Android下HWC以及drm_hwcomposer普法(下)
Android下HWC以及drm_hwcomposer普法(下)
引言
不容易啊,写到这里。经过前面的普法(上),我相信童鞋们对HWC和drm_hwcomposer已经有了一定的认知了。谷歌出品,必须精品。我们前面的篇章见分析到啥来了,对了分析到了HwcDisplay::init,然后设置Backend后端来着!
一.如何理解drm_hwcomposer的backend
在正式分析drm_hwcomposer的实现前,我们先看下drm_hwcomposer下backend文件夹目录,如下:

并且它们之间存在这如下的关系:

这里的BackendManager的比较好理解,即是用来管理Backend的,那么Backend和BackendClient我们要如何理解呢?通过上面的关系图可以看出来BackendClient继承了BackendClient,并且重写了ValidateDisplay,其它的基本都一致!
-
Backend:一个后端的实现,注册为”generic”,主要是定义了ValidateDisplay方法,这个方法用来设置可见的HwcLayer应该采用什么合成方式
-
BackendClient:一个后端的实现,注册为”client”,主要是定义了ValidateDisplay方法,它把所有HwcLayer都设置成立Client合成方式
-
BackendManager:后端的管理器,用来根据Device name从已注册的backend列表中选择一个,设置给HwcDisplay;GetBackendByName就是通过Device name来从available_backends_中选择一个匹配的Backend构造函数来构建后端对象。
// backend/Backend.h
class Backend {public:virtual ~Backend() = default;// Validates the display and returns the number of supported display// types and the number of supported display requests.//// Returns:// HWC2::Error::SUCCESS if the display is valid.// HWC2::Error::BAD_DISPLAY if the display is invalid.virtual HWC2::Error ValidateDisplay(HwcDisplay *display, uint32_t *num_types,uint32_t *num_requests);//获取需要client(GPU)合成的Layer virtual std::tuple<int, size_t> GetClientLayers(HwcDisplay *display, const std::vector<HwcLayer *> &layers);//判断是否是client合成virtual bool IsClientLayer(HwcDisplay *display, HwcLayer *layer);protected:// 判断当前的layerType是否支持合成static bool HardwareSupportsLayerType(HWC2::Composition comp_type);//计算像素数量static uint32_t CalcPixOps(const std::vector<HwcLayer *> &layers,size_t first_z, size_t size);//标记相关layer合成状态static void MarkValidated(std::vector<HwcLayer *> &layers,size_t client_first_z, size_t client_size);//计算扩大额外的需要为client合成的layersstatic std::tuple<int, int> GetExtraClientRange(HwcDisplay *display, const std::vector<HwcLayer *> &layers,int client_start, size_t client_size);
};//backend/BackendClient.h
class BackendClient : public Backend {public:HWC2::Error ValidateDisplay(HwcDisplay *display, uint32_t *num_types,uint32_t *num_requests) override;
};//backend/BackendClient.cpp
HWC2::Error BackendClient::ValidateDisplay(HwcDisplay *display,uint32_t *num_types,uint32_t * /*num_requests*/) {for (auto &[layer_handle, layer] : display->layers()) {//设置所有的layer的合成方式都为clientlayer.SetValidatedType(HWC2::Composition::Client);++*num_types;}return HWC2::Error::HasChanges;
}
好了,这里我们了解初步认知了backend了,我们接下来看看两种backend是如何注册到BackendManager进行管理的!
1.1 Backend是如何注册的
通过前面的分析我们知道了有两种backend,这里我们看下它们是如何注册到BackendManager然后被管理的!
namespace android {...REGISTER_BACKEND("client", BackendClient);...} // namespace android//backend/Backend.cpp
namespace android {...REGISTER_BACKEND("generic", Backend);...} // namespace android//backend/BackendManager.h
#define REGISTER_BACKEND(name_str_, backend_) \static int \backend = BackendManager::GetInstance() \.RegisterBackend(name_str_, \[]() -> std::unique_ptr<Backend> { \return std::make_unique<backend_>(); \});//std::map<std::string, BackendConstructorT> available_backends_;
//using BackendConstructorT = std::function<std::unique_ptr<Backend>()>;
int BackendManager::RegisterBackend(const std::string &name,BackendConstructorT backend_constructor) {//将backend_constructor函数指针存入available_backends_中available_backends_[name] = std::move(backend_constructor);return 0;
}
通过上述源码可以看到BackendManager对backend的注册管理比较简单,就是将backend实存入现available_backends_中!
1.2 HwcDisplay如何选择合适的Backend
还记得我们前面已经创建好了HwcDisplay,然后也进行Init初始化了了,在Init中会设置它的Backend后端,我们看下是如何选择Backend!
//hwc2_device/HwcDisplay.cpp
HWC2::Error HwcDisplay::Init() {if (!IsInHeadlessMode()) {//通过后端管理为HwcDisplay设置后端,这个后端是干什么的呢 ret = BackendManager::GetInstance().SetBackendForDisplay(this);}
}//backend/BackendManager.cpp
int BackendManager::SetBackendForDisplay(HwcDisplay *display) {std::string driver_name(display->GetPipe().device->GetName());char backend_override[PROPERTY_VALUE_MAX];property_get("vendor.hwc.backend_override", backend_override,driver_name.c_str());//如果backend_override为空,则使用默认的backend//如果backend_override不为空,则使用backend_overridestd::string backend_name(backend_override);//根据backend_name获取对应的backend//如果找不到,则使用默认的backend//如果找不到默认的backend,则返回错误//如果成功,则将backend设置给displaydisplay->set_backend(GetBackendByName(backend_name));...return 0;
}这里我们只要明白的一点就是,绝大部分情况下使用的backend都是"generic"而不是"client"。
二. HWC的实现drm_hwcomposer是如何为Layer选择合适的合成方式的
怎么这个标题这么拗口呢,通俗的说就是如何为每个图层选择合成方式,比如壁纸啊,状态栏啊,导航栏啊,应用啊这些图层是如何合成的,是GPU呢还是hwc硬件合成呢。
2.1 合成策略的选择如何从SurfaceFlinger传递到drm_hwcomposer
说到这个得从SurfaceFlinger中Output::prepareFrame说起来了。

