自然语言处理:第三十三章FILCO:过滤内容的RAG
文章链接: [2311.08377] Learning to Filter Context for Retrieval-Augmented Generation (arxiv.org)
项目地址: zorazrw/filco: [Preprint] Learning to Filter Context for Retrieval-Augmented Generaton (github.com)
在人工智能领域,尤其是在开放域问答和事实验证等任务中,即时检索相关知识是构建可靠系统的关键因素。然而,由于检索系统并非完美,生成模型在面对部分或完全无关的段落时仍需生成输出,这可能导致对上下文的过度或不足依赖,并在生成的输出中产生幻觉等问题。为了缓解这些问题,提出了一种名为FILCO的方法,该方法通过(1)基于词汇和信息论方法识别有用的上下文,以及(2)训练上下文过滤模型以便在测试时过滤检索到的上下文。在六个知识密集型任务中使用FLAN-T5和LLaMa2模型进行实验,证明了FILCO方法在提取式问答(QA)、复杂多跳和长形QA、事实验证以及对话生成任务上优于现有方法。FILCO有效地提高了上下文的质量,无论其是否支持规范输出。
背景
检索增强型生成方法已被证明对于许多知识密集型语言任务是有效的,它们能够产生更忠实、可解释和可泛化的输出。尽管检索系统通常将检索到的顶级段落无条件地提供给生成模型,但这些系统往往返回不相关或分散注意力的内容。这导致生成模型在训练时容易产生幻觉或虚假记忆:
- 过度依赖上下文 :生成模型可能会过度依赖检索到的段落,即使这些段落包含分散注意力的内容或与问题仅有微弱关联。
- 幻觉和错误记忆 :由于检索系统返回的内容不准确或不相关,生成模型可能会产生幻觉,即生成与真实情况不符的信息,或产生错误记忆,即使用错误信息生成输出。
FILCO(Filtering Context for Retrieval-Augmented Generation)方法针对上述问题提出了创新的解决方案,通过以下两个方面显著提升了性能:
- 上下文的精细过滤 :FILCO通过细粒度的句子级别过滤检索到的上下文,而非整个段落,从而更精确地提供对生成任务有用的信息。
- 过滤模型的训练 :FILCO训练了一个上下文过滤模型(Mctx),该模型能够在测试时动态过滤检索到的上下文,确保生成模型(Mgen)接收到的信息是相关且有用的。
核心算法
FILCO的核心思想如下图,主要的pipeline也是分成两部分
- 是在细粒度的句子级别上学习过滤检索到的上下文,简单的来说就是通过计算query 和 向量数据库的相似度召回top_k相关文档后,训练一个专属的过滤模型(Mctx)对召回的文档进行精简/过滤 (ps: 有点像之前说的Corrective RAG)
- 然后再将过滤完的文档输入给生成模型(Mgen)进行回答。
下面会分别的对这两部分模型进行介绍
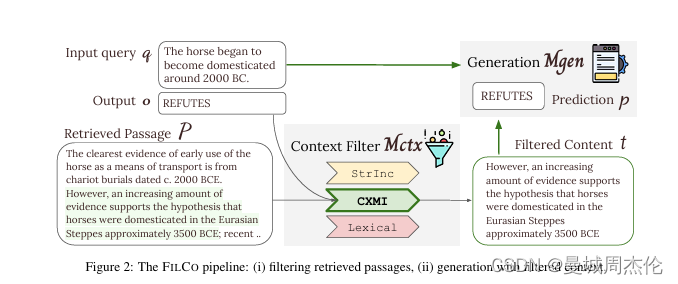
上下文过滤模型(Mctx)
FILCO训练了一个上下文过滤模型(Mctx),使用上述三种度量方法过滤检索到的上下文。(i)STRINC:段落是否包含生成输出;(ii)词汇重叠:内容和输出之间有多少单字重叠;(iii)条件交叉互信息(CXMI):当提供内容时,生成器生成输出的可能性增加多少。FILCO训练上下文过滤模型Mctx,使用这三种度量方法过滤检索到的上下文,并学习在过滤上下文中生成输出。训练数据是通过将检索到的段落和查询作为输入,然后应用过滤方法获得过滤后的上下文(tsilver)。Mctx 原始输入是问题query + 检索召回的上下文 , 最后的输出就是过滤后的上下文
-
数据准备:
- 对于每个训练样本,使用检索系统(如Dense Passage Retriever,DPR)从知识库(如Wikipedia)中检索相关的文档或段落,并将其与查询一起作为输入。
-
过滤算法选择:
三种过滤策略(STRINC、LEXICAL、CXMI)选择最优的文本片段。
-
字符串包含(String Inclusion, STRINC):
- STRINC是一种基于词汇的简单过滤方法,它检查检索到的文本片段是否包含生成输出的确切文本。
- 该方法通过枚举检索到的段落,并选择第一个包含输出文本的文本片段。
-
词汇重叠(Lexical Overlap):
- 该策略通过计算示例和候选文本片段之间的单字重叠来评估它们之间的主题相似性。
- 对于问答(QA)和对话生成任务,它使用F1分数来衡量文本片段和输出之间的相似度。
- 对于事实验证任务,由于输出是一个二元标签,它使用查询和文本片段之间的F1分数。
-
条件交叉互信息(Conditional Cross-Mutual Information, CXMI):
- CXMI是一种基于信息论的方法,用于衡量在给定上下文的情况下,生成模型生成期望输出的概率变化。 该策略选择具有最高CXMI分数的文本片段,因为它们最有可能增加生成正确输出的概率。下图是作者关于CXMI的算法图解
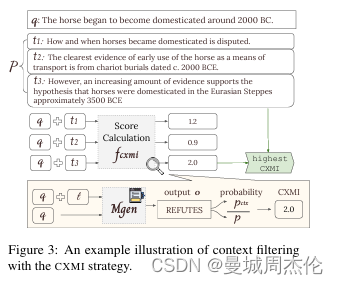
-
-
过滤上下文:
- 应用选择的过滤策略,从检索到的段落中生成过滤后的上下文(tsilver)。这是非完美的过滤结果,因为真实的输出标签在训练时是未知的。
-
模型训练:
- 训练Mctx,使其能够基于查询和检索到的段落生成过滤后的上下文tsilver。这个过程可以形式化为:[ M_{ctx}(t_{silver} | q \oplus P) ],其中( q )是查询,( P )是检索到的段落,( t_{silver} )是过滤后的上下文。
生成模型(Mgen)
在训练时,FILCO将过滤后的上下文(tsilver)预处理到查询中,然后输入到生成模型(Mgen)进行训练,以输出规范的响应。在推理时,使用Mctx预测过滤后的上下文(tpred),然后将其与查询一起提供给Mgen以预测输出。
- 准备输入:
- 将过滤后的上下文tsilver预处理到查询q的前面,形成模型的输入( q \oplus t_{silver} )。
-
训练生成模型:
- 使用上述输入训练Mgen生成规范的输出o。这个过程可以形式化为:[ M_{gen}(o | t_{silver} \oplus q) ]。
-
推理:
- 在推理时,使用训练好的Mctx模型为每个测试查询q预测过滤后的上下文tpred:[ tpred = M_{ctx}(q \oplus P) ]。
- 然后将tpred与查询q一起提供给Mgen,以预测输出:[ M_{gen}(o | tpred \oplus q) = M_{gen}(o | M_{ctx}(q, P) \oplus q) ]。
训练细节如下:
- 模型架构:FLAN-T5和LLAMA2作为Mctx和Mgen的模型架构,因其在开源模型中的潜在优越性能。
- 序列长度:所有序列的最大长度设置为1024个token。Mctx生成的过滤上下文最多512个token,Mgen生成的输出最多128个token。
- 解码策略:使用贪婪解码策略生成过滤上下文和最终生成输出。
- 训练周期:通常训练所有Mctx和Mgen模型3个epoch,使用学习率为5e-5,批量大小为32。
实验结果
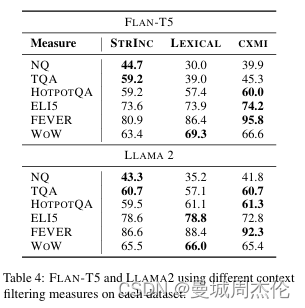
