流形学习(Manifold Learning)
基本概念
Manifold Learning(流形学习)是一种机器学习和数据分析的方法,它专注于从高维数据中发现低维的非线性结构。流形学习的基本假设是,尽管数据可能在高维空间中呈现,但它们实际上分布在一个低维的流形上。这个流形是数据的真实结构,它捕捉了数据中的内在关系和模式。
流形是一个数学概念,指的是在局部类似于欧几里得空间的拓扑空间。在高维数据分析中,流形可以被看作是数据点自然聚集的低维表面或曲线。例如,人脸图像可能在成千上万个像素维度上表示,但实际上它们可能分布在一个远低于这个维度的流形上,因为人脸的形状和表情变化是有限的。
流形学习的目标是从高维观测数据中恢复出这个低维流形的结构,这通常涉及到以下几个步骤:
- 数据预处理:包括归一化、去噪等,以确保数据的质量。
- 流形构造:通过各种算法(如Isomap、局部线性嵌入(LLE)、拉普拉斯特征映射(Laplacian Eigenmaps)等)来构造或近似表示数据的流形结构。
- 降维:将高维数据映射到低维流形上,以便于可视化、分析或进一步的机器学习任务。
- 分析与应用:在低维流形上进行数据分析,如聚类、分类、异常检测等。
流形学习在处理非线性数据结构时特别有效,它能够揭示数据背后的复杂关系,而不仅仅是通过线性变换来简化数据。这种方法在计算机视觉、生物信息学、社交网络分析等领域都有广泛的应用。
流行学习与表示学习的联系和区别
流形学习和表示学习都是机器学习领域中用于处理和理解数据的方法,它们之间存在紧密的联系,但侧重点和方法有所不同。
流形学习(Manifold Learning)
流形学习是一种非线性降维技术,它假设高维数据实际上分布在一个低维流形上。流形学习的目标是从高维观测数据中恢复出这个低维流形的结构,从而揭示数据的内在几何关系。流形学习算法通常包括Isomap、局部线性嵌入(LLE)、拉普拉斯特征映射(Laplacian Eigenmaps)等。
表示学习(Representation Learning)
表示学习是一种更广泛的概念,它关注的是如何自动地从数据中学习到有用的特征表示。表示学习的目标是找到一种能够捕捉数据重要特征的低维表示,这种表示可以用于后续的机器学习任务,如分类、回归或聚类。表示学习的方法包括自动编码器(Autoencoders)、受限玻尔兹曼机(RBMs)、深度神经网络等。
联系
-
降维:流形学习和表示学习都涉及到将高维数据映射到低维空间,以便于理解和处理。
-
特征提取:两者都旨在从原始数据中提取有意义的特征,这些特征可以更好地反映数据的内在结构和模式。
-
非线性:流形学习和表示学习都处理非线性数据结构。流形学习通过假设数据分布在低维流形上来处理非线性,而表示学习通过使用非线性变换(如神经网络中的激活函数)来学习非线性特征。
-
数据驱动:两者都是数据驱动的方法,不需要手动设计特征,而是依赖于算法从数据中自动学习特征。
区别
-
目标:流形学习主要关注于发现数据的几何结构,而表示学习更侧重于为后续的机器学习任务提供有用的特征表示。
-
方法:流形学习通常使用特定的几何和拓扑方法来揭示流形结构,而表示学习使用更广泛的机器学习技术,包括深度学习方法。
-
应用:流形学习在可视化和高维数据分析中较为常见,而表示学习在各种机器学习任务中都有应用,如图像识别、语音识别和自然语言处理等。
总的来说,流形学习和表示学习都是为了更好地理解和处理复杂数据而发展起来的方法,它们在实践中经常相互补充,共同推动了机器学习领域的发展。
多维尺度分析(MDS)
多维尺度分析(Multidimensional Scaling,简称MDS)是一种统计技术,用于探索和可视化数据集中的相似性或距离关系。MDS的目标是在低维空间中找到数据点的表示,使得这些点在低维空间中的距离尽可能地反映它们在原始高维空间中的相似性或距离。
基本步骤
-
距离矩阵的构建:首先,需要一个表示数据点之间相似性或距离的矩阵。这个矩阵可以是直接测量的距离(如欧氏距离),也可以是基于相似性度量的转换(如将相似性转换为距离)。
-
低维表示:MDS的目标是在一个较低维度的空间中找到数据点的坐标,使得这些坐标之间的距离尽可能地与原始距离矩阵中的距离相匹配。这通常通过最小化一个特定的目标函数来实现,该函数衡量低维空间中的距离与原始距离之间的差异。
-
压力函数:在MDS中,通常使用压力函数(Stress function)来衡量低维表示的质量。压力函数定义为低维空间中距离与原始距离之间差异的某种度量。MDS算法的目标是最小化这个压力函数。
-
特征值分解:在经典(或度量)MDS中,通常使用特征值分解来找到低维表示。这涉及到计算距离矩阵的平方并进行中心化,然后计算其内积矩阵的特征值和特征向量。低维表示可以通过选择最大的特征值对应的特征向量来获得。
