【实战】kafka3.X kraft模式集群搭建
文章目录
- 前言
- kafka2.0与3.x对比
- 准备工作
- JDK安装
- kafka安装
- 服务器增加hosts
- 修改Kraft协议配置文件
- 格式化存储目录
- 启动集群
- 停止集群
- 测试Kafka集群
- 创建topic
- 查看topic列表
- 查看消息详情
- 生产消息
- 消费消息
- 查看消费者组
- 查看消费者组列表
前言
相信很多同学都用过Kafka2.0吧,其中需要zookepper集群来做元数据管理和集群选举,大大增加了运维成本,而且也很是影响Kafka性能。言归正传今天我们就分享一期Kafka3.x Kraft模式集群搭建,简直不要太爽。
kafka2.0与3.x对比

上图中黑色代表broker(消息代理服务),褐色/蓝色代表Controller(集群控制器服务)
左图(kafka2.0):一个集群所有节点都是broker角色,kafka从三个broker中选举出来一个Controller控制器,控制器将集群元数据信息(比如主题分类、消费进度等)保存到zookeeper,用于集群各节点之间分布式交互。
右图(kafka3.0):假设一个集群有四个broker,指定三个作为Conreoller角色(蓝色),从三个Controller中选举出来一个Controller作为主控制器(褐色),其他的2个备用。zookeeper不再被需要!相关的元数据信息以kafka日志的形式存在(即:以消息队列消息的形式存在)。
controller通信端口:9093, 作用与zk的2181端口类似 。
这样做的好处有以下几个:
- Kafka 不再依赖外部框架,而是能够独立运行;
- controller 管理集群时,不再需要从 zookeeper 中先读取数据,集群性能上升;
- 由于不依赖 zookeeper,集群扩展时不再受到 zookeeper 读写能力限制;
在搭建kafka3.0集群之前, 我们需要先做好kafka实例角色规划。(三个broker, 需要通过主动配置指定三个作为Controller, Controller需要奇数个, 这一点和zk是一样的)
| 主机名称 | ip | 角色 | node.id |
|---|---|---|---|
| senfel-test | 192.168.112.10 | broker,controller | 1 |
| senfel-test2 | 192.168.112.130 | broker,controller | 2 |
| senfel-test3 | 192.168.112.129 | broker,controller | 3 |
准备工作
JDK安装
kafka3.x不再支持JDK8,依然可用,建议安装JDK11或JDK17。
新建kafka持久化日志数据mkdir -p /data/kafka;并保证安装kafka的用户具有该目录的读写权限。
各个机器节点执行:
安装jdk(kafka3.x不再支持JDK8,目前暂时还可以用,建议安装JDK11或JDK17, 这里安装jdk11)
下载安装jdk省略
kafka安装
下载kafka

