基于聚类和回归分析方法探究蓝莓产量影响因素与预测模型研究
🌟欢迎来到 我的博客 —— 探索技术的无限可能!
🌟博客的简介(文章目录)
目录
- 背景
- 数据说明
- 数据来源
- 思考
- 正文
- 数据预处理
- 数据读取
- 数据预览
- 数据处理
- 相关性分析
- 聚类分析
- 数据处理
- 确定聚类数
- 建立k均值聚类模型
- 多元线性回归模型
- 检测多重共线性
- 主成分分析
- 建立多元线性回归模型
- 残差项检验
- 模型预测
- 随机森林
- 建立模型
- 参数优化
- 模型预测
- 总结
背景
蓝莓在全球范围内备受欢迎,其独特的风味和丰富的营养价值令消费者为之倾倒。蓝莓生长对适宜气候和土壤的依赖,因此主要分布于北美、欧洲、澳洲等地区。
野生蓝莓养殖目前正处于蓬勃发展的阶段,吸引了越来越多的投资者和农户投身其中。全球对健康食品的需求不断增加,野生蓝莓以其天然的营养价值和丰富的抗氧化物质而备受瞩目。然而,养殖野生蓝莓也面临一系列挑战,包括气候不稳定、疾病威胁和市场价格波动。因此,成功的野生蓝莓养殖需要不断的创新和可持续的农业实践,以满足日益增长的全球市场需求。
蓝莓是多年生开花植物,浆果呈蓝色或紫色。它们被归类于越橘属中的蓝越橘科。越橘还包括小红莓、山桑子、胡越橘和马德拉蓝莓。商业蓝莓–野生(低丛)和栽培(高丛)–均原产于北美洲。高丛品种在 20 世纪 30 年代引入欧洲。
蓝莓通常是匍匐灌木,高度从 10 厘米(4 英寸)到 4 米(13 英尺)不等。在蓝莓的商业生产中,生长在低矮灌木丛中、浆果较小、豌豆大小的品种被称为 “低丛蓝莓”(与 "野生 "同义),而生长在较高、栽培灌木丛中、浆果较大的品种被称为 “高丛蓝莓”。加拿大是低丛蓝莓的主要生产国,而美国生产的高丛蓝莓约占全球供应量的 40%。

