【人工智能Ⅱ】实验8:生成对抗网络
实验8:生成对抗网络
一:实验目的
1:理解生成对抗网络的基本原理。
2:学会构建改进的生成对抗网络,如DCGAN、WGAN、WGAN-GP等。
3:学习在更为真实的数据集上应用生成对抗网络的方法。
二:实验要求
1:理解生成对抗网络改进算法的改进内容和改进目的。
2:参考课程资源中的2024年春第八次实验代码,完成生成对抗网络改进算法WGAN或DCGAN网络的实现。
3:在Fashion MNIST数据集上验证生成对抗网络改进算法的效果,并对其进行调优。
4:在玉米数据集上验证生成对抗网络改进算法在真实场景下对复杂数据集的生成结果。(选做)
5:撰写实验报告,对结果进行分析。
三:实验环境
本实验所使用的环境条件如下表所示。
| 操作系统 | Ubuntu(Linux) |
| 程序语言 | Python(3.11.4) |
| 第三方依赖 | torch, torchvision, matplotlib等 |
四:实验原理
1:GAN
GAN的中文名称为生成对抗网络。GAN是一种深度学习模型,由一个生成器网络和一个判别器网络组成,它们相互竞争地学习生成逼真的数据样本。GAN的核心思想是通过对抗训练来使生成器生成逼真的数据样本,同时训练判别器来区分真实数据样本和生成的数据样本。
【1】生成器网络
生成器网络的目标是接收一个随机噪声向量(通常服从某种先验分布,如均匀分布或正态分布)作为输入,并生成与真实数据样本相似的假数据样本。生成器网络通常由一系列反卷积层(也称为转置卷积层)组成,用于逐渐将输入噪声向量映射到数据空间。生成器网络的输出通常通过某种激活函数(如sigmoid、tanh等)进行转换,以确保生成的数据在合适的范围内。
生成器的训练过程如下图所示。
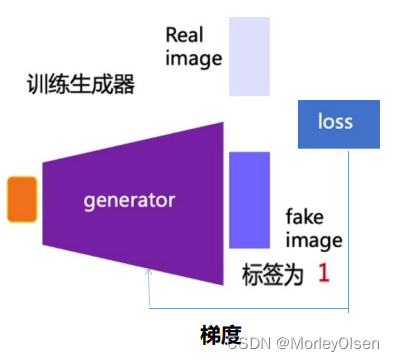
【2】判别器网络
判别器网络的目标是接收真实数据样本或生成的假数据样本作为输入,并输出一个标量值,表示输入数据是真实数据样本的概率。判别器网络通常由一系列卷积层组成,用于从输入数据中提取特征,并最终将这些特征映射到一个标量输出。判别器的输出通常通过sigmoid激活函数进行转换,将其限制在0到1之间,以表示输入数据是真实数据样本的概率。
判别器的训练过程如下图所示。

【3】对抗训练
在对抗训练中,生成器和判别器网络相互竞争,以改善其性能。生成器试图生成越来越逼真的假数据样本,以欺骗判别器,使其无法区分生成的假数据样本和真实数据样本。而判别器则试图提高其准确性,以尽可能准确地区分真实数据样本和生成的假数据样本。这种竞争的动态最终导致了生成器生成逼真的数据样本。
【4】损失函数
生成对抗网络使用两个损失函数来训练生成器和判别器。对于判别器,损失函数通常是二元交叉熵损失函数,用于衡量判别器在真实数据样本和生成的假数据样本上的分类性能。对于生成器,损失函数通常是判别器在生成的假数据样本上的输出与真实标签(即1)之间的二元交叉熵损失函数。通过最小化生成器和判别器的损失函数,可以实现对抗训练。
2:GAN的变种
目前GAN的变体主要从网络结构、条件生成网络、图像翻译、归一化和限制、损失函数、评价指标等方面进行改进。
变体的发展过程如下图所示。

其中,DCGAN(Deep Convolutional Generative Adversarial Networks)、WGAN(Wasserstein Generative Adversarial Networks)和 WGAN-GP(Wasserstein Generative Adversarial Networks with Gradient Penalty)都是GAN的常见变体,用于生成逼真的图像。
上述三种GAN变种的对比如下:
【1】损失函数
DCGAN:DCGAN使用交叉熵损失函数来训练生成器和判别器。
WGAN:WGAN引入了Wasserstein距离作为生成器和判别器之间的损失函数。Wasserstein距离能够更好地衡量生成分布和真实分布之间的差异,从而提高了训练的稳定性。
WGAN-GP:WGAN-GP在WGAN的基础上引入了梯度惩罚项,用于限制判别器的梯度,从而进一步提高了训练的稳定性和生成图像的质量。
【2】训练稳定性
DCGAN:DCGAN在训练过程中可能会出现训练不稳定的问题,例如模式崩溃(mode collapse)和梯度消失等。
WGAN:WGAN的损失函数设计使其更加稳定,可以缓解训练过程中出现的模式崩溃和梯度消失等问题,有助于生成更加高质量和多样化的图像。
WGAN-GP:WGAN-GP进一步改进了WGAN的稳定性,通过梯度惩罚项有效地限制了判别器的梯度,减轻了训练过程中的梯度爆炸和梯度消失问题。
五:算法流程
- 数据准备。准备训练所需的Fashion MNIST数据集。
- 网络构建。利用PyTorch框架搭建不同GAN的判别器和生成器。
- 可视化数据。导出生成器和判别器随着迭代次数所变化的损失曲线图像,同时利用生成器生成图像。
六:实验展示
1:DCGAN在Fashion MNIST数据集上的应用
DCGAN的生成器网络构建,如下图所示。

