大语言模型的工程技巧(三)——分布式计算
相关说明
这篇文章的大部分内容参考自我的新书《解构大语言模型:从线性回归到通用人工智能》,欢迎有兴趣的读者多多支持。
本文将讨论如何利用多台机器进行神经网络的分布式训练。利用多台机器来加速大语言模型的训练,是其获得成功的重要原因。
关于其他的工程技巧可以参考:
- 大语言模型的工程技巧(一)——GPU计算
- 大语言模型的工程技巧(二)——混合精度训练
关于大语言模型的内容,推荐参考这个专栏。
内容大纲
- 相关说明
- 一、概述
- 二、两种并行
- 三、数据并行
- 四、模型并行
- 五、代码实现
一、概述
本文将讨论如何巧妙地借助多台机器来优化模型训练和应用速度。在神经网络领域,常常利用GPU进行模型计算,以迅速提高计算效率。然而,正如大语言模型的工程技巧(一)——GPU计算所述,即使在同一台机器上,跨GPU的数据也无法直接运算。因此,对于分布式运算,多台机器之间的协作机制相当于不同GPU之间(不管它们是否在同一台机器上)的协作机制。为了表述简单,本节后续的讨论都只针对在多个GPU之间的分布式计算。
二、两种并行
模型计算的基础是计算图,因此,模型的分布式计算实质上就是在计算图层面进行分布式运算。关于这一主题,业界出现了两种截然不同的分布式计算方法,分别是数据并行(Data Parallelism)和模型并行(Model Parallelism)。数据并行,也就是梯度累积[TODO],它根据数据将计算图纵向切分,从而进行并行计算。与之不同,模型并行是将计算图的不同层放置在不同的GPU上进行计算。这可以被形象地理解为:数据并行将计算图从竖直方向切分,而模型并行从水平方向切分,如图1所示。

三、数据并行
在传统的观念里,模型的分布式计算意味着对数据的并行处理。这种方法的核心思想遵循著名的Map/Reduce框架1模式,如图2所示。首先,数据被智能地分发到各个GPU上。接着,完整的模型被逐一复制到每个GPU上。然后,这些GPU利用各自的数据进行向前传播和反向传播,这一系列步骤类似于“映射”(Map)操作。随后,执行“归约”(Reduce)操作(更确切地说是“All Reduce”操作2)。在这一阶段,算法将每个GPU上的反向传播梯度传递给其他GPU。简而言之,每个GPU都积累了所有GPU计算得出的梯度信息,能够独立地累加梯度,并进行后续的参数迭代更新。由于每个GPU上累加的梯度相同,因此在参数更新后得到的模型也是相同的。持续循环,直到得到最终的模型。这个过程确保了模型的并行训练和参数同步。

从每个GPU的角度来看,尽管每次迭代只处理批次数据中的一部分,但在Reduce阶段,通过梯度的传递,参与模型参数更新的梯度却基于整个批次的所有数据。换句话说,这个阶段汲取了批次中全部数据的智慧。这就好比一份试卷,一个班级的学生各自分工做不同的试题,然后相互交流答案,这样每个学生只解答了部分问题,却获得了全部答案。因此,即使硬件未经升级,GPU的学习速度也会更快,从而加速整个模型的训练过程。借助这种巧妙的分布式计算方式,我们能够汇聚个体的努力,更迅速地训练模型。
四、模型并行
近年来,随着模型规模的持续扩大,针对单个数据的模型计算量变得异常庞大,有时甚至超越了单个GPU的处理能力,导致计算难以进行。为了应对这一挑战,业界开始探索一种全新的分布式计算思路,即模型并行。如图3所示,将计算图的不同层分散到不同的GPU上,以神经网络为例,可以将神经网络的各层分配给不同的GPU。这样,每个GPU只需要负责模型的一部分,只有按照正确的顺序将它们串联在一起,才能构建出完整的模型。在计算过程中,前一个GPU的计算结果将成为后一个GPU的计算图输入,多个GPU合作完成一次计算图的计算。通过多个GPU的协同合作,我们能够有效地处理单个GPU难以胜任的大规模模型的计算。
模型并行不仅可以应对庞大的模型规模带来的挑战,还能够提升模型计算的速度。为了理解这一点,可以将模型并行的过程类比为流水线,GPU是流水线上的一环。如图3所示,在GPU:1处理第一份数据的同时,GPU:0已经开始处理第二份数据了。通过充分利用流水线的并行原理,整个模型的计算速度得到了显著提升。

