大语言模型拆解——Tokenizer
1. 认识Tokenizer
1.1 为什么要有tokenizer?
计算机是无法理解人类语言的,它只会进行0和1的二进制计算。但是呢,大语言模型就是通过二进制计算,让你感觉计算机理解了人类语言。
- 举个例子:单=1,双=2,计算机面临“单”和“双”的时候,它所理解的就是2倍关系。
- 再举一个例子:赞美=1,诋毁=0, 当计算机遇到0.5的时候,它知道这是“毁誉参半”。
- 再再举一个例子:女王={1,1},女人={1,0},国王={0,1},它能明白“女人”+“国王”=“女王”。
可以看出,计算机面临文字的时候,都是要通过数字去理解的。
所以,如何把文本转成数字,是语言模型中最基础的一步,而Tokenizer的作用就是完成文本到数字的转换,是大语言模型最基础的组件。
1.2 什么是tokenizer?
Tokenizer是一个词元生成器,它首先通过分词算法将文本切分成独立的token列表,再通过词表映射将每个token转换成语言模型可以处理的数字。
这里有一个网站,可以在线演示tokenizer的切分,见:tokenizer在线演示
大多数常见的英语单词都分配一个token:

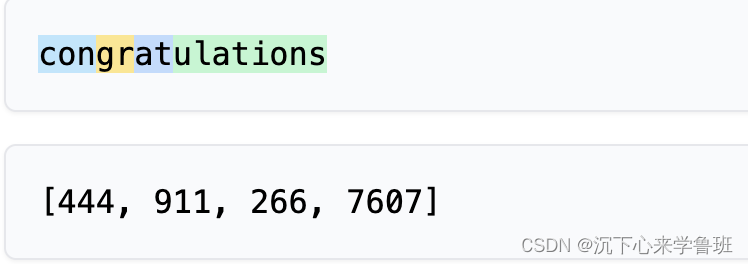
而有的单词却分配不止一个token:
像congratulations就被切分成4个token.
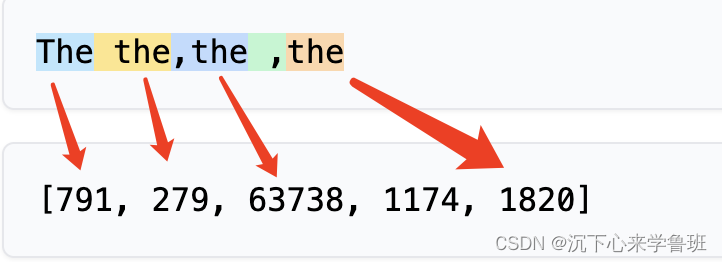
不仅如此,而字母大小写,空格和标点符号对分词结果也有影响,如下面示例:
以上这些分词效果,均与token的切分方式有关。
2. token切分方式
根据切分粒度的不同可以把tokenizer分为:
- 基于词的切分
- 基于字的切分
- 基于subword的切分
2.1 基于词的切分
将文本按照词语进行分割,通过空格或者标点符号来把文本分成一个个单词,这样分词之后的 token 数量就不会太多,比如 It is a nice day -> It, is, a, nice, day。缺点是:
- 词表规模可能会过大;
- 一定会存在UNK,造成信息丢失;
- 不能学习到词根、词缀之间的关系,例如:dog与dogs,happy与unhappy;
UNK是"unknown"(未知)的缩写,表示模型无法识别的单词或标记,对于一些新词、生僻词、专有名词或拼写错误的词可能未被词典收录。
词表规模过大原因:自然语言中存在大量的词汇,而词汇与词汇之间的排列组合又能造出大量的复合词,这会导致词表规模很大,并且持续增长。
2.2 基于字的切分
将文本按照字符进行切分,把文本拆分成一个个字符单独表示,比如 highest -> h, i, g, h, e, s, t。
- 优点:
- 词表Vocab 不会太大,Vocab 的大小为字符集的大小,英文只有26个字母;
- 也不会遇到UNK问题;
- 缺点:
- 字符本身并没有传达太多的语义,丧失了词的语义信息;
- 分词之后的 token序列过长,例如
highest一个单词就可以得到 7 个 token,如果是很长的文本分出来的token数量将难以想象,这会造成语言模型的解码效率很低;
2.3 基于subword的切分
从上可以看出,基于词和基于字的切分方式是两个极端,其优缺点也是互补的。而subword就是一种相对平衡的折中方案,基本切分原则是:
- 高频词依旧切分成完整的整词,例如
It=>[ It ] - 低频词被切分成有意义的子词,例如
dogs=>[dog, s]
它的特点是:
- 词表规模适中,解码效率较高
- 不存在UNK,信息不丢失
- 能学习到词缀之间的关系
因此基于subword的切分是目前的主流切分方式。
3. subword分词流程
分词的基本需求:给定一个句子,基于分词模型切分成一连串token。效果如下:
input: Hello, how are u tday?
output: ['Hello', ',', 'Ġhow', 'Ġare', 'Ġu', 'Ġt', 'day', '?']
整个tokenize的过程可以用下面这个图来理解,分为预分词、基于模型分词、编码三步。

