Shell正则表达式与文本处理器
一、grep
1. 正则表达式
是一种匹配字符串的方法,通过一些特殊符号,快速实现查找,删除,替换某特定字符串。
选项:
-a 不要忽略二进制数据。
-A 显示该行之后的内容。
-b 显示该行之前的内容。
-c 计算符合范本样式的列数。
-C 除了显示符合范本样式的那一列之外,并显示该列之前后的内容。
-d 当指定要查找的是目录而非文件时,必须使用这项参数,否则grep命令将回报信息并停止动作。
-e 指定字符串作为查找文件内容的范本样式。
-E 能使用扩展正则表达式。
-f 指定范本文件,其内容有一个或多个范本样式,让grep查找符合范本条件的文件内容,格式为每一列的范本样式。
-F 固定字符串的列表。
-G 普通的表示法来使用。
-h 不标示该列所属的文件名称。
-H 标示该列的文件名称。
-i 忽略字符大小写的差别。
-l 列出文件名称。
-L 列出内容不符合的文件名称。
-n 标示出该列的编号。
-q 不显示任何信息。
-R/-r 此参数的效果和指定“-d recurse”参数相同。
-s 不显示错误信息。
-v 反转查找。
-w 只显示全字符合的列。
-x 只显示全列符合的列。
-y 此参数效果跟“-i”相同。
-o 只输出文件中匹配到的部分。
2. 基础正则表达式
创建该文件,以该文件为例进行编辑。
[root@localhost ~]# vim txt
he was short and fat.
he was weating a blue polo shirt with black pants.
The home of Football on BBC Sport online.
the tongue is boneless but it breaks bones.12!
google is the best tools for search keyword.
PI=3.14
a wood cross!
Actions speak louder than words#woood #
#woooooooood #
AxyzxyzxyzxyzC
I bet this place is really spooky late at night!
Misfortunes never come alone/single.
I shouldn't have lett so tast.(1)查看包含the的行
[root@localhost ~]# grep -ni 'the' txt 查找包含the的行
备注:
- -n 显示行号
- -i 不区分大小写
- -v 不包含指定字符
(2)利用[ ] 查找
[root@localhost ~]# grep -n 'sh[io]rt' txt查找shirt和short,其中[ ]无论有几个字符,都匹配一个字符。即[io]匹配i或者o。
[root@localhost ~]# grep -n '[^w]oo' txt 查找oo前面非w的内容
[root@localhost ~]# grep -n '[a-z]oo' txt 查找oo前面是a-z的内容
[root@localhost ~]# grep -n '[0-9]' txt 查找0-9相关的内容
备注:
^ 在字母前,表示取反。
^ 在[ ] 前,表示以括号中的字符开头。
(3)查找行首行尾
[root@localhost ~]# grep -n '^the' txt 查找以the为行首的内容
[root@localhost ~]# grep -n '^[a-z]' txt 查询以小写字母开头的行
[root@localhost ~]# grep -n '^[A-Z]' txt 查询以大写字母开头的行
[root@localhost ~]# grep -n '^[^a-zA-Z]' txt 查询非字母开头的行[root@localhost ~]# grep -n '\.$' txt 查询以 . 结尾的行
[root@localhost ~]# grep -n '^$' txt 查询空行
[root@localhost ~]# grep -n -v '^$' txt 查询非空行备注:
^ 行首;$ 行尾
^在[ ] 内表示反向选择;在[ ]前表示定位行首。
(4)查找任意字符和重复字符
[root@localhost ~]# grep -n 'w..d' txt 查询以d开头,w结尾的内容
[root@localhost ~]# grep -n 'ooo*' txt 查询至少包含两个字母00的内容
[root@localhost ~]# grep -n 'woo*d' txt 查询包含w字母开头,d结尾中间至少一个字母o
[root@localhost ~]# grep -n 'w.*d' txt w开头,d结尾,中间字符可有可无
[root@localhost ~]# grep -n '[0-9][0-9]*' txt 查询包含数字的行 备注:
'w..d' 一个点只能代表一个字符
ooo*:前两个o是条件,表示包含两个o;然后是o*,表示后面有零个或多个重复o。
(5)查询连续字符内容
[root@localhost ~]# grep -n 'o\{2\}' txt 查询包含两个o的字符
[root@localhost ~]# grep -n 'wo\{2,5\}d'txt w开头,d结尾中间有2--5个o
[root@localhost ~]# grep -n 'wo\{2,\}d' txt w开头,d结尾中间有2个以上o二、sed 文本处理器
sed 的工作流程主要包括读取、执行和显示三个过程。
- 读取:sed 从输入流(文件、管道、标准输入)中读取一行内容并存储到临时的缓冲区中(又称模式空间,pattern space)。
- 执行:默认情况下,所有的 sed 命令都在模式空间中顺序地执行,除非指定了行的地址,否则 sed 命令将会在所有的行上依次执行。
- 显示:发送修改后的内容到输出流。在发送数据后,模式空间将会被清空。
1. sed常用选项
-n :使用安静(silent)模式。在一般 sed 的用法中,所有来自 STDIN 的数据一般都会被列出到终端上。但如果加上 -n 参数后,则只有经过sed 特殊处理的那一行(或者动作)才会被列出来。
-e :直接在命令列模式上进行 sed 的动作编辑;