五、代码实现
上述两种方法并非互斥的选择,而是可以将两者结合使用,以提升计算效率。例如,在数据并行的大框架下,当一台拥有多个GPU的机器对相应数据进行计算时,可以采用模型并行的策略将模型分散到不同的GPU上,从而进一步提升计算速度。
分布式计算本身相当复杂,除了涉及算法层面的代码实现,还涉及集群层面的构建和维护工作,如机器间的通信和错误恢复等。在这两个方面,PyTorch提供了出色的支持。在代码方面,PyTorch提供了3个优秀的封装工具3,分别是torch.distributed、torch.multiprocessing和torch.nn.parallel.DistributedDataParallel,可以帮助我们快速搭建分布式模型,具体的代码实现可以参考这个链接。在集群搭建4方面,PyTorch提供了torchrun工具,致力于更轻松地配置集群环境。
Map/Reduce框架是一种经典的分布式计算模式,整个计算过程分为两个关键阶段:Map和Reduce。它最初由Google提出,并在处理海量数据时取得了巨大成功。这个框架的设计思想旨在将复杂的任务分解成多个简单的子任务,分布在多台机器上并行执行(Map阶段),然后将结果合并(Reduce阶段)以得到最终的计算结果。 ↩︎
在经典的Map/Reduce框架中,Reduce操作只在选定的一台机器上进行,并非在全部机器上执行,因此这里的步骤被称为All Reduce。 ↩︎
这里涉及的3个工具都用于数据并行的情况,若要实现模型并行,则需要自行编写代码。幸运的是,具体的实现并不复杂,所涉及的核心流程是GPU计算中的数据复制。 ↩︎
对于用于机器学习的专用集群(通常为GPU集群),有一些更专业的工具可用于集群的搭建和管理,比如NVIDIA Bright Cluster Manager、Slurm等。这些工具旨在优化集群的性能,确保计算资源得到最大限度的利用。 ↩︎
相关文章:
大语言模型的工程技巧(三)——分布式计算
相关说明 这篇文章的大部分内容参考自我的新书《解构大语言模型:从线性回归到通用人工智能》,欢迎有兴趣的读者多多支持。 本文将讨论如何利用多台机器进行神经网络的分布式训练。利用多台机器来加速大语言模型的训练,是其获得成功的重要原…...
AI开发初体验:昇腾加持,OrangePi AIpro 开发板
文章目录 一、前言二、板子介绍2.1 拆箱2.2 板子规格2.2.1 常规项目2.2.2 扩展项目2.2.3 操作系统 2.3 点板画面 三、AI程序初体验3.1 新奇的地方3.2 运行第一个AI程序3.2.1 硬件连接3.2.2 串口连接3.2.3 开启外部IP端口3.2.4 查询板子IP地址3.2.5 了解 juypter lab 启动脚本&a…...

微服务架构下Docker容器技术与Kubernetes(K8S)
Kubernetes、微服务和Docker容器技术的结合提供了一个强大、灵活且高效的平台,能够应对现代应用程序的复杂性和动态性。Kubernetes的自动化管理、服务发现、负载均衡和配置管理,与Docker的标准化打包和运行环境相结合,最大化地发挥了微服务架…...

风萧萧兮易水寒,壮士一去兮不复还 的 rm 命令
风萧萧兮易水寒,壮士一去兮不复还 的 rm 命令 风萧萧兮易水寒,壮士一去兮不复还 的 rm语法几个示例/bin/rm Argument list too long – Linux”配合find与xargs完成删除海量文件使用find的delete选项 快速删除大文件 风萧萧兮易水寒,壮士一去…...

