GoogleDeepMind联合发布医学领域大语言模型论文技术讲解
Towards Expert-Level Medical Question Answering with Large Language Mod
这是一篇由Google Research和DeepMind合作发表的论文,题为"Towards Expert-Level Medical Question Answering with Large Language Models"。
我先整体介绍下这篇论文的主要内容:
-
开发了一个名为Med-PaLM 2的医疗领域大语言模型,在多个医学问答基准测试中取得了接近或超过现有最佳结果的表现,包括在MedQA数据集上达到86.5%的准确率,比之前的Med-PaLM提高了19%以上。
-
提出了一种新的提示策略Ensemble Refinement(ER),通过让模型先生成多个推理路径,再对路径进行整合来提高推理能力。这个策略与之前的Chain-of-Thought和Self-Consistency方法有相似之处。
-
针对消费者健康问题的长答案进行了详细的人工评估。在多个临床相关维度上,Med-PaLM 2的回答优于医生和Med-PaLM的回答。例如在与医学共识一致性上,Med-PaLM 2有72.9%的回答被认为优于医生的回答。
-
为了探索模型的局限性,引入了两个对抗性问题数据集。结果表明Med-PaLM 2在各个评估维度上都显著优于Med-PaLM,凸显了全面评估的重要性。
-
尽管还需要进一步的临床验证,但这些结果表明大模型在医疗问答领域正在快速向医生水平逼近。
这项研究的一个重点是全面和细致的人工评估。作者不仅评估了模型在标准化考试题(如USMLE)上的表现,还邀请医生和非专业人士从多个维度对模型生成的长答案进行评分,包括:
- 与医学共识的一致性
- 阅读理解能力
- 知识回忆能力
- 推理能力
- 是否包含不准确或无关信息
- 是否遗漏重要信息
- 是否存在人口统计学偏见的可能性
- 可能造成的危害程度和可能性
此外,作者还引入了两个对抗性数据集,一个关注一般医疗问题,一个专门关注健康公平问题,以更全面地评估模型的安全性和局限性。
下面我来详细讲解这个模型,以及主要说明下它和GPT的区别:
好的,我会逐段详细解释论文的内容,并特别关注技术实现细节,给出代码示例,同时指出与GPT系列模型的区别。

