MMSegmentation改进:增加Kappa系数评价指数
将mmseg\evaluation\metrics\iou_metric.py文件中的内容替换成以下内容即可:
支持输出单类Kappa系数和平均Kappa系数。
使用方法:将dataset的config文件中:val_evaluator 添加'mKappa',如 val_evaluator = dict(type='mmseg.IoUMetric', iou_metrics=['mFscore', 'mIoU', 'mKappa'])。
欢迎关注大地主的CSDN与 ABCnutter (github.com),敬请期待更多精彩内容
# Copyright (c) OpenMMLab. All rights reserved.
import os.path as osp
from collections import OrderedDict
from typing import Dict, List, Optional, Sequenceimport numpy as np
import torch
from mmengine.dist import is_main_process
from mmengine.evaluator import BaseMetric
from mmengine.logging import MMLogger, print_log
from mmengine.utils import mkdir_or_exist
from PIL import Image
from prettytable import PrettyTablefrom mmseg.registry import METRICS@METRICS.register_module()
class IoUMetric(BaseMetric):"""IoU evaluation metric.Args:ignore_index (int): Index that will be ignored in evaluation.Default: 255.iou_metrics (list[str] | str): Metrics to be calculated, the optionsinclude 'mIoU', 'mDice', 'mFscore', and 'Kappa'.nan_to_num (int, optional): If specified, NaN values will be replacedby the numbers defined by the user. Default: None.beta (int): Determines the weight of recall in the combined score.Default: 1.collect_device (str): Device name used for collecting results fromdifferent ranks during distributed training. Must be 'cpu' or'gpu'. Defaults to 'cpu'.output_dir (str): The directory for output prediction. Defaults toNone.format_only (bool): Only format result for results commit withoutperform evaluation. It is useful when you want to save the resultto a specific format and submit it to the test server.Defaults to False.prefix (str, optional): The prefix that will be added in the metricnames to disambiguate homonymous metrics of different evaluators.If prefix is not provided in the argument, self.default_prefixwill be used instead. Defaults to None."""def __init__(self,ignore_index: int = 255,iou_metrics: List[str] = ['mIoU'],nan_to_num: Optional[int] = None,beta: int = 1,collect_device: str = 'cpu',output_dir: Optional[str] = None,format_only: bool = False,prefix: Optional[str] = None,**kwargs) -> None:super().__init__(collect_device=collect_device, prefix=prefix)self.ignore_index = ignore_indexself.metrics = iou_metricsself.nan_to_num = nan_to_numself.beta = betaself.output_dir = output_dirif self.output_dir and is_main_process():mkdir_or_exist(self.output_dir)self.format_only = format_onlydef process(self, data_batch: dict, data_samples: Sequence[dict]) -> None:"""Process one batch of data and data_samples.The processed results should be stored in ``self.results``, which willbe used to compute the metrics when all batches have been processed.Args:data_batch (dict): A batch of data from the dataloader.data_samples (Sequence[dict]): A batch of outputs from the model."""num_classes = len(self.dataset_meta['classes'])for data_sample in data_samples:pred_label = data_sample['pred_sem_seg']['data'].squeeze()# format_only always for test dataset without ground truthif not self.format_only:label = data_sample['gt_sem_seg']['data'].squeeze().to(pred_label)self.results.append(self.intersect_and_union(pred_label, label, num_classes,self.ignore_index))# format_resultif self.output_dir is not None:basename = osp.splitext(osp.basename(data_sample['img_path']))[0]png_filename = osp.abspath(osp.join(self.output_dir, f'{basename}.png'))output_mask = pred_label.cpu().numpy()# The index range of official ADE20k dataset is from 0 to 150.# But the index range of output is from 0 to 149.# That is because we set reduce_zero_label=True.if data_sample.get('reduce_zero_label', False):output_mask = output_mask + 1output = Image.fromarray(output_mask.astype(np.uint8))output.save(png_filename)def compute_metrics(self, results: list) -> Dict[str, float]:"""Compute the metrics from processed results.Args:results (list): The processed results of each batch.Returns:Dict[str, float]: The computed metrics. The keys are the names ofthe metrics, and the values are corresponding results. The keymainly includes aAcc, mIoU, mAcc, mDice, mFscore, mPrecision,mRecall, and Kappa."""logger: MMLogger = MMLogger.get_current_instance()if self.format_only:logger.info(f'results are saved to {osp.dirname(self.output_dir)}')return OrderedDict()# convert list of tuples to tuple of lists, e.g.