软件设计不是CRUD(21):在流式数据处理系统中进行业务抽象落地——需求分析
本文主要介绍如何在数据处理系统中应用业务抽象的设计思想。目前业界流行的数据处理方式是流式处理,主流的流式处理引擎有Apache Spark,Apache Flink等等。本文选择Apache Flink作为实战案例的落地。由于本文主要是讲解设计思想和流式处理引擎相结合的方法,所以本文不会讲解如何使用Apache Flink,也不会讲解Apache Flink的脚本语法。本文会假定读者已经对Apache Flink有了一个大致了解,并能在Flink上独立完成一些数据处理脚本的开发工作。至少读者应该知道类似如下这样的Apache Flink数据流处理视图可能涉及的流处理函数大致有哪些:

(以上Flink控制台脚本工作效果图,均来源于网络)
当然为了方便读者理解落地细节,本文在详细设计阶段也会随着内容解释一些必要的Flink开发知识,但这种讲解并不是系统化的,而只是出于方便读者理解设计细节的目的。
1、需求描述
某高速路的智能检测系统(后文简称为系统)需要进行各种IoT设备检测信息的收集、清洗、早期处理,以及落库操作。这些落库的数据将作为后续正式数据分析的数据基础。由于这些IoT设备属于不同的应用厂商、使用不同的数据传输协议、设备设计定型时技术背景也不一样,所以不可能有一种统一的数据接入方式,如下图所示:
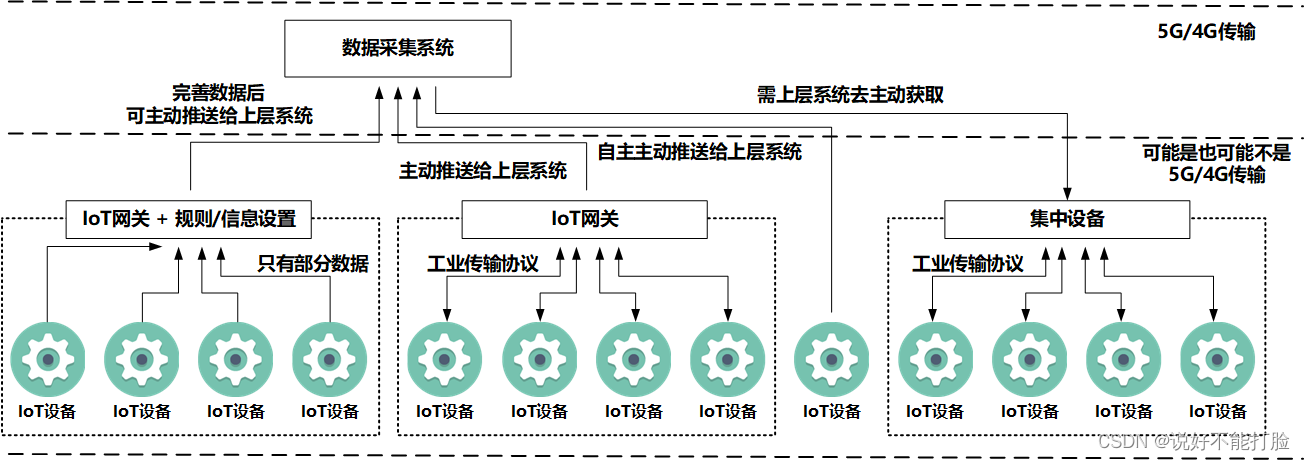
上图所示的数据采集系统仅是智能检测系统的一个子系统,该系统就是进行数据采集、清晰、初步处理的主力系统。仅仅是上图就至少提到了四种数据收集方式,这些明确提出的需要数据采集系统支持的数据收集方式,详细场景描述如下:
-
第一种情况,IoT设备本身内置了5G/4G模块,通过移动网络通讯,将简单的监测数据传输给远端的网关模块,这个网关模块负责了这条高速公路大约100公里内50-100个这样的IoT设备的信息收集工作,并内置了一套规则程序,可将这些简单的监测数据进行完善后,主动推送给上层网络中的消息队列组件(或上层系统)。这种类型数据收集,适用于内置了5G/4G模块,且主要用于收集数据的IoT设备,例如温度传感器、车流量传感器等。
-
