Kafka原生API使用Java代码-生产者-分区策略-默认分区策略轮询分区策略
文章目录
- 1、代码演示
- 1.1、pom.xml
- 1.2、KafkaProducerPartitioningStrategy.java
- 1.2.1、ProducerConfig.LINGER_MS_CONFIG取 0 值得情况,不轮询
- 1.2.2、ProducerConfig.LINGER_MS_CONFIG取 0 值得情况,轮询
- 1.2.3、ProducerConfig.LINGER_MS_CONFIG取 1000 值得情况,轮询
- 1.2.4、ProducerConfig.LINGER_MS_CONFIG取 1000 值得情况,不轮询
- 2、分区策略
- 2.1、linger.ms参数的含义
- 2.2、linger milliseconds
- 2.3、linger.ms配置参数的理解
1、代码演示
1.1、pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>3.0.5</version><relativePath/> <!-- lookup parent from repository --></parent><!-- Generated by https://start.springboot.io --><!-- 优质的 spring/boot/data/security/cloud 框架中文文档尽在 => https://springdoc.cn --><groupId>com.atguigu.kafka</groupId><artifactId>kafka-producer</artifactId><version>0.0.1-SNAPSHOT</version><name>kafka-producer</name><description>kafka-producer</description><properties><java.version>17</java.version></properties><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>3.0.0</version></dependency></dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId></plugin></plugins></build></project>1.2、KafkaProducerPartitioningStrategy.java
1.2.1、ProducerConfig.LINGER_MS_CONFIG取 0 值得情况,不轮询
不等待,不轮询,默认分区策略
package com.atguigu.kafka.producer;
import org.apache.kafka.clients.producer.*;
import java.util.Properties;
import java.util.UUID;
public class KafkaProducerPartitioningStrategy {public static void main(String[] args) {// 初始化Kafka生产者配置Properties props = new Properties();props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.74.148:9092"); // 指定Kafka broker的地址和端口// 确认消息写入策略,"acks"设置为all表示所有副本都确认消息接收后才会响应props.put("acks", "all");// 消息发送失败时的重试次数,设置为0表示不重试props.put("retries", 0);// 发送缓冲区等待时间,等待1秒后,发送//props.put(ProducerConfig.LINGER_MS_CONFIG, 1000);props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // 指定键的序列化器props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // 指定值的序列化器// 分区器选择RoundRobinPartitioner,实现消息在主题分区间的轮询分配//props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, "org.apache.kafka.clients.producer.RoundRobinPartitioner" );// 创建Kafka生产者实例Producer<String, String> producer = new KafkaProducer<>(props);for (int i = 0; i < 1000; i++) {producer.send(new ProducerRecord<String, String>("my_topic3", "88"), new Callback() {@Overridepublic void onCompletion(RecordMetadata recordMetadata, Exception e) {if (e == null) {System.out.println("recordMetadata.partition() = " + recordMetadata.partition());}}});}producer.close();}
}
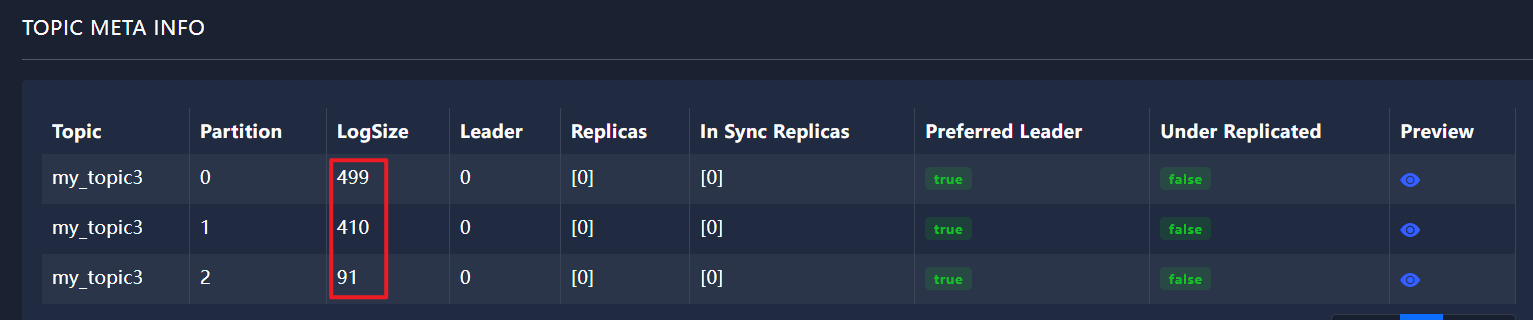
1.2.2、ProducerConfig.LINGER_MS_CONFIG取 0 值得情况,轮询
不等待,立即发送,轮询策略
package com.atguigu.kafka.producer;
import org.apache.kafka.clients.producer.*;
import java.util.Properties;
import java.util.UUID;