# [(A_1, B_1, C_1, D_1), ..., (A_n, B_n, C_n, D_n)] to# ([A_1, ..., A_n], ..., [D_1, ..., D_n])results = tuple(zip(*results))assert len(results) == 4total_area_intersect = sum(results[0])total_area_union = sum(results[1])total_area_pred_label = sum(results[2])total_area_label = sum(results[3])ret_metrics = self.total_area_to_metrics(total_area_intersect, total_area_union, total_area_pred_label,total_area_label, self.metrics, self.nan_to_num, self.beta)class_names = self.dataset_meta['classes']# summary tableret_metrics_summary = OrderedDict({ret_metric: np.round(np.nanmean(ret_metric_value) * 100, 2)for ret_metric, ret_metric_value in ret_metrics.items()})metrics = dict()for key, val in ret_metrics_summary.items():if key == 'aAcc':metrics[key] = valelse:metrics['m' + key] = val# each class tableret_metrics.pop('aAcc', None)# ret_metrics.pop('Kappa', None)ret_metrics_class = OrderedDict({ret_metric: np.round(ret_metric_value * 100, 2)for ret_metric, ret_metric_value in ret_metrics.items()})ret_metrics_class.update({'Class': class_names})ret_metrics_class.move_to_end('Class', last=False)class_table_data = PrettyTable()for key, val in ret_metrics_class.items():class_table_data.add_column(key, val)print_log('per class results:', logger)print_log('\n' + class_table_data.get_string(), logger=logger)return metrics@staticmethoddef intersect_and_union(pred_label: torch.tensor, label: torch.tensor,num_classes: int, ignore_index: int):"""Calculate Intersection and Union.Args:pred_label (torch.tensor): Prediction segmentation mapor predict result filename. The shape is (H, W).label (torch.tensor): Ground truth segmentation mapor label filename. The shape is (H, W).num_classes (int): Number of categories.ignore_index (int): Index that will be ignored in evaluation.Returns:torch.Tensor: The intersection of prediction and ground truthhistogram on all classes.torch.Tensor: The union of prediction and ground truth histogram onall classes.torch.Tensor: The prediction histogram on all classes.torch.Tensor: The ground truth histogram on all classes."""mask = (label != ignore_index)pred_label = pred_label[mask]label = label[mask]intersect = pred_label[pred_label == label]area_intersect = torch.histc(intersect.float(), bins=(num_classes), min=0,max=num_classes - 1).cpu()area_pred_label = torch.histc(pred_label.float(), bins=(num_classes), min=0,max=num_classes - 1).cpu()area_label = torch.histc(label.float(), bins=(num_classes), min=0,max=num_classes - 1).cpu()area_union = area_pred_label + area_label - area_intersectreturn area_intersect, area_union, area_pred_label, area_label@staticmethoddef total_area_to_metrics(total_area_intersect: np.ndarray,total_area_union: np.ndarray,total_area_pred_label: np.ndarray,total_area_label: np.ndarray,metrics: List[str] = ['mIoU'],nan_to_num: Optional[int] = None,beta: int = 1):"""Calculate evaluation metricsArgs:total_area_intersect (np.ndarray): The intersection of predictionand ground truth histogram on all classes.total_area_union (np.ndarray): The union of prediction and groundtruth histogram on all classes.total_area_pred_label (np.ndarray): The prediction histogram onall classes.total_area_label (np.ndarray): The ground truth histogram onall classes.metrics (List[str] | str): Metrics to be evaluated, 'mIoU', 'mDice','mFscore', and 'Kappa'.nan_to_num (int, optional): If specified, NaN values will bereplaced by the numbers defined by the user. Default: None.beta (int): Determines the weight of recall in the combined score.Default: 1.Returns:Dict[str, np.ndarray]: per category evaluation metrics,shape (num_classes, )."""def f_score(precision, recall, beta=1):"""calculate the f-score value.Args:precision (float | torch.Tensor): The precision value.recall (float | torch.Tensor): The recall value.beta (int): Determines the weight of recall in the combinedscore. Default: 1.Returns:[torch.tensor]: The f-score value."""score = (1 + beta**2) * (precision * recall) / ((beta**2 * precision) + recall)return scoreif isinstance(metrics, str):metrics = [metrics]allowed_metrics = ['mIoU', 'mDice', 'mFscore', 'mKappa']if not set(metrics).issubset(set(allowed_metrics)):raise KeyError(f'metrics {metrics} is not supported')all_acc = total_area_intersect.sum() / total_area_label.sum()ret_metrics = OrderedDict({'aAcc': all_acc})for metric in metrics:if metric == 'mIoU':iou = total_area_intersect / total_area_unionacc = total_area_intersect / total_area_labelret_metrics['IoU'] = iouret_metrics['Acc'] = accelif metric == 'mDice':dice = 2 * total_area_intersect / (total_area_pred_label + total_area_label)acc = total_area_intersect / total_area_labelret_metrics['Dice'] = diceret_metrics['Acc'] = accelif metric == 'mFscore':precision = total_area_intersect / total_area_pred_labelrecall = total_area_intersect / total_area_labelf_value = torch.tensor([f_score(x[0], x[1], beta) for x in zip(precision, recall)])ret_metrics['Fscore'] = f_valueret_metrics['Precision'] = precisionret_metrics['Recall'] = recallelif metric == 'mKappa':total = total_area_label.sum()po = total_area_intersect / total_area_labelpe = (total_area_pred_label * total_area_label) / (total ** 2)kappa = (po - pe) / (1 - pe)ret_metrics['Kappa'] = kapparet_metrics = {metric: value.numpy() if isinstance(value, torch.Tensor) else valuefor metric, value in ret_metrics.items()}if nan_to_num is not None:ret_metrics = OrderedDict({metric: np.nan_to_num(metric_value, nan=nan_to_num)for metric, metric_value in ret_metrics.items()})return ret_metrics
相关文章:

MMSegmentation改进:增加Kappa系数评价指数
将mmseg\evaluation\metrics\iou_metric.py文件中的内容替换成以下内容即可: 支持输出单类Kappa系数和平均Kappa系数。 使用方法:将dataset的config文件中:val_evaluator 添加mKappa,如 val_evaluator dict(typemmseg.IoUMetri…...

专栏【汇总】
专栏【汇总】 前言版权推荐专栏【汇总】付费 汇总置顶在读在学我的面试计算机重要课程java面试Java基础数据存储Java框架java提高计算机科学与技术课程算法杂项 最后 前言 2024-5-12 21:13:02 以下内容源自《【专栏】》 仅供学习交流使用 版权 禁止其他平台发布时删除以下此…...

成功解决IndexError: index 0 is out of bounds for axis 1 with size 0
成功解决IndexError: index 0 is out of bounds for axis 1 with size 0 🛠️ 成功解决IndexError: index 0 is out of bounds for axis 1 with size 0摘要引言正文内容(详细介绍)🤔 错误分析:为什么会发生IndexError&…...

C# MES通信从入门到精通(11)——C#如何使用Json字符串
前言 我们在开发上位机软件的过程中,经常需要和Mes系统进行数据交互,并且最常用的数据格式是Json,本文就是详细介绍Json格式的类型,以及我们在与mes系统进行交互时如何组织Json数据。 1、在C#中如何调用Json 在C#中调用Json相关…...

