VGGNet
VGGNet
CNN卷积网络的发展史
1. LetNet5(1998)
2. AlexNet(2012)
3. ZFNet(2013)
4. VGGNet(2014)
5. GoogLeNet(2014)
6. ResNet(2015)
7. DenseNet(2017)
8. EfficientNet(2019)
9. Vision Transformers(2020)
10. 自适应卷积网络(2021)
上面列出了发展到现在CNN的一些经典的网络模型,我将持续不断更新学习上述神经网络的笔记。共勉!
原论文地址VGGNet
关键知识点
- 使用3 * 3的卷积核,增加网络深度用于提取更多特征,提高分类准确度。
- 使用尺度抖动增强训练集,提高模型准确率
- 密集评估,多裁剪评估,单尺度评估,多尺度评估,多模型融合
1. 简介

本文研究了在大型图像识别设置中,卷积网络深度对准确性的影响。我们的主要贡献是通过对具有非常小的(3×3)卷积滤波器的架构进行彻底的深度评估,深度增加到16-19个权重层,这表明通过将深度推向16-19个权重层,可以获得对先前的配置的显着改进。这些发现是我们在2014年ImageNet挑战赛中的主要贡献,我们的团队在本地化和分类轨道上分别获得了第一名和第二名。我们还展示了我们的表示在其它数据集上具有良好的泛化性,在那里它们获得了最先进的结果。我们已将我们的两个最佳表现卷积网络模型公开可用,以促进进一步研究深度视觉表示在计算机
2. ConvNet Configurations(卷积配置)
2.1 Architecture(结构)

输入的是224224的RGB图片,经过堆叠的3 * 3卷积核(为什么这个小的卷积核是33不是22或者是11呢,因为只有3*3是捕捉画面中心左右上下的最小尺寸)步长是1(也叫特征精度),对卷积层的输入进行填充为了保持卷积后的空间分辨率保持不变,padding=1,使用了5个池化层,最大池化由2 * 2像素,步长为2。3个全连接层,前两个都有4096个神经元,最后一个有1000个神经元。所有隐层都使用Relu激活函数,除了一个其他的所有网络都没有包含局部响应归一化在2.4节说明了,这种并不能显著提升性能还会导致内存消耗计算时间增加。

在上一节的ZFNet网络中我们知道,过大卷积核提取到的feature存在高频或低频这种无效信息,所以VGGNet网络中使用3*3的小卷积核,这样能够提取到更多的有效信息。
2.2 Configurations(网络配置)

表1:从A-E不停的增加网络深度(11层到16再到19层),每次经过最大池化后卷积的通道数成倍增加直到512为止。

在表2中,我们报告了每个配置的参数数量。尽管深度很大,但我们的网络中的权重数量并不大于具有更大卷积层宽度和感受野的更浅的网络中的权重数量((Sermanet et al., 2014)中的144M权重)。
2.3 Discussion(讨论)

采用3*3的卷积核:
- 3*3层卷积核可以捕捉3中不同的feature
- 可以减少参数数量
例如: 采用3层3 * 3的卷积核参数数量为 3 ( 3 2 C 2 ) = 27 C 2 3(3^2C^2)= 27C^2 3(32C2)=27C2,采用7 * 7为: 7 2 C 2 = 49 C 2 7^2C^2 = 49C^2 72C2=49C2
这里表1中配置C采用添加了一层1 * 1的卷积核是为了增加决策函数非线性而不影响函数感受野(就是Relu函数)这里重点用的是D的配置。
3. Classification Framework(分类框架)
3.1 Training(训练细节)
使用的是有动量的小批次梯度下降,batch size是256,动量是0.9,权重是 5 ∗ 1 0 − 4 5*10^{-4} 5∗10−4,dropout为0.5,学习率learning rate为 1 0 − 2 10^{-2} 10−2,训练过程中学习率一共下降了3次,经过37w次迭代74轮。
先随机初始化浅层的网络然后逐渐将网络的层数增加,增加的部分参数随机初始化其他部分继承前面网络。进行了水平翻转和颜色变换进行数据增强。
模型分为单尺度和多尺度结构(模型可以接受多个size的图像),单尺度模型训练时可以先训练小尺度然后再训练大尺度来增加训练速度。
对于选择softmax分类器还是k个logistics分类器,取决于所有类别之间是否互斥。所有类别之间明显互斥用softmax;所有类别之间不互斥有交叉的情况下最好用k个logistics分类器
训练图片预处理过程:
1.训练图片归一化,图像等轴重调(最短边为S)
等轴重调剪裁时的两种解决办法:
(1) 固定最小遍的尺寸为256
(2) 随机从[256,512]的确定范围内进行抽样,这样原始图片尺寸不一,有利于训练,这个方法叫做尺度抖动,有利于训练集增强。 训练时运用大量的裁剪图片有利于提升识别精确率。
2.随机剪裁(每SGD一次)
3.随机水平翻转
4.RGB颜色偏移
3.2 Testing(测试细节)
- 密集评估(Dense Evaluation): 在VGGNet的测试阶段,首先将网络转化为全卷积网络。第一个全连接层转为7×7的卷积层,后两个全连接层转化为1×1的卷积层。这种转换能使得网络能够接受任意尺寸的输入图像,并在整个图像上个密集的应用卷积操作。最终,网络输出一个类被分数图,其尺寸取决于输入图像的调整尺寸Q。每个类别的得分是通过对这个分数图进行空间平均得到的。
- 多裁剪评估(Multi-crop Evaluation): VGGNet还使用了多裁剪评估方法,即在测试时对输入图像进行多次不同区域的裁剪,并对每个裁剪的图像分别应用于网络。这种方法通常包括对图像的四个角落和中心区域进行裁剪,有时还包括它们的水平翻转版本。每个裁剪得到的预测结果最后被合并,以提高分类的准确性。
- 测试集增强: 我们还通过水平翻转图像来增强测试集,运用原始图片的softmax的后验概率以及其水平翻转的平均来获得图片的得分
3.3 实验
单尺度评估
在固定的训练和测试图像尺寸S=Q和变化的训练图像尺寸 S ∈ [ S m i n , S m a x ] , Q = 0.5 ( S m i n + S m a x ) S\in[S_{min},S_{max}],Q = 0.5(S_{min}+S_{max}) S∈[Smin,Smax],Q=0.5(Smin+Smax) ,在不同深度的模型A-E上的测试结果,如下所示:

从结果我们可以发现通过尺寸变化的训练集增强有助于捕获多尺度的图像统计。
多尺度评估
评估测试时尺寸变化的影响,对于固定的训练尺寸S,测试时采用 Q ∈ { S − 32 , S + 32 } Q\in \{S-32,S+32\} Q∈{S−32,S+32},对于变化的训练尺寸 S ∈ [ S m i n , S m a x ] S\in[S_{min},S_{max}] S∈[Smin,Smax],测试尺寸采用 Q = { S m i n , 0.5 ( S m i n + S m a x ) , S m a x } Q = \{S_{min},0.5(S_{min}+S_{max}),S_{max}\} Q={Smin,0.5(Smin+Smax),Smax}。在模型A-E上的测试结果如下所示:

测试时的尺寸变化能够取得更好的性能
多裁剪评估
1.上面我们放弃了测试时剪裁图像,但是我们也觉得剪裁图片有一定的效果,因为同时,如Szegedy等人(2014)所做的那样,使用大量的裁剪图像可以提高准确度。
他们成功的原因是:
1.因为与全卷积网络相比,它使输入图像的采样更精细。
2.此外,由于不同的卷积边界条件,多裁剪图像评估是密集评估的补充:当将ConvNet应用于裁剪图像时,卷积特征图用零填充,而在密集评估的情况下,相同裁剪图像的填充自然会来自于图像的相邻部分(由于卷积和空间池化),这大大增加了整个网络的感受野,因此捕获了更多的上下文。
2.虽然我们认为在实践中,多裁剪图像的计算时间增加并不足以证明准确性的潜在收益(计算消耗的时间带来了准确性的提高不足以说明它对网络来说是一种增益),但作为参考,我们还在每个尺度使用50个裁剪图像(5×5规则网格,2次翻转)评估了我们的网络,在3个尺度上总共150个裁剪图像。这种测试方法,和训练过程类似,不用将网络转化为全卷积网络,是从Q×Q大小的图中随机裁剪224×224的图作为输入,文中裁剪了50个图像,而每个图像之前缩放为三个尺寸,所以每个图像的测试图像数目变为150个,最终结果就是在150个结果中取平均。
3.再加上原来的密集评估和两者的结合(即两者结果取平均,其能大大增加网络的感受野,因此捕获更多的上下文信息,实验中也发现这种方法表现最好。)
测试结果如下:

这一结果说明了两种评估方法有一定的互补性。(利用模型的互补性提高模型的性能,这也是现在比赛中参赛者所做的
多模型融合

通过对多个不同ConvNet模型的softmax类后验概率进行平均,来组合这些模型的输出。由于不同模型之间的互补性,这种做法可以改进性能。作者将表现最佳的两个模型(D和E)进行组合,得到了top-5错误率6.8%的效果。
与最新模型进行比较

