一文打通Sleuth+Zipkin 服务链路追踪
1、为什么用
微服务架构是一个分布式架构,它按业务划分服务单元,一个分布式系统往往有很多个服务单元。由于服务单元数量众多,业务的复杂性,如果出现了错误和异常,很难去定位。主要体现在,一个请求可能需要调用很多个服务,而内部服务的调用复杂性,决定了问题难以定位。所以微服务架构中,必须实现分布式链路追踪,去跟进一个请求到底有哪些服务参与, 参与的顺序又是怎样的,从而达到每个请求的步骤清晰可见,出了问题,很快定位。
链路追踪组件有 Google 的 Dapper,Twitter 的 Zipkin,以及阿里的 Eagleeye (鹰眼)等,它 们都是非常优秀的链路追踪开源组件。
2、基本术语
Span(跨度):基本工作单元,发送一个远程调度任务 就会产生一个 Span,Span 是一 个 64 位 ID 唯一标识的,Trace 是用另一个 64 位 ID 唯一标识的,Span 还有其他数据信 息,比如摘要、时间戳事件、Span 的 ID、以及进度 ID。
Trace(跟踪):一系列 Span 组成的一个树状结构。请求一个微服务系统的 API 接口, 这个 API 接口,需要调用多个微服务,调用每个微服务都会产生一个新的 Span,所有 由这个请求产生的 Span 组成了这个 Trace。
Annotation(标注):用来及时记录一个事件的,一些核心注解用来定义一个请求的开 始和结束 。这些注解包括以下:
cs - Client Sent -客户端发送一个请求,这个注解描述了这个 Span 的开始
sr - Server Received -服务端获得请求并准备开始处理它,如果将其 sr 减去 cs 时 间戳 便可得到网络传输的时间。
ss - Server Sent (服务端发送响应)–该注解表明请求处理的完成(当请求返回客户 端),如果 ss 的时间戳减去 sr 时间戳,就可以得到服务器请求的时间。
cr - Client Received (客户端接收响应)-此时 Span 的结束,如果 cr 的时间戳减 去cs 时间戳便可以得到整个请求所消耗的时间。
官方文档:
https://cloud.spring.io/spring-cloud-static/spring-cloud-sleuth/2.1.3.RELEASE/single/spring-cloud
-sleuth.html如果服务调用顺序如下

那么用以上概念完整的表示出来如下:

Span 之间的父子关系如下:

3、整合 Sleuth
1、服务提供者与消费者导入依赖
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>2、打开 debug 日志
logging:level:org.springframework.cloud.openfeign: debugorg.springframework.cloud.sleuth: debug3、发起一次远程调用,观察控制台
DEBUG [user-service,541450f08573fff5,541450f08573fff5,false] user-service:服务名
541450f08573fff5:是 TranceId,一条链路中,只有一个 T
ranceId 541450f08573fff5:是 spanId,链路中的基本工作单元 id
false:表示是否将数据输出到其他服务,true 则会把信息输出到其他可视化的服务上观察
4、整合 zipkin 可视化观察
通过 Sleuth 产生的调用链监控信息,可以得知微服务之间的调用链路,但监控信息只输出 到控制台不方便查看。我们需要一个图形化的工具-zipkin。Zipkin 是 Twitter 开源的分布式跟 踪系统,主要用来收集系统的时序数据,从而追踪系统的调用问题。
zipkin 官网地址如下
https://zipkin.io/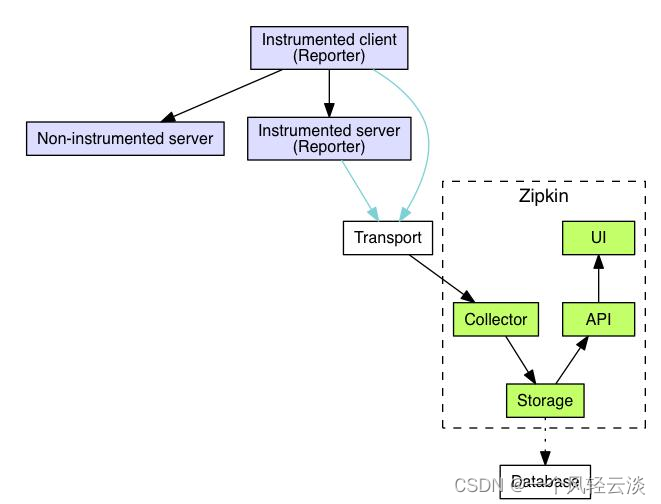
1、docker 安装 zipkin 服务器
docker run -d -p 9411:9411 openzipkin/zipkin2、pom导入
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>zipkin 依赖也同时包含了 sleuth,可以省略 sleuth 的引用
3、添加 zipkin 相关配置
spring:application:name: user-servicezipkin:base-url: http://192.168.56.10:9411/ # zipkin 服务器的地址# 关闭服务发现,否则 Spring Cloud 会把 zipkin 的 url 当做服务名称discoveryClientEnabled: falsesender:type: web # 设置使用 http 的方式传输数据sleuth:sampler:probability: 1 # 设置抽样采集率为 100%,默认为 0.1,即 10%发送远程请求,测试 zipkin。
服务调用链追踪信息统计

