Llama模型家族之使用 ReFT技术对 Llama-3 进行微调(三)为 ReFT 微调准备模型及数据集
LlaMA 3 系列博客
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (一)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (二)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (三)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (四)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (五)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (六)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (七)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (八)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (九)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (十)
构建安全的GenAI/LLMs核心技术解密之大模型对抗攻击(一)
构建安全的GenAI/LLMs核心技术解密之大模型对抗攻击(二)
构建安全的GenAI/LLMs核心技术解密之大模型对抗攻击(三)
构建安全的GenAI/LLMs核心技术解密之大模型对抗攻击(四)
构建安全的GenAI/LLMs核心技术解密之大模型对抗攻击(五)
你好 GPT-4o!
大模型标记器之Tokenizer可视化(GPT-4o)
大模型标记器 Tokenizer之Byte Pair Encoding (BPE) 算法详解与示例
大模型标记器 Tokenizer之Byte Pair Encoding (BPE)源码分析
大模型之自注意力机制Self-Attention(一)
大模型之自注意力机制Self-Attention(二)
大模型之自注意力机制Self-Attention(三)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (十一)
Llama 3 模型家族构建安全可信赖企业级AI应用之 Code Llama (一)
Llama 3 模型家族构建安全可信赖企业级AI应用之 Code Llama (二)
Llama 3 模型家族构建安全可信赖企业级AI应用之 Code Llama (三)
Llama 3 模型家族构建安全可信赖企业级AI应用之 Code Llama (四)
Llama 3 模型家族构建安全可信赖企业级AI应用之 Code Llama (五)
Llama 3 模型家族构建安全可信赖企业级AI应用之使用 Llama Guard 保护大模型对话(一)
Llama 3 模型家族构建安全可信赖企业级AI应用之使用 Llama Guard 保护大模型对话(二)
Llama 3 模型家族构建安全可信赖企业级AI应用之使用 Llama Guard 保护大模型对话(三)
大模型之深入理解Transformer位置编码(Positional Embedding)
大模型之深入理解Transformer Layer Normalization(一)
大模型之深入理解Transformer Layer Normalization(二)
大模型之深入理解Transformer Layer Normalization(三)
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(一)初学者的起点
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(二)矩阵操作的演练
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(三)初始化一个嵌入层
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(四)预先计算 RoPE 频率
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(五)预先计算因果掩码
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(六)首次归一化:均方根归一化(RMSNorm)
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(七) 初始化多查询注意力
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(八)旋转位置嵌入
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(九) 计算自注意力
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(十) 残差连接及SwiGLU FFN
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(十一)输出概率分布 及损失函数计算
大模型之使用PyTorch编写Meta的Llama 3实际功能代码(一)加载简化分词器及设置参数
大模型之使用PyTorch编写Meta的Llama 3实际功能代码(二)RoPE 及注意力机制
大模型之使用PyTorch编写Meta的Llama 3实际功能代码(三) FeedForward 及 Residual Layers
大模型之使用PyTorch编写Meta的Llama 3实际功能代码(四) 构建 Llama3 类模型本身
大模型之使用PyTorch编写Meta的Llama 3实际功能代码(五)训练并测试你自己的 minLlama3
大模型之使用PyTorch编写Meta的Llama 3实际功能代码(六)加载已经训练好的miniLlama3模型
Llama 3 模型家族构建安全可信赖企业级AI应用之使用 Llama Guard 保护大模型对话 (四)
Llama 3 模型家族构建安全可信赖企业级AI应用之使用 Llama Guard 保护大模型对话 (五)
Llama 3 模型家族构建安全可信赖企业级AI应用之使用 Llama Guard 保护大模型对话 (六)
Llama 3 模型家族构建安全可信赖企业级AI应用之使用 Llama Guard 保护大模型对话 (七)
Llama 3 模型家族构建安全可信赖企业级AI应用之使用 Llama Guard 保护大模型对话 (八)
Llama 3 模型家族构建安全可信赖企业级AI应用之 CyberSecEval 2:量化 LLM 安全和能力的基准(一)
Llama 3 模型家族构建安全可信赖企业级AI应用之 CyberSecEval 2:量化 LLM 安全和能力的基准(二)
Llama 3 模型家族构建安全可信赖企业级AI应用之 CyberSecEval 2:量化 LLM 安全和能力的基准(三)
Llama 3 模型家族构建安全可信赖企业级AI应用之 CyberSecEval 2:量化 LLM 安全和能力的基准(四)
Llama 3 模型家族构建安全可信赖企业级AI应用之code shield(一)Code Shield简介
Llama 3 模型家族构建安全可信赖企业级AI应用之code shield(二)防止 LLM 生成不安全代码
Llama 3 模型家族构建安全可信赖企业级AI应用之code shield(三)Code Shield代码示例
Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(一) LLaMA-Factory简介
Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(二) LLaMA-Factory训练方法及数据集
大模型之Ollama:在本地机器上释放大型语言模型的强大功能
Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(三)通过Web UI微调
Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(四)通过命令方式微调
Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(五) 基于已训练好的模型进行推理
Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(六)Llama 3 已训练的大模型合并LoRA权重参数
Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(七) 使用 LoRA 微调 LLM 的实用技巧
Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(八) 使用 LoRA 微调 LLM 的实用技巧
Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(九) 使用 LoRA 微调常见问题答疑
Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(十) 使用 LoRA 微调常见问题答疑
Llama模型家族训练奖励模型Reward Model技术及代码实战(一)简介
Llama模型家族训练奖励模型Reward Model技术及代码实战(二)从用户反馈构建比较数据集
Llama模型家族训练奖励模型Reward Model技术及代码实战(三) 使用 TRL 训练奖励模型
Llama模型家族之RLAIF 基于 AI 反馈的强化学习(一)RLHF简介
Llama模型家族之RLAIF 基于 AI 反馈的强化学习(二)RLHF 与RAIF比较
Llama模型家族之RLAIF 基于 AI 反馈的强化学习(三) RLAIF 的工作原理
Llama模型家族之RLAIF 基于 AI 反馈的强化学习(四)RLAIF 优势
Llama模型家族之RLAIF 基于 AI 反馈的强化学习(五)RLAIF 挑战
Llama模型家族之RLAIF 基于 AI 反馈的强化学习(六) RLAIF 代码实战
Llama模型家族之RLAIF 基于 AI 反馈的强化学习(七) RLAIF 代码实战
Llama模型家族之RLAIF 基于 AI 反馈的强化学习(八) RLAIF 代码实战
Llama模型家族之RLAIF 基于 AI 反馈的强化学习(九) RLAIF 代码实战
Llama模型家族之RLAIF 基于 AI 反馈的强化学习(十) RLAIF 代码实战
Llama模型家族之拒绝抽样(Rejection Sampling)(一)
Llama模型家族之拒绝抽样(Rejection Sampling)(二)均匀分布简介
Llama模型家族之拒绝抽样(Rejection Sampling)(三)确定缩放常数以优化拒绝抽样方法
Llama模型家族之拒绝抽样(Rejection Sampling)(四) 蒙特卡罗方法在拒绝抽样中的应用:评估线与样本接受标准
Llama模型家族之拒绝抽样(Rejection Sampling)(五) 蒙特卡罗算法在拒绝抽样中:均匀分布与样本接受标准
Llama模型家族之拒绝抽样(Rejection Sampling)(六) 拒绝抽样中的蒙特卡罗算法:重复过程与接受标准
Llama模型家族之拒绝抽样(Rejection Sampling)(七) 优化拒绝抽样:选择高斯分布以减少样本拒绝
Llama模型家族之拒绝抽样(Rejection Sampling)(八) 代码实现
Llama模型家族之拒绝抽样(Rejection Sampling)(九) 强化学习之Rejection Sampling
Llama模型家族之使用 ReFT技术对 Llama-3 进行微调(一)ReFT简介
Llama模型家族之使用 ReFT技术对 Llama-3 进行微调(二) PyReFT简介