public class KafkaProducerPartitioningStrategy {public static void main(String[] args) {// 初始化Kafka生产者配置Properties props = new Properties();props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.74.148:9092"); // 指定Kafka broker的地址和端口// 确认消息写入策略,"acks"设置为all表示所有副本都确认消息接收后才会响应props.put("acks", "all");// 消息发送失败时的重试次数,设置为0表示不重试props.put("retries", 0);// 发送缓冲区等待时间,设置为0表示不等待,立即发送props.put(ProducerConfig.LINGER_MS_CONFIG, 0); props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // 指定键的序列化器props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // 指定值的序列化器// 分区器选择RoundRobinPartitioner,实现消息在主题分区间的轮询分配props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, "org.apache.kafka.clients.producer.RoundRobinPartitioner" );// 创建Kafka生产者实例Producer<String, String> producer = new KafkaProducer<>(props);for (int i = 0; i < 1000; i++) {producer.send(new ProducerRecord<String, String>("my_topic3", "88"), new Callback() {@Overridepublic void onCompletion(RecordMetadata recordMetadata, Exception e) {if (e == null) {System.out.println("recordMetadata.partition() = " + recordMetadata.partition());}}});}producer.close();}
}
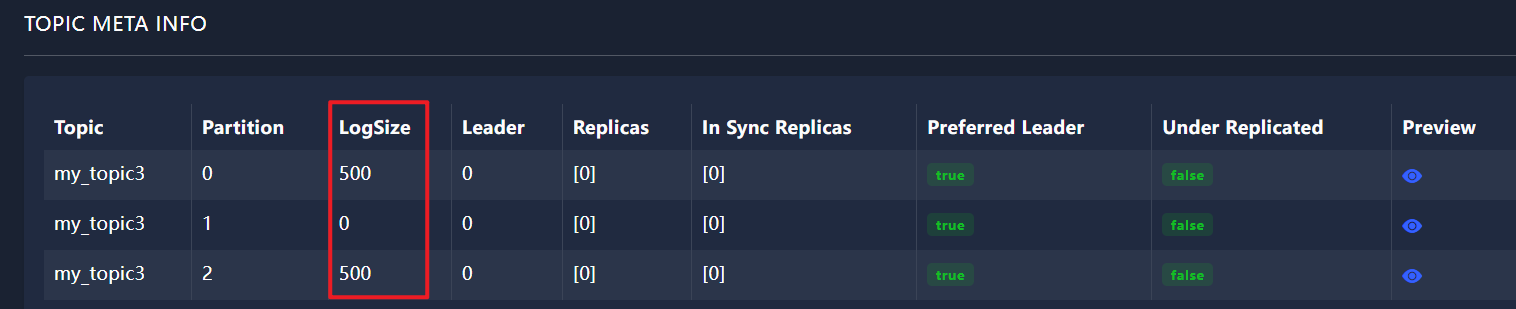
1.2.3、ProducerConfig.LINGER_MS_CONFIG取 1000 值得情况,轮询
等待1秒后发送,轮询策略
package com.atguigu.kafka.producer;
import org.apache.kafka.clients.producer.*;
import java.util.Properties;
import java.util.UUID;
public class KafkaProducerPartitioningStrategy {public static void main(String[] args) {// 初始化Kafka生产者配置Properties props = new Properties();props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.74.148:9092"); // 指定Kafka broker的地址和端口// 确认消息写入策略,"acks"设置为all表示所有副本都确认消息接收后才会响应props.put("acks", "all");// 消息发送失败时的重试次数,设置为0表示不重试props.put("retries", 0);// 发送缓冲区等待时间,等待1秒后,发送props.put(ProducerConfig.LINGER_MS_CONFIG, 1000);props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // 指定键的序列化器props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // 指定值的序列化器// 分区器选择RoundRobinPartitioner,实现消息在主题分区间的轮询分配props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, "org.apache.kafka.clients.producer.RoundRobinPartitioner" );// 创建Kafka生产者实例Producer<String, String> producer = new KafkaProducer<>(props);for (int i = 0; i < 1000; i++) {producer.send(new ProducerRecord<String, String>("my_topic3", "88"), new Callback() {@Overridepublic void onCompletion(RecordMetadata recordMetadata, Exception e) {if (e == null) {System.out.println("recordMetadata.partition() = " + recordMetadata.partition());}}});}producer.close();}
}
1.2.4、ProducerConfig.LINGER_MS_CONFIG取 1000 值得情况,不轮询
等待1秒后发送,不轮询
package com.atguigu.kafka.producer;
import org.apache.kafka.clients.producer.*;
import java.util.Properties;
import java.util.UUID;
public class KafkaProducerPartitioningStrategy {public static void main(String[] args) {// 初始化Kafka生产者配置Properties props = new Properties();props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.74.148:9092"); // 指定Kafka broker的地址和端口// 确认消息写入策略,"acks"设置为all表示所有副本都确认消息接收后才会响应props.put("acks", "all");// 消息发送失败时的重试次数,设置为0表示不重试props.put("retries", 0);// 发送缓冲区等待时间,等待1秒后,发送props.put(ProducerConfig.LINGER_MS_CONFIG, 1000);props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // 指定键的序列化器props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // 指定值的序列化器// 分区器选择RoundRobinPartitioner,实现消息在主题分区间的轮询分配//props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, "org.apache.kafka.clients.producer.RoundRobinPartitioner" );// 创建Kafka生产者实例Producer<String, String> producer = new KafkaProducer<>(props);for (int i = 0; i < 1000; i++) {producer.send(new ProducerRecord<String, String>("my_topic3", "88"), new Callback() {@Overridepublic void onCompletion(RecordMetadata recordMetadata, Exception e) {if (e == null) {System.out.println("recordMetadata.partition() = " + recordMetadata.partition());}}});}producer.close();}