它的核心逻辑是选择合成策略,判断是device还是GPU合成,如果是device合成,直接present,如果要走GPU合成则需要validate。让我们通过代码具体分析:
文件:frameworks/native/services/surfaceflinger/CompositionEngine/src/Output.cppvoid Output::prepareFrame() {...const auto& outputState = getState();if (!outputState.isEnabled) {return;}// 选择合成类型,如果是device合成,则跳过validate,直接present送显chooseCompositionStrategy();// 把合成类型送到frameBufferSurface,没啥逻辑mRenderSurface->prepareFrame(outputState.usesClientComposition,outputState.usesDeviceComposition);
}void Output::chooseCompositionStrategy() {// The base output implementation can only do client composition// 默认使用GPU合成,针对没有hwc的设备auto& outputState = editState();outputState.usesClientComposition = true;outputState.usesDeviceComposition = false;outputState.reusedClientComposition = false;
}文件:frameworks/native/services/surfaceflinger/CompositionEngine/src/Display.cppvoid Display::chooseCompositionStrategy() {...// Default to the base settings -- client composition only.Output::chooseCompositionStrategy();...// Get any composition changes requested by the HWC device, and apply them.std::optional<android::HWComposer::DeviceRequestedChanges> changes;auto& hwc = getCompositionEngine().getHwComposer();// 从HWC device获得合成类型的改变,这个根据hwc能力来选择device还是GPU合成if (status_t result = hwc.getDeviceCompositionChanges(*mId, anyLayersRequireClientComposition(),&changes);result != NO_ERROR) {ALOGE("chooseCompositionStrategy failed for %s: %d (%s)", getName().c_str(), result,strerror(-result));return;}//如果有变化则设置给对应的layerif (changes) {applyChangedTypesToLayers(changes->changedTypes);applyDisplayRequests(changes->displayRequests);applyLayerRequestsToLayers(changes->layerRequests);applyClientTargetRequests(changes->clientTargetProperty);}// Determine what type of composition we are doing from the final state// 决定最后的合成类型auto& state = editState();state.usesClientComposition = anyLayersRequireClientComposition();state.usesDeviceComposition = !allLayersRequireClientComposition();
}文件:frameworks/native/services/surfaceflinger/DisplayHardware/HWComposer.cppstatus_t HWComposer::getDeviceCompositionChanges(DisplayId displayId, bool frameUsesClientComposition,std::optional<android::HWComposer::DeviceRequestedChanges>* outChanges) {...if (!frameUsesClientComposition) {sp<Fence> outPresentFence;uint32_t state = UINT32_MAX;// 如果所有的layer都能走device合成,则在hwc里面直接present,若有不支持device合成的情况,则走GPU合成,会走validate逻辑error = hwcDisplay->presentOrValidate(&numTypes, &numRequests, &outPresentFence , &state);if (!hasChangesError(error)) {RETURN_IF_HWC_ERROR_FOR("presentOrValidate", error, displayId, UNKNOWN_ERROR);}if (state == 1) { //Present Succeeded.// present成功,数据直接提交给了hwcstd::unordered_map<HWC2::Layer*, sp<Fence>> releaseFences;error = hwcDisplay->getReleaseFences(&releaseFences);displayData.releaseFences = std::move(releaseFences);displayData.lastPresentFence = outPresentFence;displayData.validateWasSkipped = true;displayData.presentError = error;return NO_ERROR;}// Present failed but Validate ran.} else {// 这个分支走不到error = hwcDisplay->validate(&numTypes, &numRequests);}// 接收hwc过来的change,对于device合成不走,GPU合成走的逻辑,这个后续GPU合成专门分析...prepareFrame 的作用是根据hwc的能力选择合成方式,如果是device能全部合成所有的则直接走hwc present上屏,如果是只能接收部分layer进行device,则会将部分layer进行GPU合成然后将合成后的layer传递给hwc。那我们接下来看看hwc的实现是如何决定layer的合成方式的。
2.2 drm_hwcomposer如何决定layer的合成方式
我们先梳理下drm_hwcomposer是如何相应上层ssurfaceflinger的presentOrValidate的!
case HWC2::FunctionDescriptor::ValidateDisplay:return ToHook<HWC2_PFN_VALIDATE_DISPLAY>(DisplayHook<decltype(&HwcDisplay::ValidateDisplay),&HwcDisplay::ValidateDisplay, uint32_t *, uint32_t *>);HWC2::Error HwcDisplay::ValidateDisplay(uint32_t *num_types,uint32_t *num_requests) {if (IsInHeadlessMode()) {*num_types = *num_requests = 0;return HWC2::Error::None;}//通过后端来决定layer的合成方式return backend_->ValidateDisplay(this, num_types, num_requests);
}
去调用到HwcDisplay绑定的后端的具体validate方法,根据前面的分析这个后端通常是Backend::ValidateDisplay,并且这个方法代码有一定的长度,所以童鞋们一定要有耐心,让我们慢慢来进行分析!
//backend/Backend.cpp
HWC2::Error Backend::ValidateDisplay(HwcDisplay *display, uint32_t *num_types,uint32_t *num_requests) {*num_types = 0;//表示多少layer需要client合成*num_requests = 0;// 按Z-order顺序排列的HwcLayer的集合,这些layer是怎么生成的,这个前面源码已经分析过了auto layers = display->GetOrderLayersByZPos();int client_start = -1;//表示所有layres中需要client合成layer的起始位置size_t client_size = 0;//表示所有layres中需要client合成layer的数量//通常不会进入这个分支if (display->ProcessClientFlatteningState(layers.size() <= 1)) {display->total_stats().frames_flattened_++;client_start = 0;client_size = layers.size();//设置合成类型,client_start到client_start+client_size之间的设置为client,其它的设置为deviceMarkValidated(layers, client_start, client_size);} else {std::tie(client_start, client_size) = GetClientLayers(display, layers);//核心实现,标记那些layer需要client合成//设置合成类型,client_start到client_start+client_size之间的设置为Client,其它的设置为DeviceMarkValidated(layers, client_start, client_size);//只有一个情况testing_needed为flase,所有的layers都是client_layerbool testing_needed = !(client_start == 0 && client_size == layers.size());AtomicCommitArgs a_args = {.test_only = true};//尝试送显示一次,如果失败,则将所有的layer都标记为client合成,有点你device不行的话,那我就让gpu全部干了算了味道if (testing_needed &&display->CreateComposition(a_args) != HWC2::Error::None) {++display->total_stats().failed_kms_validate_;client_start = 0;client_size = layers.size();MarkValidated(layers, 0, client_size);}}*num_types = client_size;display->total_stats().gpu_pixops_ += CalcPixOps(layers, client_start,client_size);display->total_stats().total_pixops_ += CalcPixOps(layers, 0, layers.size());//如果需要client合成,则返回HWC2::Error::HasChanges//否则返回HWC2::Error::None,然后上层SurfaceFlinger根据这个返回值//来判断是否需要进行gpu介入对其它标记为client layer通过GPU合成return *num_types != 0 ? HWC2::Error::HasChanges : HWC2::Error::None;
}std::tuple<int, size_t> Backend::GetClientLayers(HwcDisplay *display, const std::vector<HwcLayer *> &layers) {int client_start = -1;size_t client_size = 0;//遍历所有的layer,判断那些layer需要强制client合成//client_start表示所有layer中需要client合成layer的起始位置//client_size表示所有layer中需要client合成layer的数量//client_start和client_size的计算逻辑是://1. 遍历所有layer,找到第一个需要client合成layer的起始位置//2. 遍历所有layer,找到最后一个需要client合成layer的结束位置//3. 计算client_size = 最后一个需要client合成layer的结束位置 - 第一个需要client合成layer的起始位置 + 1//4. 得到client_start和client_size//并且这里可以看到如果clinet_start和被其它标记为client layer之间有间隔,间隔的layer也会被标记为client_layerfor (size_t z_order = 0; z_order < layers.size(); ++z_order) {if (IsClientLayer(display, layers[z_order])) {if (client_start < 0)client_start = (int)z_order;client_size = (z_order - client_start) + 1;}}//扩大额外的需要为client的layersreturn GetExtraClientRange(display, layers, client_start, client_size);
}//判断layer是不是必须为client合成或者已经指定了client合成
/*** @brief
判断指定的Layer是否要Client合成,满足其中一个条件即可:1. HardwareSupportsLayerType硬件不支持的合成方式2. IsHandleUsable buffer handle无法转为DRM要求的buffer object3. color_transform_hint !=HAL_COLOR_TRANSFORM_IDENTITY4. 需要scale or phase,但hwc强制GPU来处理*/
bool Backend::IsClientLayer(HwcDisplay *display, HwcLayer *layer) {return !HardwareSupportsLayerType(layer->GetSfType()) ||!BufferInfoGetter::GetInstance()->IsHandleUsable(layer->GetBuffer()) ||display->color_transform_hint() != HAL_COLOR_TRANSFORM_IDENTITY ||(layer->RequireScalingOrPhasing() &&display->GetHwc2()->GetResMan().ForcedScalingWithGpu());
}bool Backend::HardwareSupportsLayerType(HWC2::Composition comp_type) {return comp_type == HWC2::Composition::Device ||comp_type == HWC2::Composition::Cursor;
}
//计算连续几个layer的像素点之和
uint32_t Backend::CalcPixOps(const std::vector<HwcLayer *> &layers,size_t first_z, size_t size) {uint32_t pixops = 0;for (size_t z_order = 0; z_order < layers.size(); ++z_order) {if (z_order >= first_z && z_order < first_z + size) {hwc_rect_t df = layers[z_order]->GetDisplayFrame();pixops += (df.right - df.left) * (df.bottom - df.top);}}return pixops;
}//根据start和size标记那些layer需要client合成,那些需要device合成
void Backend::MarkValidated(std::vector<HwcLayer *> &layers,size_t client_first_z, size_t client_size) {for (size_t z_order = 0; z_order < layers.size(); ++z_order) {if (z_order >= client_first_z && z_order < client_first_z + client_size)//标记该layer的合成方式是clientlayers[z_order]->SetValidatedType(HWC2::Composition::Client);else//标记该layer的合成方式是devicelayers[z_order]->SetValidatedType(HWC2::Composition::Device);}
}std::tuple<int, int> Backend::GetExtraClientRange(HwcDisplay *display, const std::vector<HwcLayer *> &layers,int client_start, size_t client_size) {auto planes = display->GetPipe().GetUsablePlanes();//获取整个drm支持的planes的数量size_t avail_planes = planes.size();/** If more layers then planes, save one plane* for client composited layers*///如果layer的数量大于plane的数量,则保留一个plane用于target client layer//这个target client layer是用来存放所有被client layer通过GPU合成后的layer的if (avail_planes < display->layers().size())avail_planes--;//保留一个用于存放所有client合成的layerint extra_client = int(layers.size() - client_size) - int(avail_planes);//计算剩余需要成为client的数量if (extra_client > 0) {int start = 0;size_t steps = 0;if (client_size != 0) {//有layer指定了client合成int prepend = std::min(client_start, extra_client);//计算可以从前面插入的layer的数量int append = std::min(int(layers.size()) -int(client_start + client_size),extra_client);//计算可以从后面插入的layer的数量start = client_start - (int)prepend;//计算插入的起始位置client_size += extra_client;//计算client合成的layer数量steps = 1 + std::min(std::min(append, prepend),int(layers.size()) - int(start + client_size));} else {//没有layer指定了client合成。代码分析client_size = extra_client;//剩余的都是clientsteps = 1 + layers.size() - extra_client;//计算可以移动计算的step范围}//选择像素之和最少的连续layersuint32_t gpu_pixops = UINT32_MAX;for (size_t i = 0; i < steps; i++) {uint32_t po = CalcPixOps(layers, start + i, client_size);if (po < gpu_pixops) {gpu_pixops = po;client_start = start + int(i);}}}//返回client合成的起始位置和layer数量return std::make_tuple(client_start, client_size);
}
上述标记逻辑已经给出来了比较详细的源码解释,就不过多阐述了。我们只需要抓住几个重点的方法,了解清楚其功能就问题不大了:
-
IsClientLayer:判断指定的Layer是否强制要Client合成
-
GetExtraClientRange: 进一步标记client layer, 当layer的数量多于hwc支持的planes时,需要留出一个给 client target
-
CalcPixOps:计算相邻layer之间的像素和
三. drm_hwcomposer最终如何输出到显示设备
葵花宝典终于要练成了,要想成功必须自宫,错了重来,要想成功必须发狠。革命尚未成功,通知仍需努力!
我们接着看drm_hwcomposer是如何接收HWC命令,将最终图层layer显示到输出设备的。那么这个就得从Output::postFramebuffer说起了!
3.1 drm_hwcomposer是如何接收到显示命令的
我们接着看drm_hwcomposer是如何接收HWC命令,将最终图层layer显示到输出设备的。那么这个就得从Output::postFramebuffer说起了!

