编译器屏障概述
文章目录
- 1. 前言
- 2. 编译器内存屏障
- 2.1 编译器内存访问重排序规则
- 2.2 编译器屏障的几种形式
- 2.2.1 显式编译器屏障
- 2.2.2 隐式编译器屏障
- 2.2.3 硬件内存屏障充当编译屏障
- 2.2.4 编程语言内存模型提供的编译屏障
- 2.3 编译器内存屏障实例
- 2.3.1 Linux spinlock
- 3. 结语
- 4. 参考资料
1. 前言
2. 编译器内存屏障
编译屏障,相对于运行时的硬件屏障,它是一种编译时行为,其目的是阻止编译器对内存访问实行程序员不期望的优化行为,如存储访问合并、将循环内的读取行为移动到循环外等等。
2.1 编译器内存访问重排序规则
虽然编译器可以优化代码的存储访问,以得到更好的性能,但编译器开发人员和CPU 供应商普遍应遵循的内存访问重排序的一个基本规则,该规则可以表述为:不得修改单线程程序的行为。这条基本规则的意思是,不管是编译时的编译器内存访问重排序,还是运行时的 CPU 内存访问重排序,都要在不改变单线程行为的前提下进行。如有以下代码:
int x, y;void foo(void)
{x = y + 1;y = 0;
}
假定代码通过如下版本 ARM GCC 编译器(这也是本文所有示范代码采用的编译器)进行编译:
$ arm-linux-gnueabi-gcc --version
arm-linux-gnueabi-gcc (Ubuntu/Linaro 5.4.0-6ubuntu1~16.04.9) 5.4.0 20160609
Copyright (C) 2015 Free Software Foundation, Inc.
This is free software; see the source for copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
在不启用优化的情形下编译,会生成如下汇编代码(只截取函数 foo() 对应部分):
$ arm-linux-gnueabi-gcc -S foo.c
/* foo.s */....type foo, %function
foo:@ args = 0, pretend = 0, frame = 0@ frame_needed = 1, uses_anonymous_args = 0@ link register save eliminated.str fp, [sp, #-4]!add fp, sp, #0ldr r3, .L2 // r3 = &yldr r3, [r3] // r3 = yadd r3, r3, #1 // r3 = y + 1ldr r2, .L2+4 // r2 = &xstr r3, [r2] // (1) x = y + 1ldr r3, .L2 // r3 = &ymov r2, #0 // r2 = 0str r2, [r3] // (2) y = 0nopsub sp, fp, #0@ sp neededldr fp, [sp], #4bx lr
.L3:.align 2
.L2:.word y.word x
...
从上面编译器生成的汇编代码代码我们看到,在上面 (1) 和 (2) 处,先 x = y + 1; 后 y = 0; 是符合编程顺序的。再看一下,在(加上 -O2 编译选项)启用编译器优化的情形下,会生成怎样的汇编代码(只截取函数 foo() 对应部分):
$ arm-linux-gnueabi-gcc -O2 -S foo.c
/* foo.s */....type foo, %function
foo:@ args = 0, pretend = 0, frame = 0@ frame_needed = 0, uses_anonymous_args = 0@ link register save eliminated.mov r0, #0ldr r2, .L2 // r2 = &yldr r1, .L2+4 // r1 = &xldr r3, [r2] // r3 = ystr r0, [r2] // (1) x = 0 add r3, r3, #1 // r3 = y + 1str r3, [r1] // (2) x = y + 1bx lr
.L3:.align 2
.L2:.word y.word x
...
我们看到,优化后的汇编代码,在 (1) 和 (2) 处,将 x = 0; 的赋值操作,放在了 x = y + 1 的赋值操作之前,这和前面的编程顺序不一致,也即编译器出现了对存储访问的重排序。由于 y 的初始值为0,所以 x = 0; 和 x = y + 1 无论哪个在前执行,在单线程执行环境下,都不影响结果,这遵循前面提到的规则。
由于这条规则,编写单线程代码的程序员基本上不会注意到内存重排序。在多线程编程中,它也经常被忽视,因为互斥锁、信号量自带编译屏障功能,可以防止在它们周围的内存操作重排序。只有当使用无锁技术时,当内存在线程之间共享而没有任何互斥操作时,可以清楚地观察到内存重排序的效果。编译器的内存访问重排序通常只在启用优化的时候发生。在单处理器系统上,编译屏障已经足够保障对数据的并发访问安全,因为不会出现真正的并行访问,毕竟系统中只有一个处理器。
2.2 编译器屏障的几种形式
2.2.1 显式编译器屏障
以 GCC 编译器为例,来说明显式编译器屏障,其定义如下:
__asm__ volatile("" ::: "memory")
"memory" 阻止将变量缓存到寄存器,强制从内存读取;同时如果访问变量既没有出现在 __asm__ 语句的 input 部分,也没有出现在 __asm__ 语句的 output 部分,则还要加上 __volatile__ 关键字,强制从内存读取。__volatile__ 关键字同时也阻止了编译移动语句(譬如移出循环),指令重排。
编译器(显式)屏障的作用,就是阻止对其前后的内存访问进行重排序。还是以章节 2.1 的代码为例,在其中插入插入一个显式编译器屏障,仍然用 -O2 优化选项进行编译,看是否能阻止对 x = y + 1; 和 y = 0; 的重排序。修改后的代码如下:
int x, y;void foo(void)
{x = y + 1;asm volatile("" ::: "memory"); // 插入一个编译屏障y = 0;
}
再看一下,在(加上 -O2 编译选项)启用编译器优化的情形下,会生成怎样的汇编代码(只截取函数 foo() 对应部分):
$ arm-linux-gnueabi-gcc -O2 -S foo.c
....type foo, %function
foo:@ args = 0, pretend = 0, frame = 0@ frame_needed = 0, uses_anonymous_args = 0@ link register save eliminated.@ A = B + 1;ldr r2, .L2 // r2 = &yldr r1, .L2+4 // r1 = &xldr r3, [r2] // r3 = yadd r3, r3, #1 // r3 = y + 1str r3, [r1] // (1) x = y + 1mov r3, #0 // r3 = 0str r3, [r2] // (2) y = 0bx lr
.L3:.align 2
.L2:.word y.word x
...