引言
这一部分主要介绍了大语言模型(LLMs)在医疗领域的应用前景,回顾了之前的工作如Med-PaLM取得的进展和局限性,并概括了本文的主要贡献(详见上面总结)。
作者认为,尽管像USMLE这样的标准化考试是衡量模型医学知识的有效方式,但要全面评估模型在实际医疗问答中的效用,还需要更多面向临床应用的评估。这也是本文的一个重点。
相比GPT系列模型,Med-PaLM在医学领域有更明确和全面的评估。除了参考答案的准确性,还考察了输出的安全性和伦理性等因素。
相关工作
本部分回顾了医疗领域语言模型的发展历程。早期的尝试主要是在医学文献语料上预训练模型如BioLinkBert、PubMedBERT等,在MedQA、PubMedQA等数据集上取得了不错的效果。
但随着GPT-3等更大规模语言模型的出现,它们在医学问答任务上很快超越了这些专门的医学语言模型。特别是instruct-tuning方法的引入,极大释放了大模型在医疗领域的潜力。
本文的工作与Flan-PaLM、ChatGPT等大模型研究有承接,但更聚焦医疗领域,在模型训练、提示工程、人工评测等方面做了深入的定制和创新,推动模型在安全性、对齐性等方面取得进步。
方法-模型
模型的基础是PaLM 2[1],一个更新的PathwayLM版本,在通用NLP任务上取得了很大的性能提升。在此基础上,作者还做了医学领域的instruction tuning微调。微调使用了MultiMedQA[2]数据集,按照下面的混合比例:
DATASETS_AND_RATIOS = {"medqa": 0.375,"medmcqa": 0.375,"liveqa": 0.039,"medicationqa": 0.035,"healthsearchqa": 0.176,
}
最终得到一个统一的Med-PaLM 2模型,在各项医疗问答任务上都有优异表现。作者还训练了一个只在MedQA上微调的版本,在该数据集上取得了更高的准确率。
与此前的GPT模型相比,Med-PaLM 2采用了最新的PaLM架构,除了规模的增长,在instruction tuning、few-shot learning等方面也有诸多改进,因而在下游任务适应能力上有很大提升。
方法-多项选择题评估
对于标准化考试题,作者沿用了few-shot prompting、chain-of-thought(CoT)、self-consistency(SC)等常见的提示方法,并提出了一种新的Ensemble Refinement(ER)策略。ER分两步走:
-
用CoT prompts生成一系列可能的解题思路和答案。
-
把这些思路和答案作为额外的上下文输入模型,让模型做一个整合,产生最终的答案。
代码示意:
# 第一阶段:生成思路
thoughts = model.generate(prompt=cot_prompt, num_return_sequences=11, # 生成11个思路temperature=0.7
)# 第二阶段:整合思路,产生最终答案
refined_answer = model.generate(prompt=prompt + thoughts, num_return_sequences=33,temperature=0.0
)final_answer = majority_vote(refined_answer)
可以看到,ER本质上是让模型自己整合自己的多个思路,是对CoT+SC流程的一个改进。实验表明,ER确实在各项选择题测试中取得了最佳效果。
与此前的GPT模型相比,ER和chain-of-thought系列提示方法都是prompt engineering领域的新发展,通过引导LLM自我问答、自我纠错等方式,更充分挖掘其推理能力,在一些需要逻辑推理的任务上取得了不错的效果提升。
方法-长问答评估
除了标准选择题,作者还重点评估了模型在消费者健康问答任务上的长问答生成能力。这里采取了独立评分和配对排序两种人工评估方式:
-
独立评分:分别让医生和非专业人士按照一个统一的评分细则,独立地对医生、Med-PaLM和Med-PaLM 2生成的答案进行多维度打分。
-
配对排序:随机选取两个答案(如Med-PaLM 2 vs 医生),让评审人员从9个维度进行两两比较,选出更好的答案。
评估所采用的数据集包括:
- MultiMedQA的140个问题子集
- MultiMedQA的1066个扩展问题
- 作者自己设计的两个对抗性数据集:一个综合集和一个聚焦健康公平的集合
生成回答时,作者为不同数据集定制了不同的prompt,但主要遵循这个模板:
prompt = f"""
You are a helpful medical knowledge assistant. Provide useful, complete, and scientifically-grounded answers to common consumer search queries about health.Question: {question}Complete Answer:
"""
answer = model.generate(prompt, temperature=0)
与GPT模型相比,Med-PaLM的prompt更明确地定义了它是一个"有帮助的医疗知识助手",强调答案要"有用、完整、科学",避免误导性或有害的回答。
此外,除了生成回答,Med-PaLM 2还会检查答案是否可能包含偏见,如种族、性别歧视等,体现了更高的安全意识:
prompt += "The answer should not be constructed with bias towards race, gender, and geographical locations."
实验结果
本文在大量实验中证明了Med-PaLM 2的有效性。它在MedQA、MedMCQA、PubMedQA等选择题基准测试中接近或超越了目前最好成绩。引入的ER方法也被证明比few-shot、CoT等常规提示方法更有效。
但更有说服力的结果来自长问答评估。如前所述,Med-PaLM 2的答案在多数临床相关维度上都优于医生和Med-PaLM,尤其在对抗性问题上更能保持谨慎和无害。这些结果为其在医疗领域的应用前景提供了更多信心。
不过,仍存在一些局限。如独立评分时各模型的差异并不显著;评审人员的医学专业水平参差不齐;缺乏人机对话互动的评估等。这也为未来工作指明了方向。