-f :直接将 sed 的动作写在一个文件内, -f filename 则可以运行 filename 内的 sed 动作;
-r :sed 的动作支持的是延伸型正规表示法的语法。(默认是基础正规表示法语法)
-i :直接修改读取的文件内容,而不是输出到终端。
2.sed常用操作
a :新增行, a 的后面可以是字串,而这些字串会在新的一行出现(目前的下一行)
c :取代行, c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行
d :删除行,因为是删除,所以 d 后面通常不接任何参数,直接删除地址表示的行;
i :插入行, i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行);
p :打印,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运行
s :替换,可以直接进行替换的工作
y:字符转换
3. 输出符合条件的文本
[root@localhost ~]# sed -n 'p' txt 输出所有内容
[root@localhost ~]# sed -n '3p' txt 输出第三行
[root@localhost ~]# sed -n '3,5p' txt 输出3~5行
[root@localhost ~]# sed -n 'p;n' txt 输出所有奇数行
[root@localhost ~]# sed -n 'n;p' txt 输出所有偶数行
[root@localhost ~]# sed -n '1,5{p;n}' txt 输出第1~5行之间的奇数行
[root@localhost ~]# sed -n '10,${n;p}' txt 输出第10行至文件尾之间的偶数行
[root@localhost ~]# sed -n '/the/p' txt 输出包含the的行
[root@localhost ~]# sed -n ' 4,/the/p' txt 输出从第4行开始至第一个包含the的行
[root@localhost ~]# sed -n '/the/=' txt 输出包含the的行所在的行号
注释:
=用来输出行号[root@localhost ~]# sed -n '/^PI/p' txt 输出以PI开头的行
[root@localhost ~]# sed -n '/\<wood\>/p' test.txt
或
[root@localhost ~]# sed -n '/wood/p' txt 输出包含单词wood的行4. 删除符合条件的文本
[root@localhost ~]# nl txt | sed '3d' 显示行号
或
[root@localhost ~]# sed '3d' txt 不显示行号
[root@localhost ~]# nl txt |sed '3,5d' 删除3~5行
[root@localhost ~]# nl txt |sed '/cross/d' 删除包含cross的行
[root@localhost ~]# nl txt |sed '/cross/! d' 删除不包含cross的行
[root@localhost ~]# sed '/^[a-z]/d' txt 删除以小写字母开头的行
[root@localhost ~]# sed '/\.$/d' txt 删除以点结尾的行
[root@localhost ~]# sed '/^$/d' txt 删除空行5.替换符合条件的文本
[root@localhost ~]# sed 's/the/THE/' txt 将每行的第一个the换成THE
[root@localhost ~]# sed 's/l/L/2' txt 将每行中的第2个l换成L
[root@localhost ~]# sed 's/the/THE/g' test.txt 将文中所有的the换成THE
[root@localhost ~]# sed 's/o//g' txt 将文中所有的o删除
[root@localhost ~]# sed 's/^/#/' txt 在每行的行首插入#
[root@localhost ~]# sed 's/$/#/' txt 在每行行尾添加#
[root@localhost ~]# sed '/the/s/^/#/' txt 在包含the的每行的行首插入#
[root@localhost ~]# sed 's/$/EOF/' txt 在每行的行尾插入字符串EOF
[root@localhost ~]# sed '3,5s/the/THE/g' txt 将第3~5行中的所有the替换成THE
[root@localhost ~]# sed '/the/s/o/O/g' txt 将包含the的所有行中的o都替换成O
6. 迁移符合条件的文本
H:复制到剪切板
g:将剪切板中的内容覆盖到指定行
G:将剪切板中的内容追加到指定行
w:保存文件
r:读取指定文件
a:追加指定内容
[root@localhost ~]# sed '/the/{H;d};$G' txt 将包含the的行迁移至文件的末尾
[root@localhost ~]# sed '1,5{H;d};17G' txt 将第1~5行的内容转移至第17行后
[root@localhost ~]# sed '/the/w out.txt' txt 将包含the的行另存为文件out.txt
[root@localhost ~]# sed '/the/r /etc/hostname' txt 将文件/etc/hostname的内容添加到包含the的每一行后
[root@localhost ~]# sed '3a#chkconfig:35 82 20' txt 在第3行后插入一个新行,内容为#chkconfig:35 82 20
[root@localhost ~]# sed '/the/aNew' txt (6)在包含the的每行后插入一个新行,内容为New
[root@localhost ~]# sed '3aNew1\nNew2' txt 在第3行后插入多行内容注释:\n为换行,添加两行为New1和New2
三、awk 文本处理器
awk 是一个功能强大的编辑工具,逐行读取输入文本,并根据指定的匹配模式进行查找,对符合条件的内容进行格式化输出或者过滤处理。