cd /
mkdir tools
cd tools
wget https://downloads.apache.org/kafka/3.5.2/kafka_2.12-3.5.2.tgz
tar -xf kafka_2.12-3.5.2.tgz
chown -R kafka:kafka kafka_2.12-3.5.2*
mkdir -p /data/kafka
chown -R kafka:kafka /data/kafka
服务器增加hosts
vim /etc/hosts,各个节点,添加如下内容:
192.168.112.10 data-vm1
192.168.112.130 data-vm2
192.168.112.129 data-vm3
修改Kraft协议配置文件
在kafka3.x版本中,使用Kraft协议代替zookeeper进行集群的Controller选举,所以要针对它进行配置。
vim /tools/kafka_2.12-3.5.2/config/kraft/server.properties
具体配置参数如下:
# data-vm1节点
node.id=1
process.roles=broker,controller
listeners=PLAINTEXT://data-vm1:9092,CONTROLLER://data-vm1:9093
advertised.listeners=PLAINTEXT://:9092
controller.quorum.voters=1@data-vm1:9093,2@data-vm2:9093,3@data-vm3:9093
log.dirs=/data/kafka/
num.partitions=3
offsets.topic.replication.factor=3
transaction.state.log.replication.factor=3
transaction.state.log.min.isr=3# data-vm2节点
node.id=2
process.roles=broker,controller
listeners=PLAINTEXT://data-vm2:9092,CONTROLLER://data-vm2:9093
advertised.listeners=PLAINTEXT://:9092
controller.quorum.voters=1@data-vm1:9093,2@data-vm2:9093,3@data-vm3:9093
log.dirs=/data/kafka/
num.partitions=3
offsets.topic.replication.factor=3
transaction.state.log.replication.factor=3
transaction.state.log.min.isr=3
# data-vm3节点
node.id=3
process.roles=broker,controller
listeners=PLAINTEXT://data-vm3:9092,CONTROLLER://data-vm3:9093
advertised.listeners=PLAINTEXT://:9092
controller.quorum.voters=1@data-vm1:9093,2@data-vm2:9093,3@data-vm3:9093
log.dirs=/data/kafka/
num.partitions=3
offsets.topic.replication.factor=3
transaction.state.log.replication.factor=3
transaction.state.log.min.isr=3
node.id:这将作为集群中的节点 ID,唯一标识,按照我们事先规划好的(上文),在不同的服务器上这个值不同。其实就是kafka2.0中的broker.id,只是在3.0版本中kafka实例不再只担任broker角色,也有可能是controller角色,所以改名叫做node节点。
process.roles:一个节点可以充当broker或controller或两者兼而有之。按照我们事先规划好的(上文),在不同的服务器上这个值不同。多个角色用逗号分开。
listeners: broker将使用9092端口,而kraft controller控制器将使用9093端口。
advertised.listeners: 这里指定kafka通过代理暴漏的地址,如果都是局域网使用,就配置PLAINTEXT://:9092即可。
controller.quorum.voters:这个配置用于指定controller主控选举的投票节点,所有process.roles包含controller角色的规划节点都要参与,即:zimug1、zimug2、zimug3。其配置格式为:node.id1@host1:9093,node.id2@host2:9093
log.dirs:kafka 将存储数据的日志目录,在准备工作中创建好的目录。
num_partitions: 分区,一般根据broker数量进行确定
offset.topic.replication.factor: 副本数,一般根据broker数量进行确定
所有kafka节点都要按照上文中的节点规划进行配置,完成config/kraft/server.properties配置文件的修改。
格式化存储目录
生成一个唯一的集群ID(在一台kafka服务器上执行一次即可),这一个步骤是在安装kafka2.0版本的时候不存在的。
sudo /tools/kafka_2.12-3.5.2/bin/kafka-storage.sh random-uuid
MsBU_ZELT2G0E0oPFX6Gxw
使用生成的集群ID+配置文件格式化存储目录log.dirs,
所以这一步确认配置及路径确实存在,
并且kafka用户有访问权限(检查准备工作是否做对)
主机服务器执行命令:
sudo /tools/kafka_2.12-3.5.2/bin/kafka-storage.sh format
-t MsBU_ZELT2G0E0oPFX6Gxw
-c /tools/kafka_2.12-3.5.2/config/kraft/server.properties