第二种情况,IoT设备出于成本考虑,并没有内置5G/4G模块,其利用诸如Moubus这样的通讯协议,接入到近端集中设备上。近端集中设备不止可以接受IoT设备传输的信息,还能对IoT设备进行操作(诸如停止IoT设备、开启IoT设备、重启IoT设备、旋转IoT设备等)。由于是近端设备,所以它可以集中管理的IoT设备仅限于其周围有限距离、有限数量的IoT设备(诸如周围100米范围的10个设备)。近端集中设备一般具有4G/5G模块,可以将这些IoT设备的信息主动推送给上层网络中的消息队列组件(或上层系统),也可以接受上层网络发送过来的控制信息,并做出相关控制操作。这种类型的数据收集,适用于为了降低成本而集中部署的场景,例如车速传感器、智能路灯、电子限速牌等。
-
第三种情况,IoT设备本身的技术参数较高,设备自带5G/4G模块,不需要远端网关便可自主传输较完善的监控数据到上层网络中的消息队列中(或上层系统)。这种类型的数据收集常见于技术参数较高的高清网络摄像头。
-
第四种情况,IoT设备和集中设备技术参数较陈旧,在设计时并没有考虑主动接入物联网的情况。集中设备具有数据收集和IoT设备控制的基本功能,但如果想要取得收集的数据,需要上层组件(或上层系统)主动对集中设备发起请求才能获得(也就是说数据获取并不是普遍采用的“推“模式,而是不常采用的”拉“模式)。
另外,由于这些设备来源于不同的集成设备商,技术参数规格也不一样,所以不能保证所有IoT设备、IoT网关设备向上层网络传输的数据一定具有某种特定的格式、某种特定的字段,甚至不能保证传输的信息都是JSON格式的数据描述(当然最后一种情况实际工作中已经比较少见)。数据收集系统需要自己想办法来解决数据适配的问题。最后,在项目之初确认的IoT设备、IoT网关设备在项目运营过程中可能涉及替换、新增或者升级的情况,这些情况将导致适配的传输数据发送变化的。
2、设计思考
在正式讨论设计前,我们需要进行一些讨论以便确定设计方向,确定在这种流式数据采集系统中应用业务抽象设计思想的原因和目标。
2.1、为什么采用流式处理进行系统设计
截止本文发布时,业界对数据处理的解决方案主要分为两种,一种是批处理式的解决方案,一种是流处理式的解决方案。要选择哪种数据处理方式,我们首先需要比较一下这两种数据处理方案适用的场景,以及优缺点:
| 批处理 | 流处理 | |
|---|---|---|
| 数据处理时机 | 周期性的、具有延迟的处理时机。例如在以1个小时为周期,在这一个小时之内收集的数据先临时存储起来,到了一个小时以后,再对这批数据进行处理。 | 非周期性、实时进行。也就是说收集到一条数据或者说一条数据达到数据处理系统后,就立即进行数据的处理。 |