服务依赖信息统计

5、Zipkin 数据持久化
Zipkin 默认是将监控数据存储在内存的,如果 Zipkin 挂掉或重启的话,那么监控数据就会丢 失。所以如果想要搭建生产可用的 Zipkin,就需要实现监控数据的持久化。而想要实现数据 持久化,自然就是得将数据存储至数据库。好在 Zipkin 支持将数据存储至:
内存(默认)
MySQL
Elasticsearch
Cassandra
Zipkin 数据持久化相关的官方文档地址如下:
https://github.com/openzipkin/zipkin#storage-component![]() https://github.com/openzipkin/zipkin#storage-component
https://github.com/openzipkin/zipkin#storage-component
Zipkin 支持的这几种存储方式中,内存显然是不适用于生产的,这一点开始也说了。而使用MySQL 的话,当数据量大时,查询较为缓慢,也不建议使用。Twitter 官方使用的是 Cassandra作为 Zipkin 的存储数据库,但国内大规模用 Cassandra 的公司较少,而且 Cassandra 相关文档也不多。Zipkin-server不处理跟踪数据的保留管理。使用ElasticSearch推荐的工具管理数据保留或群集 会无限增长!(这使用Elasticsearch 5 + 功能) 综上,故采用 Elasticsearch 是个比较好的选择,关于使用 Elasticsearch 作为 Zipkin 的存储数 据库的官方文档如下:
elasticsearch-storage:
https://github.com/openzipkin/zipkin/tree/master/zipkin-server#elasticsearch-storage![]() https://github.com/openzipkin/zipkin/tree/master/zipkin-server#elasticsearch-storagezipkin-storage/elasticsearch:
https://github.com/openzipkin/zipkin/tree/master/zipkin-server#elasticsearch-storagezipkin-storage/elasticsearch:
https://github.com/openzipkin/zipkin/tree/master/zipkin-storage/elasticsearch![]() https://github.com/openzipkin/zipkin/tree/master/zipkin-storage/elasticsearch通过 docker 的方式:
https://github.com/openzipkin/zipkin/tree/master/zipkin-storage/elasticsearch通过 docker 的方式:
docker run --env STORAGE_TYPE=elasticsearch --env ES_HOSTS=192.168.56.10:9200
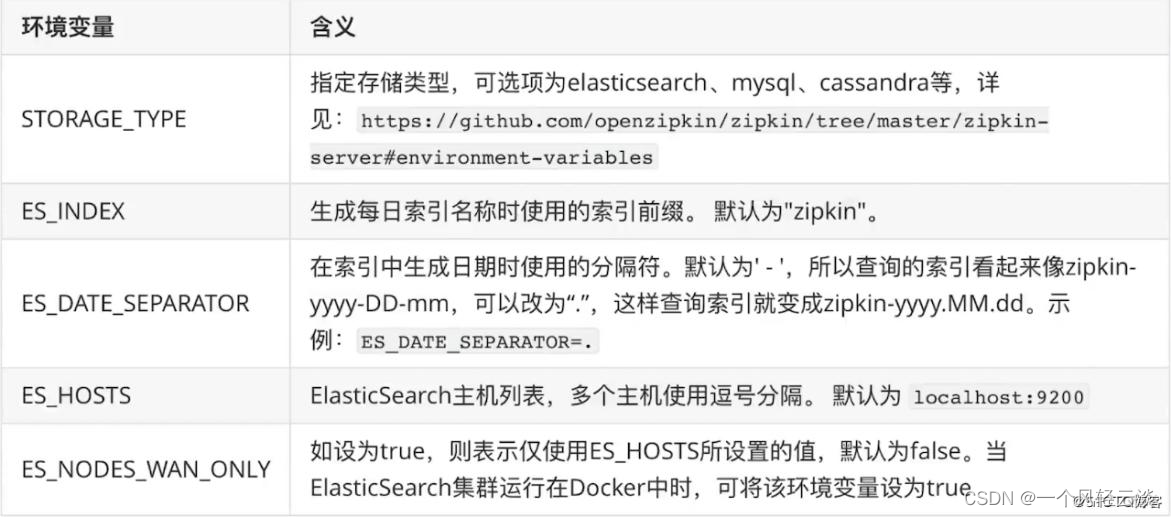
openzipkin/zipkin-dependencies 使用 es 时 Zipkin Dependencies 支持的环境变量