文件:frameworks/native/services/surfaceflinger/CompositionEngine/src/Output.cppvoid Output::postFramebuffer() {ATRACE_CALL();ALOGV(__FUNCTION__);...auto frame = presentAndGetFrameFences();mRenderSurface->onPresentDisplayCompleted();...
}文件:frameworks/native/services/surfaceflinger/DisplayHardware/HWComposer.cpp
status_t HWComposer::presentAndGetReleaseFences(DisplayId displayId) {ATRACE_CALL();RETURN_IF_INVALID_DISPLAY(displayId, BAD_INDEX);auto& displayData = mDisplayData[displayId];auto& hwcDisplay = displayData.hwcDisplay;...// GPU合成时执行present,返回present fenceauto error = hwcDisplay->present(&displayData.lastPresentFence);RETURN_IF_HWC_ERROR_FOR("present", error, displayId, UNKNOWN_ERROR);std::unordered_map<HWC2::Layer*, sp<Fence>> releaseFences;// 从hwc里面获得release fenceerror = hwcDisplay->getReleaseFences(&releaseFences);RETURN_IF_HWC_ERROR_FOR("getReleaseFences", error, displayId, UNKNOWN_ERROR);displayData.releaseFences = std::move(releaseFences);return NO_ERROR;
}文件: frameworks/native/services/surfaceflinger/DisplayHardware/FramebufferSurface.cppvoid FramebufferSurface::onFrameCommitted() {if (mHasPendingRelease) {sp<Fence> fence = mHwc.getPresentFence(mDisplayId);if (fence->isValid()) {// 更新BufferSlot的 fencestatus_t result = addReleaseFence(mPreviousBufferSlot,mPreviousBuffer, fence);ALOGE_IF(result != NO_ERROR, "onFrameCommitted: failed to add the"" fence: %s (%d)", strerror(-result), result);}// 释放之前的Bufferstatus_t result = releaseBufferLocked(mPreviousBufferSlot, mPreviousBuffer);ALOGE_IF(result != NO_ERROR, "onFrameCommitted: error releasing buffer:"" %s (%d)", strerror(-result), result);mPreviousBuffer.clear();mHasPendingRelease = false;}
}
3.2 drm_hwcomposer是如何处理到显示逻辑的
有了前面的铺垫,我们应该很容易找到drm_hwcomposer处理present的入口,我们看看:
//hwc2_device/hwc2_device.cppcase HWC2::FunctionDescriptor::PresentDisplay:return ToHook<HWC2_PFN_PRESENT_DISPLAY>(DisplayHook<decltype(&HwcDisplay::PresentDisplay),&HwcDisplay::PresentDisplay, int32_t *>);//
HWC2::Error HwcDisplay::PresentDisplay(int32_t *present_fence) {...//是不是好像SurfaceFlinger里面的compositionengine::CompositionRefreshArgs refreshArgsret = CreateComposition(a_args); ...
}//drm_hwcomposer处理合成显示的核心方法
HWC2::Error HwcDisplay::CreateComposition(AtomicCommitArgs &a_args) {if (IsInHeadlessMode()) {//无头模式,即该HwcDisplay对应的drmpipe显示管线为空ALOGE("%s: Display is in headless mode, should never reach here", __func__);return HWC2::Error::None;}int PrevModeVsyncPeriodNs = static_cast<int>(1E9 / GetPipe().connector->Get()->GetActiveMode().v_refresh());auto mode_update_commited_ = false; // 是否需要更新/提交if (staged_mode_ && // staged_mode_ 当前所处的显示模式staged_mode_change_time_ <= ResourceManager::GetTimeMonotonicNs()) {//这里的client_layer_是HwcDisplay的成员变量,它是一个HwcLayer对象,是用来存储前面标记为cleint合成layer使用gpu合成后的图层//client_layer_的成员变量SetLayerDisplayFrame()用于设置图层的显示区域//SetLayerDisplayFrame()的参数是一个hwc_rect_t类型的对象,该对象包含四个成员变量:left, top, right, bottom//left, top, right, bottom分别表示图层的左上角、右上角、右下角、左下角的坐标client_layer_.SetLayerDisplayFrame((hwc_rect_t){.left = 0,.top = 0,.right = static_cast<int>(staged_mode_->h_display()),.bottom = static_cast<int>(staged_mode_->v_display())});configs_.active_config_id = staged_mode_config_id_;a_args.display_mode = *staged_mode_;if (!a_args.test_only) {mode_update_commited_ = true;}}// order the layers by z-orderbool use_client_layer = false;uint32_t client_z_order = UINT32_MAX;std::map<uint32_t, HwcLayer *> z_map;for (std::pair<const hwc2_layer_t, HwcLayer> &l : layers_) {switch (l.second.GetValidatedType()) {//获取layer合成方式case HWC2::Composition::Device:// z_map中是按照z-order排序的,Device合成的图层z_map.emplace(std::make_pair(l.second.GetZOrder(), &l.second));break;case HWC2::Composition::Client:// Place it at the z_order of the lowest client layer// 找到GPU合成图层中最小的z-order值use_client_layer = true;client_z_order = std::min(client_z_order, l.second.GetZOrder());break;default:continue;}}if (use_client_layer)//将GPU合成的图层添加到z_map中z_map.emplace(std::make_pair(client_z_order, &client_layer_));if (z_map.empty())//z_map为空,没有需要显示或者刷新显示的图层return HWC2::Error::BadLayer;std::vector<DrmHwcLayer> composition_layers;// now that they're ordered by z, add them to the compositionfor (std::pair<const uint32_t, HwcLayer *> &l : z_map) {DrmHwcLayer layer;/*** @brief * HwcLayer转为DrmHwcLayer * 1. 调用HwcLayer的PopulateDrmLayer()方法,将HwcLayer的成员变量拷贝到DrmHwcLayer的成员变量中* 2. 调用DrmHwcLayer的ImportBuffer()方法,做drmPrimeFDToHandle处理,并且这块会根据gralloc的具体* 实现来决定如何获取buffer_info信息*/l.second->PopulateDrmLayer(&layer);int ret = layer.ImportBuffer(GetPipe().device);if (ret) {ALOGE("Failed to import layer, ret=%d", ret);return HWC2::Error::NoResources;}composition_layers.emplace_back(std::move(layer));//将所有需要通过kms显示的图层添加到composition_layers中}/* Store plan to ensure shared planes won't be stolen by other display* in between of ValidateDisplay() and PresentDisplay() calls*///创建DrmKms显示计划 这里的composition_layers就是需要通过kms显示的图层current_plan_ = DrmKmsPlan::CreateDrmKmsPlan(GetPipe(),std::move(composition_layers));if (!current_plan_) {if (!a_args.test_only) {ALOGE("Failed to create DrmKmsPlan");}return HWC2::Error::BadConfig;}a_args.composition = current_plan_;//提交显示,将显示输出到屏幕,这块主要就是调用libdrm的相关API接口进行相关操作,这块的具体逻辑可以看何小龙相关bugint ret = GetPipe().atomic_state_manager->ExecuteAtomicCommit(a_args);return HWC2::Error::None;
}
内容有点多啊,核心的源码已经注释了。我们这里重点看下HwcLayer::PopulateDrmLayer和DrmHwcLayer::ImportBuffer的实现!
HwcLayer::PopulateDrmLayer
//include/drmhwcomposer.h
struct DrmHwcLayer {buffer_handle_t sf_handle = nullptr;hwc_drm_bo_t buffer_info{};std::shared_ptr<DrmFbIdHandle> fb_id_handle;int gralloc_buffer_usage = 0;DrmHwcTransform transform{};DrmHwcBlending blending = DrmHwcBlending::kNone;uint16_t alpha = UINT16_MAX;hwc_frect_t source_crop;hwc_rect_t display_frame;DrmHwcColorSpace color_space;DrmHwcSampleRange sample_range;UniqueFd acquire_fence;int ImportBuffer(DrmDevice *drm_device);bool IsProtected() const {return (gralloc_buffer_usage & GRALLOC_USAGE_PROTECTED) ==GRALLOC_USAGE_PROTECTED;}