DCGAN的判别器网络构建,如下图所示。
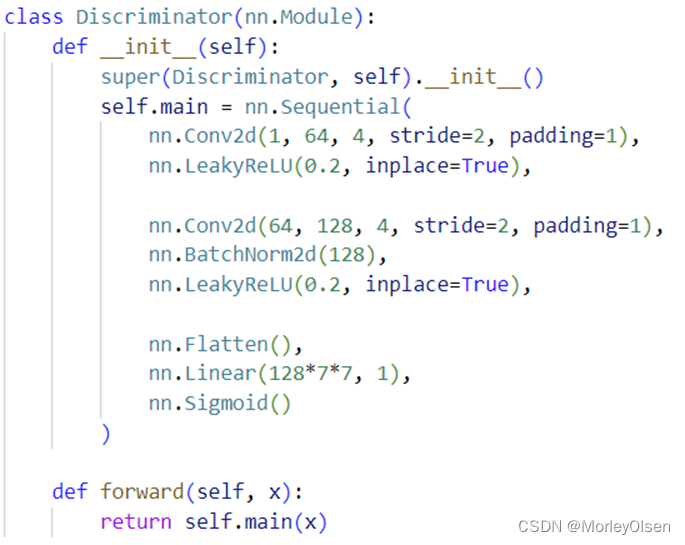
DCGAN使用的损失函数为BCE损失函数,优化器使用Adam,优化器的学习率为0.0002,训练迭代次数为30次。
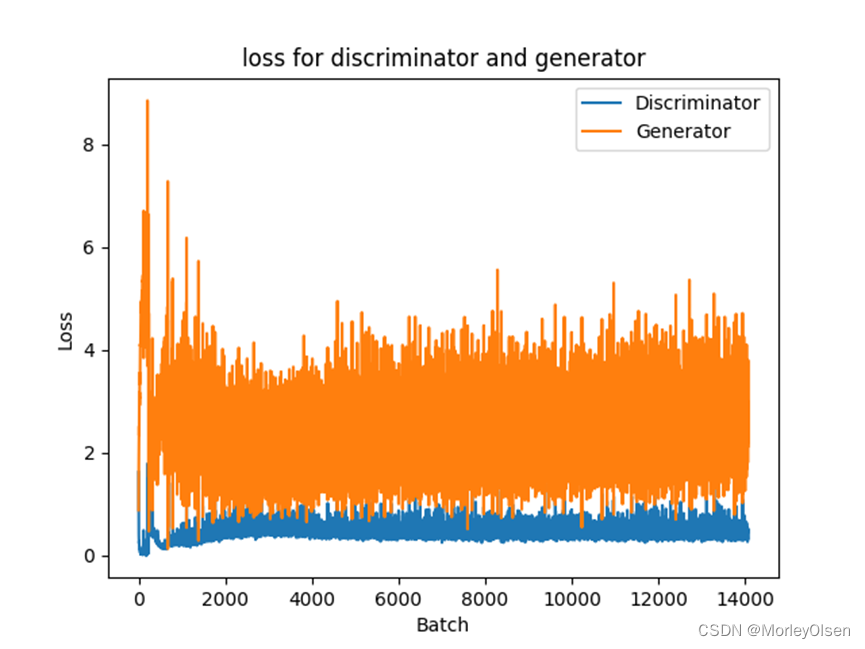
DCGAN中判别器和生成器的损失曲线,如下图所示。其中,橘色部分为生成器、蓝色部分为判别器。
DCGAN的生成效果,如下图所示。

2:WGAN在Fashion MNIST数据集上的应用
WGAN的生成器网络构建,如下图所示。
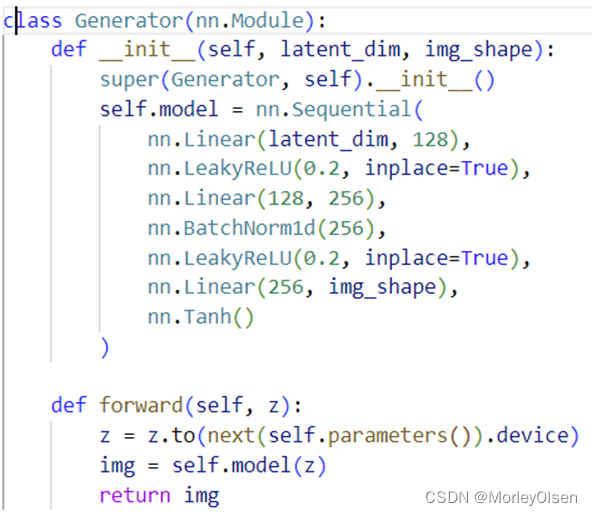
WGAN的判别器网络构建,如下图所示。