数据说明
| 字段 | 说明 |
|---|---|
| Clonesize* | 蓝莓克隆平均大小,单位: m 2 m^2 m2 |
| Honeybee | 蜜蜂密度(单位: 蜜蜂 / m 2 / 分钟 蜜蜂/m^2/分钟 蜜蜂/m2/分钟 ) |
| Bumbles | 大型蜜蜂密度(单位: 大型蜜蜂 / m 2 / 分钟 大型蜜蜂/m^2/分钟 大型蜜蜂/m2/分钟 ) |
| Andrena | 安德烈纳蜂密度(单位: 安德烈纳蜂 / m 2 / 分钟 安德烈纳蜂/m^2/分钟 安德烈纳蜂/m2/分钟 ) |
| Osmia | 钥匙蜂密度(单位: 钥匙蜂 / m 2 / 分钟 钥匙蜂/m^2/分钟 钥匙蜂/m2/分钟 ) |
| MaxOfUpperTRange | 花期内最高温带日平均气温的最高记录,单位: ∘ C {^{\circ}C} ∘C |
| MinOfUpperTRange | 花期内最高温带日平均气温的最低记录,单位: ∘ C {^{\circ}C} ∘C |
| AverageOfUpperTRange | 花期内最高温带日平均气温,单位: ∘ C {^{\circ}C} ∘C |
| MaxOfLowerTRange | 花期内最低温带日平均气温的最高记录,单位: ∘ C {^{\circ}C} ∘C |
| MinOfLowerTRange | 花期内最低温带日平均气温的最低记录,单位: ∘ C {^{\circ}C} ∘C |
| AverageOfLowerTRange | 花期内最低温带日平均气温,单位: ∘ C {^{\circ}C} ∘C |
| RainingDays | 花期内降雨量大于 0 的日数总和,单位:天 |
| AverageRainingDays | 花期内降雨日数的平均值,单位:天 |
| fruitset | 果实集 |
| fruitmass | 果实质量 |
| seeds | 种子数 |
注:
Clonesize 表示每个蓝莓克隆株的平均占地面积大小。
蓝莓克隆(Blueberry clone)指的是蓝莓的克隆体。蓝莓繁殖和种植主要有两种方式:
- 种子育种。从蓝莓果实中提取种子,播种育苗。这种方式育出来的蓝莓植株遗传特征会有很大变异。
- 克隆繁殖。选取优良品种蓝莓母株,通过组织培养等焉条繁殖出基因特征高度一致的克隆蓝莓株。这种子植出来的蓝莓园,每个蓝莓株的性状和产量会趋于一致。
所以蓝莓克隆就指的是通过无性繁殖方式培育出来的蓝莓株。整个蓝莓园被同一个蓝莓品种的克隆株占满。
数据来源
https://www.kaggle.com/competitions/playground-series-s3e14/data
思考
蓝莓克隆大小与基因表达、气候条件、土壤特性等因素有关。气温对蓝莓生长有显著影响,尤其在花芽形成和果实发育阶段。降雨对蓝莓生长的影响主要体现在水分管理上。机器学习预测模型在农业领域能够有效预测作物产量、病虫害发生以及土壤属性等。
蓝莓克隆大小相关分析:可以通过统计分析和数据可视化,探讨蓝莓克隆平均大小(Clonesize)与其他因素之间的关系
-
基因表达:研究表明,蓝莓VcLon1基因的表达与植株抗旱性有关。该基因在不同组织中的表达量不同,且干旱条件下其转录水平显著提高,可能与植物适应环境压力的能力有关。
-
气候条件:温度和光照是影响蓝莓生长的关键气象因素。适宜的温度促进根系发展,而充足的日照则有利于光合作用和花芽的形成。
-
土壤特性:土壤pH值对蓝莓的生长至关重要。土壤pH值过高或过低都会限制蓝莓的生长,因此需通过改良土壤来优化蓝莓的生长条件。
-
水分管理:适量的降雨有助于蓝莓生长,但过多则可能导致营养过剩和根系疾病。合理的灌溉策略对于维持蓝莓正常生长周期非常重要。
-
授粉活动:蓝莓的花期授粉活动也会影响果实的产量和质量。蜜蜂等传粉昆虫的活跃度直接影响授粉效率和果实的成熟。
气温与蓝莓生长的关系:可以使用最高温带日平均气温(MaxOfUpperTRange、MinOfUpperTRange、AverageOfUpperTRange)和最低温带日平均气温(MaxOfLowerTRange、MinOfLowerTRange、AverageOfLowerTRange)等气象数据,分析它们与蓝莓果实集(fruitset)、果实质量(fruitmass)以及种子数(seeds)之间的关联
-
生长发育:在一定范围内,气温升高可以促进蓝莓的生长发育。但是,超过最适温度范围会导致生长受阻。
-
花芽形成:适宜的温度有利于花芽的形成,而不恰当的低温可能会造成来年减产。
-
果实发育:较高的温度可以加速果实的发育,使果实更大,成熟期提前。
-
种子发育:变温处理可以提高种子的萌芽率,说明温度波动对蓝莓种子的萌发有积极影响。
-
光合作用:温度对蓝莓叶片的光合作用有显著影响,适宜的温度可以增加CO2吸收率,提高光合效率。
降雨对蓝莓生长的影响:使用降雨数据(RainingDays、AverageRainingDays),可以研究降雨对蓝莓的生长和生产是否有影响
-
水分需求:蓝莓对水分的需求较为严格,过多的降雨会导致营养过剩和果实品质下降。
-
涝害问题:蓝莓不耐涝,持续降雨可能引起根部病害,影响植株健康。
-
灌溉管理:科学的灌溉管理是保证蓝莓良好生长的关键,应根据降雨量和土壤湿度适时调整灌溉计划。
-
果实品质:适度降雨有利于提升蓝莓果实的水溶性总糖含量,改善口感;而过量降雨则会稀释果实中的糖分,降低甜度。
-
枝叶生长:雨水过多时,蓝莓表现出枝叶徒长,这可能会影响光合作用的效率和能量分配。
机器学习预测模型在农业领域的应用:预测蓝莓克隆大小、果实集、果实质量或种子数等目标变量
-
土壤分析优化:利用机器学习模型分析土壤数据,预测土壤质量并提供改进建议,以实现精准施肥和灌溉。
-
病虫害监测防控:结合图像识别技术和预测模型,监测并预测农田中可能发生的病虫害,制定防控方案。
-
收割智能化:应用物体识别技术识别成熟粮食,引入自动化收割装置完成收割,提高效率和减少损失。
-
产量预测模型:通过分析历史数据,建立预测模型预估当前农田的产量,为仓储管理和销售策略提供依据。
-
数据整合决策支持:将不同来源的数据整合,构建全面的信息网络,为农民提供实时的决策支持。
正文
- 数据预处理
- 相关性分析
- 聚类分析
- 回归模型
- 随机森林
数据预处理
数据读取
train_data = pd.read_csv("train.csv")
test_data = pd.read_csv("test.csv")
数据预览
查看训练集和测试集数据维度

