数据结构-十大排序算法集合(四万字精讲集合)

前言
1,数据结构排序篇章是一个大的工程,这里是一个总结篇章,配备动图和过程详解,从难到易逐步解析。
2,这里我们详细分析几个具备教学意义和实际使用意义的排序:
冒泡排序,选择排序,插入排序,希尔排序,快排(递归,霍尔版本),快排(递归,前后指针版本),快排(非递归版本),堆排序(解决top_k问题),归并排序(递归),归并排序(非递归),计数排序
3,这里我想说一下,学习排序之前需要了解一些相关的知识,
- 复杂度:目的是了解算法的时间复杂度,复杂度精讲(时间+空间)-CSDN博客
https://blog.csdn.net/Jason_from_China/article/details/138073981
- 栈和队列:目的是在排序非递归实现里面,我们需要用到栈,比如速排的非递归实现,数据结构-栈和队列(速通版本)-CSDN博客
- 二叉树:目的是在排序计算里面,递归的解决方式是比较常用的方式,二叉树正好是用递归来完成的,可以辅助我们深入的了解一下排序的递归数据结构-二叉树系统性学习(四万字精讲拿捏)-CSDN博客
4,当然最后一点就是这些知识也可以不直接涉及到,如果你的时间比较紧张的话,只是理解起来相对而言需要一点难度,这些知识不是必须的。需要知道的是,这些知识可以帮助你深入理解排序的逻辑。
5,对于排序的学习很重要的一点就是,每次实现的时候我们往往需要先实现单趟排序的实现,之后再实现多趟的完结,这个是很重要的思路
6,这里的代码观看,尤其是对于排序代码的实现
- 先看内循环,因为内循环是单趟实现
- 再看外循环,因为外循环是全部实现逻辑。
- 这里一定不能搞错顺序,不然数据结构排序篇章很容易就无法看懂。
- 并且单趟实现往往重于多趟实现,因为多趟实现往往是单趟循环的循环和重复
冒泡排序
前言
冒泡排序具备很强的教学意义,但是没有什么实践意义,这里作为第一个讲解的排序,目的是从简单开始讲解,方便理解
冒泡排序gif
冒泡排序单趟实现
冒泡排序一次只解决一个数字,交换一个数字之后,开始交换第二个数字
那么多趟实现就直接for循环多趟实现就可以了
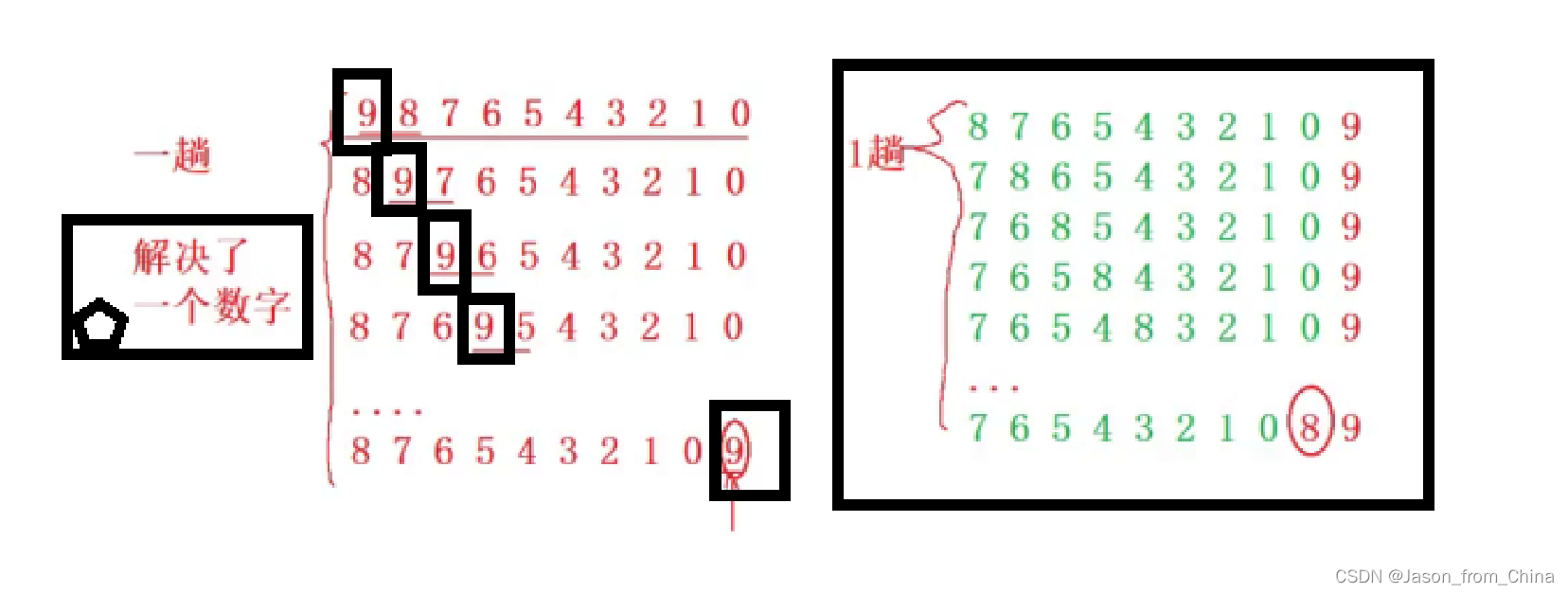
冒泡排序多趟实现逻辑
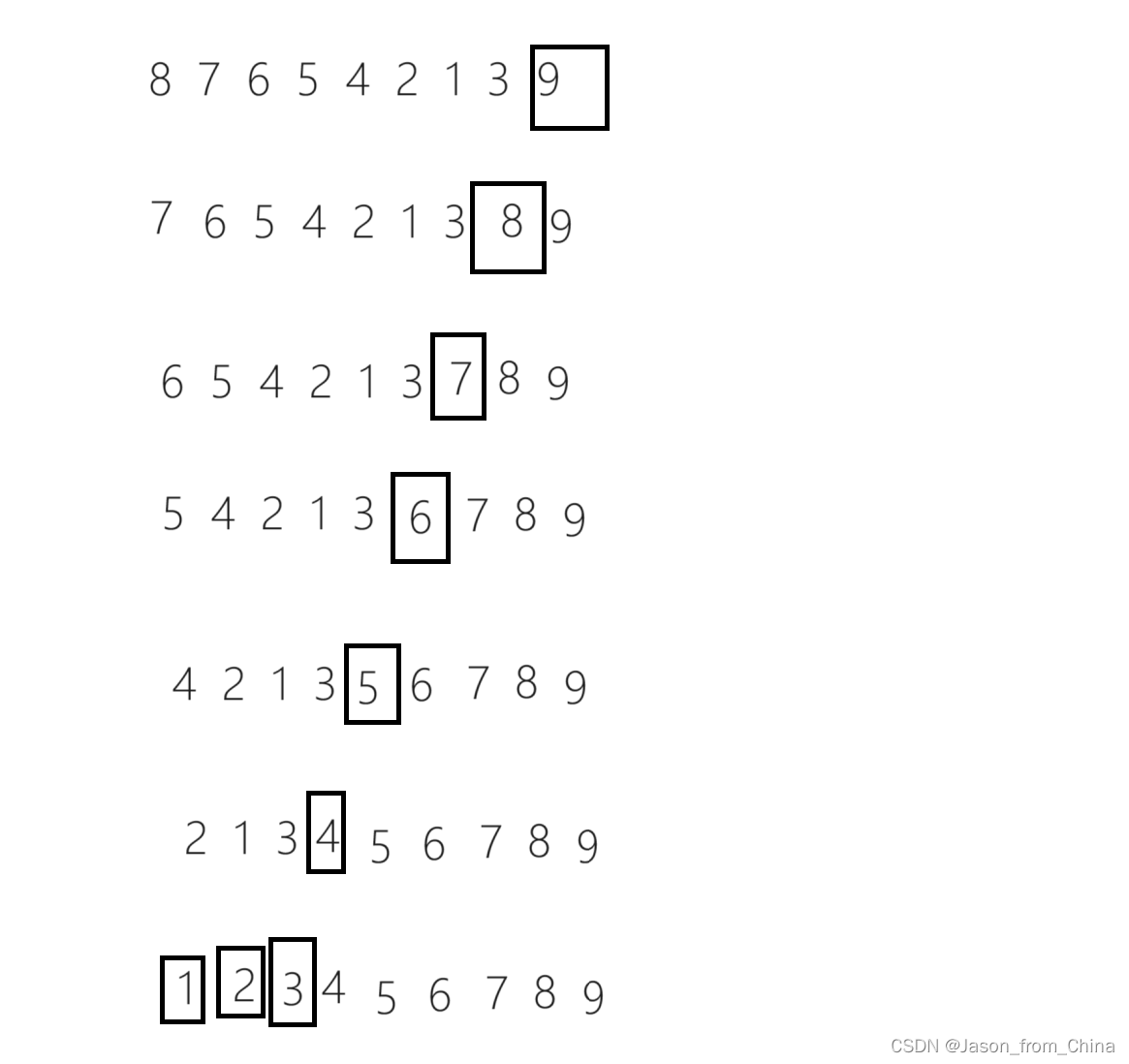
举例2(无法理解可以先不看举例2,这里是参照组):
假设初始数组: [4, 2, 9, 1, 5]
第一轮后: [2, 4, 9, 1, 5] (9移到末尾)
第二轮后: [2, 4, 1, 5, 9] (9和5移到末尾)
第三轮后: [2, 1, 4, 5, 9] (9、5和4移到末尾)
第四轮后: [1, 2, 4, 5, 9] (9、5、4和2移到末尾)
第五轮后: [1, 2, 4, 5, 9] (数组已经排序完成)
冒泡排序注意事项
单趟循环需要注意事项
这里如果传参如果传递是是n,那么单趟实现的时候,我们不能循环n次数,只能循环n-1次数,因为
多趟循环需要注意事项

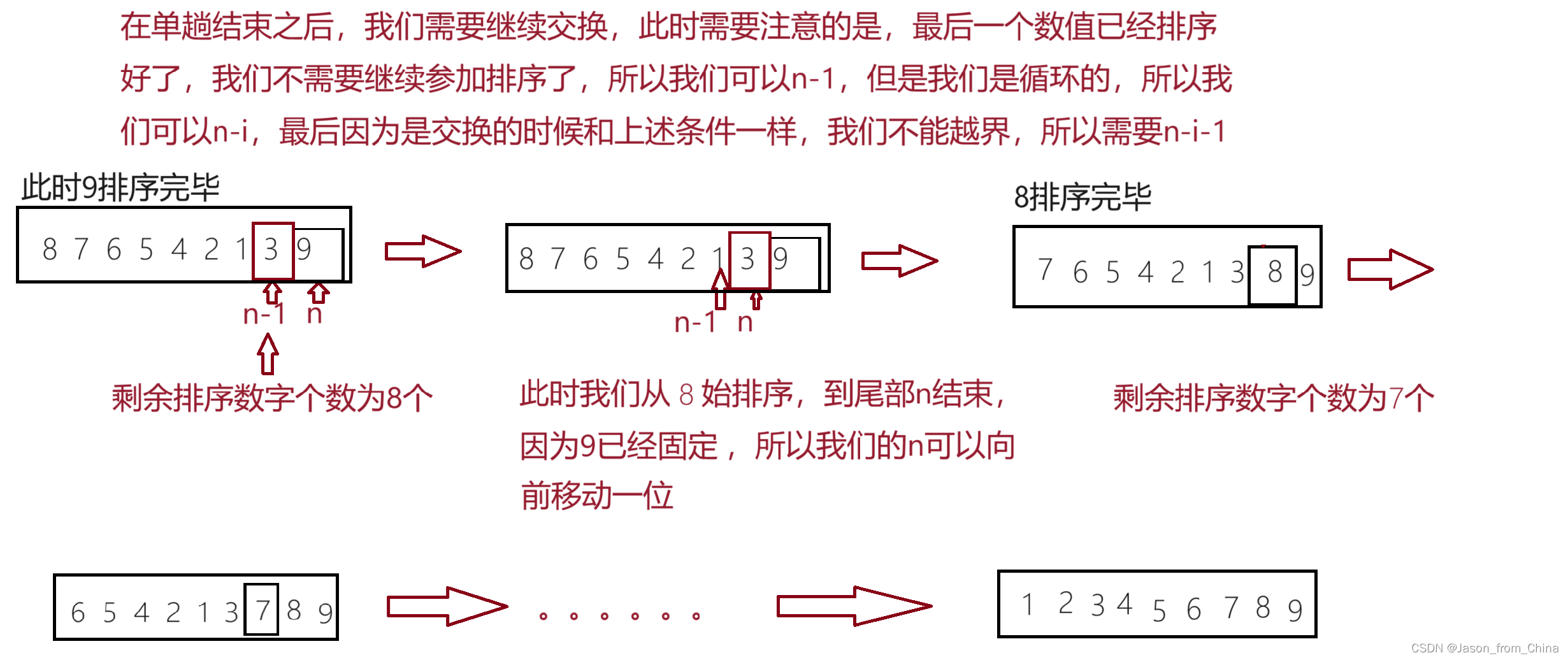
冒泡排序的交换逻辑

冒泡排序代码实现
//交换函数 void Swap(int* p1, int* p2) {int tmp = *p1;*p1 = *p2;*p2 = tmp; } //冒泡排序 void BubbleSort(int* a, int n) {for (int i = 0; i < n - 1; i++){for (int j = 0; j < n - i - 1; j++){if (a[j] < a[j + 1]){Swap(&a[j], &a[j + 1]);}}} }解释:
交换函数(Swap):
- 函数原型:
void Swap(int* p1, int* p2)- 参数:
p1和p2是指向两个整数的指针。- 功能:交换两个指针所指向的整数的值。
- 实现:首先,使用一个临时变量
tmp存储p1指向的值。然后将p2指向的值赋给p1指向的位置,最后将临时变量tmp(原来p1的值)赋给p2指向的位置。冒泡排序(BubbleSort):
- 函数原型:
void BubbleSort(int* a, int n)- 参数:
a是指向整数数组的指针,n是数组中元素的数量。- 功能:对数组
a进行原地排序,使数组中的元素按照非递减顺序排列。- 实现:冒泡排序通过重复遍历要排序的数组,比较相邻元素,如果它们的顺序错误就把它们交换过来。遍历数组的工作是在外层循环中完成的,内层循环负责实际的比较和交换。
- 交换函数就是一个交换函数,因为后面我还需要调用,所以这里我单独拿出来。
冒泡排序时间复杂度计算
冒泡排序的时间复杂度计算基于算法执行的比较和交换操作的次数。下面是冒泡排序的时间复杂度分析:
最佳情况:当数组已经完全有序时,冒泡排序只需要进行一次遍历即可确定数组已经有序,不需要进行任何交换。在这种情况下,时间复杂度是 O(n),其中 n 是数组的长度。
平均情况和最坏情况:在平均情况和最坏情况下,冒泡排序需要进行 n-1 次遍历,每次遍历中进行的比较次数依次减少。具体来说:
- 第一次遍历最多进行 n-1 次比较。
- 第二次遍历最多进行 n-2 次比较。
- ...
- 最后一次遍历进行 1 次比较。
总的比较次数可以表示为:(n-1) + (n-2) + ... + 1。这是一个等差数列求和问题,其和为 n(n-1)/2。因此,平均情况和最坏情况下的时间复杂度是 O(n^2)。
空间复杂度:冒泡排序是原地排序算法,它不需要额外的存储空间来创建另一个数组,只需要一个临时变量用于交换元素。因此,冒泡排序的空间复杂度是 O(1)。
稳定性:冒泡排序是稳定的排序算法,因为它不会改变相同元素之间的相对顺序。
总结来说,冒泡排序的时间复杂度是:
- 最佳情况:O(n)
- 平均情况:O(n^2)
- 最坏情况:O(n^2)
由于冒泡排序在大多数情况下效率不高,特别是对于大数据集,它通常不作为首选排序算法。然而,它的简单性和稳定性使其在某些特定情况下(如小数据集或基本有序的数据)仍然有用。
直接选择排序
前言
直接选择排序也是一个比较简单的排序,所以这里放在第二个进行讲解,这里和冒泡排序是有一点相似。直接选择排序和冒泡排序一样,也是具备一定的教学意义,但是没有什么实际操作的意义,因为直接选择排序的时间复杂度比较高,书写起来和插入排序又差不多,所以没有必要写直接选择排序。
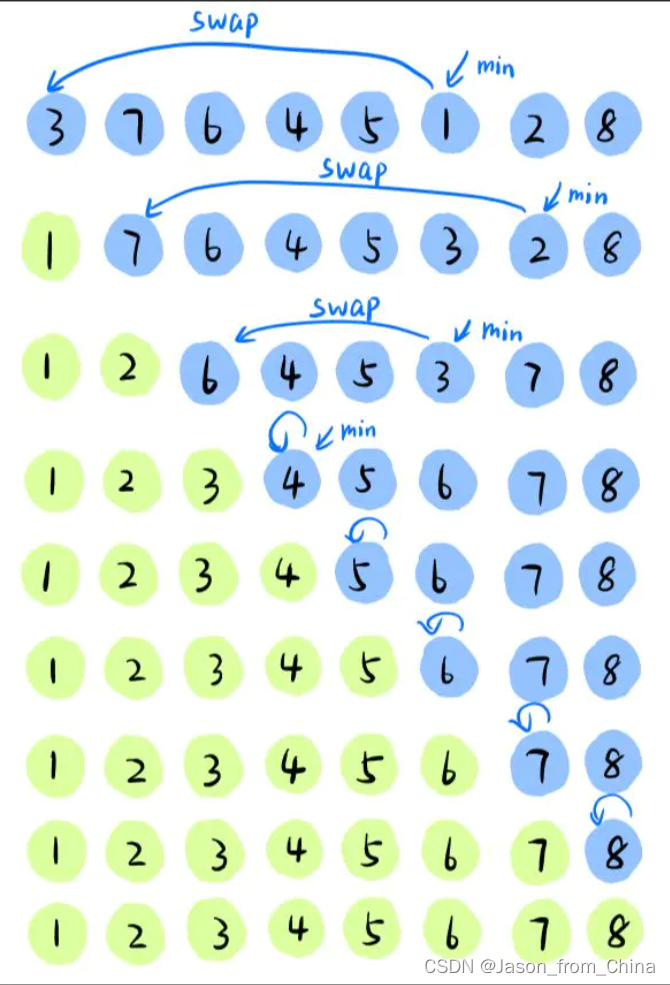
直接选择排序gif
直接选择排序单趟实现
1,初始化min(最小值)=0(也就是最左边的下标)的元素为最小值
2,遍历数组,如果此时出现更小的元素,这个元素的下标是i,那么我们设定min=i
3,之后交换最左边的元素和数值最小元素,因为这个时候我们已经找到下标了
4,最后排序好的最小值放在了最左边,那么此时最左边所在位置不需要进行排序了,分离出来就可以
5,这里因为选择排序效率太低了 ,我们稍微进阶一下,我们从两侧开始,选出最小和最大,从而进行交换,虽然没有提高多少效率,但是还是比之前的速度快两倍
直接选择排序注意事项
1,这里begin和end都是外层循环,也就是随着++和--进行缩小差距
2,这里begin和end不是索引,而是缩小差距用的
3,这里是mini和maxi是索引
4,最后交换的时候交换的是下标的元素,不是下标
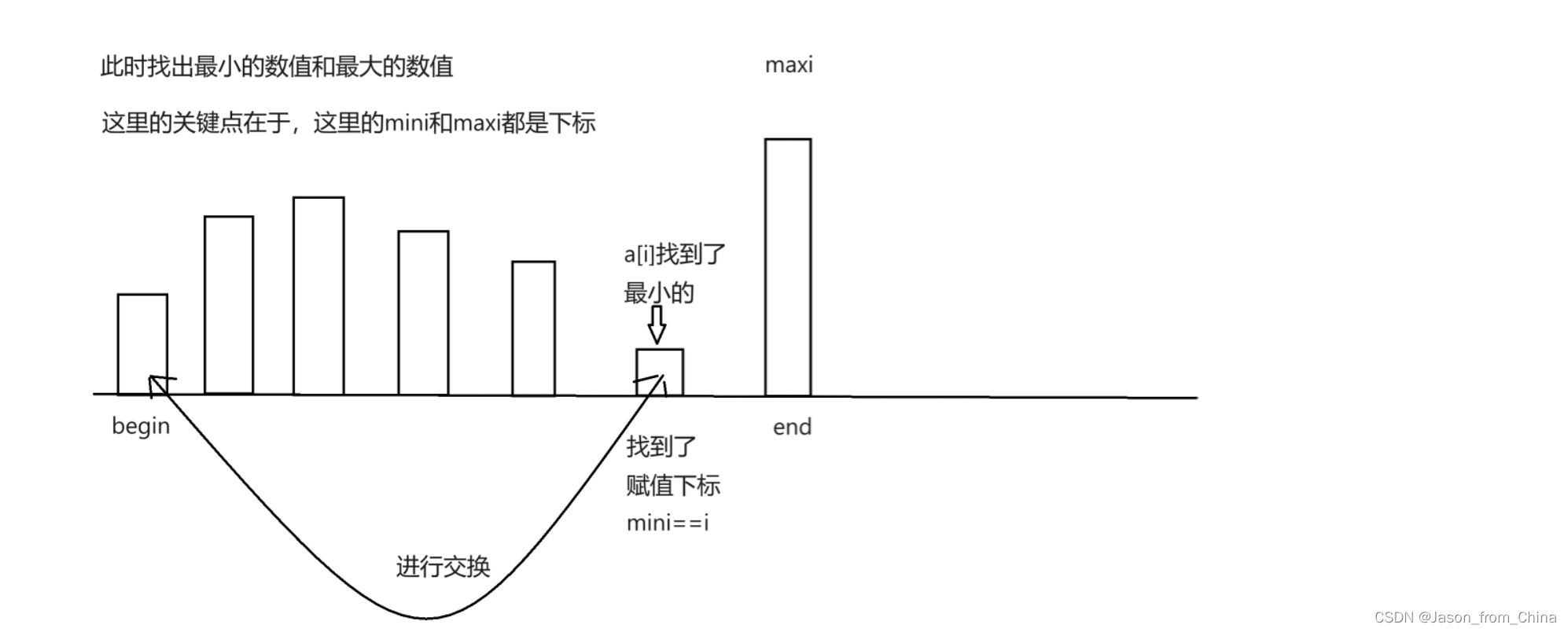
直接选择排序多趟实现图解
直接选择排序代码实现
//交换函数 void Swap(int* p1, int* p2) {int tmp = *p1;*p1 = *p2;*p2 = tmp; } //直接选择排序 void SelectSort(int* a, int n) {//多趟循环int begin = 0, end = n - 1;while (begin < end){//单趟循环,找出最小值和最大值int mini = begin, maxi = end;for (int i = begin; i <= end; i++){//找到最小值,赋值下标if (a[i] < a[mini]){mini = i;}//找到最小值,赋值下标if (a[i] > a[maxi]){maxi = i;}}//把最小值和最大值放到开头和结尾去Swap(&a[mini], &a[begin]);Swap(&a[maxi], &a[end]);begin++; end--;} }解释:
- 外层循环从索引0开始,直到倒数第二个元素。
- 在每次外层循环中,假设当前索引位置的元素是未排序部分的最小值。
- 内层循环从外层循环的下一个位置开始,遍历未排序部分的元素,寻找最小值的索引
minIndex。- 如果找到的最小值不在当前索引位置,使用
Swap函数将其交换到当前索引位置。- 这样,每次外层循环结束时,未排序部分的最小值都被移动到了排序好的部分的末尾。
注意:
- 直接选择排序不是稳定的排序算法,即相等元素之间的相对顺序可能会改变。
- 直接选择排序的时间复杂度是O(n^2),在大多数情况下,它不如其他更高效的排序算法。
- 直接选择排序的空间复杂度是O(1),因为它是原地排序算法。
选择排序时间复杂度计算
外层循环:选择排序算法有一个外层循环,它从第一个元素遍历到倒数第二个元素。这个循环执行了 n−1 次,其中 n 是数组的长度。
内层循环:对于外层循环的每一次迭代,都有一个内层循环,它从当前考虑的元素之后的第一个元素遍历到数组的最后一个元素。在第一次外层循环迭代时,内层循环执行 n−1 次;在第二次迭代时,执行n−2 次;依此类推,直到最后一次迭代,只执行一次。
总迭代次数:内层循环的总迭代次数可以表示为一个等差数列之和: (𝑛−1)+(𝑛−2)+…+2+1=n(n−1)/2
时间复杂度:由于外层循环和内层循环的迭代次数都是 Θ(𝑛)(即线性关系),因此选择排序的总时间复杂度是 Θ(𝑛^2)。
空间复杂度:选择排序是原地排序算法,它只需要一个额外的变量来存储最小元素的索引,因此空间复杂度是 Θ(1)。
插入排序
前言
插入排序是很重要的排序,著名的希尔排序就是从插入排序演变过来的,所以我们需要并且很多时候有些面试也是会面试插入排序的,所以需要好好捋清楚插入排序的逻辑是什么
插入排序gif