| 数据处理方式 | 正如批处理这个词一样,数据的处理针对这个周期所收集到的一批数据进行。处理完成后,系统工作结束或者进入下一个等待数据收集的新周期。 | 系统不会停止处理,数据就像流经系统的一条河流,永不停止。系统对数据的处理规模就是这条河流的容量。 |
| 适用场景 | 批处理适合在系统资源相对有限的情况下,在系统用户对数据分析结果实时性要求不高的情况下,或者数据本来就是周期性提供的情况下使用。这种情况主要出现在偏业务执行的场景,例如月台账结转、月度结算、月度操作日志汇总等 | 流处理适用在对数据统计、数据分析实时性较高的场景,当然相对于批处理来说流处理需要计算资源相对多一些。这些场景一般偏向于数据应用的场景,这些场景下数据都会连续生成。例如日志收集、内容推荐、实时舆情等。 |
| 方案缺点 | 数据结果有延迟,这种延迟是使用者肉眼可见的。例如秒级、小时级、星期级。一般来说批处理方案是无法适应流处理匹配的需求场景的。 | 流处理需要的计算资源相对较多,流处理需要设计的系统相对较复杂。 |
| 方案优点 | 所需的计算资源较少,功能的设计和运维相对较简单。 | 数据结果是实时的或者近实时的,也就是说这种延迟是使用者不可感知的,或者能感知但仍可接受延迟的。从另一个层面上说,流处理在相当程度下,是可以匹配批处理适应的需求场景的。 |
那么具体到本系统的需求上,首先高速道路的数据收集和分析其中一个目标是为了发现高速道路上的紧急情况,例如火灾、泥石流、重大交通事故等。基于这样的理由,这部分数据对实时性的要求是比较高的。另外,这些监控数据的传输是持续不断的,数据传输本身不存在周期的概念。所以,从本需求描述的数据收集场景来说,更匹配的是采用流式处理的技术方案。
2.2、对二次开发性的思考
需求中已经提到,在系统的设计初期客户实际上已经开始了一些设备供应商的洽谈工作,而有的设备供应商甚至采用的单一采购源的方式进行采购。另外,客户也明确提出在系统正式运维后,还会陆续接入一些新的设备,开启一些新的数据分析功能;除了接入新的设备外,已有的设备还需要支持升级操作以及下线操作。很明显,这套系统是需要具有较强的二次开发性的,主要体现在:
-
新设备的接入可能会出现系统对新收集的数据格式分析方式的扩展,这种扩展应该可以由客户自己的运维团队完成,并且这种扩展不应该对其它设备的数据采集、处理过程产生影响。