ON DUPLICATE KEY UPDATE 子句
ON DUPLICATE KEY UPDATE 是 MySQL 中的一个 SQL 语句中的子句,主要用于在执行 INSERT 操作时处理可能出现的重复键值冲突。当尝试插入的记录导致唯一索引或主键约束冲突时(即试图插入的记录的键值已经存在于表中),此子句会触发一…...

perl use HTTP::Server::Simple 轻量级 http server
cpan -i HTTP::Server::Simple 返回:已是 up to date. 但是我在 D:\Strawberry\perl\site\lib\ 找不到 HTTP\Server 手工安装:下载 HTTP-Server-Simple-0.52.tar.gz 解压 tar zxvf HTTP-Server-Simple-0.52.tar.gz cd D:\perl\HTTP-Server-Simple-…...
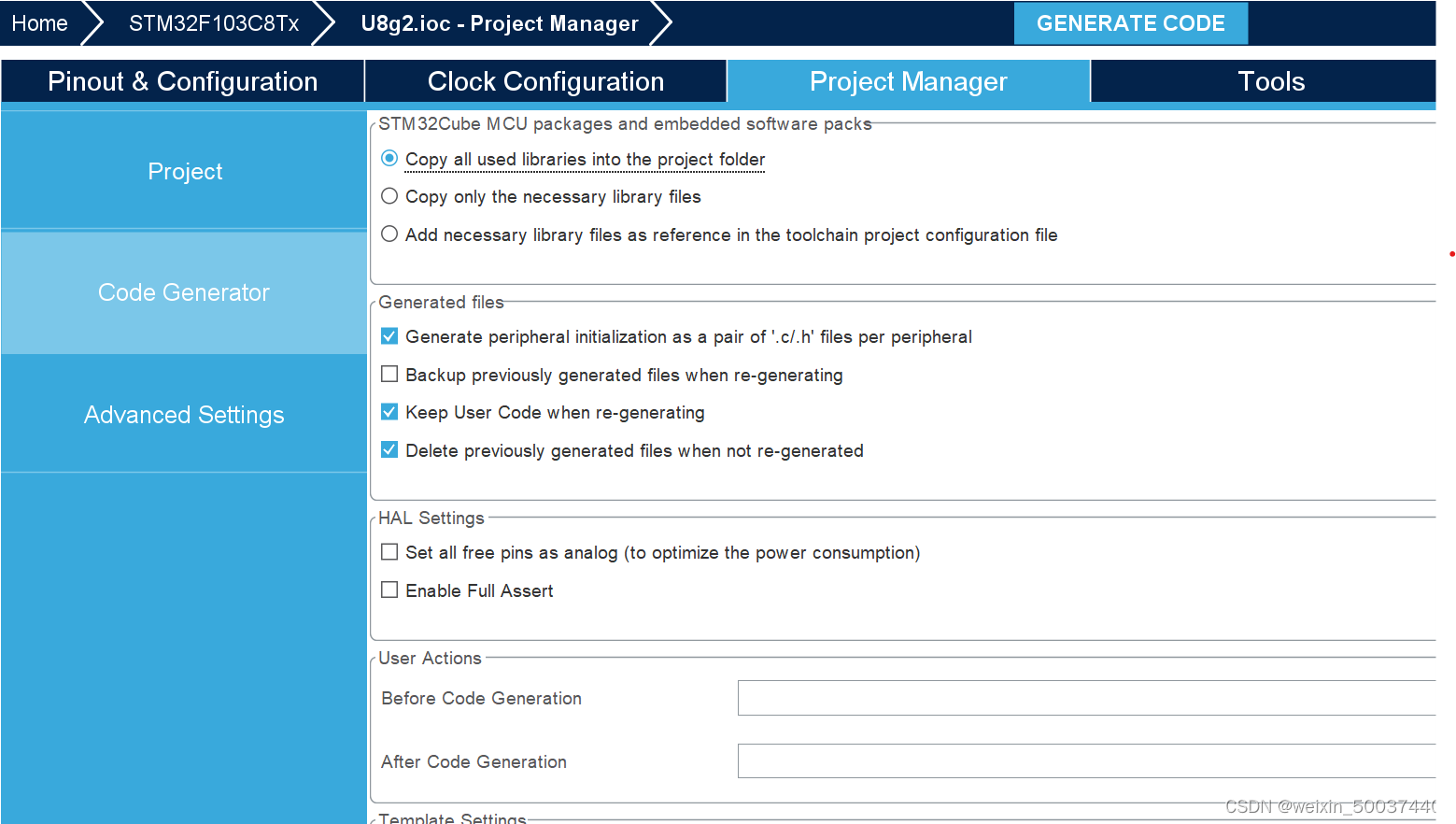
【STM32】基于I2C协议的OLED显示(利用U82G库)
【STM32】基于I2C协议的OLED显示(利用U82G库) 文章目录 【STM32】基于I2C协议的OLED显示(利用U82G库)一、实验背景二、U8g2介绍(一)获取(二)简介 三、实践(一)CubexMX配置(二)U8g2配…...