};//hwc2_device/HwcLayer.cpp
//将HwcLayer的属性转移到DrmHwcLayre中
void HwcLayer::PopulateDrmLayer(DrmHwcLayer *layer) {layer->sf_handle = buffer_;//buffer_handle_t buffer_// TODO(rsglobal): Avoid extra fd duplicationlayer->acquire_fence = UniqueFd(fcntl(acquire_fence_.Get(), F_DUPFD_CLOEXEC));layer->display_frame = display_frame_;layer->alpha = std::lround(alpha_ * UINT16_MAX);layer->blending = blending_;layer->source_crop = source_crop_;layer->transform = transform_;layer->color_space = color_space_;layer->sample_range = sample_range_;
}
DrmHwcLayer::ImportBuffer
我们接着看下它的实现逻辑:
//utils/hwcutils.cpp
int DrmHwcLayer::ImportBuffer(DrmDevice *drm_device) {buffer_info = hwc_drm_bo_t{};//核心逻辑把buffer_handle_t对象转换成hwc_drm_bo_t对象//sf_handle是buffer_handle_t对象//buffer_info是hwc_drm_bo_t对象,并且这块和gralloc的具体实现有关系,那么就会对饮不同的BufferInfo//有好几个类实现了ConvertBoInfo,那么最终调用的是那个呢int ret = BufferInfoGetter::GetInstance()->ConvertBoInfo(sf_handle,&buffer_info);if (ret != 0) {ALOGE("Failed to convert buffer info %d", ret);return ret;}//核心逻辑是调用drmPrimeFDToHandlefb_id_handle = drm_device->GetDrmFbImporter().GetOrCreateFbId(&buffer_info);if (!fb_id_handle) {ALOGE("Failed to import buffer");return -EINVAL;}return 0;
}//bufferinfo/BufferInfoGetter.cpp
BufferInfoGetter *BufferInfoGetter::GetInstance() {static std::unique_ptr<BufferInfoGetter> inst;if (!inst) {
//这块逻辑只有配置ro.hardware.hwcomposer=drm且Android SDK版本大于等于30时才会执行
#if PLATFORM_SDK_VERSION >= 30 && defined(USE_IMAPPER4_METADATA_API)inst.reset(BufferInfoMapperMetadata::CreateInstance());if (!inst) {ALOGW("Generic buffer getter is not available. Falling back to legacy...");}
#endifif (!inst) {//这里会创建一个LegacyBufferInfoGetter的实例,但是在当前类中返回的是null,那么只有一个可能是在子类中实现了inst = LegacyBufferInfoGetter::CreateInstance();}}return inst.get();
}__attribute__((weak)) std::unique_ptr<LegacyBufferInfoGetter>
LegacyBufferInfoGetter::CreateInstance() {ALOGE("No legacy buffer info getters available");return nullptr;
}
那么是谁重重写实现了LegacyBufferInfoGetter::CreateInstance()呢,这个就要从ro.hardware.hwcomposer的配置说起了,这里我们配置为minigbm,所以编译的就是hwcomposer.drm_minigbm,如下:
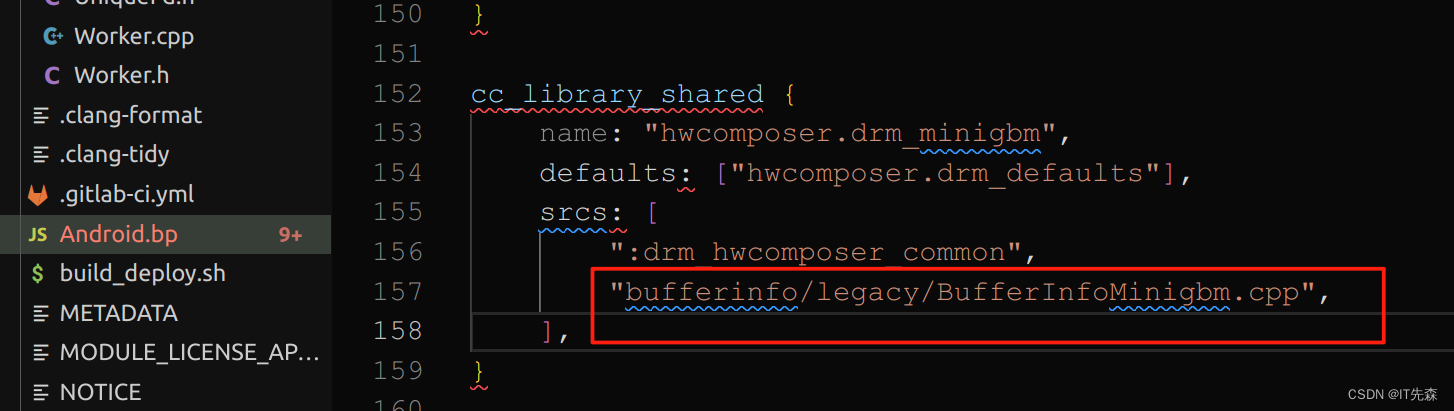
//Android.bp
cc_library_shared {name: "hwcomposer.drm_minigbm",defaults: ["hwcomposer.drm_defaults"],srcs: [":drm_hwcomposer_common","bufferinfo/legacy/BufferInfoMinigbm.cpp",],
}
我们进入到BufferInfoMinigbm瞧瞧看看:
//
namespace android {
LEGACY_BUFFER_INFO_GETTER(BufferInfoMinigbm);
}//bufferinfo/BufferInfoGetter.h
#define LEGACY_BUFFER_INFO_GETTER(getter_) \std::unique_ptr<LegacyBufferInfoGetter> \LegacyBufferInfoGetter::CreateInstance() { \auto instance = std::make_unique<getter_>(); \if (instance) { \int err = instance->Init(); //初始化 \if (err) { \ALOGE("Failed to initialize the " #getter_ " getter %d", err); \instance.reset(); \} \err = instance->ValidateGralloc(); \if (err) { \instance.reset(); \} \} \return std::move(instance); \}
那我们接着看下minigbm的ConvertBoInfo实现:
//bufferinfo/BufferInfoGetter.cpp
int LegacyBufferInfoGetter::Init() {//加载gralloc模块int ret = hw_get_module(GRALLOC_HARDWARE_MODULE_ID,// NOLINTNEXTLINE(cppcoreguidelines-pro-type-reinterpret-cast)reinterpret_cast<const hw_module_t **>(&gralloc_));if (ret != 0) {ALOGE("Failed to open gralloc module");return ret;}ALOGI("Using %s gralloc module: %s\n", gralloc_->common.name,gralloc_->common.author);return 0;
}//bufferinfo/legacy/BufferInfoMinigbm.cpp
int BufferInfoMinigbm::ConvertBoInfo(buffer_handle_t handle, hwc_drm_bo_t *bo) {if (handle == nullptr) {return -EINVAL;}uint32_t width{};uint32_t height{};//通过gralloc_->perform来获取buffer的信息if (gralloc_->perform(gralloc_, CROS_GRALLOC_DRM_GET_DIMENSIONS, handle,&width, &height) != 0) {ALOGE("CROS_GRALLOC_DRM_GET_DIMENSIONS operation has failed. ""Please ensure you are using the latest minigbm.");return -EINVAL;}int32_t droid_format{};if (gralloc_->perform(gralloc_, CROS_GRALLOC_DRM_GET_FORMAT, handle,&droid_format) != 0) {ALOGE("CROS_GRALLOC_DRM_GET_FORMAT operation has failed. ""Please ensure you are using the latest minigbm.");return -EINVAL;}uint32_t usage{};if (gralloc_->perform(gralloc_, CROS_GRALLOC_DRM_GET_USAGE, handle, &usage) !=0) {ALOGE("CROS_GRALLOC_DRM_GET_USAGE operation has failed. ""Please ensure you are using the latest minigbm.");return -EINVAL;}struct cros_gralloc0_buffer_info info {};if (gralloc_->perform(gralloc_, CROS_GRALLOC_DRM_GET_BUFFER_INFO, handle,&info) != 0) {ALOGE("CROS_GRALLOC_DRM_GET_BUFFER_INFO operation has failed. ""Please ensure you are using the latest minigbm.");return -EINVAL;}bo->width = width;bo->height = height;bo->hal_format = droid_format;bo->format = info.drm_fourcc;bo->usage = usage;for (int i = 0; i < info.num_fds; i++) {bo->modifiers[i] = info.modifier;bo->prime_fds[i] = info.fds[i];bo->pitches[i] = info.stride[i];bo->offsets[i] = info.offset[i];}return 0;
}
DrmKmsPlan::CreateDrmKmsPlan
最后我们看下CreateDrmKmsPlan的实现
//compositor/DrmKmsPlan.cpp
namespace android {
auto DrmKmsPlan::CreateDrmKmsPlan(DrmDisplayPipeline &pipe,std::vector<DrmHwcLayer> composition)-> std::unique_ptr<DrmKmsPlan> {auto plan = std::make_unique<DrmKmsPlan>();//获取可用的planeauto avail_planes = pipe.GetUsablePlanes();int z_pos = 0;for (auto &dhl : composition) {std::shared_ptr<BindingOwner<DrmPlane>> plane;/* Skip unsupported planes */do {if (avail_planes.empty()) {return {};}//这个地方有疑问,为啥要erase掉plane,万一它能匹配后面遍历的plane呢plane = *avail_planes.begin();avail_planes.erase(avail_planes.begin());} while (!plane->Get()->IsValidForLayer(&dhl));LayerToPlaneJoining joining = {.layer = std::move(dhl),.plane = plane,.z_pos = z_pos++,};//使用构建的joining填充DrmKmsPlaneplan->plan.emplace_back(std::move(joining));}return plan;
}} // namespace android四. 写在最后
好了今天的博客Android下HWC以及drm_hwcomposer普法(下)就到这里了。总之,青山不改绿水长流先到这里了。如果本博客对你有所帮助,麻烦关注或者点个赞,如果觉得很烂也可以踩一脚!谢谢各位了!!
相关文章:
Android下HWC以及drm_hwcomposer普法(下)
Android下HWC以及drm_hwcomposer普法(下) 引言 不容易啊,写到这里。经过前面的普法(上),我相信童鞋们对HWC和drm_hwcomposer已经有了一定的认知了。谷歌出品,必须精品。我们前面的篇章见分析到啥来了,对了分析到了HwcDisplay::in…...