-
已有设备的升级操作也可能导致已有的检测数据格式发生变化,这种变化可以通过运维团队自行修改对应的数据分析逻辑来进行适配,而不应该对其它数据的采集、处理过程产生影响。
2.3、数据流设计的思考
设想一下,为了保证上一小节提到的二次开发性要求,设计人员可以为每一种数据格式(每一种IoT设备/设备网关)设计一个独立的数据处理流(Flink中的Job),但这种设计有几个问题:
-
由于IoT设备/设备网关是比较多的(少则20、30种,多则接近百种也是可能的),如果为每一个IoT设备/设备网关都设计独立的数据处理流,那么这些处理流很难进行有效管理。就算运维团队有能力进行有效管理,系统所需资源和运维成本也不好控制。
-
由于需要为每一个IoT设备/设备网关独立开发数据处理流,所以这些数据处理流本身的执行脚本,开发成本也是比较高的。另外,技术管理者会发现为了管理、维护这些处理脚本,还需要大量的辅助脚本,例如Jenkins中的部署设置,DevOps各种中间件中的自动化脚本。
-
那么我们应该如何考虑数据处理流(Flink中的Job)的个数呢?我们可以把数据处理流看做是数据处理功能中的控制逻辑,只要某些IoT设备/设备网关的数据处理过程控制逻辑是一致的,那么它们的处理过程就可以交给一个数据处理流。我们来看以下两种不同的控制逻辑:
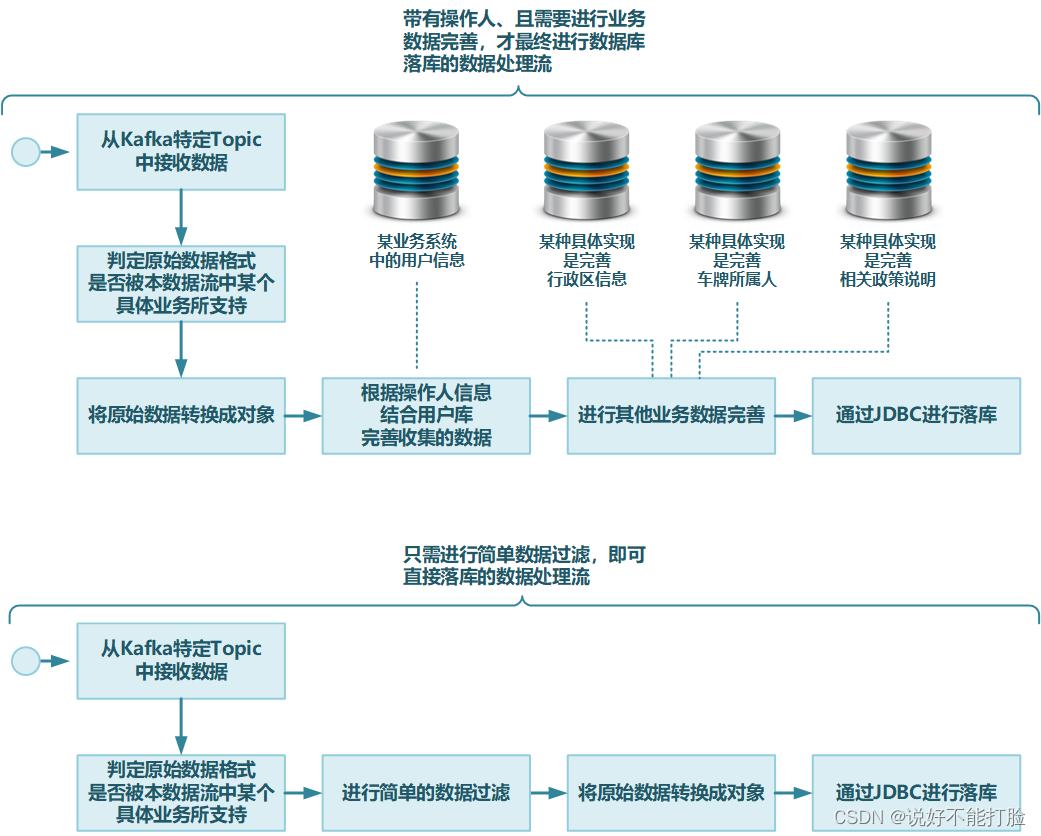
那么以上两种不同的控制逻辑,可以在Flink中形成两个不同的数据处理流(Flink中的Job)。而匹配同一种控制逻辑的不同IoT设备/设备网关,实际上只是具体控制点上的业务逻辑不一样而已。所以完全可以定义抽象行为,然后各自进行具体业务逻辑的实现。这样一来,设计人员就可以将大量的IoT设备/设备网关,归纳成有限的几种控制逻辑一样的数据处理流,即保证各个具体业务都能进行匹配,又保证了对这些数据处理流的有效管理。
下一篇文章,我们将基于这样的需求分析来进行数据采集系统的设计落地工作。
相关文章:
软件设计不是CRUD(21):在流式数据处理系统中进行业务抽象落地——需求分析
本文主要介绍如何在数据处理系统中应用业务抽象的设计思想。目前业界流行的数据处理方式是流式处理,主流的流式处理引擎有Apache Spark,Apache Flink等等。本文选择Apache Flink作为实战案例的落地。由于本文主要是讲解设计思想和流式处理引擎相结合的方…...