掌握Python3输入输出:轻松实现用户交互、日志记录与数据处理
Python 是一门简洁且强大的编程语言,广泛应用于各个领域。在 Python 编程中,输入和输出是基本而重要的操作。无论是进行用户交互、记录日志信息,还是将计算结果输出到控制台或文件,掌握这些操作都是编写高效 Python 程序的关键。本…...

用于每个平台的最佳WordPress LMS主题
你已选择在 WordPress 上构建学习管理系统 (LMS)了。恭喜! 你甚至可能已经选择了要使用的 LMS 插件,这已经是成功的一半了。 现在是时候弄清楚哪个 WordPress LMS 主题要与你的插件配对。 我将解释 LMS 主题和插件之间的区别,以便你了解要…...

pytorch 加权CE_loss实现(语义分割中的类不平衡使用)
加权CE_loss和BCE_loss稍有不同 1.标签为long类型,BCE标签为float类型 2.当reduction为mean时计算每个像素点的损失的平均,BCE除以像素数得到平均值,CE除以像素对应的权重之和得到平均值。 参数配置torch.nn.CrossEntropyLoss(weightNone,…...

【iOS】UI——关于UIAlertController类(警告对话框)
目录 前言关于UIAlertController具体操作及代码实现总结 前言 在UI的警告对话框的学习中,我们发现UIAlertView在iOS 9中已经被废弃,我们找到UIAlertController来代替UIAlertView实现弹出框的功能,从而有了这篇关于UIAlertController的学习笔记…...