使用 es 时 Zipkin Dependencies 支持的环境变量
相关文章:
一文打通Sleuth+Zipkin 服务链路追踪
1、为什么用 微服务架构是一个分布式架构,它按业务划分服务单元,一个分布式系统往往有很多个服务单元。由于服务单元数量众多,业务的复杂性,如果出现了错误和异常,很难去定位。主要体现在,一个请求可能需要…...
牛客刷题第一弹
1.异常处理 都是Throwable的子类: ①.Exception(异常):是程序本身可以处理的异常。 ②.Error(错误): 是程序无法处理的错误。这些错误表示故障发生于虚拟机自身、或者发生在虚拟机试图执行应用时,一般不需…...
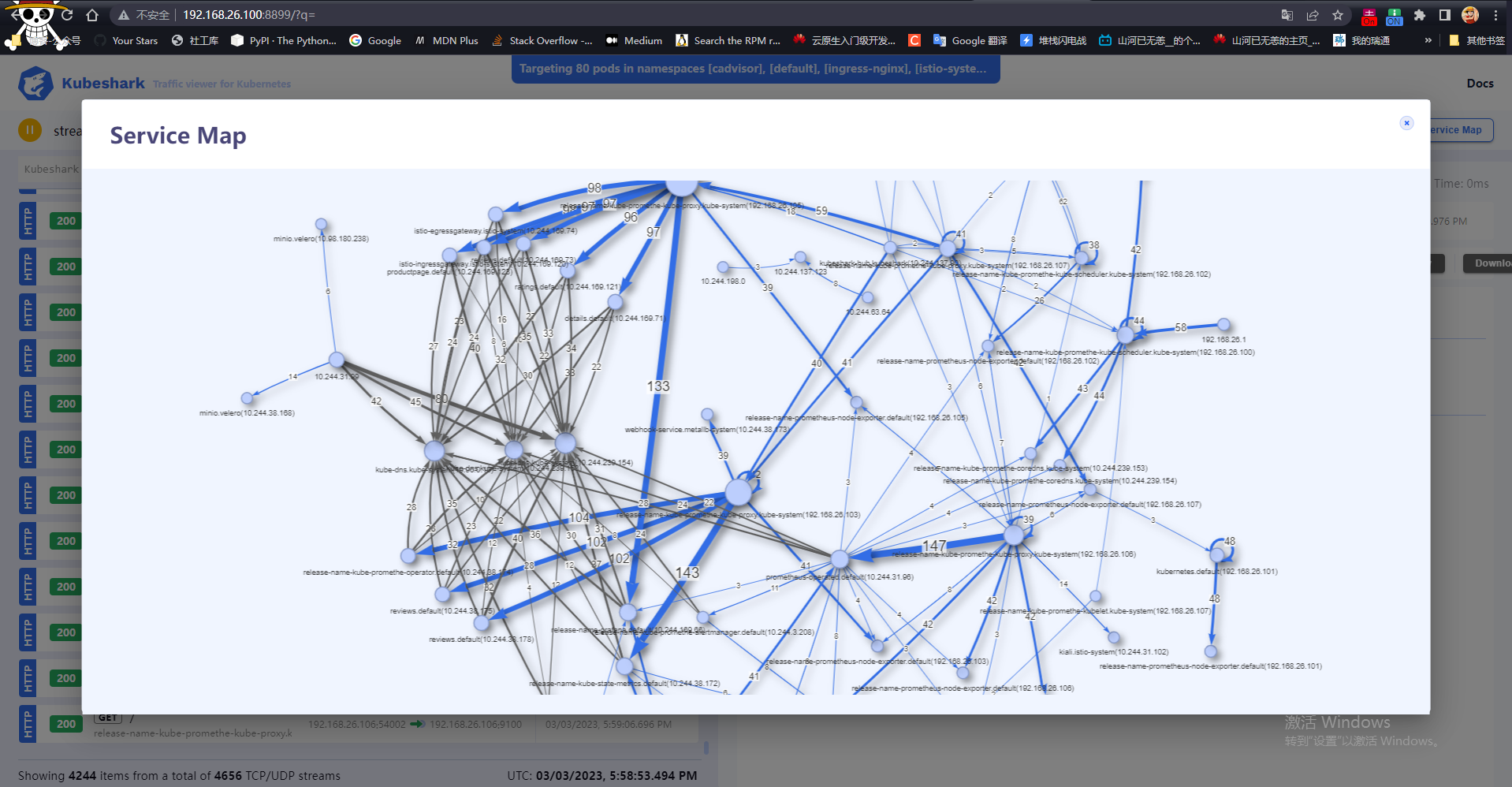
K8s:通过 Kubeshark 体验 大白鲨(Wireshark)/TCPDump 监控 Kubernetes 集群
写在前面 分享一个 k8s 集群流量查看器很轻量的一个工具,监控方便博文内容涉及: Kubeshark 简单介绍Windows、Linux 下载运行监控DemoKubeshark 特性功能介绍 理解不足小伙伴帮忙指正 对每个人而言,真正的职责只有一个:找到自我。…...
MySQL查询索引原则
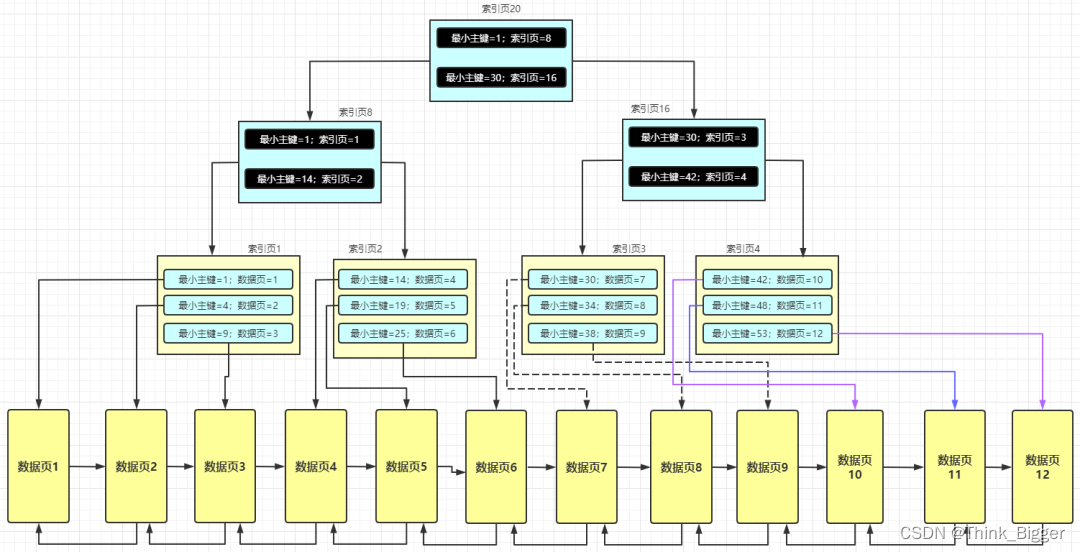
文章目录 等值匹配原则最左前缀匹配原则范围查找规则等值匹配+范围查找Order By + limit 优化分组查询优化总结MySQL 是如何帮我们维护非主键索引的等值匹配原则 我们现在已经知道了如果是【主键索引】,在插入数据的时候是根据主键的顺序依次往后排列的,一个数据页不够就会分…...

