关于多线程的理解
#系列文章
关于时间复杂度o(1), o(n), o(logn), o(nlogn)的理解
关于HashMap的哈希碰撞、拉链法和key的哈希函数设计
关于JVM内存模型和堆内存模型的理解
关于代理模式的理解
关于Mysql基本概念的理解
关于软件设计模式的理解
关于Redis知识的理解
文章目录
- 前言
- 一、线程的基本概念?
- 线程
- 并发与并行
- 线程创建
- 线程同步
- 线程间通信
- 线程状态
- 二、创建线程的方式
- 1.继承Thread类
- 2.实现Runnable接口
- 3.实现Callable接口
- 三、synchronized和volatile区别?
- volatile
- synchronized
- 四、synchronized和lock(CAS)的区别和案例场景
- 区别
- 案例场景
- 五、sleep方法和wait方法有什么区别
- 六、ThreadLocal作用和实现方式?ThreadLocal会不会发生内存泄漏?
- ThreadLocal的作用
- 实现方式
- ThreadLocal与内存泄漏
前言
Java多线程是Java编程中一个非常重要的概念,它允许程序同时执行多个任务。这对于提高程序的效率、响应速度和实现复杂的并发处理至关重要。
一、线程的基本概念?
线程
线程是程序执行流的最小单元。一个进程中可以包含多个线程,每个线程都运行在进程的上下文中,并共享进程的资源(如内存、文件句柄等)。
并发与并行
并发是指两个或多个事件在同一时间段内发生,而并行是指两个或多个事件在同一时刻同时发生。在多核CPU上,线程可以真正并行执行;在单核CPU上,通过时间片轮转,实现了线程的并发执行。
线程创建
继承Thread类;实现Runnable接口;实现Callable接口
线程同步
由于多个线程共享进程资源,可能会引发数据不一致的问题,因此需要线程同步机制来控制对共享资源的访问。Java提供了以下几种同步机制:
synchronized关键字 可以用于方法或代码块,确保同一时间只有一个线程可以执行该段代码。
Lock接口 java.util.concurrent.locks.Lock提供比synchronized更灵活的锁定机制,允许尝试锁定、定时锁定以及公平性锁等
线程间通信
wait(), notify(), notifyAll() 这些方法用于线程间的等待/通知机制,必须在同步代码块或同步方法中使用。
join() 让当前线程等待调用join方法的线程结束后再继续执行。
线程池 通过ExecutorService接口和它的实现类(如ThreadPoolExecutor)来管理和控制线程,以提高资源利用率和响应速度
线程状态
新建(New) 线程被创建但尚未启动。
可运行(Runnable) 线程可以在任何时刻被JVM选中执行。
阻塞(Blocked) 等待获取监视器锁,以便进入同步区域执行。
等待(Waiting) 无限期等待直到被其他线程显式唤醒,或者调用了Object.wait()。
超时等待(Timed Waiting) 类似于等待状态,但可以在指定时间内自行返回,如通过Thread.sleep(long millis)。
终止(Terminated) 线程已结束执行。
二、创建线程的方式
1.继承Thread类
创建一个新的类继承Thread类,重写其run()方法,在这个方法中定义需要并行执行的代码。然后创建该类的实例,并调用start()方法启动线程。
代码如下(示例):
class MyThread extends Thread {public void run() {System.out.println("通过继承Thread类创建线程");}
}MyThread t = new MyThread();
t.start();
2.实现Runnable接口
创建一个类实现Runnable接口,实现run()方法,然后将该类的实例作为参数传递给Thread类的构造器,创建Thread对象后调用start()方法启动线程。
代码如下(示例):
class MyRunnable implements Runnable {public void run() {System.out.println("通过实现Runnable接口创建线程");}
}Thread t = new Thread(new MyRunnable());
t.start();
3.实现Callable接口
在Java中,除了继承Thread类和实现Runnable接口之外,还可以通过实现Callable接口结合Future和ExecutorService来创建线程。这种方式相比前两者提供了更强大的功能,特别是能够获取线程执行的结果并且可以处理异常。
Callable接口类似于Runnable,但提供了返回结果和抛出异常的能力。它有一个抽象方法call(),该方法可以返回结果并声明抛出异常。
import java.util.concurrent.Callable;public class MyCallable implements Callable<Integer> {@Overridepublic Integer call() throws Exception {int sum = 0;for (int i = 0; i < 100; i++) {sum += i;}return sum; // 可以返回计算结果}
}Future接口
