Selenium时间等待_显示等待
特点:
针对具体元素进行时间等待
可以自定义等待时长和间隔时间
按照设定的时间,不断定位元素,定位到了直接执行下一步操作
如在设定时间内没定位到元素,则报错(TimeOutException)
显示等待概念:
设置一个等待时间和一个条件,在规定时间内,每隔一段时间查看下条件是否成立,如果成立那么程序就继续执行,否则就提示一个超时异常(TimeoutException)。
在使用显示等待时,需要结合Selenium的WebDriverWait和expected_conditions模块来实现。
- WebDriverWait负责等待的设置,
- expected_conditions模块提供了一系列常用的条件,可以根据具体的需求选择合适的条件
需要导入两个包
# 导入selenium模块中的WebDriverWait类,用于等待特定条件出现后再执行下一步操作
from selenium.webdriver.support.ui import WebDriverWait# 导入selenium模块中的expected_conditions模块的EC别名,用于定义预期条件
from selenium.webdriver.support import expected_conditions as EC使用步骤:
1)初始化WebDriverWait对象,指定等待时间和浏览器驱动。
eg:wait = WebDriverWait(driver, timeout=3)
2)调用until方法,传入要等待的条件。
eg:wait.until(condition)
3)condition条件通过:expected_conditions as EC 调用指定条件
eg:wait.until(EC.condition)
3)在until方法中,会不断地轮询条件是否满足,直到条件满足或超时时间到达。还有
until_not()正好与until相反4)条件满足后,继续执行后续代码。
5)如果超过超时时间后仍未满足条件,则抛出TimeoutException异常。
WebDriverWait参数说明:
WebDriverWait(driver, timeout=3).until(some_condition)
driver:浏览器驱动对象
timeout:最长等待时间轮询时间:默认是以每500ms轮询一次,也可以指定
.until(some_condition):调用until()方法并传递一个特定的条件some_condition。该方法将等待直到条件满足或超时时间达到
这里是一个使用until()方法的例子,它等待页面标题包含特定文本:
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC# 创建WebDriver实例,并指定使用Chrome浏览器驱动
driver = webdriver.Chrome()# 导航到菜鸟教程网页
driver.get("https://www.runoob.com/")# 显式等待直到页面标题包含“菜鸟教程”
wait = WebDriverWait(driver, 10)
title_contains_runoob = EC.title_contains("菜鸟教程")
title = wait.until(title_contains_runoob)# 输出页面标题
print(title)# 关闭浏览器
driver.quit()这里是一个使用until_not()方法的例子,它等待文本框中的值被清除:
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC# 创建WebDriver实例,并指定使用Chrome浏览器驱动
driver = webdriver.Chrome()# 导航到百度网页
driver.get("https://www.baidu.com")# 获取文本框元素并输入文本
input_elem = driver.find_element("css selector", "input[name='wd']")
input_elem.send_keys("python")# 显式等待直到文本框中的值被清除
wait = WebDriverWait(driver, 10)
value_cleared = EC.text_to_be_present_in_element_value(("css selector", "input[name='wd']"), "")
input_elem.clear()
wait.until_not(value_cleared)# 关闭浏览器
driver.quit()expected_conditions as EC 条件方法
先导包
# 导入expected_conditions类,并取别名为 EC
from selenium.webdriver.support import expected_conditions as EC条件1:title_is
检查页面标题的期望。title是预期的标题,必须完全匹配如果标题匹配,则返回True,否则返回false。
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium import webdriver# 实例化驱动对象
driver = webdriver.Chrome()
driver.get("http://shop.aircheng.com/simple/login")# 显示等待 页面标题
# 等待10s
wait = WebDriverWait(driver, 5)
# 获取页面标题
title = driver.title # 用户登录 - iWebShop商城演示
# title:"预期标题" message:提示消息
wait.until(EC.title_is(title="用户登录 - iWebShop商城演示3"), message='标题不匹配')print(title)
# 不匹配报错
D:\Scripts\python.exe D:\桌面\Hualenium_demo_6_1\demo9\显示等待2.py Traceback (most recent call last):File "D:\桌面\HuaCe_Python\code_py\selenium_demo_6_1\demo9\显示等待2.py", line 15, in <module>wait.until(EC.title_is(title="用户登录 - iWebShop商城演示3"), message='标题不匹配')File "D:\桌面\HuaCe_Python\code_py\selenium_demo_6_1\venv\lib\site-packages\selenium\webdriver\support\wait.py", line 105, in untilraise TimeoutException(message, screen, stacktrace)
selenium.common.exceptions.TimeoutException: Message: 标题不匹配
条件2:title_contains
检查标题是否包含区分大小写的子字符串。title是所需的标题片段当标题匹配时返回True,否则返回False
用法与title_is一样,唯一区别就是:
- title_is是完全相等,
- title_contains是包含
条件3:presence_of_element_located
检查元素是否存在于页面。这并不一定意味着元素是可见的。定位器-用于查找元素找到WebElement后返回该WebElemen