WGAN使用的损失函数为Wasserstein距离损失函数,优化器使用RMSprop,优化器的学习率为0.00005,训练迭代次数为30次。
WGAN中判别器和生成器的损失曲线,如下图所示。其中,橘色部分为生成器、蓝色部分为判别器。
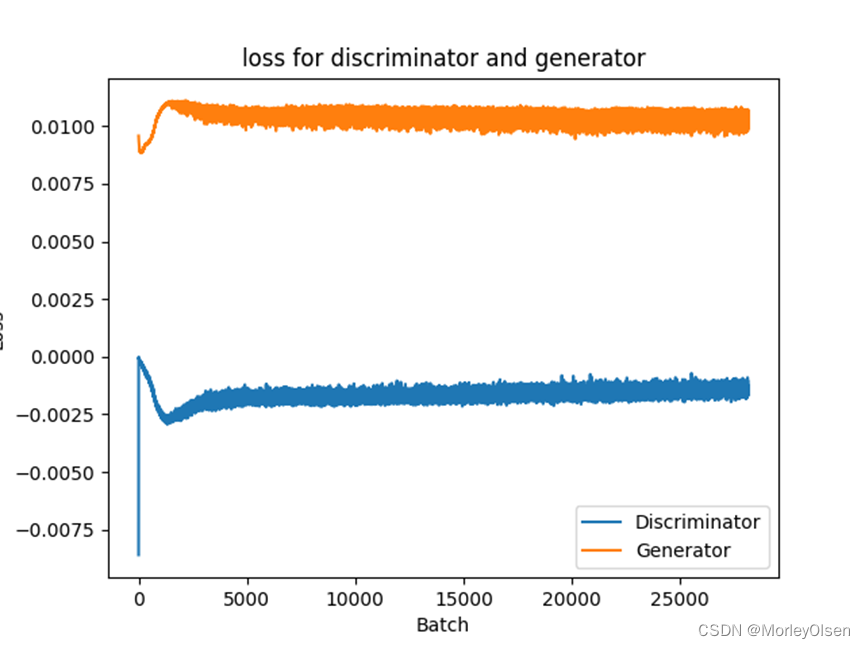
WGAN的生成效果,如下图所示。

3:DCGAN在大米数据集上的应用
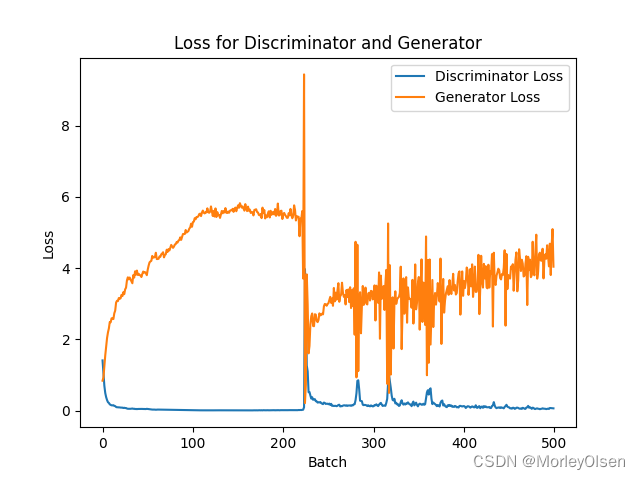
DCGAN的超参数和训练过程与第1部分类似,但是迭代次数变为了500,加载数据集时将图像尺寸压缩为了28*28。
DCGAN中判别器和生成器的损失曲线,如下图所示。其中,橘色部分为生成器、蓝色部分为判别器。
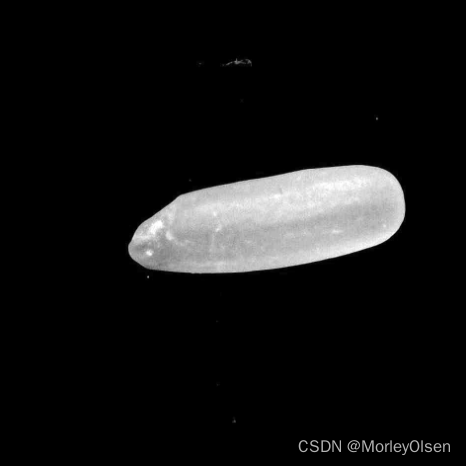
DCGAN的生成效果,如下图所示。生成的图像中包含4粒大米。

源数据集的图像样本如下。
4:DCGAN在玉米数据集上的应用
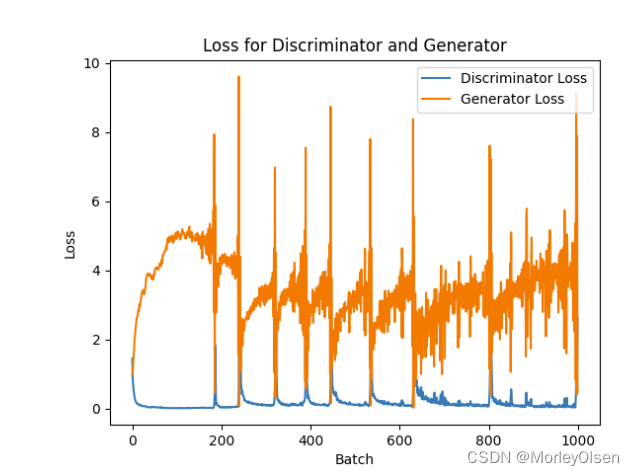
DCGAN的超参数和训练过程与第1部分类似,但是迭代次数变为了500,加载数据集时将图像尺寸压缩为了28*28。
DCGAN中判别器和生成器的损失曲线,如下图所示。其中,橘色部分为生成器、蓝色部分为判别器。
DCGAN的生成效果,如下图所示。生成的图像中包含4个玉米。

