DBSCAN 算法【python,机器学习,算法】
DBSCAN 即 Density of Based Spatial Clustering of Applications with Noise,带噪声的基于空间密度聚类算法。
算法步骤:
- 初始化:
- 首先,为每个数据点分配一个初始聚类标签,这里设为0,表示该点尚未被分配到一个聚类中。
- 设置一个聚类ID(cluster_id),初始化为0,用于标识不同的聚类。
- 遍历数据点:
遍历数据集中的每个点。如果某点已经被标记(即不属于聚类0),则跳过该点。 - 查找邻居点:
对于每个尚未被标记的点,使用get_neighbors函数查找其ε-邻域内的所有邻居点。这通常是通过计算该点与数据集中其他点之间的欧氏距离,并比较距离与ε来实现的。 - 处理邻居点数量:
- 如果找到的邻居点数量小于min_pts(最小邻居数量),则将当前点标记为噪声点(标签设为-1)。
- 如果邻居点数量大于或等于min_pts,则将该点标记为一个新的聚类(将cluster_id加1,并将该点标签设为新的cluster_id)。
- 扩展聚类:
- 对于每个新发现的聚类中的点(即刚被标记为当前cluster_id的点),执行expand_cluster函数以进一步扩展聚类。
- 在expand_cluster函数中,遍历当前点的所有邻居点,并根据其标签进行处理:
- 如果邻居点是噪声点(标签为-1),则将其标记为当前聚类(将标签改为cluster_id)。
- 如果邻居点尚未被标记(标签为0),则将其标记为当前聚类,并递归地查找并标记其邻居点(如果其邻居点数量也满足min_pts)。
- 返回结果:
当所有点都被处理完毕后,算法返回每个数据点的最终聚类标签。
下面是代码实现:
from collections import Counterimport numpy as np
from sklearn.datasets import make_blobsdef dbscan(data, eps, min_pts):# 初始化每个数据点的聚类标签为 0labels = [0] * len(data)# 聚类 idcluster_id = 0for i in range(len(data)):if labels[i] != 0:# 如果数据点已经被标记过,则跳过该点,继续下一个点continue# 获取当前点的邻居点neighbors = get_neighbors(data, i, eps)# 如果邻居点的数量小于最小邻居数量,则将当前点标记为噪声点if len(neighbors) < min_pts:labels[i] = -1else:# 否则,增加聚类 idcluster_id += 1# 将当前点标记为当前聚类 idlabels[i] = cluster_id# 扩展聚类expand_cluster(data, labels, neighbors, cluster_id, eps, min_pts)# 返回每个数据点的聚类标签return labelsdef expand_cluster(data, labels, neighbors, cluster_id, eps, min_pts):# 遍历每个邻居点for neighbor in neighbors:# 如果邻居点的标签为 -1if labels[neighbor] == -1:# 将噪声点标记为当前聚类 idlabels[neighbor] = cluster_id# 如果邻居点的标签为 0elif labels[neighbor] == 0:# 将邻居点标记为当前聚类 idlabels[neighbor] = cluster_id# 获取邻居点的邻居点new_neighbors = get_neighbors(data, neighbor, eps)# 如果新的邻居点数量满足最小邻居数量要求,则将其加入邻居列表if len(new_neighbors) >= min_pts:neighbors += new_neighborsdef get_neighbors(data, point_idx, eps):# 邻居点列表neighbors = []for i in range(len(data)):# 计算当前点与目标点之间的欧氏距离,如果距离小于邻域半径 epsif np.linalg.norm(data[i] - data[point_idx]) < eps:# 将目标点的索引加入邻居点列表neighbors.append(i)# 返回邻居点列表return neighborsnp.random.seed(0)
# 生成样例数据
data, y = make_blobs(n_samples=200, centers=5, cluster_std=0.6)
print(Counter(y))eps, min_pts = 0.6, 3
# 进行聚类
labels = dbscan(data, eps, min_pts)
print(Counter(labels))
上述代码实现了一个简单的 DBSCAN 算法。注意,在实际应用中,你需要根据实际情况调整邻域半径参数和核心点周围最小数据点数。
一般情况下,最小数据点数取数据维度值的 2 倍数,最小取 3。 该参数越大,可能的噪声点会被聚类,同样的邻域半径越小,噪声点也会被分类。
相关文章:

DBSCAN 算法【python,机器学习,算法】
DBSCAN 即 Density of Based Spatial Clustering of Applications with Noise,带噪声的基于空间密度聚类算法。 算法步骤: 初始化: 首先,为每个数据点分配一个初始聚类标签,这里设为0,表示该点尚未被分配…...
MySQL之查询性能优化(六)
查询性能优化 查询优化器 9.等值传播 如果两个列的值通过等式关联,那么MySQL能够把其中一个列的WHERE条件传递到另一列上。例如,我们看下面的查询: mysql> SELECT film.film_id FROM film-> INNER JOIN film_actor USING(film_id)-> WHERE f…...
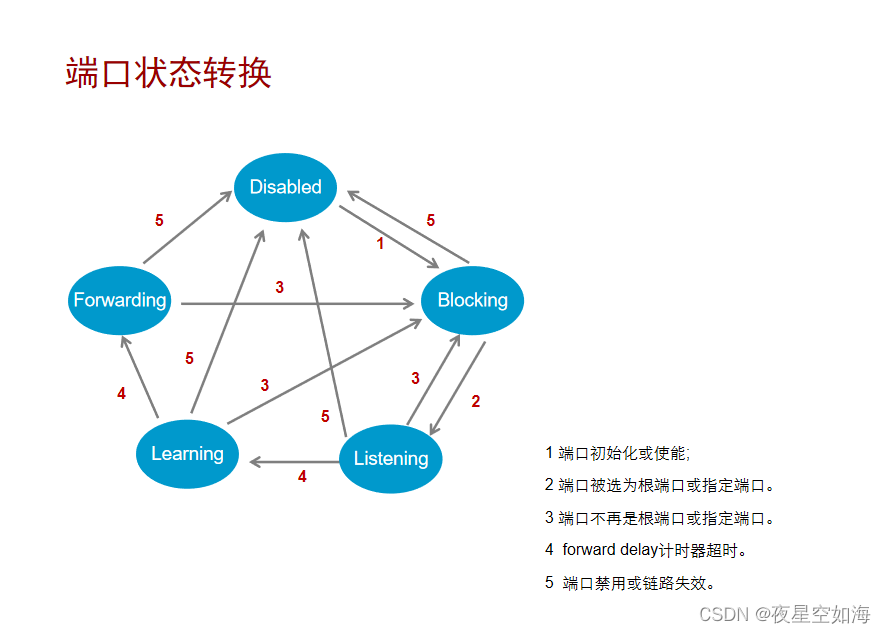
生成树协议STP(Spanning Tree Protocol)
为了提高网络可靠性,交换网络中通常会使用冗余链路。然而,冗余链路会给交换网络带来环路风险,并导致广播风暴以及MAC地址表不稳定等问题,进而会影响到用户的通信质量。生成树协议STP(Spanning Tree Protocol࿰…...