我们看到,在加入(显式)编译器屏障后,优化后的汇编代码,在 (1) 和 (2) 处,已经按编程顺序执行了对 x 和 y 的存储访问,这是编译屏障起了作用。
2.2.2 隐式编译器屏障
在代码里面的一些 sequence points 如函数调用、对 volatile 变量的访问等,可以作为隐式编译屏障。事实上,大多数函数调用都可充当编译器屏障,无论它们自身是否包含编译器屏障,但这不包括内联函数、使用 pure 属性声明的函数以及使用链接时生成的代码。另外,带编译屏障的函数,哪怕内联了,也作为编译屏障使用。下面来看函数做为隐式编译器屏障的一个例子:
int x, y;void foo(void)
{x = y + 1;y = 0;
}struct foo_data {int bar, bar2;
};void do_something(struct foo_data *foo_data)
{foo_data->bar = 5;foo();foo_data->bar2 = foo_data->bar;
}
开启 -O2 选项进行编译:
$ arm-linux-gnueabi-gcc -O2 -S foo.c
生成如下汇编代码(只截取相关部分):
....type do_something, %function
do_something:@ args = 0, pretend = 0, frame = 0@ frame_needed = 0, uses_anonymous_args = 0str lr, [sp, #-4]! // 保存 lr 到堆栈mov r1, #5 // r1 = 5mov lr, #0 // lr = 0ldr r2, .L6 // r2 = &yldr ip, .L6+4 // ip = &xldr r3, [r2] // r3 = ystr r1, [r0, #4] // (1) foo_data->bar2 = 5add r3, r3, #1 // r3 = y + 1str r1, [r0] // foo_data->bar = 5 (2)str lr, [r2] // y = 0str r3, [ip] // x = y + 1ldr pc, [sp], #4 // 从 do_something() 函数返回
.L7:.align 2
.L6:.word y.word x
...
从汇编代码看到,函数 foo() 已经被内联到函数 do_something() 内,且 在 (1) 和 (2) 处,foo_data->bar = 5; 和 foo_data->bar2 = foo_data->bar; 的顺序和编程顺序正好相反,即产生了编译乱序。为避免这种情况,第 1 种方法是阻止函数 foo() 被内联,第 2 种方法是在函数 foo() 内插入编译屏障。这里只演示第 1 种方法,修改后代码如下:
int x, y;void foo(void) __attribute__((noinline)); // 阻止函数 foo() 被内联void foo(void)
{x = y + 1;y = 0;
}struct foo_data {int bar, bar2;
};void do_something(struct foo_data *foo_data)
{foo_data->bar = 5;foo();foo_data->bar2 = foo_data->bar;
}
开启 -O2 选项进行编译:
$ arm-linux-gnueabi-gcc -O2 -S foo.c
生成如下汇编代码(只截取相关部分):
.type do_something, %function
do_something:@ args = 0, pretend = 0, frame = 0@ frame_needed = 0, uses_anonymous_args = 0mov r3, #5 // r3 = 5push {r4, lr} // 保存 r4, lr 到堆栈mov r4, r0 // r4 = foo_datastr r3, [r0] // (1) foo_data->bar = 5;bl foo // 调用函数 foo(),函数没有被内联了ldr r3, [r4] // (2) r3 = foo_data->barstr r3, [r4, #4] // (3) foo_data->bar2 = foo_data->bar;pop {r4, pc} // 从堆栈恢复 r4,并从函数返回
从 (1) 和 (3) 处看到,编译器优化后的代码,仍然保持对 foo_data->bar 和 foo_data->bar2 写操作顺序和代码一致,另外,从 (2) 处看到,对 foo_data->bar2 的赋值前,重新读取了 foo_data->bar 的值,这是合理的,因为我们无法知道,函数 foo() 是否对 foo_data->bar 进行了修改(譬如函数参数 foo_data 指向一个全局变量,而刚好 foo() 修改了它)
除了这些情况之外,对外部函数的调用甚至比编译器障碍更强,因为编译器不知道函数的副作用是什么。编译器必须忘记它对内存所做的任何假设,这些假设可能对该函数可见。仔细想想,这很有道理。在上面的代码片段中,假设 foo() 实现存在于外部库中,编译器如何知道 foo() 不依赖于 foo_data->bar 的值?它如何知道 foo() 不会修改内存中的 foo_data->bar?显然编译器不得而知。因此,为了遵守内存访问重排序的基本规则,它不得围绕对 foo() 这个外部调用对任何内存访问进行重排序。同样,在调用完成后,它必须从内存中加载 foo_data->bar 的新值,而不是假设它仍然等于 5,即使启用了优化。
在许多情况下,编译器指令重新排序是被禁止的,甚至当编译器必须从内存中重新加载某些值时也是如此。这些隐藏的规则构成了人们长期以来一直说 C 中的 valotile 数据类型,在正确编写的多线程代码中通常不是必需的重要原因。
2.2.3 硬件内存屏障充当编译屏障
硬件内存屏障,也可以充当编译屏障。而在单处理器系统上,所有的硬件内存屏障定义都退化为编译屏障。如 Linux 的内存屏障接口在单处理器系统上定义如下:
/* include/asm-generic/barrier.h *//** Force strict CPU ordering. And yes, this is required on UP too when we're* talking to devices.** Fall back to compiler barriers if nothing better is provided.*/#ifndef mb
#define mb() barrier()
#endif#ifndef rmb
#define rmb() mb()
#endif#ifndef wmb
#define wmb() mb()
#endif...#ifdef CONFIG_SMP/* 多处理器系统定义 */#else/* 单处理器系统定义 */#ifndef smp_mb
#define smp_mb() barrier()
#endif#ifndef smp_rmb
#define smp_rmb() barrier()
#endif#ifndef smp_wmb
#define smp_wmb() barrier()
#endif#endif /* CONFIG_SMP */
2.2.4 编程语言内存模型提供的编译屏障
