Linux时间子系统6:NTP原理和Linux NTP校时机制
一、前言
上篇介绍了时间同步的基本概念和常见的时间同步协议NTP、PTP,本篇将详细介绍NTP的原理以及NTP在Linux上如何实现校时。
二、NTP原理介绍
1. 什么是NTP
网络时间协议(英语:Network Time Protocol,缩写:NTP)是在计算机系统之间通过分组交换进行时钟同步的一个网络协议,位于OSI模型的应用层。用来使客户端和服务器之间进行时钟同步,提供高精准度的时间校正。NTP服务器从权威时钟源(例如原子钟、GPS)接收精确的协调世界时UTC,客户端再从服务器请求和接收时间。
NTP基于UDP报文进行传输,使用的UDP端口号为123。
2. NTP协议发展历史
NTP是由美国Delaware大学David L .Mills教授设计的,是最早用于网络中时钟同步的标准之一。NTP是从时间协议和ICMP时间戳报文演变而来,当前协议为版本4(NTPv4),这是一个RFC 5905文档中的建议标准。它向下兼容指定于RFC 1305的版本3
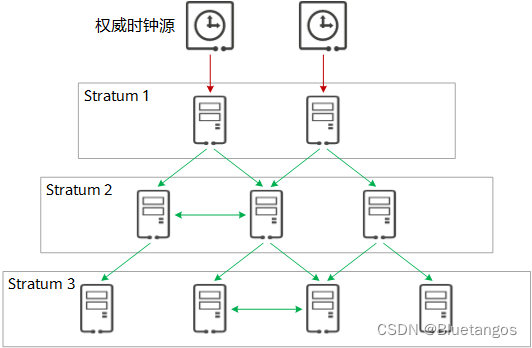
3. NTP时钟层级
NTP允许客户端从服务器请求和接收时间,而服务器又从权威时钟源(例如原子钟、GPS)接收精确的协调世界时UTC。
NTP以层级来组织模型结构,层级中的每层被称为Stratum。通常将从权威时钟获得时钟同步的NTP服务器的层数设置为Stratum 1,并将其作为主时间服务器,为网络中其他的设备提供时钟同步。而Stratum 2则从Stratum 1获取时间,Stratum 3从Stratum 2获取时间,以此类推。时钟层数的取值范围为1~16,取值越小,时钟准确度越高。层数为1~15的时钟处于同步状态;层数为16的时钟被认为是未同步的,不能使用的。
4. NTP同步原理
NTP最典型的授时方式是Client/Server方式,如下图所示。
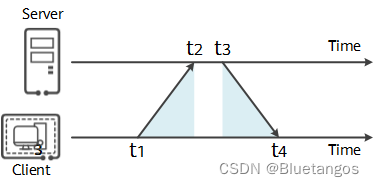
- 客户端首先向服务端发送一个NTP请求报文,其中包含了该报文离开客户端的时间戳t1;
- NTP请求报文到达NTP服务器,此时NTP服务器的时刻为t2。当服务端接收到该报文时,NTP服务器处理之后,于t3时刻发出NTP应答报文。该应答报文中携带报文离开NTP客户端时的时间戳t1、到达NTP服务器时的时间戳t2、离开NTP服务器时的时间戳t3;
- 客户端在接收到响应报文时,记录报文返回的时间戳t4。
客户端用上述4个时间戳参数就能够计算出2个关键参数:
- NTP报文从客户端到服务器的往返延迟delay。
![]()
- 客户端与服务端之间的时间差offset。
根据方程组:

