MySQL之查询性能优化(二)
查询性能优化
慢查询基础:优化数据访问
查询性能低下最基本的原因是访问的数据太多。某些查询可能不可避免地需要筛选大量数据,但这并不场景。大部分性能低下的查询都可以通过减少访问的数据量的方式进行优化。对于低效的查询,我们发现通过下面两个步骤来分析总是很有效:
- 1.确认应用程序是否在检索大量超过需要的数据。这通常意味着访问了太多的行,但有时候也可能是访问了太多的列
- 2.确认MySQL服务器是否在分析大量超过需要的数据行
是否向数据库请求了不需要的数据。
有些查询会请求超过实际需要的数据,然后这些多余的数据会被应用程序丢弃。这回给MySQL服务器带来额外的负担,并增加网络开销(如果应用服务器和数据库不在同一台主机上,网络开销就显得很明显了。即使在同一台服务器上仍然会有数据传输的开销)。另外也会消耗应用服务器的CPU和内存资源。下面是一些典型案例:
- 1.查询不需要的记录:一个常见的错误是常常误以为MySQL会只返回需要的数据,实际上MySQL却是先返回全部结果集再进行计算。我们经常会看到一些了解其他数据库系统的人会设计出这类应用程序。这些开发者习惯适用这样的使用,先使用SELECT语句查询大量的结果,然后获取前面的N行后关闭结果集(例如在新闻网站中取出100条记录,但是只是在页面上显示前面10条)。它们认为MySQL会执行查询,并只返回它们需要的10条数据,然后停止查询。实际情况是MySQL会查询出全部的结果集,客户端的应用程序会接收全部的结果集数据,然后抛弃其中大部分数据。最简单有效的解决方法就是在这样的查询后面加上LIMIT
- 2.多表关联时返回全部列:如果你想查询所有在电影Academy Dinosaur中出现的演员,千万不要按下面的写法编写查询:
mysql> SELECT * FROM actor-> INNER JOIN film_actor USING(actor_id)-> INNER JOIN film USING(film_id)-> WHERE film.title='Academy Dinosaur';
这将返回这三个表的全部数据列。正确的方式应该时像下面这样只取需要的列:
mysql>SELECT actor.* FROM actor .....
- 3.总是取出全部列:每次看到SELECT * 的时候都需要用怀疑的眼光审视,是不是真的需要返回全部的列?很可能不是必需的。取出全部列,会让优化器无法完成索引覆盖扫描这类优化,还会为服务器带来额外的IO、内存和CPU的消耗。因此,一些DBA是严格禁止SELECT * 的写法的,这样做有时候还能避免某些列被修改带来的问题。当然,查询返回超过需要的数据也不总是坏事。在许多案例中,人们会说这种有点浪费数据库资源的方式可以简化开发,因为能提高相同代码片段的复用性,如果清除这样做的性能影响,那么这种做法也是值得考虑的。如果应用程序使用了某种缓存机制,或者有其他考虑,获取超过需要的数据也可能有其他好处,但不要忘记这样做的代价是什么。获取并缓存所有的列的查询相比多个独立的只获取部分列的查询可能就更有好处。
- 4.重复查询相同的数据:如果你不太小心,很容易出现这样的错误——不断地重复执行相同的查询,然后每次都返回完全相同的数据。例如,在用户评论的地方需要查询用户头像的URL,那么用户多次评论的时候,可能就会反复查询这个数据。比较好的方案是,当初次查询的时候将这个数据缓存起来,需要的时候从缓存中取出,这样性能显然会更好。
MySQL是否扫描额外的记录
在确定查询只返回需要的数据以后,接下来应该看看查询为了返回结果是否扫描了许多的数据。对于MySQL,最简单的衡量查询开销的三个指标如下:
1.响应时间
2.扫描的行数
3.返回的行数
没有哪个指标能够完美地衡量查询的开销,但它们大致反映了MySQL在内部执行查询时需要访问多少数据,并可以大概推算出查询运行的时间。这三个指标都会记录到MySQL的慢日志中,所以检查慢日志记录是找出扫描行数过多的查询的好办法
响应时间
要记住, 响应时间只是一个表面的值。这样说可能看起来和前面关于响应时间的说法有矛盾?其实并不矛盾,响应时间仍然是最重要的指标,这有一点复杂,后面细细道来。响应时间是两个部分之和:服务时间和排队时间。服务时间是指数据处理这个查询真正花了多长时间。排队时间是指服务器因为等待某些资源而没有真正执行查询的时间——可能是等待IO操作完成,也可能是等待行锁,等等。遗憾的是,我们无法把响应时间细分到上面这些部分,除非有什么办法能够逐个测量上面这些消耗,不过很难做到,一般最常见和重要的等待是IO和锁等待,但实际情况更加复杂。所以在不同类型的应用压力下,响应时间并没有什么一致的规律或者共识。诸如存储引擎的锁(表锁、行锁)、高并发资源竞争、硬件响应等诸多因素都会影响到响应时间。所以,响应时间既可能是一个问题的结果也可能是一个问题的原因,不同案例情况不同,除非我们能深入测量出每个环节。