插入排序单趟实现
1,插入排序我们需要假设最后一个数值也就是end+1是需要排序的,其他都是排序好的
2,把end+1这个下标的数值存放在tmp里面,并且和前面进行比较
3,如果遇见的元素比tmp大,我们继续往前移动进行比较,同时a[end]=a[end+1]往后覆盖
4,当遇见的是比tmp小的数值的时候,此时我们找到了tmp数值应该在的位置,进行插入
插入排序注意事项
这里需要注意的关键也是区间问题,假设数组有n个,那么end就是倒数第二个下标,end+1就是最后一个下标,是为了防止越界
我们需要小于n-1,因为,end=n-1;end+1=n,那么就越界了
所以在循环最大值里面,end=i=n-2,;end+1=n-1(最后一个数值)
插入排序代码的实现
//插入排序 void InsertionSort(int* a, int n) {//多趟实现,这里n的截止条件-1,是因为下标从n-1就结束了,//不过我们需要小于n-1,因为,end=n-1;end+1=n,那么就越界了for (int i = 0; i < n - 1; i++){//单趟实现int end = i; int tmp = a[end + 1];while (end >= 0){//判断是不是比前一个数值小,小的话就往前走,不小的话停下来进行赋值if (tmp < a[end]){a[end + 1] = a[end];end--;}else//找到了,此时跳出循环就可以{break;}}//这里是很多人会搞混乱的一点,//因为是找到了,所以end还没有继续移动,但是end+1+1的元素已经移动,所以end+1的位置是tmp应该出现的位置a[end + 1] = tmp;} }解释:
函数
InsertionSort接受两个参数:一个指向整数数组a的指针和数组的长度n。外层循环从索引
0遍历到n-1。每次迭代,i代表已排序部分的最后一个元素的索引。在外层循环的每次迭代中,
end变量被设置为当前索引i,表示当前考虑的元素的索引。tmp变量存储了a[i + 1]的值,这是未排序的第一个元素,也是我们准备插入到已排序部分的元素。内层
while循环用于在已排序部分从后向前扫描,找到tmp应该插入的位置。end变量随着比较逐步递减。在
while循环中,如果tmp小于当前比较的元素a[end],则将a[end]向后移动一个位置,为tmp腾出空间。如果
tmp大于或等于a[end],则while循环通过break语句结束,找到了tmp应该插入的位置。循环结束后,将
tmp赋值给a[end + 1],完成插入操作。这个过程重复进行,直到数组中的所有元素都被扫描并插入到正确的位置。
代码逻辑:
- 插入排序的基本思想是,对于数组中的每个元素,将其插入到前面已经排好序的子数组中的正确位置。
- 初始时,认为数组的第一个元素是已排序的。然后,从第二个元素开始,逐个插入到前面的已排序序列中。
- 每次插入操作都需要将元素与已排序序列中的元素进行比较,直到找到合适的插入点。
注意:
- 这段代码在插入元素时,如果插入点是数组的开始,那么不需要进行任何移动操作,直接插入即可。
- 代码中的
end变量用于记录当前比较的元素在数组中的位置,而tmp变量用于暂存当前要插入的元素。- 插入排序是稳定的排序算法,因为它不会改变相等元素的相对顺序。
性能:
- 插入排序的平均时间复杂度和最坏时间复杂度都是 𝑂(𝑛^2),其中 n 是数组的长度。
- 插入排序的空间复杂度是 𝑂(1),因为它是原地排序算法,不需要额外的存储空间。
插入排序的时间复杂度
插入排序算法的时间复杂度取决于数组的初始顺序,具体如下:
最佳情况:如果输入数组已经是完全有序的,插入排序只需要进行 n 次比较(每次比较后插入一个元素到已排序部分),而不需要进行任何交换。在这种情况下,时间复杂度是O(n)。
平均情况:在平均情况下,插入排序的时间复杂度是 O(n^2)。这是因为每个元素都需要与已排序部分的多个元素进行比较,平均下来,每个元素需要比较n/2次。
最坏情况:如果输入数组是完全逆序的,插入排序需要进行n(n−1)/2次比较和 n(n−1)/2次交换,时间复杂度是 O(n^2)。
空间复杂度:插入排序是原地排序算法,它只需要一个额外的存储空间来暂存当前比较的元素,因此空间复杂度是 O(1)。
稳定性:插入排序是稳定的排序算法,它保持了相等元素的原始顺序。
时间复杂度的详细分析:
- 插入排序通过构建有序序列来工作,对于未排序的数据,在已排序的序列中从后向前扫描,找到相应位置并插入。
- 在每次迭代中,算法将当前元素与已排序序列中的元素逐一比较,找到合适的插入点。
- 对于每个元素,比较操作可能需要进行 i 次(其中 𝑖i 是当前元素在数组中的位置),从第一个元素到最后一个元素,所需比较的总次数是递增的。
时间复杂度的数学表达式是:
总比较次数=1+2+3+…+(𝑛−1)=𝑛(𝑛−1)/2总比较次数
这表明插入排序的时间复杂度是 Θ(𝑛^2),尽管在最坏情况下时间复杂度较高,插入排序对于小规模数据集或部分有序的数据集来说是非常高效的。
希尔排序
前言
从希尔开始,排序的速度就开始上升了,这里的排序开始上一个难度了,当然难一点的排序其实也不是很难,当你对于插入排序了解的足够深入的时候,你会发现其实希尔就是插入的异形,但是本质上还是一样的
希尔排序gif
希尔排序单趟实现
1,希尔排序本质就是插入排序的进化,插入排序是寻找比较进行插入,希尔这个人觉得插入排序有点慢,就觉得我们可不可以进行预排序,也就是数值原来是0-9的情况下,最坏的情况我们需要循环9次数才能找到需要插入的点在哪,那么此时我们能不能进行一个预排序
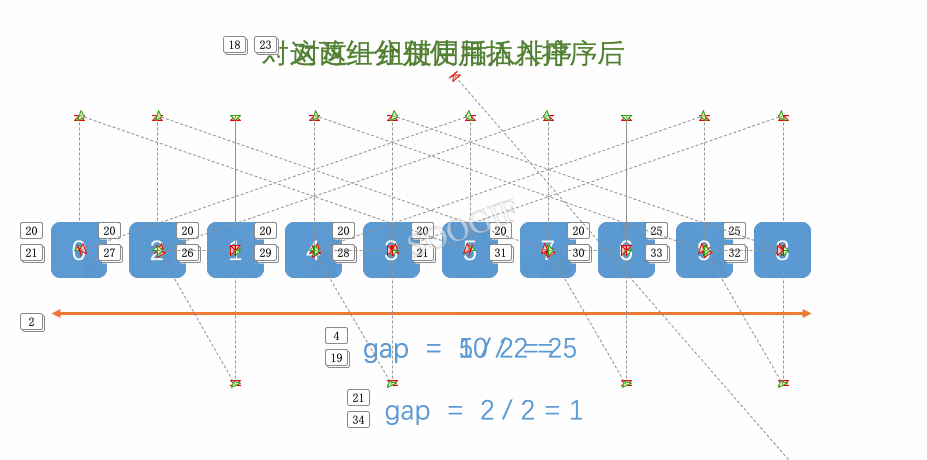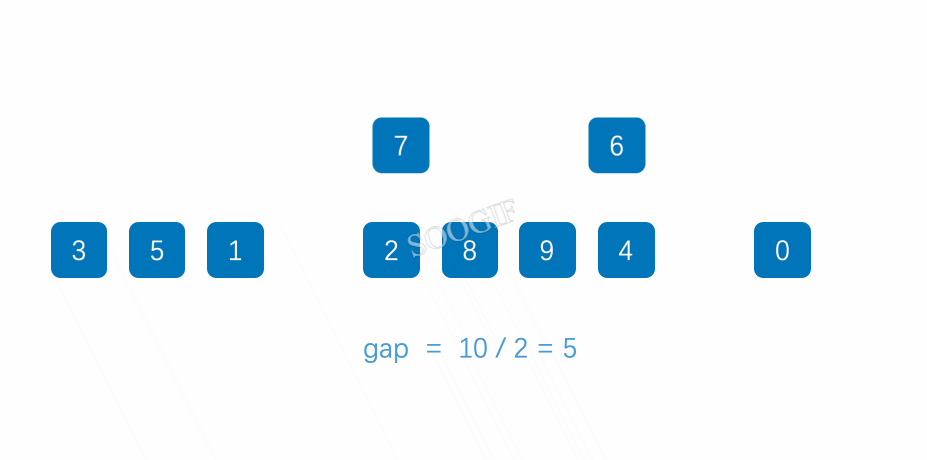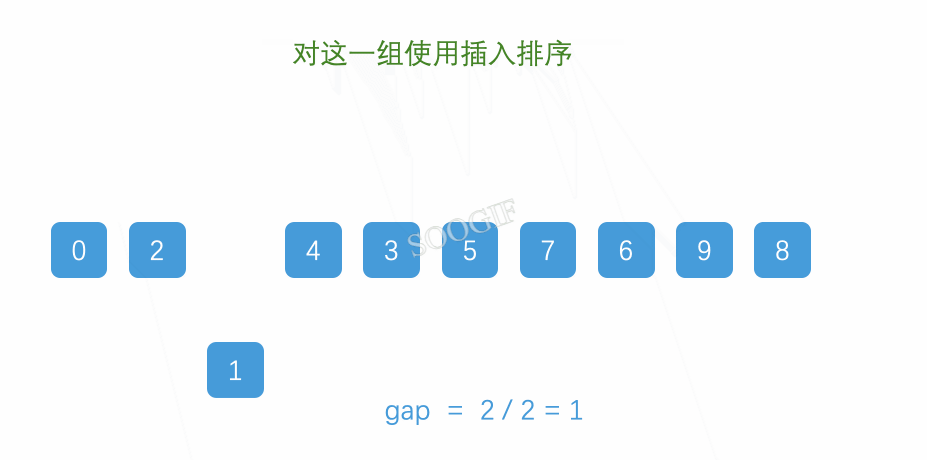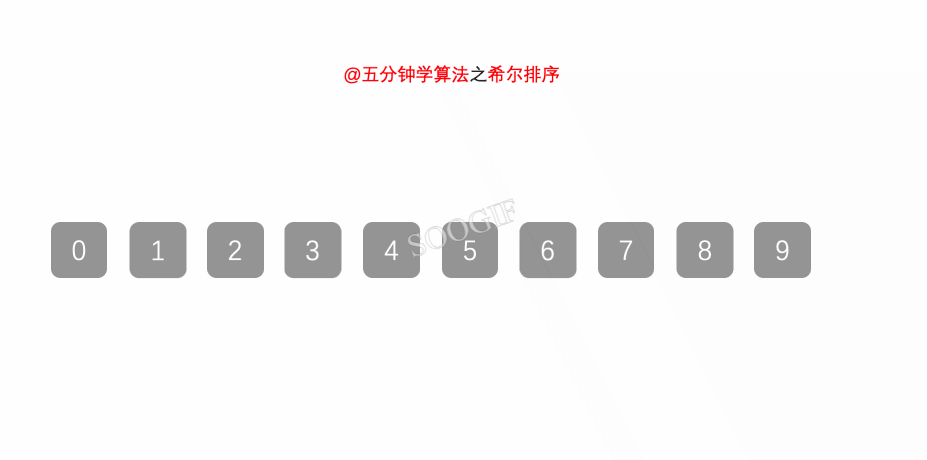
2,所谓的预排序就是,我们假设几个为一组,几个为一组,这个组的变量我们设置为gap。假设处置3个为一组,那么gap=3
3,此时我们可以把这一组,先采取插入排序的方式进行预排序,预排序之后我们就会发现这一组的这条线上的数值已经有序
4,多趟实现只是反复的实现第一趟的实现的逻辑
希尔排序的多趟实现
1,多趟实现只是反复的实现第一趟的实现的逻辑
2,我们需要先知道单趟遍历的时候,我们需要假设gap一组的,这个中间的元素是没有的,那么此时此时一组就是两个数值,我们需要让这两个数值进行交换
3,这两个数值交换之后我们这个时候需要循环开始插入排序的逻辑,也就是假设前面的两个数值是已经有序的,那么新插入的一个数值是需要排序的,我们进行排序
4,一趟结束之后,我们继续多趟实现,这几个数值继续预排序
5,继续预排序
6,此时gap=3,那么我们继续,gap/2=1,之后继续进行预排序,此时我们就得到了这个排序正确的数值