查看训练集和测试集数据信息


查看训练集和测试集各列缺失值


查看训练集和测试集重复值

数据处理

相关性分析
绘制热图来可视化相关性

-
产量高度相关变量:fruitset(果实集)、seeds(种子数)和fruitmass(果实质量)与蓝莓产量呈正相关。这些因素在决定蓝莓产量中起关键作用,尤其是fruitset和seeds与产量的相关系数非常高,表明它们对产量有显著影响。
-
蜜蜂密度变量的相关性:与蜜蜂密度相关的变量(如honeybee、bumbles、andrena、osmia)与产量的相关性较低。这表明尽管这些因素对蓝莓授粉有作用,但对最终产量的直接影响可能不如fruitset和seeds显著。
-
气温和降雨量的影响:气温和降雨量相关的变量(如MaxOfUpperTRange、MinOfUpperTRange、RainingDays等)与产量的相关性不高。这可能表明在该数据集中,气温和降雨对蓝莓产量的影响不如果实的生物学特性直接或显著。
-
多重共线性问题:fruitset、seeds和fruitmass之间存在高度相关性,可能导致多重共线性问题。
聚类分析
数据处理
# 选择所有变量进行聚类
x_cluster = train_data.copy()
# 对数据进行标准化
scaler = StandardScaler()
x_scaled = scaler.fit_transform(x_cluster)
确定聚类数
# 使用肘部法则来确定最佳聚类数
inertia = []
silhouette_scores = []
k_range = range(2, 11)
for k in k_range:kmeans = KMeans(n_clusters=k, random_state=10).fit(x_scaled)inertia.append(kmeans.inertia_)silhouette_scores.append(silhouette_score(x_scaled, kmeans.labels_))

图一展示了肘部法则(Elbow Method)的结果,这是一种用于确定聚类数目的方法。在图中,横轴代表聚类数,纵轴代表Inertia(即每个点到其所属聚类中心的距离之和)。从图中可以看出,当聚类数从2增加到3时,Inertia迅速下降;但当聚类数继续增加时,Inertia的下降速率减缓,尤其是在3或4个聚类之后。这表明,虽然增加聚类数可以降低Inertia,但在超过3或4个聚类后,这种降低的速度明显减慢,意味着增加更多聚类数目带来的信息增益较小。
图二展示了轮廓系数(Silhouette Coefficient)的结果,这是另一种评估聚类效果的方法。轮廓系数的值介于-1到1之间,值越大表示聚类效果越好。在图中,横轴代表聚类数,纵轴代表轮廓系数。最高的轮廓系数出现在2个聚类的时候,但随着聚类数的增加,轮廓系数迅速下降,并在4个聚类后稳定下来。
结合两个图的结果,可以得出以下结论:
- 肘部法则表明3或4个聚类可能是一个合适的聚类数,因为在这个点之后,Inertia的下降速率明显减慢。
- 轮廓系数图表明,虽然2个聚类的轮廓系数最高,但随着聚类数的增加,轮廓系数迅速下降,并在4个聚类后稳定下来。
综合考虑这两个指标,选择4个聚类作为最终的聚类数目是合理的。尽管2个聚类的轮廓系数最高,但从肘部法则来看,3或4个聚类能够提供更加细分的聚类,且Inertia下降率变缓,意味着增加更多聚类数目带来的信息增益较小。因此,选择4个聚类可以在保持较高轮廓系数的同时,获得更细致的聚类结果。
建立k均值聚类模型
执行K-均值聚类选择4个聚类,获取聚类标签,将聚类标签添加到原始数据中以进行分析

聚类分析结果
聚类0
- 特征: 平均克隆大小最小,蜜蜂密度最低,但有最高的钥匙蜂密度,气温范围适中,降雨天数最少。
- 果实与产量: 果实集、果实质量和种子数都很高,产量最高。
- 推测: 在较干燥和凉爽的环境中,通过优化克隆大小和蜜蜂密度可能能获得高产量。
聚类1
- 特征: 克隆大小和蜜蜂密度较高,气温范围最高,降雨天数最多。
- 果实与产量: 果实集、果实质量和种子数相对最低,产量最低。
- 推测: 过高的温度和过多的降雨对蓝莓的生产不利。
聚类2
- 特征: 拥有较小的克隆大小,蜜蜂密度相对较低,气温范围高,降雨天数较少。
- 果实与产量: 果实集、果实质量和种子数最高,产量也非常高。
- 推测: 在较热和较干燥的条件下,即使蜜蜂密度不高,也能获得高产量。
聚类3
- 特征: 具有较大的克隆大小和较高的蜜蜂密度,气温范围和降雨天数适中。
- 果实与产量: 果实集和种子数介于中等至较高,果实质量相对较低,产量中等。
- 推测: 这可能是一个相对平衡的种植环境,适合保持稳定的产量。
结论
通过对四个聚类的特征和产量分析,我们可以得出以下结论:
-
环境影响: 温度和降雨量对蓝莓产量有显著影响。
聚类0和聚类2具有相似的果实特性和产量,但聚类0的气温范围较低,降雨天数少,表明在较干燥和凉爽的环境中,通过优化克隆大小和蜜蜂密度可能能获得高产量。
聚类1在所有聚类中气温范围最高且降雨最多,但产量最低,这可能说明过高的温度和过多的降雨对蓝莓的生产不利。 -
蜜蜂密度: 蜜蜂密度对授粉有重要作用,但其影响可能受到其他因素如克隆大小和环境条件的调节。
聚类3有着适中的气温和降雨,较大的克隆大小和高蜜蜂密度,其产量和果实质量表明这可能是一个相对平衡的种植环境。 -
种植策略: 为了优化产量,应根据具体的气候和土壤条件调整克隆大小和蜜蜂密度。例如,在较凉爽和干燥的地区,可能需要较小的克隆和更高的钥匙蜂密度。
-
未来研究: 进一步的研究应关注如何在不同环境条件下优化这些变量,以及如何通过选择适宜的品种和管理实践来提高蓝莓的产量和质量。
多元线性回归模型
检测多重共线性
使用除了产量以外的所有列作为特征,并计算每个特征的VIF值

