Oracle作业调度器Job Scheduler
Oracle数据库调度器 (Oracle Database Scheduler)
- 在数据库管理系统中,数据库调度器负责调度和执行数据库中的存储过程、触发器、事件等。
- 它可以确保这些操作在正确的时间和条件下得到执行,以满足业务需求。
1、授权用户权限
-- 创建目录对象 tmp_dir
CREATE OR REPLACE DIRECTORY tmp_dir AS '/tmp';
-- 授予用户权限
GRANT READ,WRITE ON DIRECTORY tmp_dir TO hr;
GRANT CREATE JOB TO hr;
GRANT CREATE EXTERNAL JOB TO hr;
2、创建一个测试表
创建一个测试表 t_job_oggdata
conn hr/hr@orclCREATE TABLE t_job_oggdata
( scheduler_ID NUMBER CONSTRAINT PK_t_job_oggdata_ID PRIMARY KEY,Infoment VARCHAR2(50),sysguid VARCHAR(50) DEFAULT sys_guid(), createDT DATE DEFAULT SYSDATE,CONSTRAINT UQ_uniqueKeyguid UNIQUE(sysguid)
);
3、创建序列SEQUENCE及存储过程PROCEDURE
创建序列SEQUENCE SEQ_t_job_oggdataID 及存储过程PROCEDURE P_TestSchedulerJobs
-- 创建序列SEQUENCE SEQ_t_job_oggdataID
CREATE SEQUENCE SEQ_t_job_oggdataID MINVALUE 1 MAXVALUE 999999999999 START WITH 1 CYCLE NOCACHE;-- 创建存储过程PROCEDURE P_TestSchedulerJobs
CREATE OR REPLACE PROCEDURE P_TestSchedulerJobs
AS
BEGININSERT INTO t_job_oggdata(scheduler_ID,Infoment) VALUES (SEQ_t_job_oggdataID.nextval,SEQ_t_job_oggdataID.currval||'_scheduler_jobs_ID ');COMMIT;
END P_TestSchedulerJobs;
/
4、创建一个 SCHEDULER Job(创建 JOb 默认不运行)
创建一个 SCHEDULER Job,时间间隔为每分钟执行一次
BEGINDBMS_SCHEDULER.CREATE_JOB(JOB_NAME => 'AddSchedulerJobs',JOB_TYPE => 'stored_procedure',JOB_ACTION => 'P_TestSchedulerJobs',START_DATE => SYSDATE,REPEAT_INTERVAL => 'FREQ=MINUTELY;INTERVAL=1');
END;
/
5、查询 scheduler JOB
-- sys用户查
select * from dba_scheduler_jobs where owner=UPPER('sys') AND job_name=UPPER('AddSchedulerJobs');-- hr用户查
select * from user_scheduler_jobs where job_name=UPPER('AddSchedulerJobs');select * from t_job_oggdata;
6、使用 scheduler 管理 JOB
6.1、启动 JOB
begindbms_scheduler.enable('AddSchedulerJobs');
end;
/PL/SQL procedure successfully completed.-- hr用户下查user_scheduler_jobs
HR@ORCL> col JOB_NAME format a30
HR@ORCL> select JOB_NAME,ENABLED from user_scheduler_jobs where job_name=UPPER('AddSchedulerJobs');JOB_NAME ENABLED
------------------------------ ---------------
ADDSCHEDULERJOBS TRUE-- sys用户下查dba_scheduler_jobs
select JOB_NAME,ENABLED from dba_scheduler_jobs where owner=UPPER('hr') AND job_name=UPPER('AddSchedulerJobs');HR@ORCL> col INFOMENT format a30
HR@ORCL> col SYSGUID format a36
HR@ORCL> select * from t_job_oggdata;SCHEDULER_ID INFOMENT SYSGUID CREATEDT
------------ ------------------------------ ------------------------------------ -------------------1 1_scheduler_jobs_ID 1A0D38A2BDFCD321E063E650A8C0EE7F 2024-06-04 16:27:322 2_scheduler_jobs_ID 1A0D38A2BDFDD321E063E650A8C0EE7F 2024-06-04 16:28:323 3_scheduler_jobs_ID 1A0D3FCA1BDCD323E063E650A8C00246 2024-06-04 16:29:324 4_scheduler_jobs_ID 1A0D38A2BDFED321E063E650A8C0EE7F 2024-06-04 16:30:32查看启动时间和下次执行时间
-- sys as sysdba
select JOB_NAME,ENABLED,to_char(START_DATE,'yyyy-mm-dd hh24:mi:ss') as start_date,to_char(NEXT_RUN_DATE,'yyyy-mm-dd hh24:mi:ss') as next_run_date
from dba_scheduler_jobs where owner=UPPER('hr') AND job_name=UPPER('AddSchedulerJobs');-- OR schema hr
select JOB_NAME,ENABLED,to_char(START_DATE,'yyyy-mm-dd hh24:mi:ss') as start_date,to_char(NEXT_RUN_DATE,'yyyy-mm-dd hh24:mi:ss') as next_run_date
from user_scheduler_jobs where job_name=UPPER('AddSchedulerJobs');查看执行的详细信息
HR@ORCL> col LOG_DATE format a30
HR@ORCL> col STATUS format a10
HR@ORCL> col ACTUAL_START_DATE format a30
HR@ORCL> col ADDITIONAL_INFO format a50
HR@ORCL> col RUN_DURATION format a30
HR@ORCL> select owner,job_name,to_char(log_date,'yyyy-mm-dd hh24:mi:ss') as log_date,status,RUN_DURATION,to_char(ACTUAL_START_DATE,'yyyy-mm-dd hh24:mi:ss') as actual_start_date,ADDITIONAL_INFOfrom user_scheduler_job_run_details;OWNER JOB_NAME LOG_DATE STATUS RUN_DURATION ACTUAL_START_DATE ADDITIONAL_INFO