}
2、分区策略
kafka的生产者分区策略
默认分区策略:减少重新建立分区连接的性能损耗 开发使用最多的分区方式,采用黏性分区,默认向第一次连接上的主题分区发送消息,直到消息累积到 batch.size大小(16kb)轮询分区策略:每个分区接收一次消息(linger.ms决定生产者一次批量发送多少条消息 到一个分区中),开发中一定不会用轮询分区策略,顶多自定义,因为轮询性能太差,频繁跟不同的分区建立连接,大数据会用轮询策略
2.1、linger.ms参数的含义
在Kafka的生产者(Producer)配置中,props.put("linger.ms", 1); 这行代码是用于设置生产者的linger.ms参数的。
linger.ms参数的含义是:生产者会在发送消息之前等待更多消息被发送到同一个分区(partition)的额外时间(以毫秒为单位)。这样做的目的是为了提高吞吐量,因为将多个消息批量发送到同一个分区可以减少网络传输的开销和服务器端的I/O开销。
具体来说,当你设置了linger.ms参数(比如设置为1毫秒),Kafka生产者会尝试在发送消息之前等待1毫秒,看看是否还有其他的消息要发送到同一个分区。如果有,这些消息将会被合并成一个批次(batch)一起发送。
注意,设置linger.ms参数可能会增加消息的延迟,因为生产者会等待指定的时间以合并更多的消息。所以,这个参数需要在吞吐量和延迟之间进行权衡。
这里是一个简化的示例,展示如何在使用Java Kafka生产者时设置linger.ms参数:
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;import java.util.Properties;public class KafkaProducerExample {public static void main(String[] args) {Properties props = new Properties();props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");// 设置linger.msprops.put("linger.ms", 1);KafkaProducer<String, String> producer = new KafkaProducer<>(props);// 发送消息...producer.close();}
}
在这个示例中,我们创建了一个KafkaProducer对象,并设置了包括linger.ms在内的多个配置参数。然后,你可以使用这个生产者对象来发送消息到Kafka集群。
2.2、linger milliseconds
linger.ms 的英文全称就是 “linger milliseconds”,其中 “linger” 是指延迟或等待,“milliseconds” 是毫秒的意思。
在 Kafka 的 Producer 配置中,linger.ms 参数用于控制 Producer 在发送消息之前等待更多消息到达相同分区(partition)的时间,以便可以将这些消息一起发送,从而提高吞吐量。默认情况下,linger.ms 的值为 0,这意味着 Producer 收到消息后会立即发送,不进行任何延迟。
linger.ms 参数与 batch.size 参数一起使用时,可以实现更复杂的消息发送策略。batch.size 参数定义了单个批次(batch)中允许的最大消息字节数。当 Producer 收到消息时,它会尝试将消息添加到当前批次中。如果linger.ms 大于 0,并且当前批次中的消息数量尚未达到 batch.size 的限制,那么 Producer 会等待 linger.ms 指定的时间,看看是否还有更多的消息要发送到相同的分区。如果有,这些消息将被添加到当前批次中;如果没有,那么在当前时间到达后,Producer 将发送当前批次中的所有消息。
需要注意的是,linger.ms 参数的值应该根据具体的业务场景和性能需求进行调整。较小的值可以提高消息的实时性,但可能会降低吞吐量;较大的值可以提高吞吐量,但可能会增加消息的延迟。因此,在实际应用中需要根据实际情况进行权衡和选择。
2.3、linger.ms配置参数的理解
在Kafka中,linger.ms是一个配置参数,用于控制生产者(producer)在发送消息到broker之前的等待时间,以便将更多的消息累积到同一批次中,从而提高吞吐量。linger.ms的取值可以是任何非负整数,表示毫秒数。
以下是关于linger.ms的一些关键点:
- 如果
linger.ms设置为0,生产者会立即发送消息到broker,不会等待其他消息来累积到同一批次。 - 如果
linger.ms设置为大于0的值,生产者会等待该指定的毫秒数,或者直到达到batch.size(批次大小)的限制,然后将累积的消息作为一个批次发送到broker。 - 增大
linger.ms的值可能会提高吞吐量,因为可以累积更多的消息到同一批次中,减少网络传输的次数。但是,这也会增加消息的延迟。 linger.ms的取值可以根据具体的应用场景和需求进行调整。在需要低延迟的场景中,可以将linger.ms设置为较小的值;在可以容忍一定延迟的场景中,可以尝试增大linger.ms的值以提高吞吐量。
综上所述,linger.ms的取值并没有固定的几个选项,而是可以根据实际需求设置为任何非负整数。在配置Kafka生产者时,需要根据具体的业务场景和需求来选择合适的linger.ms值。
相关文章:
Kafka原生API使用Java代码-生产者-分区策略-默认分区策略轮询分区策略
文章目录 1、代码演示1.1、pom.xml1.2、KafkaProducerPartitioningStrategy.java1.2.1、ProducerConfig.LINGER_MS_CONFIG取 0 值得情况,不轮询1.2.2、ProducerConfig.LINGER_MS_CONFIG取 0 值得情况,轮询1.2.3、ProducerConfig.LINGER_MS_CONFIG取 1000…...
网页中的音视频裁剪拼接合并
一、需求描述 项目中有一个配音需求: 1)首先,前台会拿到一个英语视频,视频的内容是A和B用英语交流; 2)然后,用户可以选择为某一个角色配音,假如选择为A配音,那么视频在播…...