NTP客户端根据计算得到的offset来调整自己的时钟,实现与NTP服务器的时钟同步。
三、内核对NTP校时的支持
在之前时钟源clocksource和timekeeper的文章中,我们介绍到通常每个tick的定时中断周期,do_timer会被调用一次. 在do_timer中,调用update_wall_time函数完成xtime等时间的更新操作,更新时间的核心操作就是读取关联clocksource的计数值,累加到xtime等字段中,每过一个tick中断,xtime就增加1Hz对应的时间
而Ntp可以调整每个tick中断xtime增加的毫秒数,让系统时间走快些或走慢些。
1. timekeeper中的ntp成员
ntp_tick:记录了NTP周期的纳秒数
ntp_error:TP时间和当前实时时间之间的差值,如果ntp_error大于0,表示当前系统的实时时间慢于NTP时间,相反如果小于0则表示快于NTP时间
ntp_error_shift:存放了NTP的shift和时钟源设备shift之间的差值。NTP层也需要对纳秒数做shift的操作,其值由宏NTP_SCALE_SHIFT定义,
ntp_err_mult:如果ntp_error大于0,则为1,否则都是0。
在tk_setup_internals函数中,对上述变量进行了初始化,
tk->ntp_error = 0;tk->ntp_error_shift = NTP_SCALE_SHIFT - clock->shift;tk->ntp_tick = ntpinterval << tk->ntp_error_shift;
一开始ntp_error被设置为0,也就是没有累积错误,shift被设置为NTP层的shift和时钟源设备shift之间的差值,ntp_tick其实最终被设置成了NTP_INTERVAL_LENGTH<<NTP_SCALE_SHIFT。
2. NTP调整内核时钟的系统调用
一般来讲,调整时间有多种方式,包括直接设置时间,根据时间差offset调整时间(在当前时间上增加offset),以及调整时钟频率(根据时间跑的慢或者是快,说明当前的时钟频率存在偏移),对于系统时钟来说就是每个cycle对应的ns数,也就对应到mult和shift。
NTP可以使用adjtimex和ntp_adjtime函数来调整系统时间,内核对这两个函数的支持并没有本质区别。adjtimex支持多种调节方式
Ntp校时可分为内核模式和ntp模式这两种模式。。在ntp.conf文件中可以配置使用哪种模式校时,当两种模式都打开时,只有内核模式起作用。Ntpd默认两种模式都打开的。
enable kernel
enable ntp
disable kernel
disable ntp
NTP的系统调用ntp_adjtime和adjtime,在内核模式中,ntpd在用户态调用ntp_adjtime修改内核的频率。在ntp模式中,ntpd在用户态调用adjtime修改内核的time_adjust变量。
2. NTP的全局变量tick_length
我们观察ntp_tick的使用,发现在使用中,timekeeping模块通过ntp_tick_length函数获取最新的ntp_tick,并且根据获取到的ntp_tick判断是否要进行校时,ntp_tick_length返回的是ntp.c中定义的tick_length全局变量,如下:
u64 ntp_tick_length(void)
{return tick_length;
}那么tick_lenth又是如何计算得到的呢?
在内核ntp.c文件second_overflow函数中可以看出,tick_length等于tick_length_base加上time_adjust的和,即tick_length的值由tick_length_base和time_adjust决定。Ntp服务正是通过修改tick_length_base和time_adjust的值来修改系统的tick_length,让系统走快或走慢。
【对比一下几种改变系统时间速度的方式】
1、 adjtimex –t 命令通过修改tick_usec变量来间接修改tick_length_base变量的值。
2、 adjtimex –f 命令通过修改time_freq变量来间接修改tick_length_base变量的值。
3、 ntpd的ntp模式修改内核的time_adjust变量。
上述几种方式修改的内核变量(tick_usec, time_freq, time_adjust),它们加起来影响着tick_length变量的值(每个tick的时长)。内核timekeeping.c文件中的update_wall_time函数中会用tick_length变量不停地调整系统时间xtime,让系统时间走快或走慢。L
相关文章:
Linux时间子系统6:NTP原理和Linux NTP校时机制
一、前言 上篇介绍了时间同步的基本概念和常见的时间同步协议NTP、PTP,本篇将详细介绍NTP的原理以及NTP在Linux上如何实现校时。 二、NTP原理介绍 1. 什么是NTP 网络时间协议(英语:Network Time Protocol,缩写:NTP&a…...

边缘微型AI的宿主?—— RISC-V芯片
一、RISC-V技术 RISC-V(发音为 "risk-five")是一种基于精简指令集计算(RISC)原则的开放源代码指令集架构(ISA)。它由加州大学伯克利分校在2010年首次发布,并迅速获得了全球学术界和工…...

MySQL—navicat创建数据库表
-- 创建学生表(列,字段) 使用SQL创建 -- 学号int 登录密码varchar(20) 姓名,性别varchar(2),出生日期(datetime),家庭住址,email -- 注意点:使用英文括号(),表的名称 …...
html做一个画柱形图的软件
你可以使用 HTML、CSS 和 JavaScript 创建一个简单的柱形图绘制软件。为了方便起见,我们可以使用一个流行的 JavaScript 图表库,比如 Chart.js,它能够简化创建和操作图表的过程。 以下是一个完整的示例,展示如何使用 HTML 和 Cha…...
Pyshark——安装、解析pcap文件
1、简介 PyShark是一个用于网络数据包捕获和分析的Python库,基于著名的网络协议分析工具Wireshark和其背后的libpcap/tshark库。它提供了一种便捷的方式来处理网络流量,适用于需要进行网络监控、调试和研究的场景。以下是PyShark的一些关键特性和使用方…...