1. awk 常见用法
$0 表示整个当前行
$1 每行第一个字段
NF 字段数量变量
NR 每行的记录号,多文件记录递增
FNR 与NR类似,不过多文件记录不递增,每个文件都从1开始
2. 按行输出文本
awk -F":" '{print}' /etc/passwd //输出所有
awk -F":" '{print $0}' /etc/passwd //输出所有
awk -F: 'NR==3,NR==6{print}' /etc/passwd //显示第3行到第6行
awk -F: 'NR>=3&&NR<=6{print}' /etc/passwd //显示第3行到第6行
awk -F: 'NR==3||NR==6{print}' /etc/passwd //显示第3行和第6行
awk '(NR%2)==1{print}' /etc/passwd //显示奇数行
awk '(NR%2)==0{print}' /etc/passwd //显示偶数行
awk '/^root/{print}' /etc/passwd //显示以root开头的行
awk '/nologin$/{print}' /etc/passwd //显示以nologin结尾的行
awk 'BEGIN {x=0};/\/bin\/bash$/{x++};END {print x}' /etc/passwd //统计以/bin/bash结尾的行数
awk 'BEGIN{RS=""};END{print NR}' /etc/ssh/sshd_config //统计以空行分隔的文本段落数
awk '{print NR,$0}' /etc/passwd //输出每行的行号
awk -F: '{print NR,NF,$NF,"\t",$0}' /etc/passwd //依次打印行号,字段数,最后字段值,制表符,每行内容
awk -F: 'NR==5{print}' /etc/passwd //显示第5行
route -n|awk 'NR!=1{print}' //不显示第一行
awk -F: '{print NF}' /etc/passwd //显示每行有多少字段
awk -F: '{print $NF}' /etc/passwd //将每行第NF个字段的值打印出来awk -F: 'NF==4 {print }' /etc/passwd //显示只有4个字段的行
awk -F: 'NF>2{print $0}' /etc/passwd //显示每行字段数量大于2的行3. 按字段输出文本
awk -F":" '{print $3}' /etc/passwd //显示第三列
awk -F":" '{print $1 $3}' /etc/passwd //$1与$3相连输出,无空格,
awk -F":" '{print $1,$3}' /etc/passwd //多了一个逗号,输出第1和第3个字段,有空格
awk -F: '$2=="!!" {print}' /etc/shadow //统计密码为空的shadow记录
awk 'BEGIN {FS=":"}; $2=="!!" {print}' /etc/shadow 显示密码为空的用户的shadow信息
awk -F ":" '$7~"/bash" {print $1}' /etc/passwd 显示第七个字段为/bash的行的第一个字段
awk -F: 'NR==5{print}' /etc/passwd //显示第5行
awk -F":" '{print $1 " " $3}' /etc/passwd //$1与$3之间手动添加空格分隔4. 通过管道、双引号调用shell命令
awk -F: '/bash$/{print | "wc -l"}' /etc/passwd ##统计bash用户的个数
awk 'BEGIN {while ("w" | getline) n++ ; {print n-2}}' ##统计在线用户的数量
awk 'BEGIN {"hostname" | getline;print $0}' ##输出当前主机名四、sort
sort 是一个以行为单位对文件内容进行排序的工具,也可以根据不同的数据类型来排序。
选项:
-f:忽略大小写;
-b:忽略每行前面的空格;
-M:按照月份进行排序;
-n:按照数字进行排序;
-r:反向排序;
-u:等同于 uniq,表示相同的数据仅显示一行;
-t:指定分隔符,默认使用[Tab]键分隔;
-o <输出文件>:将排序后的结果转存至指定文件;
-k:指定排序区域。
1. 示例
[root@localhost ~]# sort /etc/passwd 将/etc/passwd 文件中的账号进行排序。
[root@localhost ~]# sort -t ':' -rk 3 /etc/passwd 将/etc/passwd 文件中第三
列进行反向排序。[root@localhost ~]# sort -t ':' -k 3 /etc/passwd -o user.txt 将/etc/passwd
文件中第三列进行排序,并将输出内容保存至 user.txt 文件中。
[root@localhost ~]# cat user.txt备注:
-r:反向排序;
-t:指定分隔符,默认使用[Tab]键分隔;
-k:指定排序区域。
五.tr
tr 命令常用来对来自标准输入的字符进行替换、压缩和删除。可以将一组字符替换之后变成另一组字符,经常用来编写优美的单行命令,作用很强大。
选项:
-c:取代所有不属于第一字符集的字符;
-d:删除所有属于第一字符集的字符;
-s:把连续重复的字符以单独一个字符表示;
-t:先删除第一字符集较第二字符集多出的字符
[root@localhost ~]# echo "KGC" | tr 'A-Z' 'a-z' 将输入字符由大写转换为小写。
[root@localhost ~]# echo "thissss is a text linnnnnnne." | tr -s 'sn' 压缩输入中重
复的字符。
[root@localhost ~]# echo 'hello world' | tr -d 'od' 删除字符串中某些字符备注:
-s:把连续重复的字符以单独一个字符表示
-d:删除所有属于第一字符集的字符
相关文章:

Shell正则表达式与文本处理器
一、grep 1. 正则表达式 是一种匹配字符串的方法,通过一些特殊符号,快速实现查找,删除,替换某特定字符串。 选项: -a 不要忽略二进制数据。 -A 显示该行之后的内容。 -b 显示该行之前的内容。 -c 计算符合范本样…...

双指针法 ( 三数之和 )
题目 :给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]] 满足 i ! j、i ! k 且 j ! k ,同时还满足 nums[i] nums[j] nums[k] 0 。请 你返回所有和为 0 且不重复的三元组。 注意:答案中不可以包含重复…...

感染恶意代码之后怎么办?
隔离设备 立即将感染设备与网络隔离,断开与互联网和其他设备的连接。这可以防止恶意代码进一步传播到其他设备,并减少对网络安全的威胁。 确认感染 确认设备是否真的感染了恶意代码。这可能需要使用安全软件进行全面扫描,以检测和识别任何已…...
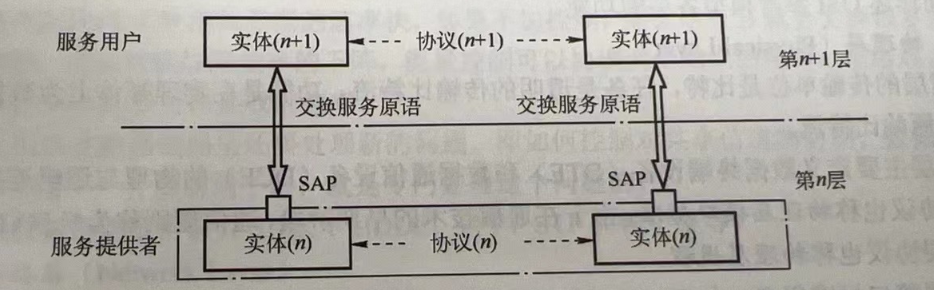
【计算机网络】P3 计算机网络协议、接口、服务的概念、区别以及计算机网络提供的三种服务方式
目录 协议什么是协议协议是水平存活的协议的组成 接口服务服务是什么服务原语 协议与服务的区别计算机网络提供的服务的三种方式面向连接服务与无连接服务可靠服务与不可靠服务有应答服务与无应答服务 协议 什么是协议 协议,就是规则的集合。 在计算机网络中&…...