远控免杀篇
0x00:前言 随着近两年hvv和红蓝对抗以及国家对于网络安全的重视,国内防护水平都蹭蹭上了一个台阶,不管是内部人员的技术水平提高还是防护设备的层层部署,均给了红队人员想要进一步行动设置了障碍。 通过weblogic的cve-2019-2725获…...
基于单片机的超声波倒车雷达设计
摘 要:文 章设计了一种基于单片机的超声波倒车雷达系统,以 AT89C51 型单片机作为控制核心,集距离测量、显示,方位显示和危险报警于一体,以提高驾驶者在倒车泊车时的安全性和舒适性。本设计采用 Keil 软件对系统程序…...

如何增加服务器的高并发
哈喽呀大家好呀,淼淼又来和大家见面啦,随着互联网应用的普及和用户量的不断增加,服务器的高并发性能成为了开发者们面临的一项重要挑战。在处理大量并发请求时,服务器需要具备高效的处理能力和稳定的性能,以确保系统的…...

webservice、WCF、webAPI权限认证
webservice 权限认证 》》soapHeader SOAPHeader案例 》》 window 集成认证 在IIS里取消匿名访问权限,若允许匿名访问,就没有必须提供验证凭证了 R2RServiceSerialNumber sN new R2RServiceSerialNumber();sN.Url "http://172.xxxxx/R2RServi…...
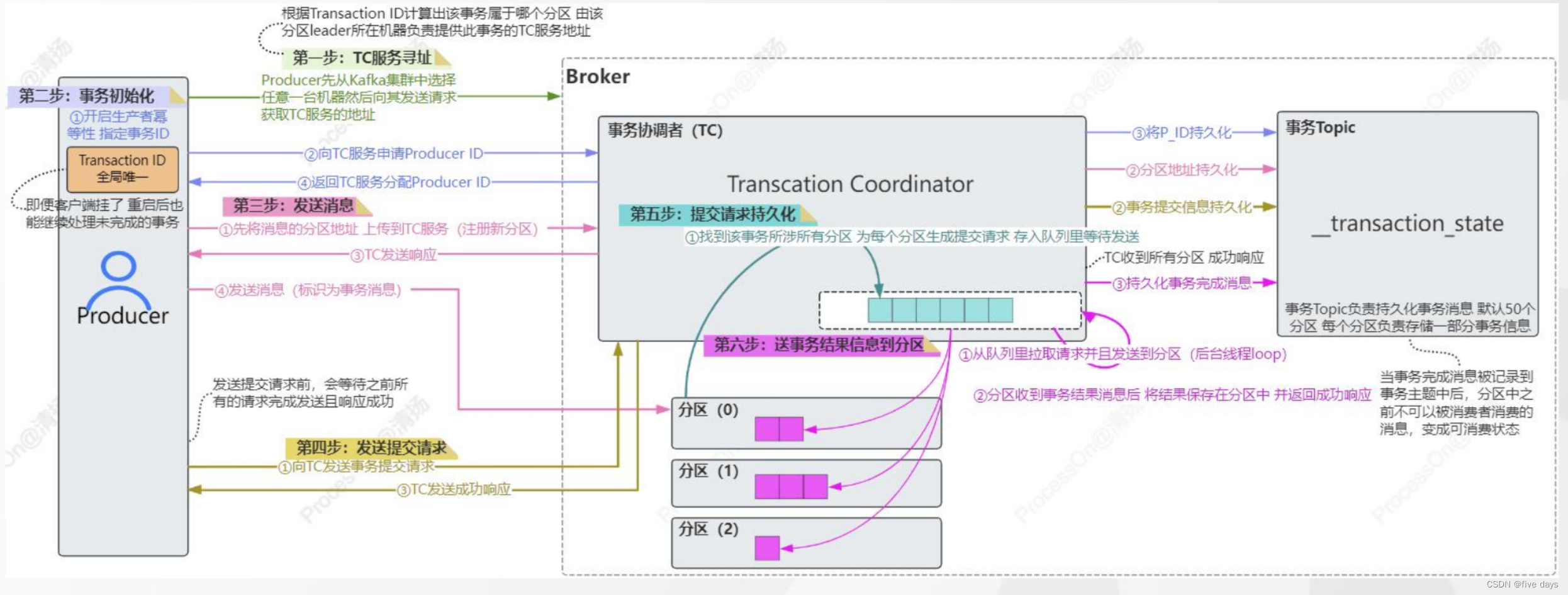
Kafka之Producer原理
1. 生产者发送消息源码分析 public class SimpleProducer {public static void main(String[] args) {Properties prosnew Properties();pros.put("bootstrap.servers","192.168.8.144:9092,192.168.8.145:9092,192.168.8.146:9092"); // pros.pu…...

ubuntu20.04部署gitlab流程
参考: https://blog.csdn.net/weixin_57025326/article/details/136048507 362 wget --content-disposition https://packages.gitlab.com/gitlab/gitlab-ce/packages/ubuntu/focal/gitlab-ce_16.2.1-ce.0_amd64.deb/download.deb367 sudo apt install gitlab-ce…...