03-3.1.1 栈的基本概念
👋 Hi, I’m Beast Cheng👀 I’m interested in photography, hiking, landscape…🌱 I’m currently learning python, javascript, kotlin…📫 How to reach me --> 458290771qq.com 喜欢《数据结构》部分笔记的小伙伴可以订…...
排序算法集合
1. 冒泡排序 排序的过程分为多趟,在每一趟中,从前向后遍历数组的无序部分,通过交换相邻两数位置的方式,将无序元素中最大的元素移动到无序部分的末尾(第一趟中,将最大的元素移动到数组倒数第一的位置&…...
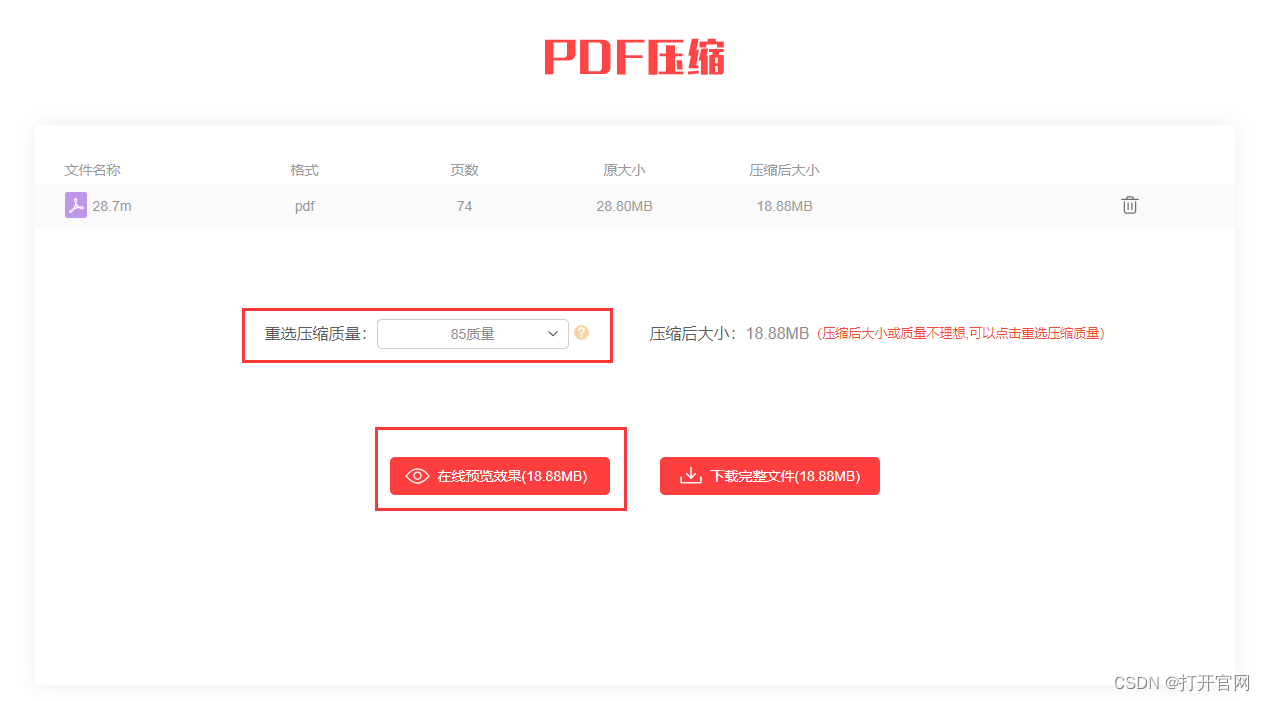
pdf文件太大如何变小,苹果电脑压缩pdf文件大小工具软件
压缩PDF文件是我们在日常办公和学习中经常会遇到的需求。PDF文件由于其跨平台、保持格式不变的特点,被广泛应用于各种场合。然而,有时候我们收到的PDF文件可能过大,不便于传输和存储,这时候就需要对PDF文件进行压缩。下面…...

vite项目打包,内存溢出
解决方案: "build1": "node --max-old-space-size8096 ./node_modules/vite/bin/vite.js build", 人工智能学习网站 https://chat.xutongbao.top...

Matlab解决施密特正交规范化矩阵(代码开源)
#最近在学习matlab,刚好和线代论文重合了 于是心血来潮用matlab建了一个模型来解决施密特正交规范化矩阵。 我们知道这个正交化矩阵挺公式化的,一般公式化的内容我们都可以用计算机来进行操作,节约我们人工的时间。 我们首先把矩阵导入进去…...

自养号测评助力:如何打造沃尔玛爆款?
沃尔玛,作为全球零售业的领军者,其平台为卖家们提供了一个巨大的商业舞台。然而,在这个竞争激烈的舞台上,如何迅速且有效地提升销量,成为了卖家们必须面对的重大挑战。 在探讨沃尔玛平台销量提升的策略时,我…...

C语言编译与链接
C语言编译与链接 目录 C语言编译与链接 一、概述 二、编译过程 三、链接过程...

电子电器架构 --- 智能座舱技术分类
电子电器架构 — 智能座舱技术分类 我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 屏蔽力是信息过载时代一个人的特殊竞争力,任何消耗你的人和事,多看一眼都是你的不对。非必要不费力证明自己,…...

提供操作日志、审计日志解决方案思路
操作日志 现在大部分公司一般使用SpringCloud这条技术栈,操作日志通过网关Gateway提供的Globalfilter统一拦截请求解析请求是比较好的选选择。 优点:相对于传统的过滤器、拦截器同步阻塞方案,SpringCloud Gateway使用的Webflux中的reactor-…...
选择富唯智能的可重构装配系统,就是选择了一个可靠的合作伙伴
在数字化、智能化的浪潮中,制造业正迎来一场前所未有的变革。而在这场变革中,富唯智能凭借其卓越的技术实力和创新能力,成为引领行业发展的领军企业。选择富唯智能的可重构装配系统,就是选择了一个可靠的合作伙伴,共同…...