-
非度量MDS:在非度量MDS中,重点是保持数据点之间的相对距离关系,而不是精确的距离值。这通常涉及到一个迭代过程,其中通过单调变换来调整低维表示,以更好地匹配原始距离的排序。
类型
- 度量MDS:适用于距离可以精确测量的情况,如欧氏距离。
- 非度量MDS:适用于距离或相似性只能通过排序或等级来表示的情况。
应用
MDS广泛应用于各种领域,包括心理学(如感知研究)、市场研究(如产品定位)、生物信息学(如基因表达数据的分析)和社交网络分析等。它特别适合于可视化复杂的数据集,帮助研究人员理解数据点之间的关系。
限制
MDS的一个主要限制是它对异常值敏感,并且可能不适用于高度非线性的数据结构。此外,MDS的结果可能依赖于所选的距离度量和压力函数的具体形式。
总的来说,多维尺度分析是一种强大的工具,用于在保持数据点间距离关系的同时,将高维数据映射到低维空间,从而实现数据的可视化和分析。
等度量映射(Isomap)
等度量映射(Isometric Feature Mapping,简称Isomap)是一种流形学习算法,用于非线性降维。Isomap结合了多维尺度分析(MDS)和图论的概念,旨在找到高维数据集的低维表示,同时保持数据点之间的测地距离。
基本原理
Isomap的核心思想是,尽管高维数据可能分布在一个非线性流形上,但流形上的点之间的最短路径(测地距离)可以提供关于数据内在结构的有用信息。Isomap通过以下步骤实现降维:
-
构建邻域图:首先,对于数据集中的每个点,确定其最近的邻居(使用欧氏距离或其他距离度量)。这些邻居构成了该点的局部邻域。然后,构建一个图,其中数据点是节点,而边连接每个点的邻居。
-
计算测地距离:在构建的图上,计算每对点之间的最短路径。这通常通过Dijkstra算法或Floyd-Warshall算法来实现。这些最短路径近似于流形上的测地距离。
-
应用MDS:使用计算得到的测地距离矩阵,应用多维尺度分析(MDS)来找到一个低维表示,使得低维空间中的距离尽可能地与测地距离相匹配。
-
可视化或进一步分析:得到的低维表示可以用于可视化数据集,或者作为其他机器学习算法的输入。
关键特点
- 全局结构保持:与仅考虑局部结构的算法(如局部线性嵌入LLE)不同,Isomap旨在保持数据的全局几何结构。
- 非线性流形:Isomap特别适用于揭示嵌入在高维空间中的非线性流形的低维结构。
- 计算复杂性:Isomap的计算复杂性相对较高,特别是在处理大型数据集时,因为需要计算图上的最短路径。
应用
Isomap已被应用于各种领域,包括计算机视觉、生物信息学和机器人技术。它特别适合于可视化高维数据集,并揭示数据中的复杂结构。
限制
- 计算成本:对于大型数据集,计算测地距离可能非常耗时。
- 对参数敏感:Isomap的性能可能对邻域大小等参数的选择非常敏感。
- 不适用于噪声数据:Isomap可能不适用于包含大量噪声或异常值的数据集。
总的来说,等度量映射是一种强大的非线性降维技术,它通过保持数据点之间的测地距离来揭示高维数据的低维结构。然而,它的计算成本和参数敏感性限制了其在某些情况下的应用。
局部线性嵌入(LLE)
局部线性嵌入(Local Linear Embedding,简称LLE)是一种流行的非线性降维方法,由Sam Roweis和Lawrence Saul于2000年提出。LLE的核心思想是假设数据集中的每个点和它的近邻是线性相关的,并试图在低维空间中保持这些局部线性关系。这种方法特别适用于当数据位于一个内在的低维流形上时。
基本步骤
-
选择邻居:首先确定每个点的邻居。这可以通过固定最近的K个邻居或固定半径ε来确定邻域内的所有点来完成。
-
计算权重:对于每个点,找到一组权重,这些权重用来线性重建该点从其邻居。也就是说,我们试图找到一个权重矩阵W,对于每个数据点Xi,它的邻居的线性组合可以尽可能地重建Xi。这个步骤通常涉及到解一个局部的最优化问题。
-
嵌入到低维空间:在保持权重固定的情况下,寻找数据点在低维空间中的坐标Y,使得原高维中的局部线性关系在低维空间中尽可能地得到保持。这一步是通过最小化重建误差的全局代价函数来实现的,这个代价函数衡量的是在整个数据集上使用固定的权重W时,低维表示的点如何重建自身。
关键特点
- 重建权重:LLE算法的第一个关键步骤是计算局部重建权重,这些权重反映了每个点和它邻居之间的局部几何结构。
- 保持邻域结构:在降维过程中,LLE试图保持数据的局部线性结构,而不是全局的几何结构。
计算流程
- 构建邻居矩阵:对于每个数据点,找出K个最近邻居。
- 计算重建权重:最小化每个点与其K个邻居的线性重建误差来计算重构权重。
- 优化低维映射:在低维空间中,最小化一个代价函数,该函数衡量了使用相同的重建权重在低维空间中的重建误差。