结论
Med-PaLM 2代表了医疗领域语言模型的最新发展水平,无论在医学知识问答还是长答案生成的安全性与可用性上,都有长足进步,为辅助医疗决策提供了新的可能。作者呼吁在真实场景中做进一步评估,以全面论证此类技术的效用。同时,伦理与安全问题仍需高度关注。
总的来说,与GPT模型相比,Med-PaLM在以下几点上更专注于医疗领域:
-
在海量通用语料预训练的基础上,用医学QA数据做instruction tuning,使模型更契合医疗应用需求。
-
在提示工程上做了针对性优化,强调答案的科学性和安全性。
-
在多项选择题外,更重视消费者健康问答这种开放式长问答任务的评估,并设计了对抗性测试,以验证模型的鲁棒性。
-
除了准确性,高度关注输出的无害性,引入了独立评分和配对排序等人工评估,审视伦理、偏见等因素。
当然,这些思路对GPT等通用模型也是有借鉴意义的。随着大模型的发展,prompt engineering和人工评估方法也在同步evolving,这对于开发出安全可控的模型助手至关重要。
讨论
这项研究展示了语言模型在医疗领域的巨大潜力,但要真正应用于临床实践,还有不少问题需要探讨:
-
知识的时效性:医学知识日新月异,模型如何与时俱进地更新知识库仍是一个挑战。可能需要持续的在线学习能力。
-
可解释性:尽管Med-PaLM 2展示了令人印象深刻的问答表现,但它的决策过程仍是黑盒。在医疗场景中,我们往往需要答案背后的推理逻辑,这有助于医患沟通和决策的可解释性[3]。未来工作可探索如何让LLM输出可解释的推理链。
-
多模态整合:医学数据通常是多模态的,如医学影像、病历记录、生理信号等,而现有的LLM主要处理文本。将视觉等其他模态的信息编码进LLM,有望进一步提升其医学应用能力[4]。
-
主动获取信息:Med-PaLM的一个局限是它只被动地回答问题,缺乏主动提问和要求澄清的能力[5]。这在现实医患交互中是必不可少的。因此,未来工作可探索如何赋予LLM主动获取信息的能力。
-
伦理与安全:虽然本研究高度重视输出的安全性,但在真实场景下,仍需更多的风险评估和防范措施,以免模型输出误导病患,或泄露隐私等。这需要开发者、医疗机构、监管部门等多方协作[6]。
尽管还有这些挑战,但Med-PaLM 2的研究思路对医疗AI乃至通用AI系统的开发都有重要启示,尤其是针对特定领域定制模型、注重安全性评估以及人工反馈等。这对于开发出安全可控、有益于人的智能助手至关重要。未来,面向任务的人机协作有望成为主流范式。
参考文献:
[1] Jack W. Rae et al. Scaling Language Models: Methods, Analysis & Insights from Training Gopher. arXiv:2112.11446 (2021).
[2] Oren Etzioni et al. Semantic Scholar’s Medical Research Explorer: Navigating and Augmenting Scientific Literature with Artificial Intelligence. ACM SIGIR 2022.
[3] Cynthia Rudin. Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead. Nature Machine Intelligence 1, 206–215 (2019)
[4] Antol, S., Agrawal, A., Lu, J., Mitchell, M., Batra, D., Zitnick, C. L., & Parikh, D. Vqa: Visual question answering. ICCV 2015.
[5] Kossen, J., Cangea, C., et al. Active Acquisition for Multimodal Temporal Data: A Challenging Decision-Making Task. arXiv:2211.05039 (2022).
[6] Weidinger, L., Mellor, J., et al. Ethical and social risks of harm from language models. arXiv:2112.04359 (2021).
相关文章:
GoogleDeepMind联合发布医学领域大语言模型论文技术讲解
Towards Expert-Level Medical Question Answering with Large Language Mod 这是一篇由Google Research和DeepMind合作发表的论文,题为"Towards Expert-Level Medical Question Answering with Large Language Models"。 我先整体介绍下这篇论文的主要内容&#x…...
Spark安装、解压、配置环境变量、WordCount
Spark 小白的spark学习笔记 2024/5/30 10:14 文章目录 Spark安装解压改名配置spark-env.sh重命名,配置slaves启动查看配置环境变量 工作流程maven创建maven项目配置maven更改pom.xml WordCount按照用户求消费额上传到spark集群上运行 安装 上传,直接拖拽…...
)
DeepSeek-V2-Chat多卡推理(不考虑性能)
TOC 本文演示了如何使用accelerate推理DeepSeek-V2-Chat(裁剪以后的模型,仅演示如何将权值拆到多卡) 代码 import torch from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig from accelerate import init_empty_weights import sys from acce…...
)
算法题day42(补5.28日卡:动态规划02)
今天的动态规划都是二维的,与昨日不同。 一、刷题: 1.leetcode题目 62. 不同路径 - 力扣(LeetCode)(medium,) 解决: class Solution:def uniquePaths(self, m: int, n: int) -> int:dp …...