#导包
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium import webdriverclass Brouser:fox = webdriver.Firefox()wait = WebDriverWait(fox, 5)def get_url(self,url):self.fox.get(url)def presence_located(self,value,*ele):el = self.wait.until(EC.presence_of_element_located(ele),message='没有发现期望的元素')el.send_keys(value)if __name__ == '__main__':b = Brouser()b.get_url('http://shop.aircheng.com/simple/login')b.presence_located('qingan',By.NAME,'login_info')
条件4:visibility_of_element_located
检查元素是否存在于页面和可见。可见性意味着不仅显示元素但其高度和宽度也大于0。定位器-用于查找元素找到并可见WebElement后返回该WebElement
用法与presence_of_element_located一样,唯一区别就是:
- visibility_of_element_located:检查元素是否出现,元素为:可见或不可见
- presence_of_element_located:检查元素是否出现,元素必须为:可见
条件5:url_to_be
检查当前url的期望值。url是预期的url,必须完全匹配。如果url匹配,则返回True,否则返回false
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium import webdriverclass Brouser:fox = webdriver.Firefox()wait = WebDriverWait(fox, 5)def get_url(self,url):self.fox.get(url)def url_be(self,url):self.wait.until(EC.url_to_be(url))if __name__ == '__main__':b = Brouser()b.get_url('http://shop.aircheng.com/simple/login')b.url_be('http://shop.aircheng.com/simple/login')
判断url还有另外的几种方式,都大同小异
- url_matches: 检查当前url的期望值。pattern是预期的模式,必须是完全匹配的如果url匹配,则返回True,否则返回false。
- url_contains: 检查当前url是否包含区分大小写的子字符串。url是所需url的片段,url匹配时返回True,否则返回False
- url_changes : 检查当前url的期望值。url是预期的url,不能完全匹配如果url不同,则返回True,否则返回false。
条件6:visibility_of
检查已知存在于页面的DOM是可见的。可见性意味着元素不仅仅是显示,但高度和宽度也大于0。元素是WebElement在WebElement可见时返回(相同的)WebElement
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium import webdriverclass Brouser:fox = webdriver.Firefox()wait = WebDriverWait(fox, 5)def get_url(self,url):self.fox.get(url)def visibility_(self,*ele):el = self.wait.until(EC.visibility_of(self.fox.find_element(*ele)))el.click()if __name__ == '__main__':b = Brouser()b.get_url('http://shop.aircheng.com/simple/login')b.visibility_(By.NAME, 'remember')
这里值得注意的是
visibility_of_element_located跟visibility_of很类似。与上面的写法不同EC.visibility_of里面写的是定位,而非单纯的元素。这也是一个区别点。在后续的使用中注意一下。
代码示例1
"""需求:等待页面出现标题"""# 创建WebDriver实例
driver = webdriver.Chrome()# 导航到网页
driver.get("https://www.csdn.net")# 等待页面标题包含"CSDN"
wait = WebDriverWait(driver, 5)
title_contains_csdn = EC.title_contains("CSDN")
wait.until(title_contains_csdn)# 输出页面标题
print(driver.title)代码示例2
# 导包
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC# 默认是以每500ms轮询一次until中的条件,传入的超时时间是10s
WebDriverWait(driver,10).until(EC.presence_of_element_located((By.ID,'kw'))) # 设置每1s轮询一次until中的条件,传入的超时时间是10s
WebDriverWait(driver,10,1).until(EC.presence_of_element_located((By.ID,'kw'))) 自定义封装-显示等待
class BackLogin:@classmethoddef wait(cls, driver, func):return WebDriverWait(driver, 5).until(func)# need_wait:形参代表默认值False不需要触发显示等待def find_element(self, by, value, driver, need_wait=False):def f(driver):# 判断当前元素是否有文本属性if driver.find_element(by, value).text:msg = driver.find_element(by, value).textif need_wait: # 是否触发隐式等待,返回实际提示信息结果return msgelse:return Trueelse:return True# 类中可以通过self对象调用类方法self.wait(driver, f)return driver.find_element(by, value)调用
# 获取实际结果
msg = BackLogin().find_element(*BackLogin.res_txt, driver,need_wait=True).text
print(msg)
assert msg == "验证码不能为空"参考博客:Selenium 等待方式详解_selenium等待元素可见-CSDN博客
selenium--显示等待(中)--详解篇_presenceofelementlocated-CSDN博客
相关文章:

Selenium时间等待_显示等待
特点: 针对具体元素进行时间等待 可以自定义等待时长和间隔时间 按照设定的时间,不断定位元素,定位到了直接执行下一步操作 如在设定时间内没定位到元素,则报错(TimeOutException) 显示等待概念&#x…...
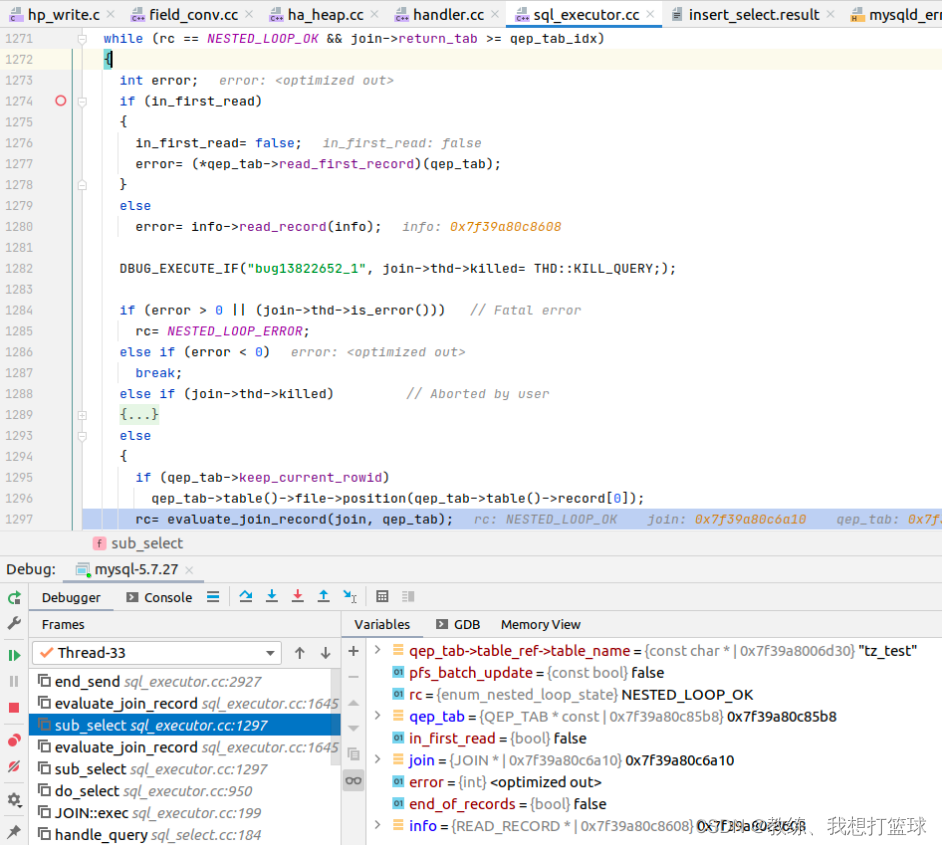
41 mysql subquery 的实现
前言 sub query 是一个我们经常会使用到的一个 用法 我们这里 看一看各个场景下面的 sub query 的相关处理 查看 本文, 需要 先看一下 join 的相关处理 测试数据表如下, 两张测试表, tz_test, tz_test03, 表结构 一致 CREATE TABLE tz_test (id int(11) unsigned NOT NUL…...
)
钉钉二次开发-企业内部系统集成官方OA审批流程(三)
书接上回,本文主要分享 企业内部系统集成钉钉官方OA审批流程的步骤 的第二部分。 前端代码集成钉钉免登JSAPI: 前端通过corpid 获得钉钉临时访问码code,再通过临时访问码code调用此接口返回当前用户的姓名、userid、 钉钉用户id、 系统工号、 钉钉部门…...