多角度剖析事务和事件的区别
事务和事件这两个概念在不同的领域有着不同的含义,尤其是在计算机科学、数据库管理和软件工程中。下面从多个角度来剖析事务和事件的区别: 计算机科学与数据库管理中的事务 事务(Transaction): 定义:在数据库管理中,…...
模糊小波神经网络(MATLAB 2018)
模糊系统是一种基于知识或规则的控制系统,从属于智能控制,通过简化系统的复杂性,利用控制法来描述系统变量之间的关系,采用语言式的模糊变量来描述系统,不必对被控对象建立完整的数学模型。相比较传统控制策略…...

HTML布局
标准流: 标准流就是元素在页面中的默认排列方式,也就是元素在页面中的默认位置。 1.1 块元素----独占一行----从上到下排列 1.2 行内元素----不独占一行----从左到右排列,遇到边界换行 1.3 行内块元素----不独占一行…...

数据结构:双链表
数据结构:双链表 题目描述参考代码 题目描述 输入样例 10 R 7 D 1 L 3 IL 2 10 D 3 IL 2 7 L 8 R 9 IL 4 7 IR 2 2输出样例 8 7 7 3 2 9参考代码 #include <iostream>using namespace std;const int N 100010;int m; int idx, e[N], l[N], r[N];void init…...

Python3 元组、列表、字典、集合小结
前言 本文主要对Python中的元组、列表、字典、集合进行小结,主要内容包括知识点回顾、异同点、使用场景。 文章目录 前言一、知识点回顾1、列表(List)2、 元组(Tuple)3、 字典(Dictionary)4.、…...

2024会声会影破解免费序列号,激活全新体验!
会声会影2024序列号注册码是一款专业的视频编辑软件,它以其强大的功能和易用性受到了广大用户的喜爱。在这篇文章中,我将详细介绍会声会影2024序列号注册码的功能和特色,帮助大家更好地了解这款产品。 会声会影全版本绿色安装包获取链接&…...
机器学习18个核心算法模型
1. 线性回归(Linear Regression) 用于建立自变量(特征)和因变量(目标)之间的线性关系。 核心公式: 简单线性回归的公式为: , 其中 是预测值, 是截距, 是斜…...
)
平滑值(pinghua)
平滑值 题目描述 一个数组的“平滑值”定义为:相邻两数差的绝对值的最大值。 具体的,数组a的平滑值定义为 f ( a ) m a x i 1 n − 1 ∣ a i 1 − a i ∣ f(a)max_{i1}^{n-1}|a_{i1}-a_i| f(a)maxi1n−1∣ai1−ai∣ 现在小红拿到了一个数组…...
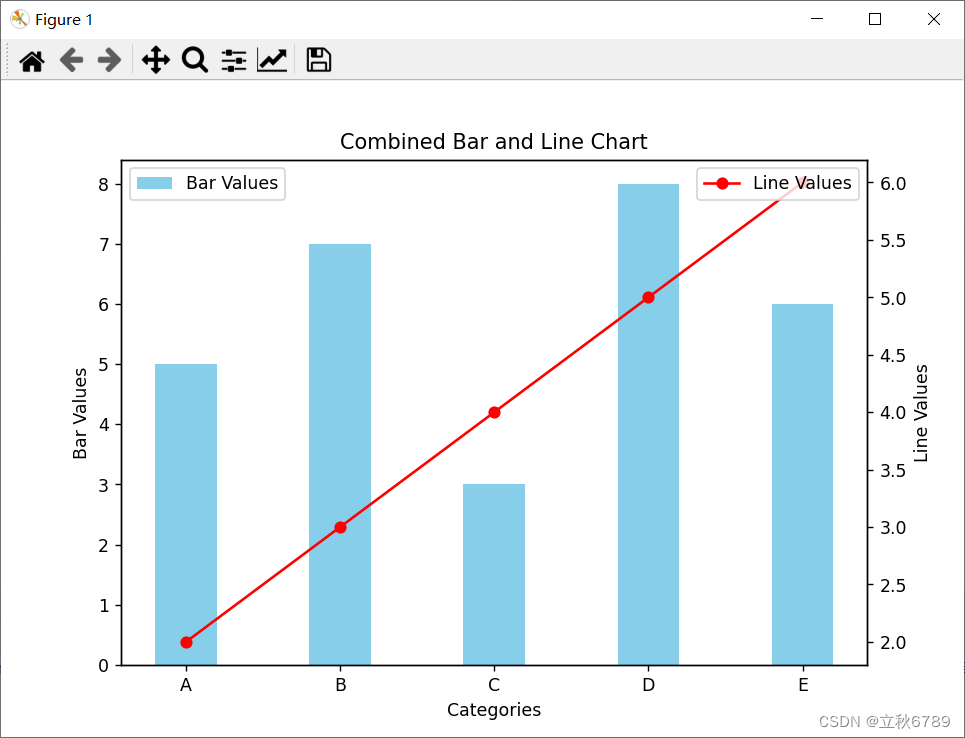
使用matplotlib绘制折线条形复合图
使用matplotlib绘制折线条形复合图 介绍效果代码 介绍 在数据可视化中,复合图形是一种非常有用的工具,可以同时显示多种数据类型的关系。在本篇博客中,我们将探讨如何使用 matplotlib 库来绘制包含折线图和条形图的复合图。 效果 代码 imp…...