C/C++动态内存管理(new与delete)
目录 1. 一图搞懂C/C的内存分布 2. 存在动态内存分配的原因 3. C语言中的动态内存管理方式 4. C内存管理方式 4.1 new/delete操作内置类型 4.2 new/delete操作自定义类型 1. 一图搞懂C/C的内存分布 说明: 1. 栈区(stack):在…...

搭建一个基于主流技术Spring Boot 2 + Vue 3 + Ant Design Vue的技术框架的简要步骤
搭建一个基于主流技术Spring Boot 2 Vue 3 Ant Design Vue的技术框架涉及前后端分离的开发模式。以下是一个简化的步骤指南,用于帮助你开始这个项目: 1. 后端(Spring Boot 2) 1.1 初始化项目 使用Spring Initializr(…...
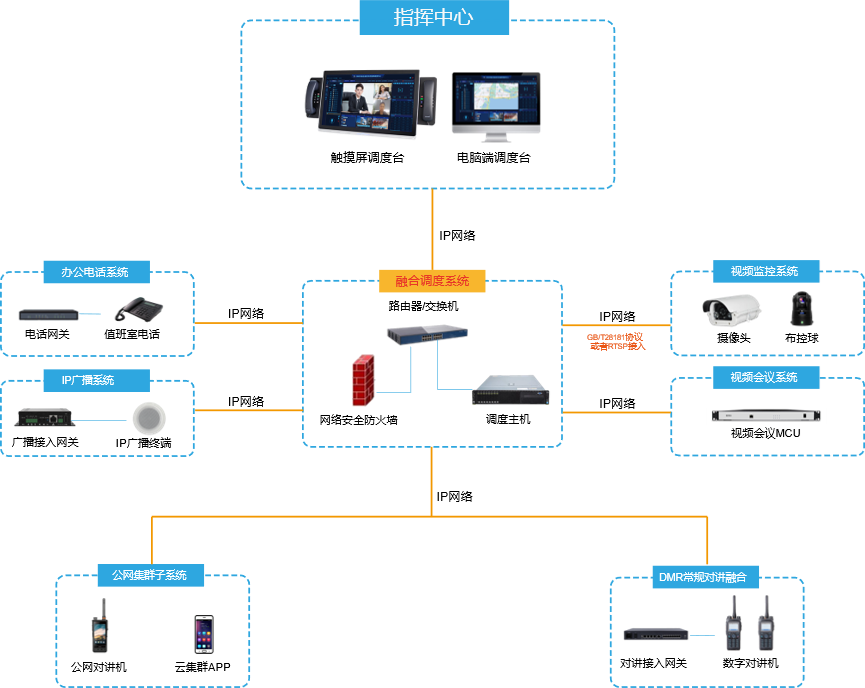
水电站生产指挥调度系统方案
一、方案背景 在碧波荡漾的大江大河之上,巍然屹立着一座座水电站,它们如同一个个巨人在默默地守护着我们的家园。在这些建设者的辛勤耕耘下,水电站在保障国家能源安全、优化能源结构以及减少环境污染等方面发挥着重要作用。 然而,…...

深度学习入门-第3章-神经网络
前面的待补充 3.6 手写数字识别 3.6.1 MNIST 数据集 本书提供了便利的 Python 脚本 mnist.py ,该脚本支持从下载 MNIST 数据集到将这些数据转换成 NumPy 数组等处理(mnist.py 在 dataset 目录下)。 使用 mnist.py 时,当前目录必须…...