高VIF值通常意味着相关变量之间存在强烈的线性关系,这可能会影响线性回归模型的准确性和稳定性。在这种情况下,可以采取主成分分析来处理多重共线性。
在统计学和机器学习领域,线性回归模型通过拟合一个线性方程来描述自变量(解释变量)与因变量(响应变量)之间的关系。然而,数据集中的两个或多个解释变量之间的高度相关性会导致多重共线性现象。这种现象会扭曲模型的回归系数估计,增大标准误差,降低模型的稳定性和预测准确性。高VIF值揭示了模型中某些解释变量之间的相关性过高,这些变量相互之间可以在一定程度上互相替代,从而使得单独的变量影响力难以准确估计。此外,这种高度相关性会增加回归系数的方差,使模型对样本数据的微小变化非常敏感,即模型的稳定性下降。多重共线性还可能导致本应显著的变量未能显示出显著性,或者导致回归系数的符号与理论预期相反,从而误导结论的解释。
针对多重共线性的问题,主成分分析(PCA)提供了一种有效的解决方案。PCA通过将原始数据转换成一组线性不相关的新变量(即主成分),在保留大部分原始信息的同时降低了数据的维度。这种方法减少了变量之间的多重共线性,提高了模型的解释能力和预测准确性。
逐步回归法、增加样本容量、引入正则化项(如岭回归)等方法也可以用来处理多重共线性。逐步回归法通过逐步添加或移除变量来选择最终的模型,有助于减少变量之间的多重共线性。虽然增加样本容量有时也能有效缓解多重共线性的影响,但这通常难以实现。引入正则化项的岭回归则通过牺牲一部分偏差来减少方差的波动,提升模型的稳定性和可靠性。
高VIF值所指示的多重共线性问题是线性回归模型中不容忽视的问题。通过采用主成分分析以及其他一系列方法,可以有效解决这一问题,提高模型的稳定性和预测能力。这对于构建更加可靠、准确的预测模型具有重要意义。
主成分分析
对数据进行标准化处理,然后使用PCA类对标准化后的数据进行主成分分析,计算主成分的方差贡献率


因为前7项的特征已经达到了95%以上的贡献率,所以选择前7项进行建模。
建立多元线性回归模型
使用前7个主成分作为特征集,由于PCA是无监督的,我们需要重新获取目标变量’y’。接着,将数据集分割为训练集和测试集(3 7分)。最后,创建一个多元线性回归模型,并使用训练数据对其进行拟合。
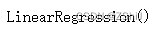
预测测试数据并计算模型性能指标

残差项检验
# 计算残差
residuals = y_test - y_pred
绘制残差序列图

残差在零线周围波动,没有显示出明显的趋势或周期性模式,看起来是随机分布的,可以认为残差项具有独立性,这意味着模型的每个预测值的误差是独立的,没有显示出依赖于其他预测值的误差,符合模型的假设,随机误差项是独立的。
在线性回归分析中,残差是观察值与模型预测值之间的差异。如果残差在零线周围波动,没有明显的趋势或周期性模式,并且看起来像是随机分布的,那么这通常被认为是一个积极的迹象。它表明模型没有遗漏任何重要的变量或关系,也表明模型的误差项是独立的,这是线性回归模型的一个基本假设。
当残差项具有独立性时,这意味着模型的每个预测值的误差是独立的,没有显示出依赖于其他预测值的误差。这是一个理想的情况,因为它意味着我们的模型能够捕捉到数据中的大部分信息,而剩下的只是随机噪音,这些噪音是由于我们无法解释或控制的因素造成的。
如果残差项不具有独立性,那么我们的模型可能存在问题。例如,如果残差显示出明显的趋势或周期性模式,那么这可能意味着我们的模型遗漏了一个重要的变量或关系,或者我们的模型形式不正确。在这种情况下,我们可能需要重新审查我们的模型,寻找可能的遗漏变量或关系,或者尝试使用不同的模型形式。
绘制残差的直方图 和 残差的Q-Q图

直方图:残差的分布看起来接近于正态分布,但似乎在中心附近稍微偏离,这可能表明残差分布略微偏斜。
Q-Q图:大多数点似乎沿着直线排列,这表明残差的分布接近正态分布。然而,图的两端有一些点偏离直线,这可能表明残差在尾部有一些偏离正态分布。
综合来看,残差大致呈正态分布,但存在轻微的偏差。这种偏差在实际应用中是常见的,尤其是当样本量较大时。尽管存在一些偏离,模型的残差还是在很大程度上符合正态分布的假设。
绘制残差与预测值的散点图以检查同方差性