譬如 C++,引入了自己的内存模式,并提供内存屏障接口对存储访问保序。如下面的例子:
int value;
std::atomic<int> is_updated(0);void update_value(int x)
{value = x;// 在这里阻止 value 和 is_updated 存储操作的重排序is_updated.store(1, std::memory_order_release);
}
2.3 编译器内存屏障实例
2.3.1 Linux spinlock
/* kernel/locking/qspinlock.c *//** Per-CPU queue node structures; we can never have more than 4 nested* contexts: task, softirq, hardirq, nmi.** Exactly fits one 64-byte cacheline on a 64-bit architecture.** PV doubles the storage and uses the second cacheline for PV state.*/
/* per-cpu 的数组 mcs_nodes[MAX_NODES] */
static DEFINE_PER_CPU_ALIGNED(struct mcs_spinlock, mcs_nodes[MAX_NODES]);void queued_spin_lock_slowpath(struct qspinlock *lock, u32 val)
{...
queue:node = this_cpu_ptr(&mcs_nodes[0]); // node 指向当前 CPU 的 mcs_nodes[MAX_NODES] 数组idx = node->count++; // count 最大值为 MAX_NODEStail = encode_tail(smp_processor_id(), idx);node += idx; // 使用当前 CPU mcs_nodes[MAX_NODES] 的 mcs_nodes[idx]/** Ensure that we increment the head node->count before initialising* the actual node. If the compiler is kind enough to reorder these* stores, then an IRQ could overwrite our assignments.*/barrier();node->locked = 0;node->next = NULL;pv_init_node(node); // (1) 修改 node 指向的结构体成员变量值...
}
在这里,由于变量 mcs_nodes[MAX_NODES] 是 per-cpu 的,每个 CPU 只会访问自己的变量空间,所以不用考虑多个 CPU 并行、并发访问 mcs_nodes[MAX_NODES] 的情形。在当前上下文,由于 spin_lock() 已经禁用了当前 CPU 上抢占,唯一的并发场景是在中断中也使用同一 spinlock 的情形,所以这里只要保障 node->count++ 操作在对 node 的初始化操作 node->locked = 0; node->next = NULL; pv_init_node(node); 之前完成,那么就不会出现中断中对当前 CPU 数据 mcs_nodes[idx] 的覆写,因为 mcs_nodes[MAX_NODES] 是每 CPU 的数据,所以不会有多个 CPU 对它的并行访问,对它的访问相当于单核场景。所以这里要做的,就是简单的插入一个编译屏障 barrier() 就可以了。如果读者难以能理解这里的场景,那么可以反过来思考:如果对 node 的初始化操作 node->locked = 0; 和 node->next = NULL; pv_init_node(node); 先于 node->count++ 发生,会变成怎样?譬如某个线程刚好执行完了 pv_init_node(node); 修改了 node 的值,在 node->count++ 执行前,中断进来了,也使用和线程相同的 spinlock,然后因为线程中 node->count++ 还没执行,所以中断和线程使用同一个 node,然后修改 node 的值,这时候前面线程对 node 的修改值就会被中断中的写操作覆写。如果 保证 node->count++ 执行在前,那么线程和中断修改的将会是不同的 node ,也就不会出现覆写的情况。
3. 结语
虽然编译乱序为我们带来了很多烦恼,但它只影响无锁编程的场合,因为带锁的场合,锁自身就含有内存屏障语义。
在多 CPU 系统下,编译器屏障无法阻止 CPU 带来的存储乱序,这需要硬件内存屏障来保护。
如果我们不是编译器的开发者,或者对使用的编译的各个细节非常熟悉,这时候编译器生成的汇编代码可以指导我们应该怎样、或这哪里插入编译屏障。
4. 参考资料
[1] How can I judge where should I put memory barrier in the code?
[2] GCC-Inline-Assembly-HOWTO
[3] Memory Ordering at Compile Time
[4] Optimization of conditional access to globals: thread-unsafe?
[5] https://www.oracle.com/technetwork/server-storage/solarisstudio/documentation/oss-compiler-barriers-176055.pdf
[6] https://topic.alibabacloud.com/a/understanding-memories-barrier-memory-barrier_8_8_10252214.html
[7] https://yarchive.net/comp/linux/ACCESS_ONCE.html
[8] https://yarchive.net/comp/linux/memory_barriers.html
[9] https://www.quora.com/Can-you-explain-what-a-compiler-barrier-is
[10] https://alibaba-cloud.medium.com/memory-model-and-synchronization-primitive-part-1-memory-barrier-9585e50b4735
[11] https://android.googlesource.com/kernel/msm/+/android-msm-marlin-3.18-nougat-dr1/Documentation/memory-barriers.txt
[12] https://hackmd.io/@VIRqdo35SvekIiH4p76B7g/Hy9JyrBw?type=view
[13] https://developer.arm.com/documentation/den0024/a/Memory-Ordering/Barriers/Use-of-barriers-in-C-code
相关文章:

编译器屏障概述
文章目录 1. 前言2. 编译器内存屏障2.1 编译器内存访问重排序规则2.2 编译器屏障的几种形式2.2.1 显式编译器屏障2.2.2 隐式编译器屏障2.2.3 硬件内存屏障充当编译屏障2.2.4 编程语言内存模型提供的编译屏障 2.3 编译器内存屏障实例2.3.1 Linux spinlock 3. 结语4. 参考资料 1.…...

RUST宏编程入门
宏指示符 在Rust的宏编程中,宏可以接受多种类型的参数,称为“指示符”。这些指示符帮助宏识别不同类型的代码片段,并相应地处理它们。 这里列出全部指示符: blockexpr 用于表达式ident 用于变量名或函数名itemliteral 用于字面常…...
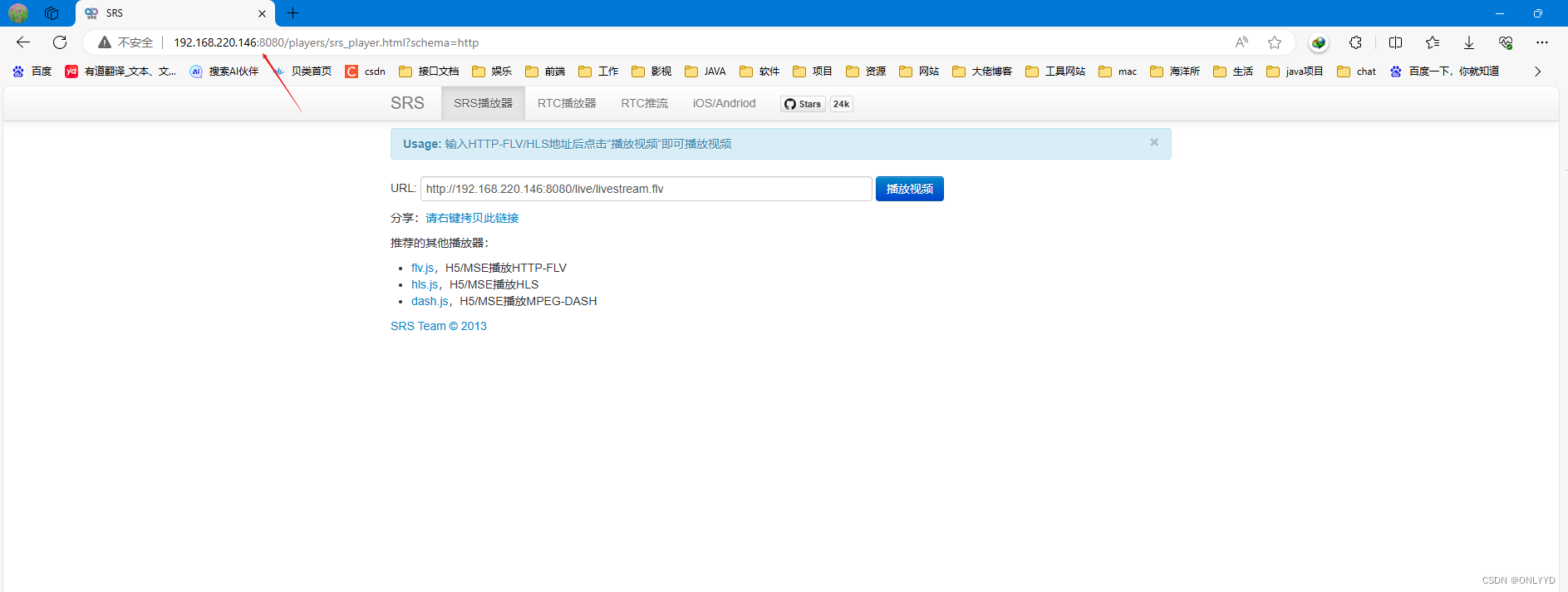
linux安装srs
获取srs cd /opt git clone -b 4.0release https://gitee.com/ossrs/srs.git cd srs/trunk 启动srs ./objs/srs -c conf/srs.conf ./etc/init.d/srs status 访问http://192.168.220.146:8080/出现下方图片说明安装成功 点击进入SRS控制台看到下方图片...
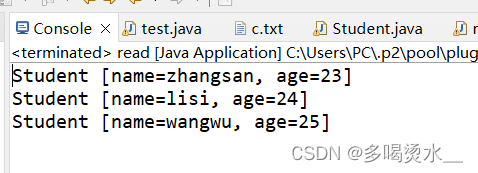
IO流(2)
缓冲流 字节缓冲流 利用字节缓冲区拷贝文件,一次读取一个字节: public class test {public static void main(String [] args) throws IOException {//利用字节缓冲区来拷贝文件BufferedInputStream bisnew BufferedInputStream(new FileInputStream(&…...