django支持https
测试环境,可以用django自带的证书 安装模块 sudo pip3 install django_sslserver服务端https启动 python3 manage.py runsslserver 127.0.0.1:8001https访问 https://127.0.0.1:8001/quota/api/XXX...
)
算法题day41(补5.27日卡:动态规划01)
一、动态规划基础知识:在动态规划中每一个状态一定是由上一个状态推导出来的。 动态规划五部曲: 1.确定dp数组 以及下标的含义 2.确定递推公式 3.dp数组如何初始化 4.确定遍历顺序 5.举例推导dp数组 debug方式:打印 二、刷题…...
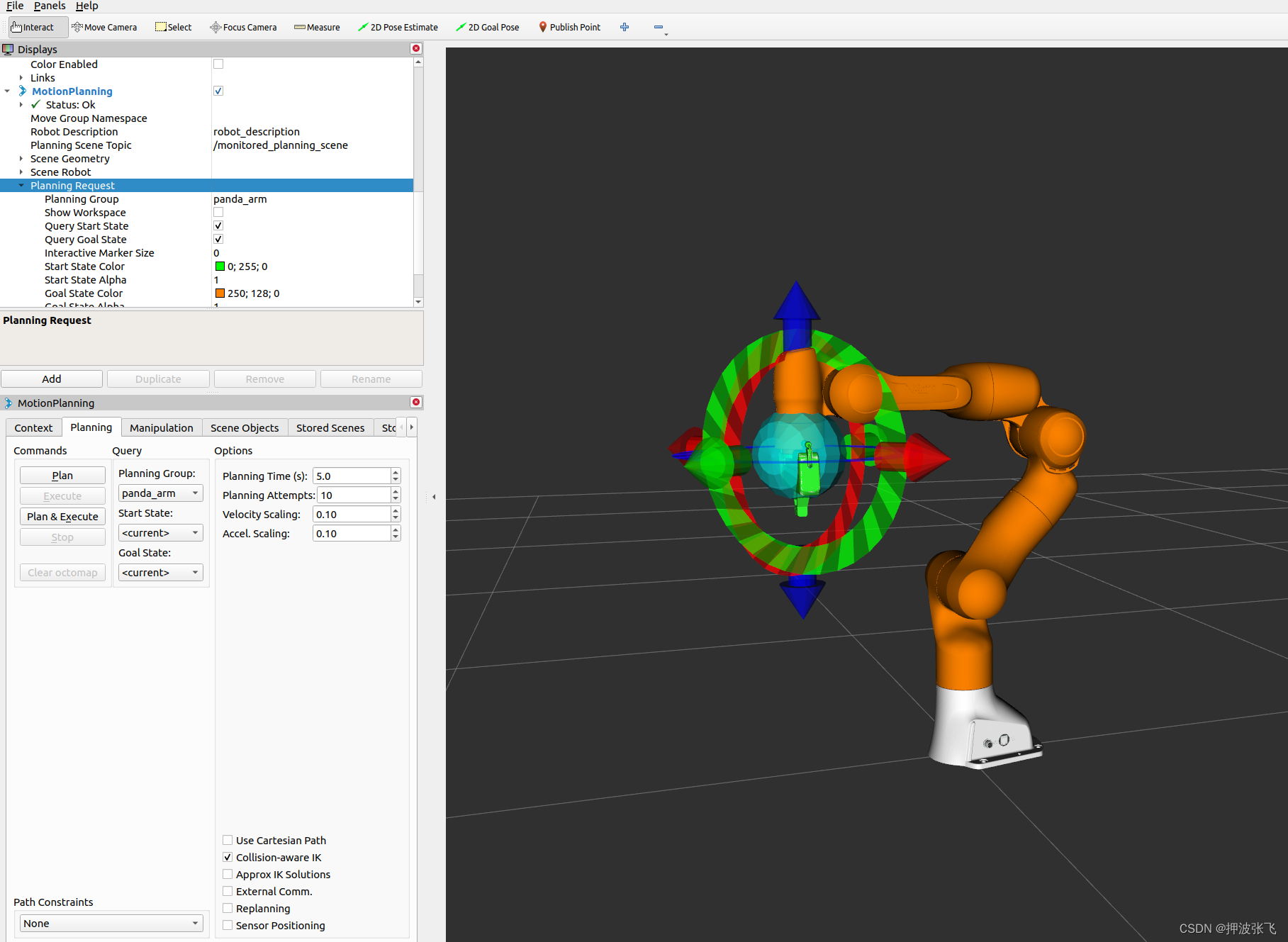
【附带源码】机械臂MoveIt2极简教程(四)、第一个入门demo