在理想情况下,如果满足同方差性假设,残差应该随机分布在水平线(红色线)周围,没有任何明显的模式。例如,残差不应该随着预测值的增加而系统地增大或减小,也不应该呈现出漏斗形状。
从图中可以看出来:残差在不同的预测值水平上是随机分布的,没有明显的趋势,也没有漏斗状的分布模式,可以认为残差满足同方差性的假设。
模型预测
使用与训练模型时相同数量的主成分进行预测

在建立多元线性回归模型中,主要针对多重共线性的特征采用主成分分析降维,再对训练集进行建模,得到了模型的均方误差和决定系数,并且对模型进行了检验,发现符合多元线性回归模型的假设,即:随机误差项独立,同方差,符合正态分布,最后通过该模型对测试集进行预测,得到预测结果。
随机森林
建立模型
划分数据集(3 7分)并建立随机森林回归模型,,并使用训练集对其进行拟合。

使用随机森林回归模型对测试数据进行预测,得到预测结果。然后计算均方误差(MSE)和R平方(R2)作为模型性能指标

参数优化
# 定义随机搜索的参数范围
param_dist = {'n_estimators': [100, 200, 300, 400, 500],'max_depth': [10, 20, 30, 40, 50, None],'min_samples_split': [2, 5, 10],'min_samples_leaf': [1, 2, 4],'max_features': ['auto', 'sqrt']
}# 创建随机森林模型
rf = RandomForestRegressor(random_state=15)# 设置随机搜索
random_search = RandomizedSearchCV(estimator=rf, param_distributions=param_dist, n_iter=10, cv=5, verbose=2, random_state=17, n_jobs=-1)# 执行随机搜索
random_search.fit(x_train, y_train)

随机搜索比网格搜索快,所以这里使用随机搜索。
最佳参数和评分:

使用最佳参数创建随机森林模型,并对其进行训练和预测。最后计算出的均方误差(MSE)和R平方(R2)来评估模型的性能:

# 获取特征重要性
feature_importances = best_rf_model.feature_importances_
# 创建特征重要性的DataFrame
features = x_train.columns
importances_df = pd.DataFrame({'Feature': features, 'Importance': feature_importances})
# 按重要性排序
importances_df.sort_values(by='Importance', ascending=False, inplace=True)
importances_df

这表明果实集(fruitset)是最重要的特征,可能是因为:果实集是产量形成的直接因素。如果果实集比率高,意味着更多的花朵被成功受粉并开始形成果实,最终导致更高的产量,与相关性分析得到的结果一致,果实集对产量具有高强度正相关。
模型预测
使用训练好的模型对测试数据进行预测

在建立随机森林模型时候,主要采用的是回归模型,与分类模型有一些差异,随机森林模型具有高准确性、抗过拟合、较好的鲁棒性,所以这里也选择用随机森林模型进行预测,并且通过随机搜索后,选择了参数范围内的最优参数,优化后的随机森林模型在均方误差和绝对系数上都优于多元线性回归模型,最后采用优化后的随机森林模型预测测试集。
总结
本项目主要采用了三个模型:
- k均值聚类模型
- 多元线性回归模型
- 随机森林模型
在数据分析项目中,选择合适的模型是至关重要的。本项目中,我们采用了三种不同的模型来分析蓝莓的生长条件和产量,以确保从不同角度全面理解数据。
一、K均值聚类模型
K均值聚类模型是一种无监督学习方法,用于根据数据的相似性将样本分成不同的组。在这个项目中,我们使用K均值聚类模型来识别具有相似特征的蓝莓品种。通过聚类分析,我们将蓝莓分为4个类别,每个类别代表了不同的生长条件和产量特性。这种分类有助于我们理解在不同环境条件下,哪些因素对蓝莓产量有显著影响。
二、多元线性回归模型
多元线性回归模型是一种监督学习方法,它假设一个依赖变量(在这里是产量)与一个或多个独立变量(如气温、降雨天数等)之间存在线性关系。通过对这些变量进行相关性分析,我们发现产量与其他变量之间确实存在线性关系。然而,由于自变量之间存在多重共线性,我们采用主成分分析(PCA)进行降维处理。虽然这样做降低了模型的可解释性,但它提高了预测模型的准确性。最后,我们通过残差项检验验证了模型的有效性,确保了随机误差项符合基本假设,模型比较好。
三、随机森林模型
随机森林模型是一种集成学习方法,它通过构建多个决策树并进行投票或平均来提高模型的预测准确性。在这个项目中,我们使用随机森林模型来预测蓝莓的产量。尽管随机森林模型的解释性不如线性模型,但其预测准确性通常更高。在优化前后的比较中,我们发现优化后的随机森林模型比多元线性回归模型具有更好的性能。此外,模型还揭示了“果实集”是最重要的特征之一,这与相关性分析的结果一致,表明果实集对产量有显著的正面影响。
总结
通过结合这三种模型,我们不仅从不同角度分析了影响蓝莓产量的因素,而且还识别出了重要的生长条件和特征。K均值聚类模型帮助我们理解了不同种类蓝莓的特性;多元线性回归模型提供了对影响因素线性关系的见解;而随机森林模型则提供了一种准确预测蓝莓产量的方法。这种多模型方法为我们提供了一个全面的分析框架,使我们能够更深入地理解数据,并为提高蓝莓产量提供科学的建议。
相关文章:
基于聚类和回归分析方法探究蓝莓产量影响因素与预测模型研究
🌟欢迎来到 我的博客 —— 探索技术的无限可能! 🌟博客的简介(文章目录) 目录 背景数据说明数据来源思考 正文数据预处理数据读取数据预览数据处理 相关性分析聚类分析数据处理确定聚类数建立k均值聚类模型 多元线性回…...