FILCO在六个知识密集型语言数据集上进行了实验,包括NaturalQuestions (NQ)、Trivia QA (TQA)、HotpotQA、ELI5、Fact Extraction and VERificaton (FEVER)以及Wizard of Wikipedia (WoW)。使用FLAN-T5和LLaMa2模型,FILCO在所有六个数据集上都优于基线方法,即全上下文增强和段落级过滤。下图事在这6个数据集上的性能,可以看到Filco 和sliver 基本都在各个数据集上能达到SOTA
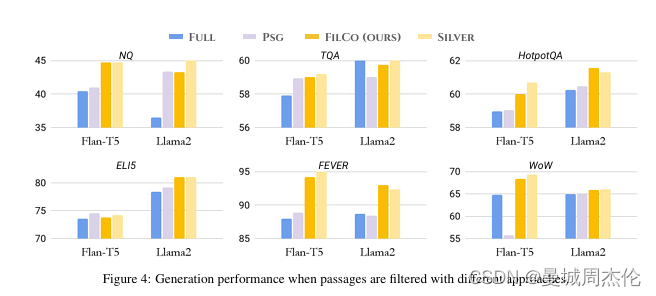
- Full: 召回top_k内容全部进行推理生成
- PSG: 基于句子场景进行部分过滤
- FILCO: 本文的算法,过滤上下文
- Silver: 迭代的算法,根据不同数据集进行微调后的算法
过滤完后的上下文不仅仅是性能上最优,并且能减少大约 4 - 6 成的内容,从而减少token消耗。
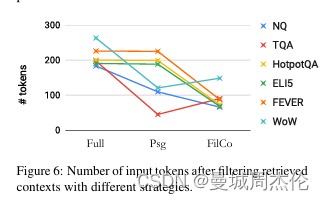
上文提到的上下文过滤模型Mctx可选三种过滤算法,其中不同算法在不同数据集上表现不同。具体如下,可以发现对于随着任务难度的增加,STRINC、LEXICAL、CXMI 算法逐渐更适合用于过滤上下文。
总结
通过实验,FILCO在以下方面显示出显著的优势:
- 性能提升:FILCO在六个知识密集型任务上的性能均优于基线方法,包括提取式问答、复杂多跳问答、长形问答、事实验证和对话生成任务。
- 上下文质量改善:FILCO有效地提高了上下文的质量,无论其是否支持规范输出。
- 输入长度减少:FILCO通过过滤检索到的上下文,显著减少了模型输入的长度,平均减少了44-64%。
- 答案精度提高:过滤后的上下文在所有任务上都实现了更高的答案精度,特别是对于抽象任务,如FEVER和WoW。
FILCO的成功证明了在检索增强型生成任务中,通过这种训练方法,FILCO能够有效地训练上下文过滤模型以精确地识别和过滤有用的上下文,同时训练生成模型以在过滤后的上下文上生成高质量的输出。这种细粒度的过滤和生成过程,使得FILCO在各种知识密集型任务中表现出色,提高了输出的准确性和相关性。FILCO的成功实施为未来在更多场景中实现忠实生成提供了新的思路。 — 对于数据里有很多冲突知识的时候这个算法会很有效
引用文献
- Alon, U., Xu, F. F., He, J., Sengupta, S., Roth, D., & Neubig, G. (2022). Neuro-symbolic language modeling with automaton-augmented retrieval. In ICML 2022 Workshop on Knowledge Retrieval and Language Models.
- Asai, A., Gardner, M., & Hajishirzi, H. (2022). Evidentiality-guided generation for knowledge-intensive NLP tasks. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies.
相关文章:
自然语言处理:第三十三章FILCO:过滤内容的RAG
文章链接: [2311.08377] Learning to Filter Context for Retrieval-Augmented Generation (arxiv.org) 项目地址: zorazrw/filco: [Preprint] Learning to Filter Context for Retrieval-Augmented Generaton (github.com) 在人工智能领域,尤其是在开放域问答和事…...