优势
- 无需全局参数调整:LLE只需要邻居的数量这一个参数,这相对于其他需要全局参数的方法来说简单很多。
- 能揭示复杂结构:LLE能够从高维数据中揭示出复杂的非线性结构。
限制
- 邻居选择敏感性:LLE的性能对邻居的选择很敏感,错误的选择可能导致较差的降维结果。
- 不适合分布不均的数据:如果数据在不同区域的密度差异很大,LLE可能无法良好地工作。
- 优化问题可能难以求解:在寻找低维表示时,可能会遇到一些困难,比如局部最小值问题。
总地来说,局部线性嵌入是一种有效的降维技术,尤其适合分析和可视化位于低维流形上的高维数据。尽管如此,它仍然存在一些局限性,例如对参数选择的敏感性和在处理某些类型数据时的表现。
拉普拉斯特征映射(Laplacian Eigenmaps)
拉普拉斯特征映射(Laplacian Eigenmaps)是一种非线性降维技术,用于发现高维数据中的低维结构。这种方法基于图论,特别是利用图的拉普拉斯矩阵来捕捉数据点之间的局部邻域关系。Laplacian Eigenmaps的目标是在低维空间中找到数据点的表示,使得局部邻域内的点在低维空间中的距离尽可能小。
基本步骤
-
构建邻域图:首先,对于数据集中的每个点,确定其最近的邻居(使用欧氏距离或其他距离度量)。这些邻居构成了该点的局部邻域。然后,构建一个图,其中数据点是节点,而边连接每个点的邻居。边的权重通常基于点之间的相似性或距离。
-
计算拉普拉斯矩阵:拉普拉斯矩阵L定义为L = D - W,其中D是度矩阵(对角矩阵,其对角线元素是图中每个节点的边的权重之和),W是权重矩阵(表示图中边的权重)。
-
特征映射:通过求解拉普拉斯矩阵的最小非平凡特征值对应的特征向量来找到低维表示。具体来说,我们寻找满足以下优化问题的特征向量:
[ \min_{f} \sum_{i, j} (f(x_i) - f(x_j))^2 W_{ij} ]
约束条件是:
[ \sum_i f(x_i) = 0 ]
和
[ \sum_i f^2(x_i) = 1 ]
通常,我们取第二小的特征值(即拉普拉斯算子的第二小的特征值,也称为Fiedler值)对应的特征向量作为一维表示,而取接下来的几个最小特征值对应的特征向量作为多维表示。
关键特点
- 局部邻域保持:Laplacian Eigenmaps特别关注保持数据点之间的局部邻域关系,而不是全局距离。
- 非线性降维:这种方法能够揭示数据中的非线性结构。
- 图论基础:算法的核心是基于图的拉普拉斯矩阵,这使得它能够有效地处理复杂的数据结构。
优势
- 揭示复杂结构:Laplacian Eigenmaps能够有效地揭示嵌入在高维空间中的复杂非线性流形。
- 简单且直观:算法的实现相对简单,且其原理直观易懂。
限制
- 参数敏感性:算法的性能可能对邻居的选择和边的权重定义敏感。
- 计算成本:对于大型数据集,计算拉普拉斯矩阵的特征向量可能非常耗时。
- 不适用于噪声数据:Laplacian Eigenmaps可能不适用于包含大量噪声或异常值的数据集。
总的来说,拉普拉斯特征映射是一种强大的非线性降维技术,特别适合于分析和可视化位于低维流形上的高维数据。然而,它的计算成本和参数敏感性限制了其在某些情况下的应用。
t-分布随机邻域嵌入(t-SNE)
t-分布随机邻域嵌入(t-SNE)是一种流行的非线性降维技术,特别适用于可视化高维数据。由Laurens van der Maaten和Geoffrey Hinton在2008年提出,t-SNE通过在低维空间中模拟高维数据点之间的相似性分布来工作。这种方法在可视化高维数据集(如文本数据、图像数据和生物信息数据)时非常有效。
基本步骤
-
测量高维空间中的相似性:首先,计算高维空间中每对数据点之间的相似性。这通常通过计算点之间的条件概率来实现,其中每个点与其最近邻居的相似性较高。使用高斯分布来定义这种相似性,即:
p j ∣ i = exp ( − ∣ ∣ x i − x j ∣ ∣ 2 / 2 σ i 2 ) ∑ k ≠ i exp ( − ∣ ∣ x i − x k ∣ ∣ 2 / 2 σ i 2 ) p_{j|i} = \frac{\exp(-||x_i - x_j||^2 / 2\sigma_i^2)}{\sum_{k \neq i} \exp(-||x_i - x_k||^2 / 2\sigma_i^2)} pj∣i=∑k=iexp(−∣∣xi−xk∣∣2/2σi2)exp(−∣∣xi−xj∣∣2/2σi2)
其中, σ i \sigma_i σi 是根据数据点 x i x_i xi 的邻居数量动态确定的参数。 -
定义低维表示的相似性:在低维空间中(通常是二维或三维),为每对点定义相似性。这里使用t分布(自由度为1的t分布,即柯西分布)来定义相似性,以避免在低维表示中出现拥挤问题:
q i j = ( 1 + ∣ ∣ y i − y j ∣ ∣ 2 ) − 1 ∑ k ≠ l ( 1 + ∣ ∣ y k − y l ∣ ∣ 2 ) − 1 q_{ij} = \frac{(1 + ||y_i - y_j||^2)^{-1}}{\sum_{k \neq l} (1 + ||y_k - y_l||^2)^{-1}} qij=∑k=l(1+∣∣yk−yl∣∣2)−1(1+∣∣yi−yj∣∣2)−1
其中, y i y_i yi 和 y j y_j yj是数据点 x i x_i xi 和 x j x_j xj 在低维空间中的表示。 -
优化:通过最小化高维空间中的相似性分布和低维空间中的相似性分布之间的Kullback-Leibler散度(KL散度)来找到最佳的低维表示。这通常通过梯度下降法来实现。
关键特点
- 非线性映射:t-SNE能够捕捉和映射高维数据中的复杂非线性结构。
- 局部结构保持:t-SNE特别关注保持数据点之间的局部结构,即相似的点在低维空间中应该靠近。
- 对异常值鲁棒:由于使用t分布来定义低维空间中的相似性,t-SNE对异常值相对鲁棒。
优势
- 高维数据可视化:t-SNE在可视化高维数据集方面非常有效,能够揭示数据中的簇和结构。
- 灵活性:t-SNE可以灵活地应用于各种类型的数据,包括文本、图像和生物信息数据。
限制
- 计算成本高:t-SNE的计算成本相对较高,特别是在处理大型数据集时。
- 参数敏感性:t-SNE的性能对参数(如困惑度)的选择敏感。
- 不适用于特征选择或降维:t-SNE主要用于可视化,而不是用于特征选择或作为其他机器学习算法的预处理步骤。
总的来说,t-SNE是一种强大的非线性降维技术,特别适合于可视化高维数据集。尽管其计算成本较高且对参数敏感,但它在揭示数据中的复杂结构方面表现出色。
统一流形近似和投影(UMAP)
统一流形近似和投影(UMAP,Uniform Manifold Approximation and Projection)是一种相对较新的非线性降维和数据可视化技术,由Leland McInnes、John Healy和James Melville在2018年提出。UMAP基于黎曼几何和代数拓扑的理论,旨在高效地找到高维数据的低维表示,同时保持数据的局部和全局结构。
基本步骤
-
构建高维空间中的图:首先,UMAP通过计算数据点之间的距离来构建一个图。这个图的节点是数据点,而边则根据距离来确定。边的权重通常基于高斯核函数,即:
[ \exp(-||x_i - x_j||^2 / 2\sigma^2) ]
其中,( \sigma ) 是一个根据数据点的局部密度动态确定的参数。 -
图的简化:UMAP使用模糊集合的概念来简化这个图。每个数据点被视为一个模糊集合,其隶属度由边的权重决定。通过这种方式,UMAP能够在保持数据局部结构的同时,减少计算复杂度。
-
低维表示:在低维空间中(通常是二维或三维),UMAP尝试找到一个图,该图的节点是高维数据点的低维表示,而边则基于点之间的距离。这个低维图应该尽可能地保持高维图的拓扑结构。
-
优化:通过最小化高维图和低维图之间的交叉熵来找到最佳的低维表示。这通常通过梯度下降法来实现。
关键特点
- 高效性:UMAP在计算上比t-SNE更高效,特别是在处理大型数据集时。
- 全局结构保持:UMAP不仅关注保持数据的局部结构,还尝试保持全局结构,这使得它在揭示数据的全局分布方面更为有效。
- 参数较少:UMAP通常需要较少的参数调整,这使得它更易于使用。
优势
- 速度快:UMAP的计算速度通常比t-SNE快,特别是在大型数据集上。
- 可扩展性:UMAP能够有效地处理大型数据集,这使得它在实际应用中非常有用。
- 全局和局部结构保持:UMAP在保持数据的局部结构的同时,也关注全局结构,这有助于更好地理解数据的整体分布。
限制
- 理论基础复杂:UMAP的理论基础涉及黎曼几何和代数拓扑,这可能对一些用户来说较为复杂。
- 可视化效果可能不如t-SNE:虽然UMAP在速度和可扩展性方面有优势,但在某些情况下,其可视化效果可能不如t-SNE直观。
总的来说,UMAP是一种强大的非线性降维技术,特别适合于处理大型数据集。它在速度和可扩展性方面优于t-SNE,但在可视化效果方面可能略有不足。UMAP的广泛应用证明了其在数据分析和机器学习领域的重要性。
相关文章:
)
流形学习(Manifold Learning)
基本概念 Manifold Learning(流形学习)是一种机器学习和数据分析的方法,它专注于从高维数据中发现低维的非线性结构。流形学习的基本假设是,尽管数据可能在高维空间中呈现,但它们实际上分布在一个低维的流形上。这个流…...

