.contentself.history.append({'role': role,'content': content})return contentclass qianfan_llm(LLMInfer):def __init__(self, system_prompt, question):super().__init__(system_prompt, question)'''pip3 install qianfan'''self.history=[]#self.history.append({'role': 'system', 'content': self.system_prompt})self.history.append({'role': 'user', 'content': self.question}) def reset(self):if len(self.history)>self.history_len:self.history=self.history[:1] + self.history[-2:]def infer(self,user_input=None): import qianfan if user_input:self.history.append({'role': 'user', 'content': user_input})response = qianfan.ChatCompletion().do(endpoint="completions_pro", messages=self.history,temperature=0.7, top_p=0.8, penalty_score=1, disable_search=False, enable_citation=False)role="assistant"content=response.body["result"]self.history.append({'role': role,'content': content})return contentclass sparkai_llm(LLMInfer):def __init__(self, system_prompt, question):super().__init__(system_prompt, question)'''pip3 install --upgrade spark_ai_python'''from sparkai.llm.llm import ChatSparkLLMfrom sparkai.core.messages import ChatMessageself.spark = ChatSparkLLM(spark_api_url='wss://spark-api.xf-yun.com/v3.5/chat',spark_app_id=os.environ['SPARKAI_APP_ID'],spark_api_key=os.environ['SPARKAI_API_KEY'],spark_api_secret=os.environ['SPARKAI_API_SECRET'],spark_llm_domain=os.environ['SPARKAI_DOMAIN'],streaming=False, temperature=0.1)self.history=[]self.history.append(ChatMessage(role="system",content=self.system_prompt))self.history.append(ChatMessage(role="user",content=self.question))def reset(self):if len(self.history)>self.history_len:self.history=self.history[:2] + self.history[-3:]def infer(self,user_input=None): from sparkai.core.messages import ChatMessagefrom sparkai.llm.llm import ChunkPrintHandlerif user_input:self.history.append(ChatMessage(role="user",content=user_input)) handler = ChunkPrintHandler()response = self.spark.generate([self.history], callbacks=[handler])self.history.append(response.generations[0][0].message)return response.generations[0][0].textclass zhipuai_llm(LLMInfer):def __init__(self, system_prompt, question):super().__init__(system_prompt, question)'''pip install zhipuai'''from zhipuai import ZhipuAIself.client = ZhipuAI(api_key=os.environ['ZhipuAI_API_KEY'])self.history=[]self.history.append({'role': 'system', 'content': self.system_prompt})self.history.append({'role': 'user', 'content': self.question}) def reset(self):if len(self.history)>self.history_len:self.history=self.history[:2] + self.history[-3:]def infer(self,user_input=None): if user_input:self.history.append({'role': 'user', 'content': user_input})completion = self.client.chat.completions.create(model="glm-4",messages=self.history,temperature=0.3,top_p=0.1)role="assistant"content=completion.choices[0].message.contentself.history.append({'role': role,'content': content})return contentclass yi_llm(LLMInfer):def __init__(self, system_prompt, question):super().__init__(system_prompt, question)'''pip install --upgrade 'openai>=1.0''''from openai import OpenAIself.client = OpenAI(api_key = os.environ['YI_API_KEY'],base_url = "https://api.lingyiwanwu.com/v1",)self.history=[]self.history.append({'role': 'system', 'content': self.system_prompt})self.history.append({'role': 'user', 'content': self.question}) def reset(self):if len(self.history)>self.history_len:self.history=self.history[:2] + self.history[-3:]def infer(self,user_input=None): if user_input:self.history.append({'role': 'user', 'content': user_input})completion = self.client.chat.completions.create(model="yi-large",messages=self.history,temperature=0.3,top_p=0.1)role="assistant"content=completion.choices[0].message.contentself.history.append({'role': role,'content': content})return contentllms=[dashscope_llm,moonshot_llm,qianfan_llm,sparkai_llm,zhipuai_llm,yi_llm]
for llm in llms:logger.info(f" ---------------------------------- {llm.__name__} ---------------------------------- ")llm=llm(system_prompt,question)response = llm.infer()for i in range(15):llm.reset()logger.info(f" ---------------------------------- 第{i}轮 ---------------------------------- ")result=Nonelogger.info("####### bot #######")logger.info(f"{response}")if response:result=f"{extract_and_run_python_code(response)}" logger.info("####### user #######")logger.info(f"{result}")response=llm.infer(result)
相关文章:

通过LLM多轮对话生成单元测试用例
通过LLM多轮对话生成单元测试用例 代码 在采用 随机生成pytorch算子测试序列且保证算子参数合法 这种方法之前,曾通过本文的方法生成算子组合测试用例。目前所测LLM生成的代码均会出现BUG,且多次交互后仍不能解决.也许随着LLM的更新,这个问题会得到解决.记录备用。 代码 impo…...
[Redis]String类型
基本命令 set命令 将 string 类型的 value 设置到 key 中。如果 key 之前存在,则覆盖,无论原来的数据类型是什么。之前关于此 key 的 TTL 也全部失效。 set key value [expiration EX seconds|PX milliseconds] [NX|XX] 选项[EX|PX] EX seconds⸺使用…...

Ai速递5.29
全球AI新闻速递 1.摩尔线程与无问芯穹合作,实现国产 GPU 端到端 AI 大模型实训。 2.宝马工厂:机器狗上岗,可“嗅探”故障隐患。 3.ChatGPT:macOS 开始公测。 4.Stability AI:推出Stable Assistant,可用S…...
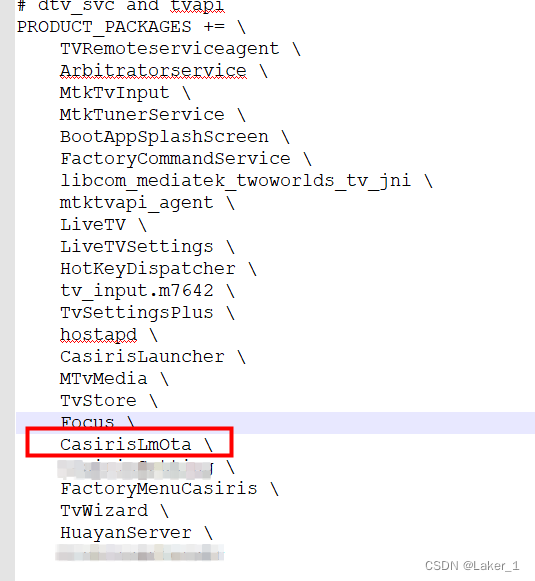
Android9.0 MTK平台如何增加一个系统应用
在安卓定制化开发过程中,难免遇到要把自己的app预置到系统中,作为系统应用使用,其实方法有很多,过程很简单,今天分享一下我是怎么做的,共总分两步: 第一步:要找到当前系统应用apk存…...
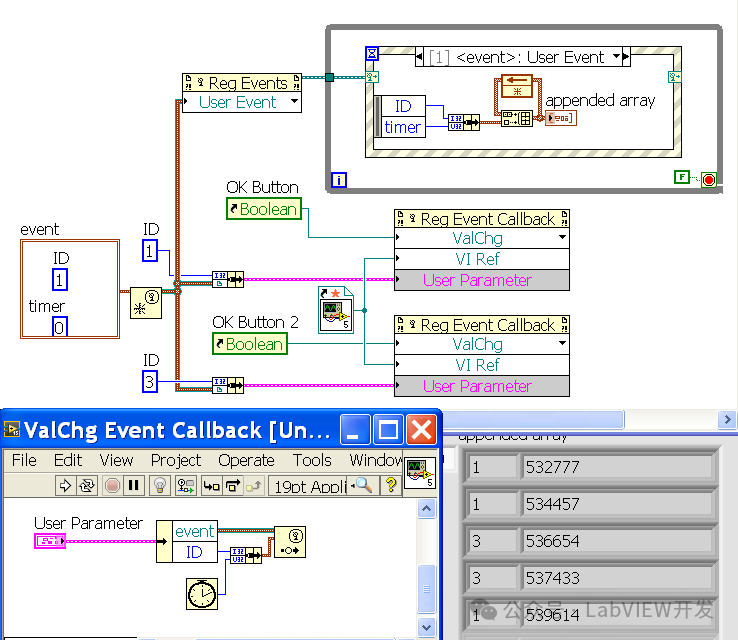
LabVIEW中实现Trio控制器的以太网通讯
在LabVIEW中实现与Trio控制器的以太网通讯,可以通过使用TCP/IP协议来完成。这种方法包括配置Trio控制器的网络设置、使用LabVIEW中的TCP/IP函数库进行数据传输和接收,以及处理通讯中的错误和数据解析。本文将详细说明实现步骤,包括配置、编程…...