当你看到一个查询的响应时间的时候,首先需要问问自己,这个响应时间是否是一个合理的值。实际上可以使用"快速上限估计"法来估算查询的响应时间,这是由Lahdenmaki和Mike Leach编写的Relational Database Index Design and the Optimizers一书中提到的技术。概括地说,了解这个查询需要哪些索引以及它的执行计划是什么,然后计算大概需要多少个顺序和随机IO,再用其乘以在具体硬件条件下一次IO的消耗。最后把这些消耗都加起来,就可以获得一个大概参考值来判断当前响应时间是不是一个合理得值
扫描的行数和返回的行数
分析查询时,查看该查询扫描的行数时非常有帮助的。这在一定程度上能够说明该查询找到需要的数据的效率高不高。对于找出哪些"糟糕"的查询,这个指标可能还不够完美,因为并不是所有的行的访问代价都是相同的。较短的行的访问速度更快,内存中的行也比磁盘中的行访问速度要快得多。理想情况下扫描得行数和返回的行数应该是相同的。但实际情况中这种"美事"并不多。例如在做一个管来奶查询时,服务器必须要扫描多行才能生成结果集中的一行。扫描的行数对返回的行数的比率通常很小,一般在1:1和10:1之间,不过有时候这个值也可能非常非常大
扫描的行数和访问类型
在评估查询开销的时候,需要考虑一下从表中找到某一行数据的成本。MySQL有好几种访问方式可以查找并返回一行结果。有些访问方式可能需要扫描很多行才能返回一行结果,也有些访问方式可能无须扫描就能返回结果。在EXPLAIN语句中的type列反应了访问类型。访问类型有很多种,从全表扫描到索引扫描、范围扫描、唯一索引查询、常数引用等。这里列的这些,速度时从慢到快,扫描的行数也是从多到少。你不需要记住这些访问类型,但需要明白扫描表、扫描索引、范围访问和单值访问的概念.如果查询没有办法找到合适的访问类型,那么解决的最好办法通常就是增加一个合适的索引。现在应该明白为什么索引对于查询优化如此重要了。索引让MySQL以最高效、扫描行数最少的方式找到需要的记录。例如,我们看看示例库Sakila中的一个查询案例:
mysql> SELECT * FROM film_actor WHERE film_id =1;
+----------+---------+---------------------+
| actor_id | film_id | last_update |
+----------+---------+---------------------+
| 1 | 1 | 2006-02-15 05:05:03 |
| 10 | 1 | 2006-02-15 05:05:03 |
| 20 | 1 | 2006-02-15 05:05:03 |
| 30 | 1 | 2006-02-15 05:05:03 |
| 40 | 1 | 2006-02-15 05:05:03 |
| 53 | 1 | 2006-02-15 05:05:03 |
| 108 | 1 | 2006-02-15 05:05:03 |
| 162 | 1 | 2006-02-15 05:05:03 |
| 188 | 1 | 2006-02-15 05:05:03 |
| 198 | 1 | 2006-02-15 05:05:03 |
+----------+---------+---------------------+
这个查询将返回10行数据,从EXPLAIN的结果可以看到,MySQL在索引idx_fk_film_id上使用了ref访问类型来执行查询:
mysql> EXPLAIN SELECT * FROM film_actor WHERE film_id=1\G
*************************** 1. row ***************************id: 1select_type: SIMPLEtable: film_actorpartitions: NULLtype: ref
possible_keys: idx_fk_film_idkey: idx_fk_film_idkey_len: 2ref: constrows: 10filtered: 100.00Extra: NULL
