【爬虫实战项目一】Python爬取豆瓣电影榜单数据
目录
一、环境准备
二、编写代码
2.1 分页分析
2.2 编码
一、环境准备
安装requests和lxml
pip install requests
pip install lxml二、编写代码
2.1 分页分析
编写代码前我们先看看榜单的url

我们假如要爬取五页的数据,那么五个url分别是:
https://movie.douban.com/top250?start=0&filter=
https://movie.douban.com/top250?start=25&filter=
https://movie.douban.com/top250?start=50&filter=
https://movie.douban.com/top250?start=75&filter=
https://movie.douban.com/top250?start=100&filter=
不难看出,规律在于start参数,每页有25条数据。
那么按照分页计算公式 (当前页数 - 1) * 每页数据量 得出 代码逻辑。
2.2 编码
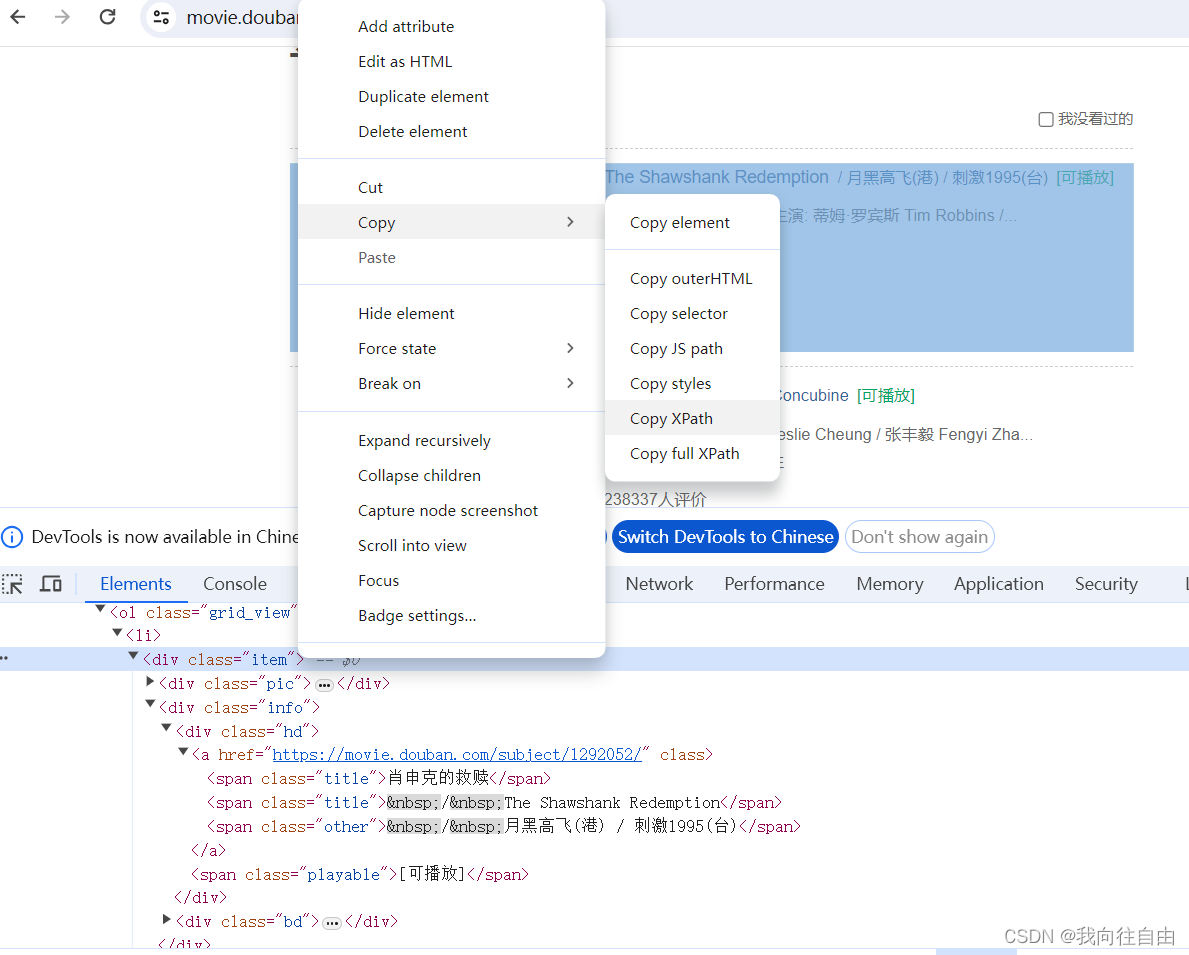
我们复制下xpath。
import random
from lxml import etree
import requests
import time# 请求头信息
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36'
}
