MySQL(四) - SQL优化
一、SQL执行流程
MySQL是客户端-服务器的模式。一条SQL的执行流程如下:
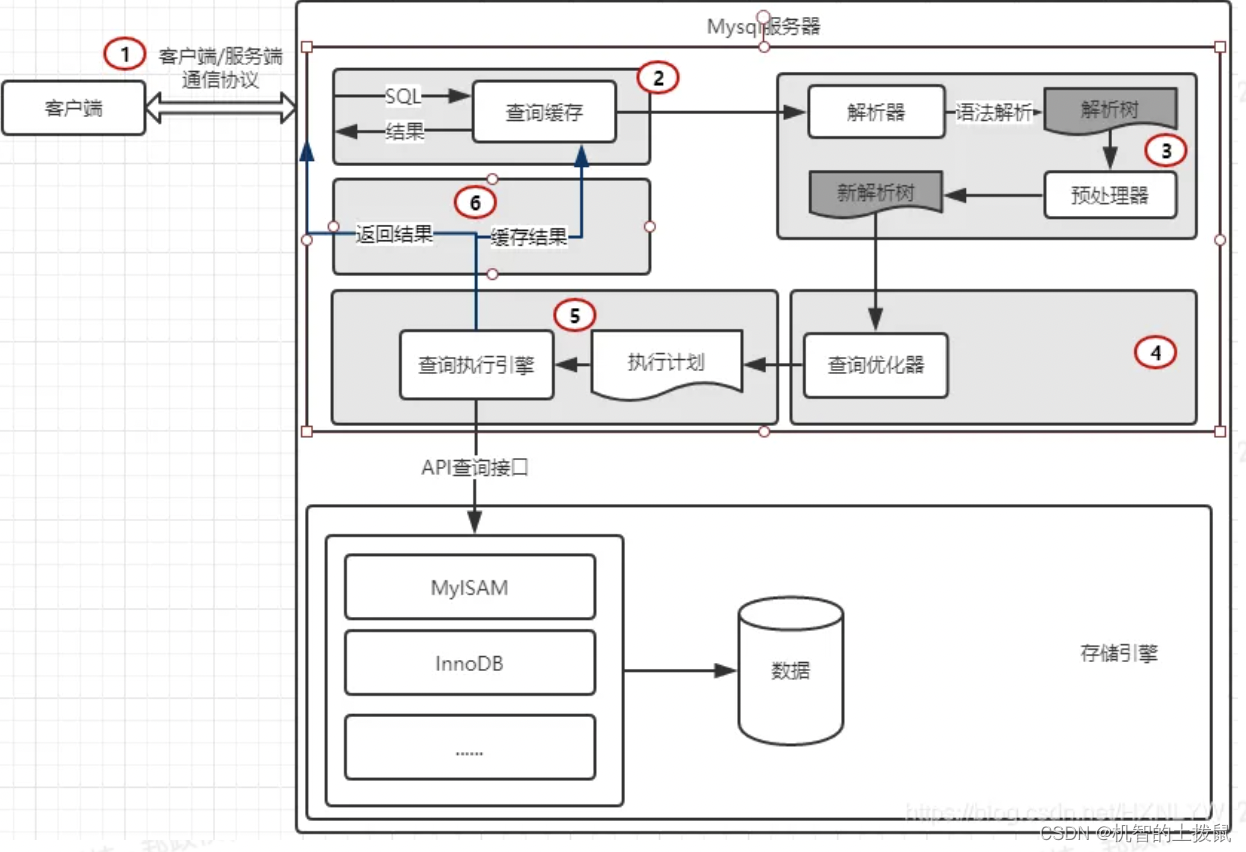
在执行过程中,主要有三类角色:客户端、服务器、存储引擎。
大致可以分为三层:
第一层:客户端连接到服务器,构造SQL并发送给服务器。
第二层:服务器收到SQL进行解析及优化,最终生成执行计划并执行
第三层:服务器调用存储引擎的API,进行数据的查询和存储。
上述的查询缓存,在MySQL8.0版本后移出,原因是不太实用,对表进行修改操作后,需要进行删除缓存并重新添加,对于一些写并不频繁的表还好,但市面上还有一些更加实用做缓存的工具,因此这个功能比较尴尬。
二、执行计划分析
可以通过explain提前知道当前MySQL是如何处理SQL语句的。
在我们要执行的SQL前加上explain即可。
explain select * from user;explain insert into user values(user_name, password, email) values('1', '1', '1');通过分析执行计划,我们可以得出以下几点:
1.表的读取顺序 -> id
2.表读取操作的类型 -> select_type
3.可以被使用的索引 -> possible_keys
4.实际使用的索引 -> key
5.表之间的引用 -> ref
6.每张表有多少行被优化器查询 -> rows
上述查询结果字段的含义:
1.id:表示查询中执行select子句或操作表的顺序,id越大,执行优先级越高,id相同,则从上至下
2.select_type:表示查询的类型,用来区分普通查询、联合查询、子查询等。一共有9种类型。
3.table: 输出行所引用的表名,如果使用了别名则显示别名
4.partitions:使用的哪个分区
5.type:查询使用了那种类型。描述的是当前如何去找数据的,如:all 表示扫描全表。
6.possible_keys:可能有助于查询的索引
7.key:实际使用的索引
8.key_len: 使用的索引的长度
9.ref:显示索引的哪一列被使用了
10.rows:请求数据大概返回的行数
11.filtered:表示存储引擎返回的数据在server层过滤后,剩下多少满足查询的记录数量的比例
12.extra: 其他信息,出现Using filesort、Using temporary 意味着不能使用索引,效率会受到重大影响。应尽可能对此进行优化。
其中比较重要的字段:
1.type:可以看出是如何查询数据的方式。一般需要达到 ref、eq_ref 级别,范围查找需要达到 range。
2.key:是否使用索引,如果为NULL表示没有使用索引,需要优化调整。
3.rows:表示返回的行数,可以直观观察到结果。
4.extra:有Using filesort、Using temporary 的一定需要优化。
三、表结构优化
数据库效率的影响主要是因为数据量太大,进行一次查找需要扫描很多数据(硬盘上的磁头需要越过很多数据来找到目标数据),通过表结构优化的方式可以减轻当前访问的数据量。
