Adaboost集成学习 | Matlab实现基于CNN-LSTM-Adaboost集成学习时间序列预测(股票价格预测)
目录
- 效果一览
- 基本介绍
- 模型设计
- 程序设计
- 参考资料
效果一览



基本介绍
Adaboost集成学习 | Matlab实现基于CNN-LSTM-Adaboost集成学习时间序列预测(股票价格预测)
模型设计
融合Adaboost的CNN-LSTM模型的时间序列预测,下面是一个基本的框架。
数据准备:
收集并整理用于时间序列预测的数据集。确保数据集包含时间序列的输入特征和对应的目标变量。
划分数据集为训练集和测试集,一般按照时间顺序划分。
单个模型训练:
使用CNN-LSTM模型对时间序列数据进行预测。
Adaboost集成:
将CNN-LSTM的预测结果作为特征输入到Adaboost算法中。
将预测结果作为Adaboost的训练样本标签,并为每个样本分配一个权重。
训练Adaboost模型,通过迭代选择最佳的基分类器,并更新样本权重。
模型预测:
对测试集中的时间序列数据,使用已训练的Adaboost模型进行预测,得到最终的时间序列预测结果。
模型评估:
使用测试集对集成模型进行评估,计算预测结果与真实值之间的误差指标,如均方根误差(RMSE)或平均绝对误差(MAE)。
程序设计
- 完整程序订阅专栏Adaboost集成学习后获取。
%% 清空环境变量
warning off % 关闭报警信息
close all % 关闭开启的图窗
clear % 清空变量
clc %% 导入数据
data = readmatrix('Price.xlsx');
[h1,l1]=data_process(data,6); %步长为6,采用前6个时刻预测第7个时刻
res = [h1,l1];
num_samples = size(res,1); %样本个数% 训练集和测试集划分
outdim = 1; % 最后一列为输出
num_size = 0.7; % 训练集占数据集比例
num_train_s = round(num_size * num_samples); % 训练集样本个数
f_ = size(res, 2) - outdim; % 输入特征维度P_train = res(1: num_train_s, 1: f_)';
T_train = res(1: num_train_s, f_ + 1: end)';
M = size(P_train, 2);P_test = res(num_train_s + 1: end, 1: f_)';
T_test = res(num_train_s + 1: end, f_ + 1: end)';
N = size(P_test, 2);layers0 = [ ...% 输入特征sequenceInputLayer([numFeatures,1,1],'name','input') %输入层设置sequenceFoldingLayer('name','fold') %使用序列折叠层对图像序列的时间步长进行独立的卷积运算。% CNN特征提取convolution2dLayer([3,1],16,'Stride',[1,1],'name','conv1') %添加卷积层,64,1表示过滤器大小,10过滤器个数,Stride是垂直和水平过滤的步长batchNormalizationLayer('name','batchnorm1') % BN层,用于加速训练过程,防止梯度消失或梯度爆炸reluLayer('name','relu1') % ReLU激活层,用于保持输出的非线性性及修正梯度的问题% 池化层maxPooling2dLayer([2,1],'Stride',2,'Padding','same','name','maxpool') % 第一层池化层,包括3x3大小的池化窗口,步长为1,same填充方式% 展开层sequenceUnfoldingLayer('name','unfold') %独立的卷积运行结束后,要将序列恢复%平滑层flattenLayer('name','flatten')lstmLayer(25,'Outputmode','last','name','hidden1') dropoutLayer(0.1,'name','dropout_1') % Dropout层,以概率为0.2丢弃输入%% Set the hyper parameters for unet training
options0 = trainingOptions('adam', ... % 优化算法Adam'MaxEpochs', 100, ... % 最大训练次数'GradientThreshold', 1, ... % 梯度阈值'InitialLearnRate', 0.01, ... % 初始学习率'LearnRateSchedule', 'piecewise', ... % 学习率调整'LearnRateDropPeriod',70, ... % 训练100次后开始调整学习率'LearnRateDropFactor',0.01, ... % 学习率调整因子'L2Regularization', 0.001, ... % 正则化参数'ExecutionEnvironment', 'cpu',... % 训练环境'Verbose', 1, ... % 关闭优化过程'Plots', 'none'); % 画出曲线%% Adaboost增强学习部分