------------------------------ ------------------------------ ------------------------------ ---------- ------------------------------ ------------------------------ --------------------------------------------------
TESTUSER ADDSCHEDULERJOBS 2024-06-04 16:27:32 SUCCEEDED +000 00:00:00 2024-06-04 16:27:32
TESTUSER ADDSCHEDULERJOBS 2024-06-04 16:28:32 SUCCEEDED +000 00:00:00 2024-06-04 16:28:32
TESTUSER ADDSCHEDULERJOBS 2024-06-04 16:30:32 SUCCEEDED +000 00:00:00 2024-06-04 16:30:32
TESTUSER ADDSCHEDULERJOBS 2024-06-04 16:31:32 SUCCEEDED +000 00:00:00 2024-06-04 16:31:32
TESTUSER ADDSCHEDULERJOBS 2024-06-04 16:32:32 SUCCEEDED +000 00:00:00 2024-06-04 16:32:32
TESTUSER ADDSCHEDULERJOBS 2024-06-04 16:33:32 SUCCEEDED +000 00:00:00 2024-06-04 16:33:32
TESTUSER ADDSCHEDULERJOBS 2024-06-04 16:29:32 SUCCEEDED +000 00:00:00 2024-06-04 16:29:32
TESTUSER ADDSCHEDULERJOBS 2024-06-04 16:36:48 SUCCEEDED +000 00:00:00 2024-06-04 16:36:488 rows selected.6.2、禁用 JOB
begindbms_scheduler.disable('AddSchedulerJobs');
end;
/PL/SQL procedure successfully completed.6.3、执行 JOB
-- 查询测试表中的数据
HR@ORCL> select * from t_job_oggdata;SCHEDULER_ID INFOMENT SYSGUID CREATEDT
------------ ------------------------------ ------------------------------------ -------------------1 1_scheduler_jobs_ID 1A0D38A2BDFCD321E063E650A8C0EE7F 2024-06-04 16:27:322 2_scheduler_jobs_ID 1A0D38A2BDFDD321E063E650A8C0EE7F 2024-06-04 16:28:323 3_scheduler_jobs_ID 1A0D3FCA1BDCD323E063E650A8C00246 2024-06-04 16:29:324 4_scheduler_jobs_ID 1A0D38A2BDFED321E063E650A8C0EE7F 2024-06-04 16:30:325 5_scheduler_jobs_ID 1A0D38A2BDFFD321E063E650A8C0EE7F 2024-06-04 16:31:326 6_scheduler_jobs_ID 1A0D38A2BE00D321E063E650A8C0EE7F 2024-06-04 16:32:327 7_scheduler_jobs_ID 1A0D38A2BE01D321E063E650A8C0EE7F 2024-06-04 16:33:327 rows selected.-- 执行 JOB
BEGINDBMS_SCHEDULER.RUN_JOB('AddSchedulerJobs');
END;
/PL/SQL procedure successfully completed.-- 查询测试表中的数据
HR@ORCL> select * from test_scheduler_job;SCHEDULER_ID INFOMENT SYSGUID CREATEDT
------------ ------------------------------ ------------------------------------ -------------------1 1_scheduler_jobs_ID 1A0D38A2BDFCD321E063E650A8C0EE7F 2024-06-04 16:27:322 2_scheduler_jobs_ID 1A0D38A2BDFDD321E063E650A8C0EE7F 2024-06-04 16:28:323 3_scheduler_jobs_ID 1A0D3FCA1BDCD323E063E650A8C00246 2024-06-04 16:29:324 4_scheduler_jobs_ID 1A0D38A2BDFED321E063E650A8C0EE7F 2024-06-04 16:30:325 5_scheduler_jobs_ID 1A0D38A2BDFFD321E063E650A8C0EE7F 2024-06-04 16:31:326 6_scheduler_jobs_ID 1A0D38A2BE00D321E063E650A8C0EE7F 2024-06-04 16:32:327 7_scheduler_jobs_ID 1A0D38A2BE01D321E063E650A8C0EE7F 2024-06-04 16:33:328 8_scheduler_jobs_ID 1A0D1928BA26D2ACE063E650A8C04D90 2024-06-04 16:36:488 rows selected.在许多应用程序和系统中,开发人员可能会根据特定需求创建自定义的调度器来管理和调度任务。这些自定义调度器可以根据应用程序的特定逻辑和规则来选择自动或手动执行。
6.4、删除 JOB
BEGINDBMS_SCHEDULER.DROP_JOB('AddSchedulerJobs');
END;
/
再次查询user_scheduler_jobs ,发现已经没有这个 scheduler jobs
HR@ORCL> select JOB_NAME,ENABLED from user_scheduler_jobs where job_name=UPPER('AddSchedulerJobs');no rows selected
7、JOB 的时间使用总结
7.1、关于 job 运行时间 计算方法:
select TRUNC(sysdate) + 1 +2/(24) from dual;
7.2、每分钟执行
Interval => TRUNC(sysdate,'mi') + 1/(24*60)
7.3、每天定时执行
每天的凌晨 1 点执行
Interval => TRUNC(sysdate) + 1 +1/(24)
每天的凌晨 2 点执行
Interval => TRUNC(sysdate) + 1 +2/(24)
当前时间间隔2 天
Interval => TRUNC(sysdate) + 2 +1/(24)
7.4、每周定时执行
例如:每周一凌晨 1 点执行
Interval => TRUNC(next_day(sysdate,'Mon'))+1/24
7.5、每月定时执行
例如:每月 1 日凌晨 1 点执行
Interval =>TRUNC(LAST_DAY(SYSDATE))+1+1/24
7.6、每季度定时执行
例如每季度的第一天凌晨 1 点执行
Interval => TRUNC(ADD_MONTHS(SYSDATE,3),'Q') + 1/24
7.7、每半年定时执行
例如:每年 7 月 1 日和 1 月 1 日凌晨 1 点
Interval => TRUNC(ADD_MONTHS(SYSDATE,3),'Q') + 1/24Interval => TRUNC(SYSDATE, 'YEAR') + 1/24
相关文章:

Oracle作业调度器Job Scheduler
Oracle数据库调度器 (Oracle Database Scheduler) 在数据库管理系统中,数据库调度器负责调度和执行数据库中的存储过程、触发器、事件等。它可以确保这些操作在正确的时间和条件下得到执行,以满足业务需求。 1、授权用户权限 -- 创建目录对象 tmp_dir…...

Vue 组件之间的通信
在 Vue.js 中,组件是构建应用程序的基本单位。然而,当你的应用程序变得复杂时,组件之间的通信变得至关重要。本文将介绍几种 Vue 组件之间通信的方式,帮助你更好地管理和组织代码。 父子组件通信 父组件可以通过 props 向子组件传…...

Elementary OS 7.1简单桌面调整
Elementary OS的Pantheon桌面环境提供了一种非常独特和直观的用户体验。默认情况下,Pantheon桌面并没有提供传统的窗口最小化、最大化按钮。但是可以通过安装和使用特定的工具来调整和自定义这些设置。 可以通过以下步骤来启用窗口的最小化和最大化按钮:…...

【C++ | 析构函数】类的析构函数详解
😁博客主页😁:🚀https://blog.csdn.net/wkd_007🚀 🤑博客内容🤑:🍭嵌入式开发、Linux、C语言、C、数据结构、音视频🍭 ⏰发布时间⏰:2024-06-06 1…...

ceph radosgw 原有zone placement信息丢失数据恢复
概述 近期遇到一个故障环境,因为某些原因,导致集群原有zone、zonegroup等信息丢失(osd,pool等状态均健康)。原有桶和数据无法访问,经过一些列fix后修复, 记录过程 恢复realm和pool相关信息 重…...