Future接口代表异步计算的结果。它提供了检查计算是否完成、获取计算结果、取消计算等方法。
ExecutorService接口
ExecutorService是一个更高级的线程管理工具,它是java.util.concurrent.Executor接口的实现,可以用来管理Runnable和Callable任务的执行。
下面是如何使用Callable、Future和ExecutorService创建并执行线程的例子:
代码如下(示例):
import java.util.concurrent.*;public class CallableAndFutureExample {public static void main(String[] args) throws ExecutionException, InterruptedException {// 创建一个线程池ExecutorService executorService = Executors.newSingleThreadExecutor();// 提交Callable任务并获取Future对象Future<Integer> future = executorService.submit(new MyCallable());// 在这里,主线程可以继续执行其他任务,不必等待计算完成// 获取并打印结果,如果计算未完成则会阻塞直到有结果System.out.println("结果为: " + future.get());// 关闭线程池executorService.shutdown();}
}
在这个例子中,我们创建了一个MyCallable类实现了Callable接口,用于计算0到99的和。然后通过ExecutorService的submit(Callable task)方法提交任务并立即返回一个Future对象。我们可以使用future.get()来获取异步计算的结果,此方法会阻塞直到结果可用。最后,记得关闭ExecutorService来释放资源。
通过这种方式,Java提供了更灵活、功能更全面的多线程编程模型,特别适合需要获取线程执行结果或需要处理线程中抛出异常的场景。
三、synchronized和volatile区别?
volatile和synchronized都是Java中用于实现线程同步和保证数据一致性的关键字,但它们的工作机制、使用场景和提供的保证各不相同:
volatile
作用范围: volatile只能应用于变量,不能用于方法或代码块。
保证特性: 它保证了变量的可见性和有序性,但不保证原子性。这意味着一旦一个线程修改了volatile变量,其他线程可以立即看到这个修改。同时,可以防止指令重排优化,确保程序按照预期的顺序执行。
性能: 相比于synchronized,使用volatile变量通常具有更好的性能,因为它不会引起线程的阻塞。
适用场景: 适用于那些读多写少、只需保证可见性而不涉及复杂同步操作的场景,比如标志位、双重检查锁定中的非volatile变量初始化检查等。
synchronized
作用范围: synchronized可以应用于方法、代码块或者静态方法,范围更广泛。
保证特性: synchronized不仅保证了可见性和有序性,还确保了原子性,即在synchronized代码块或方法内的操作不会被其他线程打断,实现了线程安全。
==性能:==由于其通过互斥锁机制实现同步,可能会导致线程的阻塞和上下文切换,因此在某些情况下性能不如volatile。
内存开销与阻塞: 使用synchronized会有额外的内存开销,因为它涉及到锁的获取与释放。当一个线程获取到锁时,其他请求锁的线程将会阻塞,直到锁被释放。
适用场景:适用于需要保护的临界区操作,如对集合的修改、多线程间的协作控制等复杂同步逻辑。
四、synchronized和lock(CAS)的区别和案例场景
synchronized和基于CAS(Compare and Swap)的Lock机制(如ReentrantLock)在Java中都是用于实现线程同步和解决并发问题的工具,但它们在实现原理、使用方式和特性上有所不同。
区别
实现机制
synchronized是Java语言层面的原生支持,基于JVM层面的Monitor对象来实现,通过进入和退出Monitor来实现同步控制。
基于CAS的Lock,如ReentrantLock,是Java并发包java.util.concurrent.locks中的接口实现,它依赖于AbstractQueuedSynchronizer(AQS)框架,使用自旋、阻塞队列等技术,并通过CPU级别的CAS指令来实现乐观锁,以达到线程同步的目的。
锁的获取与释放
synchronized自动管理锁的获取和释放。对于非静态同步方法或同步代码块,锁与对象实例相关联;对于静态同步方法,锁与类的Class对象关联。当同步块或方法执行完毕,无论是正常结束还是异常结束,JVM都会自动释放锁。
使用Lock接口(如ReentrantLock),需要手动调用lock()获取锁,unlock()释放锁。这要求程序员必须在合适的时机手动释放锁,否则可能导致死锁。
公平性
synchronized锁默认是非公平的,即等待的线程获取锁的顺序不确定,可能会导致某些线程长时间等待(饥饿现象)。
ReentrantLock允许选择公平策略,通过构造函数指定是否为公平锁。公平锁会按照线程等待的先后顺序分配锁,减少饥饿现象,但可能会影响性能。
性能与可中断性