How Diffusion Models Work
introduction intuition goal 让神经网络学到图像是什么样的,一种方式是对数据添加不同级别的噪音,让神经网络能够区分细节/总体轮廓 训练一个神经网络去产生精灵 sampling nn 图像恢复 论文 https://zhuanlan.zhihu.com/p/686235079...
antd table列选中效果实现
前言 开发中有一个需要呈现不同时间点各个气象要素的值需求,我觉得一个table可以实现这类数据的展示,只是因为时间点时关注的重点,所以需要列选中效果,清晰的展示时间点下的要素数据。我选择的是antd的table组件,这个…...
Golang实现文件复制
方法:三种 package zdpgo_fileimport ("errors""io""os" )// CopyFile 使用io.Copy进行文件的复制,同时也会复制文件的所有权限 // param src 复制文件 // param des 目标文件 // return error 错误信息 func CopyFile(s…...
探秘SpringBoot默认线程池:了解其运行原理与工作方式(@Async和ThreadPoolTaskExecutor)
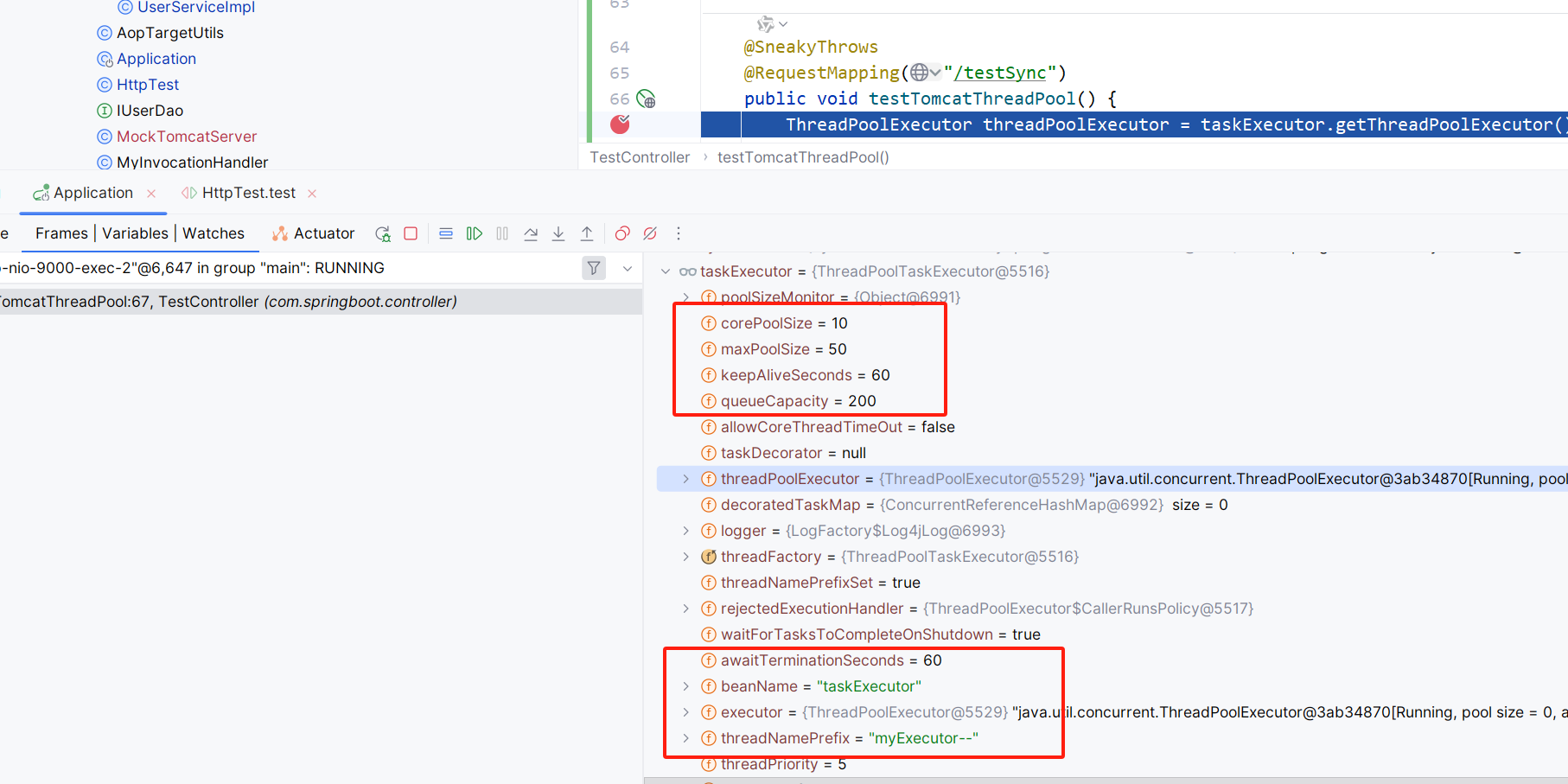
文章目录 文章导图Spring封装的几种线程池SpringBoot默认线程池TaskExecutionAutoConfiguration(SpringBoot 2.1后)主要作用优势使用场景如果没有它 2.1版本以后如何查看参数方式一:通过Async注解--采用ThreadPoolTaskExecutordetermineAsync…...
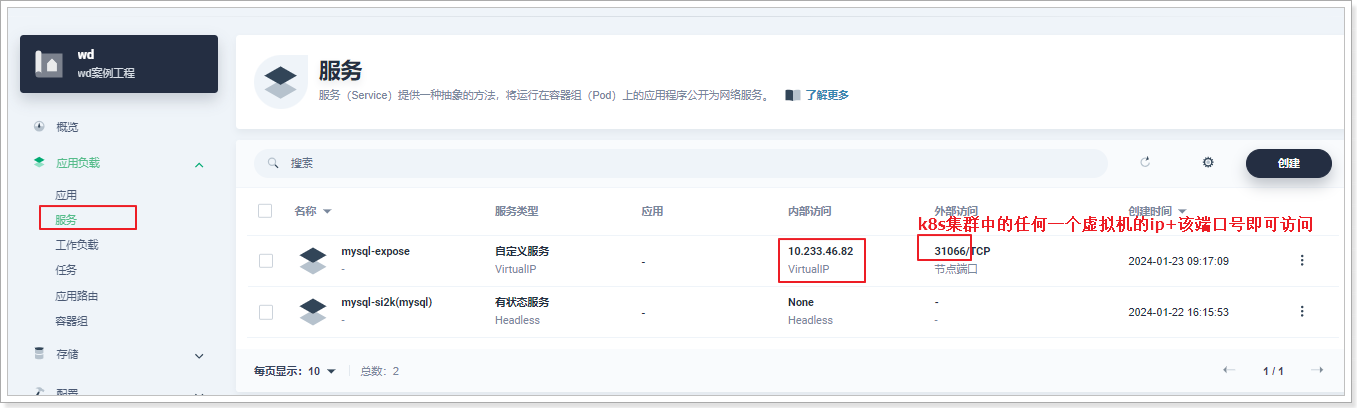
kubernetes(Jenkins、kubernetes核心、K8s实战-KubeSphere、)
文章目录 1. Jenkins1.1. 概述1.1.1. 简单部署1.1.2. 自动化部署1.1.3. DevOps概述1.1.4. CI/CD概述 1.2. jenkins介绍及安装1.2.1. 安装1.2.2. 解锁jenkins1.2.3. 安装推荐插件1.2.4. 创建管理员用户1.2.5. 升级jenkins版本1.2.6. 安装额外插件blue ocean1.2.7. jenkins界面说…...