代码随想录算法训练营第五十四 | ● 392.判断子序列 ● 115.不同的子序列
392.判断子序列 https://programmercarl.com/0392.%E5%88%A4%E6%96%AD%E5%AD%90%E5%BA%8F%E5%88%97.html class Solution { public:bool isSubsequence(string s, string t) {if(s.size()0 )return true;if(t.size()0)return false;vector<vector<int>> dp(s.size(…...
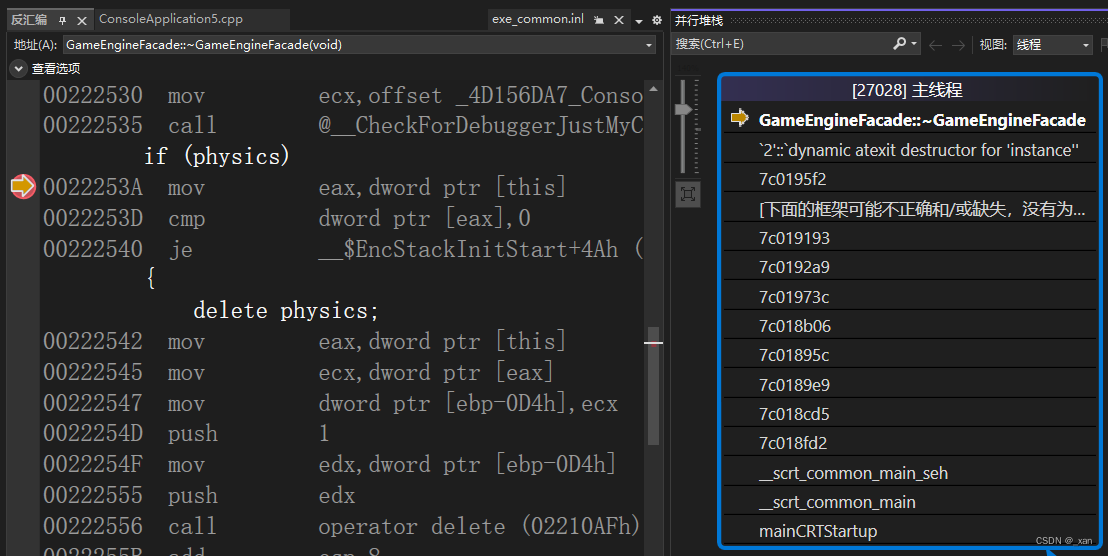
C++设计模式-外观模式,游戏引擎管理多个子系统,反汇编
运行在VS2022,x86,Debug下。 30. 外观模式 为子系统定义一组统一的接口,这个高级接口会让子系统更容易被使用。应用:如在游戏开发中,游戏引擎包含多个子系统,如物理、渲染、粒子、UI、音频等。可以使用外观…...