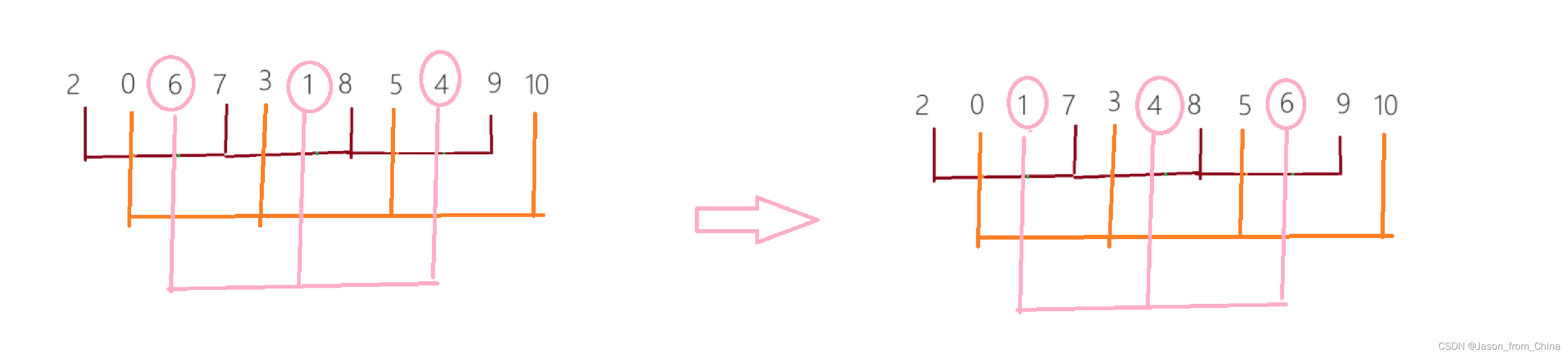

希尔排序代码的实现-版本1
//希尔排序 void ShellSort(int* a, int n) {int gap = n - 1;//定义gap,这里循环停止的条件是>1,原因是+1了,已经恒大于0了,所以需要大于1,等于都不可以while (gap > 1){gap = gap / 3 + 1;//循环实现每一组for (int j = 0; j < gap; j++){//gap单趟实现for (int i = j; i < n - gap; i += gap){int end = i; int tmp = a[end + gap];//一组的实现while (end >= 0){if (tmp < a[end]){a[end + gap] = a[end];end -= gap;}else{break;}}//交换找到的数值a[end + gap] = tmp;}}} }解释:
函数
ShellSort接受两个参数:一个指向整数数组a的指针和数组的长度n。初始化间隔
gap为数组长度n - 1,这是希尔排序开始时的最大间隔。
while循环用于逐步减小间隔,直到间隔为1。当gap大于1时,循环继续。在每次
while循环的开始,重新计算间隔gap。这里使用的是gap = gap / 3 + 1,这是一种常见的间隔序列,由Donald Shell提出。外层
for循环用于遍历数组,步长为当前的间隔gap。内层
for循环用于实现插入排序,但仅限于间隔gap内的范围。在内层循环中,
end变量记录当前考虑的元素的索引,tmp变量暂存当前要插入的元素。
while循环用于在间隔gap内从后向前扫描,找到tmp应该插入的位置。如果
tmp小于当前比较的元素a[end],则将a[end]向后移动一个间隔gap的距离,为tmp腾出空间。如果
tmp大于或等于a[end],则while循环结束,找到了tmp应该插入的位置。循环结束后,将
tmp赋值给a[end + gap],完成插入操作。这个过程重复进行,直到数组中的所有元素都被扫描并插入到正确的位置。
代码逻辑:
- 希尔排序通过多个插入排序的变体来工作,每个变体都有一个特定的间隔。
- 初始时,间隔较大,排序的稳定性较差,但可以快速减少无序度。
- 随着间隔逐渐减小,排序的稳定性逐渐提高,最终当间隔为1时,算法变为普通的插入排序,确保数组完全有序。
注意:
- 希尔排序不是稳定的排序算法,因为它可能会改变相等元素的相对顺序。
- 希尔排序的时间复杂度通常在 𝑂(𝑛log𝑛) 和 𝑂(𝑛^2) 之间,具体取决于间隔序列的选择。
- 希尔排序的空间复杂度是 𝑂(1,因为它是原地排序算法,不需要额外的存储空间。
希尔排序代码的实现-版本2
上面那个代码一般是教学使用,书写会更加详细理解,但是很多书本会这样写
这里的关键在于,不再进行先一组排序结束,再反过来进行下一组反复执行
而是直接这一组实现完毕之后,++,直接进行下一组的实现,本质上还是一样的
只是直接这样书写,容易不理解
//希尔排序 void ShellSort02(int* a, int n) {int gap = n - 1;//定义gap,这里循环停止的条件是>1,原因是+1了,已经恒大于0了,所以需要大于1,等于都不可以while (gap > 1){gap = gap / 3 + 1;//循环实现每一组+//gap单趟实现for (int i = 0; i < n - gap; i++){int end = i; int tmp = a[end + gap];//一组的实现while (end >= 0){if (tmp < a[end]){a[end + gap] = a[end];end -= gap;}else{break;}}//交换找到的数值a[end + gap] = tmp;}} }解释:
函数
ShellSort02接受两个参数:一个指向整数数组a的指针和数组的长度n。初始化间隔
gap为数组的最后一个索引n - 1。
while循环用于逐步减小间隔,直到间隔小于或等于1。循环的条件是gap > 1,这是因为间隔在每次迭代中都会减小,所以不需要检查gap == 1的情况。在
while循环内部,重新计算间隔gap。这里使用的计算方法是gap = gap / 3 + 1,这是一种常见的间隔序列,旨在逐步减小间隔,直到达到1。外层
for循环遍历数组,直到i < n - gap,即遍历到数组的末尾减去当前间隔的位置。在外层
for循环中,end变量记录当前考虑的元素的索引,tmp变量暂存当前间隔位置的元素值。内层
while循环用于在数组中找到tmp应该插入的位置。它从当前索引end开始,向前以间隔gap的距离进行比较。如果
tmp小于当前比较的元素a[end],则将a[end]向后移动一个间隔gap的距离,为tmp腾出空间。如果
tmp大于或等于a[end],则while循环结束,找到了tmp应该插入的位置。循环结束后,将
tmp赋值给a[end + gap],完成插入操作。这个过程重复进行,直到数组中的所有元素都被扫描并插入到正确的位置。
代码逻辑:
- 希尔排序通过多个插入排序的变体来工作,每个变体都有一个特定的间隔。
- 初始时,间隔较大,随着算法的进行,间隔逐渐减小,直到变为1,此时算法变为普通的插入排序。
- 通过逐步减小间隔,希尔排序能够在每次迭代中对数组的更大范围内的元素进行排序,从而减少比较和移动的次数。
希尔排序gap的界定
一般来说,一组为多少这个不好说,希尔开始书写的时候,gap是/2,来进行书写的,但是被认为效率最高的是,除以3+1,但是/3+1有一个弊端就是这个是恒大于0的,所以终止条件应该换为大于1就继续循环,小于等于1就停止循环
希尔排序的时间复杂度
希尔排序的时间复杂度取决于所选择的间隔序列,它通常介于以下范围:
最好情况:对于某些特定的间隔序列,希尔排序可以达到O(nlogn) 的时间复杂度,这与快速排序或归并排序相当。
平均情况:平均情况下,希尔排序的时间复杂度通常被认为是 O(n(logn)2),这比=O(nlogn) 稍差,但仍然比普通插入排序的 𝑂(𝑛^2) 好得多。
最坏情况:最坏情况下,希尔排序的时间复杂度可以退化到𝑂(𝑛^2),这通常发生在间隔序列选择不佳时。
实际性能:在实际应用中,希尔排序的性能通常比普通插入排序好,但不如快速排序、堆排序或归并排序。它的实际性能还取决于数据的初始状态和间隔序列的选择。
间隔序列的影响:不同的间隔序列对希尔排序的性能有很大影响。例如,使用Hibbard 间隔序列或Sedgewick间隔序列可以提高性能,有时甚至可以达到接近 O(nlogn) 的效率。
空间复杂度:希尔排序是原地排序算法,其空间复杂度为 𝑂(1)。
稳定性:希尔排序不是稳定的排序算法,这意味着相等的元素在排序后可能会改变它们原来的顺序。
总的来说,希尔排序是一种有效的排序算法,特别是对于中等大小的数据集或者当数据已经部分有序时。然而,对于大型数据集,通常推荐使用其他更高效的排序算法,如快速排序、堆排序或归并排序。
快排(霍尔版本-递归解决)
前言
快排是很重要的排序,也是一种比较难以理解的排序,这里我们会用递归的方式和非递归的方式来解决,递归来解决是比较简单的,非递归来解决是有点难度的
快排也称之为霍尔排序,因为发明者是霍尔,本来是命名为霍尔排序的,但是霍尔这个人对于自己创造的排序很自信,所以命名为快排
当然也是如他所料,快排确实很快,但是还没有达到第一批次那个程度
快排gif
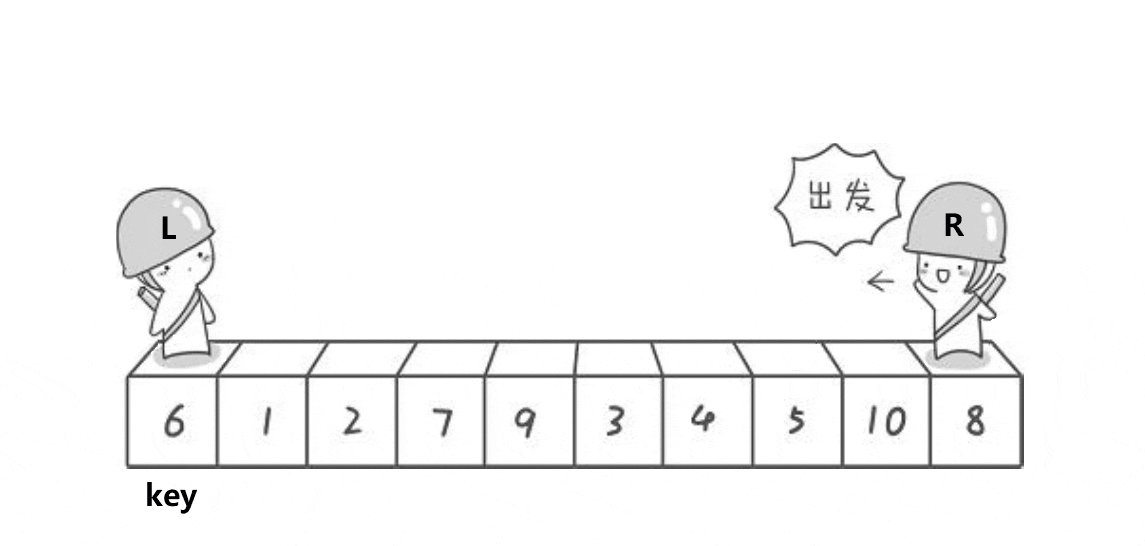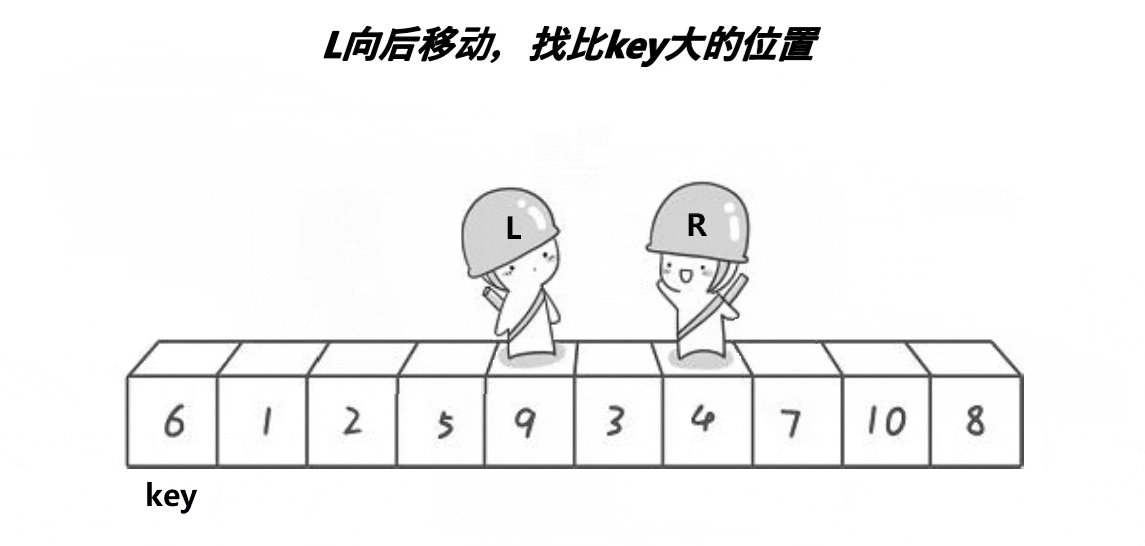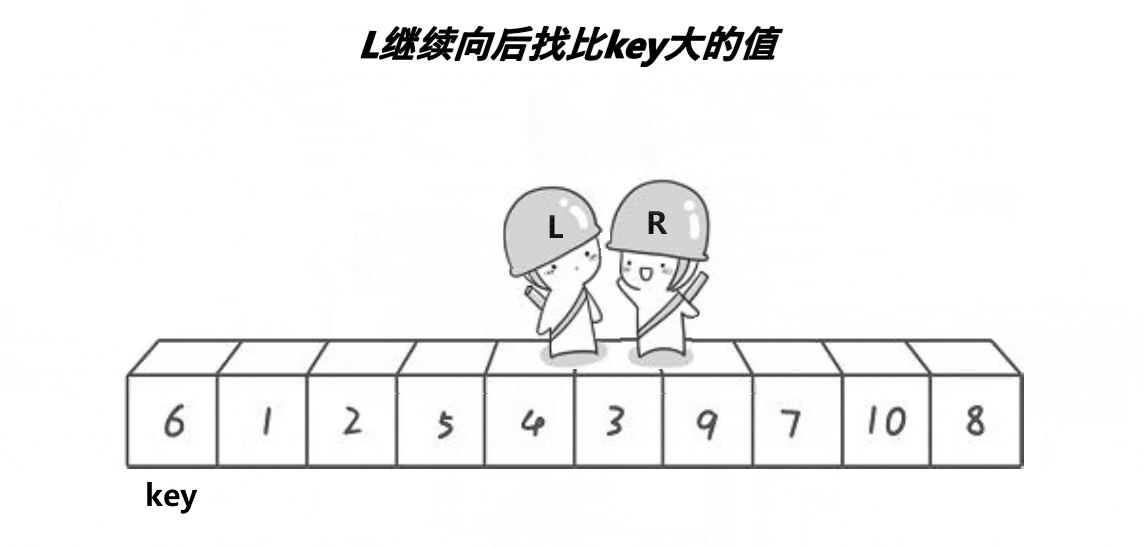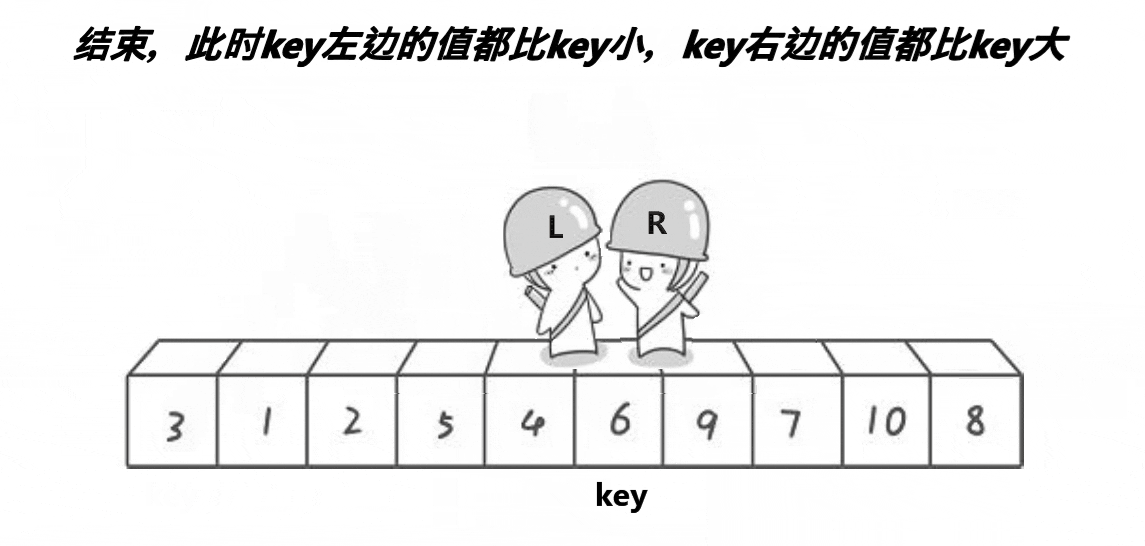
快排实现逻辑排序
单趟实现逻辑:
1.假设左边为keyi,也就是对比数值
2,右边R先走,循环寻找比keyi小的数值
3,左边l走,循环寻找比keyi大的数值
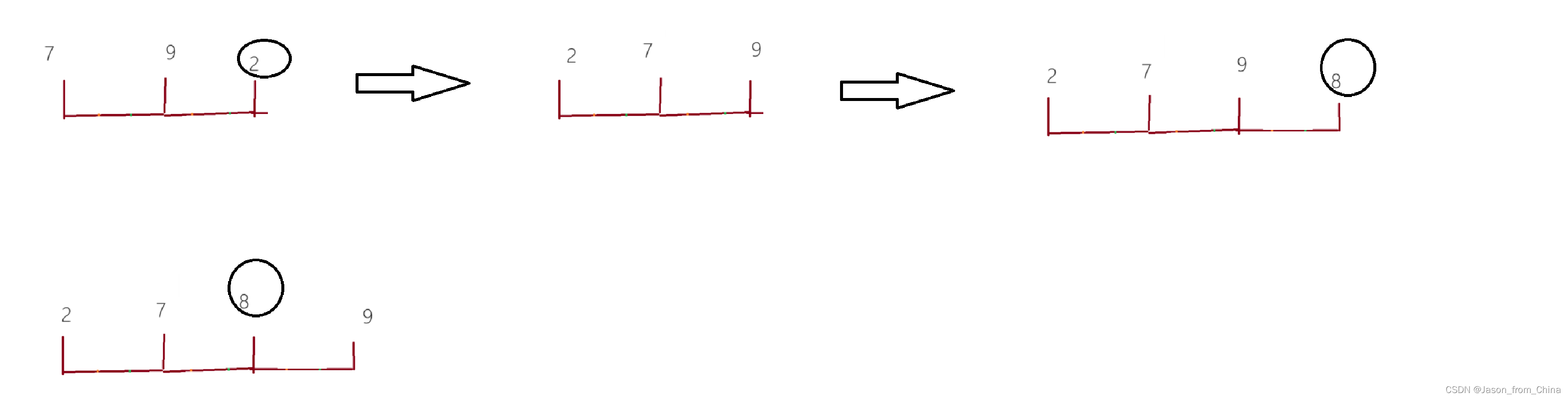
4,交换找到的比keyi大的数值和小的数值,此时会导致小的在左边,大的在右边,最后相遇的时候交换keyi和相遇的元素多趟实现:
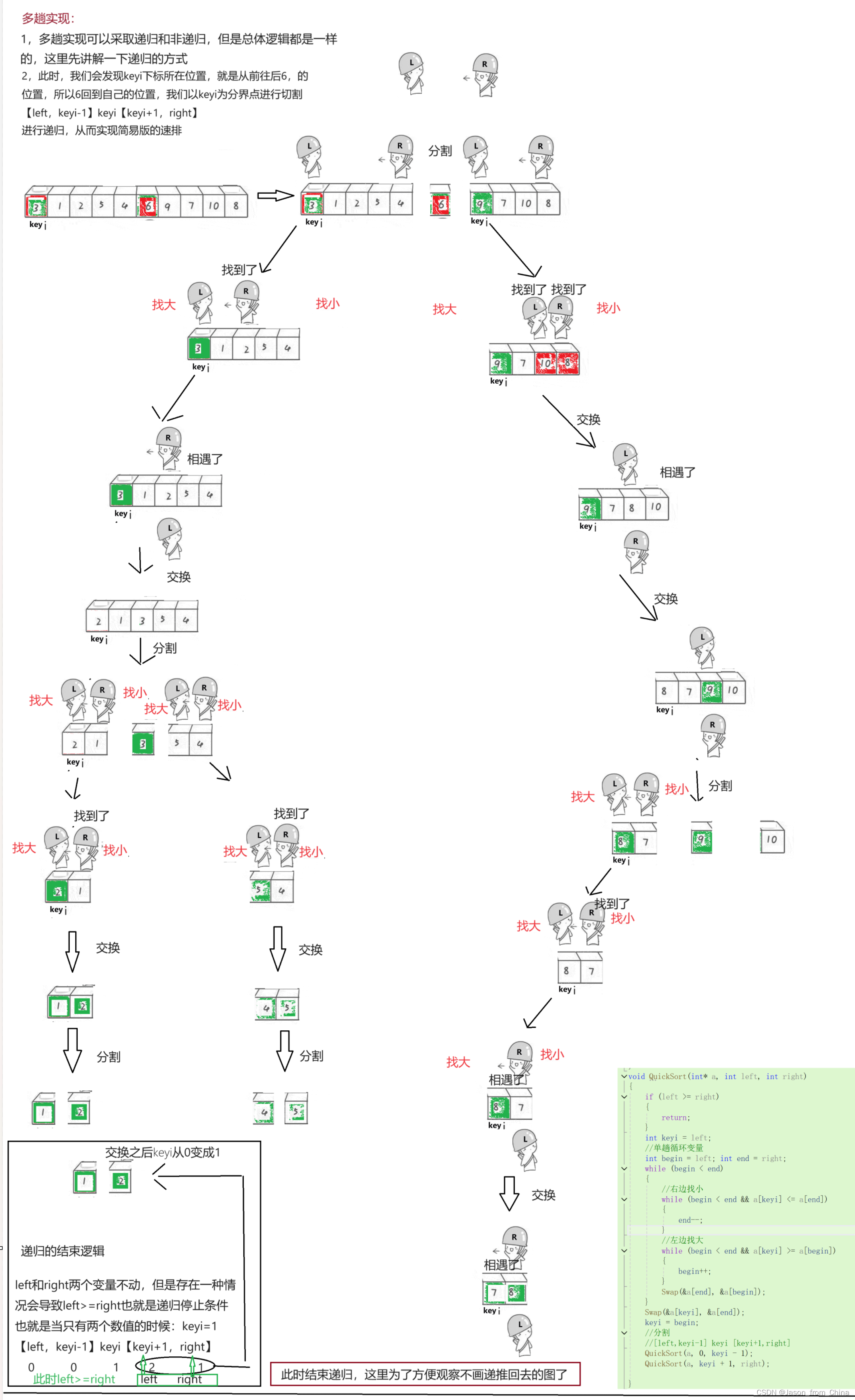
1,多趟实现可以采取递归和非递归,但是总体逻辑都是一样的,这里先讲解一下递归的方式2,此时,我们会发现keyi下标所在位置,就是从前往后6,的位置,所以6回到自己的位置,我们以keyi为分界点进行切割【left,keyi-1】keyi【keyi+1,right】
进行递归,从而实现简易版的速排
完善逻辑:
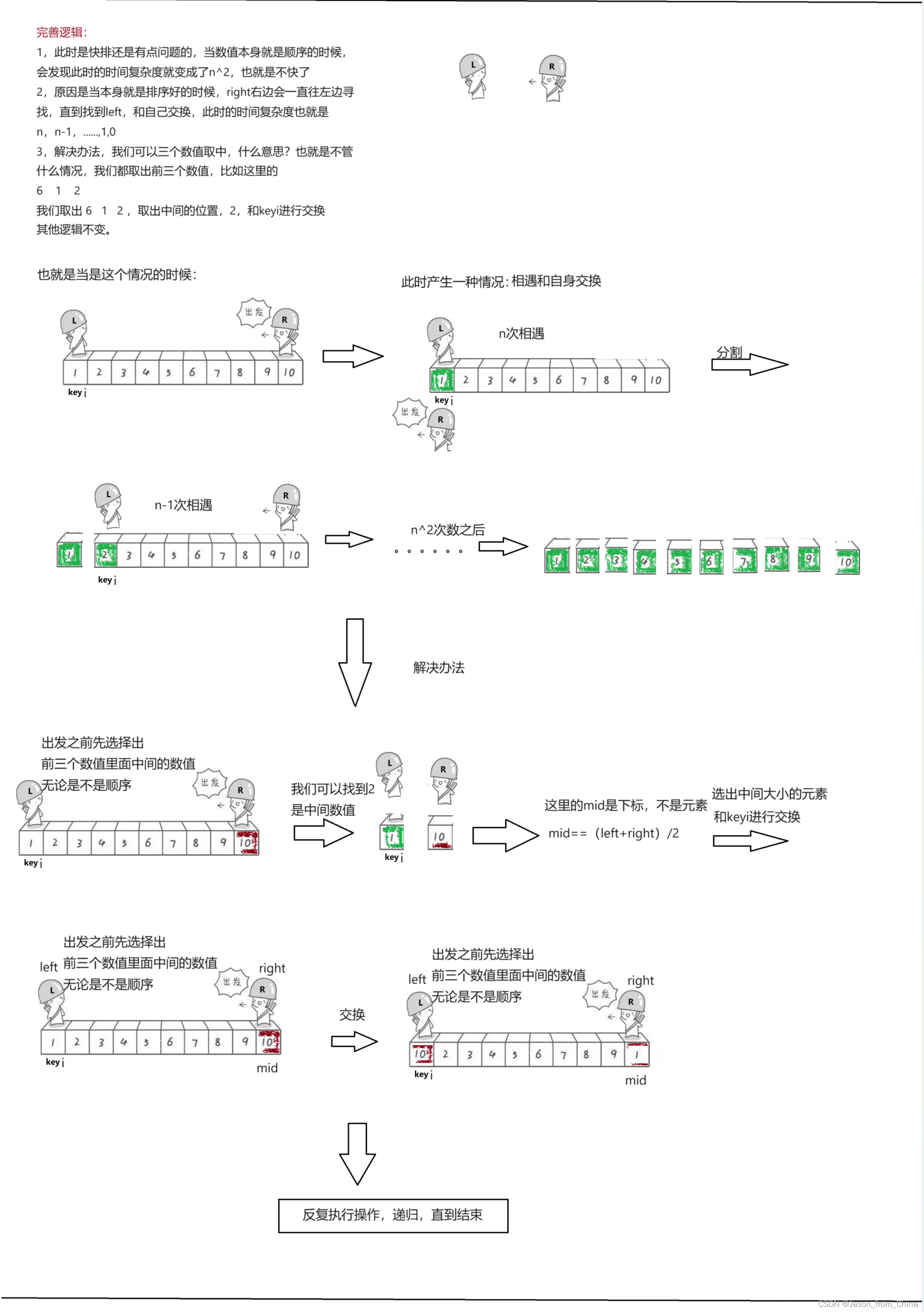
1,此时是快排还是有点问题的,当数值本身就是顺序的时候
会发现此时的时间复杂度就变成了n^2,也就是不快了
2,原因是当本身就是排序好的时候,right右边会一直往左边寻
找,直到找到left,和自己交换,此时的时间复杂度也就是
n,n-1..1.0
3,解决办法,我们可以三个数值取中,什么意思?也就是不管什么情况,我们都取出前三个数值,比如这里的
6 1 2
我们取出6 1 2,取出中间的位置,2,和keyi进行交换其他逻辑不变
完善逻辑:
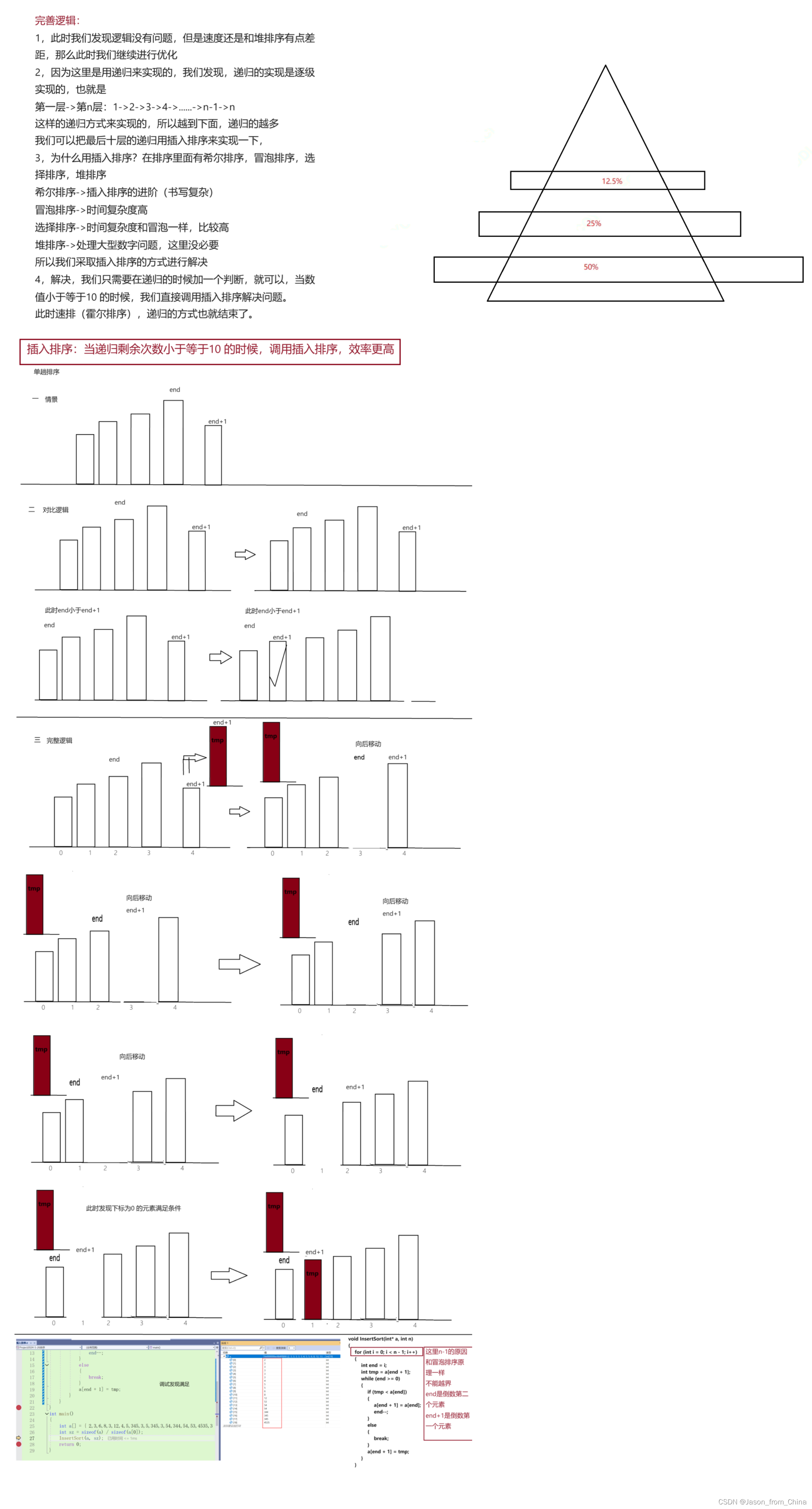
1,此时我们发现逻辑没有问题,但是速度还是和堆排序有点差距,那么此时我们继续进行优化
2,因为这里是用递归来实现的,我们发现,递归的实现是逐级实现的,也就是
第-层->第n层:1->2->3->4->…->n-1->n
这样的递归方式来实现的,所以越到下面,递归的越多
我们可以把最后十层的递归用插入排序来实现一下,
3,为什么用插入排序?在排序里面有希尔排序,冒泡排序,选
择排序,堆排序
希尔排序->插入排序的进阶(书写复杂)
冒泡排序->时间复杂度高
选择排序->时间复杂度和冒泡一样,比较高
堆排序->处理大型数字问题,这里没必要
所以我们采取插入排序的方式进行解决
4,解决,我们只需要在递归的时候加一个判断,就可以,当数
值小于等于10 的时候,我们直接调用插入排序解决问题。
此时速排(霍尔排序),递归的方式也就结束了。图解:

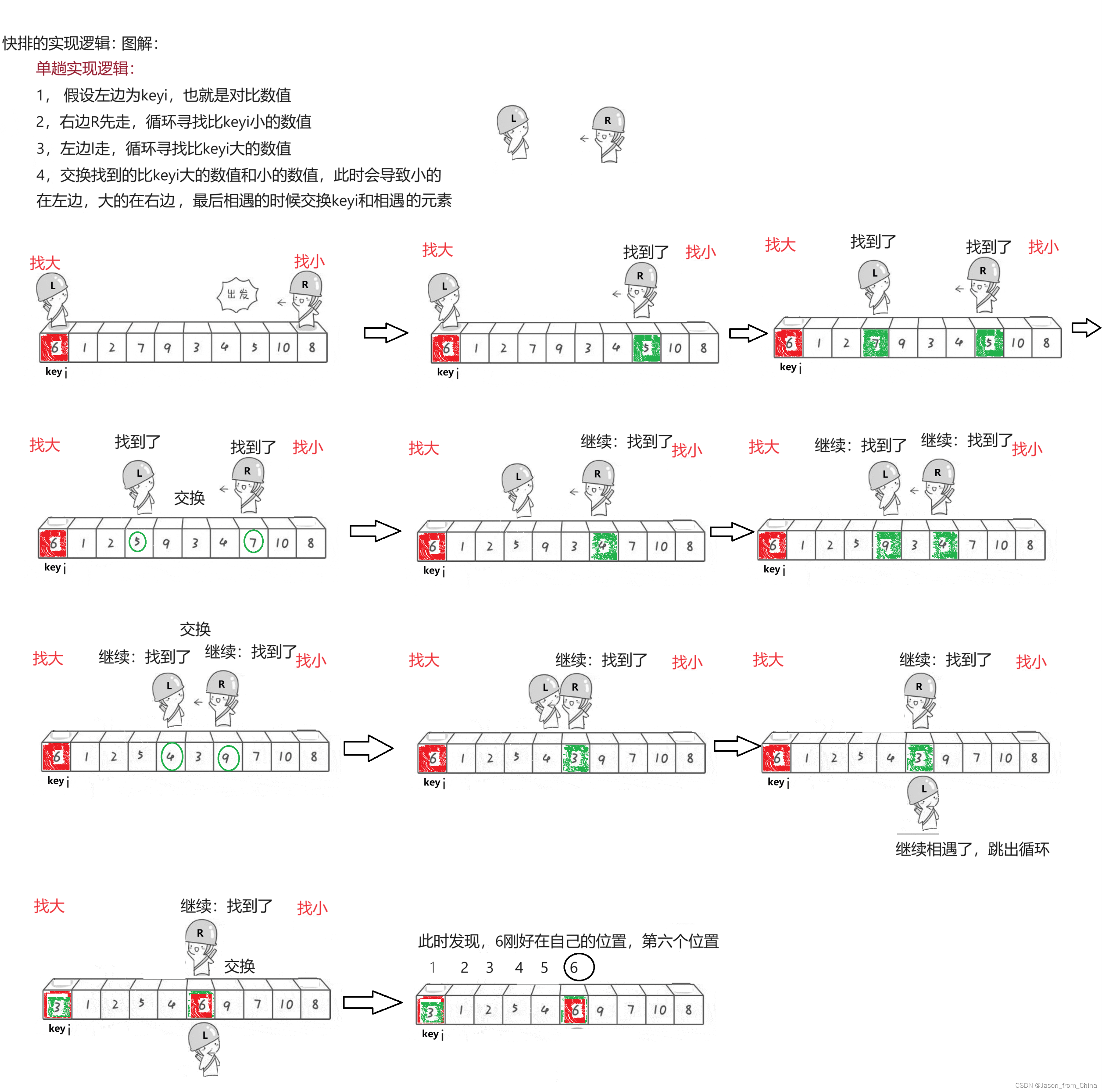
快排单趟实现
快排多趟实现
简易版本的代码实现
//霍尔方法(递归实现) void QuickSort01(int* a, int left, int right) {//递归停止条件if (left >= right)return;//单趟实现//右边找小,左边找大int begin = left; int end = right;int keyi = begin;while (begin < end){//右边找小,不是的话移动,是的话不移动,并且跳出循环while (begin < end && a[keyi] <= a[end]){end--;}//左边找大,不是的话移动,是的话不移动,并且跳出循环while (begin < end && a[keyi] >= a[begin]){begin++;}Swap(&a[begin], &a[end]);}Swap(&a[keyi], &a[begin]);keyi = begin;//多趟递归实现//[left,keyi-1] keyi [keyi+1,right] 这里传递的是区间// 1 0 1 2 1 当只剩一个数值的时候,也就是这个区间的时候,递归停止 QuickSort01(a, left, keyi - 1);QuickSort01(a, keyi + 1, right); }解释:
函数定义:
QuickSort01函数接受一个整数数组的指针a以及两个整数left和right,分别表示要排序的数组部分的起始和结束索引。递归终止条件:如果
left大于或等于right,则当前子数组无需排序,递归结束。初始化:设置两个指针
begin和end分别指向子数组的起始和结束位置,keyi作为基准元素的索引,初始位置设为left。单趟排序:
- 使用两个内层循环,一个从右侧向左寻找比基准值小的元素,另一个从左侧向右寻找比基准值大的元素。
- 当找到合适的元素时,交换这两个元素的位置,然后继续寻找,直到
begin和end相遇。基准值定位:将基准值
a[keyi]与begin指向的元素交换,此时begin指向的位置是基准值的最终位置。递归排序:对基准值左边的子数组
[left, keyi - 1]和右边的子数组[keyi + 1, right]递归调用QuickSort01函数进行排序。效率:快速排序的平均时间复杂度为O(n log n),但在最坏情况下(如数组已经排序)时间复杂度会退化到O(n^2)。霍尔方法通过减少不必要的数据交换来提高排序效率。
辅助函数:
Swap函数用于交换两个元素的值,虽然在代码中未给出定义,但它是快速排序中交换元素的关键操作。快速排序算法的效率和性能在实际应用中通常优于其他O(n log n)算法,如归并排序,尤其是在数据量较大时。然而,其稳定性不如归并排序,且在最坏情况下性能较差。在实际应用中,快速排序通常与其他排序算法结合使用,以提高整体排序性能。
注意事项
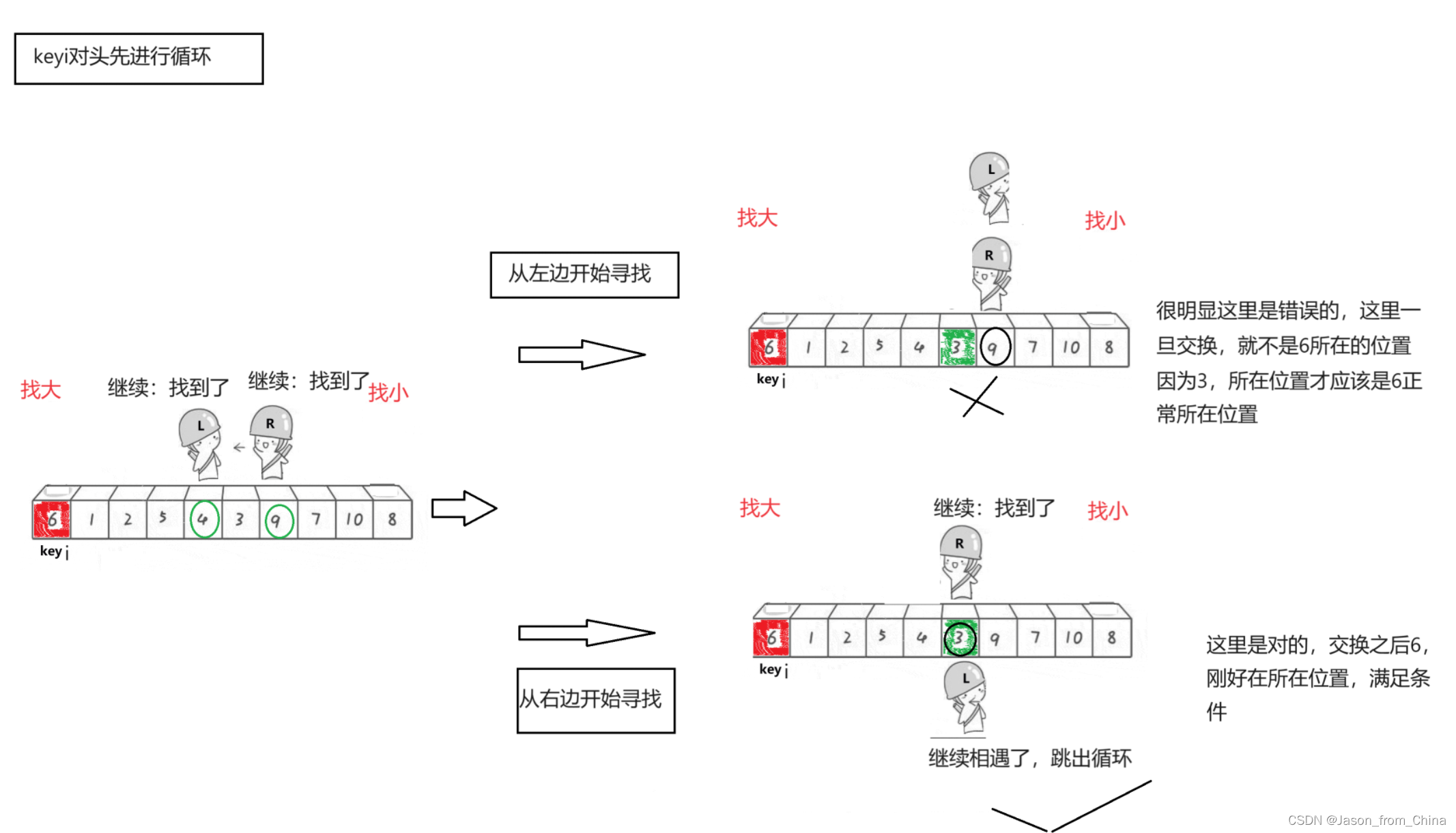
注意事项1
这里有一个关键点是很重要的,也就是我们是从右边先出发的,因为我们的keyi的位置在左边。
如果我们的keyi的下标在左边,并且左边先走的话,就会产生一种结果
如图
注意事项2
不是等于就交换,是等于会跳过往下找
当我们写的是不等于的时候


快排完整代码实现-(三数值取中)
此时存在的最大问题就是如果排序本身就是顺序排序的情况下,这时间复杂度反而高了,所以我们对排序进行修改
//交换函数 void Swap(int* p1, int* p2) {int tmp = *p1;*p1 = *p2;*p2 = tmp; } //霍尔方法(递归实现) //三数取中 int GetMid(int* a, int left, int right) {//三数取中传参的是下标,我们取中也是根据下标进行计算的int mid = (left + right) / 2;if (a[left] < a[right]){if (a[mid] < a[left])//a[mid] < a[left] < a[right]{return left;}else if(a[mid] > a[right])// a[left] < a[right] < a[mid] {return right;}else{return mid;}}else//a[left] > a[right]{if (a[mid] > a[left])//a[mid] > a[left] > a[right]{return left;}else if (a[mid] < a[right])//a[left] > a[right] > a[mid] {return right;}else{return mid;}} } void QuickSort01(int* a, int left, int right) {//递归停止条件if (left >= right)return;//三数取中int mid = GetMid(a, left, right);Swap(&a[mid], &a[left]);//单趟实现//右边找小,左边找大int begin = left; int end = right;int keyi = begin;while (begin < end){//右边找小,不是的话移动,是的话不移动,并且跳出循环while (begin < end && a[keyi] <= a[end]){end--;}//左边找大,不是的话移动,是的话不移动,并且跳出循环while (begin < end && a[keyi] >= a[begin]){begin++;}Swap(&a[begin], &a[end]);}Swap(&a[keyi], &a[begin]);keyi = begin;//多趟递归实现//[left,keyi-1] keyi [keyi+1,right] 这里传递的是区间// 1 0 1 2 1 当只剩一个数值的时候,也就是这个区间的时候,递归停止 QuickSort01(a, left, keyi - 1);QuickSort01(a, keyi + 1, right); }总结:
函数目的:选择一个合适的基准值,以提高快速排序算法的效率。
传入参数:接受一个整数数组的指针
a,以及表示数组部分边界的整数left和right。计算中间索引:通过
(left + right) / 2计算中间元素的索引mid。三数取中逻辑:
- 如果数组的第一个元素
a[left]小于最后一个元素a[right]:
- 如果中间元素
a[mid]小于第一个元素,则选择第一个元素作为基准。- 如果中间元素大于最后一个元素,则选择最后一个元素作为基准。
- 否则,选择中间元素作为基准。
- 如果第一个元素大于或等于最后一个元素(即数组首尾元素已经排序或相等):
- 如果中间元素大于第一个元素,则选择第一个元素作为基准。
- 如果中间元素小于最后一个元素,则选择最后一个元素作为基准。
- 否则,选择中间元素作为基准。
返回值:函数返回基准值的索引。
优化目的:通过三数取中法选择基准,可以减少快速排序在特定情况下性能退化的问题,如数组已经排序或包含大量重复元素。
适用场景:适用于快速排序算法中,作为选择基准值的策略。
性能影响:选择一个好的基准值可以确保数组被均匀地划分,从而接近快速排序的最佳平均时间复杂度O(n log n)。
三数取中法是一种简单而有效的基准选择策略,它通过比较数组的首元素、尾元素和中间元素,来确定一个相对平衡的基准值,有助于提高快速排序的整体性能和稳定性。
快排完整代码实现-(减少递归次数)
此时我们还面临的问题就是底层的递归次数过多的问题,递归会随着次数的增加呈现倍数增长,就像三角形一样
最后我们减少递归次数,把最底层从递归改为插入排序,逻辑完成
快排完整代码
//交换函数 void Swap(int* p1, int* p2) {int tmp = *p1;*p1 = *p2;*p2 = tmp; } //霍尔方法(递归实现) //三数取中 int GetMid(int* a, int left, int right) {//三数取中传参的是下标,我们取中也是根据下标进行计算的int mid = (left + right) / 2;if (a[left] < a[right]){if (a[mid] < a[left])//a[mid] < a[left] < a[right]{return left;}else if(a[mid] > a[right])// a[left] < a[right] < a[mid] {return right;}else{return mid;}}else//a[left] > a[right]{if (a[mid] > a[left])//a[mid] > a[left] > a[right]{return left;}else if (a[mid] < a[right])//a[left] > a[right] > a[mid] {return right;}else{return mid;}} } void QuickSort01(int* a, int left, int right) {//递归停止条件if (left >= right)return;//当区间数值小于10个,此时我们直接采取插入排序进行排序if (right - left + 1 <= 10){//这里记得是左右区间,所以不能只传递a,而是传递a + leftInsertionSort(a + left, right - left + 1);}else{//三数取中int mid = GetMid(a, left, right);Swap(&a[mid], &a[left]);//单趟实现//右边找小,左边找大int begin = left; int end = right;int keyi = begin;while (begin < end){//右边找小,不是的话移动,是的话不移动,并且跳出循环while (begin < end && a[keyi] <= a[end]){end--;}//左边找大,不是的话移动,是的话不移动,并且跳出循环while (begin < end && a[keyi] >= a[begin]){begin++;}Swap(&a[begin], &a[end]);}Swap(&a[keyi], &a[begin]);keyi = begin;//多趟递归实现//[left,keyi-1] keyi [keyi+1,right] 这里传递的是区间// 1 0 1 2 1 当只剩一个数值的时候,也就是这个区间的时候,递归停止 QuickSort01(a, left, keyi - 1);QuickSort01(a, keyi + 1, right);} }代码解释:
三数取中函数
GetMid:
- 计算中间索引
mid。- 通过比较数组的首元素、尾元素和中间元素,选择一个合适的基准值。
- 如果首元素小于尾元素,选择中间元素和首尾元素中较小或较大的一个作为基准。
- 如果首元素大于尾元素,选择中间元素和首尾元素中较大或较小的一个作为基准。
快速排序函数
QuickSort01:
- 递归停止条件:如果当前区间的左右索引
left和right交叉或重合,则不需要排序。- 当区间大小小于或等于10时,使用插入排序,因为小数组上插入排序更高效。
- 使用
GetMid函数获取基准值的索引,并将基准值与首元素交换。- 霍尔方法的分区操作,通过两个指针
begin和end进行分区。- 递归地对基准值左边和右边的子区间进行快速排序。
辅助函数
Swap:
- 交换两个元素的值,虽然代码中未给出定义,但通常是一个简单的值交换操作。
总结:
- 算法优化: 通过三数取中法选择基准值,可以提高基准值的选中质量,从而提高快速排序的效率。
- 小数组优化: 当子数组的大小,小于或等于10时,使用插入排序代替快速排序,因为小数组上插入排序的性能通常更好。
- 递归与迭代: 快速排序是一个递归算法,但在小数组上切换到迭代的插入排序可以减少递归开销。
- 分区策略: 使用霍尔方法进行分区,这是一种高效的分区策略,可以减少不必要的数据交换。
- 适用场景: 这种改进的快速排序适用于大多数需要排序的场景,尤其是在大数据集上,它能够保持较好的性能。
- 时间复杂度: 平均情况下时间复杂度为 O(n log n),最坏情况下(已排序数组)时间复杂度为 O(n^2),但由于三数取中法和插入排序的结合,最坏情况出现的概率降低。
通过这种改进,快速排序算法在处理小数组时更加高效,同时在大数据集上也能保持较好的性能,使其成为一种更加健壮的排序算法。
快排的时间复杂度
快速排序算法的时间复杂度取决于分区过程中基准值的选择。
理想情况下
基准值会将数组均匀地分成两部分,每部分的元素数量大致相等。对于这种理想情况,快速排序的时间复杂度是 O(n log n),其中 n 是数组中的元素数量。
最坏情况下
如果基准值的选择非常不均匀,从而导致每次分区都极不平衡,快速排序的最坏时间复杂度会退化到 O(n^2)。这种情况通常发生在数组已经排序或所有元素相等的情况下。
在当前代码中
使用了三数取中法来选择基准值,这种方法可以在大多数情况下避免选择极端值作为基准,从而减少最坏情况发生的概率。但是,如果数组的元素分布非常不均匀,或者存在大量重复元素,仍然可能遇到性能退化的情况。
此外,代码中还引入了一个优化:当子数组的大小小于或等于10时,使用插入排序而不是快速排序。这是因为对于小数组,插入排序的性能通常比快速排序更好,而且插入排序是稳定的。这个优化可以提高算法在处理小数组时的效率。
总的来说,这个改进的快速排序算法的平均时间复杂度是 O(n log n),但在最坏情况下仍然是 O(n^2)。然而,由于三数取中法和插入排序的优化,最坏情况的发生概率被大大降低了。在实际应用中,这种改进的快速排序算法通常能够提供非常高效的排序性能。
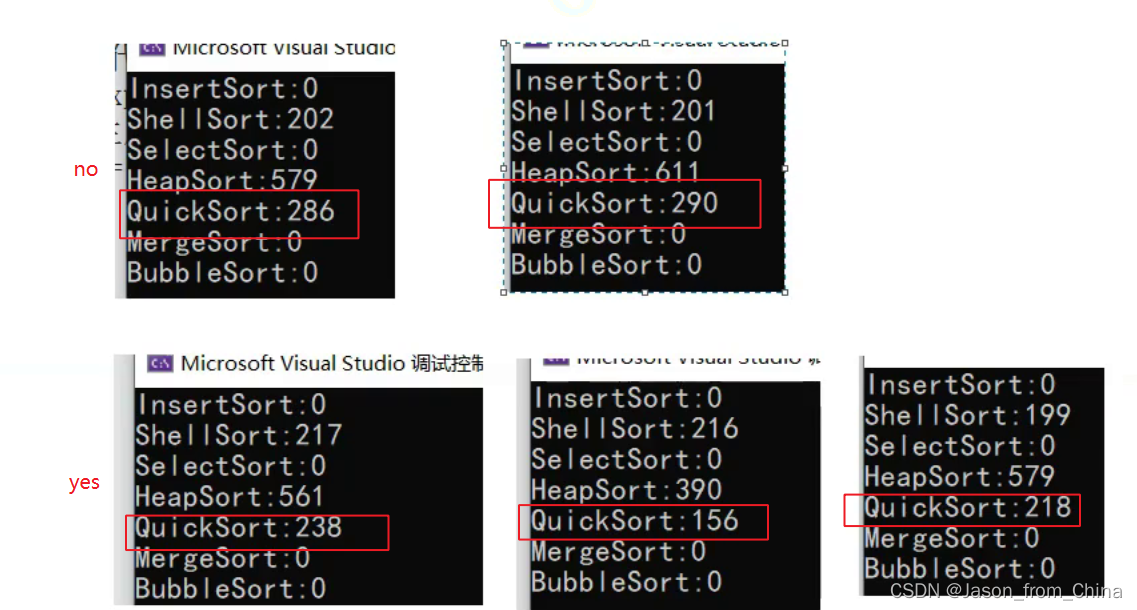
前后修改之后速度进行对比
优化,和不优化之间的区别
这里计算的是一千万个数值进行排序的毫秒数值,也就是不到一秒,还是很快的,尤其是修改之后,解决了大量的递归问题
注意事项
这里调用的插入排序是升序,写的快排也是升序,如果你需要测试降序,那么你需要把插入排序一起改成降序,不然会导致排序冲突
快排(前后指针-递归解决)
前言
快排解决办法有很多种,这里我再拿出来一种前后指针版本
虽然这个版本的时间复杂度和霍尔一样,逻辑也差不多,但是实际排序过程,确实会比霍尔慢一点
快排gif
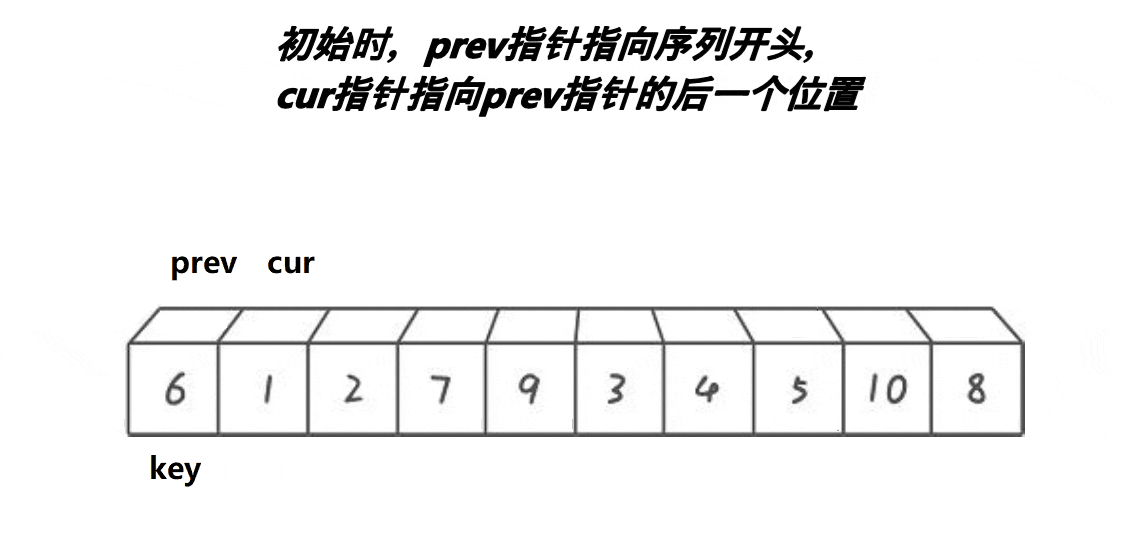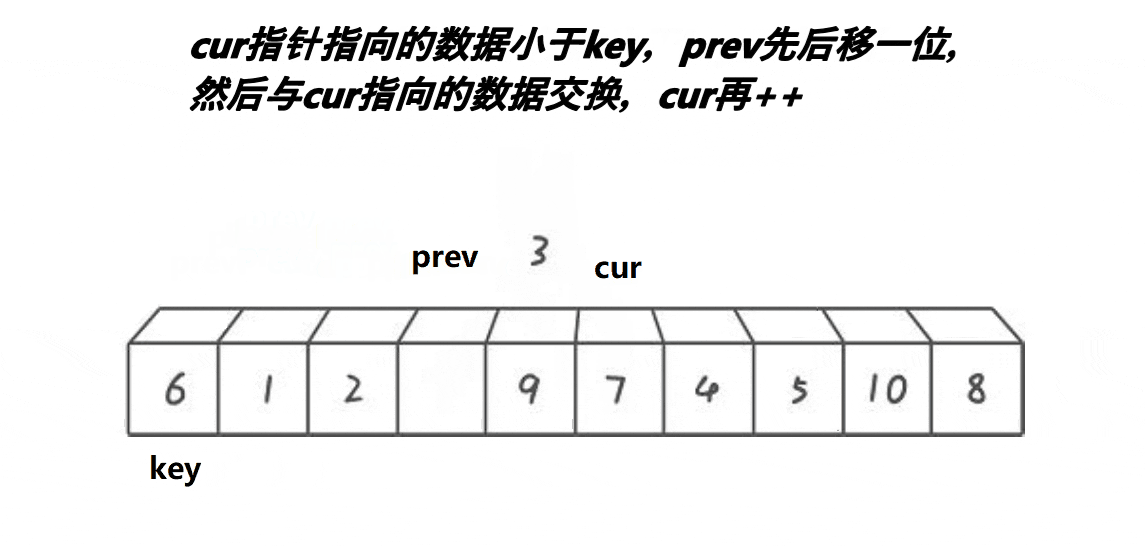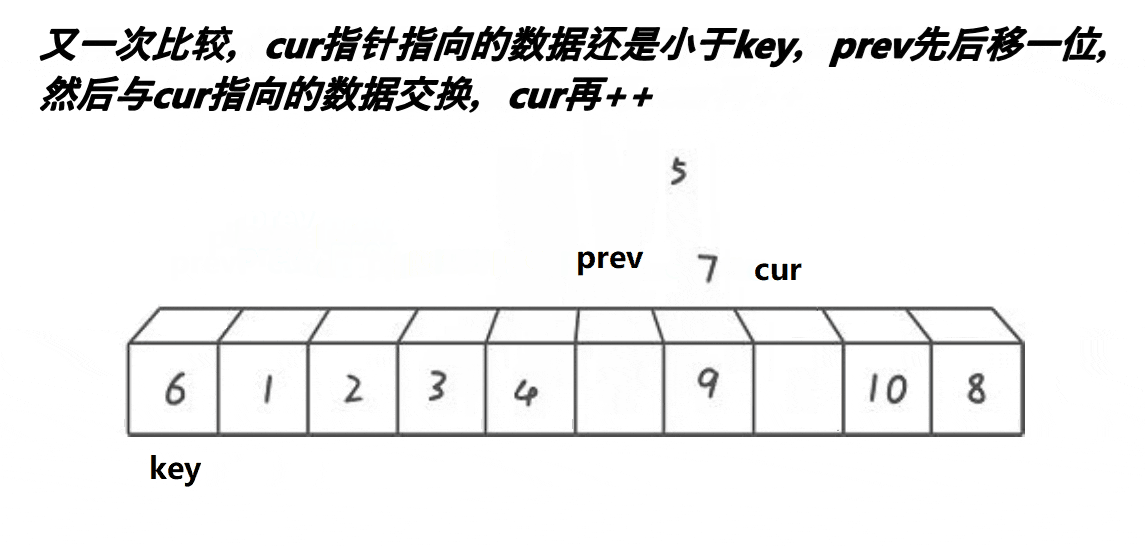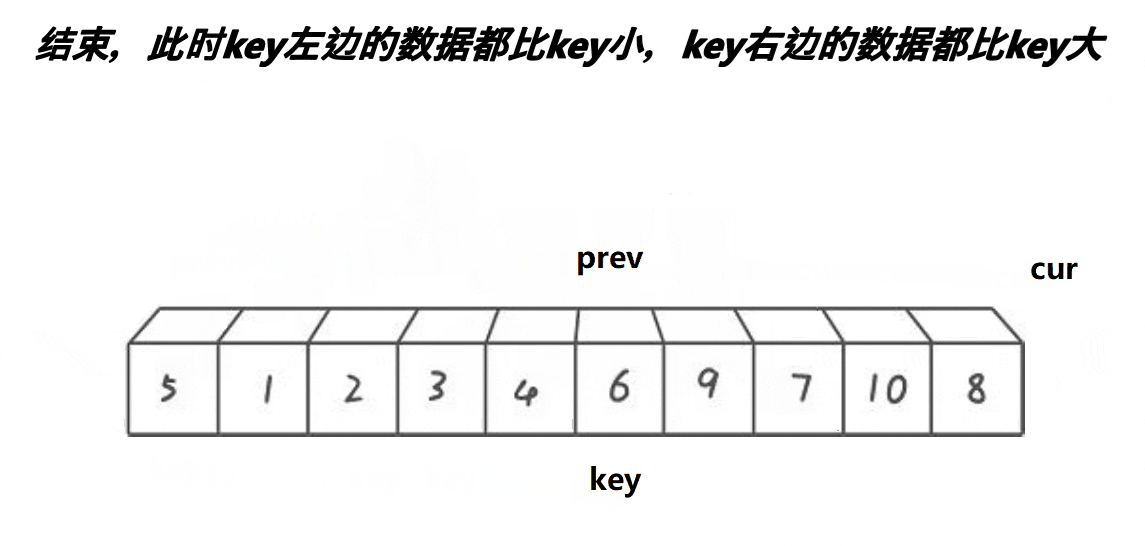
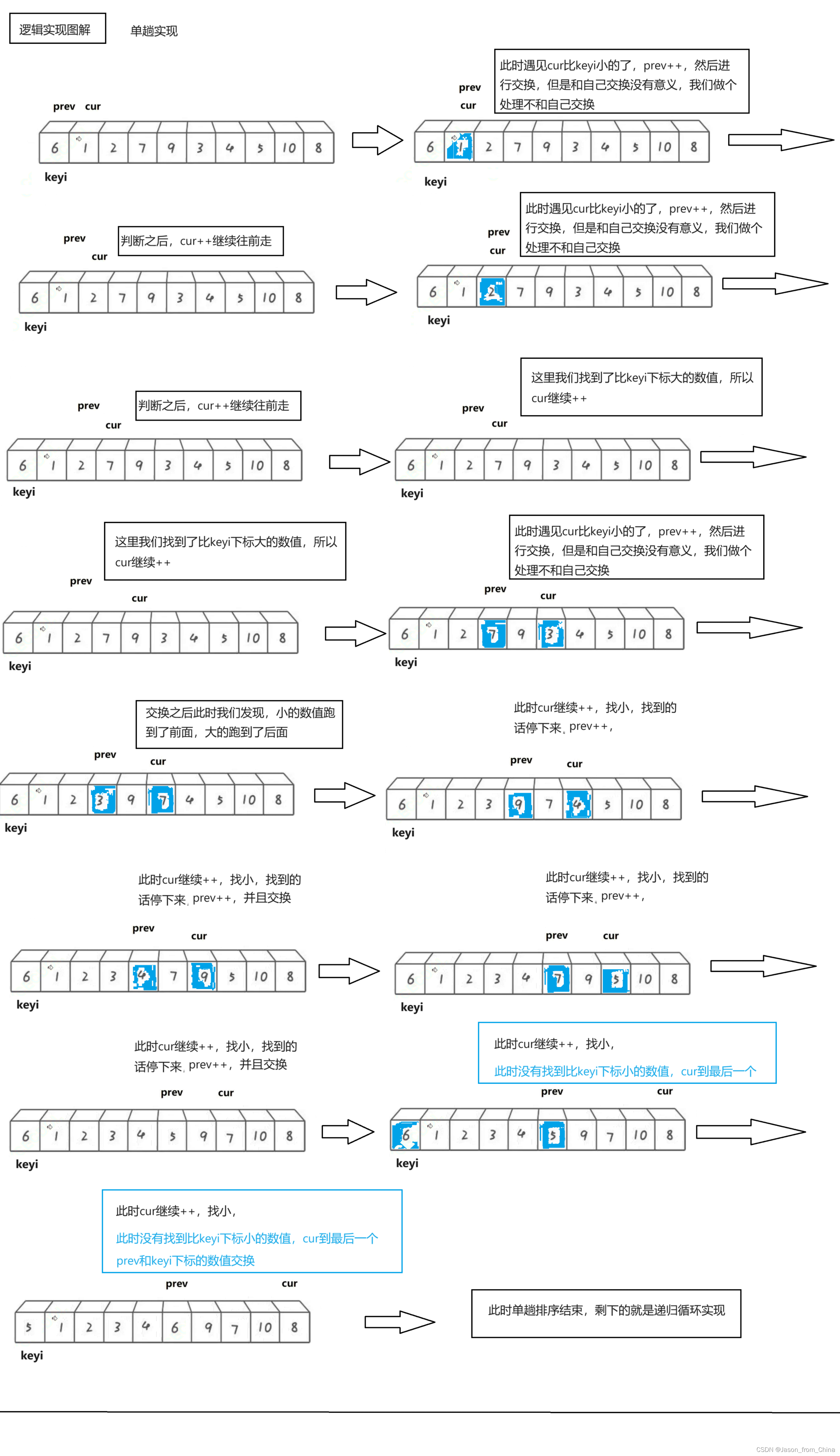
快排前后指针实现逻辑:
前后指针实现逻辑(升序):
单趟排序:
1,我们使用递归来进行实现,所以我们先实现单趟排序
2,定义两个下标,也就是所谓的指针,初始的时候,一个指向最左边第一个元素(prev),一个指向第二个元素(cur),最后定义一个对比keyi3,此时先判断我们的cur是不是小于keyi。cur小于keyi的话:prev++,交换,之后cur++4,但是我们如果和自己交换此时没有什么意义,所以这里我们需要做一个处理
5,继续往前走,如果遇见的是:比keyi下标大的元素此时,cur++,直到遇见的是比keyi下标小的元素,循环执行.prev++,交换,之后cur++6,最后cur走到最后一个元素,我们交换keyi的下标元素和prev的下标元素
多趟实现:
1,递归进行分割:【left,keyi-1】keyi【keyi+1,right】
2,停止条件就是当left>=right
原因:【left, keyi-1】keyi【keyi+1, right】