% 权重初始化%%
D = ones(1, M) / M;%% 参数设置
K = 5; % 弱回归器个数%% 弱回归器回归
for i = 1 : Ki%% 创建模型clear netnet = trainNetwork(trainD,targetD',lgraph0,options0);result1 = predict(net, trainD); result2 = predict(net, testD); % 数据格式转换E_sim1 = double(result1);% cell2mat将cell元胞数组转换为普通数组E_sim2 = double(result2);%% 仿真预测t_sim1(i, :) = E_sim1';t_sim2(i, :) = E_sim2';%% 数据反归一化
T_sim1 = mapminmax('reverse', T_sim1, ps_output);
T_sim2 = mapminmax('reverse', T_sim2, ps_output);
T_sim1 = double(T_sim1);
T_sim2 = double(T_sim2);%% 计算各项误差参数 %%
% 指标计算
disp('…………CNN-LSTM-Adaboost训练集误差指标…………')
[test_MAE1,test_MAPE1,test_MSE1,test_RMSE1,test_R2_1,test_RPD1] = calc_error(T_train,T_sim1);
fprintf('\n')
disp('…………CNN-LSTM-Adaboost测试集误差指标…………')
[test_MAE2,test_MAPE2,test_MSE2,test_RMSE2,test_R2_2,test_RPD2] = calc_error(T_test,T_sim2);
fprintf('\n')%% 训练集绘图 %%
figure
plot(1:M,T_train,'r-','LineWidth',1,'MarkerSize',2)
hold on
plot(1:M,T_sim1,'b-','LineWidth',1,'MarkerSize',3)legend('真实值','CNN-LSTM-Adaboost预测值')
xlabel('预测样本')
ylabel('预测结果')
string={'训练集预测结果对比';['(R^2 =' num2str(test_R2_1) ' RMSE= ' num2str(test_RMSE1) ' MSE= ' num2str(test_MSE1) ')'];[ '(MAE= ' num2str(test_MAE1) ' MAPE= ' num2str(test_MAPE1) ' RPD= ' num2str(test_RPD1) ')' ]};
title(string)%测试集误差图 %%
figure
plot(T_test-T_sim2,'b-','LineWidth',0.1,'MarkerSize',2)
xlabel('测试集样本编号')
ylabel('预测误差')
title('测试集预测误差')
grid on;
legend('CNN-LSTM-Adaboost预测输出误差')训练结束: 已完成最大轮数。
…………CNN-LSTM-Adaboost训练集误差指标…………
1.均方差(MSE):5.0615
2.根均方差(RMSE):2.2498
3.平均绝对误差(MAE):1.7773
4.平均相对百分误差(MAPE):3.0813%
5.R2:98.1767%
6.剩余预测残差RPD:7.4167
…………CNN-LSTM-Adaboost测试集误差指标…………
1.均方差(MSE):60.8207
2.根均方差(RMSE):7.7988
3.平均绝对误差(MAE):6.601
4.平均相对百分误差(MAPE):6.2778%
5.R2:46.9453%
6.剩余预测残差RPD:2.3064
参考资料
[1] https://hmlhml.blog.csdn.net/article/details/135536086?spm=1001.2014.3001.5502
[2] https://hmlhml.blog.csdn.net/article/details/137166860?spm=1001.2014.3001.5502
[3] https://hmlhml.blog.csdn.net/article/details/132372151
相关文章:
Adaboost集成学习 | Matlab实现基于CNN-LSTM-Adaboost集成学习时间序列预测(股票价格预测)
目录 效果一览基本介绍模型设计程序设计参考资料 效果一览 基本介绍 Adaboost集成学习 | Matlab实现基于CNN-LSTM-Adaboost集成学习时间序列预测(股票价格预测) 模型设计 融合Adaboost的CNN-LSTM模型的时间序列预测,下面是一个基本的框架。 …...