源数据集的图像样本如下。

七:实验结论与心得
1:生成对抗网络利用生成器和判别器之间的对抗训练机制,能够有效地生成逼真的数据样本,在图像生成、文本生成、图像转换等领域广泛应用。
2:GAN的性能很大程度上受到超参数的影响,如学习率、潜在空间维度、网络结构等。
3:GAN相比较其他生成模型(玻尔兹曼机等),只用到了反向传播,不需要复杂的马尔科夫链,且可以产生更加清晰、真实的样本。
4:GAN采用无监督的学习方式训练,可以被广泛用在无监督学习和半监督学习领域。
5:如果生成器生成的样本,判别器判定为真实的,则说明生成器的效果是较好的,因而可以用判别器来评价生成器,即判别的性能越差,说明生成器的性能越好。
八:主要代码
1:DCGAN源代码
| import torch from torch import nn, optim from torchvision import datasets, transforms, utils from torch.utils.data import DataLoader import matplotlib.pyplot as plt # 设备配置 device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 数据预处理 transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,)) ]) # 加载数据集 train_data = datasets.FashionMNIST(root='./data', train=True, download=True, transform=transform) train_loader = DataLoader(train_data, batch_size=128, shuffle=True) # 生成器 class Generator(nn.Module): def __init__(self): super(Generator, self).__init__() self.main = nn.Sequential( # 输入是一个 100 维的噪声向量,我们将其投射并reshape成 1x1x128 的大小 nn.Linear(100, 128*7*7), nn.BatchNorm1d(128*7*7), nn.ReLU(True), nn.Unflatten(1, (128, 7, 7)), nn.ConvTranspose2d(128, 64, 4, stride=2, padding=1), nn.BatchNorm2d(64), nn.ReLU(True), nn.ConvTranspose2d(64, 1, 4, stride=2, padding=1), nn.Tanh() ) def forward(self, x): return self.main(x) # 判别器 class Discriminator(nn.Module): def __init__(self): super(Discriminator, self).__init__() self.main = nn.Sequential( nn.Conv2d(1, 64, 4, stride=2, padding=1), nn.LeakyReLU(0.2, inplace=True), nn.Conv2d(64, 128, 4, stride=2, padding=1), nn.BatchNorm2d(128), nn.LeakyReLU(0.2, inplace=True), nn.Flatten(), nn.Linear(128*7*7, 1), nn.Sigmoid() ) def forward(self, x): return self.main(x) # 实例化模型 netG = Generator().to(device) netD = Discriminator().to(device) # 损失函数和优化器 criterion = nn.BCELoss() optimizerD = optim.Adam(netD.parameters(), lr=0.0002, betas=(0.5, 0.999)) optimizerG = optim.Adam(netG.parameters(), lr=0.0002, betas=(0.5, 0.999)) # 训练 num_epochs = 30 lossD = [] lossG = [] for epoch in range(num_epochs): for i, (images, _) in enumerate(train_loader): # 更新判别器:maximize log(D(x)) + log(1 - D(G(z))) netD.zero_grad() real_data = images.to(device) batch_size = real_data.size(0) labels = torch.full((batch_size,), 1, dtype=torch.float, device=device) output = netD(real_data) labels = labels.view(-1, 1) lossD_real = criterion(output, labels) lossD_real.backward() noise = torch.randn(batch_size, 100, device=device) fake_data = netG(noise) labels.fill_(0) output = netD(fake_data.detach()) lossD_fake = criterion(output, labels) lossD_fake.backward() optimizerD.step() # 更新生成器:minimize log(1 - D(G(z))) ≈ maximize log(D(G(z))) netG.zero_grad() labels.fill_(1) # fake labels are real for generator cost output = netD(fake_data) loss_G = criterion(output, labels) loss_G.backward() optimizerG.step()
lossD.append(lossD_real.item() + lossD_fake.item()) lossG.append(loss_G.item()) if (i+1) % 100 == 0: print(f'Epoch [{epoch+1}/{num_epochs}], Step [{i+1}/{len(train_loader)}], Loss_D: {lossD_real.item() + lossD_fake.item():.4f}, Loss_G: {loss_G.item():.4f}') # 可视化一些生成的图片 noise = torch.randn(64, 100, device=device) fake_images = netG(noise) fake_images = fake_images.reshape(fake_images.size(0), 1, 28, 28) fake_images = (fake_images + 1) / 2 # 调整像素值范围到 [0, 1] img_grid = utils.make_grid(fake_images, normalize=True) img_grid = img_grid.cpu() # 首先将张量移至 CPU plt.imshow(img_grid.permute(1, 2, 0).numpy()) plt.savefig("z.png") plt.close() # 绘制曲线 y_values1 = lossD y_values2 = lossG x_values = range(1, len(y_values1) + 1) plt.plot(x_values, y_values1, label='Discriminator Loss') plt.plot(x_values, y_values2, label='Generator Loss') # 添加标题和标签 plt.title('loss for discriminator and generator') plt.xlabel('Batch') plt.ylabel('Loss') plt.legend(['Discriminator', 'Generator']) # 显示图形 plt.savefig('loss-DCGAN.png') |
