ccc-pytorch-LSTM(8)
文章目录
- 一、LSTM简介
- 二、LSTM中的核心结构
- 三、如何解决RNN中的梯度消失/爆炸问题
- 四、情感分类实战(google colab)
一、LSTM简介
LSTM(long short-term memory)长短期记忆网络,RNN的改进,克服了RNN中“记忆低下”的问题。通过“门”结构实现信息的添加和移除,通过记忆元将序列处理过程中的相关信息一直传递下去,经典结构如下:
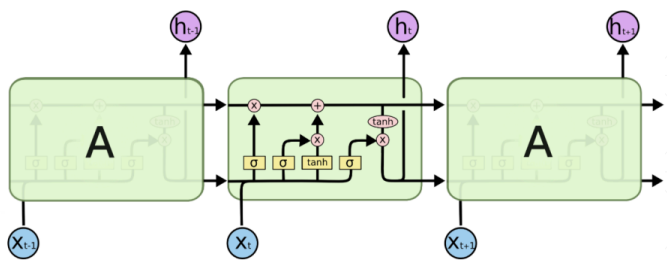

二、LSTM中的核心结构
记忆元(memory cell)-长期记忆:
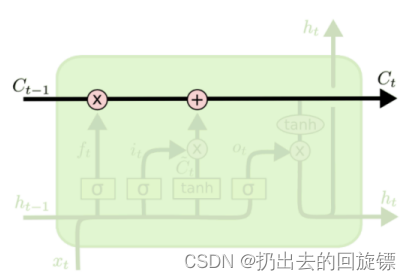
就像一个cell一样,信息通过这条只有少量线性交互的线传递。传递过程中有3种“门”结构可以告诉它该学习或者保存哪些信息
三个门结构-短期记忆
遗忘门:用来决定当前状态哪些信息被移除
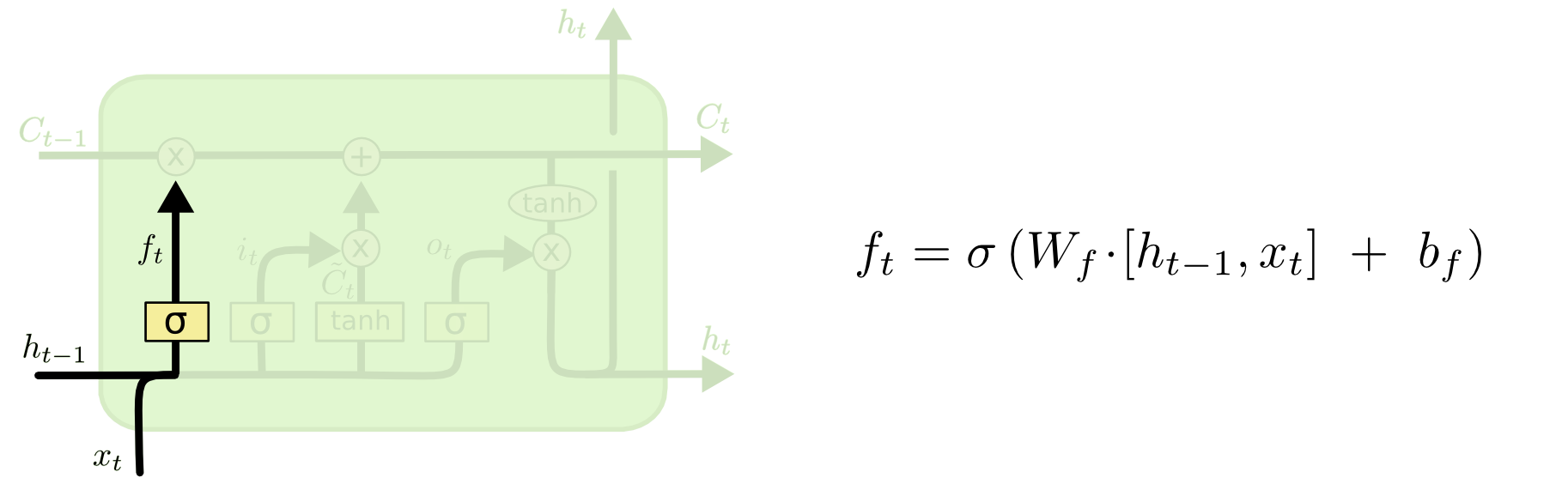
输入门:决定放入哪些信息到细胞状态
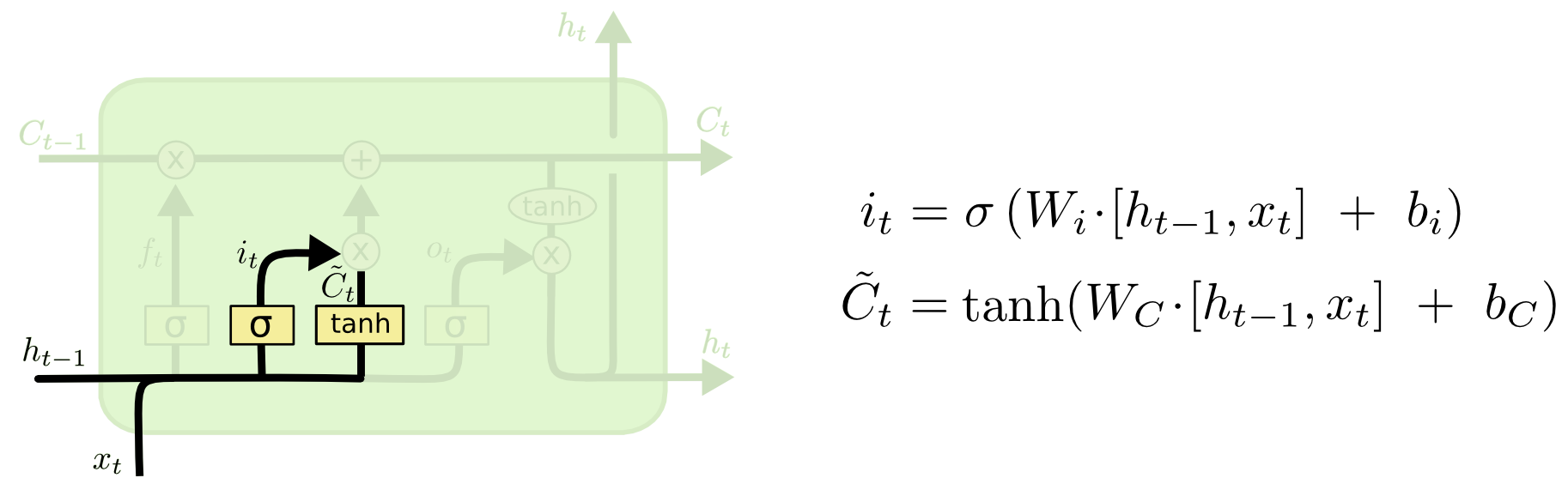
输出门:决定哪些信息用于输出
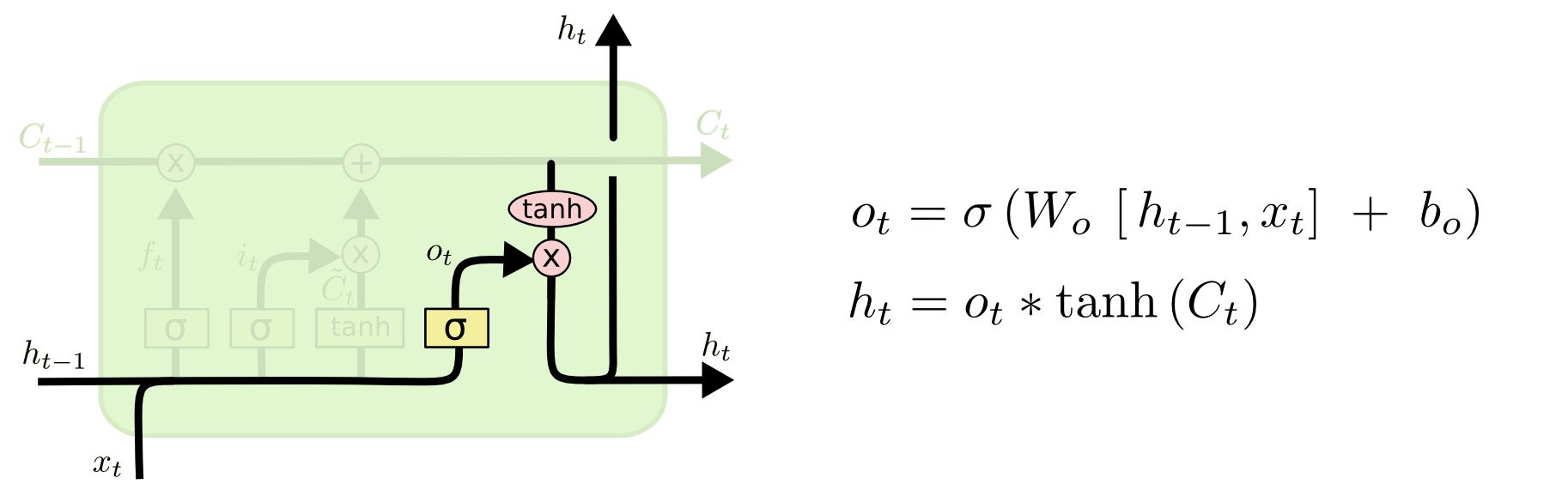
细节注意:
- 新的细胞状态只需要遗忘门和输入门就可以更新,公式为:Ct=ft∗Ct−1+it∗Ct~C_t=f_t*C_{t-1}+i_t* \tilde{C_t}Ct=ft∗Ct−1+it∗Ct~(注意所有的∗*∗都表示Hadamard 乘积)
- 只有隐状态h_t会传递到输出层,记忆元完全属于内部信息,不可手动修改