# 共取5页数据
for i in range(1, 6):start = (i - 1) * 25url = f'https://movie.douban.com/top250?start={start}&filter='response = requests.get(url, headers=headers)tree = etree.HTML(response.text)div = tree.xpath('//*[@id="content"]/div/div[1]/ol/li/div')for d in div:# 获取当前电影标题title = d.xpath('.//span[@class="title"][1]/text()')[0]print(title)time.sleep(random.randint(1, 3))
成功爬取豆瓣电影TOP250榜单。
相关文章:
【爬虫实战项目一】Python爬取豆瓣电影榜单数据
目录 一、环境准备 二、编写代码 2.1 分页分析 2.2 编码 一、环境准备 安装requests和lxml pip install requests pip install lxml 二、编写代码 2.1 分页分析 编写代码前我们先看看榜单的url 我们假如要爬取五页的数据,那么五个url分别是: htt…...
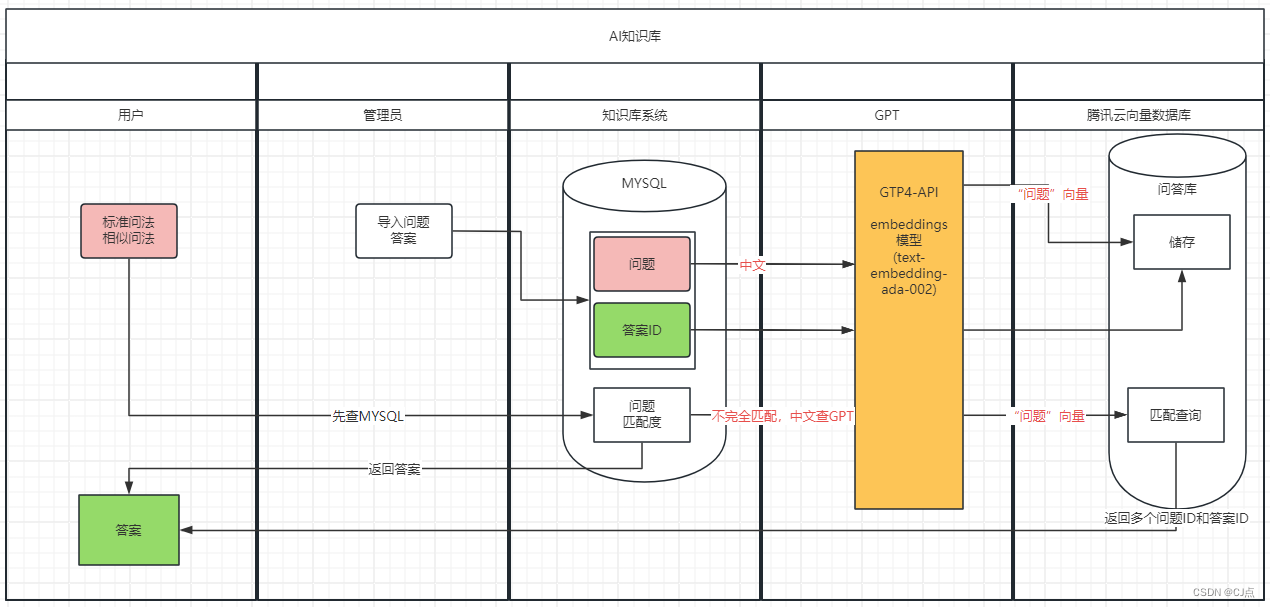
AI-知识库搭建(一)腾讯云向量数据库使用
一、AI知识库 将已知的问答知识,问题和答案转变成向量存储在向量数据库,在查找答案时,输入问题,将问题向量化,匹配向量库的问题,将向量相似度最高的问题筛选出来,将答案提交。 二、腾讯云向量数…...