【动手学深度学习】残差网络(ResNet)的研究详情
目录 🌊1. 研究目的 🌊2. 研究准备 🌊3. 研究内容 🌍3.1 残差网络 🌍3.2 练习 🌊4. 研究体会 🌊1. 研究目的 了解残差网络(ResNet)的原理和架构;探究残…...

freertos初体验 - 在stm32上移植
1. 说明 freertos内核 非常精简,代码量也很少,官方也针对主流的编译器和内核准备好了移植文件,所以 freertos 的移植是非常简单的,很多工具(例如CubeMX)点点鼠标就可以生成一个 freertos 的工程࿰…...

ubuntu使用 .deb 文件安装VScode
使用 .deb 文件安装 下载 VSCode 的 .deb 文件: wget -q https://go.microsoft.com/fwlink/?LinkID760868 -O vscode.deb使用 dpkg 安装: sudo dpkg -i vscode.deb如果有依赖项问题,使用以下命令修复: sudo apt-get install -f...
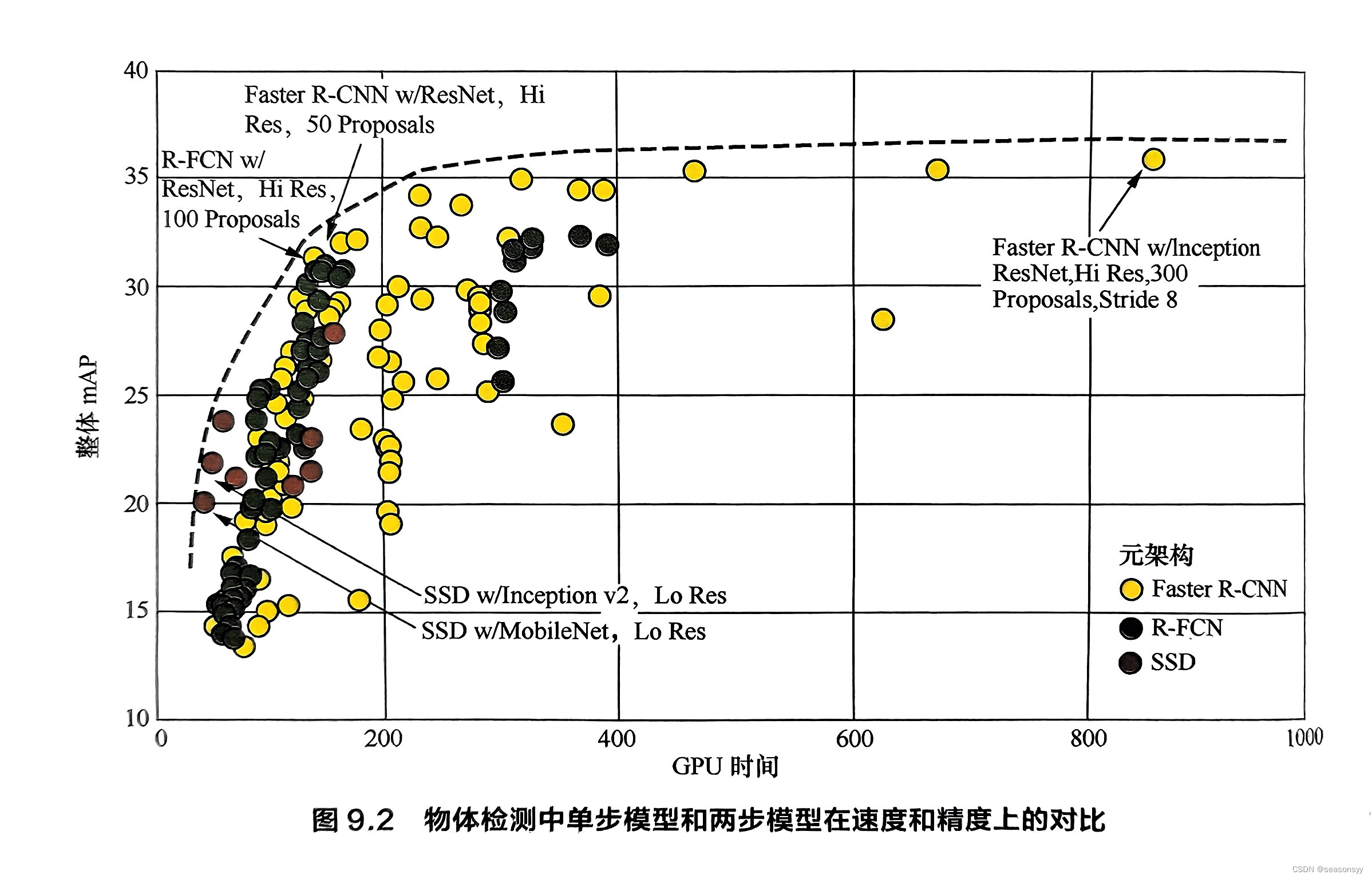
9.1.1 简述目标检测领域中的单阶段模型和两阶段模型的性能差异及其原因
9.1目标检测 场景描述 目标检测(Object Detection)任务是计算机视觉中极为重要的基础问题,也是解决实例分割(Instance Segmentation)、场景理解(Scene Understanding)、目标跟踪(Ob…...

