【QEMU中文手册】2.2 调用方式(持续更新中)
本文由 AI 翻译(ChatGPT-4)完成,并由作者进行人工校对。如有任何问题或建议,欢迎联系我。联系方式:jelin-sh@outlook.com。
原文:Invocation — QEMU documentation
qemu-system-x86_64 [选项] [磁盘镜像]
磁盘镜像是用于IDE硬盘0的原始硬盘镜像。一些目标系统不需要磁盘镜像。
当处理包含逗号的任意字符串作为选项参数时,如“file=my,file”和“string=a,b”,需要多写一个逗号。例如,“-fw_cfg name=z,string=a,b”将被解析为“-fw_cfg name=z,string=a,b”。
标准选项
-h
显示帮助信息并退出
-version
显示版本信息并退出
-machine [type=]name[,prop=value[,…]]
通过名称选择模拟的机器。使用-machine help列出可用的机器。
对于旨在支持跨版本实时迁移兼容性的架构,每个版本将引入新的版本化机器类型。例如,2.8.0版本为x86_64/i686架构引入了“pc-i440fx-2.8”和“pc-q35-2.8”机器类型。
为了允许从QEMU版本2.8.0到QEMU版本2.9.0的实时迁移,2.9.0版本必须支持“pc-i440fx-2.8”和“pc-q35-2.8”机器类型。为了允许用户在升级时跳过多个中间版本进行实时迁移,新的QEMU版本将支持多个先前版本的机器类型。
支持的机器属性有:
-
accel=accels1[:accels2[:...]]用于启用加速器。根据目标架构,可能可用的加速器有kvm、xen、hvf、nvmm、whpx或tcg。默认情况下使用tcg。如果指定了多个加速器,当前一个加速器初始化失败时将使用下一个加速器。
-
vmport=on|off|auto启用VMWare IO端口的模拟,用于vmmouse等。auto表示根据accel选择值。对于accel=xen,默认值为off,否则默认值为on。
-
dump-guest-core=on|off在核心转储中包含客体内存。默认值为on。
-
mem-merge=on|off启用或禁用内存合并支持。当主机支持此功能时,该特性会在VM实例之间去重相同的内存页(默认启用)。
-
aes-key-wrap=on|off启用或禁用s390-ccw主机上的AES密钥包装支持。此功能控制是否创建AES包装密钥以允许执行AES加密功能。默认值为on。
-
dea-key-wrap=on|off启用或禁用s390-ccw主机上的DEA密钥包装支持。此功能控制是否创建DEA包装密钥以允许执行DEA加密功能。默认值为on。
-
nvdimm=on|off启用或禁用NVDIMM支持。默认值为off。
-
memory-encryption=使用的内存加密对象。默认值为none。
-
hmat=on|off启用或禁用ACPI异构内存属性表(HMAT)支持。默认值为off。
-
memory-backend='id'用于替代传统的
-mem-path和mem-prealloc选项。允许使用内存后端作为主RAM。例如:-object memory-backend-file,id=pc.ram,size=512M,mem-path=/hugetlbfs,prealloc=on,share=on -machine memory-backend=pc.ram -m 512M迁移兼容性说明:
-
对于需要与旧QEMU(<5.0)进行迁移的情况,应使用由机器类型(通过
query-machinesQMP命令可获取)广告的‘default-ram-id’作为后端id。 -
对于4.0及更早的机器类型,用户应在迁移至/从旧QEMU(<5.0)时使用
x-use-canonical-path-for-ramblock-id=off后端选项。例如:
-object memory-backend-ram,id=pc.ram,size=512M,x-use-canonical-path-for-ramblock-id=off -machine memory-backend=pc.ram -m 512M
-
-
cxl-fmw.0.targets.0=firsttarget,cxl-fmw.0.targets.1=secondtarget,cxl-fmw.0.size=size[,cxl-fmw.0.interleave-granularity=granularity]定义一个CXL固定内存窗口(CFMW)
它们是系统中主机物理地址(HPA)的区域,可能跨一个或多个 CXL 主桥交错。系统软件将特定设备分配到这些窗口中,并在启用内存设备之前,在根端口、交换机端口和设备中配置下游的主机管理设备内存(HDM)解码器,以满足交错要求。
targets.X=target:提供到 CXL 主桥的映射,可以通过 -device 项中的 id 进行标识。当固定内存窗口表示交错内存时,需要多个条目来指定所有目标。X 是从 0 开始的目标索引。size=size:设置 CFMW 的大小。必须是 256MiB 的倍数。该区域将对齐到 256MiB,但位置依赖于平台和配置。interleave-granularity=granularity:设置交错粒度。默认值为 256(字节)。仅支持 256、512、1k、2k、4k、8k 和 16k 的粒度。
例如:
-machine cxl-fmw.0.targets.0=cxl.0,cxl-fmw.0.targets.1=cxl.1,cxl-fmw.0.size=128G,cxl-fmw.0.interleave-granularity=512
sgx-epc.0.memdev=@var{memid},sgx-epc.0.node=@var{numaid}
定义一个SGX EPC部分。
-cpu model
选择CPU模型(使用-cpu help查看列表和附加功能选择)
-accel name[,prop=value[,…]]
用于启用加速器。根据目标架构的不同,可用的加速器包括kvm、xen、hvf、nvmm、whpx或tcg。默认情况下使用tcg。如果指定了多个加速器,初始化失败时将使用下一个加速器。
-
igd-passthru=on|off当使用Xen时,此选项控制是否可以将英特尔集成显卡设备透传到虚拟机(默认值=off)。
-
kernel-irqchip=on|off|split控制KVM内核中断控制器支持。默认情况下是完全加速中断控制器。在x86架构上,split irqchip减少了内核攻击面,但非MSI中断的性能会有所降低。除非用于调试目的,不推荐完全禁用内核中断控制器。
-
kvm-shadow-mem=size定义KVM影子MMU的大小。
-
one-insn-per-tb=on|off使TCG加速器在每个翻译块中仅放置一条访客指令。这会大大降低仿真速度,但在某些情况下可能有用,例如分析由
-d选项生成的日志时。 -
split-wx=on|off控制TCG代码生成缓冲区的split w^x映射的使用。某些操作系统需要启用此功能,在这种情况下默认开启。在其他操作系统上,此功能默认关闭,但可以为测试或调试启用。
-
tb-size=n控制TCG翻译块缓存的大小(以MiB为单位)。
-
thread=single|multi控制TCG线程数量。当TCG是多线程时,每个vCPU将有一个线程,从而利用额外的主机核心。默认情况下,在后端和前端都支持且没有启用不兼容的TCG特性(例如icount/replay)时,启用多线程。
-
dirty-ring-size=n当使用KVM加速器时,控制每个vCPU脏页环缓冲区的大小(每个vCPU的条目数)。该值应为2的幂,并且应大于或等于1024(但仍小于内核支持的最大值)。如果不确定最佳值,4096可能是一个好的初始值。将此值设置为0以禁用该功能。默认情况下,该功能是禁用的(dirty-ring-size=0)。启用时,KVM将改为在位图中记录脏页。
-
eager-split-size=nKVM以PAGE_SIZE粒度实现脏页记录,启用大页的脏记录需要首先将其拆分为PAGE_SIZE页。默认情况下,ARM上的KVM懒惰地执行这种拆分。在某些情况下,积极地拆分大页在性能上有好处,特别是在TLBI成本与断前制序列相关且访客工作负载主要是读操作时。此处的大小指定一次拆分多少页,需要是有效的块大小,分别为1GB/2MB/4KB、32MB/16KB和512MB/64KB对于4KB/16KB/64KB的PAGE_SIZE。指定较大的大小会影响内存。默认情况下,该功能是禁用的(eager-split-size=0)。