AI数据分析:根据Excel表格数据绘制柱形图
工作任务:将Excel文件中2013年至2019年间线上图书的销售额,以条形图的形式呈现,每个条形的高度代表相应年份的销售额,同时在每个条形上方标注具体的销售额数值 在deepseek中输入提示词: 你是一个Python编程专家&#…...
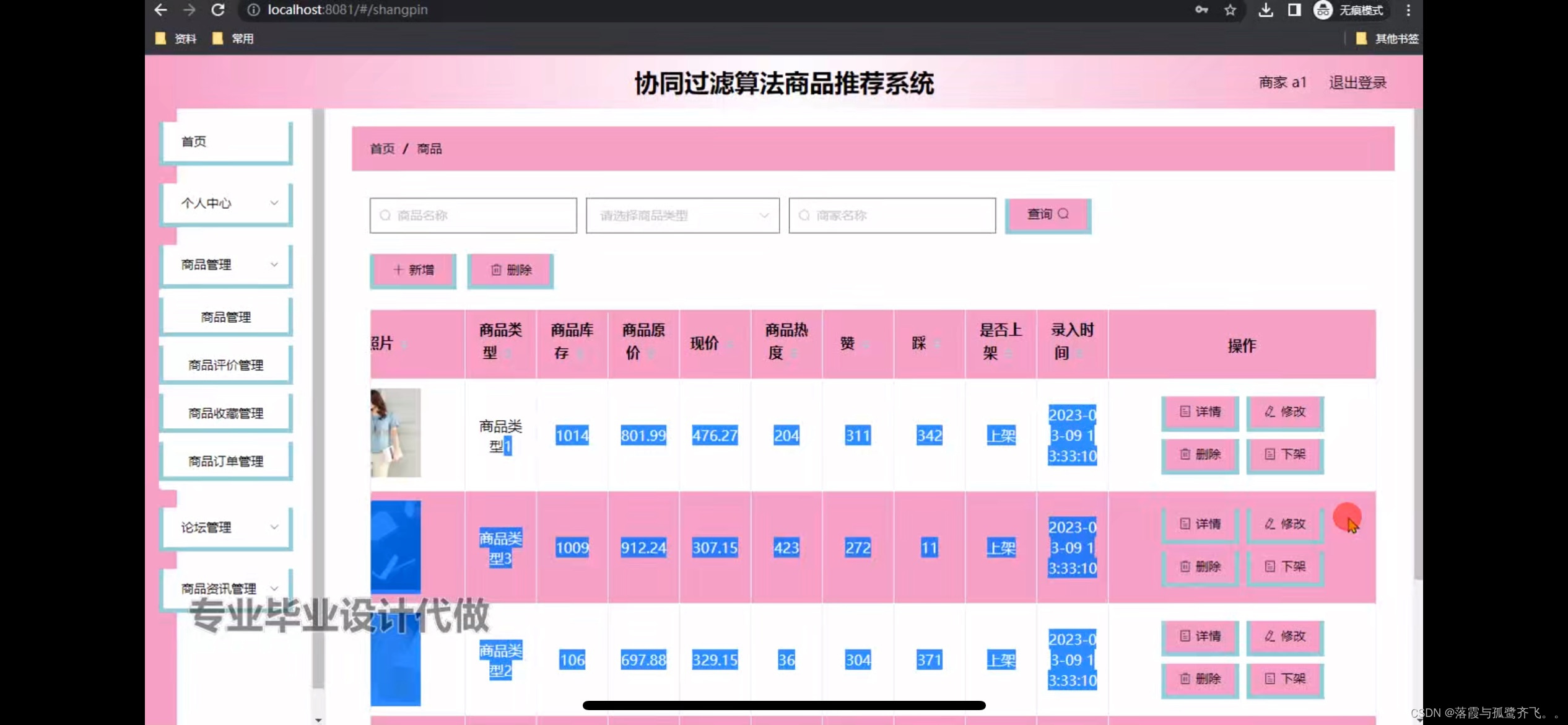
基于协调过滤算法商品推荐系统的设计
管理员账户功能包括:系统首页,个人中心,商品管理,论坛管理,商品资讯管理 前台账户功能包括:系统首页,个人中心,论坛,商品资讯,商家,商品 开发系统…...