布谷鸟优化算法C++
#include <iostream> #include <vector> #include <cmath> #include <random> #include <time.h> #include <fstream> #define pi acos(-1) //5只布谷鸟 constexpr int NestNum 40; //pi值 //规定X,Y 的取值范围 constexpr double X_…...
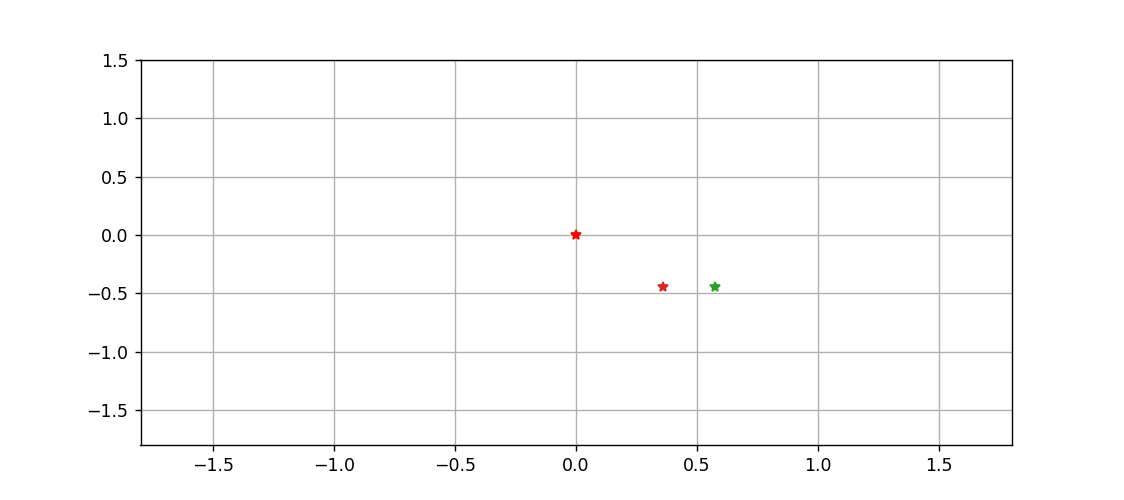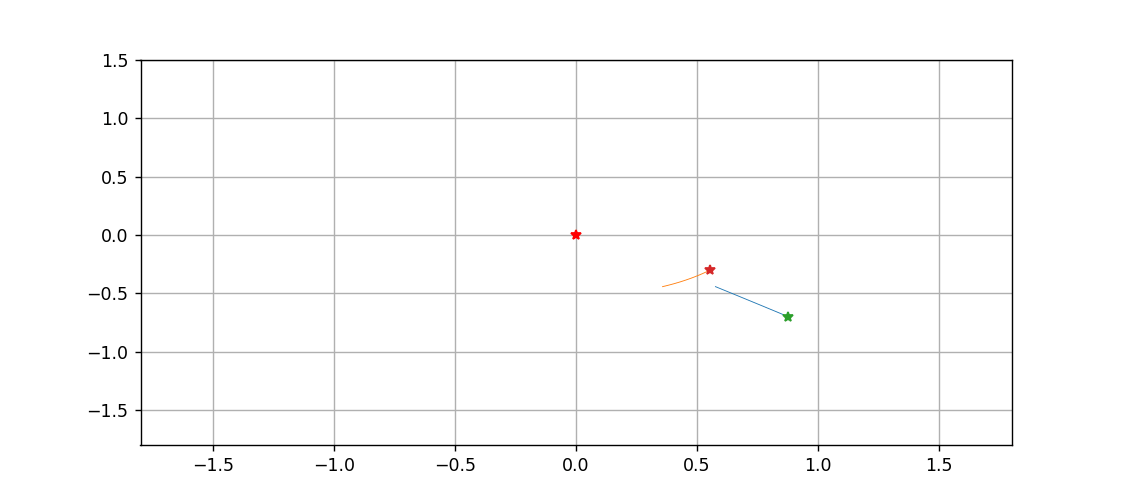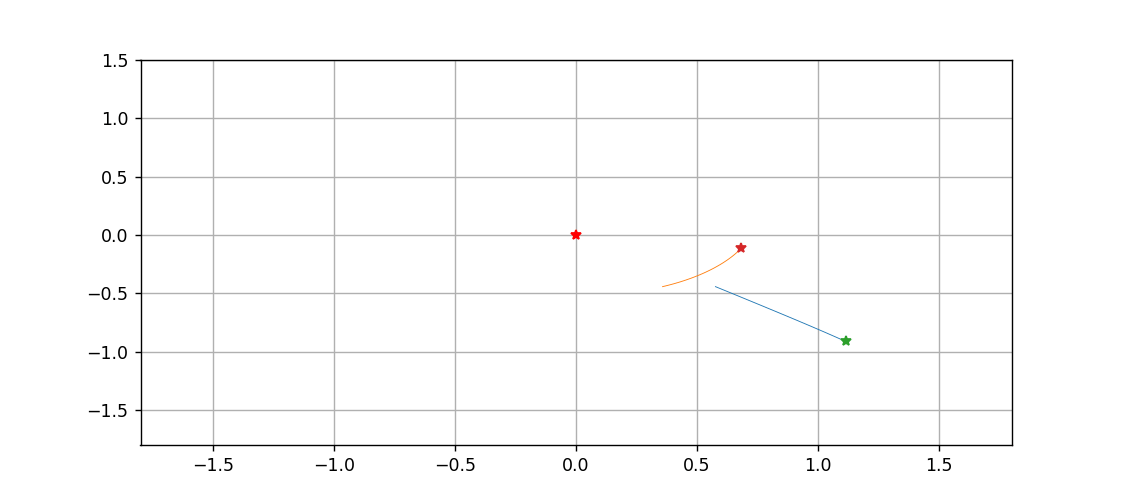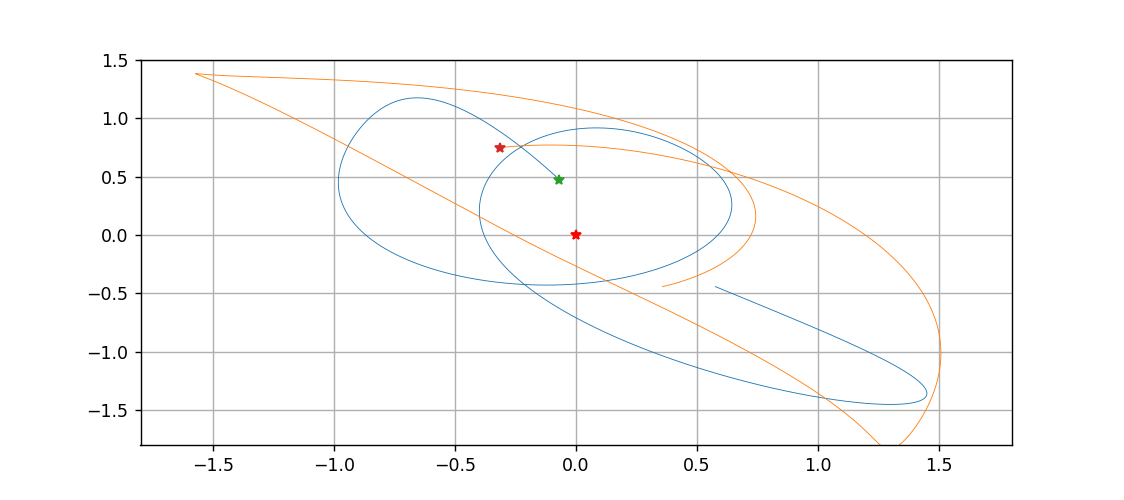
三体到底是啥?用Python跑一遍就明白了
文章目录拉格朗日方程推导方程组微分方程算法化求解画图动图绘制温馨提示,只想看图的画直接跳到最后一节拉格朗日方程 此前所做的一切三体和太阳系的动画,都是基于牛顿力学的,而且直接对微分进行差分化,从而精度非常感人…...

