【机器学习】深度探索:从基础概念到深度学习关键技术的全面解析——梯度下降、激活函数、正则化与批量归一化


文章目录
- 一、机器学习的基本概念与原理
- 二、深度学习与机器学习的关系
- 2.1 概念层次的关系
- 2.2 技术特点差异
- 2.3 机器学习示例:线性回归(使用Python和scikit-learn库)
- 2.4 深度学习示例:简单的神经网络(使用Python和PyTorch库)
- 2.5 应用场景
- 三、机器学习在深度学习领域的关键技术
- 3.1 梯度下降优化算法
- 3.2 激活函数
- 3.3 正则化技术
- 3.4 批量归一化
- 四、总结
随着科技的飞速发展,人工智能(AI)已经成为当今世界的热门话题。作为AI的核心技术之一,机器学习(Machine Learning, ML)在各个领域都发挥着举足轻重的作用。特别是在深度学习(Deep Learning, DL)领域中,机器学习提供了重要的理论支撑和实践指导。本文将通俗易懂地介绍机器学习的基本概念、原理和应用场景,并深入解析机器学习在深度学习领域中的重要作用。
一、机器学习的基本概念与原理

机器学习,作为人工智能学科内的一块瑰宝,其核心精髓在于利用复杂的算法体系,从众多数据中抽丝剥茧,提炼出隐含的规律与模式,从而使计算机系统无需详细的手动指令,即可自主地实现对未来结果的预测及对复杂决策问题的解决。简言之,此领域致力于赋予机器如同学生般的学习能力,使之能基于现有数据自我进化,掌握执行任务的技巧。
简单来说,就是教电脑自己从数据里学习和发现规律的一个方法。想象一下,电脑像一个聪明的学生,不是直接告诉它每件事怎么做,而是给它很多例子让它自己去找到做事的规律。比如,我们要教电脑认猫,就给它看成千上万张猫的照片,电脑就会慢慢学会识别什么是猫的特点,以后看到新的照片,就算没告诉它是猫,电脑也能认出来。
其背后的运行逻辑可精炼为以下步骤:
-
数据准备与模型初始化阶段:这一阶段就好比盖房子前的规划与设计。我们首先需要收集大量的“建筑材料”——数据,这些数据可以是有标签的(意味着我们知道每个数据点代表什么),也可以是无标签的。利用这些数据,我们搭建一个基础的“框架”——数学模型。这个模型是高度灵活的,能够适应各种形状,其目标是为了最终能够描摹出数据中的模式和关联。就像建筑师手里的蓝图,虽然最初只是线条和符号,但蕴含了构建大厦的全部设想。
-
模型训练与优化阶段:接下来,就进入了精雕细琢的阶段。我们使用不同的“工具”和“技艺”——算法,来逐步调整模型中的各种参数。每次调整都像是雕刻师的一次敲打或一笔刻画,都是为了让模型更加贴合数据的真实面貌,减少它在预测时的错误。通过反复迭代,模型逐步学会了从输入数据中提取关键特征,并据此作出预测或决策,这个过程就好比匠人在无数次的尝试后,手中的作品愈发接近理想状态。
经过这样的过程,模型不再是对原始数据的简单复制,而是提炼出了数据背后的规律和知识。就像一个人通过不断学习和经验积累,能够理解和应对新情况一样,机器学习模型也通过这个过程实现了“学习”,拥有了泛化能力,即在面对未曾见过的数据时,也能做出合理的判断或预测。这就是机器学习从数据到知识转化的魅力所在。
我们用大量的例子(这些例子可以是我们已经标注好的,比如哪些是猫的照片)来建立一个初始的“学习计划”。这个计划就像一个框架,等着被填充具体的知识。然后,通过一些复杂的计算方法,电脑会不断调整这个计划,让它变得更准确,错误越来越少。就像是电脑在不断地自我修正和进步,直到它变得非常擅长识别任务。
机器学习的用处非常广泛,比如能让手机识别你的声音指令,自动给你推荐喜欢的电影和歌曲,帮助医生分析病人的检查结果,或是银行用来判断交易是否安全等。现在,因为有了互联网,每天都有海量的信息产生,这就给了机器学习更多的“学习材料”,让它在医疗、金融、制造,甚至我们的日常生活中发挥更大的作用,让科技变得更加智能和贴心。
二、深度学习与机器学习的关系