从结果可知显著优于上一代模型,并在单网络性能上取得了最优的结果。
5. Conclusion(总结)
采用多个小的卷积核但是层数增加卷积核越多可以提取到更多的特征越多,所以网络的深度对识别结果,检测结果都非常有效,可以捕获更多的信息。
Pytorch实现
实现步骤:
- 导入所需要的库
- 导入pytorch中自带的vgg19网络模型参数
- 读取图片
- 对图片进行预处理
- 将图片喂入网络中并进行可视化
- 预测结果
import numpy as np
import torch
import torchvision
from torchvision import models,transforms
from PIL import Image
import torch.nn.functional as F
import pandas as pd
import matplotlib.pyplot as plt
import requests
import cv2
import json
use_pretrained = True
net = models.vgg19(pretrained=use_pretrained)
net.eval()print(net)c:\Users\10766\software\Anaconda\envs\pytorch\lib\site-packages\torchvision\models\_utils.py:208: UserWarning: The parameter 'pretrained' is deprecated since 0.13 and may be removed in the future, please use 'weights' instead.warnings.warn(
c:\Users\10766\software\Anaconda\envs\pytorch\lib\site-packages\torchvision\models\_utils.py:223: UserWarning: Arguments other than a weight enum or `None` for 'weights' are deprecated since 0.13 and may be removed in the future. The current behavior is equivalent to passing `weights=VGG19_Weights.IMAGENET1K_V1`. You can also use `weights=VGG19_Weights.DEFAULT` to get the most up-to-date weights.warnings.warn(msg)VGG((features): Sequential((0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(1): ReLU(inplace=True)(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(3): ReLU(inplace=True)(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(6): ReLU(inplace=True)(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(8): ReLU(inplace=True)(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(11): ReLU(inplace=True)(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(13): ReLU(inplace=True)(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(15): ReLU(inplace=True)(16): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(17): ReLU(inplace=True)(18): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(19): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(20): ReLU(inplace=True)(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(22): ReLU(inplace=True)(23): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(24): ReLU(inplace=True)(25): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(26): ReLU(inplace=True)(27): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(29): ReLU(inplace=True)(30): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(31): ReLU(inplace=True)(32): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(33): ReLU(inplace=True)(34): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(35): ReLU(inplace=True)(36): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False))(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))(classifier): Sequential((0): Linear(in_features=25088, out_features=4096, bias=True)(1): ReLU(inplace=True)(2): Dropout(p=0.5, inplace=False)(3): Linear(in_features=4096, out_features=4096, bias=True)(4): ReLU(inplace=True)(5): Dropout(p=0.5, inplace=False)(6): Linear(in_features=4096, out_features=1000, bias=True))
)
img = Image.open('./pre_images/Golden_Retriever.jpg')
# 将img转换为numpy数组,并除以255,使其值范围在0到1之间
imarray = np.asarray(img) / 255.0
plt.figure()
plt.imshow(imarray)
plt.axis('off')
plt.show()
data_transform = transforms.Compose([transforms.Resize((224,224)),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])input_img = data_transform(img).unsqueeze(0)
print(input_img.shape)
torch.Size([1, 3, 224, 224])
activation = {}
def get_activation(name):def hook(model, input, output):activation[name] = output.detach()return hook
net.features[4].register_forward_hook(get_activation('maxpool1'))
_ = net(input_img)
maxpool1 = activation['maxpool1']
print(maxpool1.shape)
torch.Size([1, 64, 112, 112])
plt.figure(figsize=(11,6))
for i in range(maxpool1.shape[1]):plt.subplot(6,11,i+1)plt.imshow(maxpool1.data.numpy()[0,i,:,:],cmap='gray')plt.axis('off')plt.subplots_adjust(wspace=0.1, hspace=0.1)
plt.show()

net.eval()
net.features[21].register_forward_hook(get_activation('conv21'))
_ = net(input_img)
conv21 = activation['conv21']
print(conv21.shape)torch.Size([1, 512, 28, 28])
plt.figure(figsize=(11,8))
for i in range(88):plt.subplot(8,11,i+1)plt.imshow(conv21.data.numpy()[0,i,:,:],cmap='gray')plt.axis('off')plt.subplots_adjust(wspace=0.1, hspace=0.1)
plt.show()

ImageNet标签下载地址
jsonfile = r"./data/ImageNet-1K-main/ImageNet_class_index.json"
with open(jsonfile,'r') as load_f:load_json = json.load(load_f)labels = {int(key):value for (key,value) in load_json.items()}
net.eval()
img_pre = net(input_img)
softmax = torch.nn.Softmax(dim=1)
im_pre_prob = softmax(img_pre)
prob,prelab = torch.topk(im_pre_prob,5)
prob = prob.data.numpy().flatten()
prelab = prelab.numpy().flatten()
for i,lab in enumerate(prelab):print("index: {}, label: {}, probability: {}".format(lab,labels[lab][1],prob[i]))
index: 207, label: golden_retriever, probability: 0.873153567314148
index: 852, label: tennis_ball, probability: 0.02229723334312439
index: 208, label: Labrador_retriever, probability: 0.016353365033864975
index: 220, label: Sussex_spaniel, probability: 0.009220004081726074
index: 168, label: redbone, probability: 0.006000933237373829
通过结果可知预测的结果为golden_retriever,预测结果很正确。
接下里我们再预测一张图片,看看结果是否正确
img_1 = Image.open('./pre_images/1.jpg')
imarray = np.asarray(img_1) / 255.0
plt.figure()
plt.imshow(imarray)
plt.axis('off')
plt.show()