【数据结构】从前序与中序遍历,或中序与后序遍历序列,构造二叉树
欢迎浏览高耳机的博客 希望我们彼此都有更好的收获 感谢三连支持! 首先,根据先序遍历可以确定根节点E,再在中序遍历中通过E确定左树和右数 ; 设立inBegin和inEnd,通过这两个参数的游走,来进行子树的创建&a…...

ARM公司发展历程
Arm从1990年成立前开始,历经漫长岁月树立各项公司里程碑及产品成就,一步步成为全球最普及的运算平台。 添加图片注释,不超过 140 字(可选) Acorn 时期 1978年,Chris Curry和Hermann Hauser共同创立了Acorn…...

C# :IQueryable IEnumerable
文章目录 1. IEnumerable2. IQueryable3. LINQ to SQL4. IEnumerable & IQueryable4.1 Expression4.2 Provider 1. IEnumerable namespace System.Collections: public interface IEnumerable {public IEnumerator GetEnumerator (); }public interface IEnumerator {pubi…...

三、生成RPM包
文章目录 1、编译生成so、bin 通过此工程编译生成so\bin文件 2、将so\bin打包到rpm中 ###### 1.生成可执行文件、库文件 ######### cmake_minimum_required(VERSION 3.15)project(compute) set(target zls_bin) set(target2 libcompute.so) # 依赖的头文件 include_directori…...

单实例11.2.0.4迁移到11.2.0.4RAC_使用rman异机恢复
保命法则:先备份再操作,磁盘空间紧张无法备份就让满足,给自己留退路。 场景说明: 1.本文档的环境为同平台、不同版本(操作系统版本可以不同,数据库版本相同),源机器和目标机器部分…...
)
MySQL之查询性能优化(二)
查询性能优化 慢查询基础:优化数据访问 查询性能低下最基本的原因是访问的数据太多。某些查询可能不可避免地需要筛选大量数据,但这并不场景。大部分性能低下的查询都可以通过减少访问的数据量的方式进行优化。对于低效的查询,我们发现通过下面两个步骤…...

The Best Toolkit 最好用的工具集
The Best Toolkit 工欲善其事,必先利其器,整理过往工作与生活中遇到的最好的工具软件 PDF合并等 PDF24 Tools PDF查看器 SumatraPDF 可以使用黑色来查看,相对不伤眼睛,也有电子书相关的阅读器 Kindle pdf裁边工具 briss 软件卸载…...
类型)
使用C#反射中的MAKEGENERICTYPE函数,来为泛型方法和泛型类指定(泛型的)类型
MakeGenericType 是一个在 C# 中用于创建开放类型的实例的方法。开放类型是一种未绑定类型参数的泛型类型。当你有一个泛型类型定义,并且想要用特定的类型实例化它时,你可以使用 MakeGenericType 方法。 public Type MakeGenericType (params Type[] ty…...

sql注入 (运用sqlmap解题)
注:level参数 使用–batch参数可指定payload测试复杂等级。共有五个级别,从1-5,默认值为1。等级越高,测试的payload越复杂,当使用默认等级注入不出来时,可以尝试使用–level来提高测试等级。 --level 参数决定了 sql…...

HTML5 Canvas 绘图教程二
在本教程中,我们将探讨 canvas 的高级用法,包括复杂的绘图 API、坐标系统和变换操作、平滑动画技术以及复杂应用和游戏开发的实践。 1. 绘图 API 高级方法 1.1 二次贝塞尔曲线 (quadraticCurveTo) 二次贝塞尔曲线需要两个点:一个控制点和一…...

Linux 命令 find 的深度解析与使用
Linux 命令 find 的深度解析与使用 在 Linux 系统中,find 命令是一个功能强大的工具,用于在文件系统中搜索文件或目录。无论是基于文件名、文件类型、文件大小、文件权限,还是基于文件的最后修改时间等,find 命令都能提供灵活的搜…...

字符串操作记录
1 拼接 Concat():拼接字符串 Let stringvalue “hello ”; Let result stringvalue.concat(“world”) Console.log(result) // “hello world” 2 删 Let stringvalue “hello world”Console.log(stringvalue.slice(3)); // ‘lo world’Console.log(stringvalue.subst…...