系统化自学Python的实用指南
目录 一、理解Python与设定目标 二、搭建学习环境与基础准备 三、入门学习阶段 四、中级进阶阶段 五、项目实践与持续深化 六、持续学习与拓展 一、理解Python与设定目标 Python概述:详细介绍Python的历史沿革、设计理念、主要特点(如易读、易维护…...

加密货币初创企业指南:如何寻找代币与市场的契合点
撰文:Mark Beylin,Boost VC 编译:Yangz,Techub News 原文来源:香港Web3媒体Techub News 在 Y Combinator 创始人 Paul Graham 《Be Good》一文中概述了初创企业如何找到产品与市场契合点的方法,即制造人…...

【十二】图解mybatis日志模块之设计模式
图解mybatis日志模块之设计模式 概述 最近经常在思考研发工程师初、中、高级工程师以及系统架构师各个级别的工程师有什么区别,随着年龄增加我们的技术级别也在提升,但是很多人到了高级别反而更加忧虑,因为it行业35岁年龄是个坎这是行业里的共…...
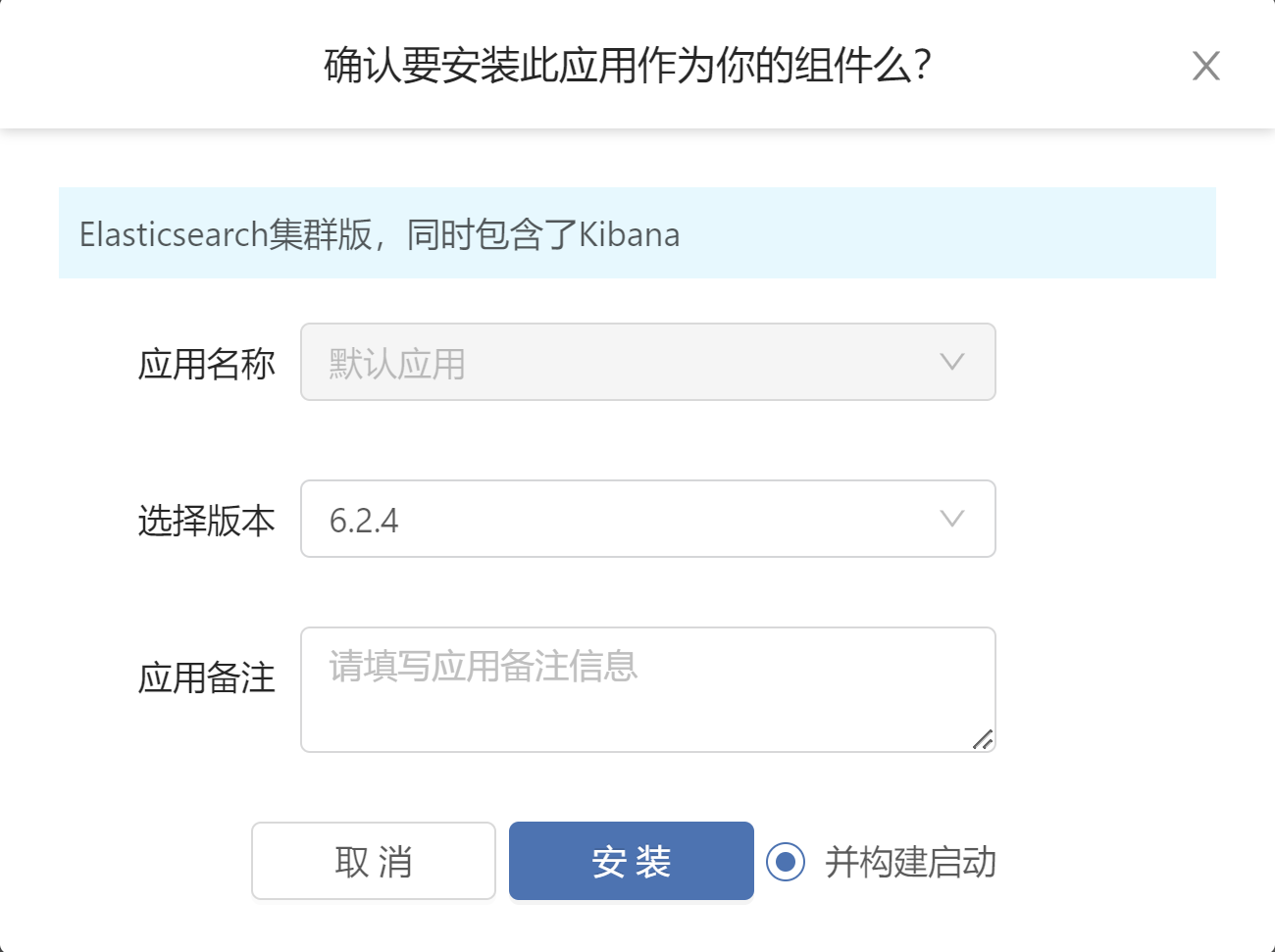