3.1 数据类型优化
主旨就是能用小字段类型就不用大字段类型~
- 使用简单的数据类型。int 要比 varchar 类型在mysql处理简单
- 尽量使用 tinyint、smallint、mediumint 作为整数类型而非 int
- 尽可能使用 not null 定义字段,因为 null 占用4字节空间。数字可以默认0,字符串默认“”
- 尽量少用 text 类型,非用不可时最好考虑分表
- 尽量使用 timestamp而非 datetime
- 单表不要有太多字段,建议在 20 以内
3.2 分库分表优化
当数据太多的时候,即使走索引啥的也不能解决效率问题,根本就在于要扫描的数据太多了,并且存储也是比较难的。
这时候就可以采用分表的方式,将一张表拆分成多张,然后通过编号等手段进行查询。
拆分大致也有两种方式:
垂直拆分:
按照列的维度,将表中的列拆分开来,分别放在多张表中。例如:某些字段在一张表中可能更加平凡的查询,可以将这些字段放到一张表中,不常用的放在另一张表中。
但需要注意的是,这种方式需要保证原子性!可以在进行插入的时候使用事务~
水平拆分:
按照行的维度,将一张表的数据切分。如0-100的数据放在这张表中,101-200的数据放在另一张表中。
3.3 读写分离优化
由于一台数据库服务器的性能肯定是有瓶颈的,可以进行部署一个数据库集群。并采用主从的方式。设置一些主库,一些从库,主库用来负责写入数据,从库用来负责读取数据,当一个新的数据写入的时候,主库需要将数据同步到从库中,以保证数据的完整性。
四、查询语句优化
4.1避免使用 select *
sql在解析过程中,还需要把*依次转换为所有的列名,这个工作需要查询数据字典完成。额外开销!因此建议将需要的列写出来。
4.2多表联查时,小表在前,大表在后
from 后的表关联查询是从左往右执行的(Oracle相反),第一张表会涉及到全表扫描,所以将小表放在前面,先扫小表,扫描快效率较高,在扫描后面的大表。
4.3调整where子句中的连接顺序
where子句是从左往右,自上而下的顺序执行的(Oracle相反),根据这个原理,应将过滤数据多的条件往前放,最快速度缩小结果集。
4.4调整group by和order by子句中的顺序
group by和order by子句是从左往右的顺序执行的,根据这个原理,应将排序影响数据多的条件往前放,最快速度缩小结果集。
4.5用exists、not exists和in、not in相互替代
exists以外层表为驱动表,先被访问,适合于外表小而内表大的情况。
in则是先执行子查询,适合外表大而内表小的情况,一般情况是不推荐使用not in,因为效率非常低。
原则是哪个的子查询产生的结果集小,就选哪个
4.6用where子句替换having子句
where子句搜索条件在进行分组操作之前应用;而having子句条件在进行分组操作之后应用。
尽可能让where来缩小结果集!
4.7分段和分页查询
使用合理的分页方式,在数据表量级逐渐增加的时候,limit分页查询的效率会降低。
可以根据字段索引进行快速定位,直接找到偏移量。
五、索引优化