Llama模型家族之使用 ReFT技术对 Llama-3 进行微调(三)为 ReFT 微调准备模型及数据集
为 ReFT 微调准备模型
设置模型的 pyreft 配置,然后使用 pyreft.get_reft_model() 方法让模型为表示微调做好准备。对于配置, 将在第 15 层对最终一个提示标记的残差流应用单个 4 级 LoReFT 干预。
# get reft model
reft_config = pyreft.ReftConfig(representations={"layer": 8, "component": "block_output","low_rank_dimension": 4,"intervention": pyreft.LoreftIntervention(embed_dim=model.config.hidden_size,low_rank_dimension=4)})
reft_model = pyreft.get_reft_model(model, reft_config)
reft_model.set_device("cuda")
reft_model.print_trainable_parameters()
这段代码是用于设置和获取一个经过表示层微调(Representation Fine-Tuning,简称REFT)的模型。
-
# get reft model:这是一行注释,说明接下来的代码将获取REFT模型。 -
reft_config = pyreft.ReftConfig(...):创建了一个ReftConfig对象,它是用于配置REFT模型的配置类。配置包括:"layer": 8:指定了REFT干预的层数为第8层。"component": "block_output":指定了干预的组件为该层的输出。"low_rank_dimension": 4:指定了低秩维度为4,这是LoReFT干预的一个参数,用于控制干预的复杂度。"intervention":定义了干预类型,这里使用的是pyreft.LoreftIntervention,它是一个低秩正则化干预,其中embed_dim参数设置为模型的隐藏层维度,low_rank_dimension也设置为4。
-
reft_model = pyreft.get_reft_model(model, reft_config):使用pyreft.get_reft_model()函数,传入预训练模型model和配置reft_config,来获取REFT模型。这个REFT模型将在指定的层上应用REFT技术。 -
reft_model.set_device("cuda"):设置REFT模型的运行设备为CUDA,即GPU,以加速计算。 -
reft_model.print_trainable_parameters():打印REFT模型中可训练参数的数量。这通常用于验证模型配置是否正确,以及了解模型的参数规模。
准备数据集
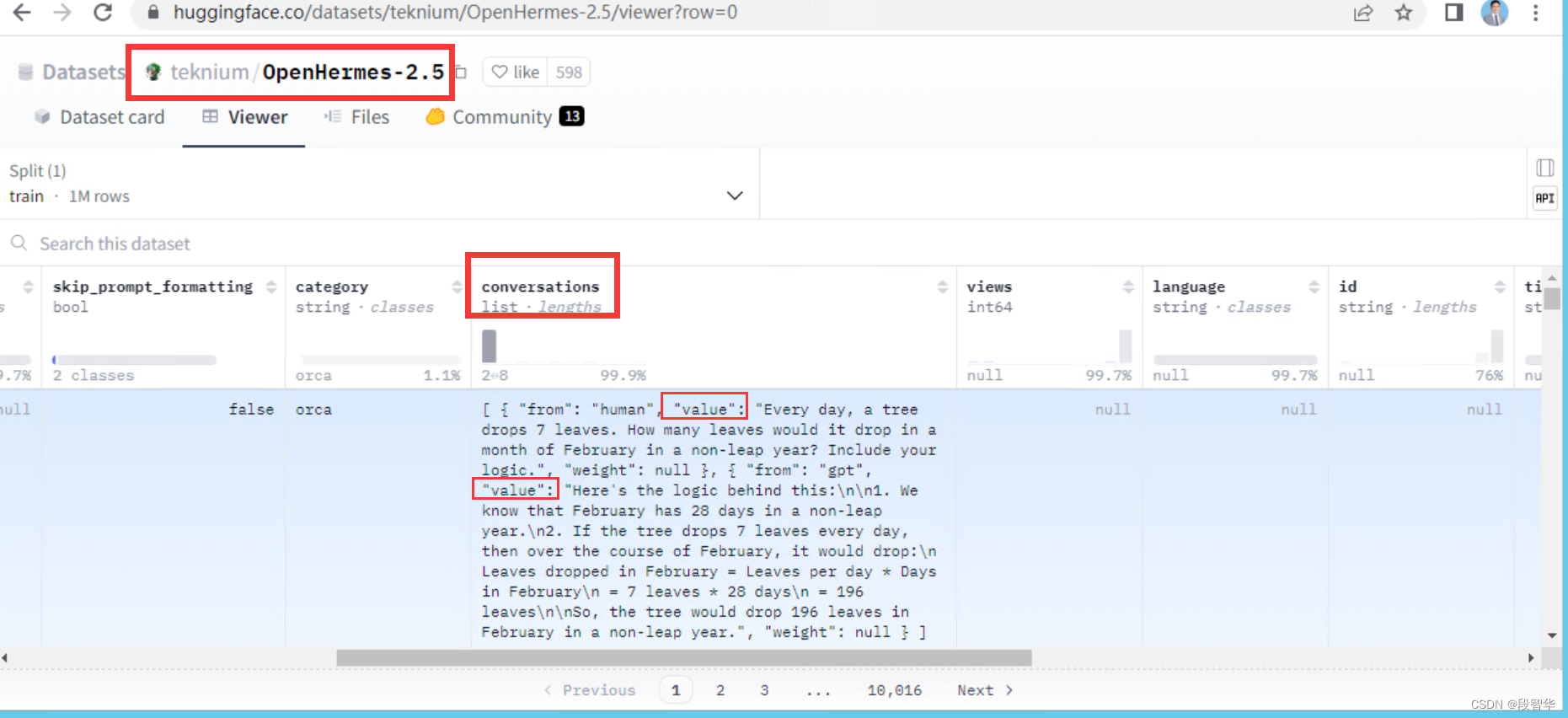
为微调准备数据集。 使用了OpenHermes-2.5数据集的10,000条子集。因为REFT训练器需要数据以特定格式存在, 将使用pyreft.make_last_position_supervised_data_module()函数来准备数据。
dataset_name = "teknium/OpenHermes-2.5"
from datasets import load_datasetdataset = load_dataset(dataset_name, split="train")
dataset = dataset.select(range(10_000))data_module = pyreft.make_last_position_supervised_data_module(tokenizer, model, [prompt_no_input_template % row["conversations"][0]["value"] for row in dataset], [row["conversations"][1]["value"] for row in dataset])
这段代码用于准备微调所需的数据集,并使用特定的函数来格式化数据,使其符合REFT(Representation Fine-Tuning)训练器的期望格式。
-
dataset_name = "teknium/OpenHermes-2.5":定义了要使用的OpenHermes-2.5数据集的名称。 -
from datasets import load_dataset:导入datasets库中的load_dataset函数,这个库通常用于加载和处理大型数据集。 -
dataset = load_dataset(dataset_name, split="train"):使用load_dataset函数加载指定数据集的训练集部分。 -
dataset = dataset.select(range(10_000)):从加载的数据集中选择前10,000个样本,创建一个新的数据集对象。 -
data_module = pyreft.make_last_position_supervised_data_module(...):使用pyreft库中的make_last_position_supervised_data_module函数来创建一个数据模块,这个模块将用于REFT训练。函数的参数包括:tokenizer:之前定义的分词器,用于将文本转换为模型可以理解的格式。model:之前加载的预训练模型。prompt_no_input_template % row["conversations"][0]["value"]:使用之前定义的prompt_no_input_template模板,并将其与数据集中每个样本的第一个对话值进行格式化,生成提示。row["conversations"][1]["value"]:直接使用数据集中每个样本的第二个对话值作为目标文本。
-
列表推导式
[prompt_no_input_template % row["conversations"][0]["value"] for row in dataset]和[row["conversations"][1]["value"] for row in dataset]分别生成了两个列表,一个包含格式化后的提示,另一个包含目标文本。
teknium/OpenHermes-2.5数据集
GPT 自回归语言模型架构、数学原理及内幕-简介
GPT 自回归语言模型架构、数学原理及内幕-简介
基于 Transformer 的 Rasa Internals 解密之 Retrieval Model 剖析-简介
基于 Transformer 的 Rasa Internals 解密之 Retrieval Model 剖析-简介
Transformer语言模型架构、数学原理及内幕机制-简介
Transformer语言模型架构、数学原理及内幕机制-简介
大模型技术分享