区块链技术和应用
文章目录 前言 一、区块链是什么? 二、区块链核心数据结构 2.1 交易 2.2 区块 三、交易 3.1 交易的生命周期 3.2 节点类型 3.3 分布式系统 3.4 节点数据库 3.5 智能合约 3.6 多个记账节点-去中心化 3.7 双花问题 3.8 共识算法 3.8.1 POW工作量证明 总结 前言 学习长…...

Docker拉取镜像报错:x509: certificate has expired or is not yet v..
太久没有使用docker进行镜像拉取,今天使用docker-compose拉取mongo发现报错(如下图): 报错信息翻译:证书已过期或尚未有效。 解决办法: 1.一般都是证书问题或者系统时间问题导致,可以先执行 da…...
猫狗分类识别模型建立②模型建立
一、导入依赖库 pip install opencv-python pip install numpy pip install tensorflow pip install keras 二、模型建立 pip install opencv-python pip install numpy pip install tensorflow pip install kerasimport os import xml.etree.ElementTree as ETimpor…...
(二十一))
React Native 之 ToastAndroid(提示语)(二十一)
ToastAndroid 是 React Native 提供的一个特定于 Android 平台的 API,用于显示简单的消息提示(Toast)。 两个方法: 1. ToastAndroid.show(message, duration, gravity) message: 要显示的文本消息。duration: Toast 的持续时间&…...