C/C++运行时库与 UCRT 通用运行时库:全面总结与问题实例剖析
推荐一个AI网站,免费使用豆包AI模型,快去白嫖👉海鲸AI 1. 概述 在开发C/C应用程序时,运行时库(Runtime Library)是不可或缺的一部分。它们提供了一系列函数和功能,使得开发者能够更方便地进行编…...

【Python001】python批量下载、插入与读取Oracle中图片数据(已更新)
1.熟悉、梳理、总结数据分析实战中的python、oracle研发知识体系 2.欢迎点赞、关注、批评、指正,互三走起来,小手动起来! 文章目录 1.背景说明2.环境搭建2.1 参考链接2.2 `oracle`查询测试代码3.数据请求与插入3.1 `Oracle`建表语句3.2 `Python`代码实现3.3 效果示例4.问题链…...
)
流形学习(Manifold Learning)
基本概念 Manifold Learning(流形学习)是一种机器学习和数据分析的方法,它专注于从高维数据中发现低维的非线性结构。流形学习的基本假设是,尽管数据可能在高维空间中呈现,但它们实际上分布在一个低维的流形上。这个流…...

区块链技术和应用
文章目录 前言 一、区块链是什么? 二、区块链核心数据结构 2.1 交易 2.2 区块 三、交易 3.1 交易的生命周期 3.2 节点类型 3.3 分布式系统 3.4 节点数据库 3.5 智能合约 3.6 多个记账节点-去中心化 3.7 双花问题 3.8 共识算法 3.8.1 POW工作量证明 总结 前言 学习长…...

Docker拉取镜像报错:x509: certificate has expired or is not yet v..
太久没有使用docker进行镜像拉取,今天使用docker-compose拉取mongo发现报错(如下图): 报错信息翻译:证书已过期或尚未有效。 解决办法: 1.一般都是证书问题或者系统时间问题导致,可以先执行 da…...
猫狗分类识别模型建立②模型建立
一、导入依赖库 pip install opencv-python pip install numpy pip install tensorflow pip install keras 二、模型建立 pip install opencv-python pip install numpy pip install tensorflow pip install kerasimport os import xml.etree.ElementTree as ETimpor…...
(二十一))
React Native 之 ToastAndroid(提示语)(二十一)
ToastAndroid 是 React Native 提供的一个特定于 Android 平台的 API,用于显示简单的消息提示(Toast)。 两个方法: 1. ToastAndroid.show(message, duration, gravity) message: 要显示的文本消息。duration: Toast 的持续时间&…...