《企业级生成式人工智能LLM大模型技术、算法及案例实战》线上高级研修讲座
模块一:Generative AI 原理本质、技术内核及工程实践周期详解
模块二:工业级 Prompting 技术内幕及端到端的基于LLM 的会议助理实战
模块三:三大 Llama 2 模型详解及实战构建安全可靠的智能对话系统
模块四:生产环境下 GenAI/LLMs 的五大核心问题及构建健壮的应用实战
模块五:大模型应用开发技术:Agentic-based 应用技术及案例实战
模块六:LLM 大模型微调及模型 Quantization 技术及案例实战
模块七:大模型高效微调 PEFT 算法、技术、流程及代码实战进阶
模块八:LLM 模型对齐技术、流程及进行文本Toxicity 分析实战
模块九:构建安全的 GenAI/LLMs 核心技术Red Teaming 解密实战
模块十:构建可信赖的企业私有安全大模型Responsible AI 实战
Llama3关键技术深度解析与构建Responsible AI、算法及开发落地实战
1、Llama开源模型家族大模型技术、工具和多模态详解:学员将深入了解Meta Llama 3的创新之处,比如其在语言模型技术上的突破,并学习到如何在Llama 3中构建trust and safety AI。他们将详细了解Llama 3的五大技术分支及工具,以及如何在AWS上实战Llama指令微调的案例。
2、解密Llama 3 Foundation Model模型结构特色技术及代码实现:深入了解Llama 3中的各种技术,比如Tiktokenizer、KV Cache、Grouped Multi-Query Attention等。通过项目二逐行剖析Llama 3的源码,加深对技术的理解。
3、解密Llama 3 Foundation Model模型结构核心技术及代码实现:SwiGLU Activation Function、FeedForward Block、Encoder Block等。通过项目三学习Llama 3的推理及Inferencing代码,加强对技术的实践理解。
4、基于LangGraph on Llama 3构建Responsible AI实战体验:通过项目四在Llama 3上实战基于LangGraph的Responsible AI项目。他们将了解到LangGraph的三大核心组件、运行机制和流程步骤,从而加强对Responsible AI的实践能力。
5、Llama模型家族构建技术构建安全可信赖企业级AI应用内幕详解:深入了解构建安全可靠的企业级AI应用所需的关键技术,比如Code Llama、Llama Guard等。项目五实战构建安全可靠的对话智能项目升级版,加强对安全性的实践理解。
6、Llama模型家族Fine-tuning技术与算法实战:学员将学习Fine-tuning技术与算法,比如Supervised Fine-Tuning(SFT)、Reward Model技术、PPO算法、DPO算法等。项目六动手实现PPO及DPO算法,加强对算法的理解和应用能力。
7、Llama模型家族基于AI反馈的强化学习技术解密:深入学习Llama模型家族基于AI反馈的强化学习技术,比如RLAIF和RLHF。项目七实战基于RLAIF的Constitutional AI。
8、Llama 3中的DPO原理、算法、组件及具体实现及算法进阶:学习Llama 3中结合使用PPO和DPO算法,剖析DPO的原理和工作机制,详细解析DPO中的关键算法组件,并通过综合项目八从零开始动手实现和测试DPO算法,同时课程将解密DPO进阶技术Iterative DPO及IPO算法。
9、Llama模型家族Safety设计与实现:在这个模块中,学员将学习Llama模型家族的Safety设计与实现,比如Safety in Pretraining、Safety Fine-Tuning等。构建安全可靠的GenAI/LLMs项目开发。
10、Llama 3构建可信赖的企业私有安全大模型Responsible AI系统:构建可信赖的企业私有安全大模型Responsible AI系统,掌握Llama 3的Constitutional AI、Red Teaming。
解码Sora架构、技术及应用
一、为何Sora通往AGI道路的里程碑?
1,探索从大规模语言模型(LLM)到大规模视觉模型(LVM)的关键转变,揭示其在实现通用人工智能(AGI)中的作用。
2,展示Visual Data和Text Data结合的成功案例,解析Sora在此过程中扮演的关键角色。
3,详细介绍Sora如何依据文本指令生成具有三维一致性(3D consistency)的视频内容。 4,解析Sora如何根据图像或视频生成高保真内容的技术路径。
5,探讨Sora在不同应用场景中的实践价值及其面临的挑战和局限性。
二、解码Sora架构原理
1,DiT (Diffusion Transformer)架构详解
2,DiT是如何帮助Sora实现Consistent、Realistic、Imaginative视频内容的?
3,探讨为何选用Transformer作为Diffusion的核心网络,而非技术如U-Net。
4,DiT的Patchification原理及流程,揭示其在处理视频和图像数据中的重要性。
5,Conditional Diffusion过程详解,及其在内容生成过程中的作用。
三、解码Sora关键技术解密
1,Sora如何利用Transformer和Diffusion技术理解物体间的互动,及其对模拟复杂互动场景的重要性。
2,为何说Space-time patches是Sora技术的核心,及其对视频生成能力的提升作用。
3,Spacetime latent patches详解,探讨其在视频压缩和生成中的关键角色。
4,Sora Simulator如何利用Space-time patches构建digital和physical世界,及其对模拟真实世界变化的能力。
5,Sora如何实现faithfully按照用户输入文本而生成内容,探讨背后的技术与创新。
6,Sora为何依据abstract concept而不是依据具体的pixels进行内容生成,及其对模型生成质量与多样性的影响。
相关文章:
Llama模型家族之使用 ReFT技术对 Llama-3 进行微调(三)为 ReFT 微调准备模型及数据集
LlaMA 3 系列博客 基于 LlaMA 3 LangGraph 在windows本地部署大模型 (一) 基于 LlaMA 3 LangGraph 在windows本地部署大模型 (二) 基于 LlaMA 3 LangGraph 在windows本地部署大模型 (三) 基于 LlaMA…...
学习Canvas过程中2D的方法、注释及感悟一(通俗易懂)
1.了解Canvas: Canvas是前端一个很重要的知识点,<canvas>标签用于创建画布绘制图形,通过JavaScript进行操作。它为开发者提供一个动态绘制图形的区域,用于创建图标、游戏动画、图像处理等。 对于能够熟练使用Canvas的开发者…...