你焦虑了吗
前段时间,无意间在图书馆看到一本书《认知觉醒》,书中提到了焦虑的相关话题,从焦虑的根源,焦虑的形式,如何破解焦虑给了我点启示,分享给一下。 引语: 焦虑肯定是你的老朋友了,它总像…...

一键分析Bulk转录组数据
我们前面介绍了经典的转录组分析流程:Hisat2 Stringtie,可以帮助用户快速获得基因的表达量矩阵。 云上生信,未来已来 | 转录组标准分析流程重磅上线! RNA STAR 也是一款非常流行的转录组数据分析工具。它不仅可以将测序 Reads 比…...
Django DetailView视图
Django的DetailView是一个用于显示单个对象详情的视图。下面是一个使用DetailView来显示单个书籍详情的例子。 1,添加视图 Test/app3/views.py from django.shortcuts import render# Create your views here. from django.views.generic import ListView from .m…...
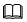
openGauss学习笔记-300 openGauss AI特性-AI4DB数据库自治运维-DBMind的AI子功能-SQL Rewriter SQL语句改写
文章目录 openGauss学习笔记-300 openGauss AI特性-AI4DB数据库自治运维-DBMind的AI子功能-SQL Rewriter SQL语句改写300.1 概述300.2 使用指导300.2.1 前提条件300.2.2 使用方法示例300.3 获取帮助300.4 命令参考300.5 常见问题处理openGauss学习笔记-300 openGauss AI特性-AI…...

typescript-泛型
typescript-泛型 泛型程序设计是一种编程风格或编程范式,允许在程序中定义形式类型参数,然后再泛型实例化时候使用实际类型参数来替代形式类型参数,通过泛型,可以定义通用的数据结构或类型,这种数据结构或类型仅仅再它…...

应急响应 | 基本技能 | 01-系统排查
系统排查 目录 系统基本信息 Windows系统Linux系统 用户信息 Windows系统 1、命令行方式2、图形界面方法3、注册表方法4、wmic方法 Linux系统 查看所有用户信息分析超级权限账户查看可登录的用户查看用户错误的登录信息查看所有用户最后的登录信息查看用户最近登录信息查看当…...
用c语言实现通讯录
目录 静态简易通讯录 代码: 功能模块展示: 设计思路: 动态简易通讯录(本质顺序表) 代码: 扩容模块展示: 设计思路: 文件版本通讯录 代码: 文件模块展示&#x…...

AI大模型技术揭秘-参数,Token,上下文和温度
深入理解 AI 大模型:参数、Token、上下文窗口、上下文长度和温度 人工智能技术的飞速发展使AI大模型大放异彩,其中涉及的“参数”、“Token”、“上下文窗口”、“上下文长度”及“温度”等专业术语备受瞩目。这些术语背后究竟蕴含何意?它们如何影响AI大模型的性能?一起揭开…...

攻防世界-fakebook题目__详解
1.打开题目先用dirsearch工具扫描一波,扫出来了robots.php目录,然后访问robots.txt 目录,发现了有一个备份文件 ,访问备份文件,下载内容 文件的大致内容如下 里面有一个curl_exec这个函数容易造成ssrf攻击的漏洞 我…...
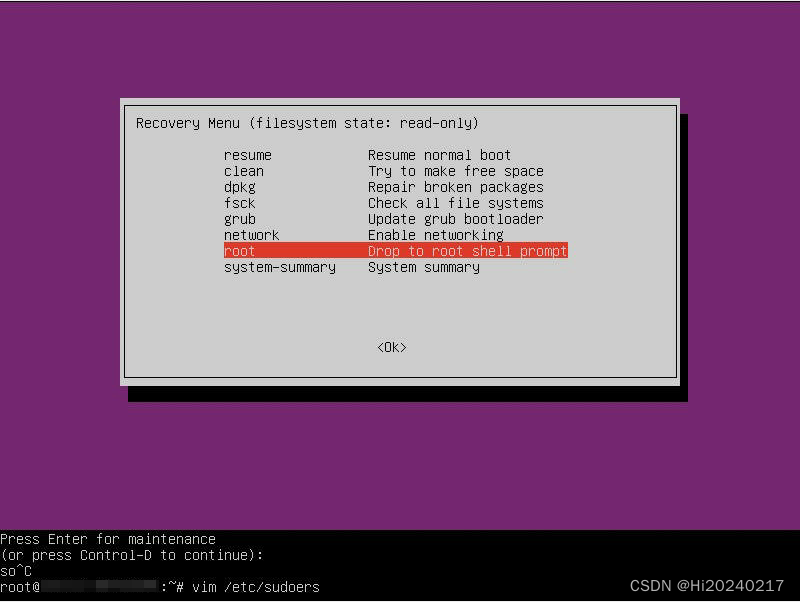
Ubuntu 18.04下普通用户的一次提权过程
Ubuntu 18.04下普通用户的一次提权过程 一.背景介绍:二.主要调试过程:三.相关命令:1.设置BMC密码,获取BMC IP2.找一台ubuntu搭建TFTP服务,用来替换grub.cfg文件3.从调试服务器的/boot/grub/grub.cfg中提取出recovery mode的配置,简化并生成新的配置文件grub.cfg,放在tftp服务的…...