-
notify-vmexit=run|internal-error|disable,notify-window=n启用或禁用x86主机上的通知VM退出支持,并指定相应的通知窗口以在启用时触发VM退出。
run选项启用该功能。如果发生退出,则不执行任何操作并继续。internal-error选项启用该功能。如果发生退出,则引发内部错误。disable选项不启用该功能。该功能可以缓解由于事件窗口在一段时间内未打开而导致的CPU卡住问题(即通知窗口)。默认值:notify-vmexit=run,notify-window=0。 -
device=path设置KVM设备节点的路径。默认为
/dev/kvm。此选项可用于通过文件描述符传递要使用的KVM设备,方法是将值设置为/dev/fdset/NN。
-smp [[cpus=]n][,maxcpus=maxcpus][,drawers=drawers][,books=books][,sockets=sockets][,dies=dies][,clusters=clusters][,modules=modules][,cores=cores][,threads=threads]
模拟一个具有‘n’个初始CPU的SMP系统。在支持CPU热插拔的主板上,可以通过可选的‘maxcpus’参数来设置,以便在运行时添加更多的CPU。当两个参数都省略时,将根据提供的拓扑成员计算最大CPU数量,初始CPU数量将与最大数量匹配。当只给出其中一个参数时,省略的参数将设置为对应的值。可以同时指定两个参数,但最大CPU数量必须等于或大于初始CPU数量。CPU拓扑层次结构的乘积必须等于最大CPU数量。两个参数都受到所选特定机器类型确定的上限的约束。
为了控制CPU拓扑信息的报告,可以指定拓扑参数的值。机器可能只支持参数的一个子集,不同机器可能支持不同的子集,这取决于相应CPU目标的能力。因此,可以通过支持的子选项为特定类型的主板定义预期的拓扑层次结构。还可以提供不支持的参数作为子选项的补充,但其值必须设置为1,以便正确解析。
必须指定初始CPU数量或至少一个拓扑参数。指定的参数必须大于零,不允许显式配置为“cpus=0”。任何省略参数的值将根据给定参数计算。
例如,以下子选项为仅支持插槽/核心/线程的机器定义了CPU拓扑层次结构(机器上总共有2个插槽,每个插槽2个核心,每个核心2个线程)。可以省略该选项的某些成员,但其值将自动计算:
-smp 8,sockets=2,cores=2,threads=2,maxcpus=8
以下子选项为支持插槽/芯片/模块/核心/线程的PC机器定义了CPU拓扑层次结构(机器上总共有2个插槽,每个插槽2个芯片,每个芯片2个模块,每个模块2个核心,每个核心2个线程)。可以省略该选项的某些成员,但其值将自动计算:
-smp 32,sockets=2,dies=2,modules=2,cores=2,threads=2,maxcpus=32
以下子选项为支持插槽/集群/核心/线程的ARM virt机器定义了CPU拓扑层次结构(机器上总共有2个插槽,每个插槽2个集群,每个集群2个核心,每个核心2个线程)。可以省略该选项的某些成员,但其值将自动计算:
-smp 16,sockets=2,clusters=2,cores=2,threads=2,maxcpus=16
历史上,在计算缺失值时优先考虑最粗略的拓扑参数(即优先考虑插槽而不是核心,而核心优先于线程),然而,这种行为可能会改变。在6.2之前,优先级是插槽高于核心高于线程。自6.2以来,优先级是核心高于插槽高于线程。
例如,以下选项在6.2之前定义了一个具有2个插槽、每个插槽1个核心的机器板,在6.2之后定义了一个具有1个插槽、每个插槽2个核心的机器板:
-smp 2
注意:集群拓扑只有在-smp中显式指定时才会在ACPI中生成并暴露给虚拟机。
-numa node[,mem=size][,cpus=firstcpu[-lastcpu]][,nodeid=node][,initiator=initiator]
-numa node[,memdev=id][,cpus=firstcpu[-lastcpu]][,nodeid=node][,initiator=initiator]
-numa dist,src=source,dst=destination,val=distance
-numa cpu,node-id=node[,socket-id=x][,core-id=y][,thread-id=z]
-numa hmat-lb,initiator=node,target=node,hierarchy=hierarchy,data-type=type[,latency=lat][,bandwidth=bw]
-numa hmat-cache,node-id=node,size=size,level=level[,associativity=str][,policy=str][,line=size]
定义一个NUMA节点,并为其分配RAM和VCPU。设置从源节点到目标节点的NUMA距离。为指定节点设置ACPI异构内存属性。
传统的VCPU分配使用‘cpus’选项,其中firstcpu和lastcpu是CPU索引。每个‘cpus’选项表示一个连续的CPU索引范围(如果省略lastcpu,则表示单个VCPU)。可以通过提供多个‘cpus’选项来表示非连续的VCPU集合。如果在所有节点上都省略了‘cpus’选项,则VCPU会自动在它们之间分配。
例如,以下选项将VCPU 0、1、2和5分配给一个NUMA节点:
-numa node,cpus=0-2,cpus=5
‘cpu’选项是‘cpus’选项的新替代方案,它使用‘socket-id|core-id|thread-id’属性,通过CPU的拓扑结构属性将CPU对象分配给节点。属性集是机器特定的,并取决于使用的机器类型和‘smp’选项。可以使用‘hotpluggable-cpus’监视器命令查询。‘node-id’属性指定将CPU对象分配到的节点,在使用‘cpu’选项之前必须用‘node’选项声明节点。
例如:
-M pc \
-smp 1,sockets=2,maxcpus=2 \
-numa node,nodeid=0 -numa node,nodeid=1 \
-numa cpu,node-id=0,socket-id=0 -numa cpu,node-id=1,socket-id=1
‘memdev’选项将来自给定内存后端设备的RAM分配给节点。建议使用‘memdev’选项代替传统的‘mem’选项。这是因为‘memdev’选项提供了更好的性能和对后端RAM的更多控制(例如‘-memory-backend-ram’的‘prealloc’参数允许内存预分配)。
出于兼容性原因,传统的‘mem’选项在5.0及更早的机器类型中受支持。注意,‘mem’和‘memdev’是互斥的。如果一个节点使用‘memdev’,其余节点也必须使用‘memdev’选项,反之亦然。
用户必须通过‘memdev’(或如果可用,通过传统的‘mem’)为所有NUMA节点指定内存。在QEMU 5.2中,移除了不指定内存的‘-numa node’的支持。
‘initiator’是一个附加选项,指向与此NUMA节点具有最佳性能(最低延迟或最大带宽)的启动NUMA节点。注意,只有在机器属性‘hmat’设置为‘on’时,才可以设置此选项。
以下示例创建了一个具有2个NUMA节点的机器,节点0有CPU,节点1只有内存,其启动节点是节点0。注意,因为节点0有CPU,默认情况下,节点0的启动节点是其自身,必须是其自身。
-machine hmat=on \
-m 2G,slots=2,maxmem=4G \
-object memory-backend-ram,size=1G,id=m0 \
-object memory-backend-ram,size=1G,id=m1 \
-numa node,nodeid=0,memdev=m0 \
-numa node,nodeid=1,memdev=m1,initiator=0 \
-smp 2,sockets=2,maxcpus=2 \