2:WGAN源代码
| import torch import torch.nn as nn import torch.optim as optim from torchvision import datasets, transforms import matplotlib.pyplot as plt # 设备配置 device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 定义生成器网络 class Generator(nn.Module): def __init__(self, latent_dim, img_shape): super(Generator, self).__init__() self.model = nn.Sequential( nn.Linear(latent_dim, 128), nn.LeakyReLU(0.2, inplace=True), nn.Linear(128, 256), nn.BatchNorm1d(256), nn.LeakyReLU(0.2, inplace=True), nn.Linear(256, img_shape), nn.Tanh() ) def forward(self, z): z = z.to(next(self.parameters()).device) img = self.model(z) return img # 定义判别器网络 class Discriminator(nn.Module): def __init__(self, img_shape): super(Discriminator, self).__init__() self.model = nn.Sequential( nn.Linear(img_shape, 256), nn.LeakyReLU(0.2, inplace=True), nn.Linear(256, 128), nn.BatchNorm1d(128), nn.LeakyReLU(0.2, inplace=True), nn.Linear(128, 1) ) def forward(self, img): validity = self.model(img) return validity # 参数 latent_dim = 100 img_shape = 28 * 28 batch_size = 64 # 准备数据 transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,)) ]) train_dataset = datasets.FashionMNIST(root='./data', train=True, transform=transform, download=True) train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True) # 初始化网络和优化器 generator = Generator(latent_dim, img_shape).to(device) discriminator = Discriminator(img_shape).to(device) optimizer_G = optim.RMSprop(generator.parameters(), lr=0.00005) optimizer_D = optim.RMSprop(discriminator.parameters(), lr=0.00005) # 训练模型 lossD = [] lossG = [] n_epochs = 30 for epoch in range(n_epochs): for i, (imgs, _) in enumerate(train_loader): # 训练判别器 optimizer_D.zero_grad() # 真实图像 real_imgs = imgs.view(-1, img_shape).to(device) validity_real = discriminator(real_imgs)
# 生成潜在空间向量 z = torch.randn(batch_size, latent_dim).to(device) fake_imgs = generator(z).detach() validity_fake = discriminator(fake_imgs) # 计算损失 d_loss = -torch.mean(validity_real) + torch.mean(validity_fake) d_loss_item = d_loss.item()
# 反向传播和优化 d_loss.backward() optimizer_D.step() # 限制判别器参数 for p in discriminator.parameters(): p.data.clamp_(-0.01, 0.01) # 训练生成器 optimizer_G.zero_grad() # 生成潜在空间向量 z = torch.randn(batch_size, latent_dim) fake_imgs = generator(z) validity = discriminator(fake_imgs) # 计算损失 g_loss = -torch.mean(validity) g_loss_item = g_loss.item() # 反向传播和优化 g_loss.backward() optimizer_G.step() lossD.append(d_loss.item()) lossG.append(g_loss.item())
# 打印损失信息 if i % 500 == 0: print( "[Epoch %d/%d] [Batch %d/%d] [D loss: %.4f] [G loss: %.4f]" % (epoch, n_epochs, i, len(train_loader), d_loss.item(), g_loss.item()) ) # 生成图像 z = torch.randn(64, latent_dim, device=device) generated_images = generator(z) generated_images = generated_images.detach().cpu().numpy() # 显示生成的图像 fig, axes = plt.subplots(nrows=8, ncols=8, figsize=(10, 10)) for i, ax in enumerate(axes.flatten()): ax.imshow(generated_images[i].reshape(28, 28), cmap='gray') ax.axis('off') plt.tight_layout() plt.savefig('zz.png') plt.close() # 绘制曲线 y_values1 = lossD y_values2 = lossG x_values = range(1, len(y_values1) + 1) plt.plot(x_values, y_values1, label='Discriminator Loss') plt.plot(x_values, y_values2, label='Generator Loss') # 添加标题和标签 plt.title('loss for discriminator and generator') plt.xlabel('Batch') plt.ylabel('Loss') plt.legend(['Discriminator', 'Generator']) # 显示图形 plt.savefig('loss-WGAN.png') |
3:玉米数据集上的DCGAN