格式化操作完成之后,log.dirs目录下多出一个Meta.properties文件,存储了当前的kafka节点的id(node.id),当前节点属于哪个集群(cluster.id)
[root@senfel-test tools]# cd /data/kafka/
[root@senfel-test kafka]# ll
总用量 8
-rw-r–r–. 1 root root 249 6月 4 15:46 bootstrap.checkpoint
-rw-r–r–. 1 root root 86 6月 4 15:46 meta.properties
[root@senfel-test kafka]# cat meta.properties
#Tue Jun 04 15:46:15 CST 2024
cluster.id=MsBU_ZELT2G0E0oPFX6Gxw
version=1
node.id=1
[root@senfel-test kafka]#
senfel-test2:
sudo /tools/kafka_2.12-3.5.2/bin/kafka-storage.sh format
-t MsBU_ZELT2G0E0oPFX6Gxw
-c /tools/kafka_2.12-3.5.2/config/kraft/server.properties
[root@senfel-test2 tools]# cd /data/kafka/
[root@senfel-test2 kafka]# ll
总用量 8
-rw-r–r–. 1 root root 249 6月 4 15:49 bootstrap.checkpoint
-rw-r–r–. 1 root root 86 6月 4 15:49 meta.properties
[root@senfel-test2 kafka]# cat meta.properties
#Tue Jun 04 15:49:55 CST 2024
cluster.id=N2TANgN1TDyZLAbpN36IxA
version=1
node.id=2
[root@senfel-test2 kafka]#
senfel-test3
sudo /tools/kafka_2.12-3.5.2/bin/kafka-storage.sh format
-t MsBU_ZELT2G0E0oPFX6Gxw
-c /tools/kafka_2.12-3.5.2/config/kraft/server.properties
[root@senfel-test3 /]# cd /data/kafka/
[root@senfel-test3 kafka]# ll
总用量 8
-rw-r–r–. 1 root root 249 6月 4 15:52 bootstrap.checkpoint
-rw-r–r–. 1 root root 86 6月 4 15:52 meta.properties
[root@senfel-test3 kafka]# cat meta.properties
#Tue Jun 04 15:52:11 CST 2024
cluster.id=KI0RD9FcQnaXNXeq49Gjuw
version=1
node.id=3
[root@senfel-test3 kafka]#
启动集群
有防火墙记得放行:
[root@senfel-test bin]# vim /etc/sysconfig/iptables
-A INPUT -p tcp -m state --state NEW -m tcp --dport 9092 -j ACCEPT
-A INPUT -p tcp -m state --state NEW -m tcp --dport 9093 -j ACCEPT
[root@senfel-test bin]# systemctl restart iptables
启动命令:
/tools/kafka_2.12-3.5.2/bin/kafka-server-start.sh
/tools/kafka_2.12-3.5.2/config/kraft/server.properties
后台运行:
nohup /tools/kafka_2.12-3.5.2/bin/kafka-server-start.sh
/tools/kafka_2.12-3.5.2/config/kraft/server.properties 2>&1 &
脚本:
vim kafka-start.sh
#!/bin/bash
kafkaServers='data-vm1 data-vm2 data-vm3'
#启动所有的kafka
for kafka in $kafkaServers
dossh -T $kafka <<EOFnohup /tools/kafka_2.12-3.5.2/bin/kafka-server-start.sh /tools/kafka_2.12-3.5.2/config/kraft/server.properties 1>/dev/null 2>&1 &
EOF
echo 从节点 $kafka 启动kafka3.0...[ done ]
sleep 5
done
chmod +x kafka-start.sh
sh kafka-start.sh
停止集群
一键停止kafka集群各节点的脚本,与启动脚本的使用方式及原理是一样的。
停止命令:
sudo /tools/kafka_2.12-3.5.2/bin/kafka-server-stop.sh
执行脚本:
#!/bin/bash
kafkaServers='data-vm1 data-vm2 data-vm3'
#停止所有的kafka
for kafka in $kafkaServers
dossh -T $kafka <<EOFcd /tools/kafka_2.12-3.5.2bin/kafka-server-stop.sh
EOF
echo 从节点 $kafka 停止kafka...[ done ]
sleep 5
done
测试Kafka集群
创建topic
[root@senfel-test2 logs]# /tools/kafka_2.12-3.5.2/bin/kafka-topics.sh