快排单趟实现
这里只是图解单趟实现逻辑,因为多趟实现的逻辑和霍尔的一样,也是递归,所以不进行多次书写
代码实现
这里的代码实现的核心逻辑不一样,大的框架是一样的,也就是三数取中,以及减少递归从而使用插入排序这样的逻辑是一样的,下面我们来看看这个新的组装怪
//快排(前后指针方法)(递归实现) void QuickSort02(int* a, int left, int right) {//递归停止条件if (left >= right)return;//创建两个变量,作为前后指针使用int prev = left; int cur = prev + 1;int keyi = left;//当快指针到尾的时候,跳出循环->交换while (cur <= right){//前后指针中间是比a[keyi]大的数值,所以遇见大的++,小的停止if (a[keyi] > a[cur]){//停止之后,慢指针++,并且进行交换,因为中间才是大的数值,cur遇见大数值++。遇见小数值才停下来prev++;Swap(&a[prev], &a[cur]);//同理快指针也进行++,往后移动cur++;}else{cur++;}}Swap(&a[prev], &a[keyi]);keyi = prev;//多趟递归实现//[left,keyi-1] keyi [keyi+1,right] 这里传递的是区间// 1 0 1 2 1 当只剩一个数值的时候,也就是这个区间的时候,递归停止 QuickSort02(a, left, keyi - 1);QuickSort02(a, keyi + 1, right); }总结:
算法基础:快速排序是一种分而治之的排序算法,它通过递归地将数组分为较小的子数组,然后对这些子数组进行排序。
分区策略:使用前后指针(
prev和cur)进行分区,而不是传统的左右指针。这种方法在某些情况下可以减少元素交换的次数。基准值选择:基准值(
keyi)是数组的第一个元素,即left索引对应的元素。指针移动规则:
prev作为慢指针,用于跟踪比基准值小的元素的边界。cur作为快指针,从left + 1开始遍历数组。元素交换:当快指针指向的元素大于基准值时,不进行交换,快指针继续移动;当快指针指向的元素小于或等于基准值时,与慢指针所指元素交换,然后慢指针和快指针都向前移动。
递归排序:在基准值确定之后,递归地对基准值左边和右边的子数组进行排序。
时间复杂度:平均情况下,快速排序的时间复杂度为O(n log n)。最坏情况下,如果每次分区都极不平衡,时间复杂度会退化到O(n^2)。
空间复杂度:由于递归性质,快速排序的空间复杂度为O(log n)。
算法优化:通过前后指针方法,可以在某些情况下提高快速排序的性能,特别是当基准值接近数组中间值时。
适用场景:快速排序适用于大多数需要排序的场景,特别是在大数据集上,它通常能够提供非常高效的排序性能。
优化
这里我们可以看到,cur无论是if还是else里面都需要++,所以我们直接放到外面
其次我们为了效率,不和自己交换,我们不和自己交换,进行一个判断条件