synchronized在早期版本中性能较差,但在Java 6之后有了显著优化,如偏向锁、轻量级锁等机制,性能与Lock差距缩小。
Lock提供了更灵活的锁等待机制,如tryLock()方法尝试获取锁而不阻塞,以及支持可中断的等待(tryLock(long time, TimeUnit unit)),提高了并发控制的灵活性和响应性。
案例场景
synchronized场景
当需要简单的线程同步,且锁的生命周期与同步代码块或方法紧密相关时,使用synchronized更为简洁便利。例如,保护一个共享资源的读写操作,防止数据不一致问题。
Lock(如ReentrantLock)场景
当需要更细粒度的锁控制,如尝试获取锁、可中断的等待、公平锁等高级特性时,选择Lock更为合适。例如,在构建高性能的并发组件、需要控制锁的持有时间以减少阻塞时,或者需要精确控制锁的释放时机,比如在finally块中释放锁以确保异常安全。
五、sleep方法和wait方法有什么区别
sleep方法和wait方法在Java中都用于暂停线程的执行,但它们之间存在几个关键区别:
来源与所属
sleep方法属于Thread类,是一个静态方法,这意味着它可以被任何线程调用,且作用于当前执行该方法的线程。
wait方法属于Object类,是一个实例方法,必须在某个对象上调用。这意味着要调用wait,线程必须已经拥有了该对象的监视器(即执行同步代码块或方法时)。
锁的处理
当线程调用sleep方法时,它不会释放任何锁。即使在同步代码块或方法中调用sleep,当前线程仍会保持它所持有的锁。
调用wait方法会导致当前线程释放它所持有的对象的监视器锁,从而使其他等待该对象锁的线程有机会执行。这促进了线程间的交互与通信。
唤醒机制
sleep方法会根据指定的时间让线程暂停执行,时间结束后线程会自动恢复执行,无需其他线程干预。
wait方法使线程等待,直到其他线程调用同一个对象上的notify()或notifyAll()方法来唤醒它。如果没有指定等待时间,wait会一直等待,直到被通知。
异常处理
sleep方法声明抛出InterruptedException,当线程在等待期间被中断时会抛出此异常。调用者可以选择捕获并处理这个异常。
wait方法同样声明抛出InterruptedException,但实践中通常在调用wait时不需要显式捕获这个异常。
使用场景
sleep通常用于让当前线程暂停执行一段时间,以避免过于频繁的操作或让出CPU给其他线程,不涉及线程间的通信。
wait主要用于线程间的同步,当一个线程需要等待某个条件满足时(通常由其他线程改变该条件),会调用对象的wait方法,等待其他线程通过notify或notifyAll来唤醒。
总结来说,sleep主要用于让线程自身暂时休息,不涉及线程间的交互,而wait则是线程间同步和通信的重要手段,需要与notify/notifyAll一起使用来协调线程之间的执行顺序。
六、ThreadLocal作用和实现方式?ThreadLocal会不会发生内存泄漏?
ThreadLocal的作用
ThreadLocal主要用于创建线程局部变量。它的主要特点和作用包括:
线程隔离:每个线程都有自己的ThreadLocal变量副本,线程之间互不影响,这有助于避免多线程环境下的同步问题。
简化共享数据的访问:在多线程环境下,ThreadLocal可以为每个线程提供独立的变量副本,减少了线程间的数据传递和同步开销。
降低耦合度:它可以降低代码间尤其是跨类、跨层的耦合,使得变量的访问更加方便和安全。
实现方式
ThreadLocal的实现基于内部类ThreadLocalMap,这是一个定制化的哈希映射,键是ThreadLocal实例本身,值是各个线程需要保存的变量副本。每个线程都有一个这样的ThreadLocalMap,存储着属于自己的ThreadLocal变量副本。
当你通过ThreadLocal的set(value)方法设置值时,实际上是将这个值放入当前线程的ThreadLocalMap中,对应的键就是这个ThreadLocal实例。
当调用get()方法时,会从当前线程的ThreadLocalMap中根据ThreadLocal实例找到对应的值。
如果没有设置过值,通常get()会返回ThreadLocal的初始值(如果有提供的话)。
ThreadLocal与内存泄漏
ThreadLocal确实有可能引起内存泄漏,主要原因在于它的内部实现ThreadLocalMap。以下是可能导致内存泄漏的情况:
未清理的ThreadLocal引用
当ThreadLocal对象不再使用时,如果没有调用remove()方法,那么其对应的Entry(键值对)仍然会保留在ThreadLocalMap中。即使ThreadLocal实例本身被垃圾回收,但由于ThreadLocalMap的生命周期与线程相同,其Entry中的键(即弱引用的ThreadLocal实例)虽然会被回收,但value仍可能保持强引用状态,导致无法被垃圾回收。
线程池场景下的问题
在使用线程池的场景下,线程会被复用,如果ThreadLocal变量没有被正确清理,随着线程的反复使用,ThreadLocalMap中可能会积累大量不再使用的Entry,从而造成内存泄漏。
如何避免内存泄漏
ThreadLocalMap的设计中已经考虑到这种情况,也加上了一些防护措施:在ThreadLocal的get(),set(),remove()的时候都会清除线程ThreadLocalMap里所有key为null的value。
相关文章:

关于多线程的理解
#系列文章 关于时间复杂度o(1), o(n), o(logn), o(nlogn)的理解 关于HashMap的哈希碰撞、拉链法和key的哈希函数设计 关于JVM内存模型和堆内存模型的理解 关于代理模式的理解 关于Mysql基本概念的理解 关于软件设计模式的理解 关于Redis知识的理解 文章目录 前言一、线程…...

C语言 | Leetcode C语言题解之第155题最小栈
题目: 题解: //单调栈 单调递减 typedef struct {//正常 stackint stack[10000];int stackTop;//辅助 stackint minStack[10000];int minStackTop; } MinStack;MinStack* minStackCreate() {MinStack* newStack (MinStack *) malloc(sizeof(MinS…...

Qdrant 的基础教程
目录 安装Qdrant安装Qdrant客户端初始化Qdrant客户端创建集合(Collection)插入向量数据创建索引搜索向量清理资源 Qdrant是一个开源的向量数据库,它专注于高维向量的快速相似性搜索。以下是一个基础的Qdrant教程,帮助你开始使用Qd…...

任务4.8.3 利用SparkSQL统计每日新增用户
实战概述:利用SparkSQL统计每日新增用户 任务背景 在大数据时代,快速准确地统计每日新增用户是数据分析和业务决策的重要部分。本任务旨在使用Apache SparkSQL处理用户访问历史数据,以统计每日新增用户数量。 任务目标 处理用户访问历史数…...
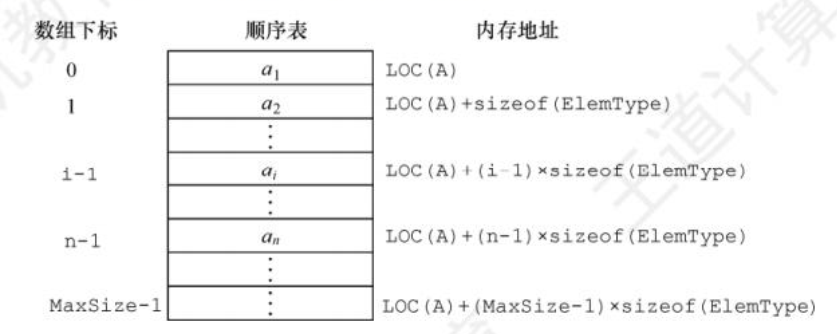
DS知识点总结--线性表定义及顺序表示
数据结构知识点汇总(考研C版) 文章目录 数据结构知识点汇总(考研C版)二、线性表2.1 线性表的定义和操作2.1.1 线性表的定义2.1.2 线性表的基本操作 2.2 线性表的顺序表示2.2.1 顺序表的定义2.2.2 顺序表上的基本操作的实现 二、线性表 2.1 线性表的定义和操作 2.1.1 线性表的…...