如何使用AES128位进行视频解密
要实现AES128位加解密,可以使用JavaScript的crypto-js库。以下是一个简单的示例: HTML代码: <video controlsList"nodownload" controls></video> 首先,需要安装crypto-js库: npm install cr…...

ArkTS是前端语言吗
ArkTS是前端语言吗 ArkTS,这个名词在现代软件开发领域里逐渐崭露头角,但对于许多人来说,它仍旧是个神秘而令人困惑的存在。那么,ArkTS究竟是前端语言吗?为了回答这个问题,我们需要从多个方面进行深入剖析。…...

git上新down下来的项目,前端启动报错npm ERR! code 1 npm ERR! path E:\code\vuehr\node_modul
解决方法在下面 问题1:> vuehr0.1.0 serve > vue-cli-service serve vue-cli-service 不是内部或外部命令,也不是可运行的程序 或批处理文件。 在项目目录下执行命令npm i -D vue/cli-service来安装vue/cli-service依赖。 运行gitee上下载的…...

oc中的数据结构在都在什么位置
数据结构 在Objective-C中,数据结构可以存在于以下几个位置: 堆(Heap):堆是动态分配的内存空间,用于存储动态创建的对象和数据结构。堆上的数据需要手动进行内存管理,即手动分配和释放内存。 …...

多云世界中的 API 治理
随着企业不断拥抱数字化转型,许多企业正在采用多云战略,以充分利用不同云平台的独特优势和功能。这种方法使企业能够避免被供应商锁定,提高灵活性,并优化 IT 成本。然而,在多个云平台上管理应用程序接口并非易事。它带…...

【稳定检索/投稿优惠】2024年环境、资源与区域经济发展国际会议(ERRED 2024)
2024 International Conference on Environment, Resources and Regional Economic Development 2024年环境、资源与区域经济发展国际会议 【会议信息】 会议简称:ERRED 2024 大会地点:中国杭州 会议官网:www.icerred.com 会议邮箱࿱…...
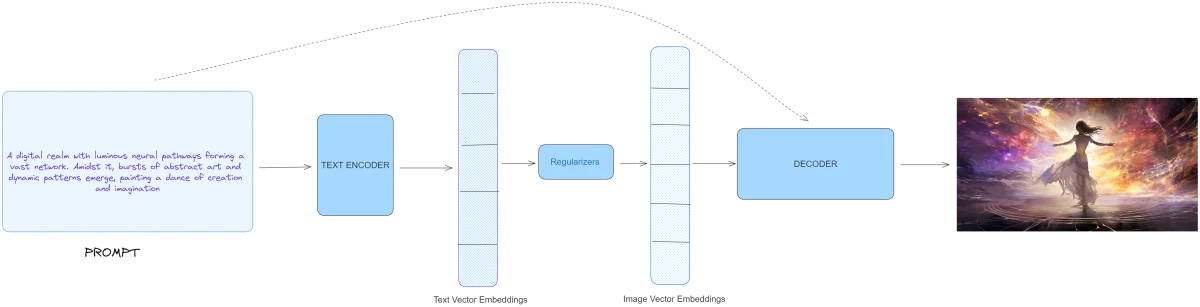
生成式 AI——ChatGPT、Dall-E、Midjourney 等算法理念探讨
1.概述 艺术、交流以及我们对现实世界的认知正在迅速地转变。如果我们回顾人类创新的历史,我们可能会认为轮子的发明或电的发现是巨大的飞跃。今天,一场新的革命正在发生——弥合人类创造力和机器计算之间的鸿沟。这正是生成式人工智能。 生成模型正在模…...

C-数据结构-树状存储基本概念
‘’’ 树状存储基本概念 深度(层数) 度(子树个数) 叶子 孩子 兄弟 堂兄弟 二叉树: 满二叉树: 完全二叉树: 存储:顺序,链式 树的遍历:按层遍历࿰…...