2.1 概念层次的关系
-
机器学习(Machine Learning, ML) 是一种让计算机系统能够从数据中自动学习并改进其表现的技术,而无需进行明确编程。它包括监督学习、无监督学习、半监督学习和强化学习等多种方法。
-
深度学习(Deep Learning, DL) 则是机器学习的一个特定分支,它受到人脑结构——神经网络的启发,通过构建多层的神经网络模型来学习数据的多层次抽象表示。深度学习模型特别擅长于捕捉数据中的复杂模式和非线性关系。
2.2 技术特点差异
-
特征学习:
- 传统机器学习:通常需要人工设计特征,这是一个耗时且需要领域专业知识的过程。例如,在图像识别任务中,可能需要手动设计边缘检测器等特征。
- 深度学习:自动进行特征学习是其显著优势之一。通过多层神经网络结构,深度学习模型能从原始数据中自动提取高级特征,大大简化了特征工程的工作。
-
模型结构:
- 传统机器学习:模型相对简单,如支持向量机(SVM)、决策树、随机森林等,它们往往处理线性可分或者较简单的问题较为有效。
- 深度学习:采用多层结构,尤其是包含多个隐藏层的神经网络,这种分层结构使得模型能够学习数据的低级到高级的抽象表示,非常适合处理高维、大规模以及非线性问题。
-
数据需求:
- 传统机器学习:某些算法在小数据集上也能表现良好。
- 深度学习:通常需要大量的标注数据来训练模型,因为复杂的网络结构和参数数量较多,需要足够的样本来避免过拟合。
-
计算资源:
- 传统机器学习:计算要求相对较低,许多算法可以在普通硬件上快速执行。
- 深度学习:由于模型复杂度高,训练过程往往需要高性能的GPU甚至是分布式计算平台来加速计算,尤其是在大型数据集上的应用。
接下来我们将分别通过一个简单的线性回归(机器学习的经典示例)和一个基本的神经网络(深度学习的入门级应用)来说明这一点。
2.3 机器学习示例:线性回归(使用Python和scikit-learn库)
线性回归是最简单的机器学习模型之一,用于预测一个连续变量。假设我们想根据房屋的面积预测房价。
from sklearn.linear_model import LinearRegression
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split# 生成模拟数据
X, y = make_regression(n_samples=100, n_features=1, noise=0.1)# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建并训练模型
model = LinearRegression()
model.fit(X_train, y_train)# 预测
predictions = model.predict(X_test)# 打印预测结果
print(predictions[:5])
2.4 深度学习示例:简单的神经网络(使用Python和PyTorch库)
下面是一个使用PyTorch实现的简单神经网络,用于解决与上述相同的房价预测问题。这里我们构造一个只有一个隐藏层的神经网络。
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset# 转换数据为PyTorch的Tensor
X_tensor = torch.tensor(X, dtype=torch.float32)
y_tensor = torch.tensor(y, dtype=torch.float32)# 划分数据集
train_data = TensorDataset(X_tensor[:-20], y_tensor[:-20])
test_data = TensorDataset(X_tensor[-20:], y_tensor[-20:])# 定义数据加载器
train_loader = DataLoader(train_data, batch_size=10)
test_loader = DataLoader(test_data, batch_size=10)# 定义神经网络模型
class SimpleNN(nn.Module):def __init__(self):super().__init__()self.layer1 = nn.Linear(1, 10) # 输入层到隐藏层self.layer2 = nn.Linear(10, 1) # 隐藏层到输出层def forward(self, x):x = torch.relu(self.layer1(x)) # 使用ReLU激活函数return self.layer2(x)model = SimpleNN()# 定义损失函数和优化器
criterion = nn.MSELoss() # 均方误差损失,适用于回归问题
optimizer = optim.SGD(model.parameters(), lr=0.01) # 随机梯度下降优化器# 训练模型
epochs = 100
for epoch in range(epochs):for inputs, targets in train_loader:# 前向传播outputs = model(inputs)loss = criterion(outputs, targets)# 反向传播和优化optimizer.zero_grad()loss.backward()optimizer.step()# 测试模型
model.eval()
with torch.no_grad():predictions = model(X_tensor[-20:])print(predictions.numpy())
通过这两个示例,可以看到机器学习中的线性回归模型相对简单,仅需几行代码即可实现,而深度学习的神经网络模型虽然实现起来稍微复杂,但通过增加网络的深度和复杂性,可以学习到数据中的更深层次特征,处理更复杂的问题。
2.5 应用场景
尽管深度学习在图像识别、自然语言处理、语音识别等领域展现了革命性的性能提升,但是否选择深度学习取决于具体问题的性质、可用数据量以及计算资源。有时,传统机器学习方法因其简洁高效,在资源有限或问题简单的情况下仍然是更优的选择。因此,深度学习与机器学习之间是一种互补而非替代的关系,两者结合使用往往能带来最佳的解决方案。
三、机器学习在深度学习领域的关键技术