众所周知,索引是通过牺牲空间来换取时间的。当我们频繁的去进行插入/删除的时候,会影响性能,因此索引更适合于“读多写少”的场景。
索引可以帮助我们提高查询效率,因此需要避免索引失效的场景。
5.1尽量避免在字段开头模糊查询
select * from user where user_name like '%陈%'; -不走索引
select * from user where user_name like '陈%'; -走索引5.2尽量避免使用not in和in
如果是连续数值,可以用between代替
select * from user id in(1,2); -不走索引
select * from user id between 1 and 2; -走索引如果是子查询,可以用exists代替
select * from A where A.id in (select id from B); -- 不走索引
select * from A where exists (select * from B where B.id = A.id); -- 走索引5.3尽量避免使用or或in
SELECT * FROM t WHERE id = 1 OR id = 3; -- 不走索引
SELECT * FROM t WHERE id in (1, 3); -- 不走索引
SELECT * FROM t WHERE id = 1UNION
SELECT * FROM t WHERE id = 3; -- 走索引5.4尽量避免查询条件使用用!=或者<>
5.5尽量避免进行null值的判断
优化方式:可以给字段添加默认值,0,对0值进行判断.
SELECT * FROM t WHERE score IS NULL; -- 不走索引
SELECT * FROM t WHERE score = 0; -- 走索引5.6尽量避免在where条件中等号的左侧进行表达式、函数操作
SELECT * FROM T WHERE score/10 = 9; -- 不走索引
SELECT * FROM T WHERE score = 9*10; -- 走索引5.7尽量避免隐式数据类型转换
有些字符串可以自动转换为数字类型,可以避免转换
5.8尽量避免使用复合索引时,不使用第一个索引列
复合(联合)索引包含key1,key2,key3三列,SQL语句没有包含索引前置列"key1"
select col1 from table where key2=2 and key3=3; -- 不走索引
select col1 from table where key1=1 and key2=2 and key3=3; -- 走索引5.9order by 条件要与where中条件一致,否则order by不会利用索引进行排序
SELECT * FROM t order by age; -- 不走age索引
SELECT * FROM t where age > 0 order by age; -- 走age索引当order by 中的字段出现在where条件中时,才会利用索引而不再二次排序,更准确的说,order by 中的字段在执行计划中利用了索引时,不用排序操作。
相关文章:

MySQL(四) - SQL优化
一、SQL执行流程 MySQL是客户端-服务器的模式。一条SQL的执行流程如下: 在执行过程中,主要有三类角色:客户端、服务器、存储引擎。 大致可以分为三层: 第一层:客户端连接到服务器,构造SQL并发送给服务器…...

用 DataGridView 控件显示数据
使用DataGridView,可以很方便显示数据。 1.为解决方案添加数据集XSD,用作为项目数据源。 2.拖DataGridView控件到WinForms上。 3.在DataGridView控件的任务处,选择数据源。 4.选好数据源后,VS自动添加DataSet、BindingSourse和T…...

VisualSVN Server/TortoiseSVN更改端口号
文章目录 概述VisualSVN Server端更改端口号TortoiseSVN客户端更改远程仓库地址 概述 Subversion(SVN)是常用的版本管理系统之一。部署在服务器上的SVN Server端通常会在端口号80,或者端口号443上提供服务。其中80是HTTP访问方式的默认端口。…...

如何解决研发数据传输层面安全可控、可追溯的共性需求?
研发数据在企业内部跨网文件交换,是相对较为普遍而频繁的文件流转需求,基于国家法律法规要求及自身安全管理需要,许多企业进行内部网络隔离。不同企业隔离方案各不相同,比如银行内部将网络隔离为生产网、办公网、DMZ区,…...
 default INSTANCES)
表 ,索引的 degree 检查, trim(degree) default INSTANCES
检查degree >1 的 select substr(owner,1,15) Owner , ltrim(degree) Degree, ltrim(instances) Instances, count(*) "Num Tables" , Parallel from dba_tables where ( trim(degree) > 1 ) and table_name not like ET$% group by owner, degree , ins…...

Git - Rebase命令介绍
Git rebase 是版本控制系统 Git 中一个功能强大、使用广泛的命令。它用于将一个分支中的改动整合到另一个分支中。rebase与merge不同, merge会创建一个新的提交,而rebase则是将一系列提交移动或合并到一个新的基础提交中。下面是详细解释: G…...
JavaScript 从入门到精通Object(对象)
文章目录 对象文本和属性方括号计算属性 属性值简写属性名称限制属性存在性测试,“in” 操作符“for…in” 循环像对象一样排序 总结✅任务你好,对象检查空对象对象属性求和将数值属性值都乘以 2 对象引用和复制通过引用来比较克隆与合并,Obj…...
Postgresql中json和jsonb类型区别
在我们的业务开发中,可能会因为特殊【历史,偷懒,防止表连接】经常会有JSON或者JSONArray类的数据存储到某列中,这个时候再PG数据库中有两种数据格式可以直接一对多或者一对一的映射对象。所以我们也可能会经常用到这类格式数据&am…...