data_transform = transforms.Compose([transforms.Resize((224,224)),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])input_img_1 = data_transform(img_1).unsqueeze(0)
print(input_img_1.shape)
torch.Size([1, 3, 224, 224])
net.eval()
net.features[21].register_forward_hook(get_activation('conv21'))
_ = net(input_img_1)
conv21 = activation['conv21']
print(conv21.shape)
torch.Size([1, 512, 28, 28])
plt.figure(figsize=(11,8))
for i in range(88):plt.subplot(8,11,i+1)plt.imshow(conv21.data.numpy()[0,i,:,:],cmap='gray')plt.axis('off')plt.subplots_adjust(wspace=0.1, hspace=0.1)
plt.show()

img_pre_1 = net(input_img_1) # 预测输入图片的类别
softmax = torch.nn.Softmax(dim=1) # 定义softmax函数
im_pre_prob_1 = softmax(img_pre_1) # 对预测结果进行softmax激活
prob_1,prelab_1 = torch.topk(im_pre_prob_1,5) # 获取概率最大的5个类别及其概率
prob_1 = prob_1.data.numpy().flatten() # 将概率值转换为numpy数组并展平
prelab_1 = prelab_1.numpy().flatten() # 将类别索引转换为numpy数组并展平
for i,lab in enumerate(prelab_1): # 遍历每个预测类别及其索引print("index: {}, label: {}, probability: {}".format(lab,labels[lab][1],prob_1[i])) # 打印每个预测类别的索引、名称和概率
index: 23, label: vulture, probability: 0.8022373914718628
index: 84, label: peacock, probability: 0.15436647832393646
index: 9, label: ostrich, probability: 0.02591262198984623
index: 88, label: macaw, probability: 0.003736903192475438
index: 17, label: jay, probability: 0.002771784085780382