三、如何解决RNN中的梯度消失/爆炸问题
解决是指很大程度上缓解,不是让它彻底消失。先解释RNN为什么会有这些问题:
∂Lt∂U=∑k=0t∂Lt∂Ot∂Ot∂St(∏j=k+1t∂Sj∂Sj−1)∂Sk∂U∂Lt∂W=∑k=0t∂Lt∂Ot∂Ot∂St(∏j=k+1t∂Sj∂Sj−1)∂Sk∂W\begin{aligned} &\frac{\partial L_t}{\partial U}= \sum_{k=0}^{t}\frac{\partial L_t}{\partial O_t}\frac{\partial O_t}{\partial S_t}(\prod_{j=k+1}^{t}\frac{\partial S_j}{\partial S_{j-1}})\frac{\partial S_k}{\partial U}\\&\frac{\partial L_t}{\partial W}= \sum_{k=0}^{t}\frac{\partial L_t}{\partial O_t}\frac{\partial O_t}{\partial S_t}(\prod_{j=k+1}^{t}\frac{\partial S_j}{\partial S_{j-1}})\frac{\partial S_k}{\partial W} \end{aligned} ∂U∂Lt=k=0∑t∂Ot∂Lt∂St∂Ot(j=k+1∏t∂Sj−1∂Sj)∂U∂Sk∂W∂Lt=k=0∑t∂Ot∂Lt∂St∂Ot(j=k+1∏t∂Sj−1∂Sj)∂W∂Sk(具体过程可以看这里)
上面是训练过程任意时刻更新W、U需要用到的求偏导的结果。实际使用会加上激活函数,通常为tanh、sigmoid等
tanh和其导数图像如下