echarts tooltip太多显示问题解决方案
思路:设置5个一换行 tooltip: {trigger: axis,confine:true,//限制tooltip在图表范围内展示// extraCssText: max-height:60%;overflow-y:scroll,//最大高度以及超出处理extraCssText: max-height:60%;overflow-y:scroll;white-space: normal;word-break: break-al…...
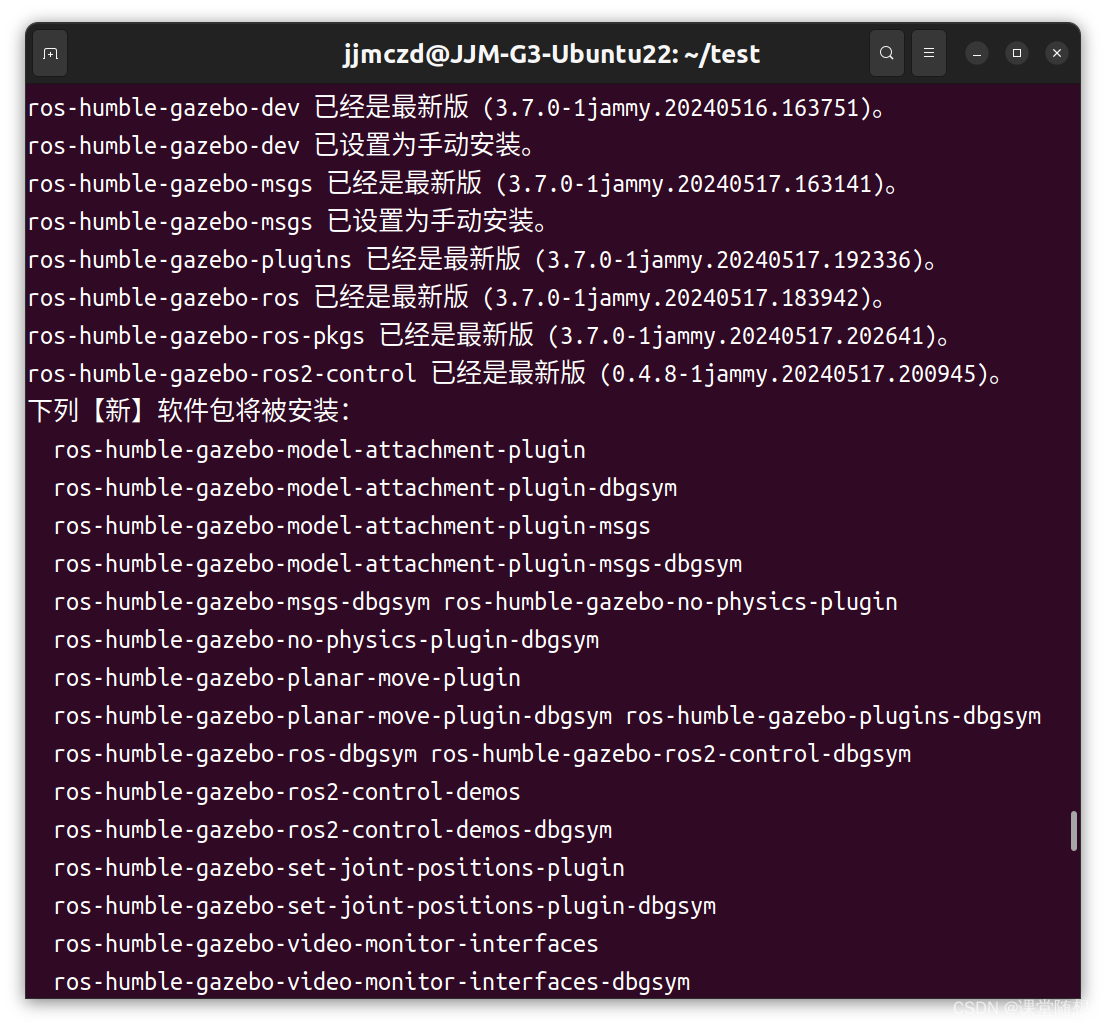
【control_manager】无法加载,gazebo_ros2_control 0.4.8,机械臂乱飞
删除URDF和SDRF文件中的特殊注释#, !,: xacro文件解析为字符串时出现报错 一开始疯狂报错Waiting for /controller_manager node to exist 1717585645.4673686 [spawner-2] [INFO] [1717585645.467015300] [spawner_joint_state_broadcaster]: Waiting for /con…...
深入对比:Transformer与LSTM的详细解析
在深度学习和自然语言处理(NLP)领域,Transformer和长短时记忆网络(LSTM)是两个备受瞩目的模型。它们各自拥有独特的优势,并在不同的任务中发挥着重要作用。本文将对这两种模型进行详细对比,帮助…...