–create
–topic senfel-test-topic
–bootstrap-server data-vm1:9092
Created topic senfel-test-topic.
查看topic列表
[root@senfel-test2 logs]# /tools/kafka_2.12-3.5.2/bin/kafka-topics.sh
–list
–bootstrap-server data-vm1:9092
senfel-test-topic
[root@senfel-test2 logs]# /tools/kafka_2.12-3.5.2/bin/kafka-topics.sh --list --bootstrap-server data-vm2:9092
senfel-test-topic
[root@senfel-test2 logs]# /tools/kafka_2.12-3.5.2/bin/kafka-topics.sh --list --bootstrap-server data-vm3:9092
senfel-test-topic
[root@senfel-test2 logs]#
查看消息详情
[root@senfel-test2 logs]# /tools/kafka_2.12-3.5.2/bin/kafka-topics.sh
–describe
–topic senfel-test-topic
–bootstrap-server data-vm1:9092
Topic: senfel-test-topic TopicId: h2Cz-yq2RYeMY3ylHuk3iw PartitionCount: 3 ReplicationFactor: 1 Configs: segment.bytes=1073741824
Topic: senfel-test-topic Partition: 0 Leader: 1 Replicas: 1 Isr: 1
Topic: senfel-test-topic Partition: 1 Leader: 2 Replicas: 2 Isr: 2
Topic: senfel-test-topic Partition: 2 Leader: 3 Replicas: 3 Isr: 3
生产消息
[root@senfel-test2 logs]# /tools/kafka_2.12-3.5.2/bin/kafka-console-producer.sh
–topic senfel-test-topic
–bootstrap-server data-vm1:9092
消费消息
[root@senfel-test3 logs]# /tools/kafka_2.12-3.5.2/bin/kafka-console-consumer.sh
–topic senfel-test-topic
–from-beginning
–bootstrap-server data-vm2:9092
–group my-group
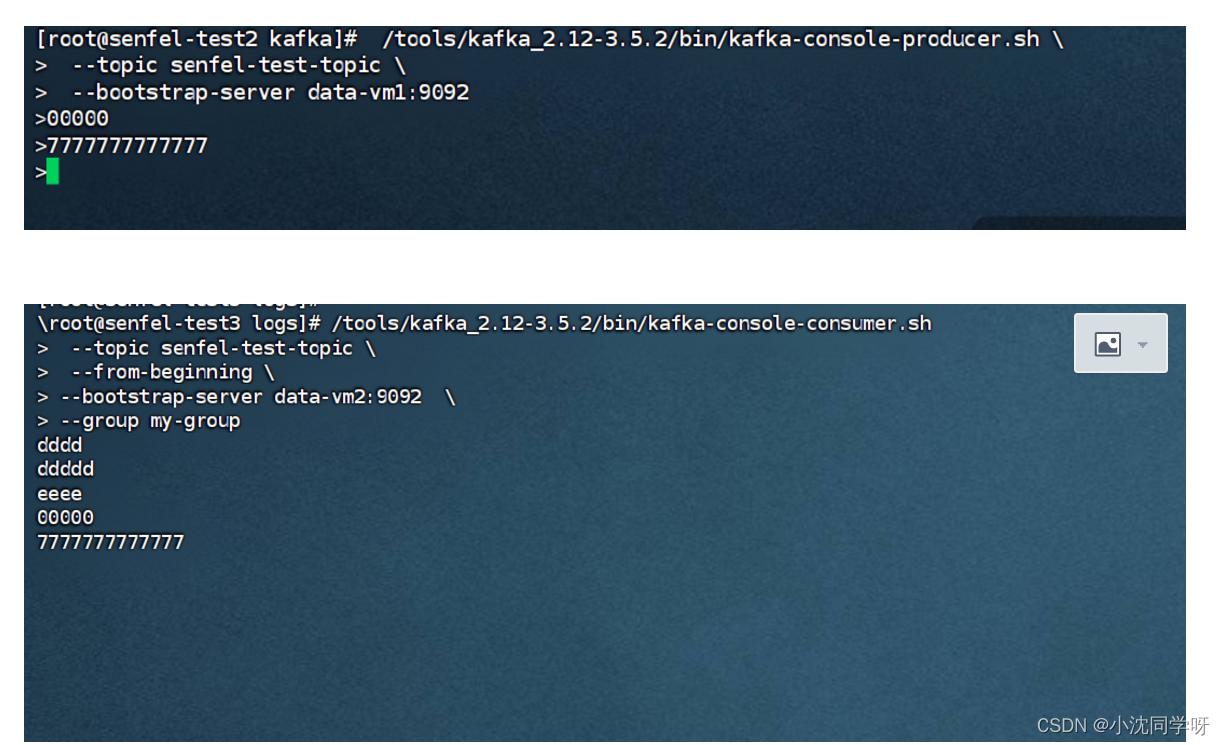
查看消费者组
#检查消费者postition
[root@senfel-test kafka]# sudo /tools/kafka_2.12-3.5.2/bin/kafka-consumer-groups.sh
–bootstrap-server data-vm2:9092
–describe
–all-groups
sudo /tools/kafka_2.12-3.5.2/bin/kafka-consumer-groups.sh
–bootstrap-server data-vm2:9092
–describe
–group my-group-new
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
my-group senfel-test-topic 0 2 2 0 console-consumer-490ae3b3-e944-49be-a6e7-c4bae3696a0f /192.168.112.129 console-consumer
my-group senfel-test-topic 1 4 4 0 console-consumer-490ae3b3-e944-49be-a6e7-c4bae3696a0f /192.168.112.129 console-consumer
my-group senfel-test-topic 2 0 0 0 console-consumer-490ae3b3-e944-49be-a6e7-c4bae3696a0f /192.168.112.129 console-consumer
[root@senfel-test kafka]#
查看消费者组列表
[root@senfel-test kafka]# /tools/kafka_2.12-3.5.2/bin/kafka-consumer-groups.sh
–bootstrap-server data-vm1:9092
–list
my-group
相关文章:
【实战】kafka3.X kraft模式集群搭建
文章目录 前言kafka2.0与3.x对比准备工作JDK安装kafka安装服务器增加hosts 修改Kraft协议配置文件格式化存储目录 启动集群停止集群测试Kafka集群创建topic查看topic列表查看消息详情生产消息消费消息查看消费者组查看消费者组列表 前言 相信很多同学都用过Kafka2.0吧…...
华为防火墙配置 SSL VPN
前言 哈喽,我是ICT大龙。本期给大家更新一次使用华为防火墙实现SSL VPN的技术文章。 本次实验只需要用到两个软件,分别是ENSP和VMware,本次实验中的所有文件都可以在文章的末尾获取。话不多说,教程开始。 什么是VPN 百度百科解…...
Redis的删除策略与内存淘汰
文章目录 删除策略设置过期时间的常用命令过期删除策略 内存淘汰相关设置LRU算法LFU 总结 在redis使用过程中,常常遇到以下问题: 如何设置Redis键的过期时间?设置完一个键的过期时间后,到了这个时间,这个键还能获取到么…...