| import torch from torch import nn, optim from torchvision import transforms, utils import matplotlib.pyplot as plt import os from PIL import Image from torch.utils.data import Dataset, DataLoader class CustomDataset(Dataset): def __init__(self, data_dir, transform=None): self.data_dir = data_dir self.transform = transform self.image_files = os.listdir(data_dir) def __len__(self): return len(self.image_files) def __getitem__(self, idx): img_name = os.path.join(self.data_dir, self.image_files[idx]) image = Image.open(img_name).convert("RGB") # 读取图像,并转换为RGB格式 if self.transform: image = self.transform(image) return image # 数据集文件夹路径 data_dir = r"/home/ubuntu/zz-test" # 设备配置 device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 数据预处理 transform = transforms.Compose([ transforms.Resize((28, 28)), # 将图像调整为28x28大小 transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,)) ]) # 加载数据集 train_data = CustomDataset(data_dir, transform=transform) train_loader = DataLoader(train_data, batch_size=32, shuffle=True) # 生成器 class Generator(nn.Module): def __init__(self): super(Generator, self).__init__() self.main = nn.Sequential( nn.Linear(100, 128*7*7), nn.BatchNorm1d(128*7*7), nn.ReLU(True), nn.Unflatten(1, (128, 7, 7)), nn.ConvTranspose2d(128, 64, 4, stride=2, padding=1), nn.BatchNorm2d(64), nn.ReLU(True), nn.ConvTranspose2d(64, 3, 4, stride=2, padding=1), # 修改这里的输出通道数为3 nn.Tanh() ) def forward(self, x): return self.main(x) # 判别器 class Discriminator(nn.Module): def __init__(self): super(Discriminator, self).__init__() self.main = nn.Sequential( nn.Conv2d(3, 64, 4, stride=2, padding=1), # 修改这里的输入通道数为3 nn.LeakyReLU(0.2, inplace=True), nn.Conv2d(64, 128, 4, stride=2, padding=1), nn.BatchNorm2d(128), nn.LeakyReLU(0.2, inplace=True), nn.Flatten(), nn.Linear(128*7*7, 1), nn.Sigmoid() ) def forward(self, x): return self.main(x) # 实例化模型 netG = Generator().to(device) netD = Discriminator().to(device) # 损失函数和优化器 criterion = nn.BCELoss() optimizerD = optim.Adam(netD.parameters(), lr=0.0002, betas=(0.5, 0.999)) optimizerG = optim.Adam(netG.parameters(), lr=0.0002, betas=(0.5, 0.999)) # 训练 num_epochs = 500 lossD = [] lossG = [] for epoch in range(num_epochs): for i, images in enumerate(train_loader): # 更新判别器:maximize log(D(x)) + log(1 - D(G(z))) netD.zero_grad() real_data = images.to(device) batch_size = real_data.size(0) labels = torch.full((batch_size,), 1, dtype=torch.float, device=device) output = netD(real_data) labels = labels.view(-1, 1) lossD_real = criterion(output, labels) lossD_real.backward() noise = torch.randn(batch_size, 100, device=device) fake_data = netG(noise) labels.fill_(0) output = netD(fake_data.detach()) lossD_fake = criterion(output, labels) lossD_fake.backward() optimizerD.step() # 更新生成器:minimize log(1 - D(G(z))) ≈ maximize log(D(G(z))) netG.zero_grad() labels.fill_(1) # fake labels are real for generator cost output = netD(fake_data) loss_G = criterion(output, labels) loss_G.backward() optimizerG.step()
lossD.append(lossD_real.item() + lossD_fake.item()) lossG.append(loss_G.item()) if (i+1) % 100 == 0: print(f'Epoch [{epoch+1}/{num_epochs}], Step [{i+1}/{len(train_loader)}], Loss_D: {lossD_real.item() + lossD_fake.item():.4f}, Loss_G: {loss_G.item():.4f}') # 保存生成的图像 noise = torch.randn(4, 100, device=device) fake_images = netG(noise) fake_images = (fake_images + 1) / 2 # 调整像素值范围到 [0, 1] img_grid = utils.make_grid(fake_images, nrow=2, normalize=True) # 将图像网格化,并且每行显示8张图像 img_grid = img_grid.permute(1, 2, 0).cpu().numpy() # 将张量转换为NumPy数组,并将通道维度放到最后 plt.imshow(img_grid) plt.axis('off') # 关闭坐标轴 plt.savefig("generated_images.png") plt.close() # 绘制损失曲线 plt.plot(lossD, label='Discriminator Loss') plt.plot(lossG, label='Generator Loss') # 添加标题和标签 plt.title('Loss for Discriminator and Generator') plt.xlabel('Batch') plt.ylabel('Loss') plt.legend() # 保存损失曲线图 plt.savefig('loss-DCGAN.png') plt.close() |
相关文章:
【人工智能Ⅱ】实验8:生成对抗网络
实验8:生成对抗网络 一:实验目的 1:理解生成对抗网络的基本原理。 2:学会构建改进的生成对抗网络,如DCGAN、WGAN、WGAN-GP等。 3:学习在更为真实的数据集上应用生成对抗网络的方法。 二:实验…...
vmware将物理机|虚拟机转化为vmware虚机
有时,我们需要从不同的云平台迁移虚拟机、上下云、或者需要将不再受支持的老旧的物理服务器转化为虚拟机,这时,我们可以用一款虚拟机转化工具:vmware vcenter converter standalone,我用的是6.6的版本,当然…...

