使用difflib实现文件差异比较用html显示
1.默认方式,其中加入文本过长,需要换行,因此做
content=html_output.replace('</style>','table.diff td {word-wrap: break-word;white-space: pre-wrap;max-width: 100%;}</style>'),添加换行操作
ps:当前text1输入是列表格式,返回是按照行形式(如果text1输入的是字符串,返回是按照列形式)
#coding:utf-8
import difflibtext1 = '''尊敬的韦尔总理、尊敬的汉恩党委书记、王省长、总领事、
女士们和先生们,
今天我非常高兴与你们共同庆祝40年的伙伴关系。'''.splitlines(keepends=True)
#
text2 = '''尊敬的韦尔总理,汉恩党委书记,王省长,总领事,
女士们,先生们,
今天我很高兴与你们一起庆祝四十年的伙伴关系。'''.splitlines(keepends=True)
html_diff = difflib.HtmlDiff()
html_output = html_diff.make_file(text1, text2)content=html_output.replace('</style>','table.diff td {word-wrap: break-word;white-space: pre-wrap;max-width: 100%;}</style>')
with open('diff_output_huanhang.html', 'w',encoding="utf-8") as fw:fw.write(content)案例展示:

2.方式1直接调用difflib.HtmlDiff()存在一个问题,在复杂场景下不能针对文本很好的比对(小伙伴们有好的方案可以推荐,当前输入字符串按列展示没有问题,但看着不舒服),因此使用diff_match_patch或者difflib.SequenceMatcher,进行修改,当前以diff_match_patch演示
#coding:utf-8
import diff_match_patch
def read(file):with open(file, 'r', encoding="utf-8") as fr:content=fr.read()return contenthtml_cont = read("diff_baseline.html")text1 = '''尊敬的韦尔总理、汉恩党委书记、王省长、总领事、女士们和先生们,今天我非常高兴与你们共同庆祝40年的伙伴关系。我们作为AHK只做了三十年。我认为这是一个感谢前任的机会,他们为这种伙伴关系付出了很多努力。这种伙伴关系不仅存在于纸面上,还存在于实践中。我认为目前是我们塑造未来40年的关键时期,这可能比过去40年更加困难。因为中国在不断变化,所以我们设法找到并利用共同的潜力。今天政治领导人在这里向我们发出明确信号,即伙伴关系符合双方利益。我还要指出,总理。创新的公司表示愿意参与这个地区的发展,寻找并实施市场潜力。作为AHK,我们已经帮助了30年,同时我们在德国的组织和工商会也在尽我们所能支持德国公司。说话人E:我很高兴你今天发起了这个会议,我们的公司可以与中国公司见面,在那里他们可以互相交谈。他们可以达成交易的地方,我相信我们都同意,未来40年只有我们继续好好交谈、合作、做生意才会越来越好。我祝愿所有与会者和会议取得圆满成功。谢谢。
'''
text2 = '''尊敬的韦尔总理,尊敬的汉恩党委书记,王省长,总领事,女士们,先生们,今天我很高兴与你们一起庆祝四十年的伙伴关系。我们作为ahk只做了三十年。尽管如此,我认为这也是一个很好的机会来感谢我们的前任,他们为这一伙伴关系付出了如此多的努力。这种伙伴关系不仅存在于纸面上,而且存在于实践中。我认为现在是我们塑造未来四十年的时候了,我认为这可能比过去四十年要困难一些。因为我们变了。中国变了。我们会不断地改变。然而,我们一次又一次地设法找到并利用共同的潜力。由于政治领导人今天在这里向我们发出了明确的信号,即伙伴关系符合我们双方的利益,我还要指出,你,总理,带来了创新的公司,他们表现出愿意参与这个地区,这个地区,寻找市场潜力,不仅谈论潜力,而且实施潜力。作为ahk,我们已经帮助了三十年,当然还有我们在德国的组织,工商会,尽我们所能支持德国公司。eben-partner to find。我很高兴你今天发起了这个会议,在那里我们的公司可以与中国公司见面,在那里他们可以互相交谈。他们可以达成交易的地方,因为我相信我们都同意,未来四十年,只有我们继续好好交谈,好好合作,好好做生意,才会好起来。我祝愿所有与会者今天取得圆满成功,并祝愿会议取得圆满成功。谢谢,谢谢
'''
dmp = diff_match_patch.diff_match_patch()
diffs = dmp.diff_main(text1, text2)
print(diffs)
a="<td>"
b="<td>"
for i in diffs:if i[0]==0:a+=i[1]b+=i[1]if i[0]==-1:a+='<span class="diff_chg">{}</span>'.format(i[1])if i[0]==1:b+='<span class="diff_chg">{}</span>'.format(i[1])
a+="</td>"
b+="</td>"one='<tr><td class="diff_next" id="difflib_chg_to0__0"><a href="#difflib_chg_to0__top">t</a></td><td class="diff_header" id="from0_1">1</td>{}<td class="diff_next"><a href="#difflib_chg_to0__top">t</a></td><td class="diff_header" id="to0_1">1</td>{}</tr>'.format(a,b)html_cont=html_cont.replace("</tbody>",one+"</tbody>")# 将HTML差异保存到文件中
with open('diff_output.html', 'w', encoding='utf-8') as f:f.write(html_cont)样例展示:

构建html格式
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN""http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"><html><head><meta http-equiv="Content-Type"content="text/html; charset=utf-8" /><title></title><style type="text/css">table.diff {font-family:Courier; border:medium;}.diff_header {background-color:#e0e0e0}td.diff_header {text-align:right}.diff_next {background-color:#c0c0c0}.diff_add {background-color:#aaffaa}.diff_chg {background-color:#ffff77}.diff_sub {background-color:#ffaaaa}table.diff td {word-wrap: break-word;white-space: pre-wrap;max-width: 100%;}</style>
</head><body><table class="diff" id="difflib_chg_to0__top"cellspacing="0" cellpadding="0" rules="groups" ><colgroup></colgroup> <colgroup></colgroup> <colgroup></colgroup><colgroup></colgroup> <colgroup></colgroup> <colgroup></colgroup><tbody></tbody></table><table class="diff" summary="Legends"><tr> <th colspan="2"> Legends </th> </tr><tr> <td> <table border="" summary="Colors"><tr><th> Colors </th> </tr><tr><td class="diff_add"> Added </td></tr><tr><td class="diff_chg">Changed</td> </tr><tr><td class="diff_sub">Deleted</td> </tr></table></td><td> <table border="" summary="Links"><tr><th colspan="2"> Links </th> </tr><tr><td>(f)irst change</td> </tr><tr><td>(n)ext change</td> </tr><tr><td>(t)op</td> </tr></table></td> </tr></table>
</body></html>3.当前以difflib.SequenceMatcher演示
#coding:utf-8
import difflib, re
def read(file):with open(file, 'r', encoding="utf-8") as fr:content=fr.read()return content
html_cont = read("diff_baseline.html")
# 比较两个文本差异点
def compare_text_index(text1, text2):# 创建SequenceMatcher对象matcher = difflib.SequenceMatcher(a=text1, b=text2)# 获取差异报告diff_report = matcher.get_opcodes()index_info=[]# 检查差异报告中是否存在关键词错误for tag, i1, i2, j1, j2 in diff_report:index_info.append([tag, i1, i2, j1, j2])return index_infotext1 = '''尊敬的韦尔总理、汉恩党委书记、王省长、总领事、女士们和先生们,今天我非常高兴与你们共同庆祝40年的伙伴关系。我们作为AHK只做了三十年。我认为这是一个感谢前任的机会,他们为这种伙伴关系付出了很多努力。这种伙伴关系不仅存在于纸面上,还存在于实践中。我认为目前是我们塑造未来40年的关键时期,这可能比过去40年更加困难。因为中国在不断变化,所以我们设法找到并利用共同的潜力。今天政治领导人在这里向我们发出明确信号,即伙伴关系符合双方利益。我还要指出,总理。创新的公司表示愿意参与这个地区的发展,寻找并实施市场潜力。作为AHK,我们已经帮助了30年,同时我们在德国的组织和工商会也在尽我们所能支持德国公司。说话人E:我很高兴你今天发起了这个会议,我们的公司可以与中国公司见面,在那里他们可以互相交谈。他们可以达成交易的地方,我相信我们都同意,未来40年只有我们继续好好交谈、合作、做生意才会越来越好。我祝愿所有与会者和会议取得圆满成功。谢谢。