太强了,使用 C# 开发的开源内网穿透工具
🏆作者:科技、互联网行业优质创作者 🏆专注领域:.Net技术、软件架构、人工智能、数字化转型、DeveloperSharp、微服务、工业互联网、智能制造 🏆欢迎关注我(Net数字智慧化基地),里面…...
leetcode及牛客网二叉树相关题、单值二叉树、相同的树、二叉树的前序、中序、后序遍历、另一棵树的子树、二叉树的遍历、 对称二叉树等的介绍
文章目录 前言一、单值二叉树二、相同的树三、二叉树的前序遍历四、二叉树的中序遍历五、二叉树的后序遍历六、另一棵树的子树七、二叉树的遍历八、 对称二叉树总结 前言 leetcode及牛客网二叉树相关题、单值二叉树、相同的树、二叉树的前序、中序、后序遍历、另一棵树的子树、…...
Spring Cloud)
Spring (38)Spring Cloud
Spring Cloud是一系列框架的集合,它利用Spring Boot的开发便利性,简化了分布式系统(如配置管理、服务发现、断路器、路由、微代理、事件总线、全局锁、决策竞选、分布式会话等)的开发。Spring Cloud为开发人员提供了在分布式系统中…...
)
MySQL之数据库相关操作学习笔记(一)
数据库相关操作 数据库表创建 定义逻辑库、数据表 DML 添加修改删除查询 DCL 用户权限事务 DDL 逻辑库数据表视图索引 DCL (Data Control Language) 示例 DCL(数据控制语言)主要用于控制数据库用户的访问权限和管理事务。DCL 主要包含两类语句&…...
【Node】node的Events模块(事件模块)的介绍和使用
文章目录 简言EventsPassing arguments and this to listeners 向监听器传递参数Asynchronous vs. synchronous 异步和同步Handling events only once 只一次处理事件Error events 错误事件Capture rejections of promises 捕捉拒绝承诺的情况Class: EventEmitter 事件类Event:…...
C#中字节数组(byte[])末尾继续添加字节的示例
方法一:使用List 使用List可以很容易地在末尾添加字节,然后如果需要,可以将其转换回byte[]。 using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; using System.Drawing; using System.Lin…...
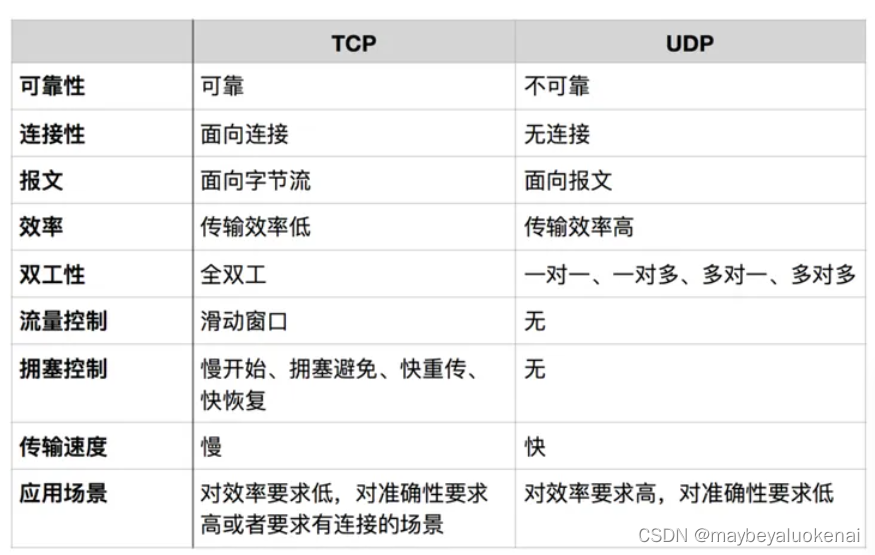
Socket编程学习笔记之TCP与UDP
Socket: Socket是什么呢? 是一套用于不同主机间通讯的API,是应用层与TCP/IP协议族通信的中间软件抽象层。 是一组接口。在设计模式中,Socket其实就是一个门面模式,它把复杂的TCP/IP协议族隐藏在Socket接口后面&#…...