云计算中网络虚拟化的核心组件——NFV、NFVO、VIM与VNF
NFV NFV(Network Functions Virtualization,网络功能虚拟化),是一种将传统电信网络中的网络节点设备功能从专用硬件中解耦并转换为软件实体的技术。通过运用虚拟化技术,NFV允许网络功能如路由器、防火墙、负载均衡器、…...

# SpringBoot 如何让指定的Bean先加载
SpringBoot 如何让指定的Bean先加载 文章目录 SpringBoot 如何让指定的Bean先加载ApplicationContextInitializer使用启动入口出注册配置文件中配置spring.factories中配置 BeanDefinitionRegistryPostProcessor使用 使用DependsOn注解实现SmartInitializingSingleton接口使用P…...

家用洗地机哪个品牌好?洗地机怎么选?这几款全网好评如潮
如今,人们家里越来越多的智能清洁家电,小到吸尘器、电动拖把,大到扫地机器人、洗地机,作为一个用过所有这些清洁工具的家庭主妇,我觉得最好用的还是洗地机。它的清洁效果比扫地机器人更好,功能也比吸尘器更…...

iOS与前端:深入解析两者之间的区别与联系
iOS与前端:深入解析两者之间的区别与联系 在数字科技高速发展的今天,iOS与前端技术作为两大热门领域,各自在移动应用与网页开发中扮演着不可或缺的角色。然而,这两者之间究竟存在哪些差异与联系呢?本文将从四个方面、…...