js:flex弹性布局
目录 代码: 1、 flex-direction 2、flex-wrap 3、justify-content 4、align-items 5、align-content 代码: <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewp…...

Pytorch常用函数用法归纳:创建tensor张量
1.torch.arange() (1)函数原型 torch.arange(start,end,step,*,out,dtype,layout,device,requires_grad) (2)参数说明: 参数名称参数类型参数说明startNumber起始值,默认值为0endNumber结束值,取不到,为开区间stepNumber步长值࿰…...

WPF前端:一个纯Xaml的水平导航栏
效果图: 代码: 1、样式代码,可以写在窗体资源处或者样式资源文件中 <Style x:Key"MenuRadioButtonStyle" TargetType"{x:Type RadioButton}"><Setter Property"FontSize" Value"16" />…...
谷粒商城实战(033 业务-秒杀功能4-高并发问题解决方案sentinel 1)
Java项目《谷粒商城》架构师级Java项目实战,对标阿里P6-P7,全网最强 总时长 104:45:00 共408P 此文章包含第326p-第p331的内容 关注的问题 sentinel(哨兵) sentinel来实现熔断、降级、限流等操作 腾讯开源的tendis,…...

STM32项目分享:智能家居(机智云)系统
目录 一、前言 二、项目简介 1.功能详解 2.主要器件 三、原理图设计 四、PCB硬件设计 1.PCB图 2.PCB板及元器件图 五、程序设计 六、实验效果 七、资料内容 项目分享 一、前言 项目成品图片: 哔哩哔哩视频链接: https://www.bilibili.c…...

游戏盾之应用加速,何为应用加速
在数字化时代,用户对于应用程序的防护要求以及速度和性能要求越来越高。为了满足用户的期望并提高业务效率,应用加速成为了不可忽视的关键。 应用加速是新一代的智能分布式云接入系统,采用创新级SD-WAN跨域技术,针对高防机房痛点进…...

Java 基础面试题
文章目录 重载与重写抽象类与接口面向对象a a b 与 a b 的区别final、finalize、finallyString、StringBuild、StringBuffer位运算反射 重载与重写 重载:是在同一个类中,方法名相同,方法参数类型,个数不同,返回类型…...

Nginx 1.26.0 爆 HTTP/3 QUIC 漏洞,建议升级更新到 1.27.0
据悉,Nginx 1.25.0-1.26.0 主线版本中涉及四个与 NGINX HTTP/3 QUIC 模块相关的中级数据面 CVE 漏洞,其中三个为 DoS 攻击类型风险,一个为随机信息泄漏风险,影响皆为允许未经身份认证的用户通过构造请求实施攻击。目前已经紧急发布…...