-numa cpu,node-id=0,socket-id=0 \
-numa cpu,node-id=0,socket-id=1
source和destination是NUMA节点ID。distance是从源节点到目标节点的NUMA距离。节点到自身的距离始终为10。如果为任意节点对设置了距离,则必须为所有节点对设置距离。但是,当每对节点只在一个方向上设置距离时,则假定相反方向的距离相同。然而,如果为甚至一个节点对设置了不对称的距离,则必须为所有节点对提供两个方向的距离值,即使它们是对称的。当一个节点无法从另一个节点到达时,将这对节点的距离设置为255。
请注意,-numa选项并不会分配任何指定的资源,它只是将现有资源分配给NUMA节点。这意味着仍然需要使用-m和-smp选项分别分配RAM和VCPU。
使用‘hmat-lb’选项在ACPI异构属性内存表(HMAT)中设置发起节点和目标NUMA节点之间的系统局部性延迟和带宽信息。发起NUMA节点可以创建内存请求,通常它有一个或多个处理器。目标NUMA节点包含可寻址内存。
在‘hmat-lb’选项中,node表示NUMA节点ID。hierarchy是目标NUMA节点的内存层次结构:如果hierarchy是‘memory’,则该结构表示内存性能;如果hierarchy是‘first-level|second-level|third-level’,则该结构表示每个域的内存侧缓存的综合性能。‘data-type’的类型表示该结构实例表示的数据类型:如果‘hierarchy’是‘memory’,‘data-type’是目标内存的‘access|read|write’延迟或‘access|read|write’带宽;如果‘hierarchy’是‘first-level|second-level|third-level’,‘data-type’是目标内存侧缓存的‘access|read|write’命中延迟或‘access|read|write’命中带宽。
lat是以纳秒为单位的延迟值。bw是带宽值,可能的值和单位是NUM[M|G|T],表示带宽值为每秒NUM字节(或MB/s、GB/s或TB/s,具体取决于使用的后缀)。注意,如果延迟或带宽值为0,则表示未提供相应的延迟或带宽信息。
在‘hmat-cache’选项中,node-id是内存所属的NUMA-id。size是以字节为单位的内存侧缓存大小。level是该结构描述的缓存级别,注意缓存级别0不应与‘hmat-cache’选项一起使用。associativity是缓存关联性,可能的值是‘none/direct(直接映射)/complex(复杂缓存索引)’。policy是写策略。line是以字节为单位的缓存行大小。
例如,以下选项描述了2个NUMA节点。节点0有2个CPU和一个RAM,节点1只有一个RAM。节点0的处理器访问节点0的内存时,访问延迟为5纳秒,访问带宽为200MB/s;节点0的处理器访问节点1的内存时,访问延迟为10纳秒,访问带宽为100MB/s。而对于内存侧缓存信息,NUMA节点0和1都具有1级内存缓存,大小为10KB,写策略为回写,缓存行大小为8字节:
-machine hmat=on \
-m 2G \
-object memory-backend-ram,size=1G,id=m0 \
-object memory-backend-ram,size=1G,id=m1 \
-smp 2,sockets=2,maxcpus=2 \
-numa node,nodeid=0,memdev=m0 \
-numa node,nodeid=1,memdev=m1,initiator=0 \
-numa cpu,node-id=0,socket-id=0 \
-numa cpu,node-id=0,socket-id=1 \
-numa hmat-lb,initiator=0,target=0,hierarchy=memory,data-type=access-latency,latency=5 \
-numa hmat-lb,initiator=0,target=0,hierarchy=memory,data-type=access-bandwidth,bandwidth=200M \
-numa hmat-lb,initiator=0,target=1,hierarchy=memory,data-type=access-latency,latency=10 \
-numa hmat-lb,initiator=0,target=1,hierarchy=memory,data-type=access-bandwidth,bandwidth=100M \
-numa hmat-cache,node-id=0,size=10K,level=1,associativity=direct,policy=write-back,line=8 \
-numa hmat-cache,node-id=1,size=10K,level=1,associativity=direct,policy=write-back,line=8
-add-fd fd=fd,set=set[,opaque=opaque]
向文件描述符集(fd set)中添加一个文件描述符。有效选项包括:
-
fd=fd此选项定义要添加到fd set中的文件描述符的副本。该文件描述符不能是stdin、stdout或stderr。
-
set=set此选项定义要将文件描述符添加到的fd set的ID。
-
opaque=opaque此选项定义一个自由格式的字符串,可以用于描述文件描述符。
您可以使用来自fd set的预打开文件描述符来打开镜像文件:
qemu-system-x86_64 \-add-fd fd=3,set=2,opaque="rdwr:/path/to/file" \-add-fd fd=4,set=2,opaque="rdonly:/path/to/file" \-drive file=/dev/fdset/2,index=0,media=disk
-set group.id.arg=value
为类型为group的项目id设置参数arg的值
-global driver.prop=value
-global driver=driver,property=property,value=value
将驱动程序属性prop的默认值设置为value,例如:
qemu-system-x86_64 -global ide-hd.physical_block_size=4096 disk-image.img
特别地,您可以使用此选项为机器模型自动创建的设备设置驱动程序属性。要创建未自动创建的设备并设置其属性,请使用-device选项。
-global driver.prop=value是-global driver=driver,property=prop,value=value的简写形式。当driver包含一个点时,长形式的语法也适用。
-boot [order=drives][,once=drives][,menu=on|off][,splash=sp_name][,splash-time=sp_time][,reboot-timeout=rb_timeout][,strict=on|off]
指定启动顺序驱动器作为驱动器字母的字符串。有效的驱动器字母取决于目标架构。x86 PC使用:a、b(软盘1和2)、c(第一个硬盘)、d(第一个CD-ROM)、n-p(从网络适配器1-4通过Etherboot启动),默认情况下为硬盘启动。要仅在第一次启动时应用特定的启动顺序,可以通过once参数指定。请注意,不应同时使用order或once参数和设备的bootindex属性,因为固件通常不支持同时使用这两者。
在固件/BIOS支持的情况下,可以通过menu=on启用交互式启动菜单/提示。默认情况下为非交互式启动。
可以通过bios传递启动画面,允许用户在启用menu=on选项并且指定splash=sp_name时显示为徽标(如果固件/BIOS支持)。目前,Seabios支持X86系统。限制条件:启动画面文件可以是jpeg文件或24位BMP文件(真彩色)。分辨率应受SVGA模式支持,因此推荐的分辨率是320x240、640x480、800x640。