接口和抽象类:如何使用普通类模拟接口和抽象类
目录 1.引言 2.抽象类和接口的定义与区别 3.抽象类和接口存在的意义 4.模拟实现抽象类和接口 5.抽象类和接口的应用场景 1.引言 在面向对象编程中,抽象类和接口是两个经常被提及的语法概念,也是面向对象编程的四大特性,以及很多设计模式…...
【文档智能】实践:基于Yolo三行代码极简的训练一个版式分析模型
一、数据集 本文以开源的CDLA数据集做为实验,CDLA是一个中文文档版面分析数据集,面向中文文献类(论文)场景。包含以下10个label: 数据集下载地址:https://github.com/buptlihang/CDLA 数据集是labelme格式…...

聚观早报 | 深蓝G318价格发布;比亚迪方程豹豹3官图发布
聚观早报每日整理最值得关注的行业重点事件,帮助大家及时了解最新行业动态,每日读报,就读聚观365资讯简报。 整理丨Cutie 6月15日消息 深蓝G318价格发布 比亚迪方程豹豹3官图发布 夸克App升级高考AI搜索 iOS 18卫星通信实测 Redmi K70…...

如何实现内网穿透?快解析-免费内网穿透工具
在现如今的ipv4时代,随着上网电脑及其他智能设备越来越多,公网IP地址出现了枯竭的情况。近几年,内网穿透这个词被不断提及,这也是在无公网IP环境下实现异地访问的一种可行办法,下面我就给大家介绍一下内网穿透的原理。…...

【python-AI篇】人工智能技能树思维导图
大致总结一下得出如下思维导图,如不完善日后迭代更新 1. python基础三方库 1.1 科学计算库 ---- numpy库 1.2 科学计算库 ---- Scipy库 1.3 数据分析处理库 ---- pandas库 1.4 可视化库 ---- matplotlib库 1.5 可视化库 ---- seaborn库 1.6 机器学习和数据挖掘库 …...

Vue的computed大致细节
computed computed具体实现流程computer的执行顺序 computed 具体实现流程 computer内部首先是标准化参数然后调用runner函数进行依赖收集设置dirty为true创建副作用函数,具体如下 const runner effect(getter,{//延迟执行lazy:true,//标记为computed effect 用…...
第5章:模型预测控制(MPC)的代码实现
1. 建立 QP 模型: 1.1 车辆模型: 注:使用车辆横向动力学模型 纵向动力学模型(误差模型) 1.2 QP 问题模型: 注:详细推导见 笔记100:使用 OSQP-Eigen 对 MPC 进行求解的方法与代码-…...
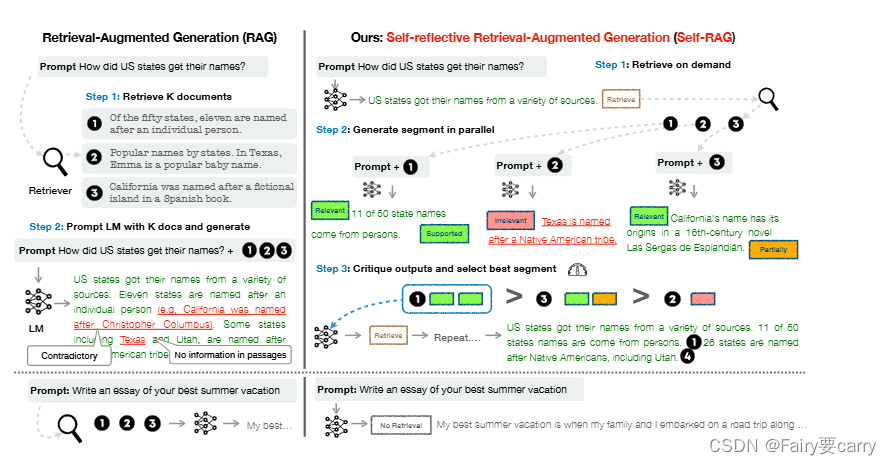
论文学习day01
1.自我反思的检索增强生成(SELF-RAG) 1.文章出处: Chan, C., Xu, C., Yuan, R., Luo, H., Xue, W., Guo, Y., & Fu, J. (2024). RQ-RAG: Learning to Refine Queries for Retrieval Augmented Generation. ArXiv, abs/2404.00610. 2.摘…...