3.1 梯度下降优化算法
梯度下降算法通过迭代地调整模型参数来最小化损失函数,从而找到最优解。在深度学习中,我们通常使用小批量梯度下降(Mini-Batch Gradient Descent),它结合了批量梯度下降和随机梯度下降的优点。
代码示例(使用PyTorch):
import torch
import torch.nn as nn
import torch.optim as optim# 假设一个简单的线性回归模型
class LinearRegressionModel(nn.Module):def __init__(self, input_dim, output_dim):super(LinearRegressionModel, self).__init__()self.linear = nn.Linear(input_dim, output_dim)def forward(self, x):return self.linear(x)input_dim = 10
output_dim = 1
model = LinearRegressionModel(input_dim, output_dim)# 定义损失函数和优化器
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9) # 添加动量以加速收敛# 生成模拟数据
X = torch.randn(64, input_dim) # 小批量数据,64为批量大小
y = torch.randn(64, output_dim)# 训练循环
num_epochs = 100
for epoch in range(num_epochs):# 前向传播outputs = model(X)loss = criterion(outputs, y)# 梯度清零optimizer.zero_grad()# 反向传播loss.backward()# 参数更新optimizer.step()# 每10个epoch打印一次损失值if (epoch + 1) % 10 == 0:print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item()}')
3.2 激活函数
激活函数能够增加神经网络的非线性,使其能够学习并逼近任意复杂的函数。ReLU (Rectified Linear Unit) 是一种常用的激活函数,因其简单且计算效率高而受到青睐。
代码示例(使用PyTorch的ReLU激活函数):
# 定义一个包含ReLU激活函数的全连接层
fc_layer = nn.Sequential(nn.Linear(10, 5),nn.ReLU(inplace=True) # inplace=True表示在原地修改数据,节省内存
)# 输入数据
X = torch.randn(1, 10)# 前向传播
output = fc_layer(X)
print(output)
3.3 正则化技术
正则化用于防止模型过拟合,提高泛化能力。L2正则化(也称为Tikhonov正则化或权重衰减)是常用的正则化方法之一。
代码示例(在PyTorch优化器中使用L2正则化):
# 定义模型、损失函数和优化器(包含L2正则化)
model = LinearRegressionModel(input_dim, output_dim)
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, weight_decay=0.001) # weight_decay即为L2正则化系数
3.4 批量归一化
批量归一化(Batch Normalization) 可以标准化神经网络的输入,减少内部协变量偏移,从而加速训练并提高性能。
代码示例(在PyTorch模型中使用批量归一化):
# 定义包含批量归一化的模型
class NormalizedModel(nn.Module):def __init__(self, input_dim, hidden_dim, output_dim):super(NormalizedModel, self).__init__()self.fc1 = nn.Linear(input_dim, hidden_dim)self.bn1 = nn.BatchNorm1d(hidden_dim) # 批量归一化层self.relu = nn.ReLU()self.fc2 = nn.Linear(hidden_dim, output_dim)def forward(self, x):x = self.fc1(x)x = self.bn1(x) # 应用批量归一化x = self.relu(x)x = self.fc2(x)return x# 实例化模型并打印输出
input_dim = 10
hidden_dim = 20
output_dim = 1
model = NormalizedModel(input_dim, hidden_dim, output_dim)
X = torch.randn(64, input_dim) # 模拟输入数据
output = model(X)
print(output)
四、总结