JavaScript第九讲BOM编程的练习题
前言 上一节有BOM的讲解,有需要的码客们可以去看一下 以下是一个结合了上述BOM(Browser Object Model)相关内容的练习题及其源代码示例: 练习题: 编写一个JavaScript脚本,该脚本应该执行以下操作&#…...

JavaScript 中创建函数的多种方式
在 JavaScript 中,可以通过多种方式创建函数。每种方式都有其特定的用途、优点和缺点,以及适用的使用场景。以下是几种常见的创建函数的方式及其详细说明。 1. 函数声明(Function Declaration) 示例 function add(a, b) {retur…...
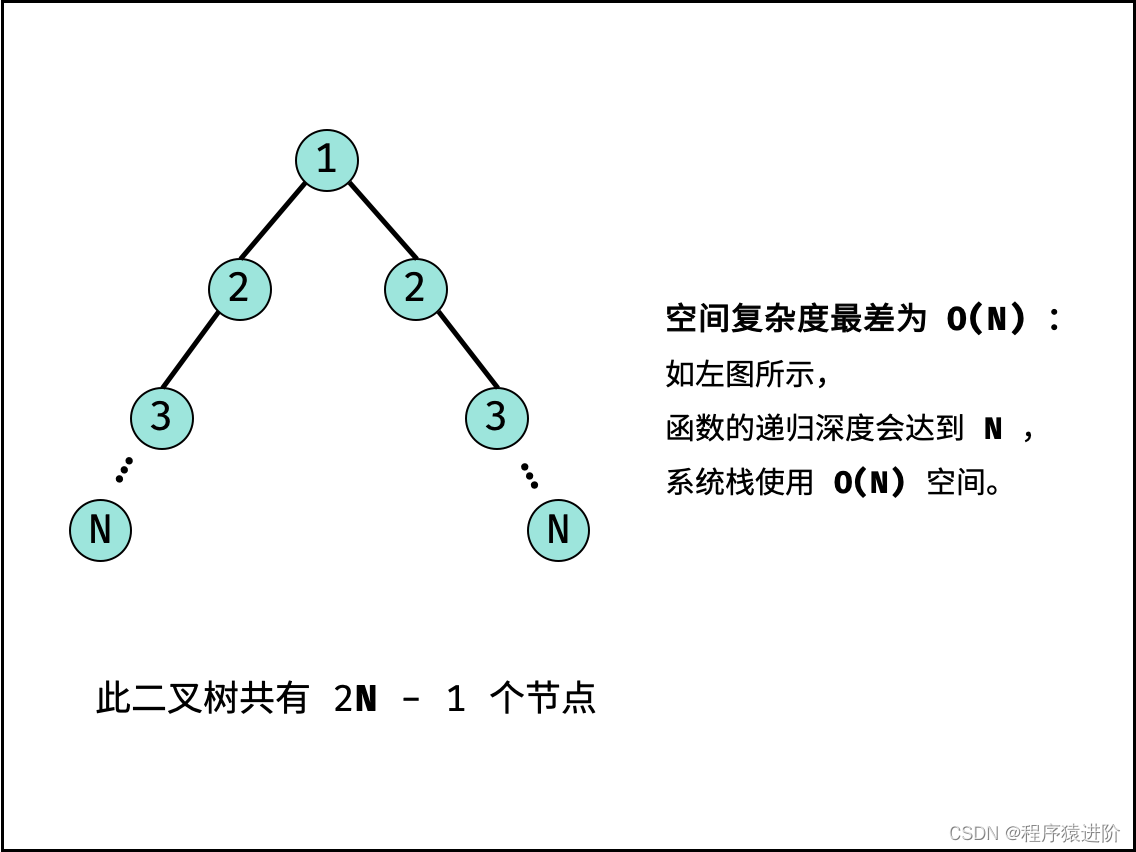
对称二叉树[简单]
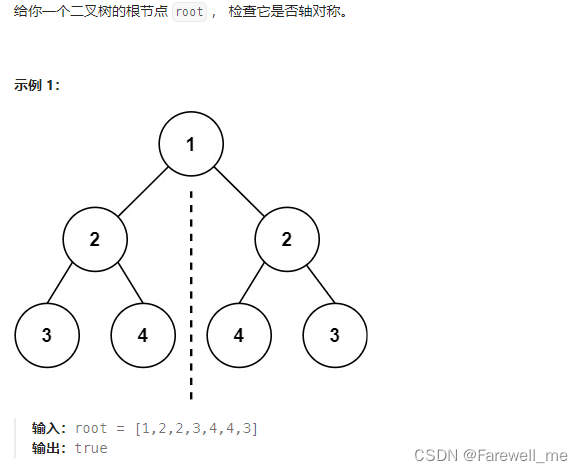
优质博文:IT-BLOG-CN 一、题目 给你一个二叉树的根节点root, 检查它是否轴对称。 示例 1: 输入:root [1,2,2,3,4,4,3] 输出:true 示例 2: 输入:root [1,2,2,null,3,null,3] 输出…...

判断GIF类型并使用ImageDecoder解析GIF图
一、判断是否为GIF图片类型 在JavaScript中,判断用户上传的文件是否为GIF文件类型时,通常可以通过检查文件的type属性或文件的拓展名来判断,但是由于文件拓展名可以轻易被用户修改,type属性是由浏览器根据文件拓展名猜测得出的&a…...