快慢指针代码优化(完整)
//交换函数 void Swap(int* p1, int* p2) {int tmp = *p1;*p1 = *p2;*p2 = tmp; } //快排(前后指针方法)(递归实现) void QuickSort02(int* a, int left, int right) {//递归停止条件if (left >= right)return;if (right - left + 1 >= 10){InsertionSort(a + left, right - left + 1);}else{//三数取中int mid = GetMid(a, left, right);Swap(&a[mid], &a[left]);//单趟实现//创建两个变量,作为前后指针使用int prev = left; int cur = prev + 1;int keyi = left;//当快指针到尾的时候,跳出循环->交换while (cur <= right){//前后指针中间是比a[keyi]大的数值,所以遇见大的++,小的停止if (a[keyi] > a[cur] && prev++ != cur){//停止之后,慢指针++,并且进行交换,因为中间才是大的数值,cur遇见大数值++。遇见小数值才停下来Swap(&a[prev], &a[cur]);}cur++;}Swap(&a[prev], &a[keyi]);keyi = prev;//多趟递归实现//[left,keyi-1] keyi [keyi+1,right] 这里传递的是区间// 1 0 1 2 1 当只剩一个数值的时候,也就是这个区间的时候,递归停止 QuickSort02(a, left, keyi - 1);QuickSort02(a, keyi + 1, right);} }总结:
基本递归结构:算法使用递归调用来处理子数组,这是快速排序算法的核心结构。
小数组优化:当子数组的大小小于或等于10时,算法使用插入排序而不是快速排序,因为插入排序在小规模数据上更高效。
三数取中法:为了更均匀地分割数组,算法使用三数取中法选择基准值,这有助于减少最坏情况发生的概率。
前后指针方法:算法使用两个指针(
prev和cur),其中prev作为慢指针,cur作为快指针,通过这种方式进行一次遍历完成分区。分区操作:快指针从
left + 1开始遍历,如果当前元素小于基准值,则与慢指针所指的元素交换,然后慢指针向前移动。递归排序子数组:基准值确定后,算法递归地对基准值左边和右边的子数组进行排序。
时间复杂度:平均情况下,算法的时间复杂度为O(n log n),最坏情况下为O(n^2)。但由于采用了小数组优化和三数取中法,最坏情况的发生概率降低。
空间复杂度:算法的空间复杂度为O(log n),这主要由于递归调用导致的栈空间使用。
适用场景:这种改进的快速排序算法适用于大多数需要排序的场景,尤其是在大数据集上,它能够提供非常高效的排序性能,同时在小数据集上也表现出较好的效率。
算法稳定性:由于使用了插入排序对小规模子数组进行排序,算法在处理小规模数据时具有稳定性。
注意:在实际测试·里面,前后指针比霍尔排序慢一点
通过这种混合排序策略,算法在保持快速排序优点的同时,也提高了在特定情况下的排序效率,使其成为一种更加健壮的排序方法。
注意事项
这里调用的插入排序是升序,写的快排也是升序,如果你需要测试降序,那么你需要把插入排序一起改成降序,不然会导致排序冲突
快排(霍尔版本-非递归解决)
前言
快拍不仅需要学习递归,还需要学东西非递归,这样更有助于我们理解快拍
首先我们需要知道,非递归的学习需要使用栈,所以如果我们的栈的学习是不完善的,建议学习一下栈
非递归gif
这里其实单词循环是谁其实不重要,可以是前后指针,也可以是霍尔方式,这里我们拿出来霍尔的gif来观看
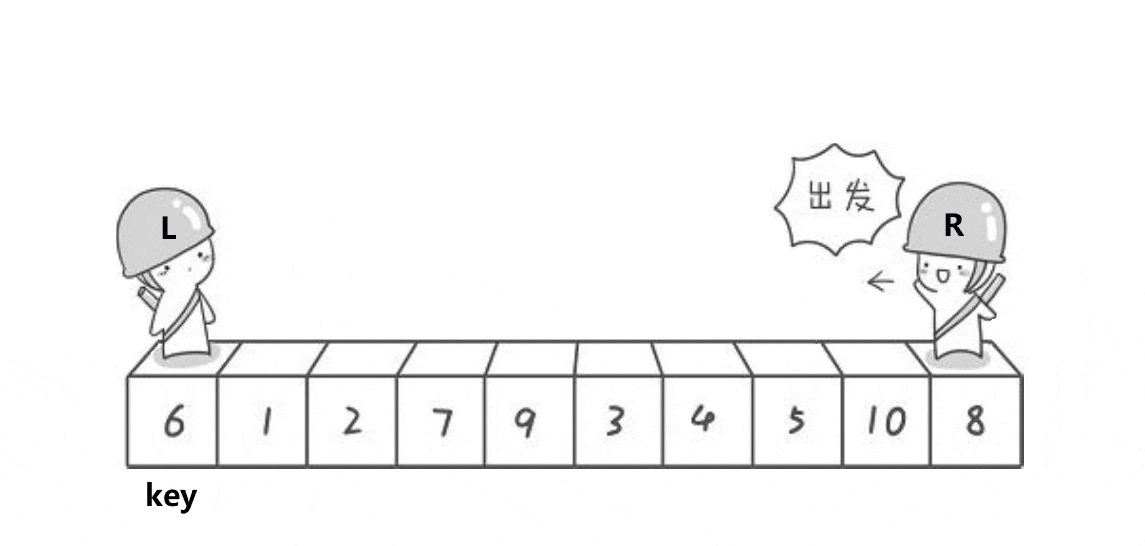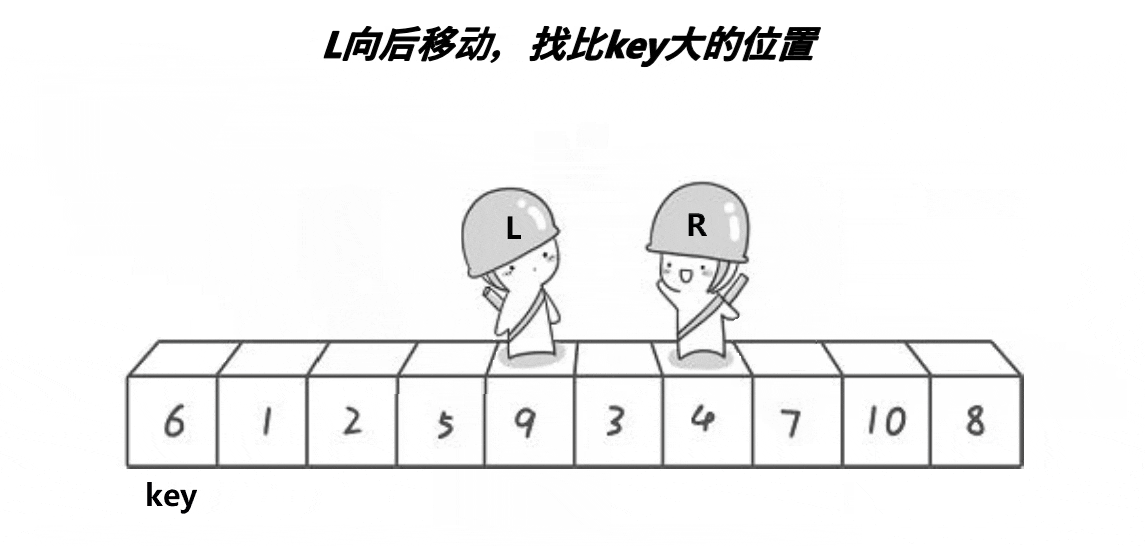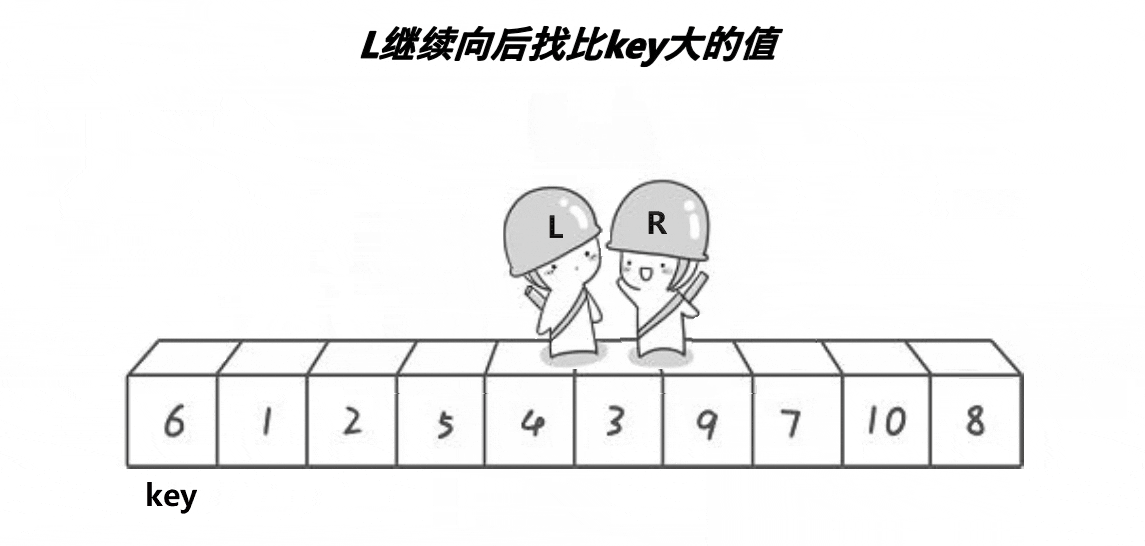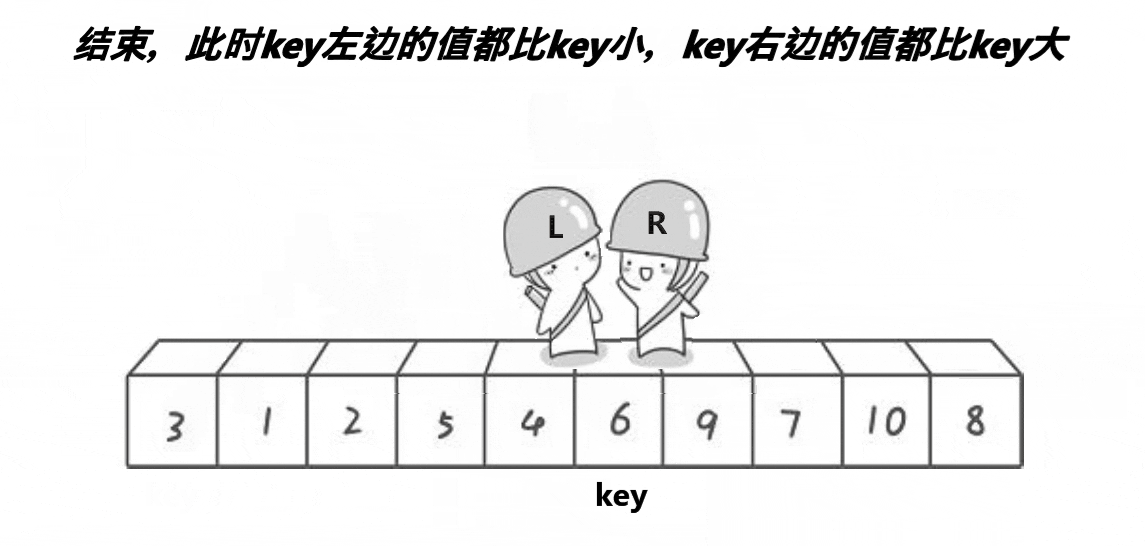
实现图解
非递归实现主要是依赖栈来进行实现,依赖栈的特点,先进后出,后进前出
1,首先我们需要写一个栈的库进行调用
2,入区间,调用单次排序的实现思路
3,入区间的时候,我们需要把握入栈和出栈的关键
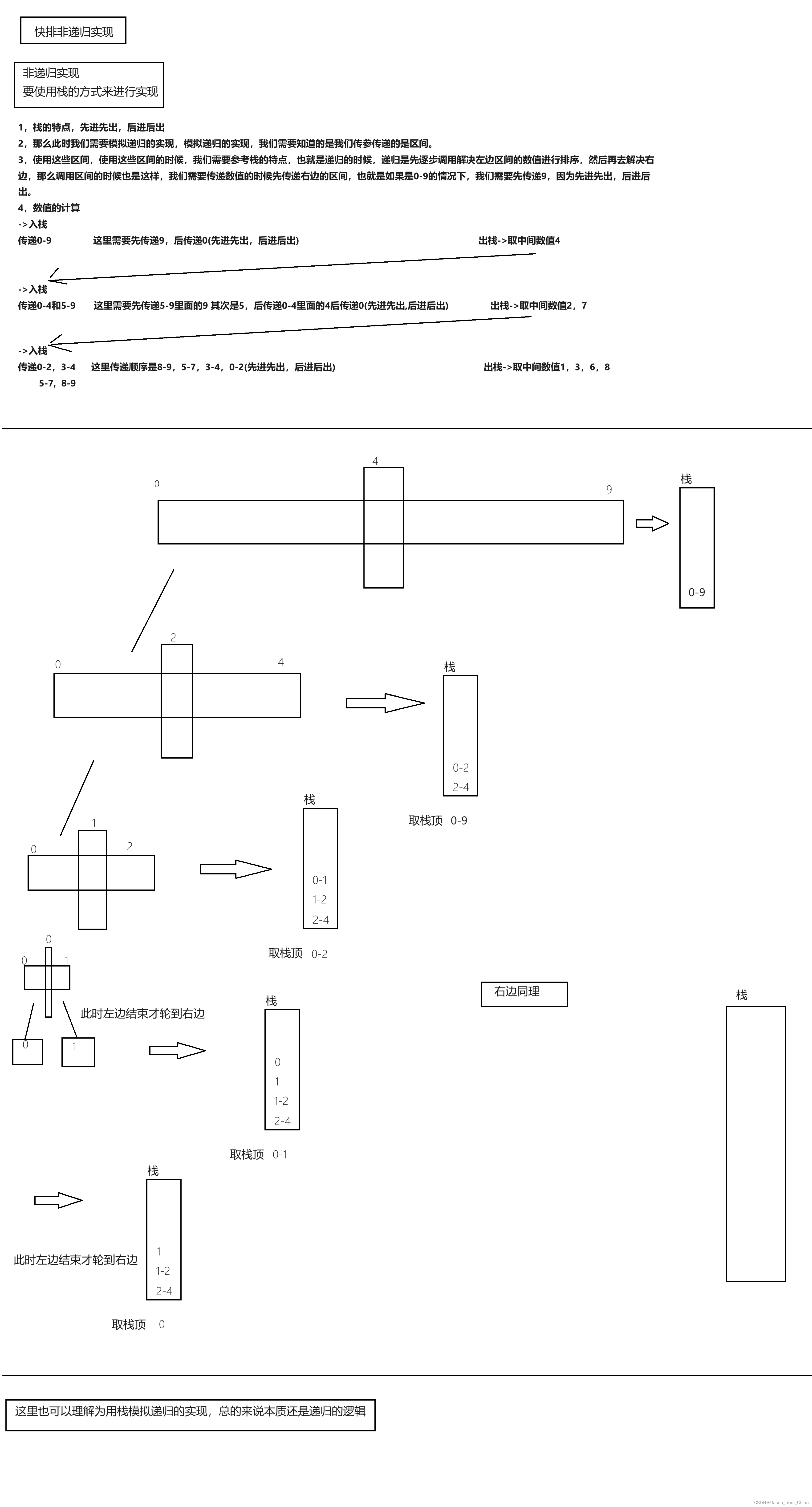
代码实现(前后指针)
首先我们调用栈
头文件
#define _CRT_SECURE_NO_WARNINGS 1 #pragma once #include<stdio.h> #include<assert.h> #include<stdlib.h> typedef int STDataType; typedef struct Stack {STDataType* _a; // 首元素的地址int _top; // 栈顶,初始化为0,也就是等同于size,初始化为-1,等同于下标int _capacity; // 容量 }Stack; // 初始化栈 void StackInit(Stack* ps); // 销毁栈 void StackDestroy(Stack* ps); // 入栈 void StackPush(Stack* ps, STDataType data); // 出栈 void StackPop(Stack* ps); // 获取栈顶元素 STDataType StackTop(Stack* ps); // 获取栈尾元素 STDataType Stackhop(Stack* ps); // 获取栈中有效元素个数 int StackSize(Stack* ps); // 检测栈是否为空,如果为空返回非零结果,如果不为空返回0 int StackEmpty(Stack* ps);实现文件
#include"Stack.h" // 初始化栈 void StackInit(Stack* ps) {ps->_a = NULL;ps->_capacity = ps->_top = 0; } // 销毁栈 void StackDestroy(Stack* ps) {assert(ps && ps->_top);free(ps->_a);ps->_a = NULL;ps->_capacity = ps->_top = 0; }// 入栈 void StackPush(Stack* ps, STDataType data) {//判断需不需要扩容,相等的时候需要扩容if (ps->_capacity == ps->_top){//判断空间是不是0,因为为0的时候,再多的数值*2,也是0int newcapacity = ps->_capacity == 0 ? 4 : ps->_capacity * 2;STDataType* tmp = (STDataType*)realloc(ps->_a, sizeof(STDataType) * newcapacity);if (tmp == NULL){perror("StackPush:tmp:err:");return;}ps->_capacity = newcapacity;ps->_a = tmp;}ps->_a[ps->_top] = data;ps->_top++; }// 出栈 void StackPop(Stack* ps) {assert(ps);ps->_top--; } // 获取栈顶元素 STDataType StackTop(Stack* ps) {//这里必须大于0 因为我们这里等同size,也就是个数,等于0都不行assert(ps);return ps->_a[ps->_top - 1]; } // 获取栈尾元素 STDataType Stackhop(Stack* ps) {assert(ps && ps->_top > 0);return ps->_a[0]; } // 获取栈中有效元素个数 int StackSize(Stack* ps) {//获取有效元素的时候,里面可以没有元素assert(ps);return ps->_top; } // 检测栈是否为空,如果为空返回非零结果,如果不为空返回0 int StackEmpty(Stack* ps) {//这里的判断是不是空,也就是里面是不是有数值,这里等于是一个判断,没有的话返回ture,有的话返回falseassert(ps);return ps->_top == 0; }其次调用前后指针来实现
//快排(前后指针方法)(单趟) int one_QuickSort02(int* a, int left, int right) {//三数取中//int mid = GetMid(a, left, right);//Swap(&a[mid], &a[left]);//单趟实现//创建两个变量,作为前后指针使用int prev = left; int cur = prev + 1;int keyi = left;//当快指针到尾的时候,跳出循环->交换while (cur <= right){//前后指针中间是比a[keyi]大的数值,所以遇见大的++,小的停止if (a[keyi] > a[cur] && prev++ != cur){//停止之后,慢指针++,并且进行交换,因为中间才是大的数值,cur遇见大数值++。遇见小数值才停下来Swap(&a[prev], &a[cur]);}cur++;}Swap(&a[keyi], &a[prev]);return prev; //快排 非递归实现 void QuickSort003(int* a, int left, int right) {//非递归实现主要是用栈来模拟实现,在c++里面我们可以直接调用栈,但是在C语言里面我们只能写出来栈再进行调用//思路(霍尔方式)//1单趟的思路还是一样的,如果是升序的情况下,依旧是先从右边出发(找小),后从左边出发(找大)//2,循环递归过程我们改为利用进栈出栈来实现。首先我们需要明确这里传递的是区间,也就是利用栈实现的时候,我们传递的是数组和区间,利用区间进行计算。这里的关键在于传递区间的时候,我们需要详细知晓栈的特点,先进后出,后进后出,。所以在传递区间的时候,如果多趟循环,一分为二的时候,我们需要先传递右侧的区间,再传递左侧区间,因为我们需要先计算左侧。同理进去之后,我们需要继续入栈,需要先-入计算左侧的区间的右侧区间,后入左侧区间。这样就会先计算左侧区间。栈的特性,先进后出,后进先出// // 所以这里我们把霍尔排序单趟实现来单独拿出来,这样的话我们接受的返回值是中间值//[left,keyi-1] keyi [keyi+1,right]//这里需要用非递归来解决Stack ps;StackInit(&ps);StackPush(&ps, right);StackPush(&ps, left);while (!StackEmpty(&ps)){int begin = StackTop(&ps);StackPop(&ps);int end = StackTop(&ps);StackPop(&ps);//假设入栈区间此时来到-> 0-2int mini = one_QuickSort02(a, begin, end);//经过计算之后,此时中间值是,keyi=1//0 1 2 三个区间三个数值,此时进行入栈判断//[begin,keyi-1]keyi[keyi+1,end]//[ 0 , 0 ] 1 [ 2 , 2 ]//所以不继续入栈if (mini + 1 < end){//右边先入栈,后计算StackPush(&ps, end);StackPush(&ps, mini + 1);}if (mini - 1 > begin){//左边区间后入栈,先计算StackPush(&ps, mini - 1);StackPush(&ps, begin);}}StackDestroy(&ps); }解释:
one_QuickSort02函数这个函数是快速排序算法中的单趟排序实现。它使用前后指针法来实现,具体步骤如下:
- 初始化指针:
prev初始化为left,cur初始化为prev + 1,keyi也初始化为left。- 循环:当
cur小于等于right时,执行循环体内的操作。- 比较和交换:如果当前
cur指向的元素小于keyi指向的元素,并且prev指针不等于cur,说明找到了一个比基准值小的元素,需要交换。将a[prev]和a[cur]交换,并将prev指针向前移动一位。- 移动快指针:无论是否发生交换,
cur指针都向前移动一位。- 交换基准值:循环结束后,将
keyi指向的元素与prev指向的元素交换,此时prev指向的是比基准值小的元素的最后一个位置。- 返回值:函数返回
prev的值,这个值是下一次分区的起始位置。
QuickSort003函数这个函数是快速排序的非递归实现,使用栈来模拟递归过程。具体步骤如下:
- 初始化栈:创建并初始化一个栈
ps。- 入栈:将
left和right作为初始区间入栈。- 循环:只要栈不为空,就执行循环。
- 单趟排序:每次从栈中取出两个值作为区间的左右边界,调用
one_QuickSort02函数进行单趟排序,得到中间值mini。- 判断区间:根据
mini的位置,判断是否需要继续对左右区间进行排序。
- 如果
mini + 1 < end,则说明右侧还有元素需要排序,将end和mini + 1入栈。- 如果
mini - 1 > begin,则说明左侧还有元素需要排序,将begin和mini - 1入栈。- 出栈:每次循环结束,都会从栈中弹出两个值,直到栈为空。
- 销毁栈:循环结束后,销毁栈。
对于栈和队列不是很明白的,推荐看一下栈和队列篇章
数据结构-栈和队列(速通版本)-CSDN博客
代码实现(霍尔排序)
这里其实不管是前后指针,还是霍尔排序,其实都是一样的,因为本质上都是让数值到应该到的位置,所以本质上是一样的,这里我再调用一个霍尔的方式是因为一方面和前后指针的调用形成对比,一方面有不同的注释
//交换函数 void Swap(int* p1, int* p2) {int tmp = *p1;*p1 = *p2;*p2 = tmp; } //霍尔方法(单趟实现) int one_QuickSort01(int* a, int left, int right) {//三数取中int mid = GetMid(a, left, right);Swap(&a[mid], &a[left]);//单趟实现//右边找小,左边找大int begin = left; int end = right;int keyi = begin;while (begin < end){//右边找小,不是的话移动,是的话不移动,并且跳出循环while (begin < end && a[keyi] <= a[end]){end--;}//左边找大,不是的话移动,是的话不移动,并且跳出循环while (begin < end && a[keyi] >= a[begin]){begin++;}Swap(&a[begin], &a[end]);}Swap(&a[keyi], &a[begin]);return begin; } //霍尔方法再次调用 void QuickSort03(int* a, int left, int right) {Stack ps;StackInit(&ps);StackPush(&ps, right);StackPush(&ps, left);while (!StackEmpty(&ps)){//取出左区间int begin = StackTop(&ps);StackPop(&ps);//取出右边区间int end = StackTop(&ps);StackPop(&ps);int mini = one_QuickSort01(a, begin, end);//计算区间//假设传递的区间是2-4 --->>> 传递过来的数值也就是下标是(1)4-2=2/2=1 --->>>此时mini=2,也就是此时我们返回的数值要么是第一个数值,要么的第二个数值的下标,不管是哪个,此时都会变成一个数值//此时我们继续入栈,入栈的是mini+1 也就是3-4,继续传递区间,此时传递回来的mini还是3,但是此时3+4==4了 所以不继续入栈,因为数值只有一个,不是区间了//右区间入栈,后出if (mini + 1 < end){//入右边,之后左边,这样取的时候栈顶先取左边,之后右边StackPush(&ps, end);StackPush(&ps, mini + 1);}//左区间入栈,先出if (mini - 1 > begin){StackPush(&ps, mini - 1);StackPush(&ps, begin);}}StackDestroy(&ps); }解释:
one_QuickSort01函数这个函数是霍尔快速排序算法的单趟实现,具体步骤如下:
- 三数取中:使用
GetMid函数找到数组a中间位置的元素,并将其与数组第一个元素交换(left索引位置的元素)。- 初始化指针:
begin初始化为left,end初始化为right,keyi初始化为begin。- 循环:使用
while循环,只要begin小于end,就继续执行循环。- 右边找小:从
end向begin扫描,找到第一个小于基准值a[keyi]的元素。如果找到,end指针向前移动,否则跳出循环。- 左边找大:从
begin向end扫描,找到第一个大于基准值a[keyi]的元素。如果找到,begin指针向后移动,否则跳出循环。- 交换元素:将找到的两个元素
a[begin]和a[end]交换位置。- 基准值交换:循环结束后,将
keyi指向的元素与begin指向的元素交换,此时begin指向的是基准值的正确位置。- 返回值:函数返回
begin的值,这个值是下一次分区的起始位置。
QuickSort03函数这个函数是快速排序的非递归实现,使用栈来模拟递归过程:
- 初始化栈:创建并初始化一个栈
ps。- 入栈:将初始区间的左右边界
left和right入栈。- 循环:只要栈不为空,就继续执行循环。
- 单趟排序:每次从栈中取出两个值作为区间的左右边界,调用
one_QuickSort01函数进行单趟排序,得到中间值mini。- 计算新区间:根据
mini的位置,计算新的左右区间。
- 如果
mini + 1 < end,则说明右侧还有元素需要排序,将end和mini + 1入栈。- 如果
mini - 1 > begin,则说明左侧还有元素需要排序,将begin和mini - 1入栈。- 栈的特性:由于栈是后进先出(LIFO)的数据结构,所以先入栈的是右侧区间,后入栈的是左侧区间,这样在出栈时,会先处理左侧区间,再处理右侧区间。
- 销毁栈:循环结束后,销毁栈。
这种非递归实现的快速排序算法利用了栈的特性来避免递归调用,从而减少了函数调用的开销,并且在处理大数据集时,可以避免递归深度过大导致的栈溢出问题。
归并排序 (递归实现)
前言
归并排序是一种逻辑很简单,但是实现有点难度的排序,尤其是非递归,对于区间的把握更是需要一点逻辑的推导,但是没有关系,轻松拿捏
归并排序gif

归并排序单趟实现
1,创建tmp数组,
2,递归到最小值进行排序,同时拷贝到题目破数组里面
3,这里的关键逻辑实现是,递归回来的时候进行排序
4,最后我们把数值重新拷贝回去原数组
注意:这里的取值我们直接取中间值进行递归,一分为二
代码实现注意事项
关于创建tmp数组,我们需要创建的数组应该是等大的,要么就进行初始化。
- 因为我们是malloc出来的空间,
- 为什么malloc出来的空间必须是等大的,因为这里我们用的是Visual Studio 2022的编译器,这个编译器里面是不支持可变长数组的。所以我们需要用malloc,或者realloc来实现创建空间,也就是动态内存的分配
- malloc创建空间的时候,空间里面是有随机值的
- realloc创建的空间里面的数值是0
- 所以一旦我们进行排序的时候,如果我们不进行覆盖的话,这里面的数值也会参与排序,从而导致数值出现偏差
这里对于这一点不清楚的可以看看之前写的文章,因为当时写这个文章的时候,刚接触编程,所以讲述的主要是以语法和一些简单的性质特点,希望可以起到帮助
- 动态内存函数的使用和综合实践-malloc,free,realloc,calloc_内存申请函数-CSDN博客
代码实现
//归并排序(递归实现)子函数(实现函数) void _MergeSort01(int* a, int* tmp, int begin, int end) {if (begin >= end)return;int mini = (begin + end) / 2;//注意,这里关键在于,区间的传递,//不应该传递【left,mini-1】【mini,right】// 应该传递【left,mini】【mini+1,right】//递归左右区间, 递归到最小个数进行对比_MergeSort01(a, tmp, begin, mini);_MergeSort01(a, tmp, mini + 1, end);int begin1 = begin, end1 = mini;int begin2 = mini + 1, end2 = end;int i = begin;while (begin1 <= end1 && begin2 <= end2){if (a[begin1] < a[begin2]){tmp[i++] = a[begin1++];}else{tmp[i++] = a[begin2++];}}while (begin1 <= end1){tmp[i++] = a[begin1++];}while (begin2 <= end2){tmp[i++] = a[begin2++];}//数据从tmp拷贝回去数组a里面memcpy(a + begin, tmp + begin, (end - begin + 1) * sizeof(int)); } //归并排序(递归实现)(创建tmp函数) void MergeSort01(int* a, int n) {//这里n传递过来的是个数int* tmp = (int*)malloc(sizeof(int) * n);if (tmp == NULL){perror("MergeSort01:tmp:err:");exit(1);//正常退出}_MergeSort01(a, tmp, 0, n - 1);free(tmp);tmp = NULL; }解释:
_MergeSort01 函数:这是归并排序的递归子函数,它接收三个参数:数组
a,临时数组tmp,以及要排序的数组区间[begin, end]。
- 如果
begin大于或等于end,则表示区间内没有元素或只有一个元素,不需要排序,直接返回。- 计算区间的中点
mini,将数组分为两部分:[begin, mini]和[mini + 1, end]。- 对这两部分分别递归调用
_MergeSort01函数进行排序,直到每个子区间只有一个元素。合并过程:
- 初始化两个指针
begin1和end1指向第一个子区间的开始和结束位置,begin2和end2指向第二个子区间的开始和结束位置。- 使用一个索引
i指向tmp数组的当前位置,用于存放合并后的有序元素。- 使用两个
while循环来比较两个子区间的元素,将较小的元素复制到tmp数组中,并移动对应的指针。- 如果第一个子区间的所有元素已经被复制到
tmp中,但第二个子区间还有剩余元素,将这些剩余元素复制到tmp数组的剩余位置。- 同理,如果第二个子区间的所有元素已经被复制,将第一个子区间的剩余元素复制到
tmp。拷贝回原数组:
- 使用
memcpy函数将tmp数组中从索引begin开始的元素复制回原数组a。这里计算了需要复制的元素数量为end - begin + 1,乘以sizeof(int)来确定字节数。MergeSort01 函数:这是归并排序的初始化函数,接收数组
a和数组的长度n。
- 首先,使用
malloc分配一个临时数组tmp,大小为n个int。- 如果内存分配失败,使用
perror打印错误信息,并调用exit(1)退出程序。- 调用
_MergeSort01函数,传入数组a、临时数组tmp和整个数组的区间[0, n - 1]进行排序。- 排序完成后,使用
free释放tmp所占用的内存,并设置tmp为NULL。归并排序的时间复杂度为 O(n log n),在大多数情况下表现良好,尤其是当数据量大且需要稳定排序时。不过,由于它需要额外的内存空间(如这里的
tmp数组),在内存受限的情况下可能不是最佳选择。
递归排序(非递归解决)
前言
这里递归排序的非递归方式还是比较有难度的,所以需要多次观看两遍,我也会多次详细的讲解,促进知识的理解
非递归实现gif

非递归实现单趟实现
这里的关键的在于对于区间的理解
尤其是
//但是此时可能产生越界行为,我们可以打印出来看一下
//产生越界的
//begin1, end1, begin2, end2 -> end2->[,][,15]
//begin1, end1, begin2, end2 -> begin2, end2->[,][12,15]
//begin1, end1, begin2, end2 -> end1, begin2, end2->[,11][12,15]
//解决
//begin2, end2区间越界的,我们直接下一次进行递归就可以
//end2,我们重新设定新的end2的区间所以我们需要对这个区间进行解决