redis 高可用及哨兵模式 @by_TWJ
目录 1. 高可用2. redis 哨兵模式3. 图文的方式让我们读懂这几个算法3.1. Raft算法 - 图文3.2. Paxos算法 - 图文3.3. 区别: 1. 高可用 在 Redis 中,实现 高可用 的技术主要包括 持久化、复制、哨兵 和 集群,下面简单说明它们的作用…...

封装tab栏,tab切换可刷新页面
dom结构 <template><div class"container"><!-- tab栏 --><div class"border-b"><tabs:tabsList"tabsList":selectTabsIndex"selectTabsIndex"tabsEven"tabsEven"></tabs></div>…...

JavaScript第八讲:日期,Math,自定义对象
目录 前言 日期 1. 创建日期对象 2. 年/月/日 3. 时:分:秒:毫秒 4. 一周的第几天 5. 经历的毫秒数 6. 修改日期和时间 Math 1. 自然对数和圆周率 2. 绝对值 3. 最小最大 4. 求幂 5. 四舍五入 6. 随机数 自定义对象 1. 通过 new Object 创建对象 2. 通过 funct…...

php质量工具系列之phploc
phploc是一个快速测量PHP项目大小的工具 结果支持raw csv xml json格式,可输出文件或者打印到控制台 安装 PHAR方式 wget https://phar.phpunit.de/phploc.pharphp phploc.phar -vComposer方式(推荐) composer global require --dev phploc/phplocphploc -v使用 …...
创建模拟器
修改模拟器默认路径 由于模拟器文件比较大,默认路径在C:\Users\用户名.android\avd,可修改默认路径 创建修改后的路径文件 D:\A-software\Android\AVD添加系统变量ANDROID_SDK_HOME:D:\A-software\Android\AVD重启Android Studio 创建模拟…...
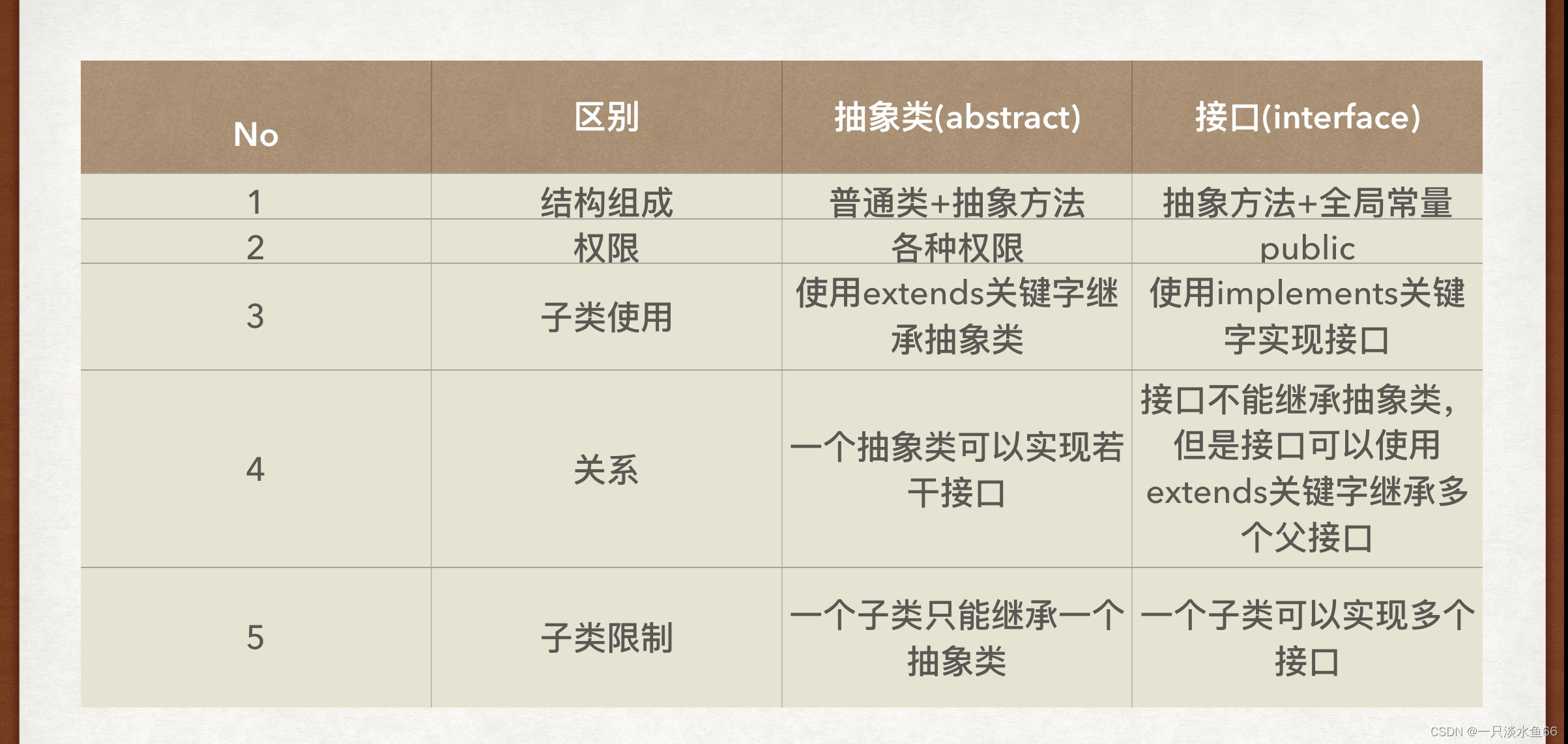
【Java】接口详解
接口是抽象类的更进一步. 抽象类中还可以包含非抽象方法, 和字段. 而接口中包含的方法都是抽象方法, 字段只能包含静态常量。 一个简单的接口代码示例 interface IShape { void draw(); } class Cycle implements IShape { Override public void draw() { System.out.println…...
去掉el-table表头右侧类名是gutter,width=17px的空白区域(包括表头样式及表格奇偶行样式和表格自动滚动)
代码如下: <el-table:data"tableData"ref"scroll_Table":header-cell-style"getRowClass":cell-style"styleBack"height"350px"style"width: 100%"><el-table-column prop"id" l…...

3079. 求出加密整数的和
给你一个整数数组 nums ,数组中的元素都是 正 整数。定义一个加密函数 encrypt ,encrypt(x) 将一个整数 x 中 每一个 数位都用 x 中的 最大 数位替换。比方说 encrypt(523) 555 且 encrypt(213) 333 。 请你返回数组中所有元素加密后的 和 。 示例 1&…...

奶茶店、女装店、餐饮店是高危创业方向,原因如下:
关注卢松松,会经常给你分享一些我的经验和观点。 现在的俊男靓女们,心中都有一个执念: (1)想证明自己了,开个奶茶去…… (2)想多赚点钱了,加盟餐饮店去…… (3)工作不顺心了,搞个女装店去…… 但凡抱着…...
)
嵌入式笔试面试刷题(day16)
文章目录 前言一、PWM波形的占空比计算公式是什么?二、ADC和DAC在嵌入式系统中的应用场景有哪些?三、watchdog定时器的作用及其在系统中的使用是什么?四、JTAG接口在嵌入式开发中的作用是什么?五、实时操作系统(RTOS)的任务调度策…...
【MyBatis】MyBatis操作数据库(二):动态SQL、#{}与${}的区别
目录 一、 动态SQL1.1 \<if>标签1.2 \<trim>标签1.3 \<where>标签1.4 \<set>标签1.5 \<foreach>标签1.6 \<include>标签 二、 #{}与${}的区别2.1 #{}是预编译sql,${}是即时sql2.2 SQL注入2.3 #{}性能高于${}2.4 ${}用于排序功能…...
[Zer0pts2020]easy strcmp 分析与加法
查壳 Ubuntu上的64位程序 第一步应该尝试运行一下 啥也不是 (这里我改了程序,原来应该是a1>1) 但是我动调发现a1值是1 我就改了判断 但是还是没什么用 也找不到a2的引用 找一下有没有什么improt调用 发现还是啥也不是 思路这里断了 刚好这个程序几个代码而已 函数看…...

力扣7. 整数反转
给你一个 32 位的有符号整数 x ,返回将 x 中的数字部分反转后的结果。 如果反转后整数超过 32 位的有符号整数的范围 [−231, 231 − 1] ,就返回 0。 假设环境不允许存储 64 位整数(有符号或无符号)。 示例 1: 输…...
)
Mac/Linux getline 无法读取文件内容(读取内容无法显示)
如下面代码 #include <iostream> #include <fstream>using namespace std;int main() {string file_name "1.txt";std::ifstream file(file_name);if (file.is_open()) {std::string line;while (std::getline(file, line)) {char c line.back();cout…...