从结果可以可以看到预测为vulture(秃鹫),预测正确
恭喜!
It’s not the alarm clock that wakes me up every morning,but my great idea.
每天早上叫醒我的不是闹钟而是我伟大的理想!
相关文章:
VGGNet
VGGNet CNN卷积网络的发展史 1. LetNet5(1998) 2. AlexNet(2012) 3. ZFNet(2013) 4. VGGNet(2014) 5. GoogLeNet(2014) 6. ResNet(2015) 7. DenseNet(2017) 8. EfficientNet(2019) 9. Vision Transformers(2020) 10. 自适应卷积网络(2021) 上面列出了发展到现在CNN的一些经典…...
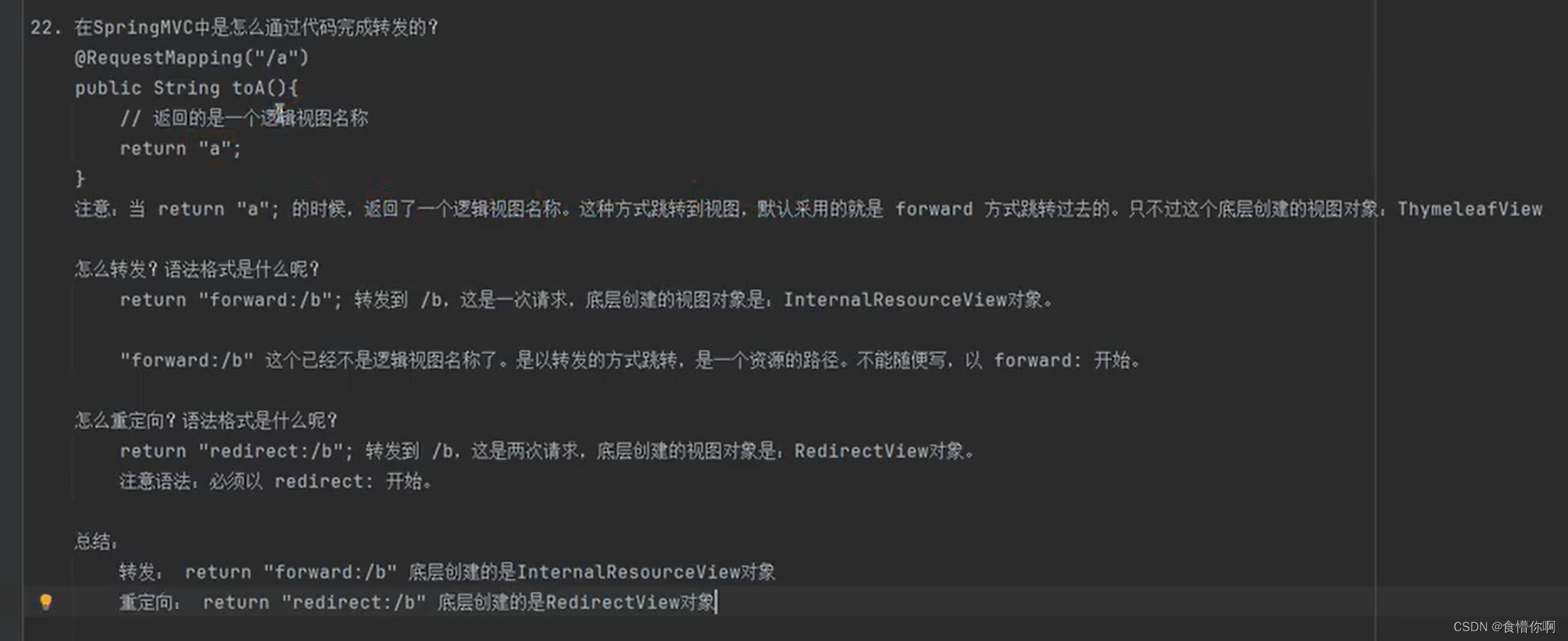
SpringMVC:转发和重定向
1. 请求转发和重定向简介 参考该链接第9点 2. forward 返回下一个资源路径,请求转发固定格式:return "forward:资源路径"如 return "forward:/b" 此时为一次请求返回逻辑视图名称 返回逻辑视图不指定方式时都会默认使用请求转发in…...
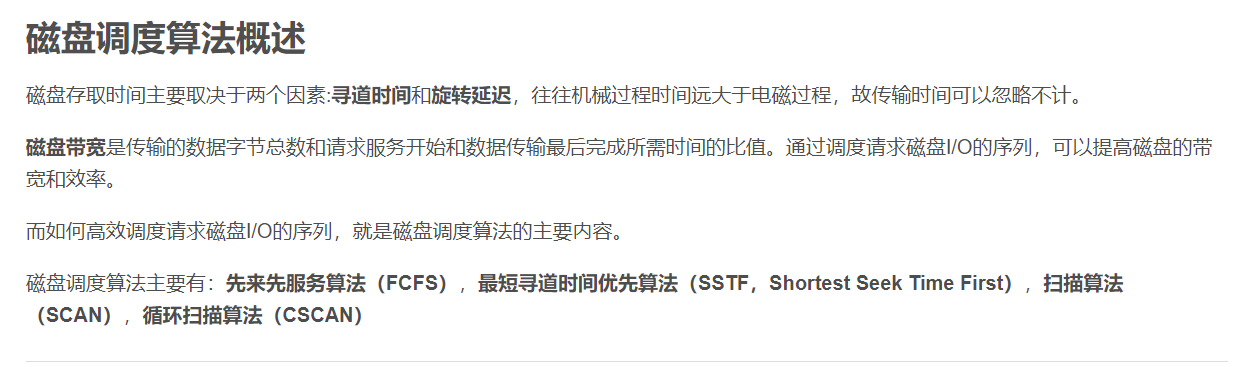
961操作系统知识总结
部分图片可能无法显示,参考这里:https://zhuanlan.zhihu.com/p/701247894 961操作系统知识总结 一 操作系统概述 1. 操作系统的基本概念 重要操作系统类型:批处理操作系统(批量处理作业,单道批处理/多道批处理系统,用…...
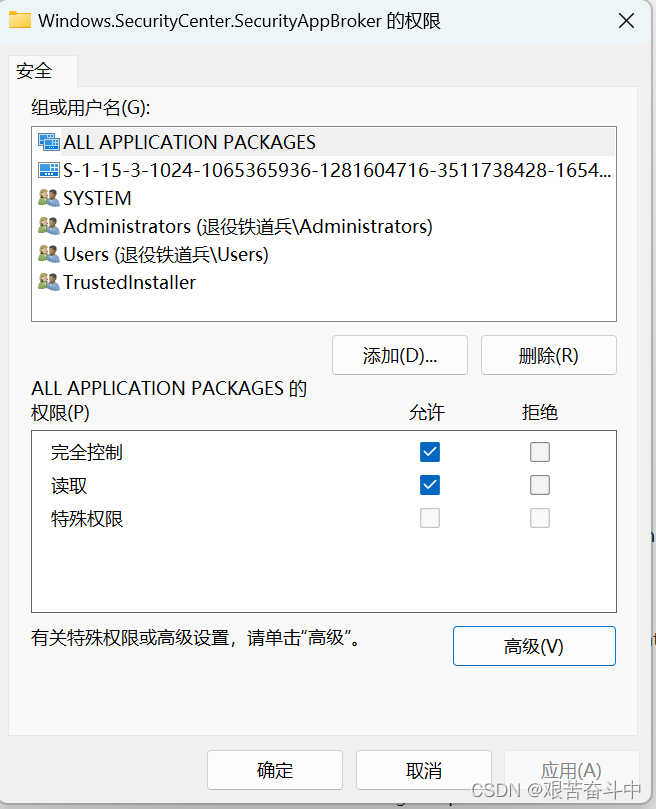
电脑死机问题排查
情况描述:2024年6月2日下午16:04分电脑突然花屏死机,此情况之前遇到过三次,认为是腾讯会议录屏和系统自带录屏软件冲突导致。 报错信息:应用程序-特定 权限设置并未向在应用程序容器 不可用 SID (不可用)中运行的地址…...
百度地图1
地图的基本操作 百度地图3.0文档 百度地图3.0实例中心 设置地图 centerAndZoom(center: Point, zoom: Number)设初始化地图,center类型为Point时,zoom必须赋值,范围3-19级, // 百度地图API功能var map new BMap.Map("map"); //…...
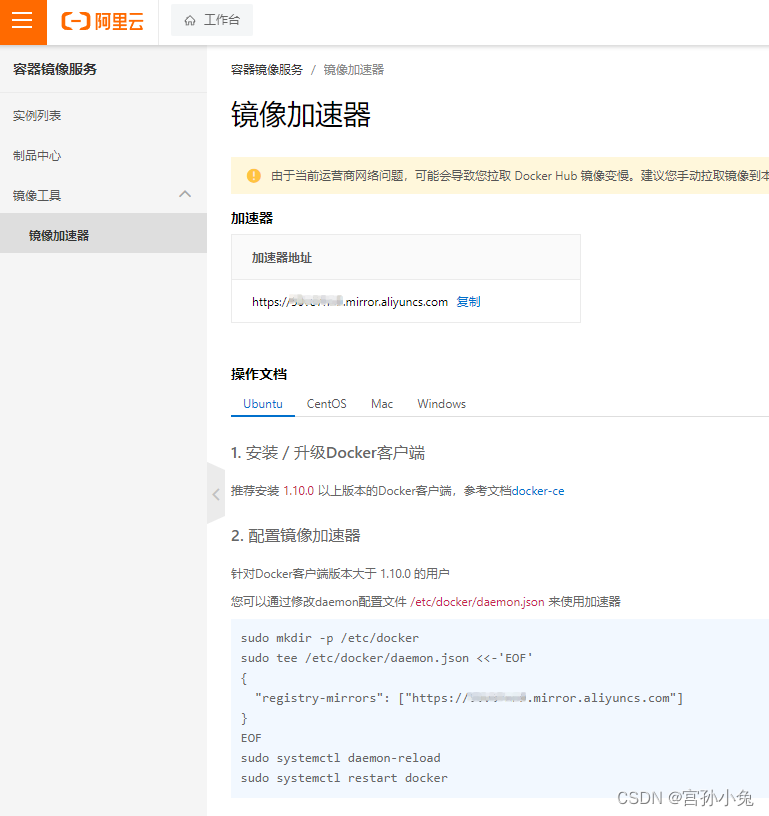
Ubuntu 24.04 LTS 安装Docker
1 更新软件包索引: sudo apt-get update 2 安装必要的软件包,以允许apt通过HTTPS使用仓库: sudo apt-get install apt-transport-https ca-certificates curl software-properties-common 3 添加Docker的官方GPG密钥: curl -fs…...