《TCP/IP网络编程》(第十三章)多种I/O函数(2)
使用readv和writev函数可以提高数据通信的效率,它们的功能可以概括为**“对数据进行整合传输及发送”**。 即使用writev函数可以将分散在多个缓冲中的数据一并发送,使用readv函数可以由多个缓冲分别接受,所以适当使用他们可以减少I/O函数的调…...

Java集合汇总
Java中的集合框架是Java语言的核心部分,提供了强大的数据结构来存储和操作对象集合。集合框架位于java.util包中,主要可以分为两大类:Collection(单列集合)和Map(双列集合)。下面是对它们的总结…...
度小满金融大模型的应用创新
XuanYuan/README.md at main Duxiaoman-DI/XuanYuan GitHub...
Android WebView上传文件/自定义弹窗技术,附件的解决方案
安卓内核开发 其实是Android的webview默认是不支持<input type"file"/>文件上传的。现在的前端页面需要处理的是: 权限 文件路径AndroidManifest.xml <uses-permission android:name"android.permission.WRITE_EXTERNAL_STORAGE"/&g…...

selenium 输入框、按钮,输入点击,获取元素属性等简单例子
元素操作 nput框 输入send_keys, input框 清除clear(), 按钮 点击click() 按钮 提交submit() 获取元素 tag_name、 class属性值、 坐标尺寸 """ input框 输入1次,再追加输入一次, 清除, 再重新输入&…...

结构体构造函数
【知识点:结构体构造函数】下面两段代码等价。 (1)结构体构造函数写法 struct LinkNode {int data;LinkNode* next;LinkNode(int x):data(x),next(NULL) {} }; LinkNode* Lnew LinkNode(123); (2)非结构体构造函数写…...

基于单片机的电子万年历设计
摘要: 本设计以 AT89C51 单片机为主控器,使用 DS1302 时钟芯片、DS18B20 温度芯片、LCD1602 显示模块,利用Proteus 仿真软件和 Keil 编译软件进行了基于单片机的电子万年历仿真,设计的万年历可以在液晶上显示时间,同时还具有时间校准、温度显示等功能。 关键词 :单片机…...