3.1 预分词
预分词阶段会把句子切分成词单元,可以基于空格或者标点进行切分。
以gpt2为例,预切分结果如下,每个单词变成了[word, (start_index, end_index)]
input: Hello, how are you?pre-tokenize:
[GPT2]: [('Hello', (0, 5)), (',', (5, 6)), ('Ġhow', (6, 10)), ('Ġare', (10, 14)), ('Ġ', (14, 15)), ('Ġyou', (15, 19)), ('?', (19, 20))]
在GPT2中,空格会保留成特殊的字符“Ġ”。
不同的模型在切分时对于空格和标点的处理方式不同,作为对比:
- BERT的tokenizer也是基于空格和标点进行切分,但不会保留空格。
[BERT]: [('Hello', (0, 5)), (',', (5, 6)), ('how', (7, 10)), ('are', (11, 14)), ('you', (16, 19)), ('?', (19, 20))]
- LLama 的T5则只基于空格进行切分,标点不会切分。并且空格会保留成特殊字符"▁",并且句子开头也会添加特殊字符"▁"。
[t5]: [('▁Hello,', (0, 6)), ('▁how', (7, 10)), ('▁are', (11, 14)), ('▁you?', (16, 20))]
3.2 基于模型分词
上面预分词的结果基本就是一个单词一个token,但这样的切分粒度是很粗的,正如上面切分方式中介绍的问题,容易造成词表规模过大。
而基于模型分词本质上就是对预分词后的每个单词再尝试进行切分,也就是上面提到的subword方式,目前主流大语言模型使用的是BPE算法。
BPE分词的过程可以简单理解为从短到长逐步查找词元的过程,概括为以下三步。
- 对于输入序列中的每个单词拆分成一个个字符,以
Ġtday为例,拆分结果如下。
('Ġ', 't', 'd', 'a', 'y')
在BPE算法中,每个字母都是最基本的词元,这样能避免UNK问题。
- 从输入的字符序列逐步查找是否有更长的词元可以代替,如果找到,就将较短的几个词元替换成这个更长的词元,还是以
Ġtday为例替换过程如下所示。
# 第一次替换:'Ġ'和't'->'Ġt'
('Ġt', 'd', 'a', 'y')
# 第二次替换:'a'和'y'->'ay'
('Ġt', 'd', 'ay')
# 第三次替换:'d'和'ay'->'day'
('Ġt', 'day')
# 结束
- 这样
Ġtday这个预分的词元就被拆分成了Ġt和day两个最终的词元,这两个词元会替换掉先前的Ġtday。
为什么
Ġt和day不能进一步合并替换呢?
原因:tday其实是today这个单词的网络用语,这个网络简称在词汇表中并不存在,所以无法合并,最终tday这个单词就在分词阶段拆分成了t和day两个token。
那么,具体哪些字符或子词能合并成更长的词元呢?
这里依据的是分词模型中子词合并记录merges.txt,这个文件是模型训练过程中生成的,其中一段示例如下。
[["]", ",\\u010a"],["\\u0120H", "e"],["_", "st"],["f", "ul"],["o", "le"],[")", "{\\u010a"],["\\u0120sh", "ould"],["op", "y"],["el", "p"],["i", "er"],["_", "name"],["ers", "on"],["I", "ON"],["ot", "e"],["\\u0120t", "est"],["\\u0120b", "et"],["rr", "or"],["ul", "ar"],["\\u00e3", "\\u0122"],["\\u0120", "\\u00d0"],["b", "s"],["t", "ing"],["\\u0120m", "ake"],["T", "r"],["\\u0120a", "fter"],["ar", "get"],["R", "O"],["olum", "n"],["r", "c"],["_", "re"],["def", "ine"],["\\u0120r", "ight"],["r", "ight"],["d", "ay"],["\\u0120l", "ong"],["[", "]"],["(", "p"],["t", "d"],["con", "d"],["\\u0120P", "ro"],["\\u0120re", "m"],["ption", "s"],["v", "id"],[".", "g"],["\\u0120", "ext"],["\\u0120", "__"],["\'", ")\\u010a"],["p", "ace"],["m", "p"],["\\u0120m", "in"],["st", "ance"],["a", "ir"],["a", "ction"],["w", "h"],["t", "ype"],["ut", "il"],["a", "it"],["<", "?"],["I", "C"],["t", "ext"],["\\u0120p", "h"],["\\u0120f", "l"],[".", "M"],["cc", "ess"],["b", "r"],["f", "ore"],["ers", "ion"],[")", ",\\u010a"],[".", "re"],["ate", "g"],["\\u0120l", "oc"],["in", "s"],["-", "s"],["tr", "ib"],
这个合并记录表与我们人类能理解的单词、词根、词缀有一定差别,既有我们常见单词的合并记录: ["def","ine"], ["r", "ight"], ["d", "ay"],也有我们看不明白的: ["\\u0120f", "l"],、 ["cc", "ess"],这些合并记录不是人工编辑的,而是模型训练阶段根据实际语料来生成的。
这种方式是有效的,它既能保留常见的独立词汇(例如:how), 又能保证未知或罕见的词汇能被拆分为较小的词根或词缀(例如:tday->t和day),即使没有词根或词缀,最后还能以单个字符(例如:?, u) 作为词元保证不会出现UNK。
这样,通过词汇表就可以将预分词后的单词序列切分成最终的词元。
input: Hello, how are u tday?
Model: ['Hello', ',', 'Ġhow', 'Ġare', 'Ġu', 'Ġt', 'day', '?']
3.3 编码
编码本质上就是给每个token分配一个唯一的数字ID,这个数字ID是分词模型训练好后就维护在词汇表中的。
每个分词模型内部都有一个vocab词汇表,以chatgpt为例,目前使用的词表为c100k_base, 它是一个index ——> token的map映射(index表示token对应的数字ID)里面有大概10万个词元,示例如下:
{"0": "!","1": "\"","2": "#","3": "$","4": "%","5": "&","6": "'","7": "(","8": ")","9": "*","10": "+",……"1268": " how","1269": "rite","1270": "'\n","1271": "To","1272": "40","1273": "ww","1274": " people","1275": "index",……"100250": ".allowed","100251": "(newUser","100252": " merciless","100253": ".WaitFor","100254": " daycare","100255": " Conveyor"
}
切分好token后,就可以根据上面示例的词汇表,将token序列转换为数字序列,如下所示:
input: ['Hello', ',', 'Ġhow', 'Ġare', 'Ġu', 'Ġt', 'day', '?']
output: [9906, 11, 1268, 527, 577, 259, 1316, 5380]
关于这个词表vocab以及合并记录merges.txt的由来,与BPE算法的实现和训练过程有关,后续再介绍。
4. 中文分词
4.1 长度疑问
我们在估算token的消耗时,经常听到有同事说汉字要占两个token,是这样吗?我们来验证下:

为何有的汉字一个token,有的汉字两个token? 这和tiktoken对中文分词的实现方式有关。
4.2 实现剖析
举例:‘山东淄博吃烧烤’
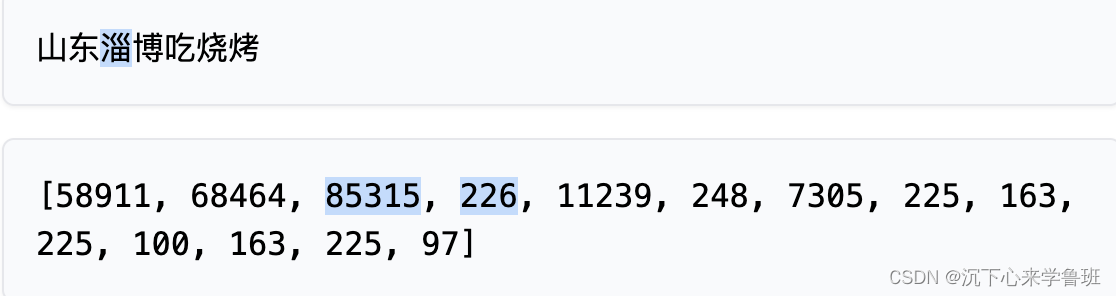
对应词汇表中的词元:
["山", "东", "b'\\xe6\\xb7'", "b'\\x84'", "b'\\xe5\\x8d'", "b'\\x9a'", "b'\\xe5\\x90'", "b'\\x83'", "b'\\xe7'", "b'\\x83'", "b'\\xa7'", "b'\\xe7'", "b'\\x83'", "b'\\xa4'"]
除了“山“、”东”这两个相对比较简单的汉字词表里面直接就有,其他的都是一些非常奇怪的Unicode编码表示。
仔细观察可以发现:tokens[85315, 226] 对应的"b’\xe6\xb7’", “b’\x84’” 拼接起来,然后按照utf-8解码回去 b’\xe6\xb7\x84’.decode(‘utf-8’) 得到的就是“淄”。
原来,OpenAI为了支持多种语言的Tokenizer,采用了文本的一种通用表示:UTF-8的编码方式,这是一种针对Unicode的可变长度字符编码方式,它将一个Unicode字符编码为1到4个字节的序列。
山和东因为比较常见,所以被编码为了独立的词元- 而
淄、博等字词频较低,所以按照Unicode编码预处理成了独立的3个字节,然后子词的迭代 合并最终分成了两个词元。
\x 表示16进制编码,可以发现
淄博分别被编码为6个16进制数字,分别占3个字节。随后,GPT-4将每2个16进制数字,也就是1字节的数据作为最小颗粒度的token,然后进行BPE的迭代、合并词表。
5. tiktoken
tiktoken是OpenAI开源一种分词工具,
采用BPE算法实现,被GPT系列大模型广泛使用。
基于某个模型来初始化tiktoken(不同模型的tiktoken词表不同):
import tiktoken
enc = tiktoken.encoding_for_model("gpt-3.5-turbo-16k")
字节对编码
encoding_res = enc.encode("Hello, how are u tday?")
print(encoding_res)> [9906, 11, 1268, 527, 577, 259, 1316, 30]
字节对解码
raw_text = enc.decode(encoding_res)
print(raw_text) > Hello, how are u tday?
如果想要控制token数量,则可以通过len函数来判断
length = len(enc.encode("Hello, how are u tday?"))
print(length)> 8
参考资料
- gpt在线分词演示
- 探索GPT Tokenizer的工作原理
相关文章:
大语言模型拆解——Tokenizer
1. 认识Tokenizer 1.1 为什么要有tokenizer? 计算机是无法理解人类语言的,它只会进行0和1的二进制计算。但是呢,大语言模型就是通过二进制计算,让你感觉计算机理解了人类语言。 举个例子:单1,双2&#x…...