系列文章目录 【附带源码】机械臂MoveIt2极简教程(一)、moveit2安装 【附带源码】机械臂MoveIt2极简教程(二)、move_group交互 【附带源码】机械臂MoveIt2极简教程(三)、URDF/SRDF介绍 【附带源码】机械臂MoveIt2极简教程(四)、第一个入门demo 目录 系列文章目录1. 创…...
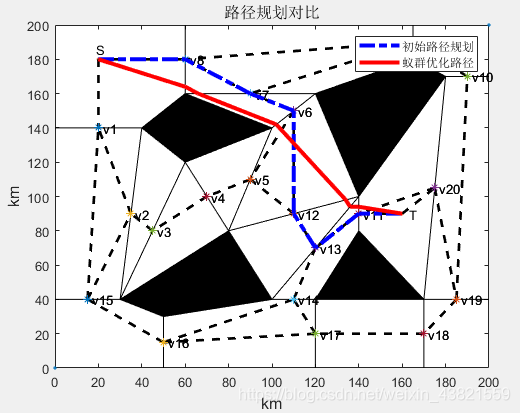
基于蚁群算法的二维路径规划算法(matlab)
微♥关注“电击小子程高兴的MATLAB小屋”获得资料 一、理论基础 1、路径规划算法 路径规划算法是指在有障碍物的工作环境中寻找一条从起点到终点、无碰撞地绕过所有障碍物的运动路径。路径规划算法较多,大体上可分为全局路径规划算法和局部路径规划算法两大类。其…...
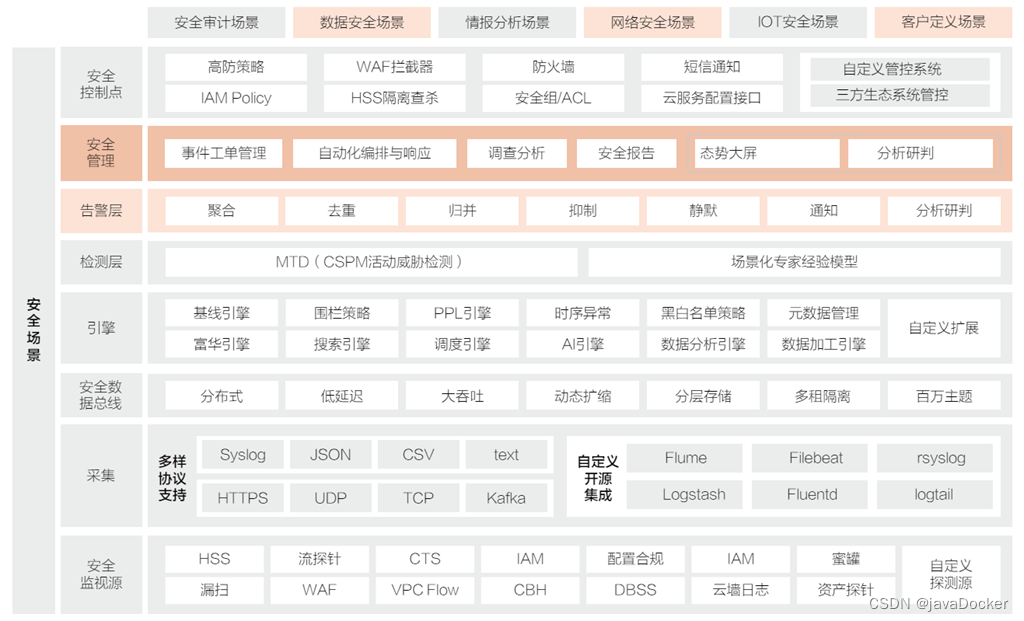
政务云参考技术架构
行业优势 总体架构 政务云平台技术框架图,由机房环境、基础设施层、支撑软件层及业务应用层组成,在运维、安全和运营体系的保障下,为政务云使用单位提供统一服务支撑。 功能架构 标准双区隔离 参照国家电子政务规范,打造符合标准的…...