可以将超时设置传递给bios,当启动失败时,guest将在rb_timeout毫秒内暂停,然后重启。如果rb_timeout为‘-1’,guest将不会重启,qemu默认传递‘-1’给bios。目前,Seabios支持X86系统。
通过strict=on进行严格启动,只要固件/BIOS支持。这仅在通过bootindex选项更改启动优先级时生效。默认情况下为非严格启动。
# 尝试先从网络启动,然后从硬盘启动
qemu-system-x86_64 -boot order=nc
# 先从CD-ROM启动,重启后恢复为默认顺序
qemu-system-x86_64 -boot once=d
# 启动时显示启动画面5秒
qemu-system-x86_64 -boot menu=on,splash=/root/boot.bmp,splash-time=5000
注意:旧格式‘-boot drives’仍然受支持,但不推荐使用,因为将来版本中可能会移除。
-m [size=]megs[,slots=n,maxmem=size]
设置客户机启动时的RAM大小为megs兆字节。默认值为128 MiB。可以选择使用“M”或“G”后缀分别表示兆字节或千兆字节的值。可选参数slots和maxmem可以用来设置热插拔内存插槽的数量和最大内存量。请注意,maxmem必须与页面大小对齐。
例如,以下命令行将客户机启动时的RAM大小设置为1GB,创建3个插槽以热插拔额外内存,并将客户机的最大内存设置为4GB:
qemu-system-x86_64 -m 1G,slots=3,maxmem=4G
如果未指定slots和maxmem,则不会启用内存热插拔,且客户机启动时的RAM大小将不会增加。
-mem-path path
从路径中临时创建的文件中分配客户机RAM。
-mem-prealloc
使用-mem-path时预分配内存。
-k language
使用键盘布局语言(例如fr表示法语)。该选项仅在不容易获得原始PC键码的情况下需要使用(例如在Mac电脑上,使用某些X11服务器或使用VNC或curses显示时)。通常在PC/Linux或PC/Windows主机上不需要使用此选项。
可用的布局有:
ar de-ch es fo fr-ca hu ja mk no pt-br sv
da en-gb et fr fr-ch is lt nl pl ru th
de en-us fi fr-be hr it lv nl-be pt sl tr
默认布局为en-us。
-audio [driver=]driver[,model=value][,prop[=value][,…]]
如果指定了model选项,-audio是用于一次性配置客户机音频硬件和主机音频后端的快捷方式。客户机硬件模型可以使用model=modelname进行设置。使用model=help列出可用的设备类型。
以下两个示例做了完全相同的事情,展示了如何使用-audio来缩短命令行长度:
qemu-system-x86_64 -audiodev pa,id=pa -device sb16,audiodev=pa
qemu-system-x86_64 -audio pa,model=sb16
如果未指定model选项,-audio用于配置一个默认音频后端,该后端将在设备或机器未设置audiodev属性时使用。特别是,-audio none确保即使对于有嵌入式声音硬件的机器也不产生音频。
在这两种情况下,driver选项与下面对应的-audiodev选项相同。使用driver=help列出可用的驱动程序。
-audiodev [driver=]driver,id=id[,prop[=value][,…]]
添加一个由id标识的新音频后端驱动程序。有全局和驱动程序特定的属性。一些值可以为输入和输出分别设置,它们用in|out.标记。您可以使用in.prop设置输入属性,使用out.prop设置输出属性。例如:
-audiodev alsa,id=example,in.frequency=44100,out.frequency=8000
-audiodev alsa,id=example,out.channels=1 # 不指定in.channels
注意:已知参数验证不完整,在许多情况下,指定无效选项会导致QEMU打印错误消息并继续仿真而没有声音。
有效的全局选项有:
-
id=identifier标识音频后端。
-
timer-period=period设置音频子系统使用的定时器周期,以微秒为单位。默认值为10000(10毫秒)。
-
in|out.mixing-engine=on|off使用QEMU的混音引擎在QEMU内部混合所有流并在后端不支持时转换音频格式。当关闭时,fixed-settings也必须关闭。注意,禁用此选项意味着所选后端必须支持多流和虚拟卡使用的音频格式,否则将没有声音。不建议禁用此选项,除非您想使用5.1或7.1音频,因为混音引擎仅支持单声道和立体声。默认值为开启。
-
in|out.fixed-settings=on|off为主机音频使用固定设置。关闭时,将根据客户机打开声卡的方式更改。在这种情况下,不能指定频率、通道或格式。默认值为开启。
-
in|out.frequency=frequency使用固定设置时指定使用的频率。默认值为44100Hz。
-
in|out.channels=channels使用固定设置时指定使用的通道数。默认值为2(立体声)。
-
in|out.format=format使用固定设置时指定使用的采样格式。有效值为:
s8、s16、s32、u8、u16、u32、f32。默认值为s16。 -
in|out.voices=voices指定使用的声音数。默认值为1。
-
in|out.buffer-length=usecs设置缓冲区大小,以微秒为单位。
-
in|out.buffer-length=usecs设置缓冲区大小,以微秒为单位。
-audiodev none,id=id[,prop[=value][,…]]
创建一个丢弃所有输出的虚拟后端。此后端没有特定的属性。
-audiodev alsa,id=id[,prop[=value][,…]]
使用ALSA创建后端。此后端仅在Linux上可用。ALSA特定选项包括:
-
in|out.dev=device指定用于输入和/或输出的ALSA设备。默认值为
default。 -
in|out.period-length=usecs设置周期长度,以微秒为单位。
-
in|out.try-poll=on|off尝试使用设备的轮询模式。默认值为on。
-
threshold=threshold播放开始时的阈值(以微秒为单位)。默认值为0。
-audiodev coreaudio,id=id[,prop[=value][,…]]
使用Apple的Core Audio创建后端。此后端仅在Mac OS上可用,并且仅支持播放。
Core Audio特定选项包括:
-
in|out.buffer-count=count在播放时增加额外的延迟,以微秒为单位。默认值为10000(10毫秒)。
-audiodev oss,id=id[,prop[=value][,…]]
使用OSS创建后端。此后端在大多数类Unix系统上可用。
OSS特定选项包括:
-
in|out.dev=device指定要使用的OSS设备的文件名。默认值为
/dev/dsp。 -
in|out.buffer-count=count设置缓冲区的数量。
-
in|out.try-poll=on|off尝试使用设备的轮询模式。默认值为on。
-
try-mmap=on|off尝试使用内存映射设备访问。默认值为off。
-
exclusive=on|off以独占模式打开设备(在这种情况下vmix将无法工作)。默认值为off。
-
dsp-policy=policy设置定时策略(0到10之间的值,数字越小延迟越小,但CPU使用率越高)。使用-1以使用
buffer和buffer-count指定的缓冲区大小。如果没有OSS 4,此选项将被忽略。默认值为5。
-audiodev pa,id=id[,prop[=value][,…]]
使用PulseAudio创建后端。此后端在大多数系统上可用。
PulseAudio特定选项包括:
-
server=server设置要连接的PulseAudio服务器。
-
in|out.name=sink使用指定的源/接收器进行录音/播放。
-