代码的逐步实现
这里代码的实现,因为非递归实现是有难度的,所以这里我不会直接给出答案,而是逐步的写出步骤,促进理解
1,创建拷贝空间tmp,设定gap,一组假设初始1个数值,当然初始的时候,实际也是一个数值
//归并排序(非递归实现)(创建tmp函数) void MergeSort02(int* a, int n) {//这里n传递过来的是个数int* tmp = (int*)malloc(sizeof(int) * n);if (tmp == NULL){perror("MergeSort01:tmp:err:");exit(1);//正常退出}//假设初始化起始是一组int gap = 1; }2,区间的设定
这里依旧是两个区间,我们根据这个区间设定的数值
这里是很关键的一点
int begin1 = 0, end1 = 0 + gap - 1;
int begin2 = 0 + gap, end2 = 0 + 2 * gap - 1;//假设此时就两个数值,一组是一个数值,也就是这两个数值进行最小对比
//begin1左区间的初始位置,肯定是0
//end1左区间的结束位置。
- 也就是第一个区间的结束位置,也就是一组,
- -1是因为一组是实际的个数
- +0,这里因为加的是第一个区间起始位置
- 因为我们也可能是2-4区间的,不可能只是这一个区间
//begin2第二个区间的起始位置,这里还是比较好理解的,只要理解了end1
//end2第二个区间的结束位置,这里同理,
- 我们有可能是2-4区间的,不只是0-1或者0-2区间的。而且随着第一次排序的结束,第二次排序就变成两个合并了,继续和另外的对比,所以是变化的
- 0也就是初始位置
- 2*gap,因为这里是需要加上中间两组,
- 最后-1,因为gap是个数,不是下标
//归并排序(非递归实现)(创建tmp函数) void MergeSort02(int* a, int n) {//这里n传递过来的是个数int* tmp = (int*)malloc(sizeof(int) * n);if (tmp == NULL){perror("MergeSort01:tmp:err:");exit(1);//正常退出}//假设初始化起始是一组int gap = 1;int begin1 = 0, end1 = 0 + gap - 1;int begin2 = 0 + gap, end2 = 0 + 2 * gap - 1; }3,排序的实现
//归并排序(非递归实现)(创建tmp函数) void MergeSort02(int* a, int n) {//这里n传递过来的是个数int* tmp = (int*)malloc(sizeof(int) * n);if (tmp == NULL){perror("MergeSort01:tmp:err:");exit(1);//正常退出}//假设初始化起始是一组int gap = 1;while (gap < n){//递归到最小值,假设一组是一个,也就是此时是最小值进行比较并且入数组,关键是找出区间//这里一次跳过两组for (int i = 0; i < n - 1; i = i + gap * 2){int begin1 = i, end1 = i + gap - 1;int begin2 = i + gap, end2 = i + 2 * gap - 1;int j = i;while (begin1 <= end1 && begin2 <= end2){if (a[begin1] < a[begin2]){tmp[j++] = a[begin1++];}else{tmp[j++] = a[begin2++];}}while (begin1 <= end1){tmp[j++] = a[begin1++];}while (begin2 <= end2){tmp[j++] = a[begin2++];}}gap *= 2;} }4,区间的拷贝
这里区间的拷贝我们需要注意的是我们拷贝的是区间,并且我们需要一边拷贝一边拷贝回去,为什么需要一边排序一边拷贝回去,在接下来的越界行为里面我们会进行讲解
最后需要关注的点是,关于拷贝空间的大小,一定是end2-begin1,因为这两个区间是排序成功然后进入到tmp里面
所以我们需要从tmp拷贝回去,不能弄错了
//归并排序(非递归实现)(创建tmp函数) void MergeSort02(int* a, int n) {//这里n传递过来的是个数int* tmp = (int*)malloc(sizeof(int) * n);if (tmp == NULL){perror("MergeSort01:tmp:err:");exit(1);//正常退出}//假设初始化起始是一组int gap = 1;while (gap < n){//递归到最小值,假设一组是一个,也就是此时是最小值进行比较并且入数组,关键是找出区间//这里一次跳过两组for (int i = 0; i < n - 1; i = i + gap * 2){int begin1 = i, end1 = i + gap - 1;int begin2 = i + gap, end2 = i + 2 * gap - 1;int j = i;while (begin1 <= end1 && begin2 <= end2){if (a[begin1] < a[begin2]){tmp[j++] = a[begin1++];}else{tmp[j++] = a[begin2++];}}while (begin1 <= end1){tmp[j++] = a[begin1++];}while (begin2 <= end2){tmp[j++] = a[begin2++];}//拷贝回a数组里面,这里的区间是end2-begin1之间的区间memcpy(a + i, tmp + i, sizeof(int) * (end2 - i + 1));}gap *= 2;} }5,解决越界行为
这里我们可以很清楚的看到哪些位置会产生越界行为
这里我们处理一下之后,我们发现就解决了
//产生越界的区间有
//begin1, end1, begin2, end2 -> end2->[,][,15]
//begin1, end1, begin2, end2 -> begin2, end2->[,][12,15]
//begin1, end1, begin2, end2 -> end1, begin2, end2->[,11][12,15]
//解决
//begin2, end2区间越界的,我们直接下一次进行递归就可以
//end2,我们重新设定新的end2的区间//归并排序(非递归实现)(创建tmp函数) void MergeSort02(int* a, int n) {//这里n传递过来的是个数int* tmp = (int*)malloc(sizeof(int) * n);if (tmp == NULL){perror("MergeSort01:tmp:err:");exit(1);//正常退出}//假设初始化起始是一组int gap = 1;while (gap < n){//递归到最小值,假设一组是一个,也就是此时是最小值进行比较并且入数组,关键是找出区间//这里一次跳过两组for (int i = 0; i < n - 1; i = i + gap * 2){int begin1 = i, end1 = i + gap - 1;int begin2 = i + gap, end2 = i + 2 * gap - 1;//但是此时可能产生越界行为,我们可以打印出来看一下//产生越界的//begin1, end1, begin2, end2 -> end2->[,][,15]//begin1, end1, begin2, end2 -> begin2, end2->[,][12,15]//begin1, end1, begin2, end2 -> end1, begin2, end2->[,11][12,15]//解决//begin2, end2区间越界的,我们直接下一次进行递归就可以//end2,我们重新设定新的end2的区间printf("[begin1=%d,end1=%d][begin2=%d,end2=%d]\n", begin1, end1, begin2, end2);if (begin2 > n){break;}if (end2 > n){//记得这里需要是n-1不能是n,因为end2是下标end2 = n-1;}int j = i;while (begin1 <= end1 && begin2 <= end2){if (a[begin1] < a[begin2]){tmp[j++] = a[begin1++];}else{tmp[j++] = a[begin2++];}}while (begin1 <= end1){tmp[j++] = a[begin1++];}while (begin2 <= end2){tmp[j++] = a[begin2++];}//拷贝回a数组里面,这里的区间是end2-begin1之间的区间memcpy(a + i, tmp + i, sizeof(int) * (end2 - i + 1));}gap *= 2;} }


时间复杂度
时间复杂度分析如下:
分解阶段:归并排序首先将原始数组分解成多个子数组,每个子数组的大小为1。这个过程是线性的,时间复杂度为 O(n),其中 n 是原始数组的大小。
合并阶段:在合并阶段,算法将这些有序的子数组逐步合并成更大的有序数组。每次合并操作都需要将两个有序数组合并成一个更大的有序数组,这个过程的时间复杂度是 O(n)。
重复合并:归并排序的合并阶段会重复进行,直到所有的元素都被合并成一个有序数组。合并的次数可以看作是对数级的,具体来说,是 log2(n) 次。
综合以上两点,归并排序的总时间复杂度主要由合并阶段决定,因为分解阶段是线性的,而合并阶段虽然每次都是线性的,但由于重复了对数级次数,所以总的时间复杂度是:
𝑂(𝑛)+𝑂(𝑛log𝑛)
由于在大 O 符号中,我们只关注最高次项和系数,所以归并排序的时间复杂度通常被简化为:𝑂(𝑛log𝑛)
这意味着归并排序的时间效率与数组的大小成对数关系,是相当高效的排序算法。此外,归并排序是一种稳定的排序算法,它保持了相等元素的原始顺序。然而,它需要与原始数组同样大小的额外空间来存储临时数组,这可能会在空间受限的情况下成为一个问题。
代码实现
//归并排序(非递归实现)(创建tmp函数) void MergeSort02(int* a, int n) {//这里n传递过来的是个数int* tmp = (int*)malloc(sizeof(int) * n);if (tmp == NULL){perror("MergeSort01:tmp:err:");exit(1);//正常退出}//假设初始化起始是一组int gap = 1;while (gap < n){//递归到最小值,假设一组是一个,也就是此时是最小值进行比较并且入数组,关键是找出区间//这里一次跳过两组for (int i = 0; i < n - 1; i = i + gap * 2){int begin1 = i, end1 = i + gap - 1;int begin2 = i + gap, end2 = i + 2 * gap - 1;//但是此时可能产生越界行为,我们可以打印出来看一下//产生越界的//begin1, end1, begin2, end2 -> end2->[,][,15]//begin1, end1, begin2, end2 -> begin2, end2->[,][12,15]//begin1, end1, begin2, end2 -> end1, begin2, end2->[,11][12,15]//解决//begin2, end2区间越界的,我们直接下一次进行递归就可以//end2,我们重新设定新的end2的区间printf("[begin1=%d,end1=%d][begin2=%d,end2=%d]\n", begin1, end1, begin2, end2);if (begin2 > n){break;}if (end2 > n){//记得这里需要是n-1不能是n,因为end2是下标end2 = n-1;}int j = i;while (begin1 <= end1 && begin2 <= end2){if (a[begin1] < a[begin2]){tmp[j++] = a[begin1++];}else{tmp[j++] = a[begin2++];}}while (begin1 <= end1){tmp[j++] = a[begin1++];}while (begin2 <= end2){tmp[j++] = a[begin2++];}//拷贝回a数组里面,这里的区间是end2-begin1之间的区间memcpy(a + i, tmp + i, sizeof(int) * (end2 - i + 1));}gap *= 2;} }解释:
内存分配:首先,函数使用
malloc分配一个与原数组a同样大小的临时数组tmp。如果内存分配失败,使用perror打印错误信息,并调用exit退出程序。初始化间隔:
gap变量初始化为 1,表示每个元素自身作为一个有序的子数组。外层循环:使用
while循环来逐步增加gap的值,每次迭代将gap乘以 2。这个循环继续进行,直到gap大于或等于数组的长度n。内层循环:对于每个
gap值,使用for循环遍历数组,计算每次合并操作的起始索引i。每次迭代,i增加gap * 2,以确保每次处理的子数组间隔是gap。计算子数组边界:在每次迭代中,计算两个子数组的起始和结束索引:
begin1、end1和begin2、end2。这两个子数组的间隔是gap。处理数组越界:如果
begin2大于数组长度n,循环将终止。如果end2超出了数组的界限,将其调整为n-1。合并子数组:使用
while循环来合并两个子数组。比较a[begin1]和a[begin2],将较小的元素复制到tmp数组中,并相应地移动索引。当一个子数组的所有元素都被复制后,使用另外两个while循环复制剩余子数组中的元素。拷贝回原数组:使用
memcpy将tmp中的有序子数组复制回原数组a。这里,拷贝的区间是从索引i到end2,拷贝的元素数量是end2 - i + 1。更新间隔:外层循环的
gap每次迭代后翻倍,这样在每次迭代中,处理的子数组的大小逐渐增加,直到整个数组被排序。非递归的归并排序在某些情况下可能比递归版本更有效,因为它避免了递归调用的开销,尤其是在深度很大的递归树中。然而,它需要更多的迭代来逐步构建有序数组,因此在实际应用中,选择哪种实现取决于具体的需求和场景。
计数排序
前言
计数排序是速度特别快的一种排序方式,甚至说可以达到o(n),什么概念,一趟就可以实现,这是很快的,虽然具备一定的局限性,但是这个速度也是叹为观止的
计数排序gif

实现图解
这里的核心逻辑就在于,我们需要入数组和出数组这两点

代码实现
//计数排序 void Countsort(int* a, int n) {//求出最小值和最大值int max = a[0], min = a[0];for (int i = 0; i < n; i++){if (max < a[i]){max = a[i];}if (min > a[i]){min = a[i];}}//计算差值,需要最小值和最大值//0 1 2三个数值,但是2-1=2,也就是两个数值,所以我们需要+1 ,这个差值也就是我们开辟多大的空间int delta = max - min + 1;//创建数组空间int* tmp = (int*)calloc(delta, sizeof(int));if (tmp == NULL){perror("Countsort:tmp:err:");exit(1);//正常退出}//把原数组里面的数值计算之后->存放到tmp数组里面,但是需要控制差值存放在数组里面for (int i = 0; i < n; i++){tmp[a[i] - min]++;}//从数组读取出,放到原数组里面int j = 0;for (int i = 0; i < delta; i++){while (tmp[i]--){a[j++] = i + min;}} }解释:
求最小值和最大值:
- 首先初始化
max和min为数组的第一个元素的值。- 遍历整个数组
a,更新max和min为数组中的最大值和最小值。计算差值:
- 计算最大值和最小值的差值
delta,这个差值加1后将用于确定计数数组tmp的大小。创建计数数组:
- 使用
calloc分配一个大小为delta的数组tmp,并将所有元素初始化为0。calloc会初始化分配的内存为0,这对于计数排序是必要的。计数:
- 遍历原数组
a,对于数组中的每个元素a[i],计算其与最小值min的差值,并在tmp数组的相应位置增加计数。例如,如果a[i]是3,且min是0,则tmp[3]会增加1。输出排序结果:
- 使用两个指针
i和j,i用于遍历tmp数组,j用于指向原数组a的当前位置。- 对于
tmp数组中的每个非零元素,将其对应的值加回到原数组a中,直到tmp[i]减至0。这意味着将min + i赋值给a[j],然后j增加,重复这个过程直到tmp[i]为0。结束排序:
- 当所有计数都减至0时,原数组
a已经是部分有序的,排序完成。错误处理:
- 如果
calloc分配内存失败,使用perror打印错误信息,并调用exit退出程序。计数排序的时间复杂度是 O(n + k),其中 n 是数组
a的长度,k 是整数的范围(在这个例子中是delta)。由于 k 通常远小于 n,计数排序对于大量数据的排序非常高效。然而,计数排序的空间复杂度也是 O(k),如果整数的范围非常大,它可能需要大量的内存。计数排序是一种稳定的排序算法,它不会改变相等元素的相对顺序。它特别适用于当数据范围不大且数据量很大时的场景。
时间复杂度
寻找最大值和最小值:遍历整个数组以找到最大值和最小值,这个过程的时间复杂度是 O(n),其中 n 是数组中元素的数量。
创建计数数组:使用
calloc为计数数组分配内存并初始化,这个操作的时间复杂度是 O(k),其中 k 是最大值和最小值的差值加 1(即整数的范围)。计数:再次遍历数组,将每个元素的计数在计数数组中增加。这个过程的时间复杂度也是 O(n)。
输出排序结果:最后,根据计数数组重建排序后的数组。这个过程涉及遍历计数数组,并且对于每个非零计数,将对应的元素值放入原数组中。如果计数数组中的非零元素数量接近 n,则这个操作的时间复杂度接近 O(n)。
综合上述步骤,计数排序的总时间复杂度主要由以下两个 O(n) 操作决定:
- 寻找最大和最小值
- 计数和输出排序结果
因此,计数排序的总时间复杂度是 O(n + k)。然而,实际上,当 k(整数的范围)远小于 n 时,k 可以被视为一个常数,所以时间复杂度可以简化为 O(n)。但是,如果 k 很大,接近或大于 n,时间复杂度就接近 O(n + k)。
计数排序的空间复杂度是 O(k),因为需要额外的计数数组来存储每个可能整数的出现次数。如果 k 非常大,这可能会成为一个问题。
堆排序
前言
堆排序是速度很快的一种排序方式,尤其是处理大数据的情况下,这个堆排序展现了无与伦比的速度,当然这里比较吃二叉树篇章,所以我放在了最后,要是有二叉树理解不深入的,可以看一下这个博客,基本上看完之后就没有问题了
数据结构-二叉树系统性学习(四万字精讲拿捏)-CSDN博客
需要在数组里面进行排序,我们可以采取堆排序对其解决问题
版本1:
创建一个数组等大的堆,把数组里面的数值输入到堆里面进行堆排序,但是这样的弊端就是,不是顺序排序
版本2:
每次我们取堆顶然后打印,最后出堆,循环
弊端就是这样是时间复杂度我们发现还是o(n),没有必要那么麻烦半天时间复杂度还是这样

版本3:(推荐)
在数组上面进行排序,直接输出顺序排序
逻辑讲解
1,需要在数组里面进行排序,我们可以采取在数组建堆
2,然后交换收尾元素,每次调整的数值减少1
讲解逻辑
首先我们需要知道,
如果我们需要排序的是降序,我们就需要建立小堆
如果我们需要排序的是升序,我们就需要建立大堆
如果我们需要的是升序建立小堆的话
如果我们采取相反的方式的话,就会导致:(出现两个根)
首先n个数建小堆,固定第一个值是最小值
剩下的n-1个数再建堆
效率就很差了
如果相反的话,会导致根节点变化,从而导致逻辑混乱,数组里面的数值少的时候是不明显的,但是多的时候就不行了
逻辑实现图解
代码实现
//向下调整(大堆) void AdjustDown(HPDataType* a, int n, int parent) {int chile = parent * 2 + 1;//循环条件不能是父亲,不然会导致越界while (chile < n){//三个孩子进行比较if (chile + 1 < n && a[chile] < a[chile + 1]){chile++;}if (a[chile] > a[parent]){Swap(&a[chile], &a[parent]);parent = chile;chile = parent * 2 + 1;}else{break;}} } //堆排序数组内进行调整解决 void sort_test(int* a, int sz) {//放出来的是小堆,所以我们只能排序降序,这样逻辑更融洽//建堆for (int i = 0; i < sz; i++){AdjustUp(a, i);}//交换排序 把首个元素和最后一个交换进行排序 每次--while (sz > 0){Swap(&a[0], &a[sz - 1]);AdjustDown(a, sz - 1, 0);sz--;} }这个
sort_test函数实现了一个堆排序算法,它接收一个整数数组a和它的大小sz:
建堆:首先,函数通过调用
AdjustUp函数来构建一个小顶堆(最小堆)。建堆过程是从最后一个非叶子节点开始向上调整,直到堆顶。交换和排序:在建堆之后,函数进入一个循环,每次循环中,它将堆顶元素(当前堆中的最小元素)与当前堆的最后一个元素交换。然后,堆的大小减少 1,并且对剩余的堆进行向下调整以保持最小堆性质。
循环结束:循环继续进行,直到堆的大小减小到 0。最终,数组
a将被排序为降序


堆排序衍生的top_k问题
前言
这里本质还是堆排序的衍生问题
也就是还是堆排序问题,我们最终需要学习的就是处理大型数据的问题
top_k问题时间复杂度的计算
这里提前说明,时间复杂度的计算的目的是来计算向上调整的更优还是向下调整更优,从肉眼看的话向下调整优于向上调整,接下来我们进行时间复杂度的计算。
此时我们会用到等比数列求和以及裂项相消
首先我们需要我们建堆的时候是向上调整,还是向下调整
如图详解
首先我们假设求的是满二叉树,我们求节点的个数
满二叉树节点个数
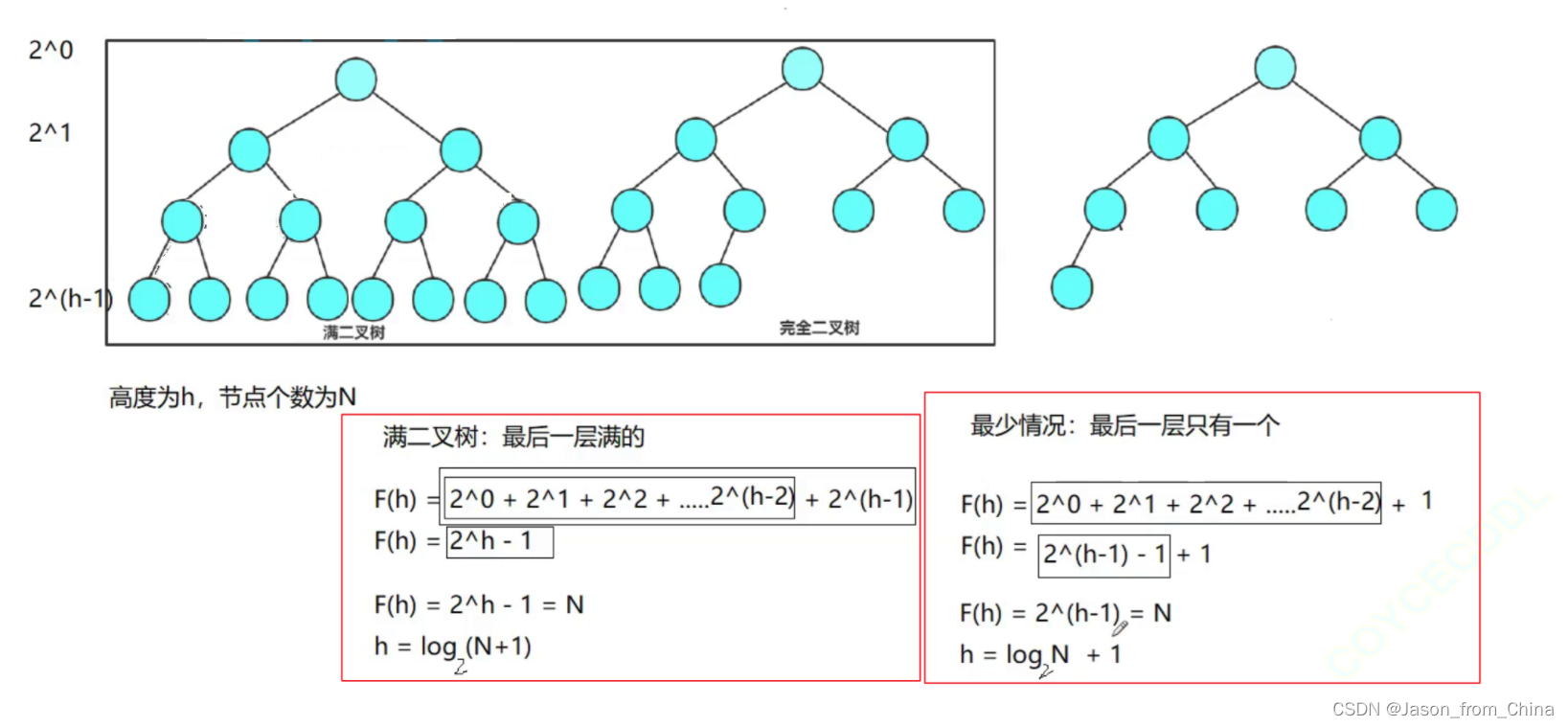
建堆问题:
建堆的话往往的倒数第一个非叶子结点建堆,会时间复杂度最优解:也就是
在构建堆(尤其是二叉堆)时,从最后一个非叶子节点开始进行调整是时间复杂度最优解的原因是,这种方法可以减少不必要的调整操作。
为什么从最后一个非叶子节点开始?
叶子节点:在完全二叉树中,叶子节点不包含任何子节点,因此不需要进行调整。
非叶子节点:从最后一个非叶子节点开始,向上逐个进行调整,可以确保每个节点在调整时,其子树已经是堆结构。这样可以减少调整的深度,因为每个节点最多只需要与其子节点交换一次。
减少调整次数:如果从根节点开始调整,那么每个节点可能需要多次调整才能达到堆的性质,特别是那些位于树底部的节点。而从底部开始,每个节点只需要调整一次即可。
时间复杂度分析
构建堆的过程涉及对每个非叶子节点进行调整。对于一个具有 𝑛n 个节点的完全二叉树:
叶子节点:有 ⌈𝑛/2⌉个叶子节点,它们不需要调整。
非叶子节点:有 ⌊𝑛/2⌋个非叶子节点,需要进行调整。
对于非叶子节点,从最后一个非叶子节点开始向上调整,每个节点最多只需要进行 log𝑘logk(𝑘k 是节点的深度)次交换。但是,由于树的结构,底部的节点不需要进行多次交换,因此整个调整过程的时间复杂度比 𝑂(𝑛log𝑛) 要低。
实际上,构建堆的时间复杂度是 𝑂(𝑛),这是因为:
从最后一个非叶子节点开始,每个节点的调整次数与其深度成反比。
根节点的调整次数最多,但只需要一次。
越往下,节点的深度越小,但需要调整的节点数量越多。
总结
从最后一个非叶子节点开始建堆,可以确保每个节点的调整次数与其深度成反比,从而减少总的调整次数。这种方法利用了完全二叉树的性质,使得整个建堆过程的时间复杂度达到最优,即 𝑂(𝑛)。这是构建堆的最优策略,因为它最小化了必要的调整操作,从而提高了算法的效率。
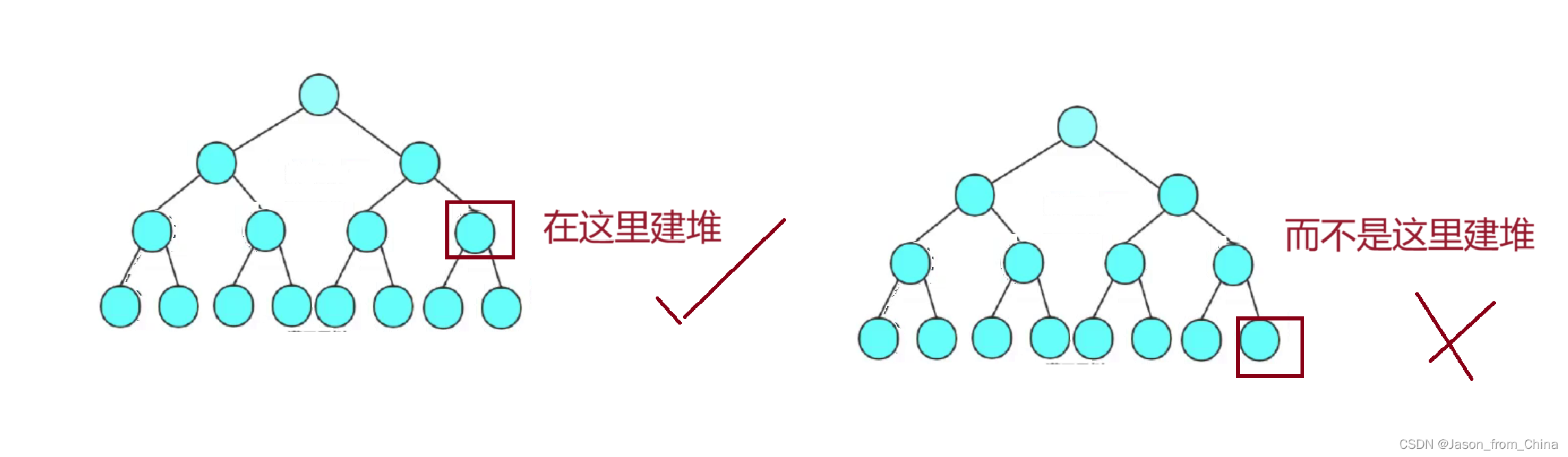
建堆复杂度讲解:(向下调整建堆计算)
如图:
这里为什么-2呢,因为我们的向下调整只是调整h-1层,第h层的节点的个数是2^h-1,所以第h-1层自然就是-2
所以我们发现,建堆的时候我们h-1高度的节点的个数相加得出的结果
为T(n)
所以我们进行计算
从而得出时间复杂度,为什么时间复杂度是高度,因为向下调整的时候,我们循环终止条件是循环的高度,也就是当父亲节点不小于sz的时候,所以计算出高度也就计算出了时间复杂度