CS1061 “HtmlHelper”未包含“Partial”的定义,并且找不到可接受第一个“HtmlHelper”类型参数的可访问扩展方法“Partial”
严重性 代码 说明 项目 文件 行 禁止显示状态 错误 CS1061 “HtmlHelper”未包含“Partial”的定义,并且找不到可接受第一个“HtmlHelper”类型参数的可访问扩展方法“Partial”(是否缺少 using 指令或程序集引用?) 14_Views_Message_E…...


在知识的海洋中航行:问题的演变与智慧的追求
在信息技术迅猛发展的今天,互联网和人工智能已成为我们生活中不可或缺的一部分。它们像是一座座灯塔,照亮了知识的海洋,使得曾经难以触及的知识变得触手可及。随着这些技术的普及,越来越多的问题能够迅速得到答案。然而࿰…...
、slice()、split()三种方法的区别)
splice()、slice()、split()三种方法的区别
slice slice() 方法返回一个新的数组对象,这一对象是一个由 start 和 end 决定的原数组的浅拷贝(包括 start,不包括 end),其中 start 和 end 代表了数组元素的索引。原始数组不会被改变。 const animals [ant, bison…...
iOS 之homebrew ruby cocoapods 安装
cocoapods安装需要ruby,更新ruby需要rvm,下载rvm需要gpg,下载gpg需要homebrew,所以安装顺序是homebrew->gpg->rvm->ruby-cocoapods Rvm 官网: RVM: Ruby Version Manager - RVM Ruby Version Manager - Docum…...

【栈】2751. 机器人碰撞
本文涉及知识点 栈 LeetCode2751. 机器人碰撞 现有 n 个机器人,编号从 1 开始,每个机器人包含在路线上的位置、健康度和移动方向。 给你下标从 0 开始的两个整数数组 positions、healths 和一个字符串 directions(directions[i] 为 ‘L’ …...

贪心算法06(leetcode738,968)
参考资料: https://programmercarl.com/0738.%E5%8D%95%E8%B0%83%E9%80%92%E5%A2%9E%E7%9A%84%E6%95%B0%E5%AD%97.html 738. 单调递增的数字 题目描述: 当且仅当每个相邻位数上的数字 x 和 y 满足 x < y 时,我们称这个整数是单调递增的。…...