大厂真实面试题(一)
滴滴大数据sql 取出累计值与1000差值最小的记录 1.题目 已知有表t_cost_detail包含id和money两列,id为自增,请累加计算money值,并求出累加值与1000差值最小的记录。 2.分析 本题主要是想找到累加值域1000差距最小的记录,也就是我们要对上述按照id进行排序并且累加,并…...
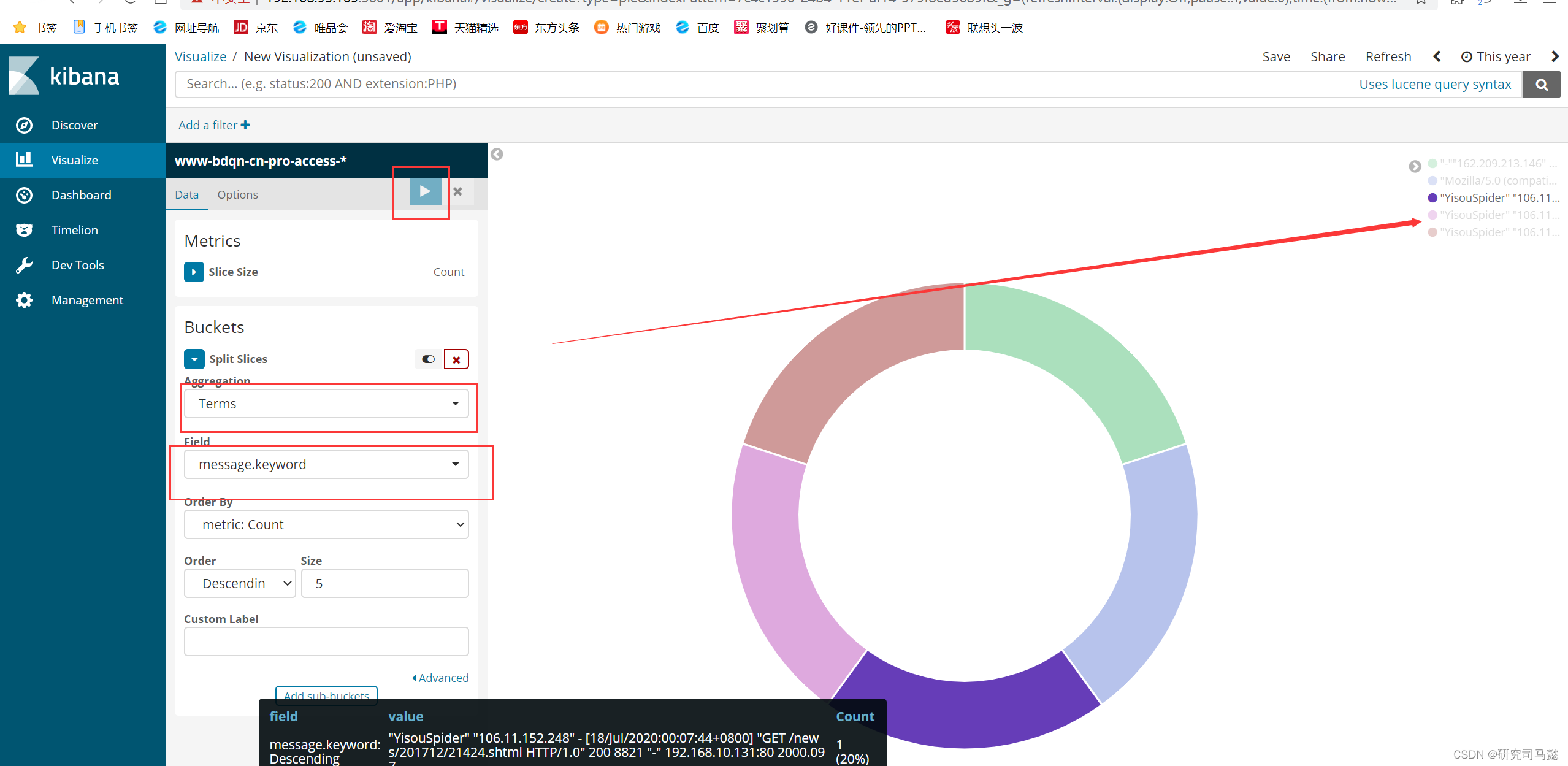
Docker搭建ELKF日志分析系统
Docker搭建ELKF日志分析系统 文章目录 Docker搭建ELKF日志分析系统资源列表基础环境一、系统环境准备1.1、创建所需的映射目录1.2、修改系统参数1.3、单击创建elk-kgc网络桥接 二、基于Dockerfile构建Elasticsearch镜像2.1、创建Elasticsearch工作目录2.2、上传资源到指定工作路…...
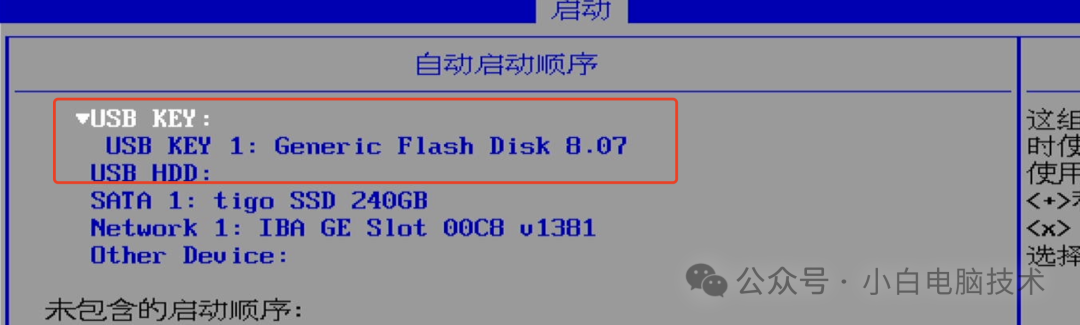
把系统引导做到U盘,实现插上U盘才能开机
前言 有个小伙伴提出了这样一个问题:能不能把U盘制作成电脑开机的钥匙? 小白稍微思考了一下,便做了这样一个回复:可以。 至于为什么要思考一下,这样会显得我有认真思考他提出的问题。 Windows7或以上系统均支持UEF…...