in|out.latency=usecs期望的延迟,以微秒为单位。PulseAudio服务器将尝试满足此值,但实际延迟可能更低或更高。
-audiodev pipewire,id=id[,prop[=value][,…]]
使用PipeWire创建后端。此后端在大多数系统上可用。
PipeWire特定选项包括:
-
in|out.latency=usecs期望的延迟,以微秒为单位。
-
in|out.name=sink使用指定的源/接收器进行录音/播放。
-
in|out.stream-name=name指定PipeWire流的名称。
-audiodev sdl,id=id[,prop[=value][,…]]
使用SDL创建后端。此后端在大多数系统上可用,但如果可能,您应使用平台的本地后端。
SDL特定选项包括:
-
in|out.buffer-count=count设置缓冲区的数量。
-audiodev sndio,id=id[,prop[=value][,…]]
使用SNDIO创建后端。此后端在OpenBSD和大多数其他类Unix系统上可用。
SNDIO特定选项包括:
-
in|out.dev=device指定用于输入和/或输出的SNDIO设备。默认值为
default。 -
in|out.latency=usecs设置期望的周期长度,以微秒为单位。
-audiodev spice,id=id[,prop[=value][,…]]
创建一个通过SPICE发送音频的后端。此后端需要-spice选项,在这种情况下会自动选择,因此通常可以忽略此选项。此后端没有特定属性。
-audiodev wav,id=id[,prop[=value][,…]]
创建一个将音频写入WAV文件的后端。
后端特定选项包括:
-
path=path将录制的音频写入指定文件。默认值为
qemu.wav。
-device driver[,prop[=value][,…]]
添加设备驱动程序。prop=value设置驱动程序属性。有效属性取决于驱动程序。要获取可能的驱动程序和属性的帮助,请使用-device help和-device driver,help。
-device ipmi-bmc-sim,id=id[,prop[=value][,…]]
添加一个IPMI BMC。这是一个硬件管理接口处理器的模拟,通常位于系统上。它提供看门狗以及重置和电源控制系统的能力。您需要将其连接到IPMI接口以使其有用。
用于BMC的IPMI从属地址。默认值为0x20。此地址是BMC在管理控制器的I2C网络上的地址。如果您不知道这意味着什么,可以安全地忽略它。
-
id=id用于接口使用此设备的BMC ID。
-
slave_addr=val定义用于BMC的从属地址。默认值为0x20。
-
sdrfile=file包含原始传感器数据记录(SDR)数据的文件。默认值为无。
-
fruareasize=val可替换单元(FRU)区域的大小。默认值为1024。
-
frudatafile=file包含原始可替换单元(FRU)清单数据的文件。默认值为无。
-
guid=uuidBMC的GUID值,采用标准UUID格式。如果设置此值,则向BMC发送“获取GUID”命令将返回它。否则,“获取GUID”将返回错误。
-device ipmi-bmc-extern,id=id,chardev=id[,slave_addr=val]
添加与外部IPMI BMC模拟器的连接。与本地仿真BMC不同,此项连接到提供IPMI服务的外部实体。
连接到外部BMC模拟器。如果这样做,强烈建议使用“reconnect=”字符设备选项,如果连接丢失,则重新连接到模拟器。请注意,如果不谨慎使用,这可能成为安全问题,因为接口能够发送重置、NMI和关闭VM的命令。最好是QEMU连接到在localhost上运行在安全端口的外部模拟器,这样模拟器和QEMU都不会暴露在任何外部网络上。
有关外部接口的更多详细信息,请参见OpenIPMI库中的“lanserv/README.vm”文件。
-device isa-ipmi-kcs,bmc=id[,ioport=val][,irq=val]
在ISA总线上添加一个KCS IPMI接口。如果合适,还会添加相应的ACPI和SMBIOS条目。
-
bmc=id要连接的BMC,可以是上面的ipmi-bmc-sim或ipmi-bmc-extern之一。
-
ioport=val定义接口的I/O地址。默认值为0xca0(用于KCS)。
-
irq=val定义要使用的中断。默认值为5。要禁用中断,请将其设置为0。
-device isa-ipmi-bt,bmc=id[,ioport=val][,irq=val]
与KCS接口类似,但定义了一个BT接口。默认端口为0xe4,默认中断为5。
-device pci-ipmi-kcs,bmc=id
在PCI总线上添加一个KCS IPMI接口。
-
bmc=id要连接的BMC,可以是上面的ipmi-bmc-sim或ipmi-bmc-extern之一。
-device pci-ipmi-bt,bmc=id
与KCS接口类似,但在PCI总线上定义了一个BT接口。
-device intel-iommu[,option=…]
仅支持在-machine q35下使用,它将在客户机中启用Intel VT-d仿真。支持以下选项:
-
intremap=on|off(默认:auto)这启用中断重映射功能。它需要启用完整的x2apic。目前仅支持kvm kernel-irqchip模式
off或split,尚不支持完整的kernel-irqchip。默认值为“auto”,将由kernel-irqchip模式决定。 -
caching-mode=on|off(默认:off)这为VT-d仿真设备启用缓存模式。当启用缓存模式时,每个客户机DMA缓冲区映射将以同步方式从客户机IOMMU驱动程序生成IOTLB无效到vIOMMU设备。对于
-device vfio-pci与VT-d设备一起工作是必需的,因为主机分配的设备需要在客户机DMA开始之前在主机上设置DMA映射。 -
device-iotlb=on|off(默认:off)这为仿真的VT-d设备启用设备IOTLB功能。目前virtio/vhost应该是此参数的唯一实际用户,设备上配置的ats=on与之配对。
-
aw-bits=39|48(默认:39)这决定了IOVA地址空间的地址宽度。地址空间对于3级IOMMU页表具有39位宽度,对于4级IOMMU页表具有48位宽度。
有关QEMU中VT-d仿真的一般场景,请参阅维基页面:https://wiki.qemu.org/Features/VT-d。
-device virtio-iommu-pci[,option=…]
仅支持在-machine q35(x86_64)和-machine virt(ARM)下使用。支持以下选项:
-
granule=val(可能的值为4k、8k、16k、64k和host;默认:host)这决定了virtio-iommu公开的默认粒度。如果为host,则粒度与主机页面大小匹配。
-
aw-bits=val(值在32到64之间,默认取决于机器)这决定了IOVA地址空间的地址宽度。
-name name
设置客户机的名称。该名称将显示在SDL窗口标题中。该名称也将用于VNC服务器。还可以选择在Linux中设置顶部可见的进程名称。还可以在Linux上启用单独线程的命名以帮助调试。
-uuid uuid
设置系统UUID。
未完待续。。
相关文章:
)
【QEMU中文手册】2.2 调用方式(持续更新中)
本文由 AI 翻译(ChatGPT-4)完成,并由作者进行人工校对。如有任何问题或建议,欢迎联系我。联系方式:jelin-shoutlook.com。 原文:Invocation — QEMU documentation qemu-system-x86_64 [选项] [磁盘镜像]磁…...
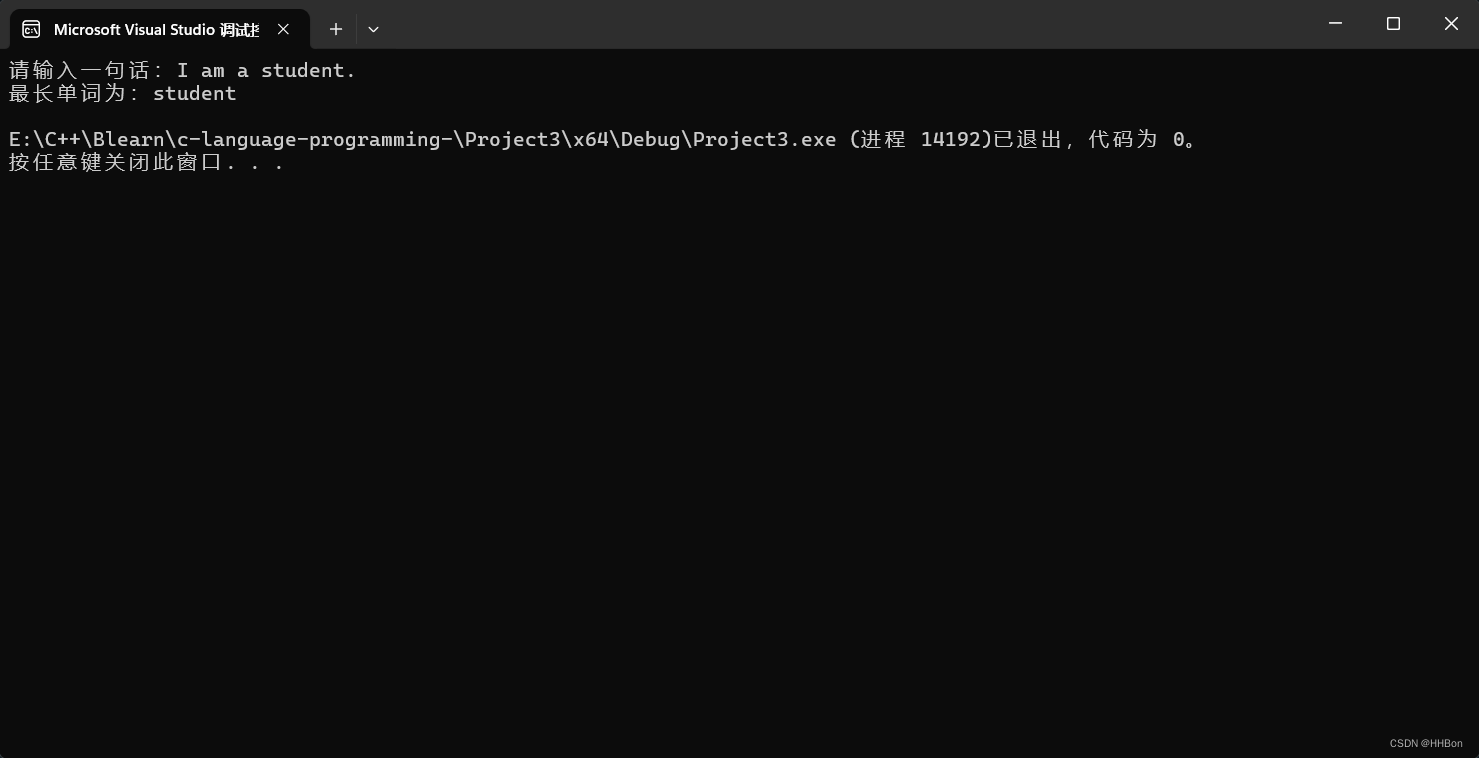
(函数)判断一句话中最长的单词(C语言)
一、运行结果; 二、源代码; # define _CRT_SECURE_NO_WARNINGS # include <stdio.h>//声明函数; int aiphabetic(char); int longest(char[]);int main() {//初始化变量值;int i;char line[100] { 0 };//获取用户输入字符…...