'''text2 = '''尊敬的韦尔总理,尊敬的汉恩党委书记,王省长,总领事,女士们,先生们,今天我很高兴与你们一起庆祝四十年的伙伴关系。我们作为ahk只做了三十年。尽管如此,我认为这也是一个很好的机会来感谢我们的前任,他们为这一伙伴关系付出了如此多的努力。这种伙伴关系不仅存在于纸面上,而且存在于实践中。我认为现在是我们塑造未来四十年的时候了,我认为这可能比过去四十年要困难一些。因为我们变了。中国变了。我们会不断地改变。然而,我们一次又一次地设法找到并利用共同的潜力。由于政治领导人今天在这里向我们发出了明确的信号,即伙伴关系符合我们双方的利益,我还要指出,你,总理,带来了创新的公司,他们表现出愿意参与这个地区,这个地区,寻找市场潜力,不仅谈论潜力,而且实施潜力。作为ahk,我们已经帮助了三十年,当然还有我们在德国的组织,工商会,尽我们所能支持德国公司。eben-partner to find。我很高兴你今天发起了这个会议,在那里我们的公司可以与中国公司见面,在那里他们可以互相交谈。他们可以达成交易的地方,因为我相信我们都同意,未来四十年,只有我们继续好好交谈,好好合作,好好做生意,才会好起来。我祝愿所有与会者今天取得圆满成功,并祝愿会议取得圆满成功。谢谢,谢谢
'''
a="<td>"
b="<td>"
chayi=compare_text_index(text1, text2)
for effect in chayi:print(effect)if effect[0]=="equal":a+=text1[effect[1]:effect[2]]b+=text2[effect[3]:effect[4]]if effect[0]=="replace":# a+=text1[effect[1]:effect[2]]# b+=text2[effect[3]:effect[4]]a+='<span class="diff_chg">{}</span>'.format(text1[effect[1]:effect[2]])b += '<span class="diff_chg">{}</span>'.format(text2[effect[3]:effect[4]])if effect[0]=="insert":# a+=text1[effect[1]:effect[2]]# b+=text2[effect[3]:effect[4]]a += '<span class="diff_add">{}</span>'.format(text1[effect[1]:effect[2]])b += '<span class="diff_add">{}</span>'.format(text2[effect[3]:effect[4]])if effect[0]=="delete":# a+=text1[effect[1]:effect[2]]# b+=text2[effect[3]:effect[4]]a += '<span class="diff_sub">{}</span>'.format(text1[effect[1]:effect[2]])b += '<span class="diff_sub">{}</span>'.format(text2[effect[3]:effect[4]])a+="</td>"
b+="</td>"one='<tr><td class="diff_next" id="difflib_chg_to0__0"><a href="#difflib_chg_to0__top">t</a></td><td class="diff_header" id="from0_1">1</td>{}<td class="diff_next"><a href="#difflib_chg_to0__top">t</a></td><td class="diff_header" id="to0_1">1</td>{}</tr>'.format(a,b)html_cont=html_cont.replace("</tbody>",one+"</tbody>")# 将HTML差异保存到文件中
with open('difflib_output.html', 'w', encoding='utf-8') as f:f.write(html_cont)
案例展示:

4.同理将多个文本按行比对:
#coding:utf-8
import diff_match_patch
def read(file):with open(file, 'r', encoding="utf-8") as fr:content=fr.read()return contenthtml_cont = read("diff_baseline.html")text11 = read("text1.txt").splitlines(keepends=True)text22 = read("text2.txt").splitlines(keepends=True)one=""
for id,text1 in enumerate(text11):text2=text22[id]dmp = diff_match_patch.diff_match_patch()diffs = dmp.diff_main(text1, text2)if id==0:a="<td>"b="<td>"for i in diffs:if i[0]==0:a+=i[1]b+=i[1]if i[0]==-1:a+='<span class="diff_chg">{}</span>'.format(i[1])if i[0]==1:b+='<span class="diff_chg">{}</span>'.format(i[1])a+="</td>"b+="</td>"print(a)print(b)one+='<tr><td class="diff_next" id="difflib_chg_to0__0"><a href="#difflib_chg_to0__top">t</a></td><td class="diff_header" id="from0_1">1</td>{}<td class="diff_next"><a href="#difflib_chg_to0__top">t</a></td><td class="diff_header" id="to0_1">1</td>{}</tr>'.format(a,b)if id>0:a = "<td>"b = "<td>"for i in diffs:if i[0] == 0:a += i[1]b += i[1]if i[0] == -1:a += '<span class="diff_chg">{}</span>'.format(i[1])if i[0] == 1:b += '<span class="diff_chg">{}</span>'.format(i[1])a += "</td>"b += "</td>"print(a)print(b)one += '<tr><td class="diff_next"></td><td class="diff_header" id="from0_{}">{}</td>{}<td class="diff_next"></td><td class="diff_header" id="to0_{}">{}</td>{}</tr>'.format(id+1,id+1,a,id+1,id+1, b)html_cont=html_cont.replace("</tbody>",one+"</tbody>")# 将HTML差异保存到文件中
with open('diff_output1.html', 'w', encoding='utf-8') as f:f.write(html_cont)#coding:utf-8
import diff_match_patch,difflib
def read(file):with open(file, 'r', encoding="utf-8") as fr:content=fr.read()return content
# 比较两个文本差异点
def compare_text_index(text1, text2):# 创建SequenceMatcher对象matcher = difflib.SequenceMatcher(a=text1, b=text2)# 获取差异报告diff_report = matcher.get_opcodes()index_info=[]# 检查差异报告中是否存在关键词错误for tag, i1, i2, j1, j2 in diff_report:index_info.append([tag, i1, i2, j1, j2])return index_infohtml_cont = read("diff_baseline.html")text11 = read("text1.txt").splitlines(keepends=True)text22 = read("text2.txt").splitlines(keepends=True)one=""
for id,text1 in enumerate(text11):text2=text22[id]chayi=compare_text_index(text1, text2)if id==0:a="<td>"b="<td>"for effect in chayi:print(effect)if effect[0] == "equal":a += text1[effect[1]:effect[2]]b += text2[effect[3]:effect[4]]if effect[0] == "replace":# a+=text1[effect[1]:effect[2]]# b+=text2[effect[3]:effect[4]]a += '<span class="diff_chg">{}</span>'.format(text1[effect[1]:effect[2]])b += '<span class="diff_chg">{}</span>'.format(text2[effect[3]:effect[4]])if effect[0] == "insert":# a+=text1[effect[1]:effect[2]]# b+=text2[effect[3]:effect[4]]a += '<span class="diff_add">{}</span>'.format(text1[effect[1]:effect[2]])b += '<span class="diff_add">{}</span>'.format(text2[effect[3]:effect[4]])if effect[0] == "delete":# a+=text1[effect[1]:effect[2]]# b+=text2[effect[3]:effect[4]]a += '<span class="diff_sub">{}</span>'.format(text1[effect[1]:effect[2]])b += '<span class="diff_sub">{}</span>'.format(text2[effect[3]:effect[4]])a+="</td>"b+="</td>"print(a)print(b)one+='<tr><td class="diff_next" id="difflib_chg_to0__0"><a href="#difflib_chg_to0__top">t</a></td><td class="diff_header" id="from0_1">1</td>{}<td class="diff_next"><a href="#difflib_chg_to0__top">t</a></td><td class="diff_header" id="to0_1">1</td>{}</tr>'.format(a,b)if id>0:a = "<td>"b = "<td>"for effect in chayi:print(effect)if effect[0] == "equal":a += text1[effect[1]:effect[2]]b += text2[effect[3]:effect[4]]if effect[0] == "replace":# a+=text1[effect[1]:effect[2]]# b+=text2[effect[3]:effect[4]]a += '<span class="diff_chg">{}</span>'.format(text1[effect[1]:effect[2]])b += '<span class="diff_chg">{}</span>'.format(text2[effect[3]:effect[4]])if effect[0] == "insert":# a+=text1[effect[1]:effect[2]]# b+=text2[effect[3]:effect[4]]a += '<span class="diff_add">{}</span>'.format(text1[effect[1]:effect[2]])b += '<span class="diff_add">{}</span>'.format(text2[effect[3]:effect[4]])if effect[0] == "delete":# a+=text1[effect[1]:effect[2]]# b+=text2[effect[3]:effect[4]]a += '<span class="diff_sub">{}</span>'.format(text1[effect[1]:effect[2]])b += '<span class="diff_sub">{}</span>'.format(text2[effect[3]:effect[4]])a += "</td>"b += "</td>"print(a)print(b)one += '<tr><td class="diff_next"></td><td class="diff_header" id="from0_{}">{}</td>{}<td class="diff_next"></td><td class="diff_header" id="to0_{}">{}</td>{}</tr>'.format(id+1,id+1,a,id+1,id+1, b)html_cont=html_cont.replace("</tbody>",one+"</tbody>")# 将HTML差异保存到文件中
with open('diff_output.html', 'w', encoding='utf-8') as f:f.write(html_cont)相关文章:
使用difflib实现文件差异比较用html显示
1.默认方式,其中加入文本过长,需要换行,因此做 contenthtml_output.replace(</style>,table.diff td {word-wrap: break-word;white-space: pre-wrap;max-width: 100%;}</style>),添加换行操作 ps:当前te…...