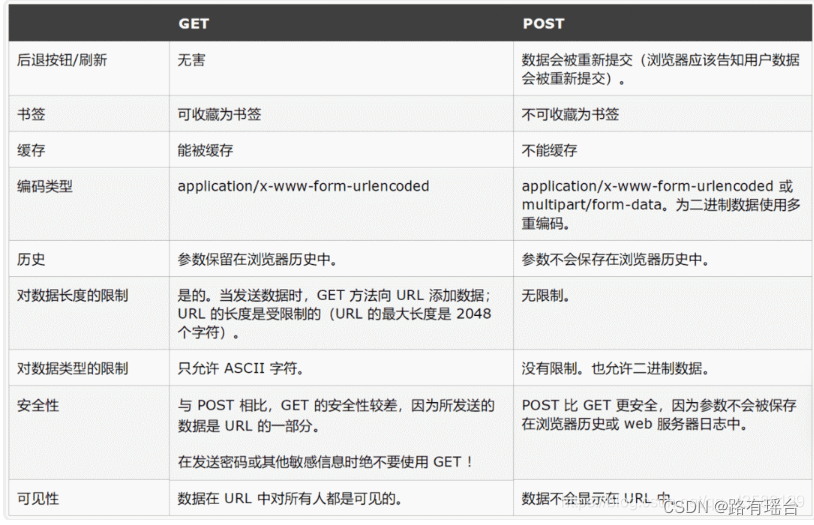
【计算机网络基础知识】
首先举一个生活化的例子,当你和朋友打电话时,你可能会使用三次握手和四次挥手的过程进行类比: 三次握手(Three-Way Handshake): 你打电话给朋友:你首先拨打你朋友的电话号码并等待他接听。这就…...

个股场外期权个人如何参与买卖?
个股场外期权作为一种金融衍生品,为个人投资者提供了多样化的投资选择和风险管理工具。想要参与个股场外期权的买卖,以下是一些关键步骤和考虑因素。 文章来源/:财智财经 第一步:选择合适的金融机构 首先,个人投资者需…...
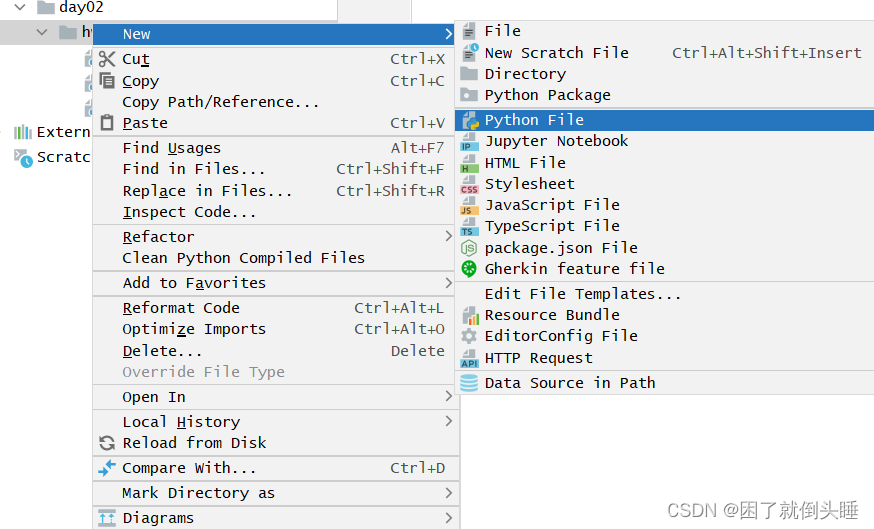
程序猿大战Python——pycharm软件的使用
基础配置 目标:了解PyCharm软件的基础配置处理。 修改背景颜色: Appearance -> Theme 修改字体大小: 搜索font -> Font 例如,一起完成背景、字体大小的修改。 总结: (1)如果要对PyChar…...