国际数字影像产业园|科技与文创产品创意集市,共筑创新文化新高地
5月29日,为进一步增强园区与企业之间粘性,不断激发企业的创新活力,园区举办了“数媒大厦科技与文创产品创意集市活动”。本次活动由成都树莓信息技术有限公司主办,成都目莓商业管理有限公司、树莓科技(成都)…...

leetcode-55 跳跃游戏
leetcode Problem: 55. 跳跃游戏 思路 假设我们是一个小人,从第一个下标开始,每次经过一个位置,我们就可以根据当前位置的数值nums[i]和位置下标i计算出该位置所能到达的后续位置的最大值rnums[i]i。而这个r之前的区域一定都是可以经过的。…...
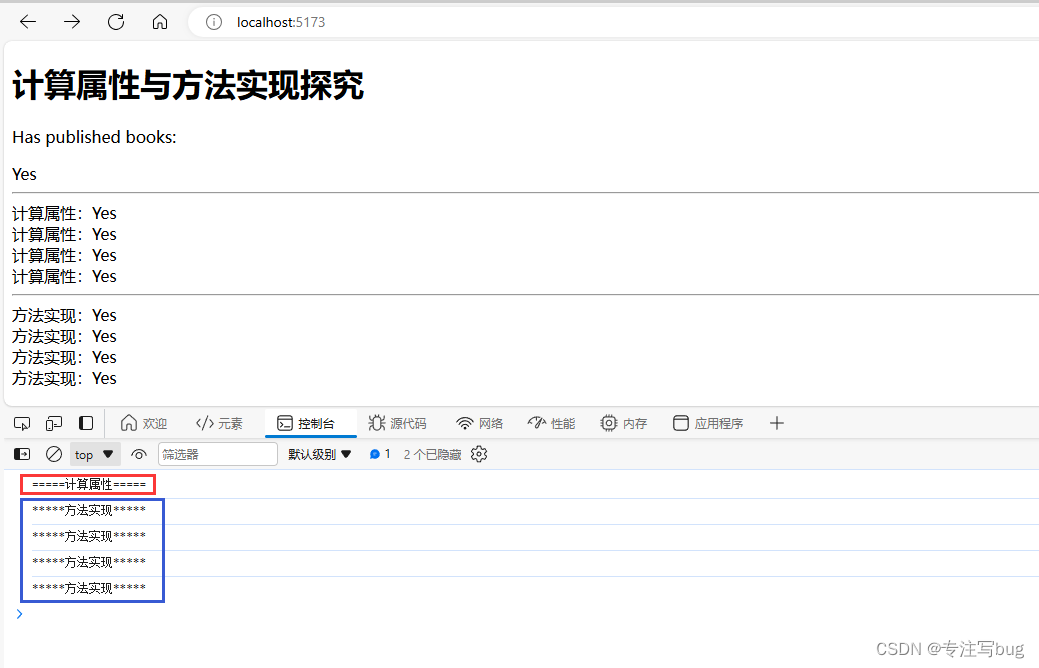
Vue——计算属性 computed 与方法 methods 区别探究
文章目录 前言计算属性的由来方法实现 计算属性 同样的效果计算属性缓存 vs 方法 前言 在官方文档中,给出了计算属性的说明与用途,也讲述了计算属性与方法的区别点。本篇博客只做自己的探究记录,以官方文档为准。 vue 计算属性 官方文档 …...