QT5.5.0中使用lambda表达式时遇到的问题
QT5.5中使用lambda表达式的遇到的error_qt中lamda不起作用-CSDN博客...

【Go语言精进之路】构建高效Go程序:了解切片实现原理并高效使用
🔥 个人主页:空白诗 文章目录 引言一、切片究竟是什么?1.1 基础的创建数组示例1.2 基础的创建切片示例1.3 切片与数组的关系 二、切片的高级特性:动态扩容2.1 使用 append 函数扩容2.2 容量管理与性能考量2.3 切片的截取与缩容 三…...

Python与C语言:深入探索两者的奥秘与差异
Python与C语言:深入探索两者的奥秘与差异 在编程的世界里,Python和C语言如同两位性格迥异的伙伴,各自拥有独特的魅力和应用场景。Python以其简洁易懂的语法和强大的库支持赢得了众多开发者的青睐,而C语言则以其接近硬件的低级特性…...

图像编解码器在AI绘画中的革新作用
随着人工智能技术的飞速发展,AI绘画已经从一个简单的概念演变为一个充满创意与可能性的领域。在这场技术与艺术的融合中,图像编解码器扮演着至关重要的角色。它们不仅提升了AI绘画的质量和效率,还拓宽了艺术创造的边界。本篇博客将深入探讨图…...