【Linux-Yocto】
Linux-Yocto ■ 1.1 安装 Git 与配置 Git 用户信息■ 1.2 获取 Yocto 项目■ 1.3 开始构建 Yocto 文件系统■ 1.4 构建 SDK 工具■■■ ■ 1.1 安装 Git 与配置 Git 用户信息 sudo apt-get install git git config --global user.name "username" // 配置 Git 用户名…...
)
不止于安装:在Ubuntu上为Arduino IDE 2.x手动添加冷门芯片支持(以LGT8F328P为例)
不止于安装:在Ubuntu上为Arduino IDE 2.x手动添加冷门芯片支持(以LGT8F328P为例) 当你在Ubuntu上完成Arduino IDE 2.x的基础安装后,真正的挑战才刚刚开始。对于那些非官方支持的开发板,如LGT8F328P,标准的库…...
)
告别低效手动:用Amass的intel命令挖掘目标企业所有关联域名(实战演示)
企业级攻击面测绘:Amass intel模块的深度情报挖掘实战 在渗透测试或红队行动中,传统子域名枚举往往只触及企业数字资产的表层。真正的高手会从组织架构、商业关系和技术基础设施三个维度构建立体化的攻击面图谱。Amass的intel模块正是这样一把瑞士军刀—…...

在Nodejs后端服务中集成Taotoken提供AI能力的配置指南
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Nodejs后端服务中集成Taotoken提供AI能力的配置指南 将大模型能力集成到后端服务是现代应用开发的常见需求。对于使用Node.js的开…...

12点标定
12点标定九点标定和十二点标定转换本质是两个平面二维空间的转换两个平面的二维空间的转换公式X物理 X图像200 k * 2 k缩放系数 k2/2000.01剪切图像是一个标准的二维平面空间物理世界,某个固定高度的平面物理空间 高度为5的,板子的所在的物理平面空间…...

零基础30天掌握渗透测试实战路径
1. 别被“渗透测试”四个字吓住:它本质是“合法授权的系统体检”很多人第一次看到“渗透测试”这个词,脑子里立刻浮现出黑客电影里飞速滚动的代码、黑底绿字的终端、戴着兜帽在咖啡馆敲键盘的神秘人——这种刻板印象害了不少想入门的朋友。我带过三十多个…...

Rust异步编程深度实战
Rust异步编程深度实战:从async/await到Tokio运行时原理 作者:Crown_22 | AI Agent & Hermes Agent 桌面程序开发者 前言:为什么Rust异步编程让人又爱又恨? 写了两年Rust异步代码,我最大的感受是:Rust的异步编程模型是所有语言中最"较真"的。它不允许你偷懒…...

5分钟搞定TikTok数据采集:DouK-Downloader终极批量下载神器
5分钟搞定TikTok数据采集:DouK-Downloader终极批量下载神器 【免费下载链接】TikTokDownloader TikTok 发布/喜欢/合辑/直播/视频/图集/音乐;抖音发布/喜欢/收藏/收藏夹/视频/图集/实况/直播/音乐/合集/评论/账号/搜索/热榜数据采集工具/下载工具 项目…...

企业级SECS/GEM协议实现:secsgem库的深度解析与实战指南
企业级SECS/GEM协议实现:secsgem库的深度解析与实战指南 【免费下载链接】secsgem Simple Python SECS/GEM implementation 项目地址: https://gitcode.com/gh_mirrors/se/secsgem 在半导体制造和工业自动化领域,设备通信的标准化和可靠性至关重要…...

测试工程师用 Claude :它修得了选择器,修不了你的需求理解
测试架构这行有个一直没解决的尴尬:开发一周能写完的功能,QA 写测试要追两周。 你越想把覆盖率补齐,这个口子张得越大。 所以当 Claude Code 加上 Playwright 这套东西开始能"自己写测试"的时候, QA 圈子是真的盯着看。但我想先泼一句:它确实改变了一些事, 但改变的…...

通过taotoken cli一键配置python与nodejs开发环境
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过taotoken cli一键配置python与nodejs开发环境 在团队协作或个人多项目开发中,管理不同的大模型API密钥与端点配置是…...