【python科学文献计量】关于中国知网检索策略的验证,以事故伤害严重程度检索为例
关于中国知网检索策略的验证,以事故伤害严重程度检索为例 1 背景2 文献下载3 数据处理1 背景 由于要进行相关研究内容的综述,需要了解当前我国对于事故伤害严重程度的研究现状,采用国内较为知名的检索网站(中国知网)进行文献数据集检索 由于最近知网出bug,检索的结果在…...

AdminController
目录 1、 AdminController 1.1、 UpdateFaculty 1.1.1、 // Check if a new image file is provided 1.1.2、 // CHECKING FOLDER EXIST OR NOT - IF NOT THEN CREATE F0LDER 1.1.3、 // READY SEND PATH TO IMAGE TO DB 1.1.4、 DeleteFaculty 1.1.5、 // If th…...

Vue3-Pinia状态管理器
Pinia 是 Vue 的专属状态管理库,它允许你跨组件或页面共享状态。如果你熟悉组合式 API 的话,你可能会认为可以通过一行简单的 export const state reactive({}) 来共享一个全局状态。对于单页应用来说确实可以,但如果应用在服务器端渲染&…...

安装存储器的段描述符并加载GDTR
代码清单 ;代码清单12-1;文件名:c12_mbr.asm;文件说明:硬盘主引导扇区代码;创建日期:2011-5-16 19:54;修改于2022-02-16 11:15;设置堆栈段和栈指针mov ax, csmov ss, axmov sp, 0x7c00;计算GDT所在的逻辑段地址12 mov ax, [c…...

2024年5月架构试题
2024年5月份架构师考试真题完整版 截至2024-5-28 19:24:14已全部收录完成 共75道选择题,5道案例题,4道论文题。题目顺序不分先后。 全网最全的2024年5月份架构师考试真题回忆版,包含答案和解析。 选择题 计算机基础 操作系统调度算法 选先来先…...

品牌控价的同时也要做好数据分析
品牌在进行电商价格监测时,确实不应仅停留在收集低价数据的层面。在数据量巨大的今天,如何深度分析和挖掘这些数据的价值,为品牌的决策和战略提供有力支持,显得尤为重要。 首先,电商数据的监测和分析有助于品牌更全面…...
微服务学习Day11-缓存问题学习
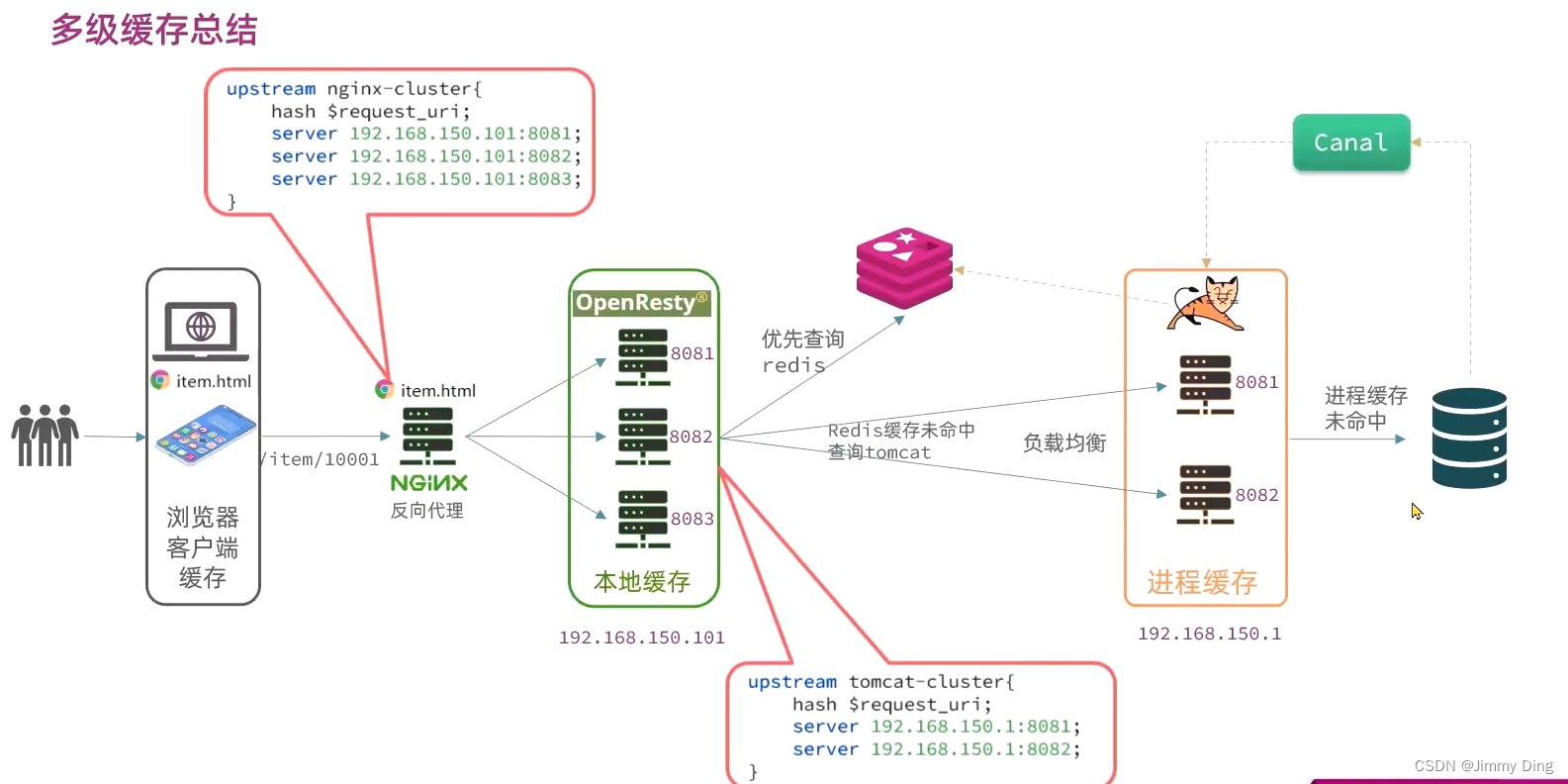
文章目录 多级缓存引入JVM进程缓存导入商品案例Caffeine学习实现进程缓存 Lua语法入门认识Lua变量和循环条件控制、函数 多级缓存安装OpenRestyOpenResty入门请求参数处理查询TomcatRedis缓存预热查询Redis缓存Nginx本地缓存 缓存同步策略策略安装Canal监听Canal 多级缓存引入 …...