cve_2022_0543-redis沙盒漏洞复现 vulfocus
1. 原理 该漏洞的存在是因为Debian/Ubuntu中的Lua库是作为动态库提供的。自动填充了一个package变量,该变量又允许访问任意 Lua 功能。 2.复现 我们可以尝试payload: eval local io_l package.loadlib("/usr/lib/x86_64-linux-gnu/liblua5.1.so…...
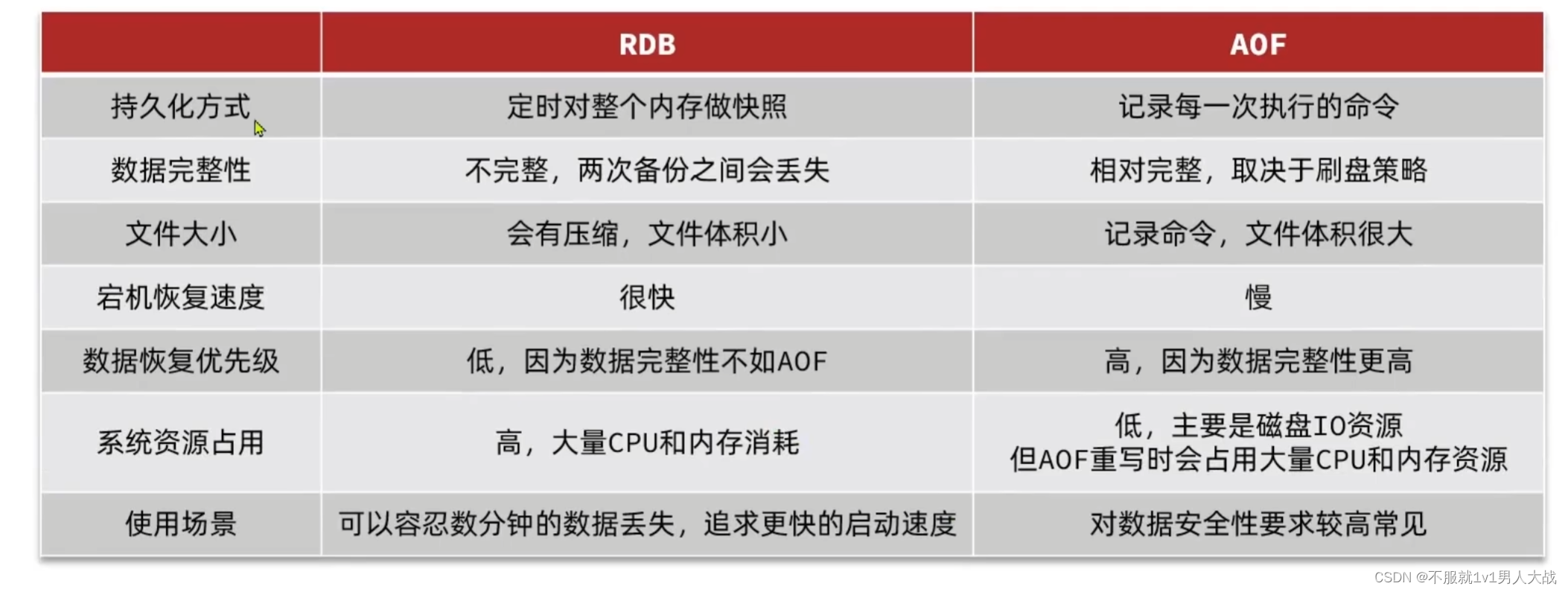
浅解Reids持久化
Reids持久化 RDB redis的存储方式: rdb文件都是二进制,很小,里面存的是数据 实现方式 redis-cli链接到redis服务端 使用save命令 注:不推荐 因为save命令是直接写到磁盘里面,速度特别慢,一般都是redis…...
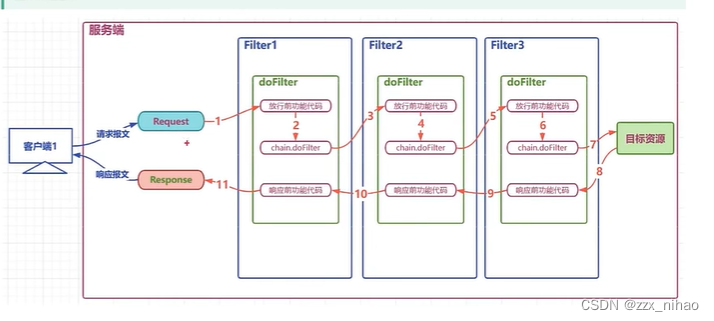
Java24:会话管理 过滤器 监听器
一 会话管理 1.cookie 是一种客户端会话技术,cookie由服务端产生,它是服务器存放在浏览器的一小份数据,浏览器 以后每次访问服务器的时候都会将这小份的数据带到服务器去。 //创建cookie对象 Cookie cookie1new Cookie("…...

web前端电影简介标签:深度解析与创意应用
web前端电影简介标签:深度解析与创意应用 在web前端开发中,电影简介标签的设计与实现是一项既具挑战性又充满创意的任务。这些标签不仅需要准确传达电影的核心信息,还要通过精美的设计和交互效果吸引用户的眼球。本文将从四个方面、五个方面…...