《一心体系至善算法》“人文+AI”成果
《一心体系至善算法》“人文AI”成果 人工智能(AI)和通用人工智能(AGI)的伦理与安全问题: 在《中法联合声明》中,着重强调了AI向善问题。在探讨人工智能(AI)和通用人工智能(AGI&…...

C#面:阐述对DDD的理解
C#是一种面向对象的编程语言,而领域驱动设计(Domain-Driven Design,简称DDD)是一种软件开发方法论,它强调将业务领域的知识和逻辑直接融入到软件设计和开发中。 在C#中实施DDD的关键是将业务领域划分为不同的领域模型…...
音视频开发19 FFmpeg 视频解码- 将 h264 转化成 yuv
视频解码过程 视频解码过程如下图所示: ⼀般解出来的是420p FFmpeg流程 这里的流程是和音频的解码过程一样的,不同的只有在存储YUV数据的时候的形式 存储YUV 数据 如果知道YUV 数据的格式 前提:这里我们打开的h264文件,默认是YU…...
Mysql 常用命令 详细大全【分步详解】
1、启动和停止MySQL服务 // 暂停服务 默认 80 net stop mysql80// 启动服务 net start mysql80// 任意地方启动 mysql 客户端的连接 mysql -u root -p 2、输入密码 3、数据库 4、DDL(Data Definition Language )数据 定义语言, 用来定义数据库对象(数…...
基于百度接口的实时流式语音识别系统
目录 基于百度接口的实时流式语音识别系统 1. 简介 2. 需求分析 3. 系统架构 4. 模块设计 4.1 音频输入模块 4.2 WebSocket通信模块 4.3 音频处理模块 4.4 结果处理模块 5. 接口设计 5.1 WebSocket接口 5.2 音频输入接口 6. 流程图 程序说明文档 1. 安装依赖 2.…...