RainBond 制作应用并上架【以ElasticSearch为例】
文章目录 安装 ElasticSearch 集群第 1 步:添加组件第 2 步:查看组件第 3 步:访问组件制作 ElasticSearch 组件准备工作ElasticSearch 集群原理尝试 Helm 安装 ES 集群RainBond 制作 ES 思路源代码Dockerfiledocker-entrypoint.shelasticsearch.yml制作组件第 1 步:添加组件…...
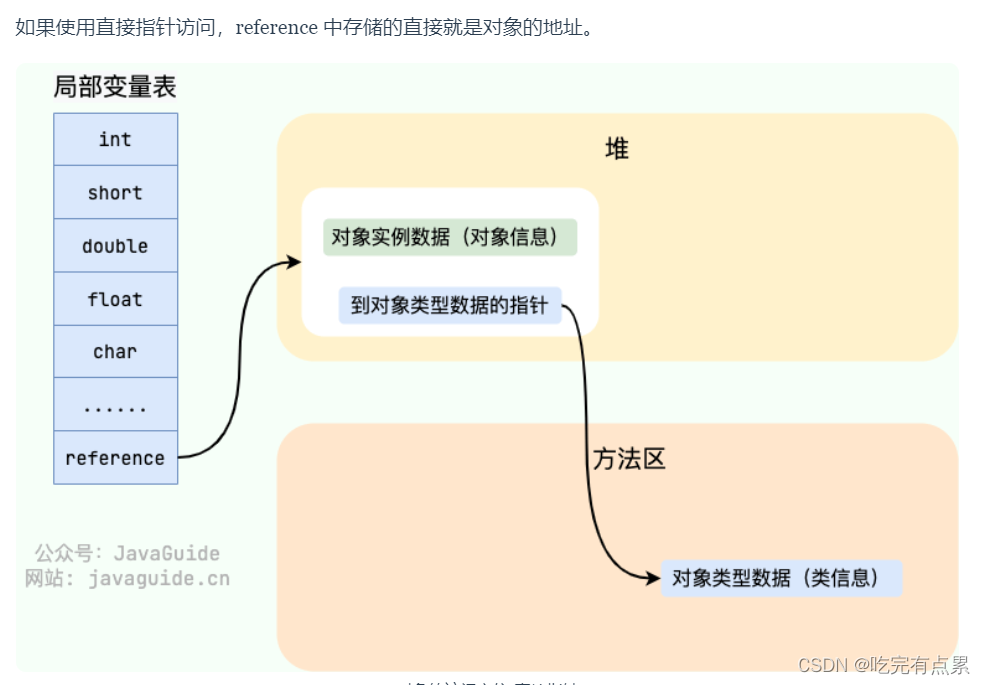
JVM相关:Java内存区域
Java 虚拟机(JVM)在执行 Java 程序的过程中会把它管理的内存划分成若干个不同的数据区域。 Java运行时数据区域是指Java虚拟机(JVM)在执行Java程序时,为了管理内存而划分的几个不同作用域。这些区域各自承担特定的任务,…...
【C++】─篇文章带你熟练掌握 map 与 set 的使用