Java面向对象-方法的重写、super
Java面向对象-方法的重写、super 一、方法的重写二、super关键字1、super可以省略2、super不可以省略3、super修饰构造器4、继承条件下构造方法的执行过程 一、方法的重写 1、发生在子类和父类中,当子类对父类提供的方法不满意的时候,要对父类的方法进行…...

解锁ChatGPT:从GPT-2实践入手解密ChatGPT
⭐️我叫忆_恒心,一名喜欢书写博客的研究生👨🎓。 如果觉得本文能帮到您,麻烦点个赞👍呗! 近期会不断在专栏里进行更新讲解博客~~~ 有什么问题的小伙伴 欢迎留言提问欧,喜欢的小伙伴给个三连支…...
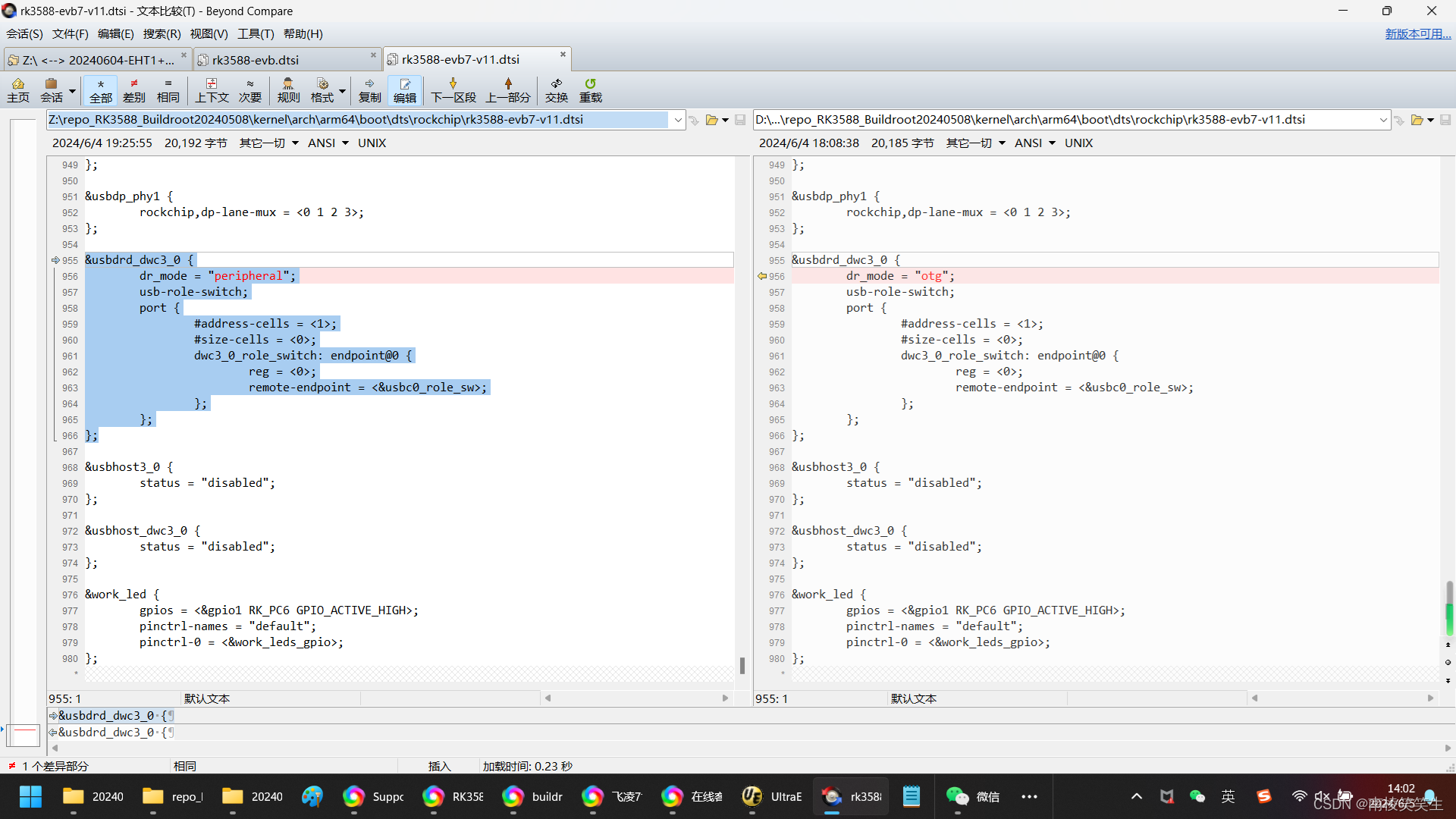
20240605解决飞凌的OK3588-C的核心板刷机原厂buildroot不能连接ADB的问题
20240605解决飞凌的OK3588-C的核心板刷机原厂buildroot不能连接ADB的问题 2024/6/5 13:53 rootrootrootroot-ThinkBook-16-G5-IRH:~/repo_RK3588_Buildroot20240508$ ./build.sh --help rootrootrootroot-ThinkBook-16-G5-IRH:~/repo_RK3588_Buildroot20240508$ ./build.sh lun…...