【评价类模型】熵权法
1.客观赋权法: 熵权法是一种客观求权重的方法,所有客观求权重的模型中都要有以下几步: 1.正向化处理: 极小型指标:取值越小越好的指标,例如错误率、缺陷率等。 中间项指标:取值在某个范围内较…...
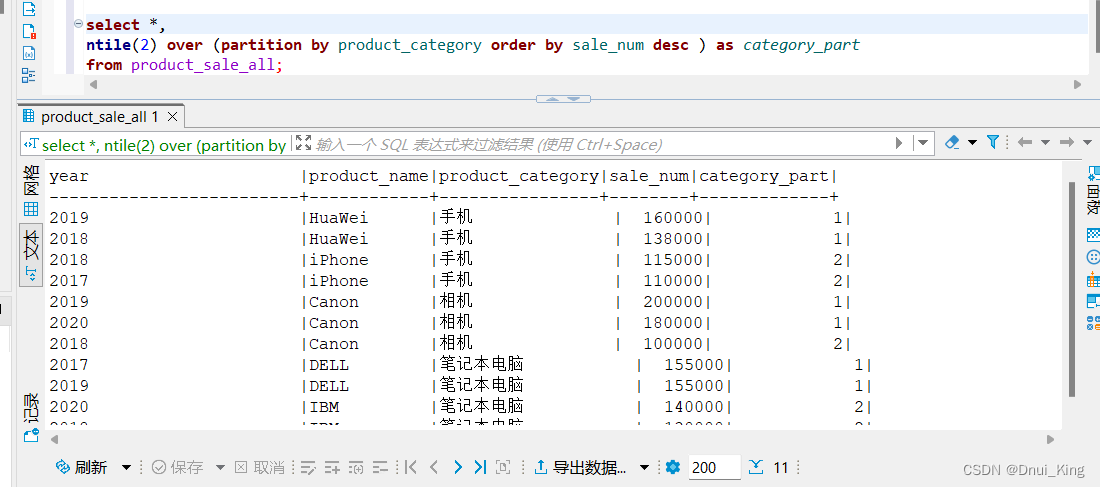
PG 窗口函数
一,简介 窗口函数也叫分析函数,也叫OLAP函数,通过partition by分组,这里的窗口表示范围,,可以不指定PARATITION BY,会将这个表当成一个大窗口。 二,应用场景 (1)用于分…...
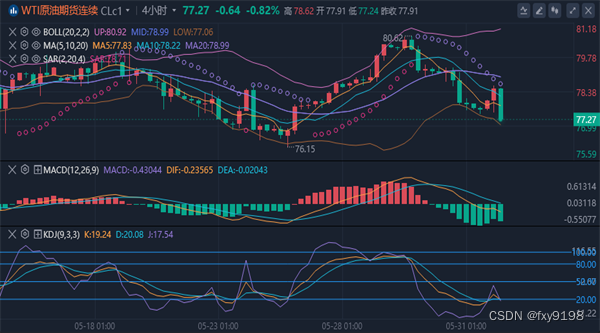
冯喜运:5.31晚间黄金原油行情分析及尾盘操作策略
【黄金消息面分析】:周五(5月31日),最新发布的数据显示,美国4月核心PCE物价指数月率录得0.2%,低于预期(0.3%),经济学家认为,核心指数比整体指数更能反映通胀。除此之外,美…...