Github入门教程,适合新手学习(非常详细)
前言:本篇博客为手把手教学的 Github 代码管理教程,属于新手入门级别的难度。教程简单易操作,能够基本满足读者朋友日常项目寄托于 Github 平台上进行代码管理的需求。Git 与 Github 是一名合格程序员 coder 必定会接触到的工具与平台&#x…...

3步搞定B站视频下载:BBDown让你的收藏从未如此简单 [特殊字符]
3步搞定B站视频下载:BBDown让你的收藏从未如此简单 🎬 【免费下载链接】BBDown Bilibili Downloader. 一个命令行式哔哩哔哩下载器. 项目地址: https://gitcode.com/gh_mirrors/bb/BBDown 还在为无法离线观看B站优质内容而烦恼吗?BBDo…...

Windows和Office激活难题?KMS智能激活脚本让你轻松告别烦恼
Windows和Office激活难题?KMS智能激活脚本让你轻松告别烦恼 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 你是否曾经因为Windows系统突然弹出激活提示而中断工作?是否遇…...

5V/7.4V/12V三个升压档位!智能门锁供电选它
在智能门锁硬件设计与实操过程中,常见的痛点是锂电池的常见电压(3.7V、3.2V)与门锁电机的工作电压需求(5V、7.4V、甚至12V)不匹配,电压不足直接导致电机无法正常驱动,进而影响门锁开关功能的实现…...

Windows删除文件权限问题解决
首先,强制删除的文件将不经过回收站。方法一:可视化获取权限如果文件不是被系统占用,可以直接在文件属性中抢夺控制权。获取所有权:右键点击该文件/文件夹,选择 属性 → 安全 → 高级-。在打开的窗口中,点击…...

重塑游戏社交:Nucleus Co-Op如何用一台电脑创造四人同屏体验
重塑游戏社交:Nucleus Co-Op如何用一台电脑创造四人同屏体验 【免费下载链接】nucleuscoop Starts multiple instances of a game for split-screen multiplayer gaming! 项目地址: https://gitcode.com/gh_mirrors/nu/nucleuscoop 问题:本地多人…...
)
避坑指南:海康威视工业相机SDK二次开发常见问题排查(从环境配置到图像采集)
海康威视工业相机SDK开发实战:从环境搭建到图像处理的深度避坑指南 工业视觉领域的开发者们,是否曾在深夜调试海康威视相机SDK时,被突如其来的"DLL缺失"错误打断思路?或是明明按照文档配置了项目属性,却始终…...

避坑指南:SciencePlots安装后样式不生效?手把手教你排查Matplotlib的stylelib路径问题
科学绘图样式失效?彻底解决Matplotlib样式库路径配置难题 当你第一次尝试用SciencePlats的science样式美化科研图表时,却发现Python报出KeyError: science is not a valid style的错误提示——这种挫败感我深有体会。作为每天与数据可视化打交道的从业者…...

如何用DdddOcr在3分钟内构建离线验证码识别系统
如何用DdddOcr在3分钟内构建离线验证码识别系统 【免费下载链接】ddddocr 带带弟弟 通用验证码识别OCR pypi版 项目地址: https://gitcode.com/gh_mirrors/dd/ddddocr 在当今的自动化测试、数据采集和网络安全领域,验证码识别是绕不开的技术难题。传统的在线…...

深耕区域数字生态,智森传媒赋能本地中小企业破局增长
在本地生活流量红利消退、行业内卷加剧的当下,中小企业数字化转型已不是选择题,而是生存题。十堰智森网络传媒立足本土市场,以技术研发为根基,以区域获客为核心,以数字人直播为抓手,为中小企业搭建全链路数…...
成最优之选)
2026年AI大模型接口加速站亲测:六家平台横评,诗云API(ShiyunApi)成最优之选
在进行AI开发时,一个现实问题摆在眼前:如何接入模型厂商的官方API?对于海外开发者而言,注册、绑卡、调用这三步便能轻松解决。然而,国内开发者却面临着诸多难题,如跨境网络波动、外币支付门槛、发票合规需求…...