Java中的ORM框架——myBatis
一、什么是ORM ORM 的全称是 Object Relational Mapping。Object代表应用程序中的对象,Relational表示的是关系型数据库,Mapping即是映射。结合起来就是在程序中的对象和关系型数据库之间建立映射关系,这样就可以用面向对象的方式,…...
vue2生命周期和计算属性
vue2的生命周期 删除一些没用的 App.vue 删成这个样子就行 <template><router-view/></template><style lang"scss"></style>来到路由把没用的删除 import Vue from vue import VueRouter from vue-router import HomeView from .…...
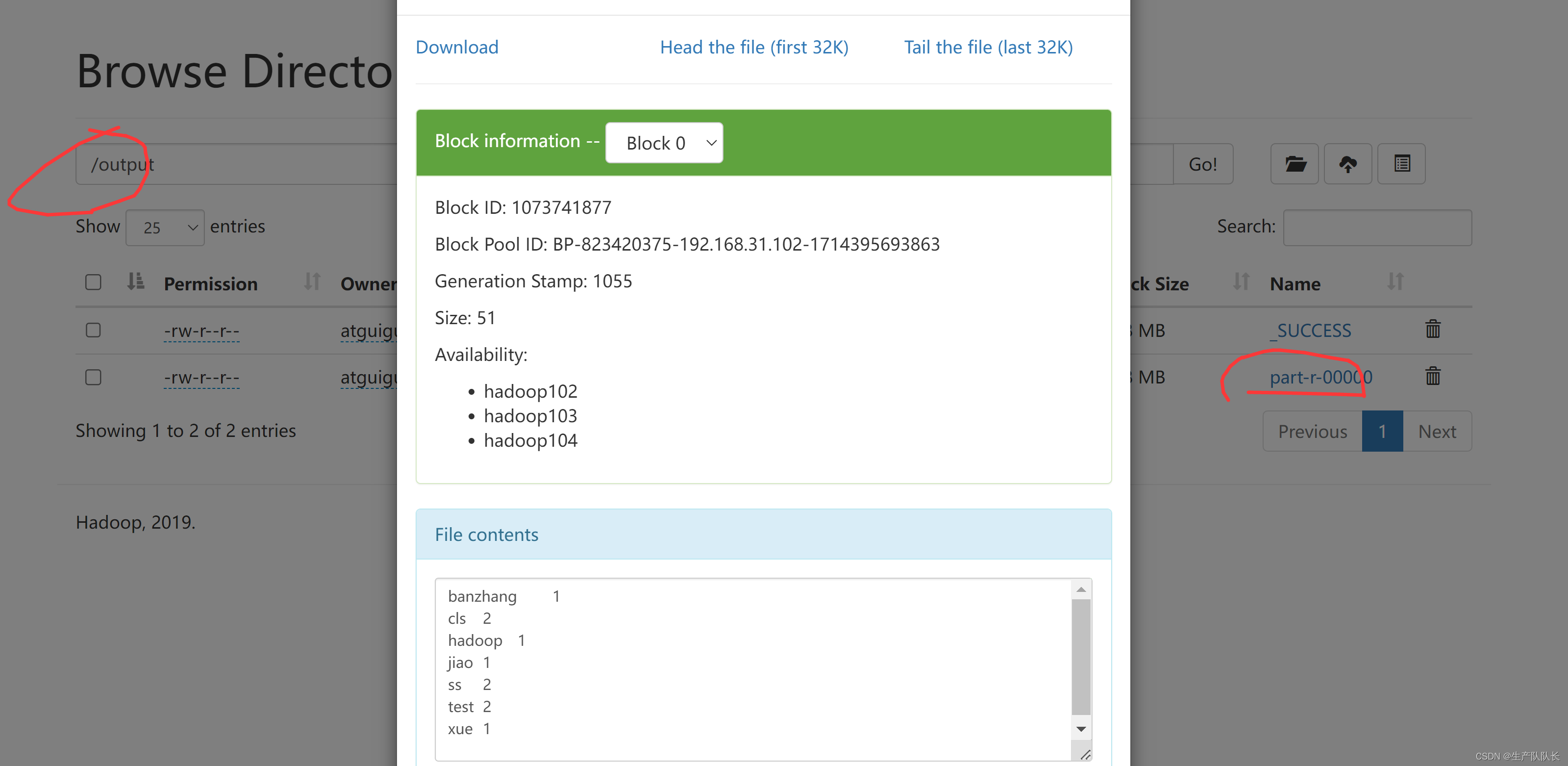
Hadoop3:MapReduce之简介、WordCount案例源码阅读、简单功能开发
一、概念 MapReduce是一个 分布式运算程序 的编程框架,是用户开发“基于 Hadoop的数据分析 应用”的核心框架。 MapReduce核心功能是将 用户编写的业务逻辑代码 和 自带默认组件 整合成一个完整的 分布式运算程序 ,并发运行在一个 Hadoop集群上。 1、M…...

centos8stream 编译安装 php-rabbit-mq模块
官方GitHub:https://github.com/php-amqp/php-amqp 环境依赖安装 dnf install cmake make -y 1.安装rabbitmq-c cd /usr/local/src/ wget https://github.com/alanxz/rabbitmq-c/archive/refs/tags/v0.14.0.tar.gz tar xvf v0.14.0.tar.gz cd rabbitmq-c-0.14.0/…...

「异步魔法:Python数据库交互的革命」(二)
哈喽,我是阿佑,上篇文章带领了大家跨入的异步魔法的大门——Python数据库交互,一场魔法与技术的奇幻之旅! 从基础概念到DB-API,再到ORM的高级魔法,我们一步步揭开了数据库操作的神秘面纱。SQLAlchemy和Djan…...

php正则中的i,m,s,x,e分别表示什么
正则表达式模式修饰符(也称为标志或模式修饰符)用于改变正则表达式的行为。这些修饰符可以附加在正则表达式的定界符之后,通常为正斜杠(/)或井号(#),以改变搜索或替换的方式。 1、i…...