c++手写的bitset
支持stl bitset 类似的api #include <iostream> #include <vector> #include <climits> #include <utility> #include <stdexcept> #include <iterator>using namespace std;const int W 64;class Bitset { private:vector<unsigned …...
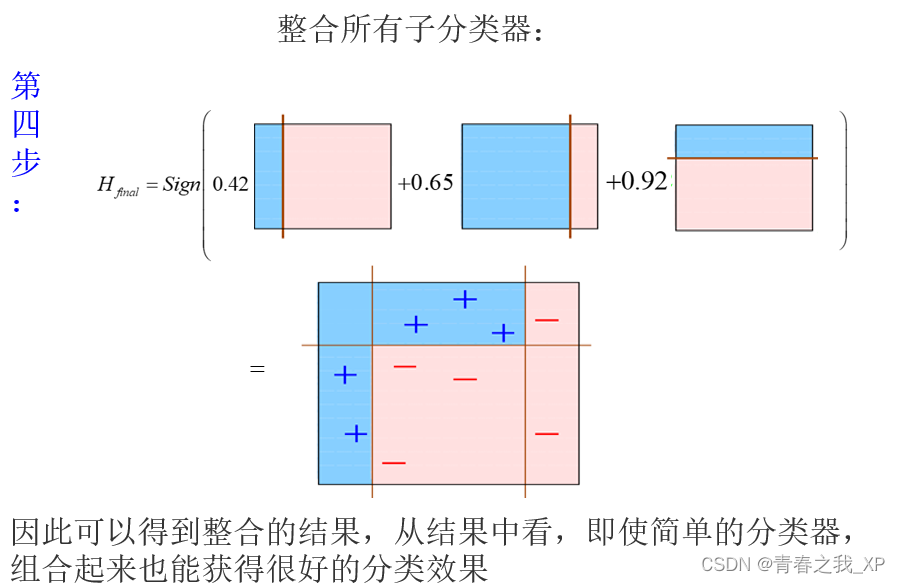
【机器学习系列】深入理解集成学习:从Bagging到Boosting
目录 一、集成方法的一般思想 二、集成方法的基本原理 三、构建集成分类器的方法 常见的有装袋(Bagging)和提升(Boosting)两种方法 方法1 :装袋(Bagging) Bagging原理如下图: …...
)
不止于安装:在 Ubuntu 20.04 上为 GAMMA 配置完整的 InSAR 科研环境(含 Python 依赖)
不止于安装:在 Ubuntu 20.04 上为 GAMMA 配置完整的 InSAR 科研环境(含 Python 依赖) 当你在Ubuntu 20.04上成功安装GAMMA后,可能会发现这仅仅是开始。真正的挑战在于构建一个完整、稳定的科研环境,让InSAR数据处理流程…...