Vue 框选区域放大(纯JavaScript实现)
需求:长按鼠标左键框选区域,松开后放大该区域,继续框选继续放大,反向框选恢复原始状态 实现思路:根据鼠标的落点,放大要显示的内容(内层盒子),然后利用水平偏移和垂直偏…...

C#加密与java 互通
文章目录 前言对方接口签名要求我方对接思路1.RSA 加密2.AES256加密 完整的加密帮助类 前言 提示:这里可以添加本文要记录的大概内容: 在我们对接其他公司接口的时候,时常会出现对方使用的开发语言和我方使用的开发语言不同的情况ÿ…...
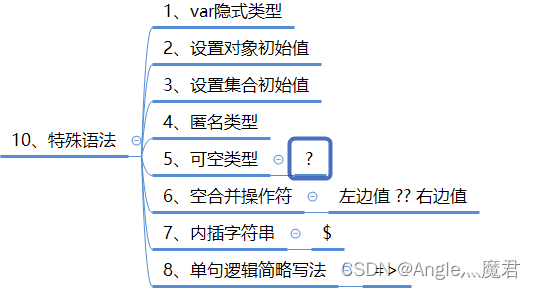
C#【进阶】特殊语法
特殊语法、值和引用类型 特殊语法 文章目录 特殊语法1、var隐式类型2、设置对象初始值3、设置集合初始值4、匿名类型5、可空类型6、空合并操作符7、内插字符串8、单句逻辑简略写法 值和引用类型1、判断值和引用类型2、语句块3、变量的生命周期4、结构体中的值和引用5、类中的值…...

c语言之向文件读写数据块
c语言需要向文件读写数据块需要用到fread语句和fwrite语句 fread语句的语法格式 fread(butter,size,count,fp) butter:读取的数据存入内存地址 size:读取的字节大小 count:读取数据的个数 fp:读取的文件指针 fwrite语句语法格式 fwrite(butter,size,count,fp…...