【文末附gpt升级秘笈】AI热潮降温与AGI场景普及的局限性
AI热潮降温与AGI场景普及的局限性 摘要: 随着人工智能(AI)技术的迅猛发展,AI热一度席卷全球,引发了广泛的关注和讨论。然而,近期一些学者和行业专家对AI的发展前景提出了质疑,认为AI热潮将逐渐…...

Vue待学习
整个渲染过程了解 Vue实例?Vue模板?渲染函数render()?虚拟DOM VNode?模板编译器?diff算法 CSS相关 CSS高级学习?过渡? 待熟悉掌握 Vue-router?VueX?Vue-Cli、Webpack和…...

TOP150-LC88
/*给你两个按 非递减顺序 排列的整数数组 nums1 和 nums2,另有两个整数 m 和 n ,分别表示 nums1 和 nums2 中的元素数目。请你 合并 nums2 到 nums1 中,使合并后的数组同样按 非递减顺序 排列。注意:最终,合并后数组不…...
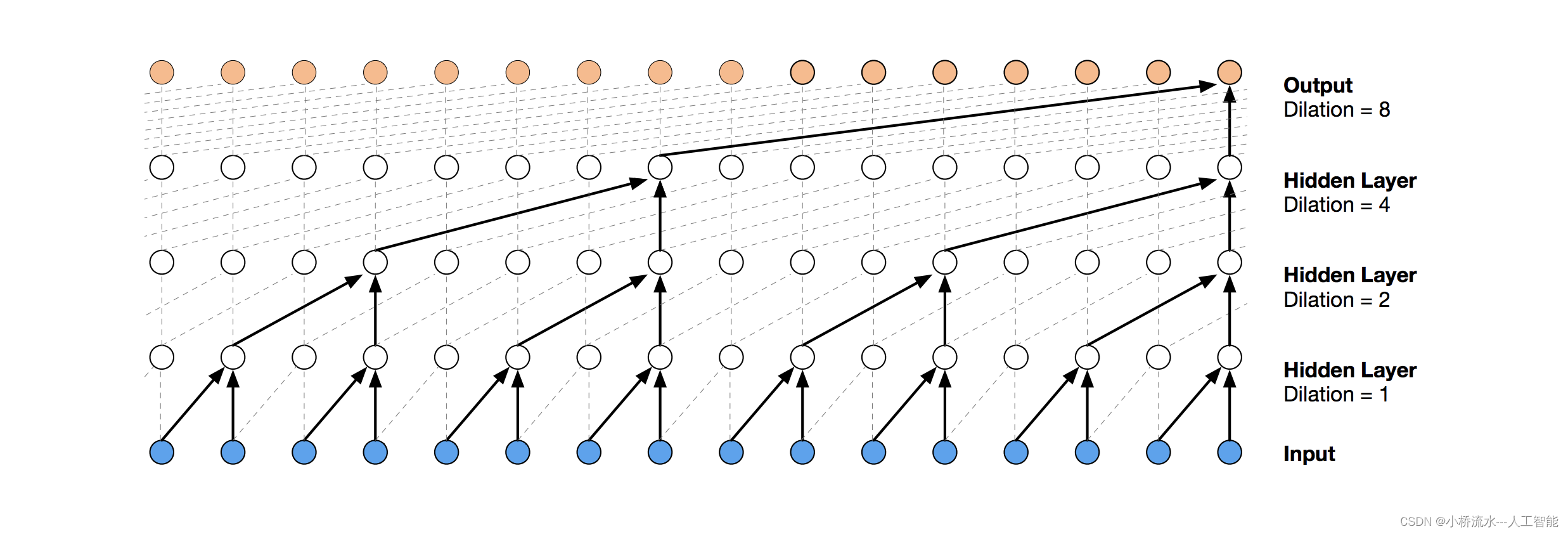
使用Python和TCN进行时间序列预测:一个完整的实战示例
使用Python和TCN进行时间序列预测:一个完整的实战示例 时间卷积网络(TCN)已被证明在处理序列数据方面表现出色,尤其是在需要捕获长期依赖关系的任务中。在本文中,我们将通过一个简单的例子,展示如何使用Py…...
如何用R语言ggplot2画高水平期刊散点图
文章目录 前言一、数据集二、ggplot2画图1、全部代码2、细节拆分1)导包2)创建图形对象3)主题设置4)轴设置5)图例设置6)散点颜色7)保存图片 前言 一、数据集 数据下载链接见文章顶部 处理前的数据…...