sigmoid和其导数如下
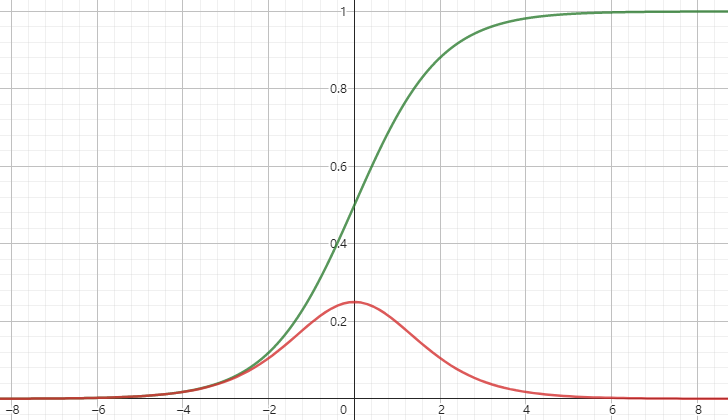
这些激活函数的导数都比1要小,又因为∏j=k+1t∂Sj∂Sj−1=∏j=k+1ttanh′(Ws)\prod_{j=k+1}^{t}\frac{\partial S_j}{\partial S_{j-1}}=\prod_{j=k+1}^{t}tanh'(W_s)∏j=k+1t∂Sj−1∂Sj=∏j=k+1ttanh′(Ws),所以当WsW_sWs过小过大就会分别造成梯度消失和爆炸的问题,特别是过小。
LSTM如何缓解
由链式法则和三个门的公式可以得到:
∂Ct∂Ct−1=∂Ct∂ft∂ft∂ht−1∂ht−1∂Ct−1+∂Ct∂it∂it∂ht−1∂ht−1∂Ct−1+∂Ct∂Ct~∂Ct~∂ht−1∂ht−1∂Ct−1+∂Ct∂Ct−1=Ct−1σ′(⋅)Wf∗ot−1tanh′(Ct−1)+Ct~σ′(⋅)Wi∗ot−1tanh′(Ct−1)+ittanh′(⋅)Wc∗ot−1tanh′(Ct−1)+ft\begin{aligned} &\frac{\partial C_t}{\partial C_{t-1}}\\&=\frac{\partial C_t}{\partial f_t}\frac{\partial f_t}{\partial h_{t-1}}\frac{\partial h_{t-1}}{\partial C_{t-1}}+\frac{\partial C_t}{\partial i_t}\frac{\partial i_t}{\partial h_{t-1}}\frac{\partial h_{t-1}}{\partial C_{t-1}}+\frac{\partial C_t}{\partial \tilde{C_t}}\frac{\partial \tilde{C_t}}{\partial h_{t-1}}\frac{\partial h_{t-1}}{\partial C_{t-1}}+\frac{\partial C_t}{\partial C_{t-1}}\\ &=C_{t-1}\sigma '(\cdot)W_f*o_{t-1}tanh'(C_{t-1})+\tilde{C_t}\sigma '(\cdot)W_i*o_{t-1}tanh'(C_{t-1})\\&+i_ttanh'(\cdot)W_c*o_{t-1}tanh'(C_{t-1})+f_t \end{aligned}∂Ct−1∂Ct=∂ft∂Ct∂ht−1∂ft∂Ct−1∂ht−1+∂it∂Ct∂ht−1∂it∂Ct−1∂ht−1+∂Ct~∂Ct∂ht−1∂Ct~∂Ct−1∂ht−1+∂Ct−1∂Ct=Ct−1σ′(⋅)Wf∗ot−1tanh′(Ct−1)+Ct~σ′(⋅)Wi∗ot−1tanh′(Ct−1)+ittanh′(⋅)Wc∗ot−1tanh′(Ct−1)+ft
- 由相乘变成了相加,不容易叠加
- sigmoid函数使单元间传递结果非常接近0或者1,使模型变成非线性,并且可以在学习过程中内部调整
四、情感分类实战(google colab)
环境和库:
!pip install torch
!pip install torchtext
!python -m spacy download en# K80 gpu for 12 hours
import torch
from torch import nn, optim
from torchtext import data, datasetsprint('GPU:', torch.cuda.is_available())torch.manual_seed(123)
加载数据集:
TEXT = data.Field(tokenize='spacy')
LABEL = data.LabelField(dtype=torch.float)
train_data, test_data = datasets.IMDB.splits(TEXT, LABEL)print(train_data.examples[15].text)
print(train_data.examples[15].label)
网络结构:
class RNN(nn.Module):def __init__(self, vocab_size, embedding_dim, hidden_dim):""""""super(RNN, self).__init__()# [0-10001] => [100]self.embedding = nn.Embedding(vocab_size, embedding_dim)# [100] => [256]self.rnn = nn.LSTM(embedding_dim, hidden_dim, num_layers=2, bidirectional=True, dropout=0.5)# [256*2] => [1]self.fc = nn.Linear(hidden_dim*2, 1)self.dropout = nn.Dropout(0.5)def forward(self, x):"""x: [seq_len, b] vs [b, 3, 28, 28]"""# [seq, b, 1] => [seq, b, 100]embedding = self.dropout(self.embedding(x))# output: [seq, b, hid_dim*2]# hidden/h: [num_layers*2, b, hid_dim]# cell/c: [num_layers*2, b, hid_di]output, (hidden, cell) = self.rnn(embedding)# [num_layers*2, b, hid_dim] => 2 of [b, hid_dim] => [b, hid_dim*2]hidden = torch.cat([hidden[-2], hidden[-1]], dim=1)# [b, hid_dim*2] => [b, 1]hidden = self.dropout(hidden)out = self.fc(hidden)return out
Embedding
rnn = RNN(len(TEXT.vocab), 100, 256)pretrained_embedding = TEXT.vocab.vectors
print('pretrained_embedding:', pretrained_embedding.shape)
rnn.embedding.weight.data.copy_(pretrained_embedding)
print('embedding layer inited.')optimizer = optim.Adam(rnn.parameters(), lr=1e-3)
criteon = nn.BCEWithLogitsLoss().to(device)
rnn.to(device)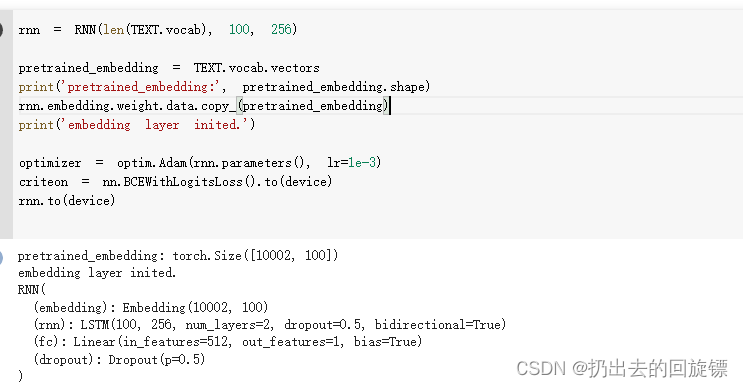
训练并测试
import numpy as npdef binary_acc(preds, y):"""get accuracy"""preds = torch.round(torch.sigmoid(preds))correct = torch.eq(preds, y).float()acc = correct.sum() / len(correct)return accdef train(rnn, iterator, optimizer, criteon):avg_acc = []rnn.train()for i, batch in enumerate(iterator):# [seq, b] => [b, 1] => [b]pred = rnn(batch.text).squeeze(1)# loss = criteon(pred, batch.label)acc = binary_acc(pred, batch.label).item()avg_acc.append(acc)optimizer.zero_grad()loss.backward()optimizer.step()if i%10 == 0:print(i, acc)avg_acc = np.array(avg_acc).mean()print('avg acc:', avg_acc)def eval(rnn, iterator, criteon):avg_acc = []rnn.eval()with torch.no_grad():for batch in iterator:# [b, 1] => [b]pred = rnn(batch.text).squeeze(1)#loss = criteon(pred, batch.label)acc = binary_acc(pred, batch.label).item()avg_acc.append(acc)avg_acc = np.array(avg_acc).mean()print('>>test:', avg_acc)for epoch in range(10):eval(rnn, test_iterator, criteon)train(rnn, train_iterator, optimizer, criteon)
最后得到的准确率结果如下:

完整colab链接:lstm
完整代码:
# -*- coding: utf-8 -*-
"""lstmAutomatically generated by Colaboratory.Original file is located athttps://colab.research.google.com/drive/1GX0Rqur8T45MSYhLU9MYWAbycfLH4-Fu
"""!pip install torch
!pip install torchtext
!python -m spacy download en# K80 gpu for 12 hours
import torch
from torch import nn, optim
from torchtext import data, datasetsprint('GPU:', torch.cuda.is_available())torch.manual_seed(123)TEXT = data.Field(tokenize='spacy')
LABEL = data.LabelField(dtype=torch.float)
train_data, test_data = datasets.IMDB.splits(TEXT, LABEL)print('len of train data:', len(train_data))
print('len of test data:', len(test_data))print(train_data.examples[15].text)
print(train_data.examples[15].label)# word2vec, glove
TEXT.build_vocab(train_data, max_size=10000, vectors='glove.6B.100d')
LABEL.build_vocab(train_data)batchsz = 30
device = torch.device('cuda')
train_iterator, test_iterator = data.BucketIterator.splits((train_data, test_data),batch_size = batchsz,device=device
)class RNN(nn.Module):def __init__(self, vocab_size, embedding_dim, hidden_dim):""""""super(RNN, self).__init__()# [0-10001] => [100]self.embedding = nn.Embedding(vocab_size, embedding_dim)# [100] => [256]self.rnn = nn.LSTM(embedding_dim, hidden_dim, num_layers=2, bidirectional=True, dropout=0.5)# [256*2] => [1]self.fc = nn.Linear(hidden_dim*2, 1)self.dropout = nn.Dropout(0.5)def forward(self, x):"""x: [seq_len, b] vs [b, 3, 28, 28]"""# [seq, b, 1] => [seq, b, 100]embedding = self.dropout(self.embedding(x))# output: [seq, b, hid_dim*2]# hidden/h: [num_layers*2, b, hid_dim]# cell/c: [num_layers*2, b, hid_di]output, (hidden, cell) = self.rnn(embedding)# [num_layers*2, b, hid_dim] => 2 of [b, hid_dim] => [b, hid_dim*2]hidden = torch.cat([hidden[-2], hidden[-1]], dim=1)# [b, hid_dim*2] => [b, 1]hidden = self.dropout(hidden)out = self.fc(hidden)return outrnn = RNN(len(TEXT.vocab), 100, 256)pretrained_embedding = TEXT.vocab.vectors
print('pretrained_embedding:', pretrained_embedding.shape)
rnn.embedding.weight.data.copy_(pretrained_embedding)
print('embedding layer inited.')optimizer = optim.Adam(rnn.parameters(), lr=1e-3)
criteon = nn.BCEWithLogitsLoss().to(device)
rnn.to(device)import numpy as npdef binary_acc(preds, y):"""get accuracy"""preds = torch.round(torch.sigmoid(preds))correct = torch.eq(preds, y).float()acc = correct.sum() / len(correct)return accdef train(rnn, iterator, optimizer, criteon):avg_acc = []rnn.train()for i, batch in enumerate(iterator):# [seq, b] => [b, 1] => [b]pred = rnn(batch.text).squeeze(1)# loss = criteon(pred, batch.label)acc = binary_acc(pred, batch.label).item()avg_acc.append(acc)optimizer.zero_grad()loss.backward()optimizer.step()if i%10 == 0:print(i, acc)avg_acc = np.array(avg_acc).mean()print('avg acc:', avg_acc)def eval(rnn, iterator, criteon):avg_acc = []rnn.eval()with torch.no_grad():for batch in iterator:# [b, 1] => [b]pred = rnn(batch.text).squeeze(1)#loss = criteon(pred, batch.label)acc = binary_acc(pred, batch.label).item()avg_acc.append(acc)avg_acc = np.array(avg_acc).mean()print('>>test:', avg_acc)for epoch in range(10):eval(rnn, test_iterator, criteon)train(rnn, train_iterator, optimizer, criteon)
相关文章:
ccc-pytorch-LSTM(8)
文章目录一、LSTM简介二、LSTM中的核心结构三、如何解决RNN中的梯度消失/爆炸问题四、情感分类实战(google colab)一、LSTM简介 LSTM(long short-term memory)长短期记忆网络,RNN的改进,克服了RNN中“记忆…...