【docker】docker启动bitnami/mysql
说明:-v 宿主机目录:docker容器目录,-p 同理 注意:/opt/bitnami/mysql/conf/bitnami 目录自定义conf的目录,不能使用原有的/opt/bitnami/mysql/conf 目录。 容器启动后可在宿主机的/宿主/mysql8.0/conf,添加my_custom.…...

边缘计算、云计算、雾计算在物联网中的作用
边缘计算和雾计算不像云那样广为人知,但可以为企业和物联网公司提供很多帮助。这些网络解决了物联网云计算服务无法解决的许多问题,并使分散的数据存储适应特定的需求。让我们分别研究一下边缘计算、雾计算和云计算的优势。 雾计算的好处 低延迟。雾网络…...

【c语言】探索内存函数
探索内存函数 memcpy函数memmove函数memset函数memcmp函数: memcpy函数 memcpy函数声明: void * memcpy ( void * destination, const void * source, size_t num );将source空间下的num个字符复制到dest中去 函数的使用: 将字符数组a的5字…...

day46 完全背包理论基础 518. 零钱兑换 II 377. 组合总和 Ⅳ
完全背包理论基础 有N件物品和一个最多能背重量为W的背包。第i件物品的重量是weight[i],得到的价值是value[i] 。每件物品都有无限个(也就是可以放入背包多次),求解将哪些物品装入背包里物品价值总和最大。 01背包内嵌的循环是从…...
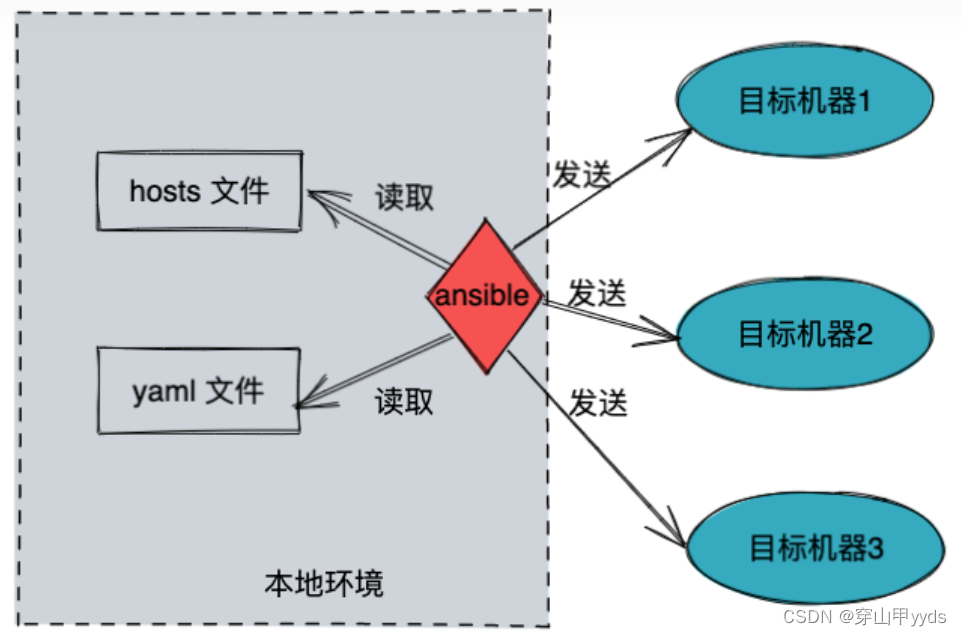
【linux】运维-基础知识-认知hahoop周边
1. HDFS HDFS(Hadoop Distributed File System)–Hadoop分布式文件存储系统 源自于Google的GFS论文,HDFS是GFS的克隆版 HDFS是Hadoop中数据存储和管理的基础 他是一个高容错的系统,能够自动解决硬件故障,eg:…...
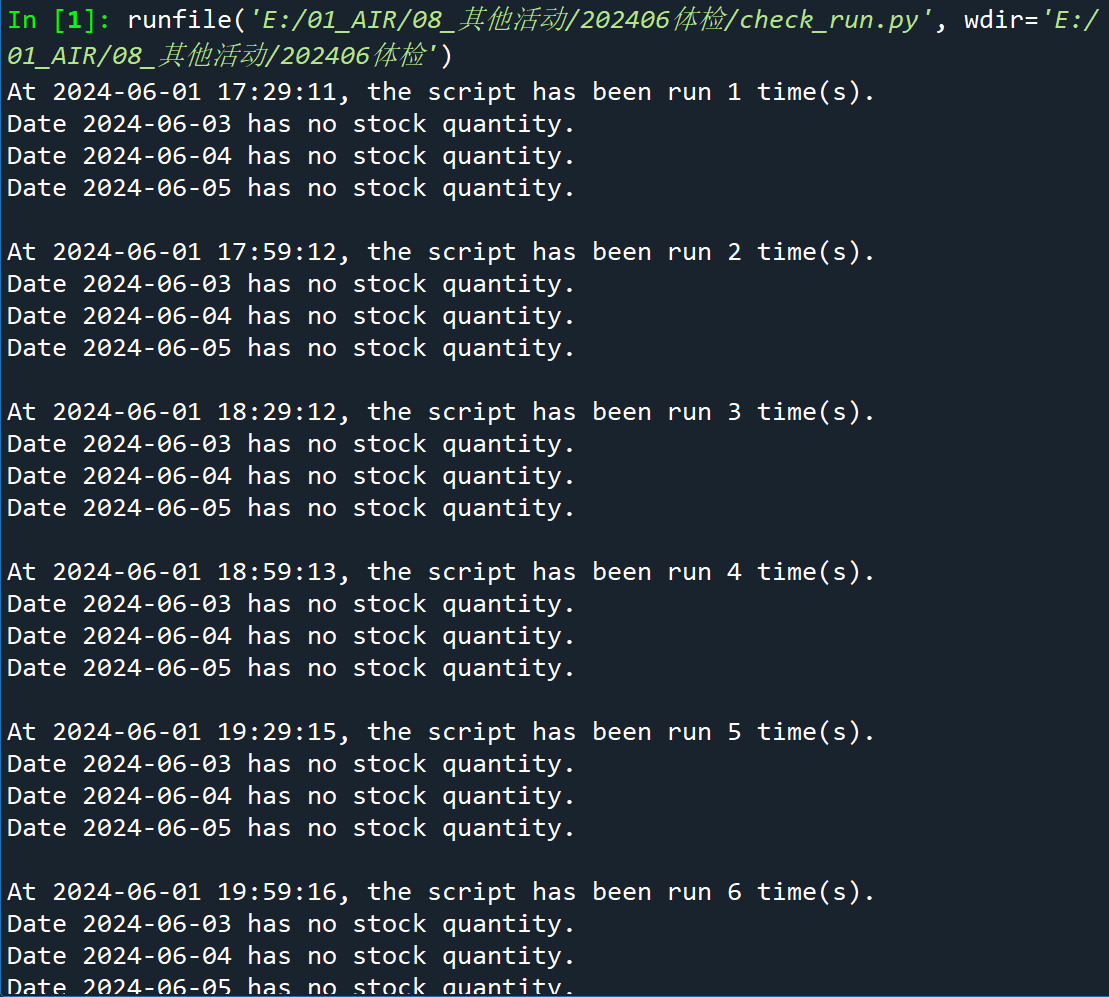
Python自动实时查询预约网站的剩余名额并在有余额时发邮件提示
本文介绍基于Python语言,自动、定时监测某体检预约网站中指定日期的体检余额,并在有体检余额时自动给自己发送邮件提醒的方法。 来到春招末期,很多单位进入了体检流程。其中,银行(尤其是四大行)喜欢“海检”…...
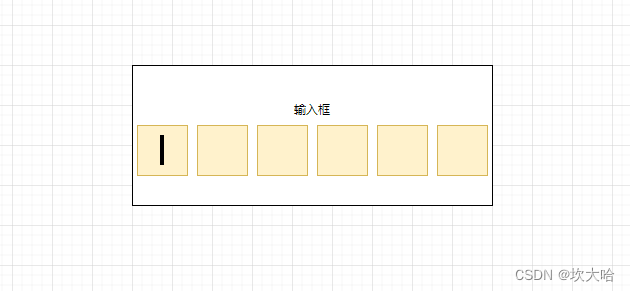
Flutter 验证码输入框
前言: 验证码输入框很常见:处理不好 bug也会比较多 想实现方法很多,这里列举一种完美方式,完美兼容 软键盘粘贴方式 效果如下: 之前使用 uniapp 的方式实现过一次 两种方式(原理相同)࿱…...