Python基于 Jupyter Notebook 的图形可视化工具库之ipysigma使用详解
概要 在数据科学和网络分析中,图(Graph)结构是一种常用的数据结构,用于表示实体及其关系。为了方便图数据的可视化和交互操作,ipysigma 提供了一个基于 Jupyter Notebook 的图形可视化工具。通过 ipysigma,用户可以在 Jupyter Notebook 中创建、编辑和展示图结构,方便进…...

四叉树和KD树
1. 简介 四叉树和KD树都是用于空间数据索引和检索的树状数据结构。它们通过将空间递归地划分为更小的区域,并存储每个区域内的点,来实现快速搜索和范围查询。 2. 四叉树 2.1 定义 四叉树是一种树状数据结构,它将二维空间递归地划分为四个…...

C语言中结构体使用.与->访问成员变量的区别
文章目录 前言点运算符(.)箭头运算符(->)总结 前言 在C语言中,. 和 -> 都是用来访问结构体成员的运算符,但它们的使用场景和含义有所不同。 提示:以下是本篇文章正文内容,下面…...

计算机二级Access选择题考点
在Access中,若要使用一个字段保存多个图像、图表、文档等文件,应该设置的数据类型是附件。在“销售表"中有字段:单价、数量、折扣和金额。其中,金额单价x数量x折扣,在建表时应将字段"金额"的数据类型定义为计算。若…...

人工智能历史与现状
1 人工智能历史与现状 1.1 人工智能的概念和起源 1.1.1 人工智能的概念 人工智能 (Artificial Intelligence ,AI)是一门研究如何使计算机 能够模拟人类智能行为的科学和技术,目标在于开发能够感知、理解、 学习、推理、决策和解决问题的智能机器。人工智能的概念主要包含 以…...

【git使用一】windows下git下载、安装和卸载
目录 (1)下载安装包 (2)安装git (3)安装验证 (4)卸载git (1)下载安装包 官网下载地址:Git 国内镜像下载地址:CNPM Binaries Mir…...

JVM 类加载器的工作原理
JVM 类加载器的工作原理 类加载器(ClassLoader)是一个用于加载类文件的子系统,负责将字节码文件(.class 文件)加载到 JVM 中。Java 类加载器允许 Java 应用程序在运行时动态地加载、链接和初始化类。 2. 类加载器的工…...

ARM Cortex-M4 CPU指令大全:作用、原理与实例
引言 在计算机系统中,CPU(中央处理器)是执行各种指令的核心部件。ARM Cortex-M4是广泛应用于嵌入式系统中的一款处理器,其指令集架构(ISA)基于ARMv7-M。本文将介绍ARM Cortex-M4处理器中的常见指令&#x…...