合约之间调用-如何实现函数静态调用?
合约之间的函数调用 EOA,external owned account,外部账号,例如metamask调用最终总是由EOA发起的合约之间的调用使得一次完整的调用成为一个调用链条 合约间调用过程 调用者须持有被调用合约的地址得到被调用合约的信息将地址重载为被调用合…...
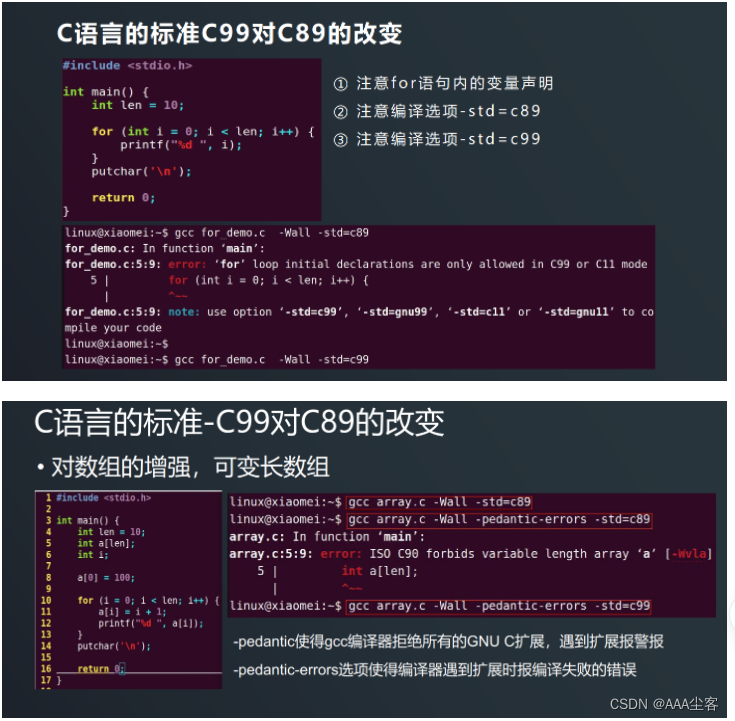
【5.基础知识和程序编译及调试】
一、GCC概述:是GUN推出的多平台编译器,可将C/C源程序编译成可执行文件。编译流程分为以下四个步骤: 1、预处理 2、编译 3、汇编 4、链接 注:编译器根据程序的扩展名来分辨编写源程序所用的语言。根据不同的后缀名对他们进行相…...
)
微信小程序(路由传参)
微信小程序的路由系统和其他Web应用类似,主要通过页面路径和URL参数进行页面导航和数据传递。下面详细介绍微信小程序路由的基本使用方法和相关技巧。 1. 基本页面导航 1.1 配置页面路径 在微信小程序的 app.json 文件中,需要配置小程序的页面路径。这…...

电脑显示不出网络
你的电脑是否在开机后显示不出网络,或者有网络消失的现象?今天和大家分享我学到的一个办法,希望对大家有用。 分析出现这类现象的原因:可能是电脑网卡松动了,电脑中存在静电流。 解决办法:先将电脑关机&am…...

random模块一
random模块 用于生成随机数。 random()返回[0,1)之间随机浮点数 例子: import randomfor i in range(5):print(random.random()) 结果: 0.5026620465128847 0.9841750667006002 0.5515465602585887 0.42796563433917456 0.2627959451391586 see…...

Spring OAuth2:开发者的安全盾牌!(下)
上文我们教了大家如何像海盗一样寻找宝藏,一步步解锁令牌的奥秘,今天将把更加核心的技巧带给大家一起学习,共同进步! 文章目录 6. 客户端凭证与密码模式6.1 客户端凭证模式应用适用于后端服务间通信 6.2 密码模式考量直接传递用户…...

kotlin基础之协程
Kotlin协程(Coroutines)是Kotlin提供的一种轻量级的线程模型,它允许我们以非阻塞的方式编写异步代码,而无需使用回调、线程或复杂的并发API。协程是一种用户态的轻量级线程,它可以在需要时挂起和恢复,从而有…...

法那科机器人M-900iA维修主要思路
发那科工业机器人是当今制造业中常用的自动化设备之一,而示教器是发那科机器人操作和维护的重要组成部分。 一、FANUC机械手示教器故障分类 1. 硬件故障 硬件故障通常是指发那科机器人M-900iA示教器本身的硬件问题,如屏幕损坏、按键失灵、电源故障等。 2…...