嵌入式软件测试相关分析
嵌入式软件测试相关分析 1. 引言 在软件发展之初,上个世纪五六十年代,软件被视为数学领域,编程是为了进行数学计算,由数学公式推导,来写函数。因此,在那个时候所编写的程序是被视为数学问题,数…...

vue+jave实现文件报表增加文件下载功能
需求背景:系统有文件交互功能。但没有做页面展示。为了测试方便,写了报表展示并可下载文件做检查。(所以下载是依赖表数据的) 使用语言和框架: 前端:vue-cli 后端:springBoot 前端实现 1、在报表vue文件,显示下载按钮并实现下载接口请求和处理。 //报…...

网站安全性评估方法
评估一个网站的安全性是一个多方面的过程,涉及到对网站的技术架构、代码质量、数据处理、用户交互等多个维度的考察。以下是一些常用的评估方法: 1.了解常见的安全风险:包括恶意软件、钓鱼攻击、跨站脚本攻击等,这些都是网站可能…...

【小程序】WXML模板语法
目录 数据绑定 数据绑定的基本原则 在data中定义页面的数据 Mustache语法的格式 Mustache语法的应用场景 事件绑定 什么是事件 小程序中常用的事件 事件对象的属性列表 target和currentTarget的区别 bindtap的语法格式 在事件处理函数中为data中的数据赋值 事件…...
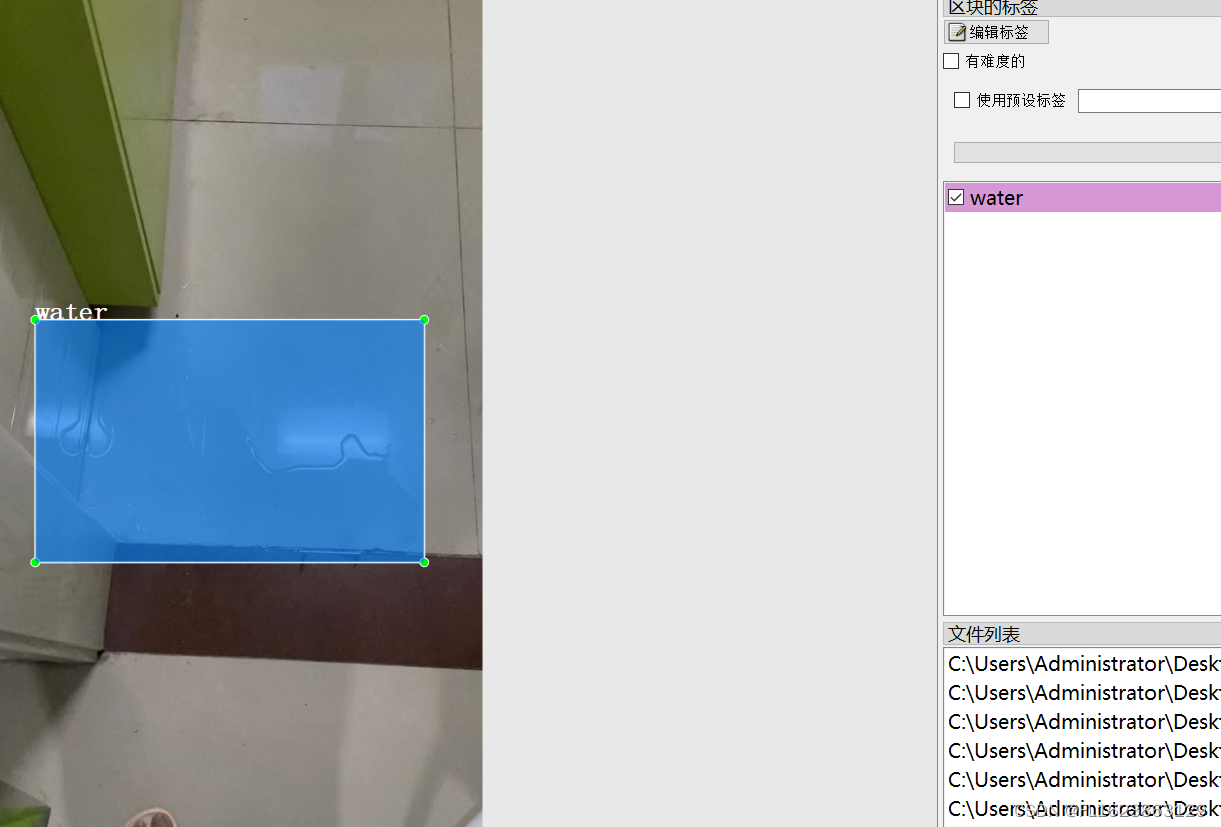
[数据集][目标检测]厨房积水检测数据集VOC+YOLO格式88张2类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):88 标注数量(xml文件个数):88 标注数量(txt文件个数):88 标注类别数…...