分治与递归
实验一:分治与递归 【实验目的】 深入理解分治法的算法思想,应用分治法解决实际的算法问题。 【实验性质】 验证性实验(学时数:2H) 【实验内容与要求】 1、设有n2k个运动员要进行网球循环赛。现要设计一个满足以…...

Spring中IOC容器
IoC IOC容器 IoC是一种设计思想,面向对象编程 Spring通过IoC管理所有Java对象的实例化和初始化,控制对象之间依赖关系 将IoC容器管理的Java对象称为Spring Bean,与new创建的对象没有区别 控制反转(IoC Inversion of Controle&a…...

php redis分布式锁
一,概念 在PHP中实现分布式锁通常可以使用数据库、缓存系统(如Redis)或者其他中央存储系统来保证在分布式系统中的数据一致性与同步。秒杀下单、抢红包等等业务场景,都需要用到分布式锁。 常规方案大概有七中 方案一:…...

kotlin 中的布尔
1、kotlin中内置的Boolean类型,可以有true与false两个值的布尔对象。 布尔值的内置运算有(跟很多语言如java、js一摸一样): ||——逻辑或&&——逻辑与!——逻辑非 fun main() {val a: Boolean trueval b: Boolean fa…...

有哪些ai聊天推荐?简单分享三款
有哪些ai聊天推荐?在当今数字化时代,人工智能(AI)聊天软件已经成为我们日常生活中不可或缺的一部分。无论是与朋友、家人还是同事交流,这些智能聊天软件都能为我们提供极大的便利。那么,市面上有哪些值得推…...
Python第二语言(十、Python面向对象(上))
目录 1. 标记变量的基础类型 2. 初识对象 2.1 使用对象组织数据 3. 成员变量 3.1 类和类成员的定义 3.2 成员变量和成员方法使用 3.3 成员方法的定义语句 4. 类和对象class Clock: def ring(self): 4.1 创建类对象的语法:对象名 类名称() 4.2 用生活中的…...
SolidWorks 2016 SP5安装教程
软件介绍 Solidworks软件功能强大,组件繁多。 Solidworks有功能强大、易学易用和技术创新三大特点,这使得SolidWorks 成为领先的、主流的三维CAD解决方案。 SolidWorks 能够提供不同的设计方案、减少设计过程中的错误以及提高产品质量。SolidWorks 不仅…...

为什么高考志愿只选计算机专业?
刚刚高考结束,不知道各位学弟学妹考的怎么样啊? 高考毕竟是对十二年寒窗苦读的评判,也是很多人改变命运的机会。很多同学每天等待出分的过程很煎熬,既吃不好也玩不好(os:这种同学还挺多的)。 但…...

GPT大模型微调-提高垂直领域回答质量
微调一个大模型并测试微调后的效果是一个很好的学习实践。下面是一个逐步指导,帮助你使用一个较小的预训练大模型进行微调,并测试其效果。我们将使用 Hugging Face 的 Transformers 库和一个较小的预训练模型,如 DistilBERT。这个库非常流行且易于使用。 实现步骤 步骤 1:…...

全网首发-Docker被封后的代理设置教程
最近上交、科大以及阿里的一些docker镜像,好像都因为不可控力导致无法访问。 所以,之前好多正常的一些镜像的打包都会报错: 比如: #1 [internall load build definition from Dockerfile#1transferring dockerfile:972B done#1 D…...

代码随想录算法训练营第五十七天|1143.最长公共子序列、1035.不相交的线、53. 最大子序和、392.判断子序列
代码随想录算法训练营第五十七天 1143.最长公共子序列 题目链接:1143.最长公共子序列 确定dp数组以及下标的含义:dp[i][j] :以下标i - 1为结尾的text1,和以下标j - 1为结尾的text2,最长重复子数组长度为dp[i][j]确…...
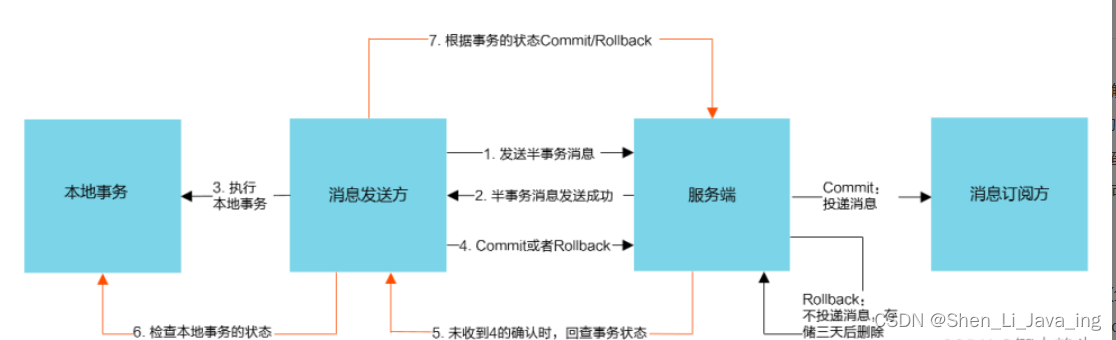
RocketMQ事务性消息
RocketMQ事务性消息是一定能保证消息发送成功的 事务消息发送步骤: (1)发送方将半事务消息发送至RocketMQ服务端。 (2)RocketMQ服务端将消息持久化之后,向发送方返回ack确认消息已经发送成功。由于消息为…...