SecureCRT[po破] for Mac SSH终端操作工具[解] 安装教程
文章目录 效果一、准备工作二、开始安装1、双击运行软件,将其从左侧拖入右侧文件夹中,等待安装完毕2、 应用程序显示软件图标,表示安装成功 三、输入对应参数1、解决“软件已损坏,无法打开,要移到废纸篓”问题解决步骤…...

【大数据架构】基于流式数据的大数据架构升级
背景 团队在升级大数据架构,摒弃了原来基于hadoop的架构,因此抛弃了hive,hdfs,mapreduce这一套,在讨论和摸索中使用了新的架构。 后端使用kafka流式数据通过rest catalog写入iceberg,存储于minio。在写入iceberg的时候,首先是写data数据文件,然后再写iceberg的metada…...
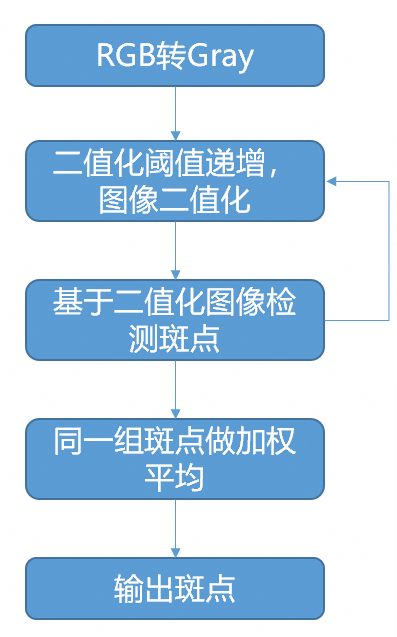
OpenCV中的圆形标靶检测——斑点检测算法(二)
前面的章节中我们已经大致介绍了算法流程,也对一些算法中用到的相关概念做了简要介绍,同时给出了算法调用的API,现在我们开始算法检测接口实现源码的分析。 1. 斑点的分组与加权 这里我们选择后者,先了解算法的处理流程,再分析各个模块的实现。算法流程图如下图所示,上一…...

网线制作(双绞线+水晶头)——T568B标准
参考视频:https://www.bilibili.com/video/BV1KQ4y1i7zP/ 1、使用剥线器 2、将线捋顺、排序、剪掉牵引线 记忆技巧 1.线序颜色整体是一浅一深 2.颜色顺序是黄、蓝、绿、棕 一个黄种人、从上向下看,分别看到的是蓝天、青草(绿)、泥土(棕色) 3.中间两根浅…...

湖南源点(市场研究咨询)如何产出更加有意义的竞品调研
湖南源点咨询认为:当前,任何项目都不能盲目开始,前期的准备工作必不可少。在基础架构搭建的同时,设计上对于前端功能、用户体验的调研就优先开始了。在这个阶段,大部分设计师都会分配很多调研任务,疯狂对竞…...

Qt/C++音视频开发76-获取本地有哪些摄像头名称/ffmpeg内置函数方式
一、前言 上一篇文章是写的用Qt的内置函数方式获取本地摄像头名称集合,但是有几个缺点,比如要求Qt5,或者至少要求安装了多媒体组件multimedia,如果没有安装呢,或者安装的是个空的呢,比如很多嵌入式板子&am…...

09 platfrom 设备驱动
platform 设备驱动,也叫做平台设备驱动。请各位重点学习! 1、驱动的分离与分层 1)驱动的分隔与分离 Linux 操作系统,代码的重用性非常重要。驱动程序占用了 Linux 内核代码量的大头,如果不对驱动程序加以管理,用不了多久 Linux 内核的文件数量就庞大到无法接受的地步。…...