目录 一、关联式容器二、键值对三、pair3.1 pair的常用接口说明3.1.1 [无参构造函数](https://legacy.cplusplus.com/reference/utility/pair/pair/)3.1.2 [有参构造函数 / 拷贝构造函数](https://legacy.cplusplus.com/reference/utility/pair/pair/)3.1.3 [有参构造函数](htt…...
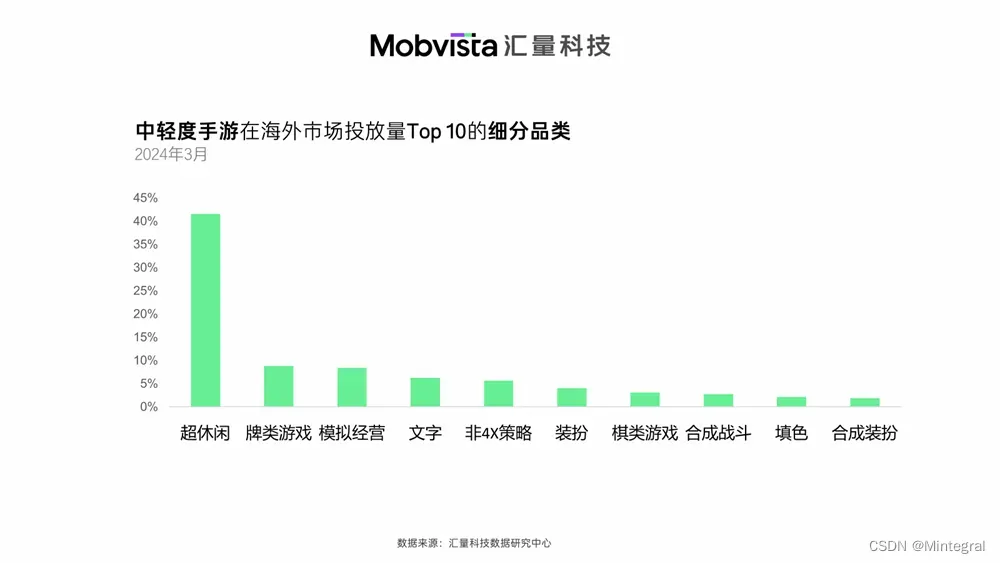
Mintegral数据洞察:全球中轻度游戏市场与创意更新频率
基于2024年3月大盘数据,汇量科技数据研究中心发现,超休闲品类仍是投流中轻度手游的中流砥柱。而投流力度较大的其他细分品类里,可以看到棋牌、模拟经营、非4X策略以及合成X游戏的身影,这些品类是近年来经常出现融合玩法的新兴赛道…...
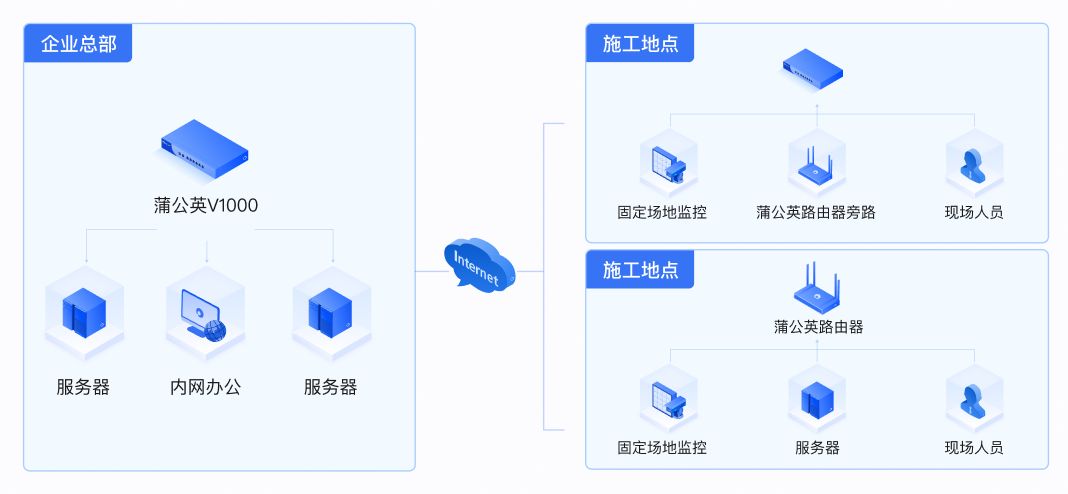
贝锐蒲公英异地组网:降低建筑工地远程视频监控成本、简化运维
中联建设集团股份有限公司是一家建筑行业的施工单位,专注于建筑施工,业务涉及市政公用工程施工总承包、水利水电工程施工总承包、公路工程施工总承包、城市园林绿化专业承包等,在全国各地开展有多个建筑项目,并且项目时间周期可能…...