【架构设计】Java如何利用AOP实现幂等操作,防止客户端重复操作
1实现方案详解 在Java中,使用AOP(面向切面编程)来实现幂等操作是一个常见的做法,特别是当你想在不修改业务代码的情况下添加一些横切关注点(如日志、事务管理、安全性等)时。幂等操作指的是无论执行多少次,结果都是相同的操作。 为了利用AOP实现幂等操作以防止客户端重…...
笔记:美团的测试
0.先启动appium 1.编写代码 如下: from appium import webdriver from appium.webdriver.extensions.android.nativekey import AndroidKeydesired_caps {platformName: Android,platformVersion: 10,deviceName: :VOG_AL10,appPackage: com.sankuai.meituan,ap…...

【30天精通Prometheus:一站式监控实战指南】第15天:ipmi_exporter从入门到实战:安装、配置详解与生产环境搭建指南,超详细
亲爱的读者们👋 欢迎加入【30天精通Prometheus】专栏!📚 在这里,我们将探索Prometheus的强大功能,并将其应用于实际监控中。这个专栏都将为你提供宝贵的实战经验。🚀 Prometheus是云原生和DevOps的…...

STM32F103借助ESP8266连接网络
ESP8266配置 STM32F103本身是不具备联网功能的,所以我们必须借助其他单片机来进行联网,然后让STM32与联网单片机通信,就可以实现STM32联网了。 本文借助的是ESP8266模块,其通过UART协议与STM32通信(http://t.csdnimg.c…...
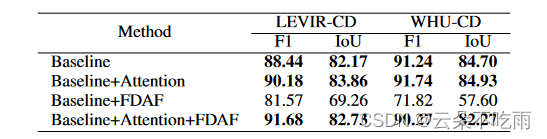
Feature Manipulation for DDPM based Change Detection
基于去噪扩散模型的特征操作变化检测 文章提出了一种基于去噪扩散概率模型(DDPM)的特征操作变化检测方法。变化检测是计算机视觉中的经典任务,涉及分析不同时间捕获的图像对,以识别场景中的重要变化。现有基于扩散模型的方法主要…...