Golang-Hello world
目录 安装 Go(如果尚未安装) 编写Hello world 使用Golang的外部包 自动下载需要的外部包...

this指针C++
🐶博主主页:ᰔᩚ. 一怀明月ꦿ ❤️🔥专栏系列:线性代数,C初学者入门训练,题解C,C的使用文章 🔥座右铭:“不要等到什么都没有了,才下定决心去做” …...

SpringBoot+WebSocket实时监控异常
# 写在前面此异常非彼异常,标题所说的异常是业务上的异常。最近做了一个需求,消防的设备巡检,如果巡检发现异常,通过手机端提交,后台的实时监控页面实时获取到该设备的信息及位置,然后安排员工去处理。因为…...
Baumer工业相机堡盟相机如何使用自动曝光功能(自动曝光优点和行业应用)(C++)
项目场景 Baumer工业相机堡盟相机是一种高性能、高质量的工业相机,可用于各种应用场景,如物体检测、计数和识别、运动分析和图像处理。 Baumer的万兆网相机拥有出色的图像处理性能,可以实时传输高分辨率图像。此外,该相机还具…...

HTML、CSS学习笔记7(移动适配:rem、less)
一、移动适配 rem:目前多数企业在用的解决方案vw / vh:未来的解决方案 1.rem(单位) 1.1使用rem单位设置尺寸 px单位或百分比布局可以实现吗? ————不可以 网页的根字号——HTML标签 1.2.rem移动适配 写法&#x…...
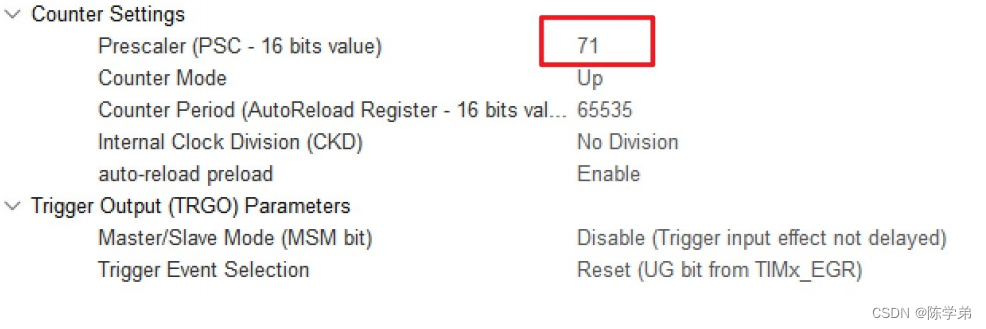
STM32感应开关盖垃圾桶
目录 项目需求 项目框图 编辑 硬件清单 sg90舵机介绍及实战 sg90舵机介绍 角度控制 SG90舵机编程实现 超声波传感器介绍及实战 超声波传感器介绍 超声波编程实战 项目设计及实现 项目需求 检测靠近时,垃圾桶自动开盖并伴随滴一声,2秒后关盖…...

进程跟线程的区别
进程跟线程的区别 文章目录进程跟线程的区别前言一.什么线程二.线程与进程的联系三.线程与进程有什么不同前言 现代所有计算机都能同时做几件事情,当一个用户程序正在运行时,计算机还能同时读取磁盘,并向屏幕打印输出正文.在一个多道操作程序中,cpu由一道程序向另外一道程的切…...

[ICLR 2016] Unsupervised representation learning with DCGANs
目录 IntroductionModel ArchitectureReferencesIntroduction 作者提出了用 CNN 搭建 GAN,使得 GAN 训练更加稳定的一系列准则,并将满足这些设计理念的模型称为 DCGANs (Deep Convolutional GANs). 此外,作者将 trained discriminators 用于图像分类任务,相比于其他无监督算…...

QT编程从入门到精通之十五:“第五章:Qt GUI应用程序设计”之“5.1 UI文件设计与运行机制”之“5.1.2 项目管理文件”
目录 第五章:Qt GUI应用程序设计 5.1 UI文件设计与运行机制 5.1.2 项目管理文件 第五章:Qt GUI应用程序设计 在“Qt 程序创建基础”上,本章将继续深入地介绍Qt Creator设计GUI应用程序的方法...

基于Three.js和MindAR实现的网页端WebAR人脸识别追踪功能的京剧换脸Demo(含源码)
前言 近段时间一直在玩MindAR的功能,之前一直在弄图片识别追踪的功能,发现其强大的功能还有脸部识别和追踪的功能,就基于其面部网格的例子修改了一个国粹京剧的换脸程序。如果你不了解MindAR的环境配置可以先参考这篇文章:基于Mi…...

动态规划思路
拉勾教育版权所有:https://kaiwu.lagou.com/course/courseInfo.htm?courseId3 动态规划思路 1.最优子结构 2.重复计算子机构 3.依靠递归,层层向上传值,所以编程时初始化子结构很重要 动态规划步骤 1.判断动态规划的类型 1.线性规划 >&…...

HTTPS关键词语解释和简单通讯流程
1、 什么是HTTPS HTTPS是基于HTTP的上层添加了一个叫做TLS的安全层,对数据的加密等操作都是在这个安全层中进行处理的,其底层还是应用的HTTP。 2、 什么是对称加密; 加密和解密都是用同一个秘钥 3、 什么是非对称加密; 加密和…...