本文全面探讨了机器学习和深度学习的核心概念、原理及其相互关系,并通过具体的代码示例,展示了两者在实际应用中的操作和实现方式。
在第一部分,我们回顾了机器学习的基本概念和原理,这是理解和应用深度学习的基石。机器学习通过训练数据来优化模型参数,从而使模型能够自动地从数据中学习并做出预测或决策。
第二部分详细阐述了深度学习与机器学习的关系。从概念层次上看,深度学习是机器学习的一个重要分支,它利用深层神经网络来模拟人脑的学习过程。深度学习在技术特点上与传统的机器学习有所不同,它能够处理更复杂、非线性的数据关系。通过线性回归和简单神经网络的示例,我们进一步比较了机器学习和深度学习在实际应用中的差异,并探讨了它们在不同应用场景中的优势。
在第三部分,我们深入剖析了机器学习在深度学习领域中的关键技术,包括梯度下降优化算法、激活函数、正则化技术和批量归一化。这些技术是构建高效、稳定深度学习模型的核心。梯度下降优化算法帮助我们在训练过程中调整模型参数,以最小化损失函数。激活函数为神经网络提供了非线性能力,使其能够学习并模拟复杂的函数关系。正则化技术通过约束模型复杂度来防止过拟合,提高模型的泛化能力。而批量归一化则通过标准化神经网络的输入来加速训练过程,并提高模型的稳定性。
综上所述,本文通过系统的理论阐述和=代码示例,全面介绍了机器学习和深度学习的基本概念、原理及关键技术。这些内容为初学者在深度学习领域的学习和实践提供了有力的支持和指导。希望大家能够从中受益,并在实际应用中发挥出深度学习的强大潜力。
相关文章:
【机器学习】深度探索:从基础概念到深度学习关键技术的全面解析——梯度下降、激活函数、正则化与批量归一化
🔥 个人主页:空白诗 文章目录 一、机器学习的基本概念与原理二、深度学习与机器学习的关系2.1 概念层次的关系2.2 技术特点差异2.3 机器学习示例:线性回归(使用Python和scikit-learn库)2.4 深度学习示例:简…...

C++模板类与Java泛型类的实战应用及对比分析
C模板类和Java泛型类都是用于实现代码重用和类型安全性的重要工具,但它们在实现方式和应用上有一些明显的区别。下面,我将先分别介绍它们的实战应用,然后进行对比分析。 C模板类的实战应用 C模板类允许你定义一种通用的类,其中类…...
使用Qt对word文档进行读写
目录 开发环境原理使用的QT库搭建开发环境准备word模板测试用例结果Gitee地址 开发环境 vs2022 Qt 5.9.1 msvc2017_x64,在文章最后提供了源码。 原理 Qt对于word文档的操作都是在书签位置进行插入文本、图片或表格的操作。 使用的QT库 除了基本的gui、core、…...