java中的Random
Random 是 Java 中的一个内置类,它位于 java.util 包中,主要用于生成伪随机数。伪随机数是指通过一定算法生成的、看似随机的数,但实际上这些数是由确定的算法生成的,因此不是真正的随机数。然而,由于这些数在统计上具…...
PyMuPDF 操作手册 - 01 从PDF中提取文本
文章目录 一、打开文件二、从 PDF 中提取文本2.1 文本基础操作2.2 文本进阶操作2.2.1 从任何文档中提取文本2.2.2 如何将文本提取为 Markdown2.2.3 如何从页面中提取键值对2.2.4 如何从矩形中提取文本2.2.5 如何以自然阅读顺序提取文本2.2.6 如何从文档中提取表格内容2.2.6.1 提…...

ResNet——Deep Residual Learning for Image Recognition(论文阅读)
论文名:Deep Residual Learning for Image Recognition 论文作者:Kaiming He et.al. 期刊/会议名:CVPR 2016 发表时间:2015-10 论文地址:https://arxiv.org/pdf/1512.03385 1.什么是ResNet ResNet是一种残差网络&a…...
)
java基础·小白入门(五)
目录 内部类与Lambda表达式内部类Lambda表达式 多线程 内部类与Lambda表达式 内部类 在一个类中定义另外一个类,这个类就叫做内部类或内置类 (inner class) 。在main中直接访问内部类时,必须在内部类名前冠以其所属外部类的名字才能使用;在…...
微观时空结构和虚数单位的关系
回顾虚数单位的定义, 其中我们把称为周期(的绝大部分),称为微分,0称为原点或者起点(意味着新周期的开始),由此我们用序数的概念反过来构建了基数的概念。 周期和单位显然具有倍数关…...

go-zero使用goctl生成mongodb的操作使用方法
目录 MongoDB简介 MongoDB的优势 对比mysql的操作 goctl的mongodb代码生成 如何使用 go-zero中mogodb使用 mongodb官方驱动使用 model模型的方式使用 其他资源 MongoDB简介 mongodb是一种高性能、开源、文档型的nosql数据库,被广泛应用于web应用、大数据以…...
服务器新硬盘分区、格式化和挂载
文章目录 参考文献查看了一下起点现状分区(base) ~ sudo parted /dev/sdcmklabel gpt(设置分区类型)增加分区 格式化需要先退出quit(可以)(base) / sudo mkfs.xfs /dev/sdc/sdc1(失败)sudo mkfs.xfs /dev/s…...

Openldap集成Kerberos
文章目录 一、背景二、Openldap集成Kerberos2.1kerberos服务器中绑定Ldap服务器2.1.1创建LDAP管理员用户2.1.2添加principal2.1.3生成keytab文件2.1.4赋予keytab文件权限2.1.5验证keytab文件2.1.6增加KRB5_KTNAME配置 2.2Ldap服务器中绑定kerberos服务器2.2.1生成LDAP数据库Roo…...
(创新)基于VMD-CNN-BiLSTM的电力负荷预测—代码+数据
目录 一、主要内容: 二、运行效果: 三、VMD-BiLSTM负荷预测理论: 四、代码数据下载: 一、主要内容: 本代码结合变分模态分解( Variational Mode Decomposition,VMD) 和卷积神经网络(Convolutional neu…...

机器 reboot 后 kubelet 目录凭空消失的灾难恢复
文章目录 [toc]事故背景报错内容 修复过程停止 kubelet 服务备份 kubelet.config重新生成 kubelet.config重新生成 kubelet 配置文件对比 kubeadm-flags.env 事故背景 因为一些情况,需要 reboot 服务器,结果 reboot 机器后,kubeadm init 节点…...