lsof 命令
lsof(list open files)是一个列出当前系统打开文件的工具。在linux环境下,任何事物都以文件的形式存在,通过文件不仅仅可以访问常规数据,还可以访问网络连接和硬件。所以如传输控制协议 (TCP) 和用户数据报协议 (UDP) …...
F5G城市光网,助力“一网通城”筑基数字中国
《淮南子》中说,“临河而羡鱼,不如归家织网”。 这句话在后世比喻为做任何事情都需要提前做好准备,有了合适的工具,牢固的基础,各种难题也会迎刃而解。 如今,数字中国发展建设如火如荼,各项任务…...
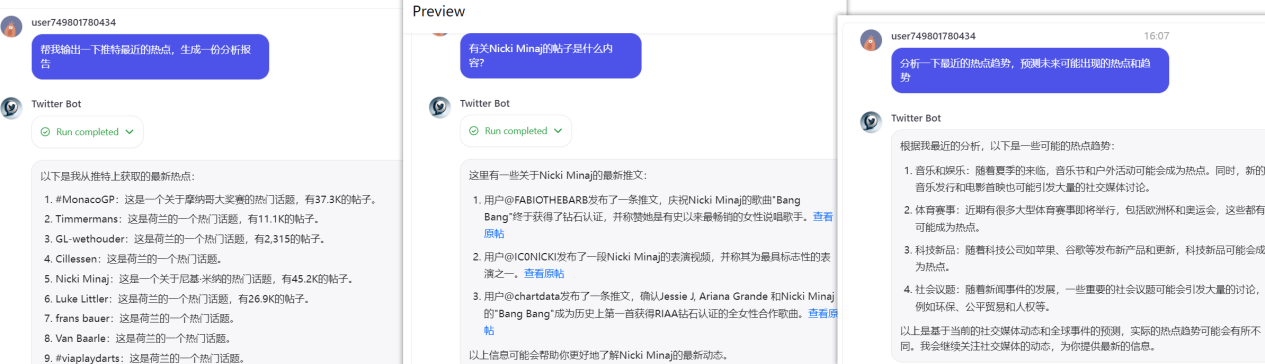
Ownips+Coze海外社媒数据分析实战指南
目录 一、引言二、ISP代理简介三、应用实践——基于Ownips和coze的社媒智能分析助手3.1、Twitter趋势数据采集3.1.1、Twitter趋势数据接口分析3.1.2、Ownips原生住宅ISP选取与配置3.1.3、数据采集 3.2、基于Ownips和Coze的社媒智能助手3.2.1、Ownips数据采集插件集成3.2.2、创建…...
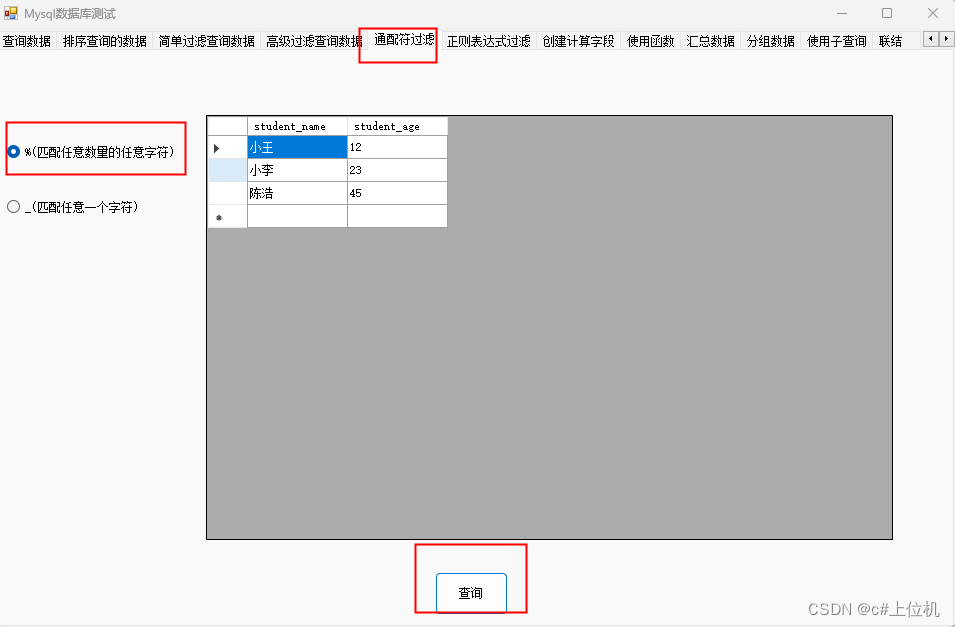
C#操作MySQL从入门到精通(10)——对查询数据进行通配符过滤
前言 我们有时候需要查询数据,并且这个数据包含某个字符串,这时候我们再使用where就无法实现了,所以mysql中提供了一种模糊查询机制,通过Like关键字来实现,下面进行详细介绍: 本次查询的表中数据如下: 1、使用(%)通配符 %通配符的作用是,表示任意字符出现任意次数…...