合约之间调用-如何实现函数静态调用?
合约之间的函数调用 EOA,external owned account,外部账号,例如metamask调用最终总是由EOA发起的合约之间的调用使得一次完整的调用成为一个调用链条 合约间调用过程 调用者须持有被调用合约的地址得到被调用合约的信息将地址重载为被调用合…...
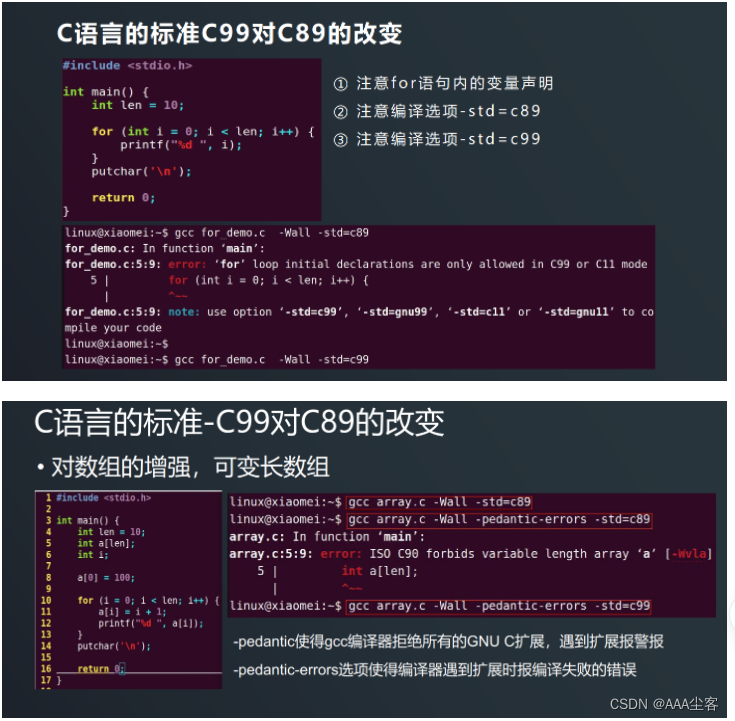
【5.基础知识和程序编译及调试】
一、GCC概述:是GUN推出的多平台编译器,可将C/C源程序编译成可执行文件。编译流程分为以下四个步骤: 1、预处理 2、编译 3、汇编 4、链接 注:编译器根据程序的扩展名来分辨编写源程序所用的语言。根据不同的后缀名对他们进行相…...
)
微信小程序(路由传参)
微信小程序的路由系统和其他Web应用类似,主要通过页面路径和URL参数进行页面导航和数据传递。下面详细介绍微信小程序路由的基本使用方法和相关技巧。 1. 基本页面导航 1.1 配置页面路径 在微信小程序的 app.json 文件中,需要配置小程序的页面路径。这…...