Mysql学习(九)——存储引擎
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 七、存储引擎7.1 MySQL体系结构7.2 存储引擎简介7.3 存储引擎特点7.4 存储引擎选择7.5 总结 七、存储引擎 7.1 MySQL体系结构 连接层:最上层是一些客户…...
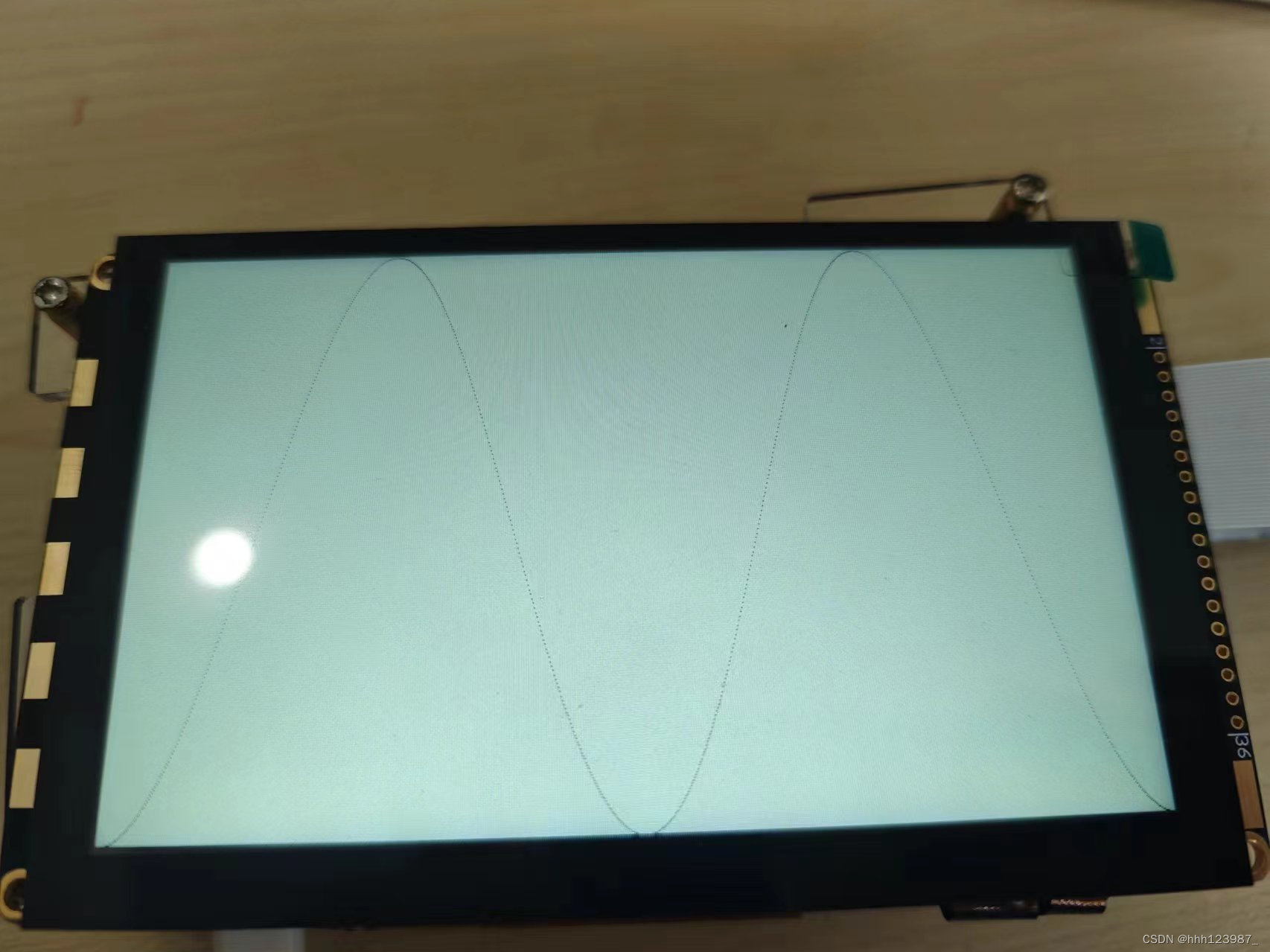
TFT屏幕波形显示
REVIEW 关于TFT显示屏,之前已经做过彩条显示: TFT显示屏驱动_tft驱动-CSDN博客 关于ROM IP核,以及coe文件生成: FPGA寄存器 Vivado IP核_fpga寄存器资源-CSDN博客 1. TFT屏幕ROM显示正弦波 ①生成coe文件 %% sin-cos wave dat…...
服务器无法远程桌面连接不上的问题排查与解决方案
一、问题概述 当尝试使用远程桌面协议(RDP)连接至服务器时,如果连接失败,这通常意味着存在一些配置问题、网络问题或服务器本身的问题。此类问题对于管理员而言,需要系统地进行排查和解决。 二、排查步骤 1. 检查网…...

JAVA面试题整理——内存溢出与内存泄露的区别与联系
内存溢出与内存泄露的区别与联系 在前面jvm学习整理的时候其实用过一个简单的例子了解过内存溢出,在jvm内存模型章节下,大家有兴趣的可以去看看:JVM初学 GC_knowwait的博客-CSDN博客 内存溢出 内存溢出(out of memory)…...

L50--- 104. 二叉树的最大深度(深搜)---Java版
1.题目描述 二叉树的 最大深度 是指从根节点到最远叶子节点的最长路径上的节点数。 2.思路 这个二叉树的结构如下: 根节点 1 左子节点 2 右子节点 3 左子节点 4 计算过程 从根节点 1 开始计算: 计算左子树的最大深度: 根节点 2…...