QSlider样式示例
参考代码: /********************QSlider横向滑动条样式**********************/ QSlider {background-color: rgba(170, 255, 255, 100); /* 设置滑动条主体*/ }QSlider::groove:horizontal {border: 1px solid #999999;height: 8px; /* 默认…...

【Linux】进程3——PID/PPID,父进程,子进程
在讲父子进程之前,我们接着上面那篇继续讲 1.查看进程 mycode.c makefile 我们在zs_108直接编译mycode.c,直接运行,然后我们转换另一个账号来查看这个进程 我们可以通过ps指令来查看进程 我们就会好奇了,第二行是什么ÿ…...

开发常用的组件库
框架: Vue.js - 渐进式 JavaScript 框架 | Vue.js (vuejs.org) React 官方中文文档 (docschina.org) Svelte 中文文档 | Svelte 中文网 SolidJS 反应式 JavaScript 库 页面样式: 网页端: 指南 |元素 (eleme.cn) Mint UI (mint-ui.github.io…...
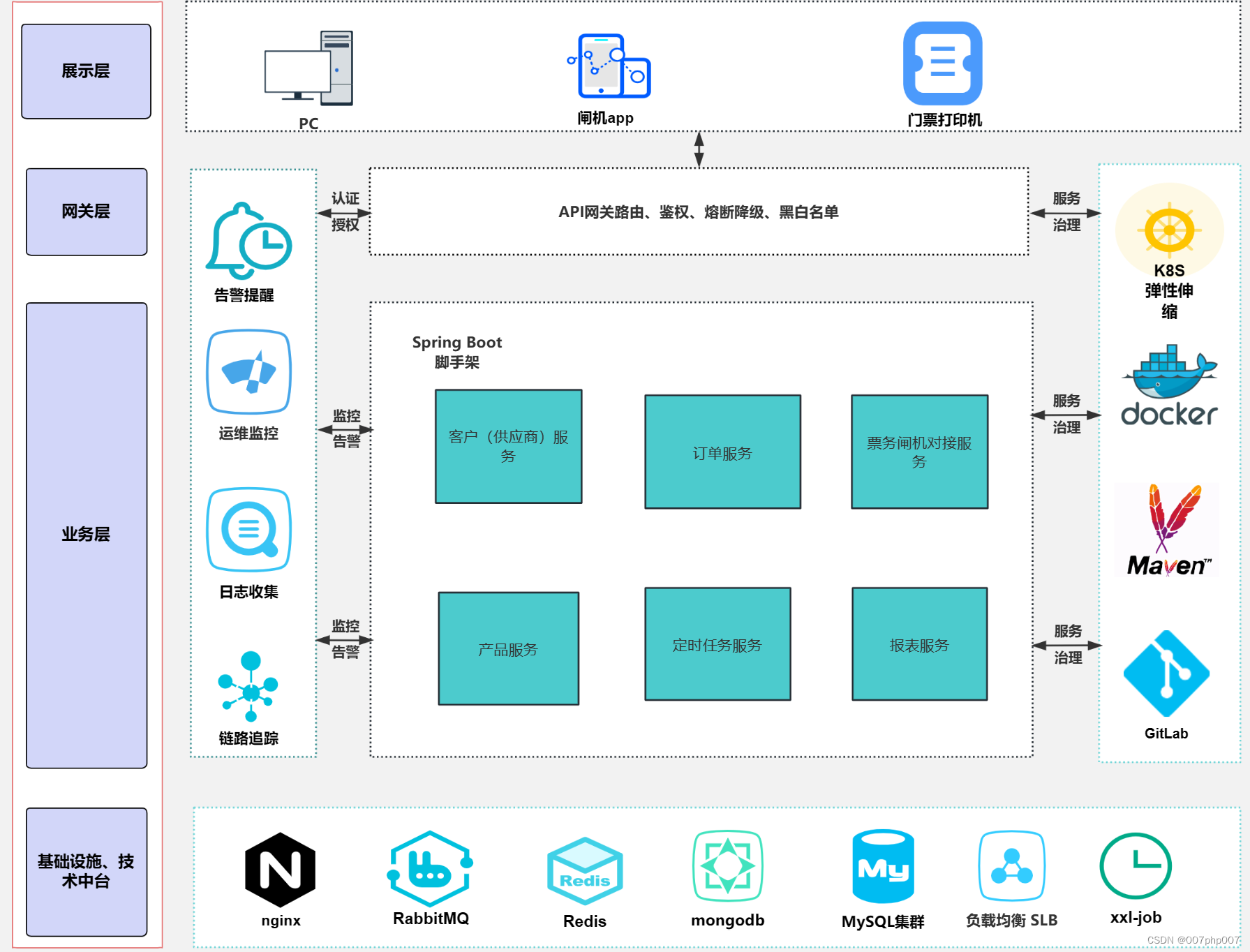
深度解析地铁票务系统的技术架构与创新应用
在城市交通体系中,地铁作为一种快速、便捷的公共交通方式,已经成为现代都市生活的重要组成部分。而地铁票务系统的技术架构,则是支撑地铁运营的核心之一。本文将深度解析地铁票务系统的技术架构与创新应用,从系统设计、数据管理、…...