如何从0到设计一个CRM系统
什么是CRM 设计开始之前,先来了解一下什么是CRM。CRM(Customer Relationship Management)是指通过建立和维护与客户的良好关系,达到满足客户需求、提高客户满意度、增加业务收入的一种管理方法和策略。CRM涉及到跟踪和管理客户的所…...
Numba 的 CUDA 示例 (2/4):穿针引线
本教程为 Numba CUDA 示例 第 2 部分。 按照本系列从头开始使用 Python 学习 CUDA 编程 介绍 在本系列的第一部分中,我们讨论了如何使用 GPU 运行高度并行算法。高度并行任务是指任务完全相互独立的任务,例如对两个数组求和或应用任何元素函数。 在本教…...

项目的各个阶段如何编写标准的Git commit消息
标准提交消息格式 一个标准的提交消息应包括三部分:标题(summary)、正文(description)和脚注(footer)。 1. 标题(Summary) 简洁明了,不超过50个字符。使用…...
Python课设-学生信息管理系统
一、效果展示图 二、前端代码 1、HTML代码 <1>index.html <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0">…...

openssl 常用命令demo
RSA Private Key的结构(ASN.1) RSAPrivateKey :: SEQUENCE { version Version, modulus INTEGER, -- n publicExponent INTEGER, -- e privateExponent INTEGER, -- d prime1 INTEGER, -- …...