1 row in set, 1 warning (0.00 sec)
EXPLAIN的结果也显示MySQL预估需要访问10行数据。换句话说,查询优化器认为这种访问类型可以高效地完成查询。如果没有合适地索引会怎样呢?MySQL就不得不使用一种更糟糕地访问类型,下面我们来看看如果我们删除对应的索引再来运行这个查询:
mysql> ALTER TABLE film_actor DROP FOREIGN KEY fk_film_actor_film;
Query OK, 0 rows affected (18.97 sec)
Records: 0 Duplicates: 0 Warnings: 0mysql> ALTER TABLE film_actor DROP KEY idx_fk_film_id;
Query OK, 0 rows affected (0.03 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> EXPLAIN SELECT * FROM film_actor WHERE film_id=1\G
*************************** 1. row ***************************id: 1select_type: SIMPLEtable: film_actorpartitions: NULLtype: ALL
possible_keys: NULLkey: NULLkey_len: NULLref: NULLrows: 5462filtered: 10.00Extra: Using where
1 row in set, 1 warning (0.00 sec)
正如我们预测的,访问类型变成了一个全表扫描(ALL),现在MySQL预估需要扫描5462条记录来完成这个查询。这里的"Using Where"表示MySQL将通过WHERE条件来筛选存储引擎返回的记录。一般MySQL能够使用如下三种方式应用WHERE条件,从好到坏依次为:
- 1.在索引中使用WHERE条件来过滤不匹配的记录。这是在存储引擎层完成的
- 2.使用索引覆盖扫描(在Extra列出现了Using index)来返回记录,直接从素银中过滤不需要的记录并返回命中的结果。这是在MySQL服务器层完成的,但无须再回表查询记录
- 3.从数据表中返回数据,然后过滤不满足条件的记录(在Extra列中出现Using WHere)。这在MySQL服务器层完成,MySQL需要从数据表独处记录后过滤。
上面这个例子说明了好的索引多么重要。好的索引可以让查询使用合适的访问了悉尼港,尽可能地只扫描需要的数据行。但也不是说增加索引就能让扫描的行数等于返回的行数。例如下面使用聚合函数COUNT()的查询:
mysql> SELECT * FROM film_actor WHERE film_id =1;
这个查询需要读取几千行数据,但是仅返回200行结果。没有什么索引能够让这样的查询减少需要扫描的行数。不幸的是,MySQL不会告诉我们生成结果实际上需要扫描多少行数据(例如关联查询结果返回的一条记录通常是由多条记录组成的)而只会告诉我们生成结果时一共扫描了多少行数据。扫描的行数中的大部分都很可能是被WHERE条件过滤掉的,对最终结果集并没有贡献。在上面的例子中,删除索引后,看到MySQL需要扫描所有记录然后根据WHERE条件过滤,最终只返回10行结果。理解一个查询需要扫描多少行和实际需要使用的行数需要先去理解这个查询背后的逻辑和思想。
如果发现查询需要扫描大量的数据但只返回少数的行,那么通常可以尝试下面的技巧去优化它:
- 1.使用索引覆盖扫描,把所有需要用的列都放到索引中,这样存储引擎无须回表获取对应行就可以返回结果;额
- 2.改变库表结构。例如使用单独的汇总表
- 3.重写这个复杂的查询,让MySQL优化器能够以更优化的方式执行这个查询
相关文章:
)
MySQL之查询性能优化(二)
查询性能优化 慢查询基础:优化数据访问 查询性能低下最基本的原因是访问的数据太多。某些查询可能不可避免地需要筛选大量数据,但这并不场景。大部分性能低下的查询都可以通过减少访问的数据量的方式进行优化。对于低效的查询,我们发现通过下面两个步骤…...