Linux自动挂载服务autofs讲解
1.产生原因 2.配置文件讲解 总结:配置客户端,先构思好要挂载的目录如:/abc/cb 然后在autofs.master中编辑: /abc(要挂载的主目录) /etc/qwe(在这个文件里去找要挂载的副目录,这个名…...

堆结构知识点复习——玩转堆结构
前言:堆算是一种相对简单的数据结构, 本篇文章将详细的讲解堆中的知识点, 包括那些我们第一次学习堆的时候容易忽略的内容, 本篇文章会作为重点详细提到。 本篇内容适合已经学完C语言数组和函数部分的友友们观看。 目录 什么是堆 建堆算法…...

JS数据类型运算符标准库
目录 数据类型运算符标准库对象Object对象属性描述对象Array对象包装对象Boolean对象Number对象String对象Math对象Date对象...

单片机之从C语言基础到专家编程 - 4 C语言基础 - 4.13数组
C语言中,有一类数据结构,它可以存储一组相同类型的元素,并且可以通过索引访问这些元素,没错,这类数据结构就是数组。数组可以说是C语言中非常重要的数据结构之一了。使用数组可以是程序逻辑更加清晰,也更加…...

【码银送书第二十期】《游戏运营与出海实战:策略、方法与技巧》
市面上的游戏品种繁杂,琳琅满目,它们是如何在历史的长河中逐步演变成今天的模式的呢?接下来,我们先回顾游戏的发展史,然后按照时间轴来叙述游戏运营的兴起。 作者:艾小米 本文经机械工业出版社授权转载&a…...

String 类
目录: 一. 认识 String 类 二. String 类的基本用法 三. String对象的比较 四.字符串的不可变性 五. 认识 StringBuffer 和 StringBuilder 一. 认识 String 类: 在C语言中已经涉及到字符串了,但是在C语言中要表示字符串只能使用字符数组或者…...
Chromebook Plus中添加了Gemini?
Chromebook Plus中添加了Gemini? 前言 就在5月29日,谷歌宣布了一项重大更新,将其Gemini人工智能技术集成到Chromebook Plus笔记本电脑中。这项技术此前已应用于谷歌的其他设备。华硕和惠普已经在市场上销售的Chromebook Plus机型,…...