数组对象数据修改后页面没有更新,无法进行编辑,校验失效问题
在 Vue 中,当你通过 Object.assign 或其他方式修改了对象中的某个属性时,Vue 并不会触发组件重新渲染,因此表单中的 input 框无法及时更新。这可能导致在修改表单数据后,页面没有更新,而且表单校验也失效的情况。这是因…...
)
告别卡顿!用SwiftFormer在iPhone上5分钟部署实时图像识别App(附完整代码)
在iPhone上5分钟部署SwiftFormer图像识别App的实战指南 从理论到实践:为什么选择SwiftFormer 去年夏天,我在为一个时尚电商客户开发AR试衣功能时,第一次被移动端视觉模型的性能问题难住。当时使用的模型在iPhone 12上每帧处理需要近200ms&…...

成为技术专家的捷径?不,只有长期主义的坚持
在软件测试领域,我们常常被一种“速成”的幻象所包围。铺天盖地的培训广告承诺“三个月精通自动化测试”、“六周成为性能测试专家”,各种“一招鲜”的测试工具和“万能”的测试框架被包装成通往成功的捷径。对于身处其中、渴望突破职业瓶颈的测试工程师…...

终极指南:3步打造你的闲鱼AI客服机器人,实现24小时自动化值守
终极指南:3步打造你的闲鱼AI客服机器人,实现24小时自动化值守 【免费下载链接】XianyuAutoAgent 智能闲鱼客服机器人系统:专为闲鱼平台打造的AI值守解决方案,实现闲鱼平台724小时自动化值守,支持多专家协同决策、智能议…...
)
香橙派Armbian系统下,用apt一键安装OpenCV的完整流程(含GPG报错解决)
香橙派Armbian系统下OpenCV-Python极简安装指南:绕过源码编译的终极方案 在单板计算机领域,香橙派凭借其出色的性价比逐渐崭露头角。当开发者尝试在这类ARM架构设备上构建计算机视觉应用时,OpenCV往往是不可或缺的核心工具。然而,…...

AI报告文档审核赋能数据不出域:IACheck重构机械制造行业本地化质量管控体系
在机械制造行业不断推进数字化与智能化转型的过程中,“数据不出域”逐渐从合规要求演变为一种核心能力,即在保障数据安全的前提下,实现数据的高效利用与价值转化,而在这一背景下,检测报告作为连接生产过程与质量评估的…...

大模型Post-training实战:从新手到高手的进阶秘籍,收藏这份学习指南!
本文系统梳理了大语言模型(LLM)后训练(Post-training)的核心方法与最新进展,通过餐厅培训厨师的类比帮助读者建立直观理解。文章详细解析了监督微调(SFT)、基于人类反馈的强化学习(R…...

3步搞定B站4K视频下载:开源工具bilibili-downloader终极指南
3步搞定B站4K视频下载:开源工具bilibili-downloader终极指南 【免费下载链接】bilibili-downloader B站视频下载,支持下载大会员清晰度4K,持续更新中 项目地址: https://gitcode.com/gh_mirrors/bil/bilibili-downloader 想要免费下载…...

基于SpringBoot + Vue的学生学习成果管理平台
文章目录前言一、详细操作演示视频二、具体实现截图三、技术栈1.前端-Vue.js2.后端-SpringBoot3.数据库-MySQL4.系统架构-B/S四、系统测试1.系统测试概述2.系统功能测试3.系统测试结论五、项目代码参考六、数据库代码参考七、项目论文示例结语前言 💛博主介绍&#…...

零域名部署实战:阿里云ECS与宝塔面板的IP直连建站指南
1. 为什么选择IP直连建站? 很多刚接触服务器部署的朋友可能会疑惑:为什么不用域名直接访问网站?其实IP直连建站特别适合以下几种场景。比如你正在开发一个内部测试项目,需要快速让团队成员查看效果;或者你要给客户演示…...
)
用8086和蜂鸣器DIY音乐盒:手把手教你复刻童年旋律(附完整汇编代码)
用8086和蜂鸣器DIY音乐盒:手把手教你复刻童年旋律(附完整汇编代码) 记得小时候第一次听到电子贺卡发出《生日快乐》的单调旋律时,那种机械却又神奇的"音乐"让我盯着电路板研究了半天。现在想来,那些简单的方…...