The Best Toolkit 最好用的工具集
The Best Toolkit 工欲善其事,必先利其器,整理过往工作与生活中遇到的最好的工具软件 PDF合并等 PDF24 Tools PDF查看器 SumatraPDF 可以使用黑色来查看,相对不伤眼睛,也有电子书相关的阅读器 Kindle pdf裁边工具 briss 软件卸载…...
类型)
使用C#反射中的MAKEGENERICTYPE函数,来为泛型方法和泛型类指定(泛型的)类型
MakeGenericType 是一个在 C# 中用于创建开放类型的实例的方法。开放类型是一种未绑定类型参数的泛型类型。当你有一个泛型类型定义,并且想要用特定的类型实例化它时,你可以使用 MakeGenericType 方法。 public Type MakeGenericType (params Type[] ty…...

sql注入 (运用sqlmap解题)
注:level参数 使用–batch参数可指定payload测试复杂等级。共有五个级别,从1-5,默认值为1。等级越高,测试的payload越复杂,当使用默认等级注入不出来时,可以尝试使用–level来提高测试等级。 --level 参数决定了 sql…...

HTML5 Canvas 绘图教程二
在本教程中,我们将探讨 canvas 的高级用法,包括复杂的绘图 API、坐标系统和变换操作、平滑动画技术以及复杂应用和游戏开发的实践。 1. 绘图 API 高级方法 1.1 二次贝塞尔曲线 (quadraticCurveTo) 二次贝塞尔曲线需要两个点:一个控制点和一…...

Linux 命令 find 的深度解析与使用
Linux 命令 find 的深度解析与使用 在 Linux 系统中,find 命令是一个功能强大的工具,用于在文件系统中搜索文件或目录。无论是基于文件名、文件类型、文件大小、文件权限,还是基于文件的最后修改时间等,find 命令都能提供灵活的搜…...

字符串操作记录
1 拼接 Concat():拼接字符串 Let stringvalue “hello ”; Let result stringvalue.concat(“world”) Console.log(result) // “hello world” 2 删 Let stringvalue “hello world”Console.log(stringvalue.slice(3)); // ‘lo world’Console.log(stringvalue.subst…...

【python科学文献计量】关于中国知网检索策略的验证,以事故伤害严重程度检索为例
关于中国知网检索策略的验证,以事故伤害严重程度检索为例 1 背景2 文献下载3 数据处理1 背景 由于要进行相关研究内容的综述,需要了解当前我国对于事故伤害严重程度的研究现状,采用国内较为知名的检索网站(中国知网)进行文献数据集检索 由于最近知网出bug,检索的结果在…...

AdminController
目录 1、 AdminController 1.1、 UpdateFaculty 1.1.1、 // Check if a new image file is provided 1.1.2、 // CHECKING FOLDER EXIST OR NOT - IF NOT THEN CREATE F0LDER 1.1.3、 // READY SEND PATH TO IMAGE TO DB 1.1.4、 DeleteFaculty 1.1.5、 // If th…...

Vue3-Pinia状态管理器
Pinia 是 Vue 的专属状态管理库,它允许你跨组件或页面共享状态。如果你熟悉组合式 API 的话,你可能会认为可以通过一行简单的 export const state reactive({}) 来共享一个全局状态。对于单页应用来说确实可以,但如果应用在服务器端渲染&…...