【C#】C#读写Excel文件
1.工具库选择 使用EPPlus读取Excel文件,在visual studio2022中安装最新NuGet。 2.读文件测试 using OfficeOpenXml; using OfficeOpenXml.Packaging.Ionic.Zip; using OfficeOpenXml.Style; using System; using System.Collections.Generic; using System.IO; u…...
绘制规范)
数据流图(DFD)绘制规范
软件数据流图(Data Flow Diagram,DFD)是一种重要的工具,用于表示系统中数据的流动和处理。DFD帮助开发团队和利益相关者理解系统的功能和数据处理过程。绘制DFD时应遵循一定的规范和步骤,以确保图表的清晰性和一致性。…...
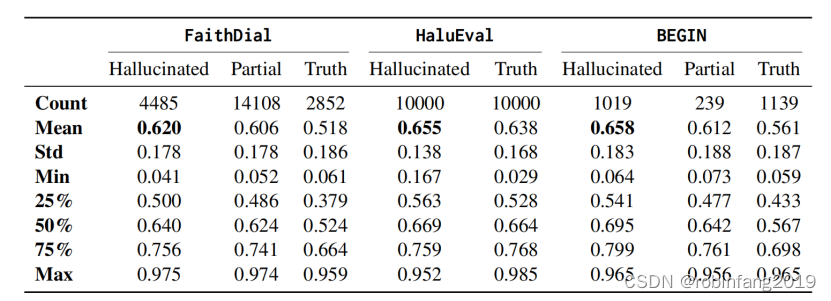
有待挖掘的金矿:大模型的幻觉之境
人工智能正在迅速变得无处不在,在科学和学术研究中,自回归的大型语言模型(LLM)走在了前列。自从LLM的概念被整合到自然语言处理(NLP)的讨论中以来,LLM中的幻觉现象一直被广泛视为一个显著的社会…...
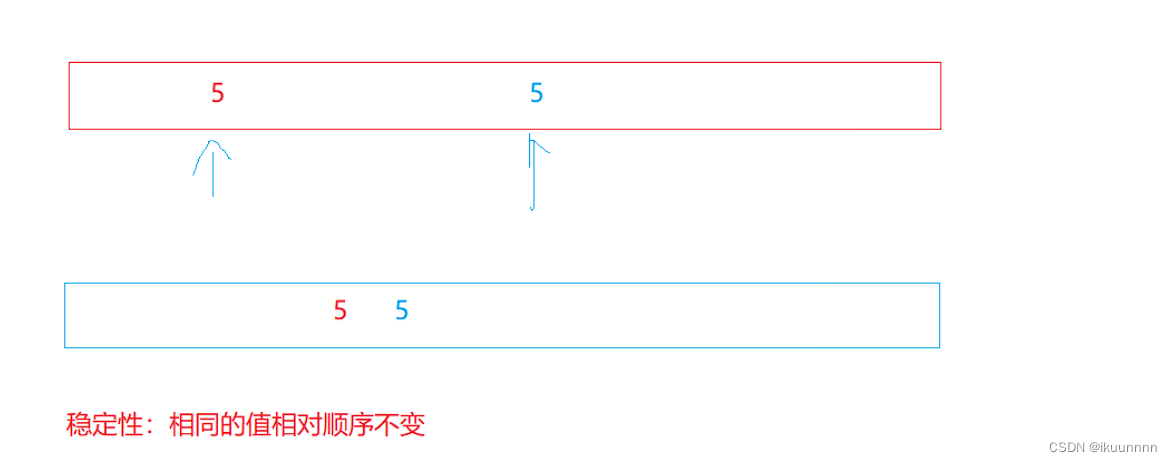
常见八大排序(纯C语言版)
目录 基本排序 一.冒泡排序 二.选择排序 三.插入排序 进阶排序(递归实现) 一.快排hoare排序 1.单趟排序 快排步凑 快排的优化 (1)三数取中 (2)小区间优化 二.前后指针法(递归实现) 三.快排的非…...
----vuex)
vue2学习(06)----vuex
目录 一、vuex概述 1.定义 优势: 2.构建环境步骤 3.state状态 4.使用数据 4.1通过store直接访问 4.2通过辅助函数 5.mutations修改数据(同步操作) 5.1定义 5.2步骤 5.2.1定义mutations对象,对象中存放修改state数据的方…...

webflux 拦截器验证token
在WebFlux中,我们可以使用拦截器(Interceptor)来验证Token。以下是一个简单的示例: 1. 首先,创建一个名为TokenInterceptor的类,实现HandlerInterceptor接口: java import org.springframewor…...

C++中的继承方式
目录 摘要 1. 公有继承(Public Inheritance) 2. 保护继承(Protected Inheritance) 3. 私有继承(Private Inheritance) 4. 多重继承(Multiple Inheritance) 继承列表的项数 摘要…...

Windows运行Android应用终极指南:APK Installer让你的电脑秒变安卓手机
Windows运行Android应用终极指南:APK Installer让你的电脑秒变安卓手机 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 在移动应用生态日益丰富的今天&…...

OpenClaw到Hermes一键迁移:自动化配置转移与智能体升级实践
1. 项目概述:从 OpenClaw 到 Hermes 的平滑迁移方案如果你正在运行一个名为 OpenClaw 的智能体项目,并且最近听说了它的“继任者”或一个更强大的替代品 Hermes,那么你很可能正面临一个经典的工程难题:如何将现有的、已经配置好的…...

基于SEID模型与ode45数值解的艾滋病传播动力学建模与区域防控策略评估
1. 当数学模型遇上艾滋病防控 我第一次接触传染病建模是在研究生时期,当时导师扔给我一叠艾滋病流行病学数据,说:"试试用微分方程描述这个传播过程"。那会儿对着密密麻麻的病例报告,我完全没想到数学公式真能模拟现实中…...

从布朗运动到伊藤公式:金融随机世界的建模基石
1. 从花粉运动到股票价格:布朗运动的金融启示 1827年,英国植物学家罗伯特布朗在显微镜下观察到花粉颗粒在水中的不规则舞动,这个看似简单的物理现象却在80年后被爱因斯坦用数学语言精确描述。有趣的是,当我们将显微镜换成股票行情…...

基于Python与aiogram构建多模型AI助手:集成GPT-4、Claude与Gemini的Telegram机器人开发实践
1. 项目概述:一个多模型AI助手的自研之路 最近在折腾一个挺有意思的玩意儿,我把它叫做“AIAssistantBot”。简单来说,这是一个跑在Telegram上的机器人,但它不是那种只会回复固定指令的“傻”机器人。它的核心是整合了市面上几家主…...

别再用眼睛猜阈值了!Halcon threshold函数实战:5分钟搞定车牌字符分割
工业视觉实战:Halcon阈值分割在车牌识别中的精准应用 在机器视觉领域,车牌识别系统是典型的工业应用场景之一。而字符分割作为识别流程中的关键环节,直接影响最终识别准确率。许多初学者往往陷入一个误区——仅凭肉眼观察随意设置阈值参数&am…...

从零构建Telegram天气机器人:Python异步编程与API集成实战
1. 项目概述:一个能聊天的天气机器人 如果你用过Telegram,大概率会见过或者用过一些机器人。它们能帮你查新闻、翻译、管理任务,甚至陪你聊天。今天要聊的这个项目, imkarimkarim/Telegram-Weather-Bot ,就是一个典型…...

PrismLauncher-Cracked:彻底解除Minecraft离线账号限制的终极指南
PrismLauncher-Cracked:彻底解除Minecraft离线账号限制的终极指南 【免费下载链接】PrismLauncher-Cracked This project is a Fork of Prism Launcher, which aims to unblock the use of Offline Accounts, disabling the restriction of having a functional Onl…...

SIGTRAN协议:电信网络IP化的关键技术解析
1. SIGTRAN:下一代电信网络的信令传输基石2003年全球电信业寒冬中,一个技术决策正在悄然改变行业格局。当运营商们紧缩资本开支时,AT&T、Verizon等巨头却不约而同地加大了对IP网络的投入。这背后隐藏着一个关键技术转折——传统TDM网络向…...

6自由度KUKA机械臂自主抓取系统:ROS架构设计与逆运动学技术实现深度解析
6自由度KUKA机械臂自主抓取系统:ROS架构设计与逆运动学技术实现深度解析 【免费下载链接】pick-place-robot Object picking and stowing with a 6-DOF KUKA Robot using ROS 项目地址: https://gitcode.com/gh_mirrors/pi/pick-place-robot 在工业自动化领…...