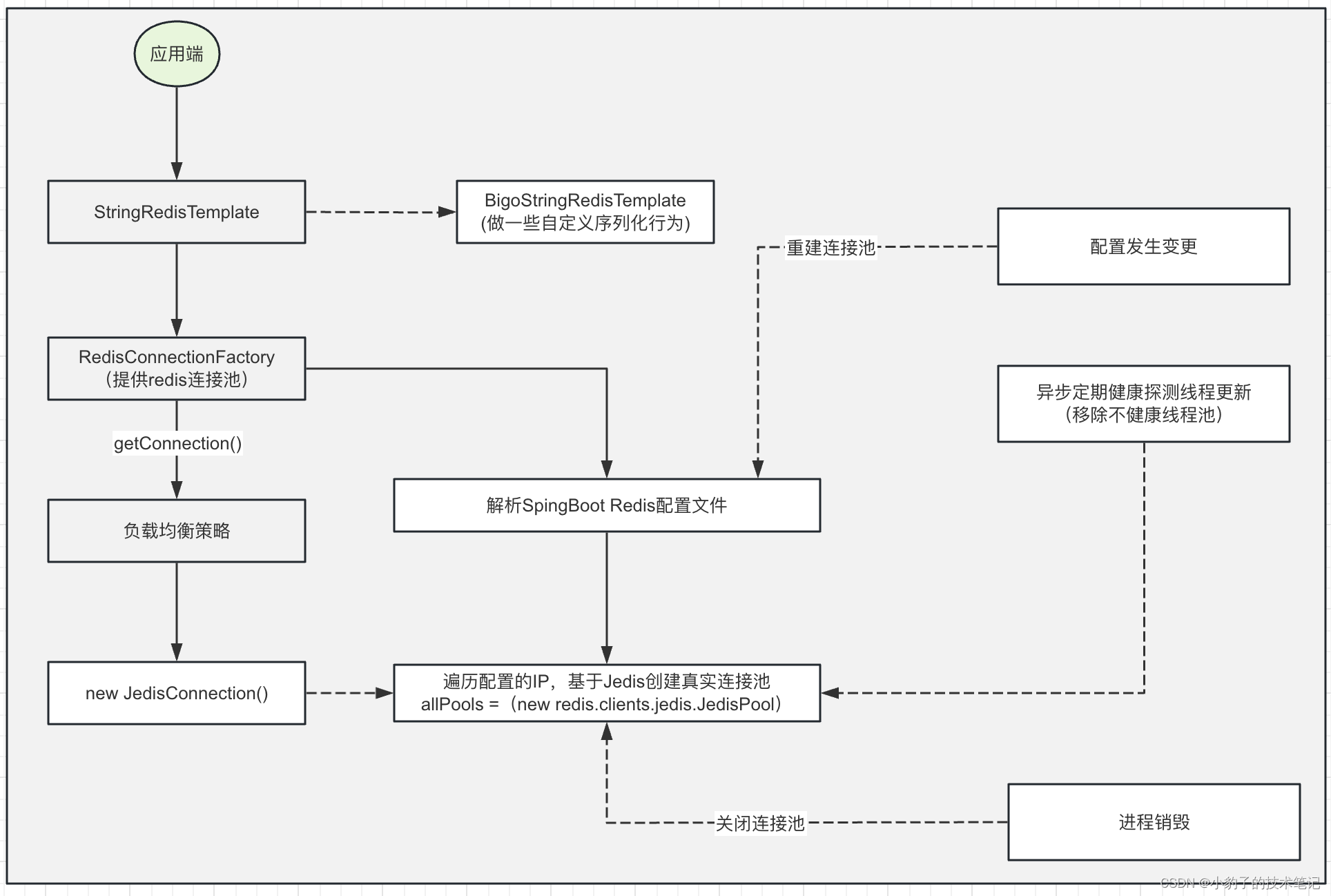
SpringBoot 基于jedis实现Codis高可用访问
codis与redis的关系 codis与redis之间关系就是codis是基于多个redis实例做了一层路由层来进行数据的路由,每个redis实例承担一定的数据分片。 codis作为开源产品,可以很直观的展示出codis运维成本低,扩容平滑最核心的优势. 其中࿰…...

力扣108. 将有序数组转换为二叉搜索树
108. 将有序数组转换为二叉搜索树 - 力扣(LeetCode) 找割点,一步一步将原数组分开。妙极了!!!!! /*** Definition for a binary tree node.* public class TreeNode {* int val;…...
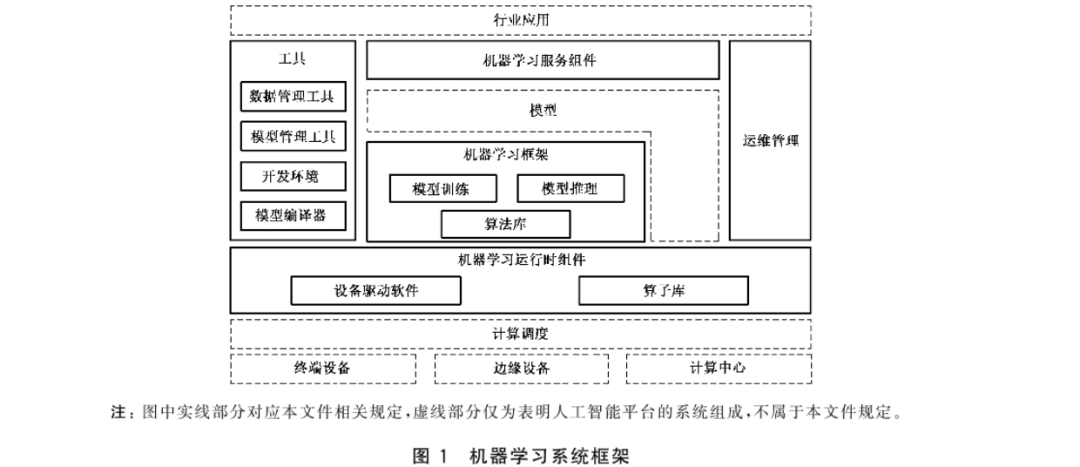
人工智能机器学习系统技术要求
一 术语和定义 1.1机器学习系统 machinelearningsystem 能运行或用于开发机器学习模型、算法和相关应用的软件系统。 1.2机器学习框架 machinelearningframework 利用预先构建和优化好的组件集合定义模型,实现对机器学习算法封装、数据调用处理和计算资源使用的软件库。 1…...