安装存储器的段描述符并加载GDTR
代码清单 ;代码清单12-1;文件名:c12_mbr.asm;文件说明:硬盘主引导扇区代码;创建日期:2011-5-16 19:54;修改于2022-02-16 11:15;设置堆栈段和栈指针mov ax, csmov ss, axmov sp, 0x7c00;计算GDT所在的逻辑段地址12 mov ax, [c…...

2024年5月架构试题
2024年5月份架构师考试真题完整版 截至2024-5-28 19:24:14已全部收录完成 共75道选择题,5道案例题,4道论文题。题目顺序不分先后。 全网最全的2024年5月份架构师考试真题回忆版,包含答案和解析。 选择题 计算机基础 操作系统调度算法 选先来先…...

品牌控价的同时也要做好数据分析
品牌在进行电商价格监测时,确实不应仅停留在收集低价数据的层面。在数据量巨大的今天,如何深度分析和挖掘这些数据的价值,为品牌的决策和战略提供有力支持,显得尤为重要。 首先,电商数据的监测和分析有助于品牌更全面…...
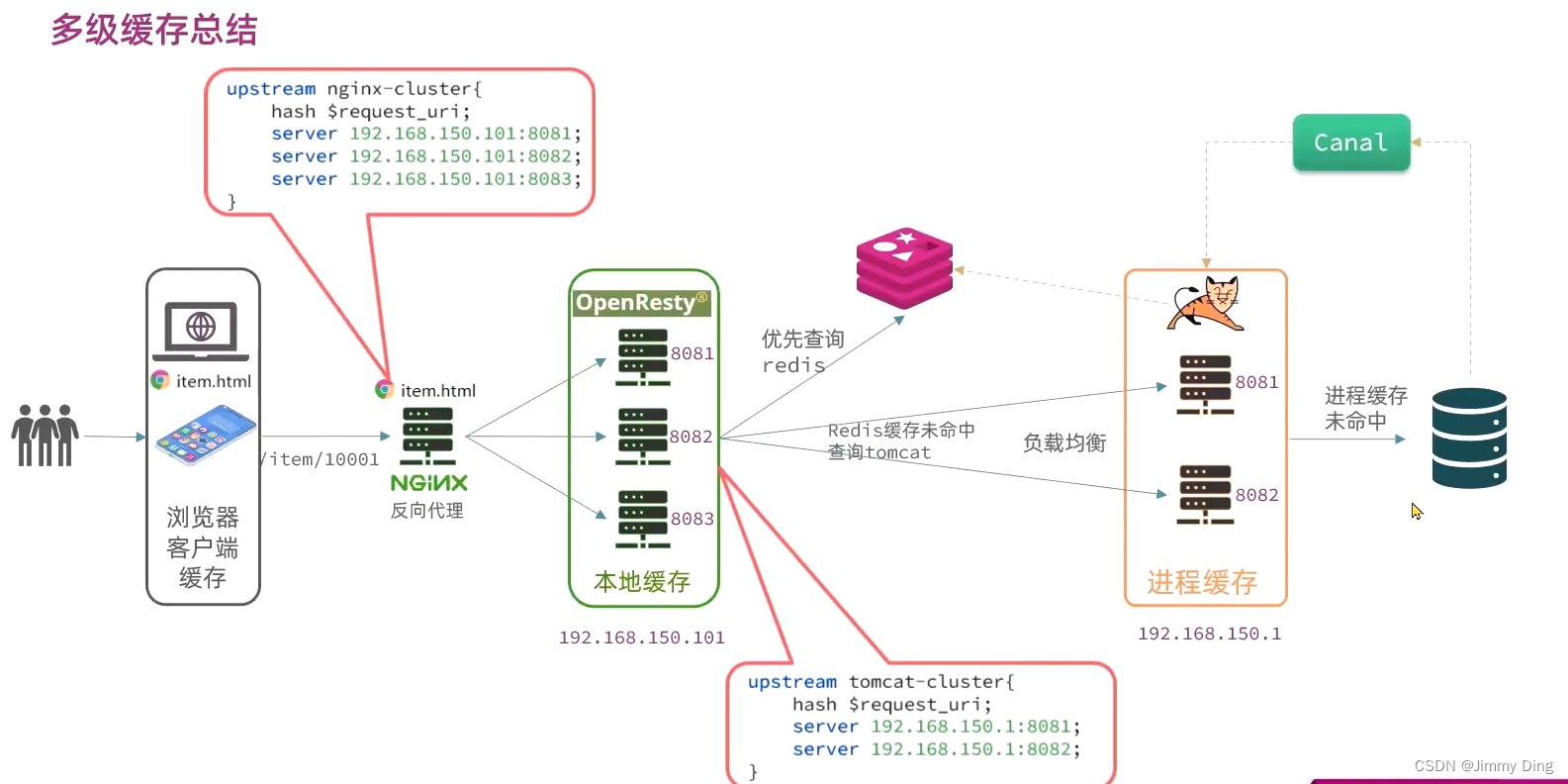
微服务学习Day11-缓存问题学习
文章目录 多级缓存引入JVM进程缓存导入商品案例Caffeine学习实现进程缓存 Lua语法入门认识Lua变量和循环条件控制、函数 多级缓存安装OpenRestyOpenResty入门请求参数处理查询TomcatRedis缓存预热查询Redis缓存Nginx本地缓存 缓存同步策略策略安装Canal监听Canal 多级缓存引入 …...