【入门】使用sklearn实现的KNN算法:鸢尾花数据集分类预测
目录 前言 第一步:安装和导入sklean模块 第二步:获取数据 第二步:分割出训练集和测试集 第三步:训练模型 第四步:测试结果 总结 前言 本文将介绍如何利用K最近邻(KNN)算法对经典的鸢尾花数…...
nss做题
[NCTF 2018]签到题 1.f12在index.php中找到flag [NSSCTF 2022 Spring Recruit]ezgame 1.在js源码中就有flag [UUCTF 2022 新生赛]websign 1.打开环境后发现ctrlu和右键,f12都被禁用了。两种方法,第一种:禁用js;第二中提前打开…...

第18章:JDK8-17新特性
1. 新特性概述 > 角度1:新的语法规则 (多关注)比如:lambda表达式、enum、annotation、自动拆箱装箱、接口中的默认方法和静态方法、switch表达式、record等> 角度2:增加、过时、删除API比如:新的日期…...
)
哈希表练习题(2024/5/29)
1有效的字母异位词 给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的字母异位词。 注意:若 s 和 t 中每个字符出现的次数都相同,则称 s 和 t 互为字母异位词。 示例 1: 输入: s "anagram", t "nagaram" 输…...

java —— 连接 MySQL 操作
MySQL 是独立于 java 之外的数据库,二者之间建立连接需要提前引入 mysql-connector-java 的 jar 包。 一、引入方法: ① 在项目中新建一个 Folder(即文件夹),该文件夹通常命名为 lib,意思是存放项目所依赖…...
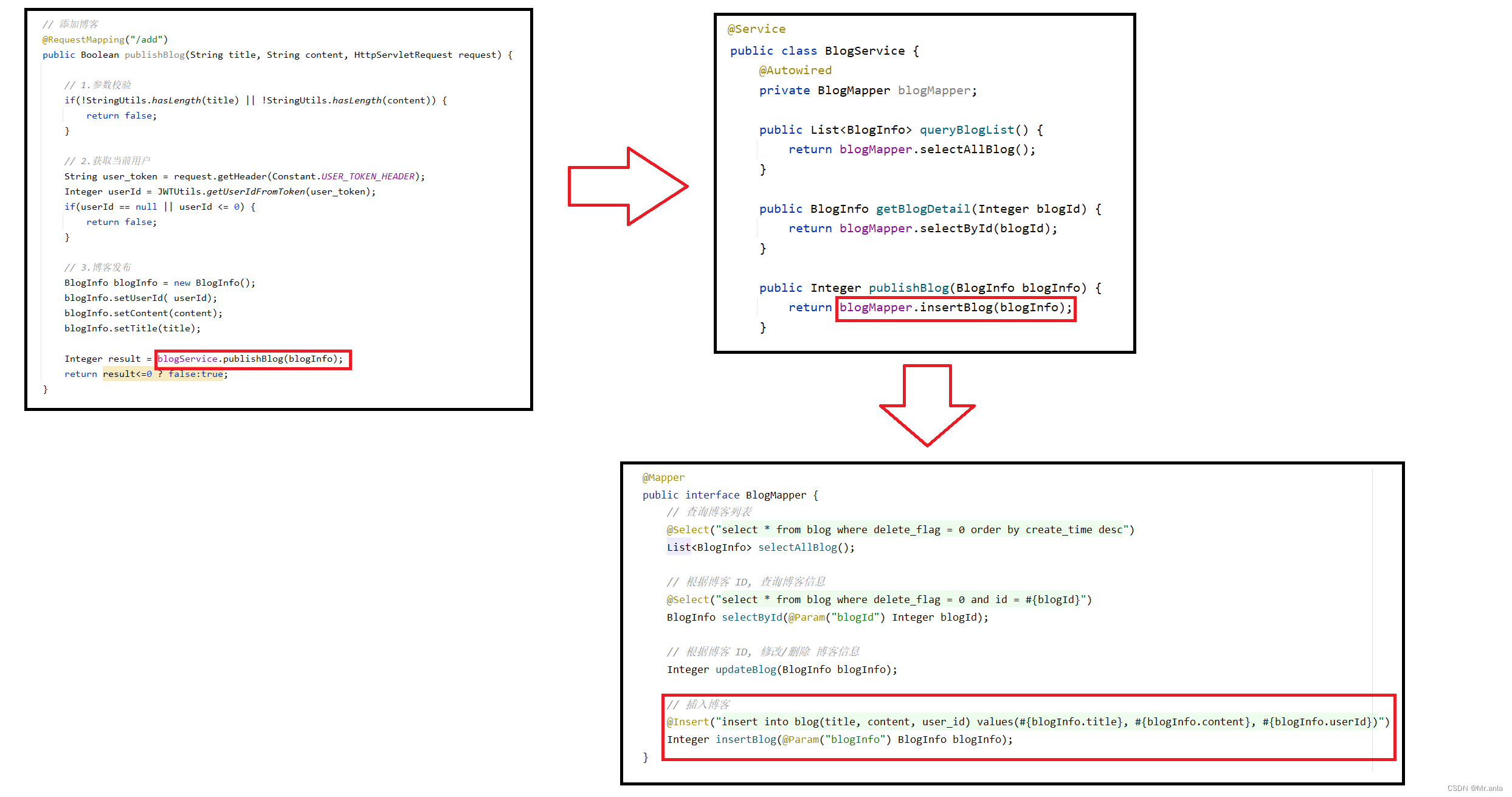
从 0 开始实现一个博客系统 (SSM 项目)
相关技术 Spring Spring Boot Spring MVC MyBatis Html Css JS pom 文件我就不放出来了, 之前用的 jdk8 做的, MySQL 用的 5.7, 都有点老了, 你们自己看着配版本就好 实现功能 用户注册 - 密码加盐加密 (md5 加密)前后端用户信息存储 - 令牌技术用户登录 - (使用 拦截…...
- C 内存管理库 - 分配并清零内存 (std::calloc))
C++标准模板(STL)- C 内存管理库 - 分配并清零内存 (std::calloc)
C 内存管理库 分配并清零内存 std::calloc void* calloc( std::size_t num, std::size_t size ); 分配 num 个大小为 size 的对象的数组,并初始化所有位为零。 若分配成功,则返回指向为任何对象类型适当对齐的,被分配内存块最低…...
)
嵌入式开发面试问题总结(持续更新)
面试问题总结 c/c 封装、继承和多态 封装:将属性和方法封装起来,并加以权限区分。继承:子类继承父类的特征和行为,复用了从基类复制而来的数据成员和成员函数(基类私有成员无法被访问),其中构…...
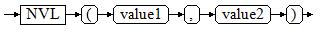
意外发现openGauss兼容Oracle的几个条件表达式
意外发现openGauss兼容Oracle的几个条件表达式 最近工作中发现openGauss在兼容oracle模式下,可以兼容常用的两个表达式,因此就随手测试了一下。 查看数据库版本 [ommopenGauss ~]$ gsql -r gsql ((openGauss 6.0.0-RC1 build ed7f8e37) compiled at 2…...