uniadmin引入iconfont报错
当在uniadmin中引入iconfont后,出现错误: [plugin:vite:css] [postcss] Cannot find module ‘E:/UniAdmin/uniAdmin/static/fonts/iconfont.woff2?t1673083050786’ from ‘E:\UniAdmin\uniAdmin\static\fonts\iconfont.css’ 这是需要更改为绝对路径…...
Vue3【三】 使用TS自己编写APP组件
Vue3【三】 使用TS自己编写APP组件 运行截图 目录结构 注意目录层级 文件源码 APP.vue <template><div class"app"><h1>你好世界!</h1></div> </template><script lang"ts"> export default {name:App //组…...
数字IC后端物理验证PV | TSMC 12nm Calibre Base Layer DRC案例解析
基于TSMC 12nm ARM A55 upf flow后端设计实现训练营将于6月中旬正式开班!小班教学!目前还有3个名额,招满为止!有需要可以私信小编 ic-backend2018报名。吾爱IC社区所有训练营课程均为直播课! 这个课程支持升级成双核A…...
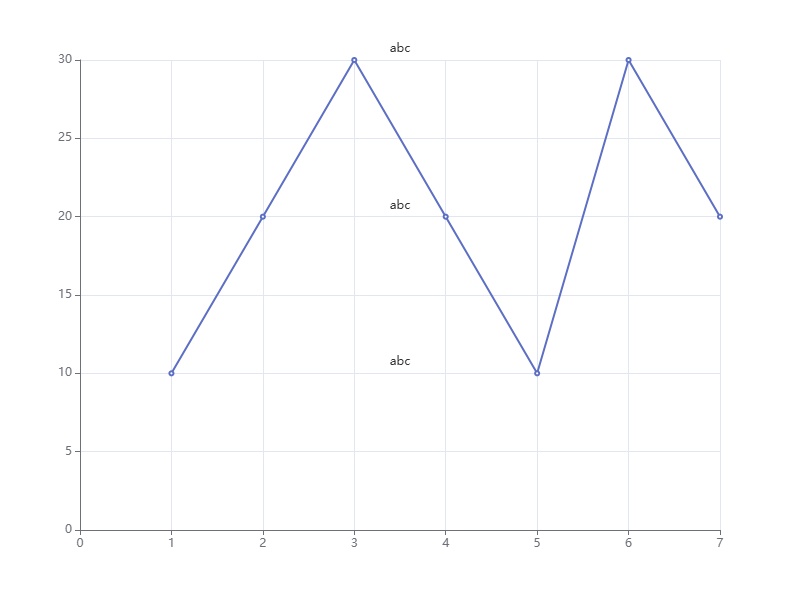
Echarts 在指定部分做文字标记
文章目录 需求分析1. demo1样式调整2. demo22. demo3 定位解决需求 实现在Echarts的折线图中,相同Y值的两点之间显示’abc’ 分析 1. demo1 使用 ECharts 的 markLine 功能来在相邻两个点之间添加标记。其中,我们通过设置标记的 yAxis 和 label 来控制标记的位置和显示内…...

如何发布自己的npm插件包
随着JavaScript在前端和后端的广泛应用,npm(Node Package Manager)已成为JavaScript开发者不可或缺的工具之一。通过npm,开发者可以轻松共享和使用各种功能模块,极大地提高了开发效率。那么,如何将自己开发的功能模块发布为npm插件包,与全球的开发者共享呢?本文将进行全…...

AI和机器人引领新一轮农业革命
AI和机器人技术在农业领域的应用正在迅速发展,未来它们可能会实现厘米级精度的自主耕作。 精确种植:AI算法可以分析土壤条件、气候数据和作物生长周期,以决定最佳种植地点和时间。 土壤管理:利用传感器和机器学习,机器…...

【Kubernetes】三证集齐 Kubernetes实现资源超卖(附镜像包)
目录 插叙前言一、思考和原理二、实现步骤0. 资料包1. TLS证书签发2. 使用 certmanager 生成签发证书3. 获取secret的内容 并替换CA_BUNDLE4.部署svc deploy 三、测试验证1. 观察pod情况2. 给node 打上不需要超售的标签【可以让master节点资源不超卖】3. 资源实现超卖4. 删除还…...

国产Sora免费体验-快手旗下可灵大模型发布
自从OpenAI公布了Sora后,震爆了全世界,但由于其技术的不成熟和应用的局限性,未能大规模推广,只有零零散散的几个公布出来的一些视频。昨日,快手成立13周年,可灵(Kling)大模型发布&am…...
linux嵌入式设备测试wifi信号强度方法
首先我们要清楚设备具体链接在哪个wifi热点上 执行:nmcli dev wifi list rootubuntu:/home/ubuntu# nmcli dev wifi list IN-USE BSSID SSID MODE CHAN RATE SIGNAL BARS > * 14:EB:08:51:7D:20 wifi22222_5G Infr…...

【名词解释】Unity的Inputfield组件及其使用示例
Unity的InputField组件是一个UI元素,它允许用户在游戏或应用程序中输入文本。InputField通常用于创建表单、登录界面或任何需要用户输入文本的场景。它提供了多种功能,比如文本验证、占位符显示、输入限制等。 功能特点: 文本输入ÿ…...

Android 安装调试 TelephonyProvider不生效
直接安装TelephonyProvider的时候,(没有重启)发现数据库没有生效。 猜测应该是原本的数据库没有删除后重建更新。 解决方法:杀掉phone进程 adb shell am force-stop com.android.phone 查看device进程 adb shell ps | grep <…...