Git Large File Storage (LFS) 的安装与使用
Git Large File Storage [LFS] 的安装与使用 1. An open source Git extension for versioning large files2. Installing on Linux using packagecloud3. Getting Started4. Error: Failed to call git rev-parse --git-dir: exit status 128References 1. An open source Git…...

使用国产工作流引擎,有那些好处?
使用国产工作流引擎的好处主要体现在以下几个方面: 符合企业独特业务: 国产工作流引擎可以深入挖掘和理解企业内部各项业务流程,精细化地定义流程模型和规则,实现“以流程驱动业务”的目标。这有助于企业更好地满足其独特的业务…...

掌握 Go 语言:使用 net/http/httptrace 包优化HTTP请求
掌握 Go 语言:使用 net/http/httptrace 包优化HTTP请求 介绍net/http/httptrace 包的基础概述适用场景 使用httptrace进行网络请求追踪配置httptrace的基本步骤示例:创建一个简单的HTTP客户端,使用httptrace监控连接 示例:追踪HTT…...

探秘Flask中的表单数据处理
新书上架~👇全国包邮奥~ python实用小工具开发教程http://pythontoolsteach.com/3 欢迎关注我👆,收藏下次不迷路┗|`O′|┛ 嗷~~ 目录 一、引言 二、Flask中的表单处理机制 三、Flask表单处理实战 四、处理表单数据的注意事项…...

java —— 包装类及拆箱、装箱
java 当中有 8 种基本类型对应其相应的包装类,分别如下: intIntegerbyteByteshortShortlongLongfloatFloatdoubleDoublecharCharacterbooleanBoolean 一、装箱 两种装箱方法: public static void main(String[] args) {Integer anew Inte…...
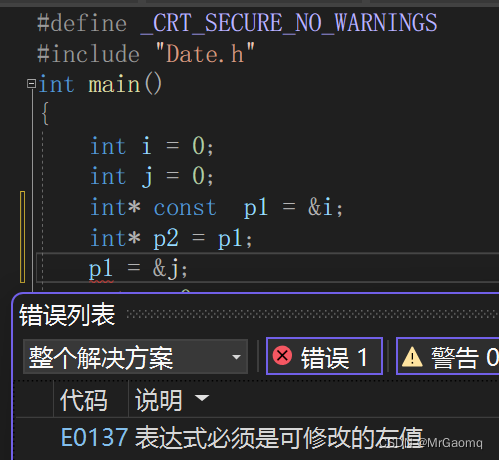
运算符重载(下)
目录 前置和后置重载前置的实现Date& Date::operator()代码 后置的实现Date Date::operator(int )代码 前置--和后置--重载前置--的实现Date& Date::operator--( )代码 后置--的实现Date Date::operator--(int )代码 流插入运算符重载流插入运算符重载的实现流提取运算…...

杭州服务器的性能如何?
挥洒激情,开启杭州服务器的无限可能! 互联网时代,服务器的性能就如同一艘航空母舰,承载着企业的发展梦想,指引着行业的发展方向。而对于杭州服务器,其性能究竟如何?让我来告诉您。 杭州服务器…...
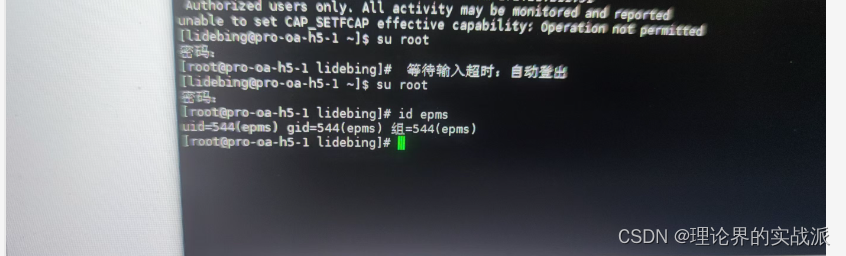
linux centos nfs挂载两台服务器挂载统一磁盘目录权限问题
查看用户id id 用户名另一台为 修改uid和gid为相同id,添加附加组 usermod -u500 -Gwheel epms groupmod -g500 epms...