虚拟化知识学习
虚拟化知识学习 关键概念和术语的简要介绍 虚拟化的基本概念 虚拟机 (VM):一个虚拟机是一个模拟计算机系统的环境。它运行在物理硬件之上,但与物理硬件隔离,提供类似于物理计算机的功能。 虚拟化技术:这是指使用软件来创建虚拟版…...

一键生成迷宫-Word插件-大珩助手新功能
Word大珩助手是一款功能丰富的Office Word插件,旨在提高用户在处理文档时的效率。它具有多种实用的功能,能够帮助用户轻松修改、优化和管理Word文件,从而打造出专业而精美的文档。 【新功能】迷宫生成器 1、可自定义迷宫大小; …...
运维开发详解(上)
🐇明明跟你说过:个人主页 🏅个人专栏:《Linux :从菜鸟到飞鸟的逆袭》🏅 🔖行路有良友,便是天堂🔖 目录 一、引言 1、什么是运维开发 二、运维开发的基础知识 1、运…...

react useState基本使用
1. React Hooks介绍 React Hooks是React 16.8版本引入的新特性,它允许在不编写类的情况下使用state和其他React特性。Hooks的引入极大地简化了组件的编写,使得函数式组件能够拥有类似类组件的功能。 1.1 函数式组件与类组件的区别 函数式组件与类组件…...
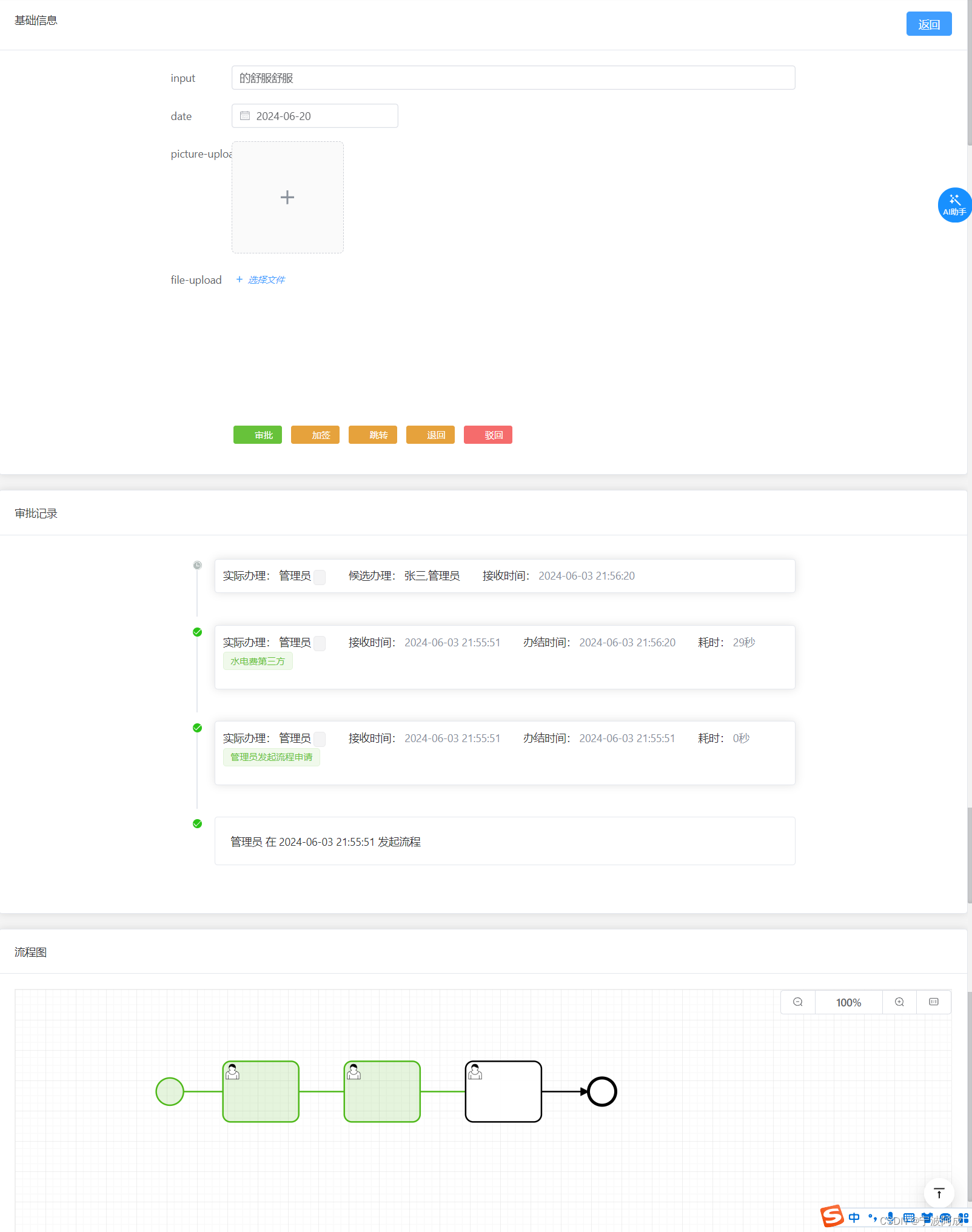
基于jeecgboot-vue3的Flowable流程-待办任务(二)
因为这个项目license问题无法开源,更多技术支持与服务请加入我的知识星球。 接下来讲待办的流程处理 1、根据这个vue3新的框架,按钮代码如下: /*** 操作栏*/function getTableAction(record) {return [{label: 处理,onClick: handleProcess…...

1103. 分糖果 II
1103. 分糖果 II 题目链接:1103. 分糖果 II 代码如下: class Solution { public:vector<int> distributeCandies(int candies, int num_people) {vector<int> res(num_people,0);int count1,i0;//count代表此时对应第i个人需要分得糖果wh…...

别再只用WPF自带的DragDrop了!手把手教你从零封装一个可拖拽合并数据的自定义控件
突破WPF原生拖拽限制:构建高定制化数据合并控件的实战指南 在构建现代企业级桌面应用时,拖拽交互已成为提升用户体验的关键要素。WPF虽然提供了基础的DragDrop API,但当我们需要实现类似看板系统中卡片合并、数据聚合等复杂交互时,…...