使用Keepalived提高吞吐量和负载均衡ip_hash.
一 . Nginx使用Keepalived提高吞吐量案例 Keepalived[表示把连接保持一定长连接数来提高吞吐量] 1.1没有使用keepalived参数 upstream tomcats {server 192.168.28.102:8080; } server {listen 88;server_name www.tomcats.com;location / {proxy_pass http://to…...

网络故障与排除(一)
一、Router-ID冲突导致OSPF路由环路 路由器收到相同Router-ID的两台设备发送的LSA,所以查看路由表看到的OSPF缺省路由信息就会不断变动。而当C1的缺省路由从C2中学到,C2的缺省路由又从C1中学到时,就形成了路由环路,因此出现路由不…...

C++之运算符重载
1、运算符重载 //Complex.h #ifndef _COMPLEX_H_ #define _COMPLEX_H_class Complex { public:Complex(int real_, int imag_);Complex();~Complex();Complex& Add(const Complex& other); void Display() const;Complex operator(const Complex& other);privat…...

使用springdoc-openapi-starter-webmvc-ui后访问swagger-ui/index.html 报错404
按照官网说明,引入 springdoc-openapi-starter-webmvc-ui后应该就可以直接访问swagger-ui.html或者swagger-ui/index.html就可以出现swagger页面了,但是我引入后,访问提示报错404. 在我的项目中,有其他依赖间接引入了org.webjars…...