教育小程序开发解决方案
如今无论是国家还是家庭对于教育的重视性也越来越高,都希望自己的孩子能够赢在起跑线上,但是因为工作的缘故许多家长并没有过多的精力去辅导孩子学习,再加上许多家长对于教育也并没有经验与技巧。而这些都充分体现了正确教育的重要性。 那么一…...

动态规划之股票问题大总结
参考资料:代码随想录 (programmercarl.com)一、只能买卖一次题目链接:121. 买卖股票的最佳时机 - 力扣(LeetCode)算法思想:设置两种状态:0表示已持有股票,1表示未持有股票1.dp[i][0]表示第i天已持有股票时&…...

我来跟你讲vue进阶
一、组件(重点) 组件(Component)是 Vue.js 最强大的功能之一。 组件可以扩展 HTML 元素,封装可重用的代码。 组件系统让我们可以用独立可复用的小组件来构建大型应用,几乎任意类型的应用的界面都可以抽象…...
E. Vlad and a Pair of Numbers)
#847(Div3)E. Vlad and a Pair of Numbers
原题链接: E. Vlad and a Pair of Numbers 题意: 题目有公式 a⊕b(ab)/2xa ⊕ b (a b) / 2 xa⊕b(ab)/2x, 给你的是 xxx,让输出一组满足题目要求的 a,ba,ba,b,没有就输出−1-1…...
怎么把pdf转换成图片?这个方法你值得拥有
想要高效率的工作,除了需要大家合理安排时间之外,一些能够辅助高效工作的工具也是必不可少的。就拿要把一份pdf文件转换成若干图片来说,如果不知道方法,找不到合适的转换工具,那么想要完成这一任务,势必要花…...

go语言使用append向二维数组添加一维数组
var ans [][]int ans append(ans, append([]int(nil), nums...))(正确写法)需要注意的是,为了避免对原切片造成影响,代码在将当前排列追加到结果数组 ans 时,使用了 append(ans, append([]int(nil), nums…)) 的方式…...

YOLOv5训练大规模的遥感实例分割数据集 iSAID从切图到数据集制作及训练
最近想训练遥感实例分割,纵观博客发现较少相关 iSAID数据集的切分及数据集转换内容,思来想去应该在繁忙之中抽出时间写个详细的教程。 iSAID数据集下载 iSAID数据集链接 下载上述数据集。 百度网盘中的train和val中包含了实例和语义分割标签。 上述…...
)
js学习5(函数)
目录 定义函数 函数的特性 使用函数模拟类 模拟私有属性和方法 闭包 函数特性利用 箭头函数 定义函数 function func1(name) { console.log(name); } func2 function (name) { console.log(name); } func3 function func0(name) { console.log(name); } co…...

用Qt画一个仪表盘
关于Qt Qt是一个跨平台的C图形用户界面应用程序框架,通过使用Qt,可以快速开发出跨平台的多平台应用程序,包括Windows、Mac OS X、Linux和其他Unix系统。Qt提供了强大的图形操作界面(GUI)程序开发和移植的能力…...
linux 端口查询命令
任何知识都是用进废退,有段时间没摸linux,这大脑里的知识点仿佛全部消失了,就无语。 索性,再写一篇记录,加强一下记忆,下次需要就看自己的资料好了。lsof命令Linux端口查询命令可以通过lsof实现:…...