Cowabunga Lite:iOS系统个性化定制的免越狱解决方案
Cowabunga Lite:iOS系统个性化定制的免越狱解决方案 【免费下载链接】CowabungaLite iOS 15 Customization Toolbox 项目地址: https://gitcode.com/gh_mirrors/co/CowabungaLite 在iOS生态系统中,用户对系统个性化的需求与日俱增,但传…...

Node.js后端集成GTE-Base-ZH:构建语义化API服务实战
Node.js后端集成GTE-Base-ZH:构建语义化API服务实战 最近在做一个智能文档检索项目,需要处理大量中文文本的语义相似度计算。一开始尝试用传统的TF-IDF,效果总是不尽如人意,直到接触到了GTE-Base-ZH这个专门针对中文优化的文本嵌…...

触控板手势增强:告别跨系统痛点,实现macOS风格三指拖动无缝体验
触控板手势增强:告别跨系统痛点,实现macOS风格三指拖动无缝体验 【免费下载链接】ThreeFingersDragOnWindows Enables macOS-style three-finger dragging functionality on Windows Precision touchpads. 项目地址: https://gitcode.com/gh_mirrors/t…...

解锁RO游戏自动化工具:从效率瓶颈到智能辅助的实践指南
解锁RO游戏自动化工具:从效率瓶颈到智能辅助的实践指南 【免费下载链接】openkore A free/open source client and automation tool for Ragnarok Online 项目地址: https://gitcode.com/gh_mirrors/op/openkore 在MMORPG游戏领域,重复刷怪、繁琐…...

VRCX:重新定义VRChat社交管理的智能伴侣工具
VRCX:重新定义VRChat社交管理的智能伴侣工具 【免费下载链接】VRCX Friendship management tool for VRChat 项目地址: https://gitcode.com/GitHub_Trending/vr/VRCX 在虚拟社交平台VRChat的生态中,社交关系管理常常成为用户体验的痛点。传统方式…...

二手破损手机涨价,业余 NAS 玩家如何破局?
最近打开手机回收 App,发现家里那台屏幕碎成渣、开不了机的旧安卓机,居然能卖一百多,甚至两三百。你可能会想:这是天上掉馅饼,还是 NAS 玩家的“矿难”前兆? 作为一名业余 NAS 玩家,我正好踩在这…...

dll修复工具绿色版免安装,2026年最新版实测与风险提示
正急着用电脑,突然弹窗“缺少dll文件”,游戏或软件打不开。第一反应就是赶紧找个工具修好它,但又不想在电脑上装一堆乱七八糟的软件,就想找个绿色版、免安装的,用完就能删,不留痕迹。但网上这种小工具满天飞…...

all-MiniLM-L6-v2入门必读:轻量级Embedding模型选型、部署与评估全流程
all-MiniLM-L6-v2入门必读:轻量级Embedding模型选型、部署与评估全流程 想找一个又快又小的文本嵌入模型,但又担心效果不好?很多开发者在做语义搜索、文本分类或者智能问答时,都会遇到这个难题。大模型效果好但太慢,小…...
)
嵌入式Linux实战:全志T3+vsftpd实现轻量级文件传输(含WinSCP连接教程)
嵌入式Linux实战:全志T3vsftpd实现轻量级文件传输(含WinSCP连接教程) 在物联网设备开发中,文件传输是一个看似简单却充满挑战的环节。当你的开发板是全志T3这样的资源受限平台时,如何在有限的存储和内存条件下搭建一个…...

保姆级教程:深求·墨鉴Podman部署全流程,小白也能轻松搞定
保姆级教程:深求墨鉴Podman部署全流程,小白也能轻松搞定 1. 为什么选择Podman部署深求墨鉴? 传统Docker部署方式虽然常见,但对于深求墨鉴这样的轻量级OCR工具来说,Podman提供了更优雅的解决方案。Podman是一款无需守…...