电脑显示不出网络
你的电脑是否在开机后显示不出网络,或者有网络消失的现象?今天和大家分享我学到的一个办法,希望对大家有用。 分析出现这类现象的原因:可能是电脑网卡松动了,电脑中存在静电流。 解决办法:先将电脑关机&am…...

random模块一
random模块 用于生成随机数。 random()返回[0,1)之间随机浮点数 例子: import randomfor i in range(5):print(random.random()) 结果: 0.5026620465128847 0.9841750667006002 0.5515465602585887 0.42796563433917456 0.2627959451391586 see…...

Spring OAuth2:开发者的安全盾牌!(下)
上文我们教了大家如何像海盗一样寻找宝藏,一步步解锁令牌的奥秘,今天将把更加核心的技巧带给大家一起学习,共同进步! 文章目录 6. 客户端凭证与密码模式6.1 客户端凭证模式应用适用于后端服务间通信 6.2 密码模式考量直接传递用户…...

kotlin基础之协程
Kotlin协程(Coroutines)是Kotlin提供的一种轻量级的线程模型,它允许我们以非阻塞的方式编写异步代码,而无需使用回调、线程或复杂的并发API。协程是一种用户态的轻量级线程,它可以在需要时挂起和恢复,从而有…...

法那科机器人M-900iA维修主要思路
发那科工业机器人是当今制造业中常用的自动化设备之一,而示教器是发那科机器人操作和维护的重要组成部分。 一、FANUC机械手示教器故障分类 1. 硬件故障 硬件故障通常是指发那科机器人M-900iA示教器本身的硬件问题,如屏幕损坏、按键失灵、电源故障等。 2…...
01_Spring Ioc(详解) + 思维导图
文章目录 一.概念实操Maven父子工程 二. IOC和DI入门案例【重点】1 IOC入门案例【重点】问题导入1.1 门案例思路分析1.2 实现步骤2.1 DI入门案例思路分析2.2 实现步骤2.3 实现代码2.4 图解演示 三、Bean的基础配置问题导入问题导入1 Bean是如何创建的【理解】2 实例化Bean的三种…...

Python开发Android手机APP
Kivy是一个开源的Python库,用于快速开发跨平台的触摸应用程序。它特别适合创建具有图形用户界面(GUI)的应用,尤其是那些需要在多种操作系统(如Windows、macOS、Linux、Android和iOS)上运行的多点触控应用。…...
Spring Cache自定义缓存key和过期时间
一、自定义全局缓存key和双冒号替换 使用 Redis的客户端 Spring Cache时,会发现生成 key中会多出一个冒号,而且有一个空节点的存在。 查看源码可知,这是因为 Spring Cache默认生成key的策略就是通过两个冒号来拼接。 同时 Spring Cache缓存…...

条件竞争漏洞
条件竞争漏洞 postMessage的客户端竞争条件 Summary AppCache可以被利用来强制浏览器加载后备的HTML页面,允许像Cookie填充(stuffing)这样的攻击,迫使出错并泄露敏感的URL。在负责任披露后,这个问题已经在各大浏览器中得到修复。对AWS S3和Google Cloud等云存储的上传策略(u…...

磁带存储:“不老的传说”依然在继续
现在是一个数据指数增长的时代,根据IDC数据预测,2025年全世界将产生175ZB的数据。 这里面大部分数据是不需要存储的,在2025预计每年需要存储11ZB的数据。换算个容易理解的说法,1ZB是10^18Bytes, 相当于要写5556万块容量18TB的硬盘…...

CentOS8环境下FTP服务器安装与配置
在本指南中,我们将一步步介绍如何在CentOS 8环境下安装和配置一个FTP服务器。FTP(文件传输协议)是一种网络传输协议,用于在网络中的计算机之间传输文件。虽然现在有更安全的传输方式,如SFTP或FTP over SSL,…...