C语言函数: 字符串函数及模拟实现strtok()、strstr()、strerror()
C语言函数: 字符串函数及模拟实现strtok()、strstr()、strerror() strstr()函数: 作用:字符串查找。在一串字符串中,查找另一串字符串是否存在。 形参: str2在str1中寻找。返回值是char*的指针 原理:如果在str1中找到了str2&…...

【学习笔记】人工智能哲学研究:《心智、语言和机器》
关于人工智能哲学,我曾在这篇文章里 【脑洞大开】从哲学角度看人工智能:介绍徐英瑾的《心智、语言和机器》 做过介绍。图片来源:http://product.dangdang.com/29419969.html在我完成了一些人工智能相关的工作以后,我再来分享《心智…...
设计模式之门面模式(外观模式)
目录 1.模式定义 2.应用场景 2.1 电源总开关例子 2.2 股民炒股场景 编辑 3. 实例如下 4. 门面模式的优缺点 传送门: 项目中用到的责任链模式 给对象讲工厂模式,必须易懂易会 策略模式,工作中你用上了吗? 1.模式定…...
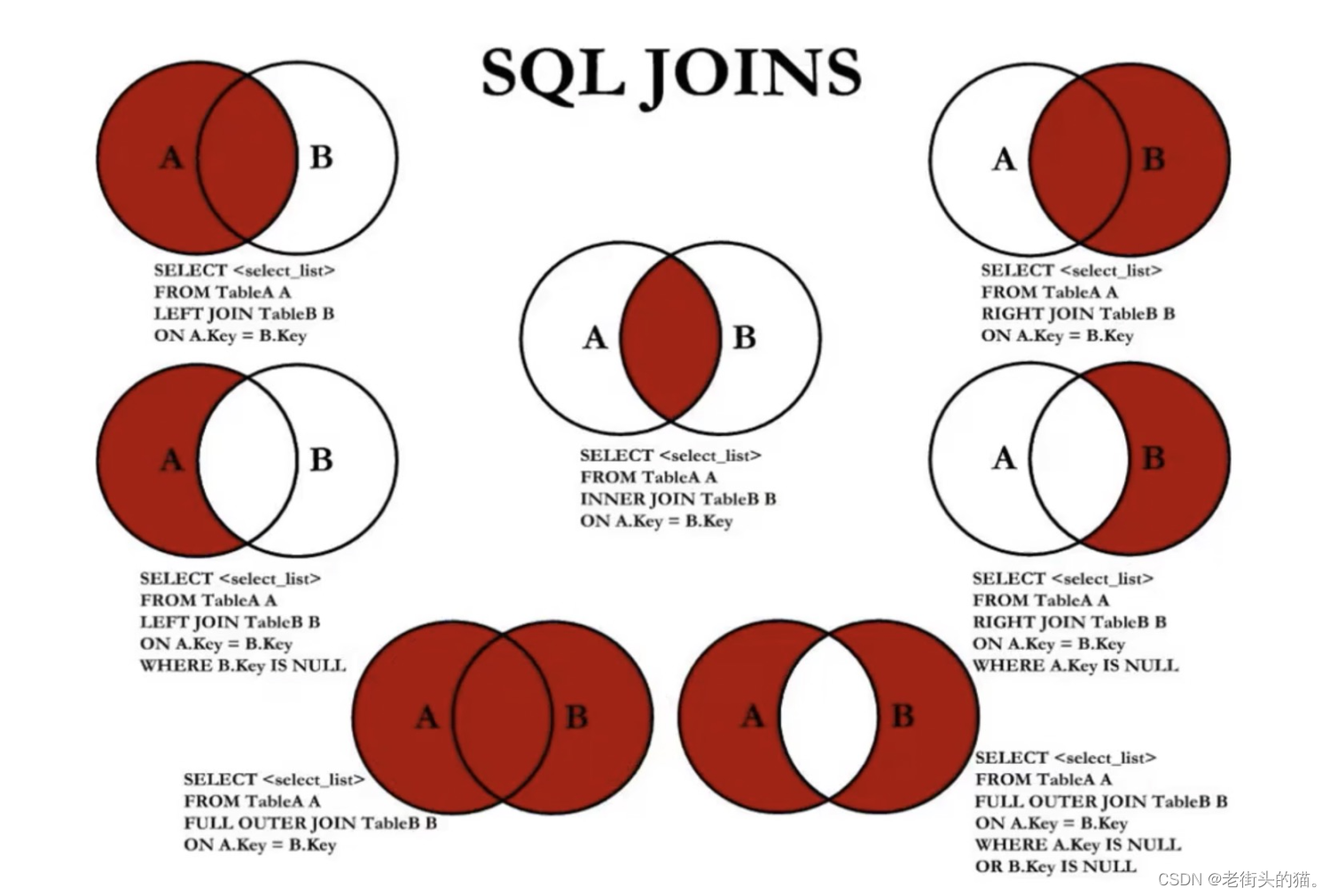
MySQL - 多表查询
目录1. 多表查询示例2. 多表查询分类2.1 等/非等值连接2.1.1 等值连接2.1.2非等值连接2.2 自然/非自然连接2.3 内/外连接2.3.1 内连接2.3.2 外连接3.UNION的使用3.1 合并查询结果3.1.1 UNION操作符3.1.2 UNION ALL操作符4. 7种JOIN操作5. join 多张表多表查询,也称为…...