Brax环境封装指南:无缝集成Gym和DM_Env接口
Brax环境封装指南:无缝集成Gym和DM_Env接口 【免费下载链接】brax Massively parallel rigidbody physics simulation on accelerator hardware. 项目地址: https://gitcode.com/gh_mirrors/br/brax Brax是一个基于JAX的高性能物理模拟引擎,专为强…...

OpenClaw飞书机器人实战:Qwen2.5-VL-7B多模态对话配置
OpenClaw飞书机器人实战:Qwen2.5-VL-7B多模态对话配置 1. 为什么选择OpenClaw飞书Qwen2.5-VL组合 去年我们团队内部沟通量激增,每天在飞书群里有数百条消息需要处理——从产品需求讨论到技术方案评审,再到会议纪要整理。最头疼的是那些包含…...

提升嵌入式开发效率:用快马平台一键生成串口通信等常用模块代码
作为一名嵌入式开发者,我经常需要和串口通信打交道。无论是调试信息输出、设备间通信还是固件升级,UART都是最常用的外设之一。但每次新项目都要重新写一遍串口初始化、中断处理这些重复性代码,实在有点浪费时间。最近发现InsCode(快马)平台能…...

SOA和微服务比较详解
SOA 与微服务架构深度比较 面向服务架构(SOA)和微服务架构(Microservices)都是将系统拆分为可独立部署的服务单元的设计风格,但它们在粒度、通信方式、数据管理、治理、适用场景等方面存在本质差异。系统分析师需要根据业务需求、团队能力和技术栈选择适合的架构。 一、定…...

突破传统切片限制:Excel驱动的GCode设计革命
突破传统切片限制:Excel驱动的GCode设计革命 【免费下载链接】FullControl-GCode-Designer Software for designing GCODE for 3D printing 项目地址: https://gitcode.com/gh_mirrors/fu/FullControl-GCode-Designer 在3D打印领域,GCode设计和参…...

聚焦AI专著生成:热门工具大盘点,满足不同写作需求
创新是学术专著的核心,也是写作过程中最重要的挑战。一本优秀的专著,不仅仅是将已有的研究成果拼凑在一起,而是需要提出贯穿整个作品的独到见解、理论框架或研究方法。在浩如烟海的学术文献面前,发掘尚未被触及的研究空白并不简单…...

HunyuanVideo-Foley部署教程:vSphere虚拟机中GPU直通RTX4090D配置指南
HunyuanVideo-Foley部署教程:vSphere虚拟机中GPU直通RTX4090D配置指南 1. 环境准备与硬件要求 1.1 硬件配置清单 显卡:RTX 4090D 24GB显存(必须)CPU:10核及以上(推荐Intel Xeon或AMD EPYC)内…...

3步解锁网盘直链:LinkSwift八大平台高速下载完全指南
3步解锁网盘直链:LinkSwift八大平台高速下载完全指南 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云…...

新手友好!FUTURE POLICE语音解构模型快速入门:搭建智能音频处理流水线
新手友好!FUTURE POLICE语音解构模型快速入门:搭建智能音频处理流水线 1. 认识FUTURE POLICE语音解构模型 1.1 什么是语音解构技术 想象一下,你有一段会议录音,想要快速找到某个关键词出现的确切时间点。传统语音识别只能告诉你…...

Lepton AI与FastAPI集成:构建高性能AI API服务的终极指南
Lepton AI与FastAPI集成:构建高性能AI API服务的终极指南 【免费下载链接】leptonai A Pythonic framework to simplify AI service building 项目地址: https://gitcode.com/gh_mirrors/le/leptonai Lepton AI是一个Pythonic框架,专门用于简化AI…...