docker容器内无法使用命令问题
更换国内源 /etc/apt/source.list 可以先apt-get install vim #进入容器 docker exec -it 容器ID /bin/bashmv /etc/apt/source.list /etc/apt/source.list.bd vim /etc/apt/source.list#此处我使用腾讯云的源 deb http://mirrors.cloud.tencent.com/debian/ buster main non…...
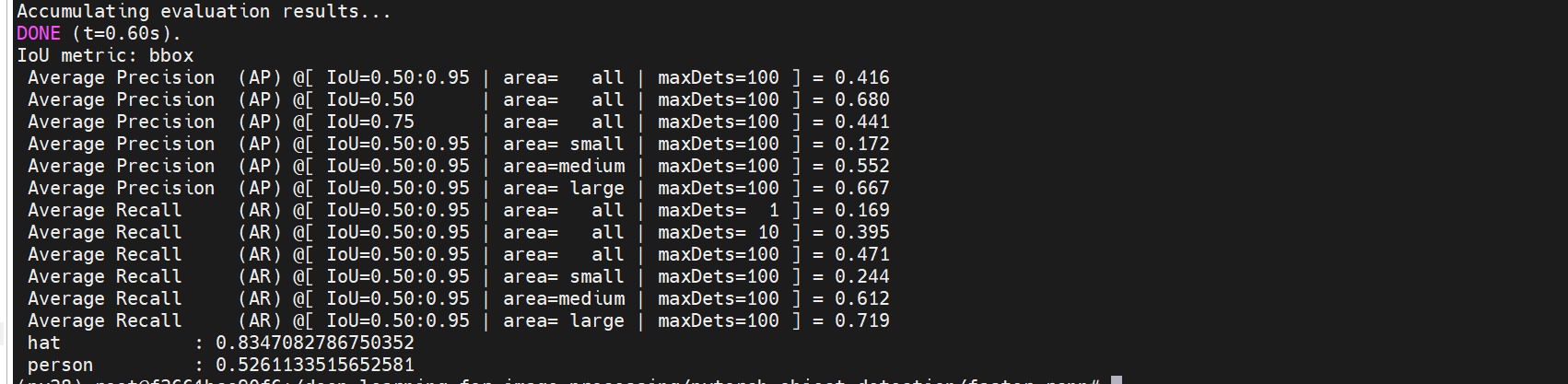
【深度学习】安全帽检测,目标检测,Faster RCNN训练
文章目录 资料环境尝试训练安全帽数据训练测试预测全部数据、代码、训练完的权重等资料见: 资料 依据这个进行训练: https://github.com/WZMIAOMIAO/deep-learning-for-image-processing/tree/master/pytorch_object_detection/faster_rcnn ├── bac…...
IDEA2024创建maven项目
1、new->project 2、创建后展示 3、生成resources文件夹 4、测试--编写一个hello文件...
linux上VirtualBox使用
前言 最近想把唯一的windows系统装成linux, 但是确实存在一些特殊软件无法舍弃,所有装完linux需要用虚拟机装个windows 上来使用特定的一些软件(不想用wine了)。 还有对一些特定usb设备的透传,这样才能保证在虚拟机中…...

PID控制算法介绍及使用举例
PID 控制算法是一种常用的反馈控制算法,用于控制系统的稳定性和精度。PID 分别代表比例(Proportional)、积分(Integral)和微分(Derivative),通过组合这三个部分来调节控制输出&#…...

因子区间[牛客周赛44]
思路分析: 我们可以发现125是因子个数的极限了,所以我们可以用二维数组来维护第几个数有几个因子,然后用前缀和算出来每个区间合法个数,通过一个排列和从num里面选2个 ,c num 2 来计算即可 #include<iostream> #include<cstring> #include<string> #include…...

代码随想录算法训练营第四十四天 | 01背包问题理论基础、01背包问题滚动数组、416. 分割等和子集
背包问题其实有很多种,01背包是最基础也是最经典的,软工计科学生一定要掌握的。 01背包问题 代码随想录 视频讲解:带你学透0-1背包问题!| 关于背包问题,你不清楚的地方,这里都讲了!| 动态规划经…...

【PingPong_注册安全分析报告】
前言 由于网站注册入口容易被黑客攻击,存在如下安全问题: 暴力破解密码,造成用户信息泄露短信盗刷的安全问题,影响业务及导致用户投诉带来经济损失,尤其是后付费客户,风险巨大,造成亏损无底洞 …...
车辆路径规划之Dubins曲线与RS曲线简述
描述 Dubins和RS曲线都是路径规划的经典算法,其中车辆运动学利用RS曲线居多,因此简单介绍Dubins并引出RS曲线。 花了点时间看了二者的论文,并阅读了一个开源的代码。 Dubins曲线 Dubins曲线是在满足曲率约束和规定的始端和末端的切线&#…...

PostgreSQL 和Oracle锁机制对比
PostgreSQL 和Oracle锁机制对比 PostgreSQL 和 Oracle 都是业界广泛使用的关系型数据库管理系统,它们在锁机制方面都有独到的设计来控制并发访问,确保数据的一致性和完整性。下面我们详细比较一下这两个数据库系统的锁机制。 1. 锁类型 PostgreSQL P…...