“前端开发中的三种定时任务及其应用“
前端定时任务是指在一定时间间隔内,自动执行指定的操作或函数。在前端开发中,定时任务被广泛应用于诸如数据更新、定时提醒、定时刷新页面等方面。在本文中,我们将介绍前端中常见的三种定时任务,分别是 setTimeout、setInterval 和…...
| 机考必刷)
华为OD机试题 - 猜字谜(JavaScript)| 机考必刷
更多题库,搜索引擎搜 梦想橡皮擦华为OD 👑👑👑 更多华为OD题库,搜 梦想橡皮擦 华为OD 👑👑👑 更多华为机考题库,搜 梦想橡皮擦华为OD 👑👑👑 华为OD机试题 最近更新的博客使用说明本篇题解:猜字谜题目输入输出描述备注示例一输入输出示例二输入输出思路C…...

光耦LED寿命评估与可靠性设计实践
1. 光耦LED寿命评估的核心价值 在工业自动化控制系统中,我曾亲眼目睹一个价值数百万的生产线因为光耦器件失效导致整个控制系统误动作。故障排查时发现,正是光耦内部的LED光源经过5年连续工作后出现严重光衰,使得信号传输出现错误。这个教训让…...

模拟内存计算与ReRAM在触觉手势识别中的应用
1. 模拟内存计算技术概述模拟内存计算(Analog In-Memory Computing,简称AiMC)正在彻底改变传统计算架构的设计范式。这项技术的核心突破在于打破了困扰计算领域长达半个多世纪的"冯诺依曼瓶颈"——即处理器与存储器之间的数据搬运带…...

别再死记硬背了!用PyTorch和TensorFlow动手实现池化层,5分钟搞懂Max Pooling和Average Pooling的区别
用PyTorch和TensorFlow实战池化层:5分钟可视化Max与Average Pooling差异 刚接触深度学习的开发者常被各种理论概念困扰,尤其是池化层这类看似简单却暗藏玄机的操作。与其死记硬背定义,不如打开Jupyter Notebook,用PyTorch和Tensor…...
)
PyTorch/TensorFlow深度学习环境搭建:在Windows10上一步到位搞定CUDA和cuDNN(避坑合集)
PyTorch/TensorFlow深度学习环境搭建:在Windows10上一步到位搞定CUDA和cuDNN(避坑合集) 刚入坑深度学习的开发者,最头疼的莫过于环境配置。明明按照教程一步步安装了PyTorch或TensorFlow,却在代码运行时看到CUDA不可用…...

宠物胰岛素注射剂量安全指南:从单位与毫升混淆到规范操作
1. 从一次惊险的“救援”说起:宠物用药中的剂量迷思昨天早上,我差点目睹了一场因误解而引发的悲剧。走进厨房准备冲杯咖啡时,我看到一位同事(我们暂且称她为“A女士”)正准备给她刚被诊断为糖尿病的小狗注射胰岛素。她…...

3分钟掌握PC端聊天软件防撤回:RevokeMsgPatcher实战指南
3分钟掌握PC端聊天软件防撤回:RevokeMsgPatcher实战指南 【免费下载链接】RevokeMsgPatcher :trollface: A hex editor for WeChat/QQ/TIM - PC版微信/QQ/TIM防撤回补丁(我已经看到了,撤回也没用了) 项目地址: https://gitcode.…...

构建工业级电力通信系统的终极指南:libiec61850开源库深度解析
构建工业级电力通信系统的终极指南:libiec61850开源库深度解析 【免费下载链接】libiec61850 Official repository for libIEC61850, the open-source library for the IEC 61850 protocols 项目地址: https://gitcode.com/gh_mirrors/li/libiec61850 在现代…...

rust-rdkafka社区生态与最佳实践:知名项目使用案例分享
rust-rdkafka社区生态与最佳实践:知名项目使用案例分享 【免费下载链接】rust-rdkafka A fully asynchronous, futures-based Kafka client library for Rust based on librdkafka 项目地址: https://gitcode.com/gh_mirrors/ru/rust-rdkafka rust-rdkafka是…...

【Git Graph】 全解析:把Git提交历史玩明白的开发者神器
写在前面:无论是个人开发还是团队协作,Git早已是开发者的标配工具。但90%的开发者都踩过同一个Git的坑:对着命令行里密密麻麻的提交记录发呆,看不懂多分支的分叉与合并流向,想回滚版本却找不到对应的commit,…...

专业指南:Anno 1800 Mod Loader完整使用教程与架构解析
专业指南:Anno 1800 Mod Loader完整使用教程与架构解析 【免费下载链接】anno1800-mod-loader The one and only mod loader for Anno 1800, supports loading of unpacked RDA files, XML merging and Python mods. 项目地址: https://gitcode.com/gh_mirrors/an…...