Python集合的基本概念和使用方法
目录 集合(Set) 基本概念 基本特性 基本操作 集合运算 成员测试 高级操作 集合推导式 总结 集合(Set) Python集合(Set)是Python语言中一个非常实用且强大的数据结构,它用于存储多个不…...
谷歌浏览器124版本Webdriver驱动下载
查看谷歌浏览器版本 在浏览器的地址栏输入: chrome://version/回车后即可查看到对应版本(不要点击帮助-关于Google chrome,因为点击后会自动更新谷歌版本) 114之前版本:下载链接 123以后版本:下载链接࿰…...

十大排序
本文将以「 通俗易懂」的方式来描述排序的基本实现。 🧑💻阅读本文前,需要一点点编程基础和一点点数据结构知识 本文的所有代码以cpp实现 文章目录 排序的定义 插入排序 ⭐ 🧐算法描述 💖具体实现 …...

微信小程序学习笔记(1)
文章目录 一、文件作用app.json:project.config.json:sitemap.json页面中.json 二、项目首页三、语法**WXML**和**HTML**WXSS 和CSS的区别小程序中.js文件的分类 一、文件作用 app.json: 当前小程序的全局配置,包括所有页面路径、窗口外观、…...
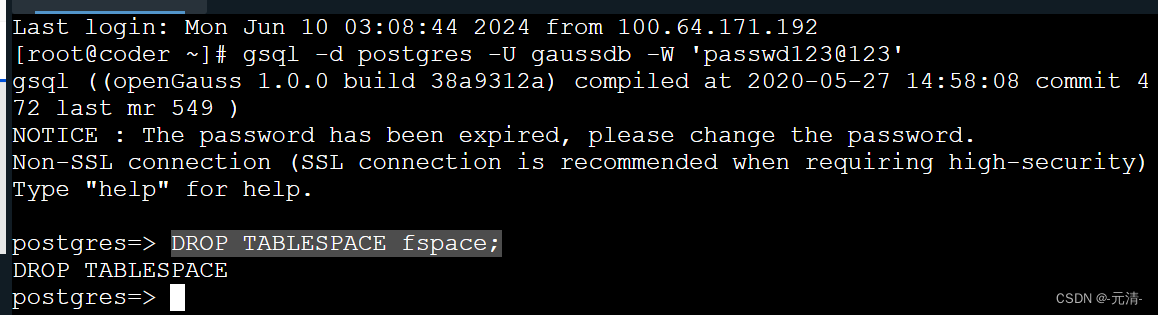
OpenGauss数据库-6.表空间管理
第1关:创建表空间 gsql -d postgres -U gaussdb -W passwd123123 CREATE TABLESPACE fastspace OWNER omm relative location tablespace/tablespace_1; 第2关:修改表空间 gsql -d postgres -U gaussdb -W passwd123123 ALTER TABLESPACE fastspace R…...
)
相约乌镇 续写网络空间命运与共的新篇章(二)
从乌镇峰会升级为世界互联网大会,既是展示互联网发展成果的技术盛会,也是尖端科技综合运用的宏大场景。从枕水江南散发出的“互联网之光”,到前沿技术的创新突破和场景应用,澎湃的是数字经济浪潮,激荡的是科技创新能量…...