NBM 算法【python,算法,机器学习】
朴素贝叶斯法(Naive Bayes model)是基于贝叶斯定理与特征条件独立假设的分类方法。 贝叶斯定理 P ( A ∣ B ) P ( B ∣ A ) ∗ P ( A ) P ( B ) P(A|B)\frac{P(B|A) * P(A)}{P(B)} P(A∣B)P(B)P(B∣A)∗P(A) 其中A表示分类,B表示属性&…...

spark3.0.1版本查询Hbase数据库例子
需求背景 现有需求,需要采用spark查询hbase数据库的数据同步到中间分析库,记录spark集成hbase的简单例子代码 import org.apache.hadoop.hbase.HBaseConfiguration import org.apache.hadoop.hbase.client.{ConnectionFactory, Scan} import org.apach…...
android高效读图方式——Hardwarebuffer读图
安卓上有许许多多使用OpenGL来渲染的原因,比方说做特效/动画/硬解/人脸识别等等。渲染完成后如何从gpu中把数据快速读取出来也是高效图像处理中的重要的一环。 相对于glReadPixel的同步读取方式,安卓GLES3.0提供了更高效快速的Hardwarebuffer读图方式&a…...

悉数六大设计原则
悉数六大设计原则 目录 悉数六大设计原则前言☕谁发明了设计模式设计原则设计原则与设计模式的关系 单一职责什么是单一职责不遵循单一职责原则的设计遵循单一职责原则的设计单一职责的优点示例代码: 里氏替换原则什么是里氏替换原则示例代码:违反里氏替…...

DDrawCompat终极指南:3步让老游戏在现代Windows上完美运行![特殊字符]
DDrawCompat终极指南:3步让老游戏在现代Windows上完美运行!🎮 【免费下载链接】DDrawCompat DirectDraw and Direct3D 1-7 compatibility, performance and visual enhancements for Windows Vista, 7, 8, 10 and 11 项目地址: https://git…...

基于STM32H750XBH6开发板调试LwIP裸机程序
目录 1 前言 2 正点原子STM32H750XBH6阿波罗开发板介绍 3 配置和调试 3.1 CubeMX配置 3.2 代码修改 1 前言 LwIP 是物联网 / 嵌入式领域使用最广的开源 精简版TCP/IP 协议栈,STM32、ESP32、国产 MCU 全都用它,对于嵌入式 / 物联网初学者来说,亲手调试 LwIP 裸机程序(无操作…...

武汉专升本民办 vs 公办机构怎么选
每年到了专科大三的春天,武汉的专升本备考群里总会出现类似的问题:“公办机构是不是比民办靠谱?”“民办会不会拿钱不办事?”“集训营到底该冲公办还是选民办?”说实话,这个问题没有标准答案,因…...

脉冲相机与NeRF结合的高速场景三维重建技术
1. 高速场景重建的技术挑战与解决方案在计算机视觉领域,高速场景的三维重建一直是个棘手的问题。传统RGB相机受限于曝光时间和帧率,在拍摄快速运动物体时会产生严重的运动模糊。这种模糊不仅影响视觉效果,更会破坏三维重建所需的几何和纹理信…...

探索Pandas groupby的各种技巧和应用实例
groupby是Pandas中用于数据分析的重要工具,它允许我们根据特定列的不同值,对数据行进行灵活分组。分组后的数据可用于生成各类聚合值,从而帮助我们深入了解数据。在Pandas中,如果你想要分析数据的潜在模式或趋势,group…...

终极Pandoc文档转换指南:5分钟掌握40+格式互转神器
终极Pandoc文档转换指南:5分钟掌握40格式互转神器 【免费下载链接】pandoc Universal markup converter 项目地址: https://gitcode.com/gh_mirrors/pa/pandoc 还在为不同文档格式之间的转换而烦恼吗?学术论文需要LaTeX排版,技术文档要…...

H3CSE 高性能园区网:生成树保护机制
H3CSE 高性能园区网:生成树保护机制一、生成树保护机制1. BPDU保护1.1 边缘端口特点及问题端口基础特性存在的安全隐患1.2 BPDU保护机制核心防护逻辑机制运行优势1.3 BPDU保护配置配置使用规范H3C设备配置命令2. 根桥保护2.1 根桥保护机制2.2 根桥保护配置要求2.3 根…...

GitLab CVE-2025-1477:URI编码绕过身份验证的应急防护指南
1. 这个漏洞不是“修个补丁就完事”的普通问题GitLab 安全漏洞 CVE-2025-1477,光看编号容易误以为是又一个常规的权限绕过或信息泄露类CVE——毕竟GitLab每年披露几十个中低危漏洞,运维同学看到CVE编号第一反应往往是查CVSS评分、翻官方通告、打补丁、走…...

Cortex-M3 LOCKUP机制解析与嵌入式系统容错设计
1. Cortex-M3 LOCKUP机制解析LOCKUP是ARM Cortex-M3处理器中的一种特殊状态,当系统遇到无法恢复的严重错误时会进入该状态。理解LOCKUP机制对于嵌入式系统开发者至关重要,因为它直接关系到系统的可靠性和故障恢复能力。LOCKUP状态的核心特征是程序计数器…...

为什么我看不到我的图库中的照片?修复并恢复图片
照片在我们生活中占据着特殊的地位,它们帮助我们重温珍贵的回忆,并与远近的亲人保持联系。照片就像一扇通往我们最珍贵时刻的私人窗口,因此,当它们突然从相册应用中消失时,会格外令人沮丧。如果你曾经疑惑过“为什么我…...