AIGC作答《2024年高考作文|新课标I卷》能拿多少分?
AIGC作答《2024年高考作文|新课标I卷》能拿多少分? 一、前言二、题目三、作答 一、前言 如火如荼的2024年高考圆满落幕,在如此Happy的时刻,AIGC技术正以其前所未有的热度席卷全球。它不仅改变了我们获取信息的方式,也…...

WHAT - 发布订阅
目录 一、常见实现方案1.1 使用事件发射器(Event Emitter)1.2 自定义事件系统(EventBus)1.3 使用库如 PubSubJS1.4 使用框架内置的状态管理工具Vue.jsReact (使用 Context API 或 Redux) 二、先后关系2.1 缓存事件数据2.2 使用 Re…...
useEffect)
React@16.x(23)useEffect
目录 1,介绍作用介绍 2,注意点2.1,参数1,副作用函数2.1.1,运行时间点2.1.2,返回值2.1.3,闭包的影响2.1.4,严禁出现在代码块中(判断,循环)2.1.5&am…...

算法竞赛一句话解题经典问题分析 ©ntsc 2024
原名:算法竞赛一句话解题&经典问题分析 ©ntsc 2024 处理进度 绿:P1381【~P(今日进度)】蓝:P1099 致CSDN网友: 本文章不定期更新!文章链接: 经典问题分析 基础知识与编程…...

【TensorFlow深度学习】强化学习中的贝尔曼方程及其应用
强化学习中的贝尔曼方程及其应用 强化学习中的贝尔曼方程及其应用:理解与实战演练贝尔曼方程简介应用场景代码实例:使用Python实现贝尔曼方程求解状态价值结语 强化学习中的贝尔曼方程及其应用:理解与实战演练 在强化学习这一复杂而迷人的领…...

牛客 NC129 阶乘末尾0的数量【简单 基础数学 Java/Go/PHP/C++】
题目 题目链接: https://www.nowcoder.com/practice/aa03dff18376454c9d2e359163bf44b8 https://www.lintcode.com/problem/2 思路 Java代码 import java.util.*;public class Solution {/*** 代码中的类名、方法名、参数名已经指定,请勿修改ÿ…...

【Spring Boot】异常处理
异常处理 1.认识异常处理1.1 异常处理的必要性1.2 异常的分类1.3 如何处理异常1.3.1 捕获异常1.3.2 抛出异常1.3.4 自定义异常 1.4 Spring Boot 默认的异常处理 2.使用控制器通知3.自定义错误处理控制器3.1 自定义一个错误的处理控制器3.2 自定义业务异常类3.2.1 自定义异常类3…...

Laravel学习-自定义辅助函数
因为laravel框架的辅助函数helpers不会进入版本库,被版本库忽略的,只有自己创建一个helpers辅助函数。 可以在任意文件下创建helpers.php文件,建议在app目录下, 然后在composer.json文件中,autoload 中间,…...