深入理解计算机系统 家庭作业4.52
练习题4.3 p.254 \sim\seq\seq-full.hcl文件内已经说的很清楚了哪些不能更改,哪些是题目要求更改的控制逻辑块. 依据家庭作业4.51的答案,在seq-full.hcl文件内更改对应的HCL描述即可 以下答案注释了#changed的就是更改部分 #/* $begin seq-all-hcl */ ######################…...
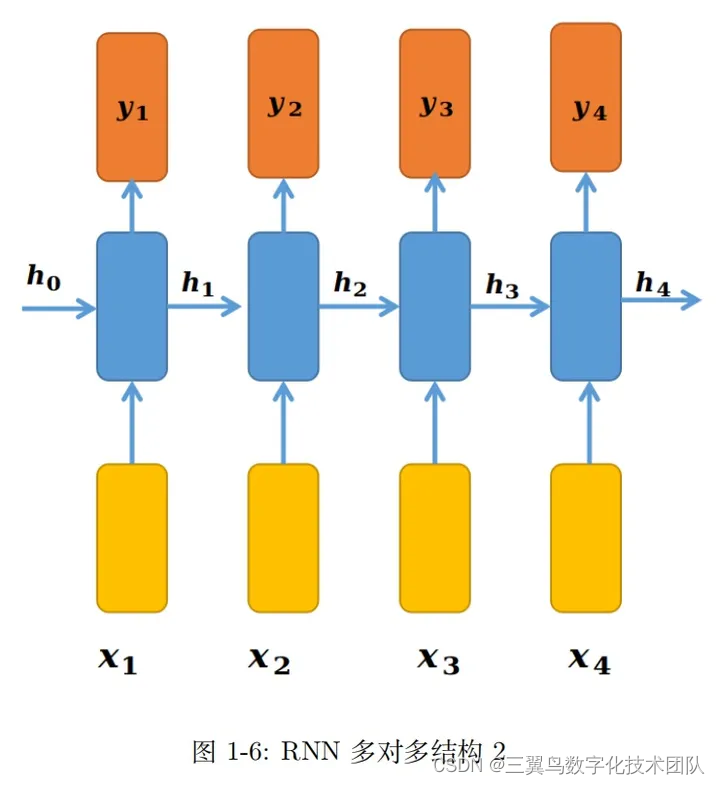
深度学习:手撕 RNN(2)-RNN 的常见模型架构
本文首次发表于知乎,欢迎关注作者。 上一篇文章我们介绍了一个基本的 RNN 模块。有了 这个 RNN 模块后,就像搭积木一样,以 RNN 为基本单元,根据不同的任务或者需求,可以构建不同的模型架构。本节介绍的所有结构&#…...