STL:string
文章目录 标准库中的string类string的构造string的赋值重载string的容量size(length)max_sizeresizereservecapacityclearemptyshink_to_fit string的元素访问operator[] 和 atfront 和 back string的迭代器 和 范围forstring的修改operatorappendpush_backassigninserterasere…...
贷款借钱平台 小额贷款系统开发小额贷款源码 贷款平台开发搭建
这款是贷款平台源码/卡卡贷源码/小贷源码/完美版 后台51800 密码51800 数据库替换application/database.php程序采用PHPMySQL,thinkphp框架代码开源,不加密后台效果:手机版效果 这款是贷款平台源码/卡卡贷源码/小贷源码/完美版 后台51800 密码…...

软设之算法的效率
算法的效率分为时间复杂度和空间复杂度。 空间复杂度是指对一个算法在运行过程中临时占用存储空间大小的度量。一个算法的空间复杂度只考虑在运行过程中为局部变量分配的存储空间的大小。说白了,就是空间换时间。 比如说计算从123……100的和。一个算法是i(1100)*…...
前端开发(2)--HTML常用的标签
100编程书屋_孔夫子旧书网 HTMl 的标签可以分为单个标签和成对标签。 单个标签:html4 规定单个标签要有一个 / 表示结尾, html5 则不用 <!--单个标签--> <meta> <!--成对标签 --> <div></div>以下是HTMl中常用的一些标签…...

使用 Taotoken CLI 工具一键配置团队成员的开发环境
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用 Taotoken CLI 工具一键配置团队成员的开发环境 在团队开发中,统一管理大模型 API 的接入配置是一项常见且繁琐的任…...

长期使用Taotoken聚合API对项目运维复杂度的简化感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Taotoken聚合API对项目运维复杂度的简化感受 作为项目维护者,我们团队在过去一段时间里,将多个大模…...

三步快速解锁网盘高速下载:LinkSwift直链解析终极指南
三步快速解锁网盘高速下载:LinkSwift直链解析终极指南 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼…...

【模块化设计-13】OAM 线程模块详解
该模块是基于 RT-Thread 实时操作系统实现的一个 OAM(Operation, Administration and Maintenance,操作、管理和维护)专用线程模块,核心功能是提供独立的 OAM 业务处理线程、消息队列机制和定时器管理能力,适用于嵌入式…...

基于OpenClaw构建智能家居环境感知系统:从传感器到自动化规则
1. 项目概述与核心价值如果你正在捣鼓一个智能家居系统,尤其是围绕着OpenClaw这类AI助手来构建,那你可能和我一样,经常遇到一个痛点:家里的设备虽然能联网、能控制,但它们大多“又聋又瞎”。空调能开能关,但…...

零门槛云端实时物体识别:基于Google Colab与MobileNet V2的实践指南
1. 项目概述:零门槛体验云端实时物体识别想亲手体验一下人工智能的“眼睛”是如何看世界的吗?物体识别,这个听起来高深莫测的技术,其实离我们并不遥远。它就像是给计算机装上了一套视觉系统,让它能像我们一样ÿ…...

大功率充电桩生产厂家:高效能产品的选择与评估标准
一、行业背景与权威数据据中国电动汽车充电基础设施促进联盟(EVCIPA)数据显示,截至2026年2月底,我国电动汽车充电基础设施(枪)总数达到2101.0万个,同比增长47.8%。其中,公共充电设施…...

利用CircuitPython内置传感器实现CPU温度监控与本地日志记录
1. 项目概述:从芯片温度到数据洞察 在嵌入式项目里,给设备“把脉”是基本功。CPU温度,这个看似简单的数据点,其实是窥探硬件运行状态的绝佳窗口。它不仅能告诉你芯片是不是在“发烧”,更能间接反映环境变化、负载情况&…...

AI智能体技能开发实战:从工具调用到安全部署全解析
1. 项目概述:当AI学会“上网”与“思考”最近在折腾AI应用开发的朋友,估计都绕不开一个核心问题:如何让大语言模型(LLM)不只是个“聊天高手”,更能成为一个能独立完成复杂任务的“智能体”。你肯定遇到过&a…...
LunaTranslator:打破语言壁垒,让视觉小说触手可及
LunaTranslator:打破语言壁垒,让视觉小说触手可及 【免费下载链接】LunaTranslator 视觉小说翻译器 / Visual Novel Translator 项目地址: https://gitcode.com/GitHub_Trending/lu/LunaTranslator 还在为日文、英文的视觉小说而烦恼吗࿱…...