6键编程智能照明:编程指南与深度解析
6键编程智能照明:编程指南与深度解析 随着智能家居的普及,智能照明系统逐渐成为现代家庭不可或缺的一部分。而6键编程智能照明,以其高度的灵活性和个性化设置,受到了越来越多消费者的青睐。那么,如何对6键编程智能照明…...

sql server 中的6种约束
一、约束定义 约束是用于定义和实施表的规则和限制,以确保数据的完整性和一致性。 即对一张表中的属性操作进行限制。 二、约束分类 通过定义约束,可以对数据库中的数据进行限制,以下是常见的约束: 1. 主键约束(Pr…...

师彼长技以助己(2)产品思维
师彼长技以助己(2)产品思维 前言 我把产品思维称之为:人生底层的能力以及蹉跎别人还蹉跎自己的能力,前者说明你应该具备良好产品思维原因,后者是你没有好的产品思维去做产品带来的灾难。 人欲即天理 请大家谈谈看到这…...
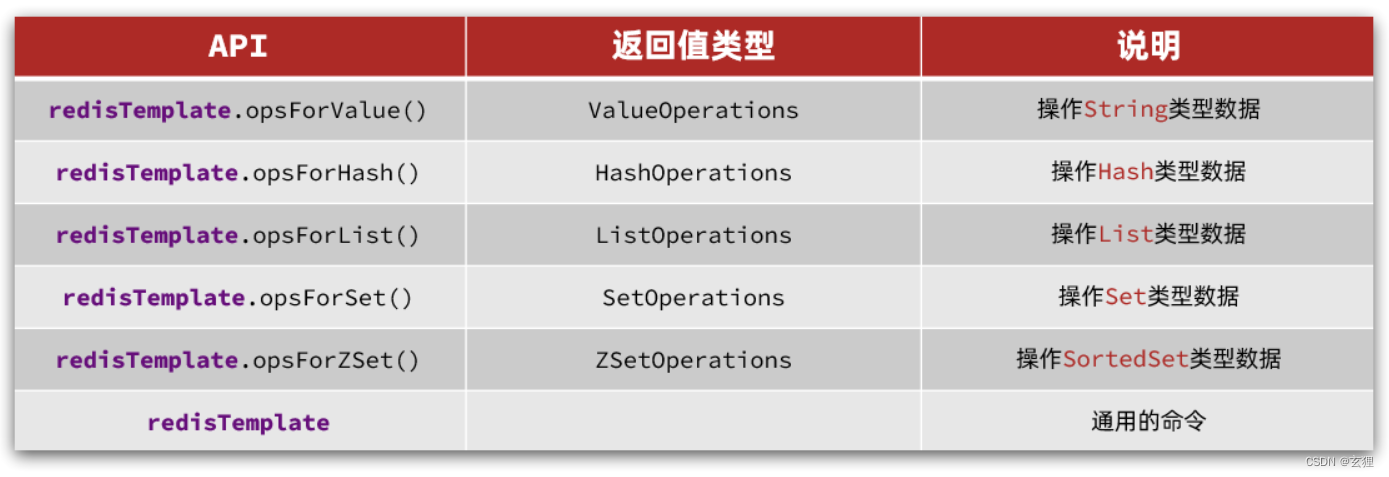
Redis学习笔记【基础篇】
SQL vs NOSQL SQL(Structured Query Language)和NoSQL(Not Only SQL)是两种不同的数据库处理方式,它们在多个维度上有所差异,主要区别包括: 数据结构: SQL(关系型数据库)…...
【文献阅读】基于模型设计的汽车软件质量属性
参考文献:《基于模型设计满足汽车软件质量和快速交付的挑战》,深向科技在2024年MATLAB XEPO大会的演讲 Tips:KISS原则,全称为“Keep It Simple, Stupid”,直译为“保持简单,愚蠢的人也能懂”...

撸广告赚金币小游戏app开发
在app上投放广告有哪些注意事项? 在app上投放广告需要注意以下几个方面。 首先,要选择合适的广告形式。根据自己的需求和目标受众,选择合适的广告形式,如横幅广告、插屏广告、视频广告等。不同的广告形式适用于不同的场景和目标…...

海外高清短视频:四川京之华锦信息技术公司
海外高清短视频:探索世界的新窗口 在数字化时代的浪潮下,海外高清短视频成为了人们探索世界、了解异国风情的新窗口。四川京之华锦信息技术公司这些短视频以其独特的视角、丰富的内容和高清的画质,吸引了无数观众的目光,让人们足…...