Java后端如何通过异步非阻塞方式提高美团外卖API并发调用能力
Java后端如何通过异步非阻塞方式提高美团外卖API并发调用能力 在“外卖霸王餐”等高并发业务场景中,系统往往需要同时调用美团、饿了么等多个第三方API。传统的同步阻塞IO模型(如使用RestTemplate或HttpClient直接调用)会导致Tomcat工作线程在…...

Jetson Orin Nano上YOLOv8训练避坑实录:从CUDA报错到ONNX导出,我的踩坑与修复指南
Jetson Orin Nano上YOLOv8训练避坑实录:从CUDA报错到ONNX导出实战指南 在边缘计算设备上部署深度学习模型总是充满挑战,特别是当硬件架构与主流x86平台存在差异时。Jetson Orin Nano作为NVIDIA最新的边缘AI计算平台,其ARM架构和独特的CUDA核心…...

MySQL源码编译部署主从及MHA高可用集群实战
一.Mysql的源码编译1.下载安装包wget https://downloads.mysql.com/archives/get/p/23/file/mysql-boost-8.3.0.tar.gz2.源码编译# 安装编译依赖的软件包,包括C/C编译器(如gcc/gcc-c)、构建工具(如cmake, git, bison)和开发库(如openssl-devel, ncurses-devel) [roo…...

高效构建智能媒体库:MetaTube插件全方位应用指南
高效构建智能媒体库:MetaTube插件全方位应用指南 【免费下载链接】jellyfin-plugin-metatube MetaTube Plugin for Jellyfin/Emby 项目地址: https://gitcode.com/gh_mirrors/je/jellyfin-plugin-metatube MetaTube是一款专为Jellyfin和Emby设计的开源元数据…...
)
Proteus仿真C51单片机:用汇编实现一个简易的脉冲计数器(附完整代码和电路图)
Proteus仿真C51单片机:用汇编实现一个简易的脉冲计数器(附完整代码和电路图) 当你第一次接触单片机编程时,可能会被各种寄存器、中断和端口配置搞得晕头转向。今天,我们就用一个实实在在的脉冲计数器项目,带…...

二进制魔法:解密Windows平台消息防撤回的底层实现
二进制魔法:解密Windows平台消息防撤回的底层实现 【免费下载链接】RevokeMsgPatcher :trollface: A hex editor for WeChat/QQ/TIM - PC版微信/QQ/TIM防撤回补丁(我已经看到了,撤回也没用了) 项目地址: https://gitcode.com/Gi…...

COLMAP点云处理完,用Brush做高斯泼溅前,这5个参数调优让你的3D模型质感飙升
COLMAP点云处理完,用Brush做高斯泼溅前,这5个参数调优让你的3D模型质感飙升 当你已经能够顺利跑通从COLMAP到Brush的完整流程,却发现生成的3D模型总是差那么点意思——要么细节模糊得像打了马赛克,要么表面噪点多得像撒了胡椒面&a…...

SillyTavern:革新性AI角色扮演平台的全方位实践指南
SillyTavern:革新性AI角色扮演平台的全方位实践指南 【免费下载链接】SillyTavern LLM Frontend for Power Users. 项目地址: https://gitcode.com/GitHub_Trending/si/SillyTavern 在人工智能对话系统日益普及的今天,用户对虚拟交互的需求已从简…...

OneNET物联网平台接入避坑指南:Android端用MQTTS协议请求数据,为什么你的Token总失效?
OneNET物联网平台MQTTS接入实战:Android端Token失效的深度排查与解决方案 第一次在Android应用中集成OneNET的MQTTS协议时,我盯着调试日志里反复出现的"401 Unauthorized"错误整整两天。官方文档看似清晰,但实际对接时才发现&…...

CopyManga下载器新手指南:从入门到精通的漫画收藏解决方案
CopyManga下载器新手指南:从入门到精通的漫画收藏解决方案 【免费下载链接】copymanga-downloader 使用python编译exe/bash/命令行参数来下载copymanga(拷贝漫画)中的漫画,支持批量选话下载和获取您收藏的漫画并下载!(windows&linux支持&…...