自定义报表是什么?
自定义报表是指根据用户的需求和要求,自行设计和生成的报表。自定义报表可以根据用户的具体需求,选择需要的数据和指标,进行灵活的排列和组合,生成符合用户要求的报表。自定义报表可以帮助用户更好地了解业务情况,发现…...

windows安装docker-小白用【避坑】【伸手党福利】
目录实操开启 Hyper-V 和容器特性下载docker安装dockercmd中,使用命令测试是否成功报错解决办法:下载linux模拟器wsl:双击打开docker重新打开cmd,输入命令,成功显示sever和clinet实操 开启 Hyper-V 和容器特性 控制面…...
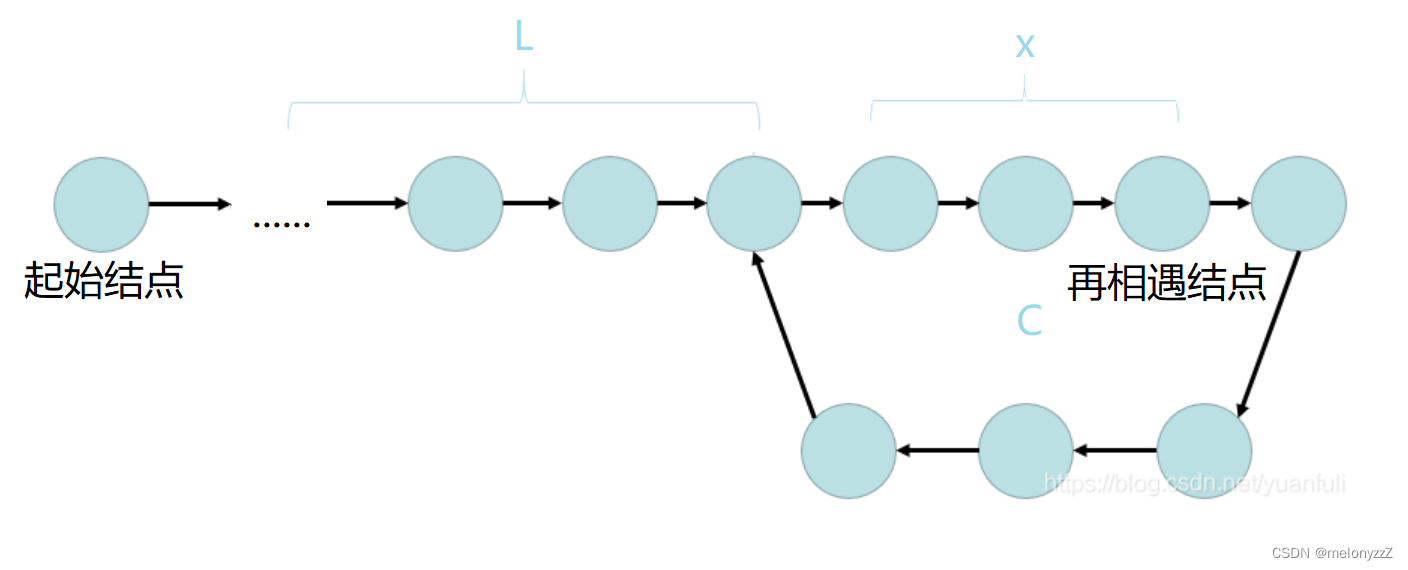
环形链表相关的练习
目录 一、相交链表 二、环形链表 三、环形链表 || 一、相交链表 给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。 图示两个链表在节点 c1 开始相交: 题目数据…...

C++ 提示对话框
头文件 #include<iostream>#include<cstdio> using namespace std; 函数格式 MessageBox( HWND hWnd, LPCTSTR lpText, LPCTSTR lpCaption, UINT uType) 参数 hWnd :此参数代表消息框拥有的窗口。如果为NULL,则消息框没有拥有窗口。 lp…...
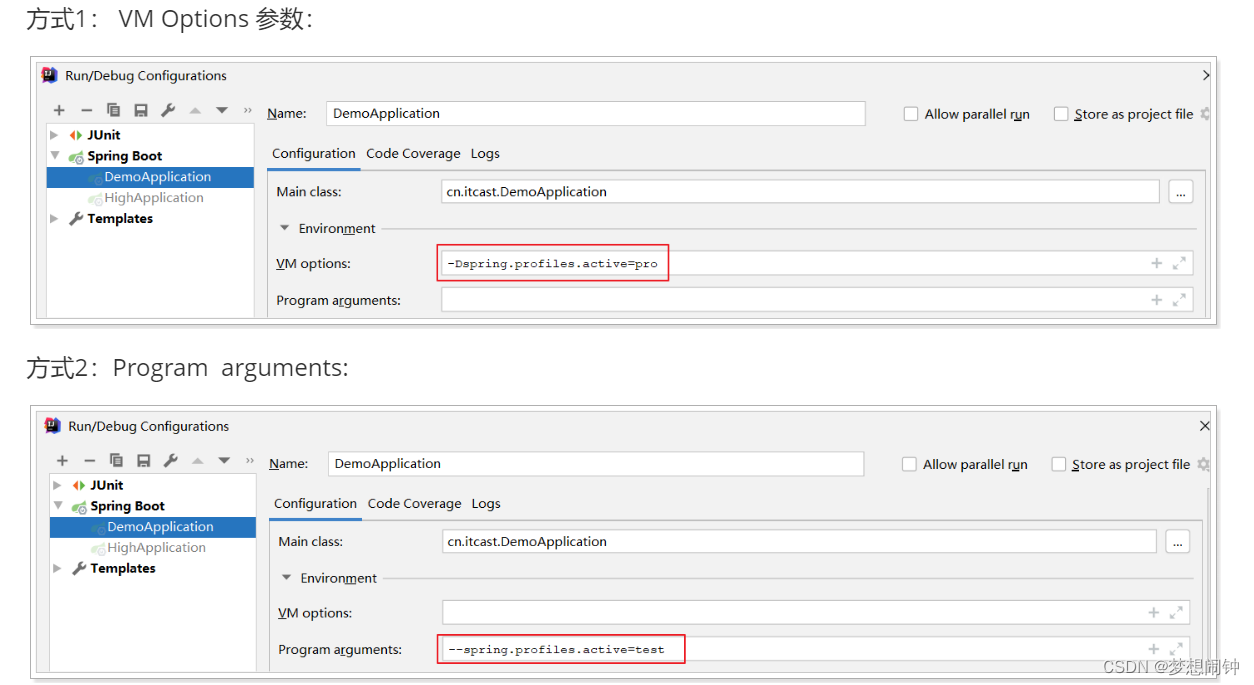
SprintBoot打包及profile文件配置
打成Jar包 需要添加打包组件将项目中的资源、配置、依赖包打到一个jar包中,可以使用maven的package;运行: java -jar xxx(jar包名) 操作步骤 第一步: 引入Spring Boot打包插件 <!--打包的插件--> <build><!--修改jar的名字--><fi…...