C# 元组 Tuple
C# 元组 Tuple 元组创建元组访问元组元素命名元组元素元组的类型使用元组作为方法返回值 解构解构元组的基本用法解构部分元组解构方法 元组 在C#中,元组(Tuple)是一种数据结构,它允许你将多个值组合成一个单一的对象。 元组在处…...

免费Windows桌面分区工具NoFences:3分钟打造高效工作空间
免费Windows桌面分区工具NoFences:3分钟打造高效工作空间 【免费下载链接】NoFences 🚧 Open Source Stardock Fences alternative 项目地址: https://gitcode.com/gh_mirrors/no/NoFences 还在为杂乱无章的Windows桌面而烦恼吗?NoFen…...

在Google Cloud上构建OpenAI兼容API网关:无缝对接Vertex AI模型
1. 项目概述:在Google Cloud上搭建你自己的OpenAI兼容API网关 如果你正在寻找一种方法,能够让你手头那些原本为OpenAI ChatGPT设计的应用,无缝对接上Google Cloud Vertex AI的强大模型,比如Gemini Pro、PaLM 2或者Codeyÿ…...

9.实战案例拆解
好的,我们开始。先别急着看那些“月入十万”的爽文,我这边先给你看一段我昨晚在调试一个树莓派Pico W的I2C总线时,在终端里敲出来的报错信息: [ERROR] I2C timeout: SDA line held low by device at 0x3C这条错误让我折腾了半小时。最后发现是传感器模块的电源纹波太大,导…...

Lie群方法在机器人状态估计中的创新应用
1. 状态估计技术演进与Lie群方法的核心价值在机器人导航与定位领域,状态估计技术扮演着大脑的角色。想象一下,当你在陌生城市使用手机导航时,系统需要实时融合GPS、陀螺仪和加速度计的数据来确定你的位置——这正是状态估计的典型应用场景。传…...

OpenFOAM-dev后处理与数据可视化:ParaView与fieldFunctionObjects实战指南
OpenFOAM-dev后处理与数据可视化:ParaView与fieldFunctionObjects实战指南 【免费下载链接】OpenFOAM-dev OpenFOAM Foundation development repository 项目地址: https://gitcode.com/gh_mirrors/op/OpenFOAM-dev OpenFOAM-dev作为开源CFD领域的核心工具&a…...

告别WSL安装玄学:从0x80072f78到0x800701bc,一次搞懂Windows 11下的完整避坑指南
从0x80072f78到0x800701bc:Windows 11下WSL完整避坑手册 每次在Windows 11上安装WSL时,那些神秘的错误代码是否让你抓狂?0x80072f78、0x800701bc...它们像是一道道密码,阻挡着你进入Linux开发环境的大门。作为长期在Windows和Linu…...

Cursor免费版高效使用指南:配置优化与本地工具链整合
1. 项目概述与核心价值最近在开发者圈子里,关于AI编程工具的讨论热度一直居高不下。Cursor作为一款深度集成AI能力的代码编辑器,凭借其强大的代码生成、理解和重构功能,迅速成为了许多程序员提升效率的“新宠”。然而,其Pro版本需…...

1.7.3 掌握Scala函数 - 神奇占位符
本次Scala函数实战主要聚焦于“神奇占位符”下划线(_)的灵活运用,通过三个递进的案例深入理解其简化代码的核心作用。 演示过滤列表:利用 filter 方法,对比了常规匿名函数与使用占位符的写法,直观展示了如何…...

数据可视化项目架构全解析:从核心原理到React+ECharts工程实践
1. 项目概述:数据可视化的价值与“SKY-lv/data-visualization”的定位在数据驱动的时代,我们每天都被海量的信息包围。无论是业务报表、用户行为日志,还是传感器采集的时序数据,它们本身只是一堆冰冷的数字。如何让这些数据“开口…...

网页项目之大五人格测试:认识真实的自己
大五人格测试:认识真实的自己 你是否曾好奇,自己的人格特质是什么?为什么有些人天生善于社交,有些人却更喜欢独处?为什么有人总是追求完美,有些人却随性自在? 心理学研究表明,人格的…...