6月05日,每日信息差
第一、特斯拉在碳博会上展示了其全品类的可持续能源解决方案,包括首次在国内展出的超大型电化学商用储能系统 Megapack 和家庭储能系统 Powerwall。此外,特斯拉还展示了电动汽车三电系统的解构和电池回收技术产品 第二、2024 年第一季度,全球…...

MongoDB~俩大特点管道聚合和数据压缩(snappy)
场景 在MySQL中,通常会涉及多个表的一些操作,MongoDB也类似,有时需要将多个文档甚至是多个集合汇总到一起计算分析(比如求和、取最大值)并返回计算后的结果,这个过程被称为 聚合操作 。 根据官方文档介绍&…...

HTML+CSS+JS 动态登录表单
效果演示 实现了一个登录表单的背景动画效果,包括一个渐变背景、一个输入框和一个登录按钮。背景动画由多个不同大小和颜色的正方形组成,它们在页面上以不同的速度和方向移动。当用户成功登录后,标题会向上移动,表单会消失。 Code <!DOCTYPE html> <html lang=&q…...

统一返回响应
前言 我们为什么要设置统一返回响应 提高代码的可维护性:通过统一返回请求的格式,可以使代码更加清晰和易于维护,减少重复的代码,提高代码质量。 便于调试和测试:统一的返回格式使得在调试和测试时更为简单ÿ…...
大数据学习问题记录