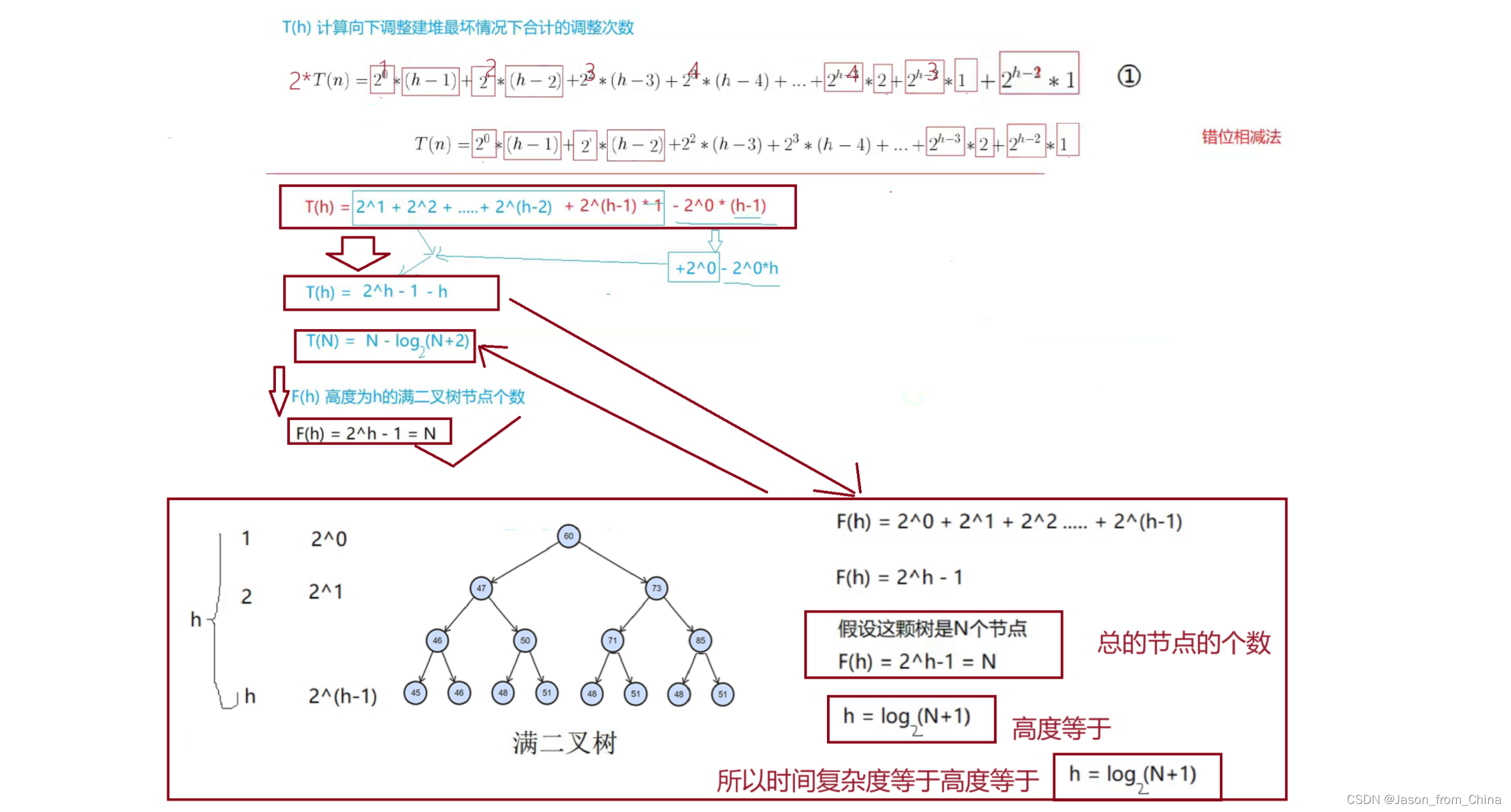
建堆复杂度讲解:(向上调整建堆计算)
如图:
计算图解
所以我们得出结论,这里多了n次



对比
向上调整(
AdjustUp)和向下调整(AdjustDown)的时间复杂度通常与堆的高度相关,即 log𝑘,其中 𝑘k 是堆中元素的数量。然而,在特定情况下,特别是在构建堆的过程中,这些操作的总时间复杂度可以是 𝑂(𝑛),这里的 𝑛 是堆中元素的数量。单个操作的时间复杂度:
向上调整 (
AdjustUp):对于单个元素,向上调整的时间复杂度是 𝑂(log𝑘),因为它可能需要从叶子节点一直调整到根节点,最多涉及 log𝑘层的比较和交换。向下调整 (
AdjustDown):同样,对于单个元素,向下调整的时间复杂度也是 𝑂(log𝑘),因为它可能需要从根节点调整到叶子节点,同样最多涉及 log𝑘层的比较和交换。构建堆的总时间复杂度:
当我们讨论构建一个包含 𝑛 个元素的堆时,所有元素的向上调整操作的总时间复杂度是 𝑂(𝑛)。这是因为:
树的非叶子节点大约是 𝑛/2(因为叶子节点也是 𝑛/2 左右)。
每个非叶子节点的调整操作最多涉及 log𝑘 的时间,但是由于树的结构,从根到叶的路径上的节点数量总和大致是 𝑛n。
因此,所有节点的向上调整操作加起来的时间复杂度是 𝑂(𝑛)。
为什么是 𝑂(𝑛) 而不是 𝑂(𝑛log𝑘)?
树的结构特性:在完全二叉树中,每个层级的节点数量是指数增长的。从根节点(1个节点)到第二层(2个节点),再到第三层(4个节点),等等。因此,较低层级的节点数量远多于较高层级的节点数量。
调整深度:根节点的调整可能需要 log𝑘 的时间,但较低层级的节点只需要较少的调整时间。由于底部层级的节点数量较多,它们较短的调整时间在总体上对总时间复杂度的贡献较小。
总结:
对于单个元素,向上调整和向下调整的时间复杂度是 𝑂(log𝑘)
在构建堆的过程中,所有元素的向上调整操作的总时间复杂度是 𝑂(𝑛),而不是 𝑂(𝑛log𝑘),这是由于完全二叉树的结构特性和调整操作的分布。
因此,向上调整和向下调整在构建堆的过程中的总时间复杂度是 𝑂(𝑛),而不是 𝑂(log𝑛)。这个线性时间复杂度是构建堆算法的一个重要特性,使得它在处理大量数据时非常高效。
向上调整和向下调整虽然最后计算的都是O(N)
但是满二叉树最后一层占据一半的节点
所以我们得出结论,向下调整的复杂度优于向上调整的复杂度
top_k问题的实现逻辑
1,首先我们创建一个文件,写入随机数值1000w个
2,如果需要读取文件里面最大的10个数值,那么我们就需要,创建一个小堆
原因:
这样的话,输入数值的时候,如果读取的数值比堆顶大,就会替换堆顶从而进堆,然后进行堆排序。
3,在读取文件的时候,我们需要读取一个接收一个,然后进行数值的对比,从而进行交换。
4,最后打印最大的数值
5,备注:我们如何判断我们的找到的最大的前十个数值的正确的,
也是很简单的,我们设定的随机数值是10000以内的,然后设定完之后,我们不调用,进入TXT里面更改一些数值。设定一些大于一万的数值,此时我们就可以发现我们筛选的数值对不对。
当然如果我们需要找最小的数值,那么我们设定数值最好为-1,因为十万个数值,很可能是有很多0的。但是我们肉眼看不出来。


top_k计算的代码实现
//进行计算 void TOP_K() {int k = 10;//scanf("%d", &k);FILE* ps = fopen("data.txt", "r");if (ps == NULL){perror("Error:opening:file");exit(1);}//创建空间存储int* tmp = (int*)malloc(sizeof(int) * k);if (tmp == NULL){perror("TOP_K():Heap* tmp:error");exit(1);}//读取个数for (int i = 0; i < 10; i++){fscanf(ps, "%d", &tmp[i]);}// 建堆,从最后一个非叶子节点开始建堆,// 这里的 -1-1 实际上看起来像是一个错误。// 通常,当我们需要找到最后一个非叶子节点的索引以开始建堆过程时,我们会从倒数第二个节点开始(因为数组索引从0开始)。对于大小为 k 的数组,最后一个非叶子节点的索引计算如下:// 简单的说就是,k是数值,我们需要传参传递是下标,找到父亲节点需要减去1 除以2 所以就有了-2的情况for (int i = (k - 1 - 1) / 2; i >= 0; i--){AdjustDown(tmp, k, i);}//排序int val = 0;int ret = fscanf(ps, "%d", &val);while (ret != EOF){if (tmp[0] < val){tmp[0] = val;AdjustDown(tmp, k, 0);}ret = fscanf(ps, "%d", &val);}//打印for (int i = 0; i < k; i++){printf("%d ", tmp[i]);}fclose(ps);}
top_k完整代码
//TOP_K问题的实现 小堆寻找最大值 //创建随机数值 void TOP_K_fopen_w() {FILE* ps = fopen("data.txt", "w");if (ps == NULL){perror("FILE* ps :fopen:error");exit(1);}srand(time(0));for (int i = 0; i < 100000; i++){int s = rand() % 10000;fprintf(ps, "%d\n", s);}fclose(ps); } //进行计算 void TOP_K() {int k = 10;//scanf("%d", &k);FILE* ps = fopen("data.txt", "r");if (ps == NULL){perror("Error:opening:file");exit(1);}//创建空间存储int* tmp = (int*)malloc(sizeof(int) * k);if (tmp == NULL){perror("TOP_K():Heap* tmp:error");exit(1);}//读取个数for (int i = 0; i < 10; i++){fscanf(ps, "%d", &tmp[i]);}// 建堆,从最后一个非叶子节点开始建堆,// 这里的 -1-1 实际上看起来像是一个错误。// 通常,当我们需要找到最后一个非叶子节点的索引以开始建堆过程时,我们会从倒数第二个节点开始(因为数组索引从0开始)。对于大小为 k 的数组,最后一个非叶子节点的索引计算如下:// 简单的说就是,k是数值,我们需要传参传递是下标,找到父亲节点需要减去1 除以2 所以就有了-2的情况for (int i = (k - 1 - 1) / 2; i >= 0; i--){AdjustDown(tmp, k, i);}//排序int val = 0;int ret = fscanf(ps, "%d", &val);while (ret != EOF){if (tmp[0] < val){tmp[0] = val;AdjustDown(tmp, k, 0);}ret = fscanf(ps, "%d", &val);}//打印for (int i = 0; i < k; i++){printf("%d ", tmp[i]);}fclose(ps);}解释:
TOP_K_fopen_w 函数:
- 这个函数用于生成随机数据并写入到 "data.txt" 文件中。
- 使用
fopen打开文件,如果失败则打印错误并退出程序。- 使用
srand和time初始化随机数生成器的种子。- 循环生成100000个0到9999之间的随机整数,并使用
fprintf将它们写入文件,每个数字一行。- 最后使用
fclose关闭文件。TOP_K 函数:
- 首先定义了要找出的最大的数的个数
k(这里设置为10)。- 使用
fopen打开 "data.txt" 文件进行读取,如果失败则打印错误并退出程序。- 分配一个大小为
k的数组tmp用于存储小顶堆的元素。- 读取前10个数字存入
tmp数组中,这里假设文件中的数字至少有10个。建堆:
- 从最后一个非叶子节点开始调整堆,以确保
tmp数组是一个有效的小顶堆。这里的注释提到 "-1-1 实际上看起来像是一个错误",但实际上,计算最后一个非叶子节点的索引是正确的。对于大小为k的完全二叉树,最后一个非叶子节点的索引是(k - 2) / 2。这里的计算(k - 1 - 1) / 2实际上得到的是倒数第二个非叶子节点的索引- 使用
AdjustDown函数从最后一个非叶子节点开始向下调整堆,确保堆的性质。排序:
- 使用
fscanf从文件中读取数字,直到文件结束(EOF)。- 对于每个读取的数字,如果它大于堆顶(即
tmp[0]),则替换堆顶元素,并调用AdjustDown函数向下调整堆。- 这个过程确保了
tmp数组中始终存储着当前读取到的最大的K个数。打印结果:
- 循环打印
tmp数组中的所有元素,这些元素就是最大的K个数。- 使用
fclose关闭文件。注意:
- 代码中没有提供
AdjustDown函数的实现,这个函数用于向下调整堆,以保持堆的性质。- 代码假设文件中的数字数量至少为10,如果少于10个,需要额外的错误处理。
- 代码中没有考虑内存分配失败的情况,实际使用中应该检查
malloc的返回值。整体上,这段代码展示了如何使用小顶堆来解决TOP-K问题,通过维护一个大小为K的最小堆,可以有效地找到数据流中最大的K个数。
相关文章:

数据结构-十大排序算法集合(四万字精讲集合)
前言 1,数据结构排序篇章是一个大的工程,这里是一个总结篇章,配备动图和过程详解,从难到易逐步解析。 2,这里我们详细分析几个具备教学意义和实际使用意义的排序: 冒泡排序,选择排序,…...
SpringBoot三层架构
目录 一、传统方式 二、三层架构 三、代码拆分 1、dao层 2、service层 3、control层 四、运行结果 一、传统方式 上述代码存在一定的弊端,在进行软件设计和软件开发中提倡单一责任原则,使代码的可读性更强,复杂性更低,可扩展性…...

uniapp微信小程序局部刷新,无感刷新,修改哪条数据刷新哪条
uniapp做微信小程序时,一个商品列表滑到几百条数据时,点进去详情跳转去编辑信息上下架等,修改完成回来商品列表就到第一条数据了,这样页面效果体验感不是很好,是因为我们把数据接口放在onshow中了,每次回来…...

golan的雪花id
今天记录一下 golang的雪花id golang的雪花id 还是比较简单的,其包含的含义以及组成我这就不讲了,好多大佬都有文章写过,我直接上怎么用 先 引入包 go get "github.com/bwmarrin/snowflake" 代码块 func main() {// 设置一个时…...
RK3568 CAN波特率500K接收数据导致CPU4满载
最近调试RK3568 CAN时发现,当CAN作为接收端,在快速接收数据时会导致cpu4满载。down掉can口或者断开外设时恢复正常。并且问题只是在部门CPU版本上出现。在CAN接收中断中打印log,能发现log是按照接收数据的时间打印的。 驱动(rockchip_canfd…...
AI实战 | 使用元器打造浪漫仪式小管家
浪漫仪式小管家 以前我们曾经打造过学习助手和待办助手,但这一次,我们决定创造一个与众不同的智能体,而浪漫将成为我们的主题。我们选择浪漫作为主题,是因为我们感到在之前的打造过程中缺乏了一些仪式感,无法给对方带来真正的惊喜。因此,这一次我们计划慢慢调试,将它发…...
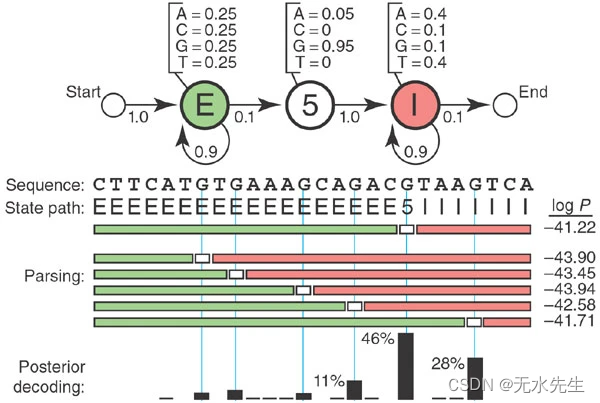
什么是隐马尔可夫模型?
文章目录 一、说明二、玩具HMM:5′拼接位点识别三、那么,隐藏了什么?四、查找最佳状态路径五、超越最佳得分对齐六、制作更逼真的模型七、收获 关键词:hidden markov model 一、说明 被称为隐马尔可夫模型的统计模型是计算生物学…...

qt中使用qsqlite连接数据库,却没有在本地文件夹中生成db文件
exe运行起来之后,发现没有在exe文件夹下生成数据库文件,,之前可以,但中间莫名其妙不行了,代码如下 // 建立和SQlite数据库的连接database QSqlDatabase::addDatabase("QSQLITE");// 设置数据库文件的名字da…...

Django的‘通用视图TemplateView’
使用通用视图的好处是:如果有一个html需要展示,不需要写view视图函数,直接写好url即可。 使用通用视图的步骤如下: 1、编辑项目urls.py文件 from django.views.generic import TemplateView 在该文件的映射表中添加:…...

java功能实现在某个时间范围之内输出true,不在某个范围输出false,时间精确到分钟
import org.slf4j.Logger; import org.slf4j.LoggerFactory; public class DateTimeChecker { private static final Logger log LoggerFactory.getLogger(DateTimeChecker.class); /** * 检查当前时间是否在指定的小时和分钟范围内。 * * param startHour 开…...
macbook屏幕录制技巧,这2个方法请你收好
在当今数字化时代,屏幕录制成为了一项不可或缺的技能,无论是教学演示、游戏直播,还是软件操作教程,屏幕录制都能帮助我们更直观地传达信息。MacBook作为苹果公司的标志性产品,其屏幕录制功能也备受用户关注。本文将详细…...

vue-loader
Vue Loader 是一个 webpack 的 loader,它允许你以一种名为单文件组件 (SFCs)的格式撰写 Vue 组件 起步 安装 npm install vue --save npm install webpack webpack-cli style-loader css-loader html-webpack-plugin vue-loader vue-template-compiler webpack…...

IO系列(十) -TCP 滑动窗口原理介绍(上)
一、摘要 之前在上分享网络编程知识文章的时候,有网友写下一条留言:“可以写写一篇关于 TCP 滑动窗口原理的文章吗?”。 当时没有立即回复,经过查询多方资料,发现这个 TCP 真的非常非常的复杂,就像一个清…...

IPython 使用技巧整理
IPython 是一个增强的 Python 交互式 shell,提供了许多实用的功能和特性,使得 Python 编程和数据科学工作变得更加便捷和高效。以下是一些 IPython 的使用技巧整理: 1. 自动补全和查询 Tab 补全:在 IPython 中,你可以…...

Python 引入中文py文件
目录 背景 思路 importlib介绍 使用方法 1.导入内置库 importlib.util 2.创建模块规格对象 spec importlib.util.spec_from_file_location("example_module", "example.py") 3.创建模块对象 module importlib.util.module_from_spec(spec) …...
qt 实现模拟实际物体带速度的移动(水平、垂直、斜角度)——————附带完整代码
文章目录 0 效果1 原理1.1 图片旋转1.2 物体按照现实中的实际距离带真实速度移动 2 完整实现2.1 将车辆按钮封装为一个类:2.2 调用方法 3 完整代码参考 0 效果 实现后的效果如下 可以显示属性(继承自QToolButton): 鼠标悬浮显示文字 按钮…...
驱动开发(三):内核层控制硬件层
驱动开发系列文章: 驱动开发(一):驱动代码的基本框架 驱动开发(二):创建字符设备驱动 驱动开发(三):内核层控制硬件层 ←本文 目录…...

企业邮箱大附件无法上传?无法确认接收状态?这样解决就行
Outlook邮箱作为最常用的邮箱系统,被全世界企业采用作为内部通用沟通方式,但Outlook邮箱却有着明显的使用缺陷,如邮箱大附件上传障碍及附件接收无提示等。 1、企业邮箱大附件无法上传 Outlook企业邮箱大附件的上传上限一般是50M,…...
)
Kotlin 数据类(Data Class)
Kotlin 数据类(Data Class)是一种特别用于持有数据的类。它们简化了数据类的创建,并提供了一些自动生成的方法。下面详细介绍 Kotlin 数据类的原理和使用方法。 数据类的定义 Kotlin 中的数据类使用 data 关键字定义。例如: da…...
gridview自带编辑功能如何判断用户修改的值的合法性
在使用GridView的编辑功能更新值时,确保输入的值合法性是十分重要的。为了实现这一点,你可以在GridView的RowUpdating事件中加入代码来检查用户输入的值。如果发现输入的值不合法,你可以取消更新操作并向用户显示错误消息。下面是如何实现的步…...

Netgear路由器急救指南:nmrpflash如何让变砖设备重获新生
Netgear路由器急救指南:nmrpflash如何让变砖设备重获新生 【免费下载链接】nmrpflash Netgear Unbrick Utility 项目地址: https://gitcode.com/gh_mirrors/nmr/nmrpflash 当你心爱的Netgear路由器因为固件升级失败、意外断电或其他原因变成一块"砖头&q…...

HS2-HF Patch:为《Honey Select 2》注入新生命的魔法补丁
HS2-HF Patch:为《Honey Select 2》注入新生命的魔法补丁 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 你是不是曾经打开《Honey Select 2》时&am…...

FanControl终极指南:免费开源的风扇控制神器,轻松解决Windows散热与噪音问题
FanControl终极指南:免费开源的风扇控制神器,轻松解决Windows散热与噪音问题 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https:…...

编程统计公司内部资料查阅使用数据,优化资料分类存储方式。提升职场员工工作查阅办事效率。
构建一个公司内部资料查阅使用统计与资料分类存储优化的商务智能示例项目,去营销化、中立化,仅用于学习与工程实践参考。一、实际应用场景描述在中大型企业中,内部资料(制度、流程文档、技术手册、项目档案)数量庞大&a…...

为开源项目OpenClaw配置Taotoken作为后端模型供应商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为开源项目OpenClaw配置Taotoken作为后端模型供应商 OpenClaw是一个功能强大的开源智能体(Agent)框架&…...

城通网盘高速解析终极指南:如何免费实现40倍下载提速
城通网盘高速解析终极指南:如何免费实现40倍下载提速 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet 你是否厌倦了城通网盘那令人抓狂的蜗牛下载速度?每次下载大文件都要面对漫长…...

从零构建可定制对话系统:模块化架构与RAG实战指南
1. 项目概述:从零构建一个可定制的对话系统最近在折腾一个挺有意思的东西,我把它叫做“定制化聊天系统”。起因很简单,市面上现成的聊天机器人,无论是开源的还是商业的,总感觉差了那么点意思。要么是功能太臃肿&#x…...

Kubernetes自动化更新利器Keel:实现容器镜像的持续部署
1. 项目概述:为什么我们需要一个“自动化的应用更新管家”? 如果你和我一样,负责维护着几个、十几个,甚至几十个运行在Kubernetes或Docker环境中的应用,那你一定对“更新”这件事又爱又恨。爱的是,新版本意…...

如何3分钟搭建智能手机号定位系统:免费归属地查询终极指南
如何3分钟搭建智能手机号定位系统:免费归属地查询终极指南 【免费下载链接】location-to-phone-number This a project to search a location of a specified phone number, and locate the map to the phone number location. 项目地址: https://gitcode.com/gh_…...

火灾动力学模拟实战:如何用FDS构建精准的火灾预测系统
火灾动力学模拟实战:如何用FDS构建精准的火灾预测系统 【免费下载链接】fds Fire Dynamics Simulator 项目地址: https://gitcode.com/gh_mirrors/fd/fds 你是否曾面临这样的困境:当设计一栋大型商业建筑时,如何科学评估火灾时的人员疏…...