大模型训练学习笔记
目录 大模型的结构主要分为三种 大模型分布式训练方法主要包括以下几种: token Token是构成句子的基本单元 1. 词级别的分词 2. 字符级别的分词 结巴分词 GPT-3/4训练流程 更细致的教程,含公式推理 大模型的结构主要分为三种 Encoder-only(自编…...

Linux C/C++时间操作
C11提供了操作时间的库chrono库,从语言级别提供了支持chrono库屏蔽了时间操作的很多细节,简化了时间操作 Unix操作系统根据计算机产生的年代把1970年1月1日作为UNIX的纪元时间,1970年1月1日是时间的中间点,将从1970年1月1日起经过…...

AI绘画工具
AI绘画工具:技术与艺术的完美融合 一、引言 随着人工智能技术的飞速发展,AI绘画工具作为艺术与技术结合的产物,已经逐渐从科幻的概念变成了现实。这些工具不仅改变了传统绘画的创作方式,还为人们带来了全新的艺术体验。本文将详…...
)
Qwen3-14B快速上手教程:命令行推理+参数详解(temperature/max_length)
Qwen3-14B快速上手教程:命令行推理参数详解(temperature/max_length) 1. 镜像概述与环境准备 Qwen3-14B是通义千问推出的大语言模型,本教程将指导您快速上手使用专为RTX 4090D 24GB显存优化的私有部署镜像。这个镜像已经预装了所…...

AI风口来袭!转型LLM应用开发工程师,非常详细收藏我这一篇就够了
一、引言:AI时代下的新职业机遇 近年来,随着人工智能技术的快速发展,尤其是大语言模型(Large Language Models, LLM)的突破,软件行业正在经历深刻变革。以GPT系列模型为代表的技术,使自然语言理…...

ESP32智能硬件开发实战指南:从环境搭建到AI功能落地
ESP32智能硬件开发实战指南:从环境搭建到AI功能落地 【免费下载链接】xiaozhi-esp32 An MCP-based chatbot | 一个基于MCP的聊天机器人 项目地址: https://gitcode.com/GitHub_Trending/xia/xiaozhi-esp32 如何在复杂的硬件开发中快速实现AI功能集成…...

深入解析CC Switch架构:构建AI开发工具统一管理引擎
深入解析CC Switch架构:构建AI开发工具统一管理引擎 【免费下载链接】cc-switch A cross-platform desktop All-in-One assistant tool for Claude Code, Codex, OpenCode, openclaw & Gemini CLI. 项目地址: https://gitcode.com/GitHub_Trending/cc/cc-swit…...

PasteMD免配置环境:Docker镜像封装,3条命令完成私有化AI格式化服务部署
PasteMD免配置环境:Docker镜像封装,3条命令完成私有化AI格式化服务部署 1. 项目简介:剪贴板智能美化工具 PasteMD是一个完全私有化的AI文本格式化工具,它基于Ollama本地大模型运行框架和强大的llama3:8b模型构建。这个工具的核心…...
)
树莓派4B避坑指南:手把手教你安装兼容的Miniconda 4.9.2(aarch64版)
树莓派4B避坑指南:手把手教你安装兼容的Miniconda 4.9.2(aarch64版) 树莓派4B作为一款高性能的单板计算机,凭借其强大的aarch64架构和丰富的扩展能力,成为众多开发者和爱好者的首选。然而,在安装Miniconda这…...

Ultimate ASI Loader深度解析:构建Windows游戏插件生态系统的技术实践
Ultimate ASI Loader深度解析:构建Windows游戏插件生态系统的技术实践 【免费下载链接】Ultimate-ASI-Loader The Ultimate ASI Loader is a proxy DLL that loads custom .asi libraries into any game process. 项目地址: https://gitcode.com/gh_mirrors/ul/Ul…...

FastAPI CSP:实现配置的终极指南
FastAPI CSP:实现配置的终极指南 【免费下载链接】fastapi FastAPI framework, high performance, easy to learn, fast to code, ready for production 项目地址: https://gitcode.com/GitHub_Trending/fa/fastapi FastAPI是一个高性能、易于学习、快速编码…...

linux https拦截与url解析
uprobe 拦截TLS库 用 eBPF uprobe 拦截 TLS 库(OpenSSL/GnuTLS/Go TLS),在加密前 / 解密后捕获明文 HTTP 请求,即可解析出 HTTPS URL,无需 CA 证书、无需修改应用。 核心原理 HTTPS 明文(含 URL…...

iOS开发效率工具:设备支持文件管理完全指南 - 无需升级Xcode的解决方案
iOS开发效率工具:设备支持文件管理完全指南 - 无需升级Xcode的解决方案 【免费下载链接】iOSDeviceSupport All versions of iOS Device Support 项目地址: https://gitcode.com/gh_mirrors/ios/iOSDeviceSupport 作为iOS开发者,你是否曾遭遇这样…...