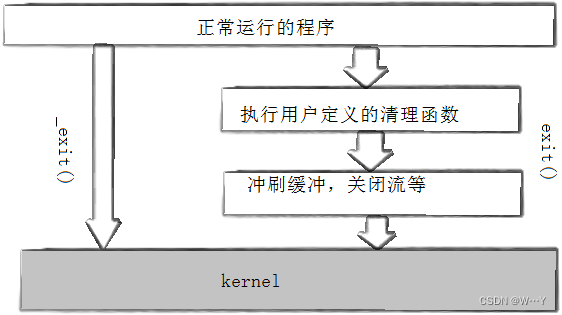
【Linux进程篇】Linux进程管理——进程创建与终止
W...Y的主页 😊 代码仓库分享💕 目录 进程创建 fork函数初识 写时拷贝 fork常规用法 fork调用失败的原因 进程终止 进程退出场景 _exit函数 exit函数 return退出 进程创建 fork函数初识 在linux中fork函数时非常重要的函数,它从已…...
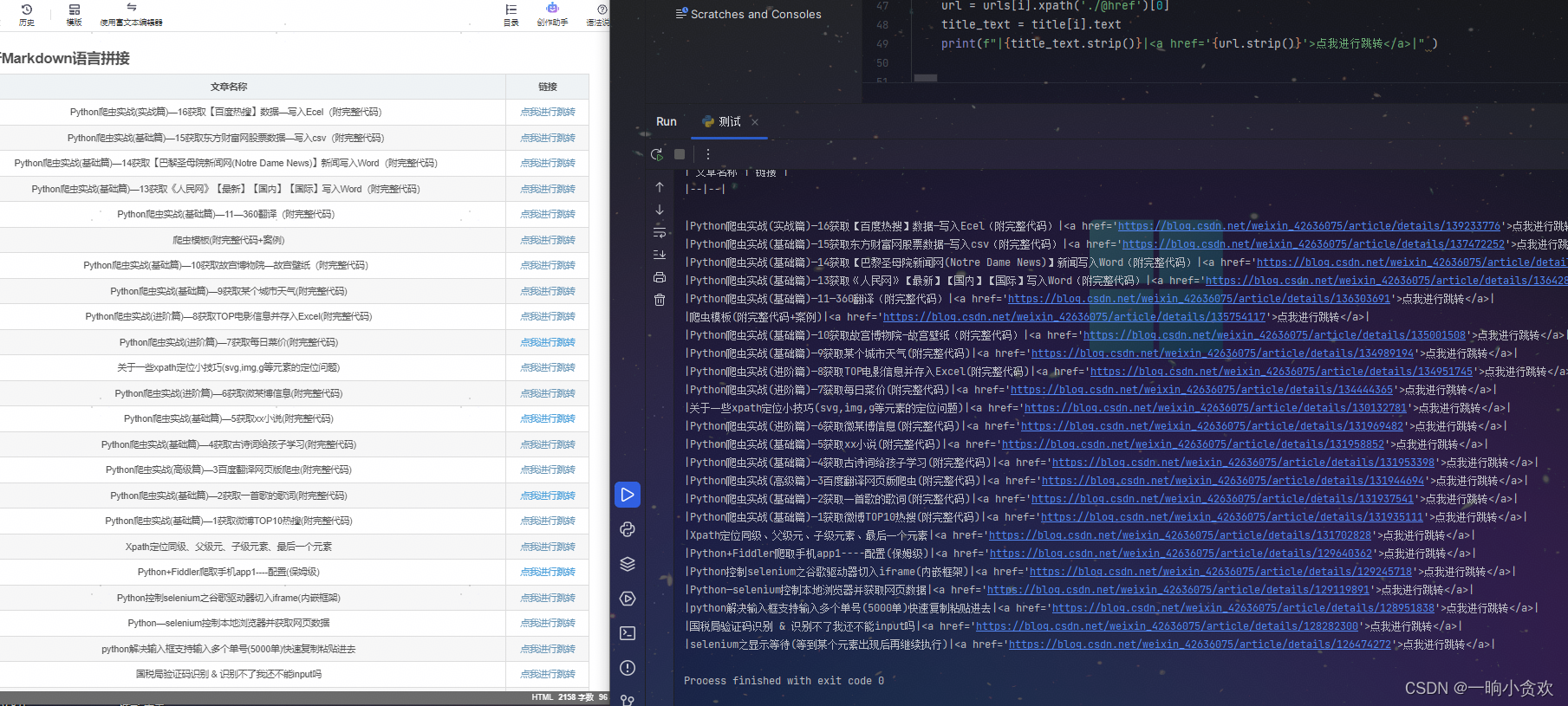
Python爬虫实战(实战篇)—17获取【CSDN某一专栏】数据转为Markdown列表放入文章中
文章目录 专栏导读背景结果预览1、页面分析2、通过返回数据发现适合利用lxmlxpath3、进行Markdown语言拼接总结 专栏导读 在这里插入图片描述 🔥🔥本文已收录于《Python基础篇爬虫》 🉑🉑本专栏专门针对于有爬虫基础准备的一套基…...