Pytorch构建vgg16模型
VGG-16 1. 导入工具包 import torch.optim as optim import torch import torch.nn as nn import torch.utils.data import torchvision.transforms as transforms import torchvision.datasets as datasets from torch.utils.data import DataLoader import torch.optim.lr_…...
分支结构相关
1.if 语句 结构: if 条件语句: 代码块 小练习: 使用random.randint()函数随机生成一个1~100之间的整数,判断是否是偶数 import random n random.randint(1,100) print(n) if n % 2 0:print(str(n) "是偶数") 2.else语…...

flutter开发实战-RichText富文本居中对齐
flutter开发实战-RichText富文本居中对齐 在开发过程中,经常会使用到RichText,当使用RichText时候,不同文本字体大小默认没有居中对齐。这里记录一下设置过程。 一、使用RichText 我这里使用RichText设置不同字体大小的文本 Container(de…...
智慧消防新篇章:可视化数据分析平台引领未来
一、什么是智慧消防可视化数据分析平台? 智慧消防可视化数据分析平台,运用大数据、云计算、物联网等先进技术,将消防信息以直观、易懂的图形化方式展示出来。它不仅能够实时监控消防设备的运行状态,还能对火灾风险进行预测和评估…...

u8g2 使用IIC驱动uc1617 lcd有时候某些像素显示不正确
折腾了很久,本来lcd是挂载到已经存在的iic总线上的,总线原来是工作正常的,挂载之后lcd也能显示,但是有时候显示不正确,有时候全白的时候有黑色的杂点。 解决方案: 1.最开始以为是IIC总线速度快࿰…...

量子噪声对机器学习模型的影响与缓解策略
1. 量子噪声与机器学习模型的复杂关系量子计算领域近年来最令人兴奋的进展之一,就是量子机器学习(QML)的兴起。作为一名长期跟踪量子计算发展的从业者,我亲眼见证了量子算法在机器学习任务中展现出的惊人潜力。然而,在…...

欢迎来到Marp世界
欢迎来到Marp世界 【免费下载链接】marp The entrance repository of Markdown presentation ecosystem 项目地址: https://gitcode.com/gh_mirrors/mar/marp 用Markdown创建专业演示文稿从未如此简单! 第二张幻灯片 列表项1列表项2列表项3 第三张幻灯片&am…...

RDMA之从userspace verbs 到kernel verbs
用户态RDMA(userspace verbs)RDMA是一种高性能网络协议,一般用在GPU集群的高速通信库,如NCCL、NVSHMEM等,这些都是用户态通信库,我们熟知的RDMA大部分都是用户态RDMA。比如,如下一个简单的RDMA程序int main() { // 1…...

基于LLM的多智能体协作框架:从原理到实践构建自主开发团队
1. 项目概述与核心价值最近在开源社区里,一个名为zxkane/autonomous-dev-team的项目引起了我的注意。乍一看这个标题,你可能会联想到科幻电影里的全自动机器人编程,或者是一些过于理想化的“AI接管开发”的噱头。但在我花时间深入研究和实践之…...

终极指南:如何使用Etcher安全快速烧录系统镜像到SD卡和USB驱动器
终极指南:如何使用Etcher安全快速烧录系统镜像到SD卡和USB驱动器 【免费下载链接】etcher Flash OS images to SD cards & USB drives, safely and easily. 项目地址: https://gitcode.com/GitHub_Trending/et/etcher Etcher(BalenaEtcher&am…...

计算机视觉入门:从OpenCV到PyTorch的实践指南
1. 项目概述:从“萌芽”到“入行”的视觉之旅 “对计算机视觉的萌芽迷恋”——这个标题精准地捕捉了无数技术爱好者,包括我自己,最初踏入这个领域时的心路历程。它描述的是一种状态:你或许被一张AI生成的艺术图片所震撼ÿ…...

基于双链笔记构建个人消费知识系统:从记录到生活策展
1. 项目概述与核心价值看到“SimonsTang/xiaofei-liberal-arts”这个项目标题,我的第一反应是,这应该是一个关于“消费”与“文科”交叉领域的知识库或工具集。作为一名长期关注效率工具和知识管理的从业者,我深知在信息爆炸的时代࿰…...

EdgeDB监控告警:生产环境运维监控体系构建终极指南
EdgeDB监控告警:生产环境运维监控体系构建终极指南 【免费下载链接】edgedb Gel supercharges Postgres with a modern data model, graph queries, Auth & AI solutions, and much more. 项目地址: https://gitcode.com/gh_mirrors/ed/edgedb EdgeDB是一…...

中小项目如何通过按token计费模式灵活启动AI功能
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 中小项目如何通过按token计费模式灵活启动AI功能 对于预算有限的中小项目团队而言,在探索产品方向、验证市场需求的早期…...

那些被“写不动“耽误的好想法,现在可以试了
脑子里的想法永远比手头的代码多。想做一个新的仲裁逻辑,想验证一种不同的流水线划分,想试试那个"也许能行"的微架构调整——但最终都没动手,因为光是搭环境、写testbench、跑仿真这一套下来,没有一两周根本出不了结论。…...