【Linux】Linux基本指令2
目录 1.man指令(重要): 2.echo指令 3.cp指令(重要): 4.mv指令 5.cat指令/echo指令重定向 6.more指令 7.less指令(重要) 8.head指令 9.tail指令 我们接着上一篇:h…...

springboot+vue+mybatis博物馆售票系统+PPT+论文+讲解+售后
如今社会上各行各业,都喜欢用自己行业的专属软件工作,互联网发展到这个时候,人们已经发现离不开了互联网。新技术的产生,往往能解决一些老技术的弊端问题。因为传统博物馆售票系统信息管理难度大,容错率低,…...
java—MyBatis框架
简介 什么是 MyBatis? MyBatis 是一款优秀的持久层框架,它支持自定义 SQL、存储过程以及高级映射。MyBatis 免除了几乎所有的 JDBC 代码以及设置参数和获取结果集的工作。MyBatis 可以通过简单的 XML 或注解来配置和映射原始类型、接口和 Java POJO&…...

如何使用Spring Cache优化后端接口?
Spring Cache是Spring框架提供的一种缓存抽象,它可以很方便地集成到应用程序中,用于提高接口的性能和响应速度。使用Spring Cache可以避免重复执行耗时的方法,并且还可以提供一个统一的缓存管理机制,简化缓存的配置和管理。 本文将详细介绍如何使用Spring Cache来优化接口,…...

HttpOnly Cookie 深度解析
一、什么是 HttpOnly Cookie HttpOnly 是一个可以附加在 Set-Cookie 响应头上的标志位(flag)。当一个 Cookie 被标记为 HttpOnly 后,客户端脚本(如 JavaScript)将无法通过 document.cookie 等 API 访问该 Cookie&…...

终极指南:在Windows上直接安装安卓APK文件的5个简单步骤
终极指南:在Windows上直接安装安卓APK文件的5个简单步骤 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 想在Windows电脑上运行安卓应用,但又厌…...

模拟IC设计避坑指南:用Cadence Virtuoso仿真,揭秘电流镜精度下降的3个元凶
模拟IC设计避坑指南:用Cadence Virtuoso仿真,揭秘电流镜精度下降的3个元凶 在模拟CMOS集成电路设计中,电流镜作为基础模块广泛应用于偏置电路、有源负载等场景。然而许多工程师在Cadence Virtuoso IC617中完成电流镜设计后,常会遇…...

AI智能体生态的包管理器:agenticmarket-cli 设计与实践
1. 项目概述:一个面向AI智能体生态的命令行工具如果你和我一样,长期在AI智能体(Agent)这个领域里折腾,那你肯定经历过这样的场景:为了测试一个最新的开源智能体框架,你需要先找到它的GitHub仓库…...

暗黑3鼠标宏终极指南:D3KeyHelper 5步配置法快速上手
暗黑3鼠标宏终极指南:D3KeyHelper 5步配置法快速上手 【免费下载链接】D3keyHelper D3KeyHelper是一个有图形界面,可自定义配置的暗黑3鼠标宏工具。 项目地址: https://gitcode.com/gh_mirrors/d3/D3keyHelper D3KeyHelper是一款专为暗黑破坏神3玩…...

如何在10分钟内搭建个人游戏流媒体服务器:Sunshine跨平台游戏串流完全指南
如何在10分钟内搭建个人游戏流媒体服务器:Sunshine跨平台游戏串流完全指南 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine 您是否梦想过在任何设备上畅玩PC游戏&#x…...

终极qmcdump指南:5分钟掌握QQ音乐加密格式解密技巧
终极qmcdump指南:5分钟掌握QQ音乐加密格式解密技巧 【免费下载链接】qmcdump 一个简单的QQ音乐解码(qmcflac/qmc0/qmc3 转 flac/mp3),仅为个人学习参考用。 项目地址: https://gitcode.com/gh_mirrors/qm/qmcdump qmcdump是…...

Navis:开源项目标准化开发环境与工具链配置框架实践
1. 项目概述:一个为开发者打造的“导航星图”如果你和我一样,常年混迹在开源项目的海洋里,那么你一定对这种感觉不陌生:面对一个全新的、功能强大的开源工具,兴奋地克隆了仓库,然后……就卡在了第一步。REA…...

用C++和RealSense D435i搞个3D手势识别?从像素坐标到相机坐标的保姆级避坑指南
3D手势识别实战:用RealSense D435i实现像素到相机坐标的高精度转换 当你的手指在空气中划出一道弧线,计算机能否精准捕捉这个三维动作?这正是3D手势识别技术试图解决的问题。作为人机交互领域的前沿方向,3D手势识别正在VR游戏、医…...

Flutter桌面端窗口控制:从隐藏标题栏到自定义全屏交互
1. 为什么需要自定义窗口控制? 当你用Flutter开发Windows桌面应用时,系统默认的标题栏和窗口样式往往显得格格不入。想象一下,你精心设计了一套深色主题的UI,结果顶部突然冒出一条灰白色的标准标题栏——就像给西装革履的绅士戴了…...