Unity Standard shader 修改(增加本地坐标裁剪)
本想随便找一个裁剪的shader,可无奈的是没找到一个shader符合要求,美术制作的场景都是用的都标准的着色器他们不在乎你的功能逻辑需求,他们只关心场景的表现,那又找不到和unity标准着色器表现一样的shader 1.通过贴图的透明通道做…...

【数据结构】排序——插入排序,选择排序
前言 本篇博客我们正式开启数据结构中的排序,说到排序,我们能联想到我之前在C语言博客中的冒泡排序,它是排序中的一种,但实现效率太慢,这篇博客我们介绍两种新排序,并好好深入理解排序 💓 个人主…...

2024.6.9刷题记录
目录 一、1103. 分糖果 II 1.模拟 2.数学 二、312. 戳气球 1.递归-记忆化搜索 2.区间dp 三、2. 两数相加 1.迭代 2.递归-新建节点 3.递归-原节点 四、4. 寻找两个正序数组的中位数 1.堆 2.双指针二分 五、5. 最长回文子串 1.动态规划 2.中心扩展算法 六、6. Z…...
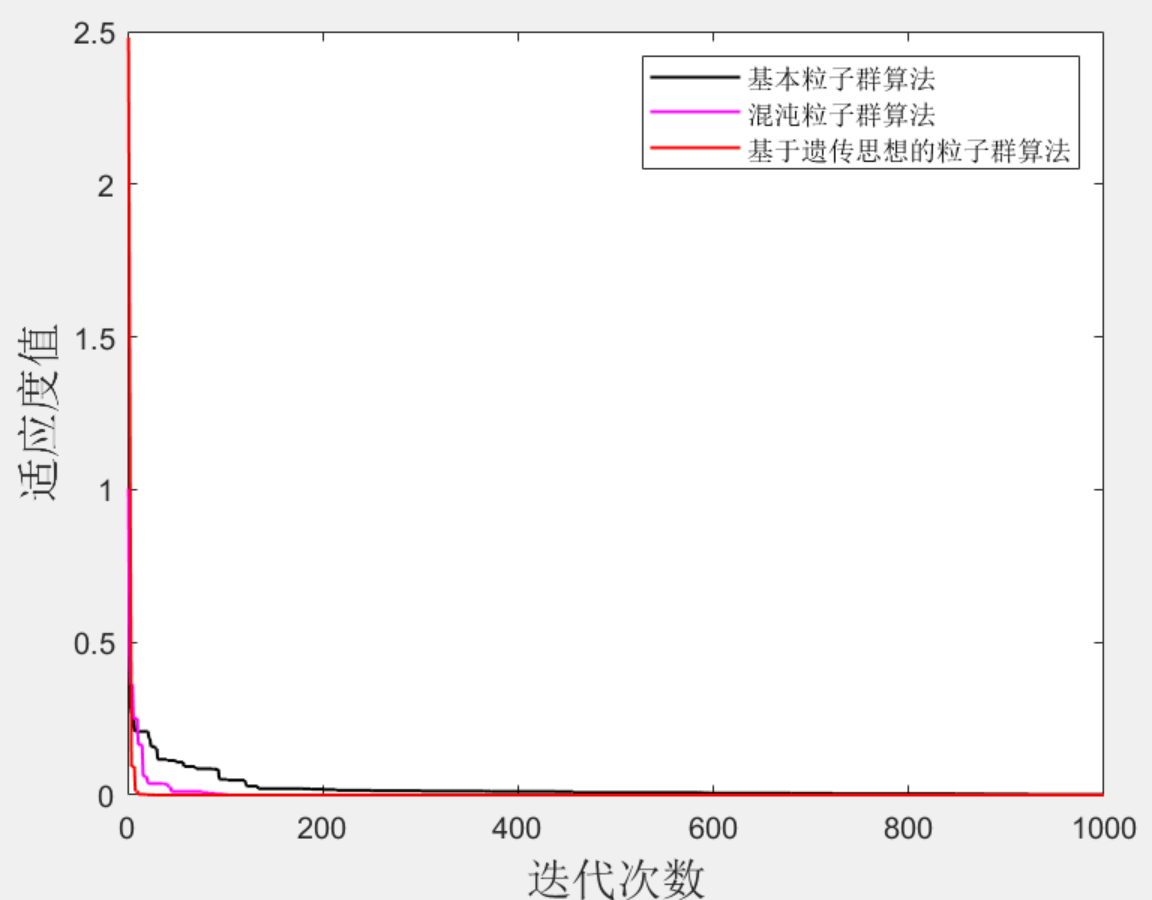
Matlab|遗传粒子群-混沌粒子群-基本粒子群
目录 1 主要内容 2 部分代码 3 效果图 4 下载链接 1 主要内容 很多同学在发文章时候最犯愁的就是创新点创新点创新点(重要的事情说三遍),对于采用智能算法的模型,可以采用算法改进的方式来达到提高整个文章创新水平的目的&…...
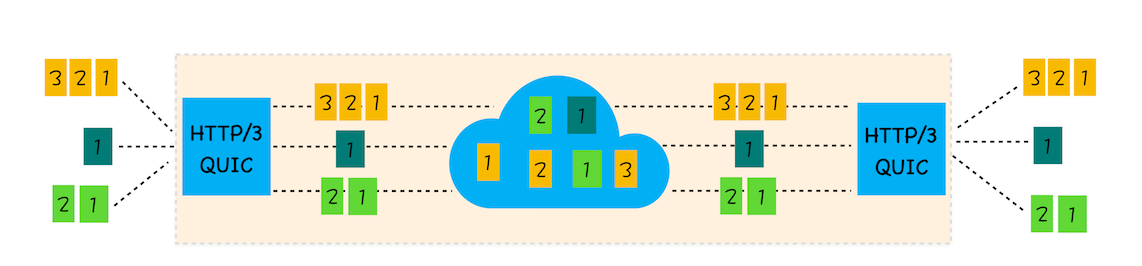
31|HTTP3:甩掉TCP、TLS 的包袱,构建高效网络
前面两篇文章我们分析了HTTP/1和HTTP/2,在HTTP/2出现之前,开发者需要采取很多变通的方式来解决HTTP/1所存在的问题,不过HTTP/2在2018年就开始得到了大规模的应用,HTTP/1中存在的一大堆缺陷都得到了解决。 HTTP/2的一个核心特性是…...
?爬楼梯模型(求排列)?)
背包模型(求组合)?爬楼梯模型(求排列)?
普通背包模型和爬楼梯模型是非常相似的两个模型。 首先,我们定义一个**“抽象背包模型”**(注意这个抽象背包模型不是前面提到的普通背包模型):给定 n 个物品,装满容积为 m 的背包,求方案数/具体方案/等等…...