LLVM Cpu0 新后端6
想好好熟悉一下llvm开发一个新后端都要干什么,于是参考了老师的系列文章: LLVM 后端实践笔记 代码在这里(还没来得及准备,先用网盘暂存一下): 链接: https://pan.baidu.com/s/1yLAtXs9XwtyEzYSlDCSlqw?…...
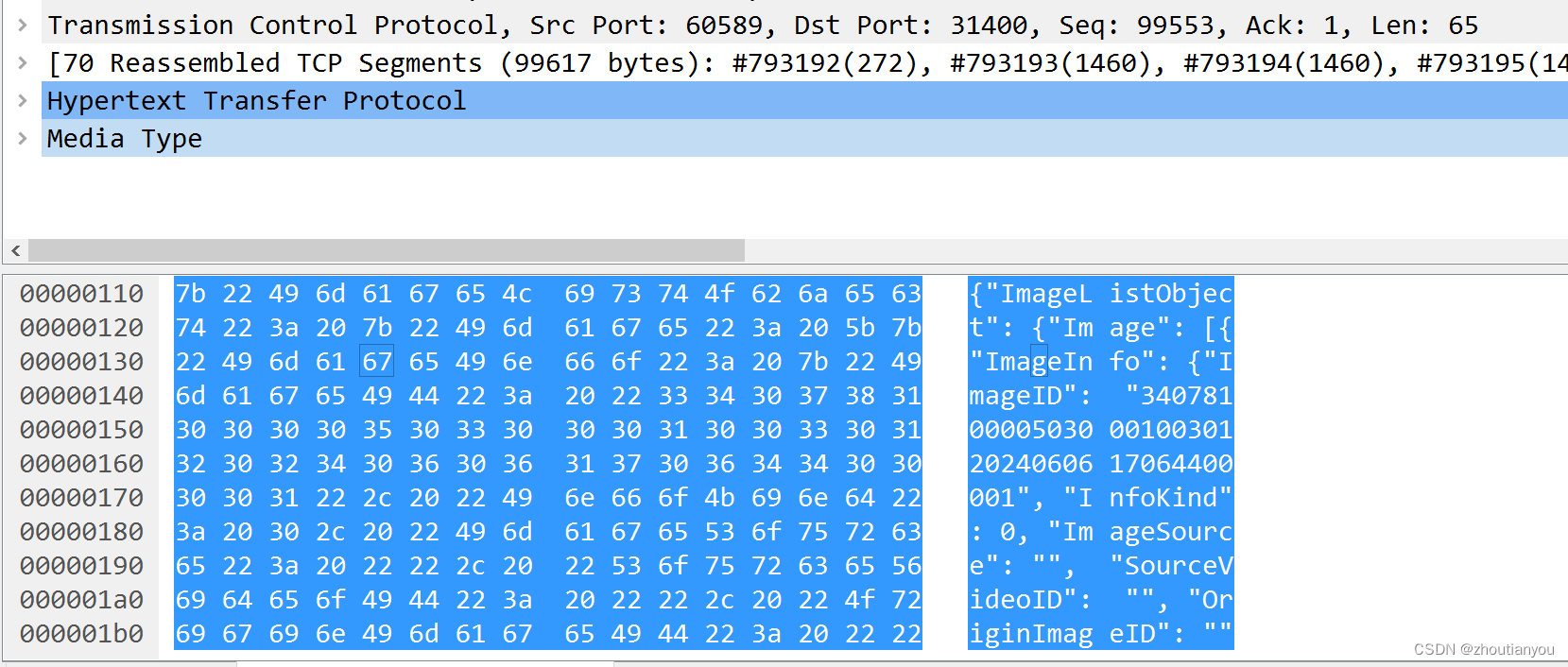
GAT1399协议分析(9)--图像上传
一、官方定义 二、wirechark实例 有前面查询的基础,这个接口相对简单很多。 请求: 文本化: POST /VIID/Images HTTP/1.1 Host: 10.0.201.56:31400 User-Agent: python-requests/2.32.3 Accept-Encoding: gzip, deflate Accept: */* Connection: keep-alive content-type:…...

Spring ApplicationContext的getBean方法
Spring ApplicationContext的getBean方法 在Spring框架的ApplicationContext中,getBean(Class<T> requiredType)方法可以接受一个类类型参数,这个参数可以是接口类也可以是实现类。 使用接口类: 如果requiredType是一个接口,…...
—— 自动摘要)
自然语言处理(NLP)—— 自动摘要
自动摘要是一种将长文本信息浓缩为短文本的技术,旨在保留原文的主要信息和意义。 1 自动摘要的第一种方法 它的第一种方法是基于理解的,受认知科学和人工智能的启发。 在这个方法中,我们首先建立文本的语义表示,这可以理解为文本…...