Topit窗口置顶效率引擎:重新定义Mac多任务工作流
Topit窗口置顶效率引擎:重新定义Mac多任务工作流 【免费下载链接】Topit Pin any window to the top of your screen / 在Mac上将你的任何窗口强制置顶 项目地址: https://gitcode.com/gh_mirrors/to/Topit 在信息爆炸的时代,我们每天需要处理的窗…...

openclaw行为式AI重构:从昂贵Token到高效对象协作
从昂贵的token消耗到高效的对象协作,重新设计行为式AI的核心架构 问题诊断:为什么当前行为式AI如此“昂贵”? OpenClaw等工具的核心架构依赖生成式大模型作为“大脑”,通过反复的推理-行动循环完成任务。这种设计导致: 高Token消耗的根源 重复的上下文传递:每次循环都需…...

量化交易回测工具革新:backtrader-pyqt-ui让策略开发效率提升10倍的实践指南
量化交易回测工具革新:backtrader-pyqt-ui让策略开发效率提升10倍的实践指南 【免费下载链接】backtrader-pyqt-ui 项目地址: https://gitcode.com/gh_mirrors/bac/backtrader-pyqt-ui backtrader-pyqt-ui是一款将Backtrader量化回测引擎与PyQt图形界面完美…...

OmenSuperHub:暗影精灵游戏本硬件控制的开源革新方案
OmenSuperHub:暗影精灵游戏本硬件控制的开源革新方案 【免费下载链接】OmenSuperHub 使用 WMI BIOS控制性能和风扇速度,自动解除DB功耗限制。 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 一、问题引入:原厂硬件控制软…...

GitHub Desktop汉化终极指南:3步快速完成中文界面配置
GitHub Desktop汉化终极指南:3步快速完成中文界面配置 【免费下载链接】GitHubDesktop2Chinese GithubDesktop语言本地化(汉化)工具 【GitHub桌面客户端中文汉化】 项目地址: https://gitcode.com/gh_mirrors/gi/GitHubDesktop2Chinese 还在为GitHub Desktop…...

最佳论文提名!DancingBox:一台手机,从任意物体捕捉角色动画!
点击下方卡片,关注“CVer”公众号AI/CV重磅干货,第一时间送达点击进入—>【顶会/顶刊】投稿交流群添加微信号:CVer2233,小助手拉你进群!扫描下方二维码,加入CVer学术星球!可以获得最新顶会/顶…...

【硬件分享】PCIE283全高PCIe3.0x8光纤采集卡,XCKU060+双40G光口
分享一款由北京匠行科技推出PCIe283 为标准的全高PCIe 3.0 x8 光纤采集卡。主处理器采用Xilinx Ultrascale系列FPGA XCKU060-FFVA1156I,板卡支持2路QSFP光口,2组 64bit DDR4 、每组容量2GB,预留16路LVDS、32 路LVTTL3.3V。核心配置FPGAXilinx…...

微信聊天记录丢了别慌!3步教你用开源工具找回珍贵回忆
微信聊天记录丢了别慌!3步教你用开源工具找回珍贵回忆 【免费下载链接】WechatBakTool 基于C#的微信PC版聊天记录备份工具,提供图形界面,解密微信数据库并导出聊天记录。 项目地址: https://gitcode.com/gh_mirrors/we/WechatBakTool …...

从Harness工程视角深度解读Claude Code源码,AI编码Agent的工业级实现逻辑
2026年3月底,Anthropic旗下命令行编码Agent工具Claude Code,因npm发布包中的source map文件意外暴露存储在官方R2存储桶内的未混淆源码,让外界首次得以窥见工业级AI Agent系统的真实架构。这份超过51万行TypeScript代码的工程样本,…...