最新!2023年台湾10米DEM地形瓦片数据
上次更新谷歌倾斜摄影转换生成OSGB瓦片V1.1版本,使用该版本生产了台北、台中、桃园三个地方的倾斜摄影OSGB数据,在OSGB可视化软件中进行展示,可视化效果和加载效率俱佳。已经很久没更新地形瓦片数据,主要是热点地区的原始数据没有…...
 |深入解析客户端缓存与服务器缓存:HTTP缓存控制头字段及优化实践)
网络学习(11) |深入解析客户端缓存与服务器缓存:HTTP缓存控制头字段及优化实践
文章目录 客户端缓存与服务器缓存的区别客户端缓存浏览器缓存应用程序缓存优点缺点 服务器缓存优点缺点 HTTP缓存控制头字段Cache-ControlExpiresLast-ModifiedETag 缓存策略的优化与实践经验分享1. 使用合适的缓存头字段2. 结合使用Last-Modified和ETag3. 利用CDN进行缓存4. 实…...

猫抓扩展完整指南:三步掌握浏览器视频嗅探与下载技巧
猫抓扩展完整指南:三步掌握浏览器视频嗅探与下载技巧 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 猫抓(Cat-Catch&#…...

前端工程化实战:基于 Kelivo 模板的配置即代码与自动化工作流
1. 项目概述与核心价值最近在整理个人开发环境时,发现一个挺有意思的项目,叫Chevey339/kelivo。乍一看这个仓库名,可能有点摸不着头脑,但点进去之后,你会发现它是一个围绕特定开发工具或框架进行深度定制、优化和功能增…...

告别答辩PPT焦虑:百考通AI智能生成,高效搞定毕业答辩全流程
毕业季悄然来临,随着毕业论文定稿,答辩PPT成了不少同学面临的下一个挑战。不懂设计、不会梳理逻辑、找不到合适的学术模板……许多同学花费大量时间在排版调整、修改打磨上,不仅效率低下,还常常做出结构混乱、风格不统一的PPT&…...

CircuitPython状态灯、安全模式与文件系统故障排查实战指南
1. 项目概述与核心价值 如果你正在用CircuitPython做项目,无论是物联网传感器节点、智能穿戴设备还是互动艺术装置,大概率都遇到过这样的瞬间:板子上的RGB状态灯突然开始闪烁诡异的颜色,或者电脑上那个熟悉的 CIRCUITPY U盘图标…...

Iris API错误处理机制与嵌入式系统优化实践
1. Iris API错误处理机制解析在嵌入式系统开发中,API的健壮性直接影响整个系统的稳定性。Iris框架作为ARM架构下的核心组件,其错误处理机制基于JSON-RPC 2.0规范进行了深度定制,特别适合资源受限的嵌入式环境。与通用Web API不同,…...

MCP服务器开发指南:为AI助手构建安全可控的外部工具扩展
1. 项目概述:一个为AI助手赋能的MCP服务器最近在折腾AI应用开发的朋友,可能都绕不开一个词:MCP。全称是Model Context Protocol,你可以把它理解成一套标准化的“插件协议”。它让像Claude、Cursor这类AI助手,能够安全、…...

结构化数字工作空间:提升创意工作效率的目录设计与自动化实践
1. 项目概述:一个为创意工作者量身定制的数字工作空间 如果你是一名设计师、开发者、内容创作者,或者任何需要处理大量数字资产、管理复杂项目流程的创意工作者,那么“Workspace-di-Yivo”这个名字可能会让你眼前一亮。这不仅仅是一个简单的文…...

基于双线性插值的AMG8833热成像分辨率提升方案与嵌入式实现
1. 项目概述:从8x8到15x15,一次软件驱动的热成像分辨率革命如果你玩过基于AMG8833这类低成本红外热成像传感器的项目,大概率会对它那8x8的“马赛克”图像印象深刻——64个像素点,勉强能看出个温度轮廓,但细节ÿ…...
)
告别命令行恐惧:用Docker Compose一键部署EMQX集群(附Web控制台和端口映射配置)
告别命令行恐惧:用Docker Compose一键部署EMQX集群(附Web控制台和端口映射配置) 在物联网和分布式系统开发中,EMQX作为高性能的MQTT消息服务器,已经成为连接海量设备与后端服务的核心枢纽。然而,传统安装方…...

Camera Graph™相机拓扑图谱引擎技术白皮书
前言在数字孪生、全域感知、智能安防等领域快速发展的今天,多镜头协同感知已成为实现全域覆盖、精准识别、连续追踪的核心基础。然而,传统多相机部署模式下,各镜头始终处于“孤立工作”状态,数据互通存在壁垒、时空对齐精度不足、…...