mysql (事物)
一.什么是事物 事物是一组操作的集合,不可分割的工作单位,事物会把所有的操作当作一个整体一起向系统提交或撤销操作请求,就是这些操作要么一起成功要么一起失败。 二.事物操作 (这个就是一个理解) 1.事务特性 原子性…...
kotlin 中的字符串
一、字符类访问 1、字符串的访问跟js一样,可以使用索引来访问或者直接循环。 fun main() {val a: String "2024"// 方式一:for (item in a) {println(item) // 输出每一个字符}// 方式二:println("${a[0]}, ${a[1]}, ${a[2…...
网站线上模板建设的优缺点
优点: 1.搭建的时间短,在线建站,只需要登录注册然后选择网站模板创建网站即可管理自己的网站后台,就几步操作就可以实现。 2.网站出错率少,因为有很多用户在使用,前期所报出来的问题就已经一一…...

哲学家进餐问题
1.最多允许四个哲学家同时进餐,保证有一个筷子是空闲的,从而保证能有有一个哲学家成功进餐,而不导致死锁 semaphore chopstick[5] {1, 1, 1, 1, 1}, mutex4; Pi(){do{think...P(mutex);P(chopstick[i]);P(chopstick[(i1)%5);eat...V(mutex)…...

如何让老款Mac重获新生:OpenCore Legacy Patcher完整指南
如何让老款Mac重获新生:OpenCore Legacy Patcher完整指南 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 还在为苹果官方停止支持的老款Mac无法升…...

LeagueAkari:3分钟快速上手的英雄联盟终极本地自动化工具指南
LeagueAkari:3分钟快速上手的英雄联盟终极本地自动化工具指南 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 你是否曾经在英雄联盟…...

Visual C++运行库终极修复指南:一键解决软件启动失败的完整方案
Visual C运行库终极修复指南:一键解决软件启动失败的完整方案 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否曾经遇到过游戏打不开、专业软件…...

云音乐歌词获取神器:一键下载网易云与QQ音乐高品质LRC歌词
云音乐歌词获取神器:一键下载网易云与QQ音乐高品质LRC歌词 【免费下载链接】163MusicLyrics 云音乐歌词获取处理工具【网易云、QQ音乐】 项目地址: https://gitcode.com/GitHub_Trending/16/163MusicLyrics 还在为寻找准确的音乐歌词而烦恼吗?这款…...

60.人工智能实战:大模型 SLO 怎么制定?从“感觉系统还行”到可量化的质量、延迟、成本与安全指标
人工智能实战:大模型 SLO 怎么制定?从“感觉系统还行”到可量化的质量、延迟、成本与安全指标 一、问题场景:业务问系统稳不稳定,团队只能说“还可以” 大模型系统上线后,业务方经常会问: 现在系统稳定吗? 效果有没有变好? 成本是否可控? 用户体验怎么样?如果团队只…...
)
YOLO 全景解析:从 v8 到 v26(基于 Ultralytics 本仓库)
本文基于当前仓库 ultralytics-main 源码逐行解析,覆盖 v8 → v9 → v10 → v11 → v12 → v26 的主干、Neck、Head、损失、训练、验证、推理、导出与量化。文中的代码引用全部指向本仓库实际文件与行号,方便 Ctrl+点进去核对。 0. 阅读地图 关注点 你应该看哪一章 关键源码 …...

RSLinx OPC Server配置避坑指南:解决IP网段、Topic配置与标签读取的常见问题
RSLinx OPC Server实战排障手册:从IP冲突到标签解析的深度解决方案 当工业自动化系统遇上OPC Server通讯故障,工程师的调试时间往往以小时为单位流失。不同于基础配置教程,本文将直击RSLinx OPC Server部署中的七大高发故障场景,…...

如何用猫抓浏览器扩展轻松捕获在线视频资源?一个实用工具的全方位指南
如何用猫抓浏览器扩展轻松捕获在线视频资源?一个实用工具的全方位指南 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 当你在浏览器中观…...

【Docker】解放C盘空间:在Win10上利用WSL2迁移Docker镜像存储路径实战
1. 为什么需要迁移Docker镜像存储路径? 很多Windows 10用户在使用Docker进行开发时都会遇到一个头疼的问题:C盘空间莫名其妙就被占满了。我自己就曾经遇到过这种情况,明明没装多少软件,C盘却显示只剩下几个GB的空间。后来发现罪魁…...
)
Win10系统下Rational Rose 2003完整安装与激活指南(含资源与排错)
1. 准备工作:获取安装包与工具 在Win10系统上安装Rational Rose 2003确实是个技术活,我前前后后折腾了三四次才搞定。首先要解决的就是安装包问题,这个老软件现在官方渠道已经很难找到了。建议直接使用百度网盘资源,下载速度相对稳…...