第十三届蓝桥杯国赛大学B组填空题(c++)
A.2022 动态规划 AC; #include<iostream> #define int long long using namespace std; int dp[2050][15]; //dp[i][j]:把数字i分解为j个不同的数的方法数 signed main(){dp[0][0]1;for(int i1;i<2022;i){for(int j1;j<10;j){//一种是已经分成j个数,这时只需每一个…...

conda源不能用了的问题
conda旧没用了,不知道什么原因,安装源出问题,报如下错: Loading channels: failedUnavailableInvalidChannel: HTTP 404 NOT FOUND for channel anaconda/pkgs/main <https://mirrors.aliyun.com/anaconda/pkgs/main>The c…...

【C#】自定义List排序规则的两种方式
目录 1.系统排序原理 2.方式一:调用接口并重写 3.方式二:传排序规则函数做参数 1.系统排序原理 当我们对一个List<int>类型的数组如list1排序时,一个轻松的list1.sort();帮我们解决了问题 但是在实际应用过程中,往往我们…...
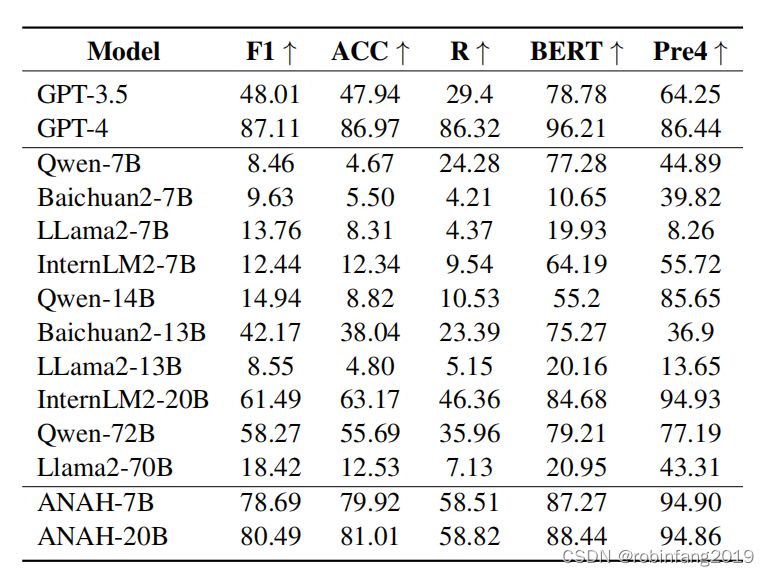
ANAH数据集- 大模型幻觉细粒度评估工具
大型语言模型(LLMs)在各种自然语言处理任务中取得了显著的性能提升。然而,它们在回答用户问题时仍面临一个令人担忧的问题,即幻觉,它们会产生听起来合理但不符合事实或无意义的信息,尤其是当问题需要大量知…...

AI前沿技术探索:智能化浪潮下的创新与应用
一、引言 随着科技的不断进步,人工智能(AI)已成为推动社会发展的重要力量。从自动驾驶汽车到智能医疗诊断,从智能家居到虚拟助手,AI技术正逐渐渗透到我们生活的方方面面。本文旨在探讨AI的前沿技术、创新应用以及未来…...
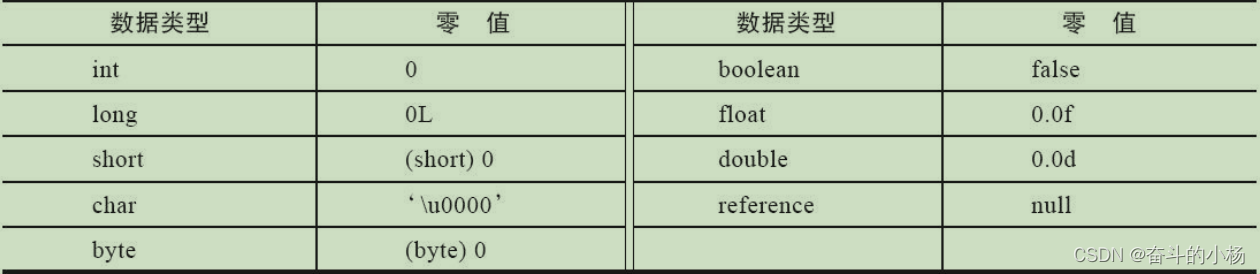
JVM类加载过程
在Java虚拟机规范中,把描述类的数据从class文件加载到内存,并对数据进行校验、转换解析和初始化,最终形成可以被虚拟机直接使用的java.lang.Class对象,这个过程被称作类加载过程。一个类在整个虚拟机周期内会经历如下图的阶段&…...