【深度解析】从 Antigravity 2.0 看 AI Agent 的产品化演进:动态子代理、项目工作区与多模型编排实战
摘要: Google Antigravity 2.0 的核心变化,不只是功能增加,而是把 AI Agent 从“对话工具”推进到“可编排的执行系统”。本文解析动态子代理、项目级工作区、后台任务与工具链设计,并给出基于 OpenAI 兼容接口的 Python 实战代码…...

2025_NIPS_Language Models Don‘t Always Say What They Think: Unfaithful Explanations in Chain-of-T...
文章主要内容与创新点总结 一、主要内容 该研究聚焦大语言模型(LLMs)的思维链(CoT)提示法,核心探讨CoT解释的“不忠实性”——即模型生成的分步推理过程可能无法真实反映其预测的底层逻辑,反而会系统性地误导用户。 研究背景:CoT提示法通过引导模型输出分步推理再给出…...

LiveSplit深度解析:构建专业级速度跑计时系统的核心技术架构
LiveSplit深度解析:构建专业级速度跑计时系统的核心技术架构 【免费下载链接】LiveSplit A sleek, highly customizable timer for speedrunners. 项目地址: https://gitcode.com/gh_mirrors/li/LiveSplit LiveSplit是一款为速度跑者设计的专业级计时软件&am…...

智慧树自动刷课插件:3分钟完成安装的终极学习效率工具
智慧树自动刷课插件:3分钟完成安装的终极学习效率工具 【免费下载链接】zhihuishu 智慧树刷课插件,自动播放下一集、1.5倍速度、无声 项目地址: https://gitcode.com/gh_mirrors/zh/zhihuishu 还在为智慧树平台繁琐的视频学习而烦恼吗?…...

ARM SVE存储指令ST1D与ST1H深度解析与优化
1. ARM SVE存储指令深度解析在ARMv8架构的可扩展向量扩展(SVE)指令集中,ST1D和ST1H指令扮演着关键角色。这些指令专为高效的内存存储操作设计,特别适合处理大规模数据集的场景。与传统的标量存储指令相比,它们能同时处理多个数据元素…...

从“佩戴感知”到“无感融入”:UWB vs 镜像视界——空间智能的代际跃迁
从“佩戴感知”到“无感融入”:UWB vs 镜像视界——空间智能的代际跃迁空间智能产业正迎来划时代理念革新,行业认知正式完成从主动佩戴式感知向全域无感化融入的核心转变。以UWB为代表的传统定位技术,始终停留在依托外接设备实现信息采集的初…...

终极指南:如何用TrafficMonitor股票插件打造桌面投资监控中心
终极指南:如何用TrafficMonitor股票插件打造桌面投资监控中心 【免费下载链接】TrafficMonitorPlugins 用于TrafficMonitor的插件 项目地址: https://gitcode.com/gh_mirrors/tr/TrafficMonitorPlugins 还在为错过重要股票行情而烦恼吗?想在工作时…...

快速上手Notepad2-mod:5个步骤打造你的专属轻量级代码编辑器
快速上手Notepad2-mod:5个步骤打造你的专属轻量级代码编辑器 【免费下载链接】notepad2-mod LOOKING FOR DEVELOPERS - Notepad2-mod, a Notepad2 fork, a fast and light-weight Notepad-like text editor with syntax highlighting 项目地址: https://gitcode.c…...

从 LangChain 到 LangGraph:大语言模型应用开发框架极简史
大模型应用开发正经历一场静悄悄的革命——从“把LLM接进工作流”走向“为Agent构建操作系统”。作为这场革命的两大核心引擎,LangChain与LangGraph的故事,既是一部框架演进史,也是一部开发者认知升级史。 一、源起:一个框架的诞生与大模型开发的“蛮荒时代” 时间回到202…...

告别手动排班!明日方舟智能基建助手Arknights-Mower五分钟上手指南
告别手动排班!明日方舟智能基建助手Arknights-Mower五分钟上手指南 【免费下载链接】arknights-mower 《明日方舟》长草助手 项目地址: https://gitcode.com/gh_mirrors/ar/arknights-mower 还在为《明日方舟》繁琐的基建管理而头疼吗?每天重复的…...