Linux 中 “ 磁盘、进程和内存 ” 的管理
在linux虚拟机中也有磁盘、进程、内存的存在。第一步了解一下磁盘 一、磁盘管理 (1.1)磁盘了解 track( 磁道 ) :就是磁盘上的同心圆,从外向里,依次排序1号,2号磁盘........等等。…...

OpenClaw技能扩展实战:安装Phi-3-vision-128k-instruct专用图文处理模块
OpenClaw技能扩展实战:安装Phi-3-vision-128k-instruct专用图文处理模块 1. 为什么需要专用技能模块? 上周我在整理技术文档时遇到一个典型场景:需要将十几份混杂着截图和文字说明的会议纪要,自动转换成结构化的Markdown文件。当…...

OpenClaw日志分析:千问3.5-35B-A3B-FP8任务执行问题定位
OpenClaw日志分析:千问3.5-35B-A3B-FP8任务执行问题定位 1. 问题背景与日志分析的价值 上周我在尝试用OpenClaw自动化处理一批技术文档时,遇到了任务频繁中断的问题。当时对接的是千问3.5-35B-A3B-FP8模型,系统提示"模型响应异常"…...

Windows平台OpenClaw部署:百川2-13B-4bits量化版调用详解
Windows平台OpenClaw部署:百川2-13B-4bits量化版调用详解 1. 为什么选择这个组合? 去年冬天,当我第一次尝试在Windows笔记本上部署本地AI助手时,遇到了显存不足的难题。我的GTX 3060显卡根本无法承载常规的13B模型,直…...

OpenClaw备份恢复:千问3.5-35B-A3B-FP8配置迁移指南
OpenClaw备份恢复:千问3.5-35B-A3B-FP8配置迁移指南 1. 为什么需要备份OpenClaw配置 上周我的开发机突然硬盘故障,不得不重装系统。当我准备重新部署OpenClaw时,突然意识到一个严重问题——过去三个月精心调试的千问3.5模型配置、飞书机器人…...

新手入门:零基础借助快马生成你的第一个openmaic网页版调用程序
今天想和大家分享一个特别适合新手入门的实践项目——如何借助InsCode(快马)平台快速生成你的第一个openmaic网页版调用程序。作为一个刚接触AI开发的新手,我最初看到各种API文档和代码示例时也是一头雾水,但通过这个可视化工具,居然半小时就…...

嵌入式开发中数据结构的优化与应用实践
1. 数据结构在嵌入式开发中的核心价值作为一名在嵌入式领域摸爬滚打十年的老兵,我深刻体会到数据结构就像瑞士军刀里的各种工具——选对工具能让工作事半功倍。在资源受限的MCU环境中,一个精心选择的数据结构可能意味着程序能否流畅运行和内存是否会爆掉…...

Omni-Vision Sanctuary 企业级部署架构设计:高可用与弹性伸缩
Omni-Vision Sanctuary 企业级部署架构设计:高可用与弹性伸缩 1. 企业级AI部署面临的挑战 当企业决定在生产环境中部署Omni-Vision Sanctuary这类AI服务时,通常会遇到几个关键挑战。首先是服务可用性问题,任何计划外停机都可能直接影响业务…...

从零到专业:League Director 让你的英雄联盟回放变成电影级大片
从零到专业:League Director 让你的英雄联盟回放变成电影级大片 【免费下载链接】leaguedirector League Director is a tool for staging and recording videos from League of Legends replays 项目地址: https://gitcode.com/gh_mirrors/le/leaguedirector …...

text2vec-base-chinese终极指南:如何用768维向量彻底改变中文语义理解
text2vec-base-chinese终极指南:如何用768维向量彻底改变中文语义理解 【免费下载链接】text2vec-base-chinese 项目地址: https://ai.gitcode.com/hf_mirrors/ai-gitcode/text2vec-base-chinese 还在为中文文本的语义匹配而头疼吗?传统的基于关…...

C语言基础:LiuJuan20260223Zimage嵌入式开发入门
C语言基础:LiuJuan20260223Zimage嵌入式开发入门 1. 学习目标与前置知识 如果你是刚开始接触嵌入式开发的C语言初学者,这篇文章就是为你准备的。我们将从最基础的C语言语法开始,一步步带你了解如何在嵌入式环境中使用C语言进行开发。不需要…...