如何安装ansible
ansible安装 1、 准备环境----关闭防护墙和selinux 一般用ansible不会少于10台以上 环境: 主机:4台 一个控制节点 3个被控制节点 解析:本地互相解析(所有机器) # vim /etc/hosts 192.168.1.10 ansible-web1 192.168.1.11 ansible-web2 192.168.1.12…...

html+CSS+js部分基础运用11
一、改变新闻网页中的字号 1、设计如图1-1所示的界面,要求当网络访问者选择字号中的【大、中、小】时能实现页面字号大小变化,选择“中”时,页面效果如图1所示。 图1 单击前初始状态页面 图2 单击“中”链接后页面 2、div中内容如下&#x…...

6,串口编程———通过串口助手发送数据,控制led亮灭
//功能:串口助手每次发送数据格式:0000& // 第二个字节控制LED1亮灭 // 第三个字节控制LED2亮灭 // 第四个字节控制LED3亮灭 // 第无个字节控制LED4亮灭 //要求:代码能够一直运行,能够接收多字节数据 上节讲了串口的基本…...
)
别再怪硬件了!DELL服务器风扇噪音的元凶与精准静音指南(iDRAC+IPMI实战)
别再怪硬件了!DELL服务器风扇噪音的元凶与精准静音指南(iDRACIPMI实战) 服务器风扇突然狂转,噪音飙升?先别急着给硬件判死刑。这背后往往是一场系统散热策略与硬件兼容性的无声对话。作为管理员,我们需要透…...

Go语言整洁架构:分层设计
Go语言整洁架构:分层设计 1. 分层结构 internal/domain/ # 领域实体usecase/ # 用例adapter/ # 适配器handler/ # HTTP处理2. 总结 整洁架构强调业务逻辑的独立性和依赖方向的正确性。...

论文AI率90%熬夜怎么办?2026年5招实测,一次过知网维普AIGC
2025 年 12 月 25 日知网 AIGC 检测系统升级,2026 年 4 月 27 日维普 AI 率检测平台升级…2026 毕业季,各大主流 AIGC 检测软件陆续升级系统,识别 AI 痕迹更加精准。 临近毕业,同学们看者飘红的 AIGC 检测报告、纷繁复杂的降 AI 系…...

把SAC model的数据导出到BW的ADSO中
目录 1. SAC 侧的准备 1.1 OData连接要做好 1.2 SAC里的model设置要配置好允许导出到Odata 2. BW侧要做的准备(先跟着SAP的note走) 3. SAC 模型数据导出 一般都是把planning model的数据导出到一个ADSO中,然后再用Composite Provider里…...

Word文档保护技巧:防止内容被轻易复制
Word文档如何防止复制呢?其实,Word根本没有真正意义上的禁止复制,因为用户按一下手机截图,或者拍张照片,内容照样能拿走。但是,我们可以提高复制门槛,也就是让其他用户通过“CtrlC”无法直接复制…...
)
LeetCode--112. 路径总和(二叉树)
题目描述 给你二叉树的根节点 root 和一个表示目标和的整数 targetSum 。判断该树中是否存在 根节点到叶子节点 的路径,这条路径上所有节点值相加等于目标和 targetSum 。如果存在,返回 true ;否则,返回 false 。 叶子节点 是指没…...

GanttProject免费开源项目管理工具:简单高效的甘特图软件完全指南
GanttProject免费开源项目管理工具:简单高效的甘特图软件完全指南 【免费下载链接】ganttproject Official GanttProject repository. 项目地址: https://gitcode.com/gh_mirrors/ga/ganttproject GanttProject是一款功能强大的免费开源项目管理工具…...

Godot 4.3 RTS开发实战:事件驱动架构与指令队列优化
1. 这不是又一个“Hello World”教程:RTS游戏在Godot里到底难在哪?你点开过十几个“Godot RTS教程”,结果发现前两分钟还在画UI按钮,第三分钟就跳到“接下来我们用NavigationServer实现寻路”——然后卡住。你翻遍官方文档&#x…...

特朗普移动数据泄露:客户信息险曝光,T1 手机真实订单远低于网传
特朗普移动数据泄露:客户信息岌岌可危就在 T1 手机似乎即将发布之时,特朗普移动(Trump Mobile)被指控不安全地存储客户数据,使得客户的地址和电话号码面临泄露风险。YouTuber Coffeezilla 最先在他的第二个频道 voidzi…...

注塑行业的数智化突围:告别“黑盒”生产,拥抱透明化管理新纪元
在从“经验驱动”向“数据驱动”的关键跃迁中,注塑成型作为典型的离散制造环节,其数字化转型的痛点尤为尖锐。盘古信息基于近二十年的行业深耕,依托其自主研发的IMS工软底座,为注塑行业带来了一套完整的数智化破局方案,…...