问题记录 node1突然无法连接finalshell node1突然无法连接finalshell 今天我打开虚拟机和finalshell的时候,发现我的node1连接不上finalshell,但是node2、node3依旧可以链接,我在网上找了很多方法,但是是关于全部虚拟机连接不上finalshell&a…...
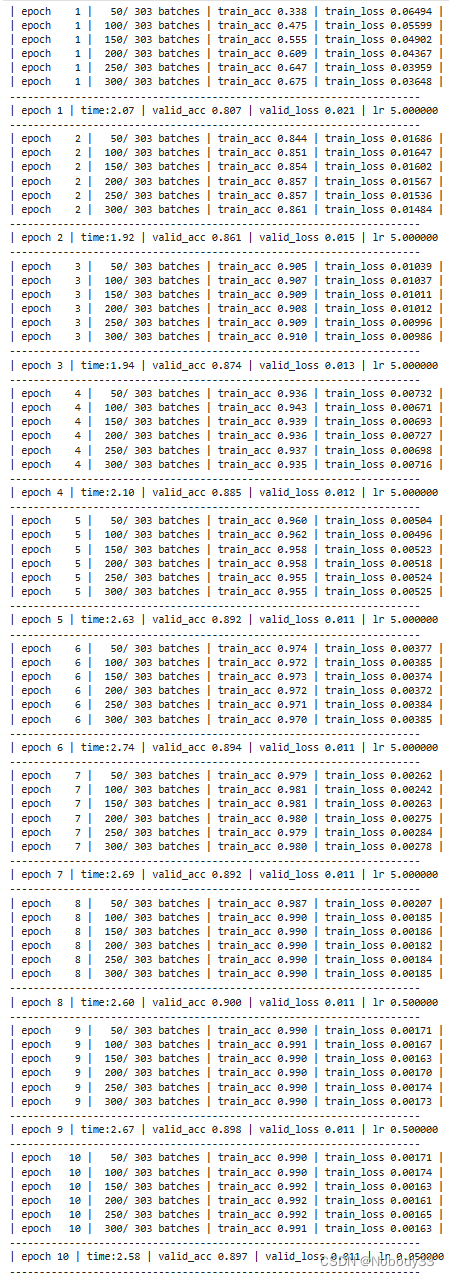
第N4周:中文文本分类
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 一、预备知识 中文文本分类和英文文本分类都是文本分类,为什么要单独拎出来个中文文本分类呢? 在自然语言处理(NLP&#x…...
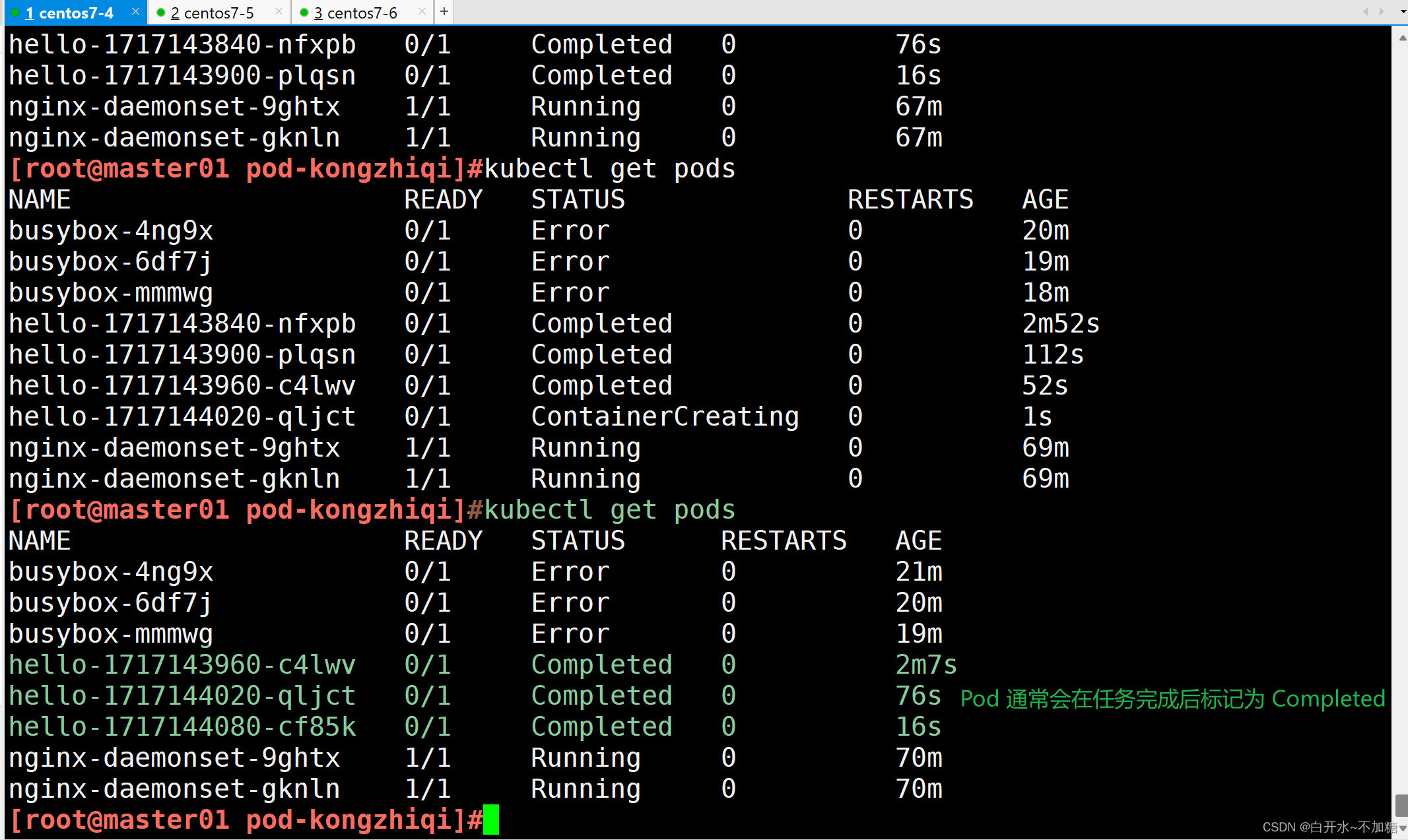
【kubernetes】探索k8s集群的pod控制器详解(Deployment、StatefulSet、DaemonSet、Job、CronJob)
目录 一、Pod控制器及其功用 二、pod控制器有多种类型 2.1ReplicaSet 2.1.1ReplicaSet主要三个组件组成 2.2Deployment 2.3DaemonSet 2.4StatefulSet 2.5Job 2.6Cronjob 三、Pod与控制器之间的关系 3.1Deployment 3.2SatefulSet 3.2.1StatefulSet三个组件 3.2.2为…...