VR大空间项目屡获行业大奖,AI数字人公司赋能文旅智慧升级
在经历了早期的概念普及和单点试验后,AI数字人、VR、MR等技术正在文旅行业完成从“尝鲜”到“刚需”的蜕变。不再仅仅是博物馆或景区里的一块互动屏幕,而是一套能够重塑服务流程、活化文化IP、创造全新消费场景的完整解决方案。从边疆秘境到城市地标&…...

3分钟搞定浏览器二维码:Chrome QRCode插件的终极使用秘籍
3分钟搞定浏览器二维码:Chrome QRCode插件的终极使用秘籍 【免费下载链接】chrome-qrcode :zap: A Chrome plugin to Genrate QRCode of URL / Text, or Decode the QRcode in website. 一个Chrome浏览器插件,用于生成当前URL或者选中内容的二维码&#…...

AI安全控制框架:应对能力超越控制的风险与韧性防御策略
1. 项目概述:当能力超越控制“Project Glasswing”这个名字本身就充满了隐喻。玻璃翼,轻盈、透明、脆弱,却又能在阳光下折射出复杂的光谱。这像极了我们今天要讨论的核心议题:人工智能的能力边界正以前所未有的速度扩张࿰…...

Windows平台ADB驱动终极安装指南:3分钟搞定Android开发环境
Windows平台ADB驱动终极安装指南:3分钟搞定Android开发环境 【免费下载链接】Latest-adb-fastboot-installer-for-windows A Simple Android Driver installer tool for windows (Always installs the latest version) 项目地址: https://gitcode.com/gh_mirrors/…...

终极Moonlight TV游戏串流指南:3分钟实现电视大屏游戏体验
终极Moonlight TV游戏串流指南:3分钟实现电视大屏游戏体验 【免费下载链接】moonlight-tv Lightweight NVIDIA GameStream Client, for LG webOS TV and embedded devices like Raspberry Pi 项目地址: https://gitcode.com/gh_mirrors/mo/moonlight-tv 你是…...

5步掌握OpenCore Configurator:黑苹果配置终极可视化指南
5步掌握OpenCore Configurator:黑苹果配置终极可视化指南 【免费下载链接】OpenCore-Configurator A configurator for the OpenCore Bootloader 项目地址: https://gitcode.com/gh_mirrors/op/OpenCore-Configurator 如果你正在为黑苹果系统的复杂配置而烦恼…...

如何绕过Cursor Pro试用限制:技术原理与实战指南
如何绕过Cursor Pro试用限制:技术原理与实战指南 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your trial re…...

AI教材编写利器!低查重AI写教材工具,快速生成30万字专业教材!
在开始编写教材之前,选择合适的工具真的是一个“非常纠结”的过程!如果用常见的办公软件来写,功能太简单,框架设计和格式处理都得自己手动来搞;而要是尝试那些专业的编写工具,又会觉得操作太复杂࿰…...

Cursor编辑器配置重置工具:自动化清理与恢复出厂设置
1. 项目概述与核心价值 最近在折腾代码编辑器,特别是像 Cursor 这类深度整合了 AI 能力的 IDE,发现一个挺有意思但容易被忽略的问题: 编辑器配置的“熵增” 。简单来说,就是你用久了之后,各种插件、主题、快捷键、代…...

从SolidWorks到Simulink:手把手教你用Simscape Multibody Link搭建你的第一个虚拟样机
从SolidWorks到Simulink:手把手教你用Simscape Multibody Link搭建你的第一个虚拟样机 虚拟样机技术正在彻底改变传统机电系统的开发流程。想象一下,你刚刚在SolidWorks中完成了一个精巧的自动门闭锁装置的设计,现在不需要花费数周时间加工金…...