UHP驱动器热管理:Flotherm仿真与优化实践
1. UHP高电流驱动器热设计挑战在投影仪用超高压(UHP)灯驱动器的开发中,热管理始终是制约产品小型化和功率提升的关键瓶颈。飞利浦工业技术中心的案例显示,当驱动器体积从150x73x32mm缩减到120x41x24mm时,功率密度从0.02mW/mm激增至0.18mW/mm—…...

ESXi 7.0升级后Windows Server 2022启动报错?解决安全引导与驱动兼容性实战
ESXi 7.0升级后Windows Server 2022启动报错的深度解决方案 当你在一台运行ESXi 7.0的ThinkSystem服务器上部署了Windows Server 2022虚拟机,突然某天系统更新后虚拟机无法启动,屏幕上赫然显示"找不到磁盘"的错误信息——这种场景对于任何中级…...

为AI助手打造企业级FTP/SFTP操作引擎:告别重复脚本,实现智能文件部署
1. 项目概述:为AI助手量身打造的FTP/SFTP操作引擎如果你和我一样,经常让AI助手(比如Claude、Cursor、Windsurf)帮忙写代码、部署项目,那你肯定遇到过这个让人哭笑不得的场景:AI能帮你从零开始配置一台VPS&a…...
技术:原理、优化与应用)
光学邻近校正(OPC)技术:原理、优化与应用
1. 光学邻近校正技术概述在半导体制造的光刻工艺中,光学邻近效应(Optical Proximity Effect)是影响图案转移精度的主要挑战之一。当特征尺寸缩小到45nm及以下节点时,光衍射和光阻化学反应导致的图案失真变得尤为显著。具体表现为&…...

量子纠缠蒸馏技术:原理、应用与最新进展
1. 量子纠缠蒸馏技术概述量子纠缠蒸馏(Quantum Entanglement Distillation)是量子信息科学中的一项基础性技术,其核心目标是从受噪声污染的混合态中提取出高纯度的纠缠态。这项技术最早由Bennett等人于1996年提出,现已成为构建量子…...

月薪8K到年薪80万!这个AI职位一年暴涨985%,普通人如何抓住风口?2026年最火爆的5个岗位+3条入场路径全解析!
文章讲述了AI Agent开发工程师的兴起,年薪可达80万。文章以小李的真实故事为例,展示了通过主动学习AI技术,可以实现职业的巨大转变。文章还分析了Agentic AI的特点及其对就业市场的影响,指出40%的岗位将被重新定义。文章列举了AI …...

阿里云第一季营收416亿:EBITA为38亿 同比增57%
雷递网 乐天 5月13日阿里巴巴(美股代码:“baba”,港股代号:9988)今日发布2026年第一季度的财报。财报显示,阿里2026年第一季度营收为2433.8亿元(352.83亿美元),同比增长3…...

资深工程师如何应对年龄增长带来的工作挑战:从照明优化到人体工学实践
1. 从一次生日派对说起:工程师的“年龄”与“视界”去年,我参加了一个在餐厅举办的50岁生日派对。餐厅的灯光有些昏暗,当菜单递过来时,除了我,桌上的每个人都掏出了手机,打开了LED手电筒。而在隔壁桌&#…...
)
别再只用AES了!手把手教你用Java BouncyCastle库实现SM4国密加密(附完整工具类)
国密算法实战:用Java BouncyCastle实现SM4加密的完整指南 在数据安全领域,国际通用算法长期占据主导地位,但随着技术自主可控需求的提升,国产密码算法正成为企业级应用的新选择。SM4作为我国商用密码标准体系中的重要对称加密算法…...
---ESP32-S3-RGB-LED矩阵开发板之全屏循环显示七种颜色)
【花雕学编程】Arduino动手做(252)---ESP32-S3-RGB-LED矩阵开发板之全屏循环显示七种颜色
37款传感器与模块的提法,在网络上广泛流传,其实Arduino能够兼容的传感器模块肯定是不止37种的。鉴于本人手头积累了一些传感器和执行器模块,依照实践出真知(一定要动手做)的理念,以学习和交流为目的,这里准备逐一动手试试多做实验,不管成功与否,都会记录下来——小小的…...