DeepLake:AI原生数据湖统一管理多模态数据与向量嵌入
1. 项目概述:当数据湖遇上AI向量化如果你正在构建一个AI应用,无论是RAG检索增强生成系统、多模态模型训练,还是复杂的语义搜索,数据管理环节的复杂性往往会让你头疼不已。传统的文件系统、数据库,甚至是对象存储&#…...

MCP-Commander:让AI助手操作本地文件与命令行的智能接口
1. 项目概述:一个连接思维与执行的智能接口最近在折腾AI工作流的时候,发现了一个挺有意思的项目,叫nmindz/mcp-commander。乍一看这个名字,可能有点摸不着头脑,但如果你正在尝试让大型语言模型(LLM…...

STM32F407最小系统板DIY全记录:从原理图绘制到PCB打样,手把手带你复刻一块自己的核心板
STM32F407最小系统板DIY全记录:从原理图绘制到PCB打样,手把手带你复刻一块自己的核心板 1. 项目规划与芯片选型 在开始动手之前,我们需要明确几个关键问题:为什么要选择STM32F407?这个芯片适合哪些应用场景?…...

6000万美元拿下世界杯:FIFA终于清醒了?
5月15号下午,央视和国际足联官宣了新周期的版权合作。朋友圈里炸开了锅,大家都在讨论那个数字:6000万美元。这是2026年美加墨世界杯的中国区转播权价格。说实话,看到这个价格我有点意外。上一届卡塔尔世界杯,传闻中的版…...

子高斯随机变量与深度学习异常检测原理
1. 子高斯随机变量基础解析子高斯随机变量是概率论中一类具有特殊尾部性质的分布。简单来说,一个随机变量X如果满足存在常数σ>0,使得对于所有λ∈R都有E[exp(λX)] ≤ exp(λσ/2),那么我们就称X是σ-子高斯的。这类分布的关键特征是它们…...
)
【负荷预测】基于LSTM-KAN的负荷预测研究(Python代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

Smart-10 多模光时域反射仪:铁路高速光纤故障首选
铁路、高速公路通信光纤线路长、环境复杂,精准检测与故障定位是运维关键。Smart-10 多模光时域反射仪集成 OTDR、光功率计、红光源等功能,为交通行业光纤运维提供高效、可靠的解决方案。Smart-10 多模光时域反射仪是一款一体化光纤综合测试仪,…...

【深度解析】Qwen 3.6 vs Gemma 4:本地大模型时代,如何选对“日常开发模型”
摘要: 开源权重模型正在快速逼近闭源模型能力边界。本文结合 Qwen 3.6 与 Gemma 4 的实际案例,从架构、上下文、显存、基准测试到落地场景,拆解本地大模型选型逻辑,并给出可直接运行的 Python 调用示例。 背景介绍 近两年…...

从「PPT丑到被挂」到「评委全场抬头」!只花25元的答辩PPT救命教程
论文写到头秃,结果答辩PPT还要从零学起!😭 网上模板要么花哨得像婚礼请柬,要么把论文段落直接往上堆,交去预审,导师批注四个字:“毫无逻辑。”别慌!这篇亲妈级教程,把我答…...

5个核心功能:Winhance中文版如何重塑你的Windows体验
5个核心功能:Winhance中文版如何重塑你的Windows体验 【免费下载链接】Winhance-zh_CN A Chinese version of Winhance. C# application designed to optimize and customize your Windows experience. 项目地址: https://gitcode.com/gh_mirrors/wi/Winhance-zh_…...