Ardb源码深度解析:从网络层到存储引擎的完整架构设计
Ardb源码深度解析:从网络层到存储引擎的完整架构设计 【免费下载链接】ardb A redis protocol compatible nosql, it support multiple storage engines as backend like Googles LevelDB, Facebooks RocksDB, OpenLDAPs LMDB, PerconaFT, WiredTiger, ForestDB. …...

Office RibbonX Editor:打造个性化Office界面的终极工具
Office RibbonX Editor:打造个性化Office界面的终极工具 【免费下载链接】office-ribbonx-editor An overhauled fork of the original Custom UI Editor for Microsoft Office, built with WPF 项目地址: https://gitcode.com/gh_mirrors/of/office-ribbonx-edit…...

Windows上的革命性文件系统:WinBtrfs完整指南与实用教程
Windows上的革命性文件系统:WinBtrfs完整指南与实用教程 【免费下载链接】btrfs WinBtrfs - an open-source btrfs driver for Windows 项目地址: https://gitcode.com/gh_mirrors/bt/btrfs WinBtrfs是一个开源的Windows驱动程序,为Windows用户带…...

AI 写作进入长篇记忆时代,AI让小说创作更可控
AI 写小说最常被讨论的问题,是写得快不快、文笔好不好。但对于真正写长篇的作者来说,还有一个更重要的问题:AI 记不记得住。 一部网文写到几十章、几百章后,人物关系会越来越复杂,伏笔会越来越多,世界观设…...
)
GPT-Image 2 对标竞争者研发?——理性看待“对手传闻”的技术路径(2026 观察)
深度观察:OpenAI 是否在暗中加速 GPT-Image 2 对标竞争者研发?——理性看待“对手传闻”的技术路径(2026 观察)“竞争对手是否在秘密被研发?”“OpenAI 背后是不是在悄悄做某种 GPT-Image 2 的替代方案?”这…...

STM32 HAL库设计解析:从GPIO到外设的面向对象编程实践
1. 项目概述:从寄存器操作到HAL API的思维跃迁如果你是从标准外设库(SPL)或者更早的寄存器直接操作时代过来的STM32开发者,第一次接触HAL库时,可能会觉得有点“绕”。为什么一个简单的引脚翻转,不再是对GPI…...

DayZ社区离线模式完全指南:打造你的专属末日沙盒世界
DayZ社区离线模式完全指南:打造你的专属末日沙盒世界 【免费下载链接】DayZCommunityOfflineMode A community made offline mod for DayZ Standalone 项目地址: https://gitcode.com/gh_mirrors/da/DayZCommunityOfflineMode 想在DayZ中完全掌控自己的生存命…...

淘金币自动化脚本:5分钟完成淘宝全任务,每天节省20分钟宝贵时间
淘金币自动化脚本:5分钟完成淘宝全任务,每天节省20分钟宝贵时间 【免费下载链接】taojinbi 淘宝淘金币自动执行脚本,包含蚂蚁森林收取能量,芭芭农场全任务,解放你的双手 项目地址: https://gitcode.com/gh_mirrors/t…...

8255 Boot流程深度解析与Bring Up实战避坑指南
1. 8255芯片启动流程全景解析 第一次拿到8255芯片开发板时,最让我困惑的就是这个"安全岛"架构的启动流程。和传统芯片不同,8255的启动更像是一场精心编排的交响乐,SAIL(安全岛)、APPS(应用处理器…...