分享稳定可靠的TMC5160、TMC5130高性能步进电机驱动代码,支持级联,简单易用,附送原理图
TMC5160、TMC5130高性能步进电机驱动代码 代码都已长时间验证,稳定可靠运行! 图里资料就是到手资料 简介: 德国TMC步进电机驱动代码 送你OrCAD或者AD版本原理图 自己整个重新写的代码,注释详细 支持多个TMC5160级联 调用很简单&a…...

用快马快速构建API限流演示原型,直观理解rate limit exceeded
最近在开发一个需要调用第三方API的项目时,遇到了"rate limit exceeded"的错误提示。为了更直观地理解API限流机制,我决定用InsCode(快马)平台快速搭建一个演示原型。整个过程比想象中简单很多,分享下我的实现思路和经验。 项目构思…...

快速原型:用快马ai一键生成openclaw在mac上的自动化安装脚本
最近在Mac上折腾OpenClaw这个开源工具时,发现它的安装过程对新手确实不太友好。作为一个经常需要快速验证工具可行性的开发者,我尝试用InsCode(快马)平台来生成自动化安装脚本,整个过程意外地顺畅。下面分享下我的实践心得: 环境检…...

用快马平台五分钟搭建countif函数交互演示原型,告别枯燥文档
最近在帮同事做Excel培训时,发现很多人对countif函数的使用总是一知半解。传统的文档说明太抽象,于是我尝试用InsCode(快马)平台快速搭建了一个交互式演示工具,效果出乎意料的好。整个过程只用了不到5分钟,完全不需要操心环境配置…...

如何用 GitHub Actions 自部署 GitHub Readme Stats,并统计私有仓库数据
目录背景介绍通过 GitHub Actions 自部署 GitHub Readme Stats如何使用 GitHub Actions 配置统计私有仓库数据1. 生成 Personal Access Token (PAT) 以统计私有仓库**如何生成 Personal Access Token (PAT)**:2. 使用 GitHub Secrets 存储 PAT3. 为什么默认配置无法…...
AgentCPM-Report开源模型教程:Pixel Epic在科研团队中的协作部署实践
AgentCPM-Report开源模型教程:Pixel Epic在科研团队中的协作部署实践 1. 项目介绍与核心价值 Pixel Epic是一款基于AgentCPM-Report大模型构建的创新型研究报告辅助工具。它将枯燥的科研工作流程转化为充满游戏化体验的交互过程,让团队成员在轻松愉悦的…...

ChromeDriver vs GeckoDriver终极选择指南:如何为php-webdriver项目挑选最佳浏览器驱动
ChromeDriver vs GeckoDriver终极选择指南:如何为php-webdriver项目挑选最佳浏览器驱动 【免费下载链接】php-webdriver PHP client for Selenium/WebDriver protocol. Previously facebook/php-webdriver 项目地址: https://gitcode.com/gh_mirrors/ph/php-webdr…...

gallery性能分析工具:找出本地AI平台的性能瓶颈
gallery性能分析工具:找出本地AI平台的性能瓶颈 【免费下载链接】gallery A gallery that showcases on-device ML/GenAI use cases and allows people to try and use models locally. 项目地址: https://gitcode.com/GitHub_Trending/gallery44/gallery 在…...

5G NR物理层控制信令实战:从PDCCH盲解码到DCI格式解析
5G NR物理层控制信令实战:从PDCCH盲解码到DCI格式解析 在5G新空口(NR)系统中,物理层控制信令是实现高效资源调度和可靠数据传输的核心机制。作为无线通信协议栈开发工程师和网络优化人员,深入理解PDCCH盲解码机制、COR…...

如何构建自修复AI系统:Seldon Core 2数据漂移检测终极指南
如何构建自修复AI系统:Seldon Core 2数据漂移检测终极指南 【免费下载链接】seldon-core An MLOps framework to package, deploy, monitor and manage thousands of production machine learning models 项目地址: https://gitcode.com/gh_mirrors/se/seldon-cor…...