16:00面试,16:08就出来了,问的问题有点变态。。。
从小厂出来,没想到在另一家公司又寄了。 到这家公司开始上班,加班是每天必不可少的,看在钱给的比较多的份上,就不太计较了。没想到8月一纸通知,所有人不准加班,加班费不仅没有了,薪资还要降40%…...
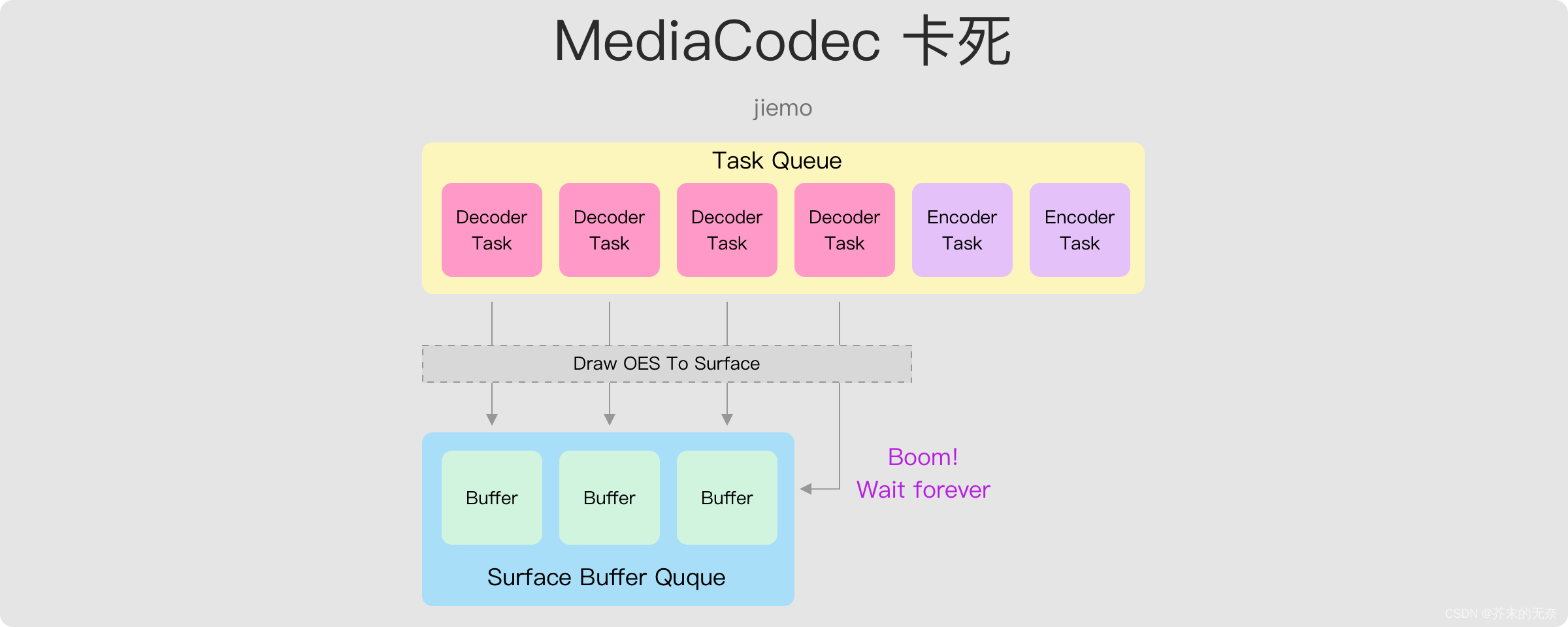
Android MediaCodec 简明教程(九):使用 MediaCodec 解码到纹理,使用 OpenGL ES 进行处理,并编码为 MP4 文件
系列文章目录 Android MediaCodec 简明教程(一):使用 MediaCodecList 查询 Codec 信息,并创建 MediaCodec 编解码器Android MediaCodec 简明教程(二):使用 MediaCodecInfo.CodecCapabilities 查…...
Neo4j安装部署及python连接neo4j操作
Neo4j安装部署及python连接neo4j操作 Neo4j安装和环境配置 安装依赖库: sudo apt-get install wget curl nano software-properties-common dirmngr apt-transport-https gnupg gnupg2 ca-certificates lsb-release ubuntu-keyring unzip -y 增加Neo4 GPG key&…...
一维时间序列信号的改进小波降噪方法(MATLAB R2021B)
目前国内外对于小波分析在降噪方面的方法研究中,主要有小波分解与重构法降噪、小波阈值降噪、小波变换模极大值法降噪等三类方法。 (1)小波分解与重构法降噪 早在1988 年,Mallat提出了多分辨率分析的概念,利用小波分析的多分辨率特性进行分…...
Java整合EasyExcel实战——3(上下列相同合并单元格策略)
参考:https://juejin.cn/post/7322156759443095561?searchId202405262043517631094B7CCB463FDA06https://juejin.cn/post/7322156759443095561?searchId202405262043517631094B7CCB463FDA06 准备条件 依赖 <dependency><groupId>com.alibaba</gr…...

终极qmcdump指南:5分钟掌握QQ音乐加密格式解密技巧
终极qmcdump指南:5分钟掌握QQ音乐加密格式解密技巧 【免费下载链接】qmcdump 一个简单的QQ音乐解码(qmcflac/qmc0/qmc3 转 flac/mp3),仅为个人学习参考用。 项目地址: https://gitcode.com/gh_mirrors/qm/qmcdump qmcdump是…...

终极指南:3步掌握yfinance金融数据获取与智能修复实战
终极指南:3步掌握yfinance金融数据获取与智能修复实战 【免费下载链接】yfinance Download market data from Yahoo! Finances API 项目地址: https://gitcode.com/GitHub_Trending/yf/yfinance yfinance是一个强大的Python库,能够从Yahoo! Finan…...

多维子集和问题:NP难问题的算法与应用解析
1. 多维子集和问题概述多维子集和问题(Multi-dimensional Subset Sum Problem)是计算复杂度理论中的经典NP难问题。简单来说,它要求在给定的n维向量集合中,找出一个子集,使得该子集中所有向量在每一维上的和恰好等于目标向量对应的分量。这个…...

智能体开发实战:从框架选型到部署优化的完整指南
1. 项目概述:一个为智能体开发者准备的“军火库”如果你正在或打算踏入智能体(Agent)开发这个领域,那么你很可能已经体会过那种“万事开头难”的迷茫。从选择哪个框架开始,到如何设计一个有效的智能体工作流࿰…...
Pixel Framebuf库:图形化编程驱动LED矩阵,告别底层坐标换算
1. 项目概述:告别点灯,拥抱图形化LED矩阵编程如果你玩过Arduino或者树莓派,大概率接触过WS2812B这类可寻址LED,也就是大家常说的NeoPixel。单个灯珠的控制很简单,setPixelColor一下就能亮。但当你面对一个8x8、16x16甚…...

如何用Wedecode实现微信小程序源代码的完美还原:从加密包到可读代码的完整指南
如何用Wedecode实现微信小程序源代码的完美还原:从加密包到可读代码的完整指南 【免费下载链接】wedecode 全自动化,微信小程序 wxapkg 包 源代码还原工具, 线上代码安全审计,支持 Windows, Macos, Linux 项目地址: https://gitcode.com/gh…...

从二维到三维:DIY LED视频立方体构建全攻略
1. 项目概述:从平面到立体的视觉革命几年前,当我第一次成功点亮一整面由32x32 RGB LED面板组成的视频墙时,那种由1024个像素点共同编织出的动态画面所带来的震撼,至今记忆犹新。但作为一个热衷于将技术推向边界的创作者࿰…...

ARM ETMv4跟踪单元架构与寄存器详解
1. ARM ETMv4跟踪单元架构概述在嵌入式系统开发领域,指令跟踪技术是调试复杂软件问题的关键工具。ARM架构中的嵌入式跟踪宏单元(Embedded Trace Macrocell, ETM)作为处理器核心的实时跟踪组件,能够非侵入式地记录程序执行流程。ETMv4作为当前主流版本&am…...

C++中的封装、继承、多态理解
封装(encapsulation):就是将抽象得到的数据和行为(或功能)相结合,形成一个有机的整体,也就是将数据与操作数据的源代码进行有机的结合,形成”类”,其中数据和函数都是类的成员。封装的目的是增强安全性和简化编程&…...

从刺绣到互动:用导电绣线与微控制器打造光控可穿戴艺术
1. 项目概述与核心价值最近在捣鼓一个特别有意思的玩意儿:把会发光的电子元件“绣”到衣服上,让它不仅能穿,还能跟你互动。这个光控发光琵琶鱼刺绣项目,就是一个绝佳的入门案例。它完美地融合了传统手工艺(刺绣&#x…...