局域网聊天室终极解决方案:无需互联网的即时通讯工具
局域网聊天室终极解决方案:无需互联网的即时通讯工具 【免费下载链接】LAN-Chat-Room 😉基于QT开发的局域网聊天室 项目地址: https://gitcode.com/gh_mirrors/la/LAN-Chat-Room 在办公室、学校或家庭网络中,你是否曾遇到过需要快速分…...
在工程优化中的应用)
电磁场仿真实战——5. 有限元法(FEM)在工程优化中的应用
1. 有限元法(FEM)在电磁场仿真中的核心价值 想象一下你正在设计一台新型电机,需要精确计算内部电磁场的分布。传统解析方法面对复杂几何结构时束手无策,而有限元法就像把整个电机拆解成无数个"乐高积木",在每…...

如何通过MobaXterm中文版快速构建一体化远程管理环境
如何通过MobaXterm中文版快速构建一体化远程管理环境 【免费下载链接】Mobaxterm-Chinese Mobaxterm simplified Chinese version. Mobaxterm 的简体中文版. 项目地址: https://gitcode.com/gh_mirrors/mo/Mobaxterm-Chinese 远程管理工具的选择常常让系统管理员和开发者…...

二进制逆向新选择:Binary Ninja核心功能与实战指南
二进制逆向新选择:Binary Ninja核心功能与实战指南 【免费下载链接】deprecated-binaryninja-python Deprecated Binary Ninja prototype written in Python 项目地址: https://gitcode.com/gh_mirrors/de/deprecated-binaryninja-python 一、定位解析&#…...

DeepAnalyze模型量化部署实战:减小50%显存占用
DeepAnalyze模型量化部署实战:减小50%显存占用 1. 引言 你是不是遇到过这样的情况:好不容易找到一个强大的AI模型,比如最近很火的DeepAnalyze数据分析大模型,结果发现自己的显卡根本跑不起来?8GB显存的消费级显卡只能…...

MySQL数据库备份实战:全量、增量、差异备份到底怎么选?
MySQL数据库备份实战:全量、增量、差异备份到底怎么选? 作为数据库管理员,每天最担心的莫过于数据丢失。记得去年我们团队遇到过一次硬盘故障,当时如果没有完善的备份策略,后果不堪设想。选择正确的备份方式不仅关系到…...

终极指南:MFE-starter如何让Angular与React和平共存的实战方案
终极指南:MFE-starter如何让Angular与React和平共存的实战方案 【免费下载链接】MFE-starter MFE Starter 项目地址: https://gitcode.com/gh_mirrors/mf/MFE-starter 在现代前端开发中,框架冲突是许多开发者面临的头疼问题,尤其是当项…...

2026届必备的十大降AI率助手推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 于内容创作里,将 AI 生成率予以降低的关键之处在于把机器输出的规整性还有重复性…...

猫抓扩展专业配置指南:提升资源嗅探效率的四大核心策略
猫抓扩展专业配置指南:提升资源嗅探效率的四大核心策略 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 猫抓(cat-catch)作为一款强大的…...

granite-4.0-h-350m效果展示:中英双语问答、代码补全、文本摘要三连击
granite-4.0-h-350m效果展示:中英双语问答、代码补全、文本摘要三连击 今天带大家看看一个轻量级但能力不俗的AI模型——granite-4.0-h-350m。这个模型虽然只有3.5亿参数,但在多个任务上的表现却让人眼前一亮。我用Ollama部署了它的文本生成服务&#x…...