android 13 aosp 预置so库
展讯对应的main.mk配置 device/sprd/qogirn**/ums***/product/***_native/main.mk $(call inherit-product-if-exists, vendor/***/build.mk)vendor/***/build.mk PRODUCT_PACKAGES \libtestvendor///Android.bp cc_prebuilt_library_shared{name:"libtest",srcs:…...

mongo篇---mongoDB Compass连接数据库
mongo篇—mongoDB Compass连接数据库 mongoDB笔记 – 第一条 一、mongoDB Compass连接远程数据库,配置URL。 URL: mongodb://username:passwordhost:port点击connect即可。 注意:host最好使用名称,防止出错连接超时。...

基于SOA海鸥优化算法的三维曲面最高点搜索matlab仿真
目录 1.程序功能描述 2.测试软件版本以及运行结果展示 3.核心程序 4.本算法原理 5.完整程序 1.程序功能描述 基于SOA海鸥优化算法的三维曲面最高点搜索matlab仿真,输出收敛曲线以及三维曲面最高点搜索结果。 2.测试软件版本以及运行结果展示 MATLAB2022A版本…...

前端js解析websocket推送的gzip压缩json的Blob数据
主要依赖插件pako https://www.npmjs.com/package/pako 1、安装 npm install pako 2、使用, pako.inflate(reader.result, {to: "string"}) 解压后的string 对象,需要JSON.parse转成json this.ws.onmessage (evt) > {console.log("…...

H3C模拟器实战:基于时间与部门的精细化ACL策略部署
1. 企业网络访问控制的痛点与ACL解决方案 在企业网络管理中,最让人头疼的就是如何平衡安全性和便利性。我见过太多公司要么一刀切封锁所有端口导致业务受阻,要么放任自流引发数据泄露。就拿去年帮某中型企业排查的问题来说,他们的销售部员工在…...

从零到跑通:Windows下OTB100数据集与Matlab评测环境保姆级避坑指南
从零到跑通:Windows下OTB100数据集与Matlab评测环境保姆级避坑指南 刚接触目标跟踪领域的研究者,往往需要从经典数据集评测开始。OTB(Object Tracking Benchmark)作为目标跟踪领域的基石数据集,包含100个具有挑战性的视…...

Windows系统美化终极指南:如何快速实现个性化定制与性能优化 [特殊字符]
Windows系统美化终极指南:如何快速实现个性化定制与性能优化 🚀 【免费下载链接】Atlas 🚀 An open and lightweight modification to Windows, designed to optimize performance, privacy and usability. 项目地址: https://gitcode.com/…...
)
从劝退到离不开:Vim新手入门实战博客(附高效技巧)
文章目录前言💙一、vim是什么?💜二、为什么要学习vim?💚三、vim总览💔四、vim的基本操作4.1vim正常模式命令集(命令模式)4.2vim底行模式命令集4.3vim视图模式💗五、一些小技巧💖六、…...
Pixel-to-Space 像素到空间 一镜到底·跨镜连续技术解析方案
Pixel-to-Space 像素到空间 一镜到底跨镜连续技术解析方案一、技术总览1.1 核心定义Pixel-to-Space像素到空间,是一套自成体系的二维视频像素向三维物理空间实时反演的全域感知范式,跳出市面传统视频解析与空间重建的通用研发路线,形成专属化…...

OpenClawWatch:本地优先的AI智能体监控工具,实现成本、安全与行为全链路追踪
1. 项目概述:为什么我们需要一个“本地优先”的AI智能体监控工具?如果你正在开发或运行能够自主执行任务的AI智能体,比如自动处理邮件、调用API、操作文件,甚至进行线上交易,那么你肯定经历过这样的焦虑时刻࿱…...

图解CA注意力机制:用Keras一步步拆解‘宽高分离池化’,理解位置信息如何嵌入通道注意力
图解CA注意力机制:用Keras拆解‘宽高分离池化’的视觉密码 当我们谈论注意力机制时,脑海中往往会浮现SE(Squeeze-and-Excitation)模块的通道加权画面。但今天要探讨的CA(Coordinate Attention)机制…...

RTK内置电台:如何能撬动消费电子万亿市场|深圳海导科技navynav
在测绘、农业、智能交通等领域,厘米级甚至毫米级的高精度定位需求正推动着定位技术的持续革新。作为实时动态载波相位差分技术的核心组件,RTK内置电台凭借其无需外接设备、抗干扰能力强、部署灵活等优势,已成为高精度定位系统的“神经中枢”。…...

SuperMap GIS集成天地图服务:从协议解析到多端应用实战
1. 天地图服务与SuperMap GIS集成基础 第一次接触天地图服务集成时,我被各种参数和协议搞得晕头转向。后来在智慧城市项目中反复实践才发现,理解这些基础概念就像学做菜要先认识调料一样重要。 天地图服务主要分为国家版和地方版两种。国家天地图采用449…...

C语言--day14
指针的常见操作 指针变量,有两方面的意思 一个指针指向的内容(数据值,一级) 指针变量本身存储的数据 (地址值) #include <stdio.h> int main() {int a 10;int b 0 ;int c 50;int *p NULL;int *q NULL;p &a; // 对指针变量本身进行修改…...