深入浅出Livepatch:从kprobe到ftrace的Linux热补丁实现原理
深入浅出Livepatch:从kprobe到ftrace的Linux热补丁实现原理 当你的生产环境服务器正在处理每秒数万次请求时,突然发现一个关键内核漏洞需要立即修复,传统方式要求重启系统——这无异于在高速公路上急刹车。Livepatch技术应运而生,…...
快速上手教程)
Qwen3.5-2B镜像免配置部署:开箱即用WebUI(7860端口)快速上手教程
Qwen3.5-2B镜像免配置部署:开箱即用WebUI(7860端口)快速上手教程 1. 模型简介 Qwen3.5-2B是通义千问系列中的轻量化多模态基础模型,仅有20亿参数规模,专为低功耗、低门槛部署场景设计。这个版本特别适合在端侧设备和…...

【技术干货】把 Claude 变成“本地自动化工程师”:Anthropic Computer Use 能力与实战落地指南
摘要 Anthropic 在 Claude Code 中正式引入 Computer Use 能力,让大模型可以直接操作你的桌面应用和浏览器,从“写代码助手”升级为“全栈自动化代理”。本文从原理、典型场景、跨平台替代方案,到如何用统一 OpenAI 兼容 API(基于…...

3大技术突破重新定义魔兽地图编辑工作流
3大技术突破重新定义魔兽地图编辑工作流 【免费下载链接】HiveWE A Warcraft III world editor. 项目地址: https://gitcode.com/gh_mirrors/hi/HiveWE 对于《魔兽争霸III》地图制作者而言,最令人沮丧的体验莫过于:精心设计的地形布局在实际测试中…...

ANIMATEDIFF PRO教学创新:Jupyter Notebook交互式教程
ANIMATEDIFF PRO教学创新:Jupyter Notebook交互式教程 让AI动画学习变得像玩游戏一样有趣,实时调整参数,即刻看到效果变化 1. 引言:为什么需要交互式动画教学? 传统的AI动画教学有个痛点:学生写了一大段代…...

Python大麦网智能抢票脚本:三分钟搭建你的自动购票系统
Python大麦网智能抢票脚本:三分钟搭建你的自动购票系统 【免费下载链接】Automatic_ticket_purchase 大麦网抢票脚本 项目地址: https://gitcode.com/GitHub_Trending/au/Automatic_ticket_purchase 还在为抢不到心仪的演唱会门票而烦恼吗?每次开…...
`反而变慢了?Python 3.14 JIT缓存键生成算法变更深度解析(附3.13→3.14 ABI不兼容警告))
为什么你的`@jit(cache=True)`反而变慢了?Python 3.14 JIT缓存键生成算法变更深度解析(附3.13→3.14 ABI不兼容警告)
第一章:Python 3.14 JIT 编译器性能调优 面试题汇总Python 3.14 引入了实验性内置 JIT(Just-In-Time)编译器,基于 PGO(Profile-Guided Optimization)与轻量级字节码重写机制,在 CPU-bound 场景下…...

GinCdn内容分发系统V1.0.9更新内容
GinCdn内容分发系统GinCdn是一款基于Go语言Gin框架自研的轻量高效内容分发系统,专为中小型企业/个人搭建CDN打造,采用主控边缘节点分布式架构,实现智能调度、高效缓存、精准监控的一体化解决方案。无需复杂命令行,小白也能轻松上手…...

从三角函数到雷达滤波:三角窗的DSP实现与性能测试全记录
从三角函数到雷达滤波:三角窗的DSP实现与性能测试全记录 1. 三角窗的数学本质与信号处理价值 在数字信号处理领域,窗函数就像是一位精密的调音师,能够对原始信号进行细致的修饰和调整。三角窗作为其中最基础却又最富特色的成员之一࿰…...