Go语言-big.Int
文章目录 Go 语言 big.Int应用场景:大整数位运算使用举例: go sdk中crypto/ecdsa 椭圆曲线生成私钥相关结构中就有使用 Go 语言 big.Int Go 语言 big.Int 参考URL: https://blog.csdn.net/wzygis/article/details/82867793 math/big 作为 Go 语言提供的…...

Windows-build-tools终极指南:5个步骤快速配置C++构建环境
Windows-build-tools终极指南:5个步骤快速配置C构建环境 【免费下载链接】windows-build-tools :package: Install C Build Tools for Windows using npm 项目地址: https://gitcode.com/gh_mirrors/wi/windows-build-tools Windows-build-tools是一个专为Wi…...

NAS极速搭建PostgreSQL:打造个人专属数据仓库
1. 为什么选择NASPostgreSQL组合? 最近几年,越来越多的技术爱好者开始在家用NAS上部署数据库服务。我自己从2018年开始尝试这种方案,先后测试过MySQL、MongoDB和PostgreSQL,最终发现PostgreSQL在NAS上的表现最为出色。相比云数据库…...

对比按需计费与 Token Plan 在 Taotoken 平台上的长期成本差异感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比按需计费与 Token Plan 在 Taotoken 平台上的长期成本差异感受 在构建和运营依赖大模型能力的应用时,成本控制是一…...

一款**AI + 工作流驱动**的跨平台低代码
图片页面预览 猫拽低代码是一款基于 Vue3 TypeScript Vite 构建的跨平台低代码平台,集成了可视化设计器、工作流引擎、AI 智能辅助三大核心能力,让你通过拖拽就能快速搭建小程序、H5 和 APP 应用。 官网:猫拽低代码平台:https…...

浏览器扩展开发实战:光标交互防火墙的设计与实现
1. 项目概述与核心价值最近在折腾浏览器插件开发,偶然在GitHub上看到了一个名为“Raidu Firewall Cursor Extension”的项目。光看这个名字,就让我这个对网络安全和效率工具都感兴趣的老码农眼前一亮。这玩意儿本质上是一个浏览器扩展,但它把…...

Wonder3D终极指南:如何用单张图片快速生成高质量3D模型
Wonder3D终极指南:如何用单张图片快速生成高质量3D模型 【免费下载链接】Wonder3D Single Image to 3D using Cross-Domain Diffusion for 3D Generation 项目地址: https://gitcode.com/gh_mirrors/wo/Wonder3D 你是否曾梦想过将一张普通的2D图片瞬间变成生…...

为Hermes Agent配置自定义Provider指向Taotoken聚合服务的操作方法
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为Hermes Agent配置自定义Provider指向Taotoken聚合服务的操作方法 Hermes Agent 是一个功能强大的AI代理框架,它支持通…...

联想M920x黑苹果EFI配置终极指南:轻松实现macOS完美兼容
联想M920x黑苹果EFI配置终极指南:轻松实现macOS完美兼容 【免费下载链接】M920x-Hackintosh-EFI Hackintosh Opencore EFIs for M920x 项目地址: https://gitcode.com/gh_mirrors/m9/M920x-Hackintosh-EFI 想要在联想M920x迷你主机上体验macOS系统吗…...

基于树莓派与AstroPrint搭建无线3D打印控制中心实战指南
1. 项目概述:为什么需要无线3D打印控制?如果你和我一样,是个喜欢折腾3D打印机的创客或爱好者,那你肯定经历过这样的场景:为了打印一个模型,需要先在电脑上用切片软件生成G-code文件,然后找到读卡…...

别再为LocalDateTime头疼了!SpringBoot 3.x全局配置Jackson与表单提交的完整避坑指南
SpringBoot 3.x日期处理终极指南:从Jackson到表单提交的全链路解决方案 每次看到控制台抛出Failed to convert from type [java.lang.String] to type [java.time.LocalDateTime]异常时,我都想对着屏幕大喊:"我知道日期格式应该是yyyy-M…...