百度文库AI产品“橙篇”:支持10万字长文生成,开启AI创作新篇章
6月19日,百度文库发布了一款创新产品「橙篇」,这一行业首创的产品集成了10万字长文生成及多模态编辑能力,成为首个实现「查阅创编」一站式AI自由创作平台的里程碑。 百度“橙篇”官网: 地址:橙篇AI - 用橙篇…...

wsl子系统ubuntu20.04 设置docker服务开机自启动
docker的重要性毋庸置疑。掌握虚拟化必备工具。windows台式机相信大家都有,那么开启windows的wsl子系统ubuntu来熟悉linux分布式开发就方便多了,用不着另购电脑。docker是在有限成本前提下尽可能多的尝试使用多OS、隔离物理环境影响的方便工具。下面就介…...
SAP ScreenPersonas
https://developers.sap.com/mission.screen-personas.html 跟着这个练习做一遍就了解了Personas 访问SAP提供的Personas练习系统 申请用户 登录练习系统 随便找一个可以支持Personas的程序搞起来,比如IW51 执行后等它出现这个图标就可以开始了....
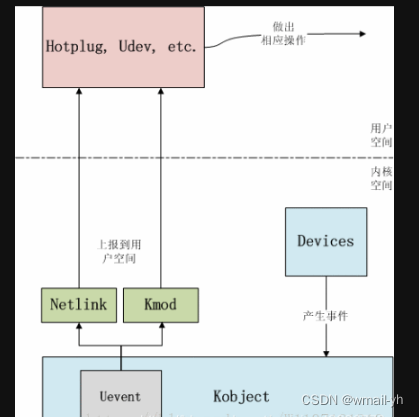
充电学习—3、Uevent机制和其在android层的实现
sysfs 是 Linux userspace 和 kernel 进行交互的一个媒介。通过 sysfs,userspace 可以主动去读写 kernel 的一些数据,同样的, kernel 也可以主动将一些“变化”告知给 userspace。也就是说,通过sysfs,userspace 和 ker…...

“河南省勘察设计资质整合趋势与企业应对“
"河南省勘察设计资质整合趋势与企业应对" 河南省勘察设计资质的整合趋势与企业应对策略可以从以下几个方面来分析: 整合趋势: 资质标准简化与合并:随着国家和地方政府深化“放管服”改革,勘察设计资质的管理趋向简化&…...

简单了解雪花算法
雪花算法是什么 不多解释。看一看 具体是怎么 生产 唯一ID 的。 ID 由多个数据组合拼接成64位,分别是 时间戳 服务器节点ID 序列号,每个数据项占的位数不固定,可以根据实际需求设置。首位 1 个二进制位 是 符号位。 public long allocate(l…...

决策树算法详细介绍原理和实现
决策树是一种常用的分类算法,它通过一系列的问题将数据分割成不同的分支,最终确定数据属于哪个类别。下面是决策树的原理、实现方式以及一个案例实现的详细介绍。 决策树原理 特征选择:决策树的构建过程首先需要选择一个特征作为节点&#…...
vue:vue2与vue3如何全局注册公共组件(包括涉及到的相关方法函数的讲解)
目录 第一章 vue2全局注册公共组件 1.1 方法一:逐个注册 1.2 方法二:批量注册 1.2.1 require.context()方法解释 第二章 vue3全局注册公共组件 1.1 方法一:逐个注册 1.2 方法二:批量注册 第一章 vue2全局注册公共组件 Vue…...

LoRa126X系列LoRa模块:专为物联网设计而生
LoRa126X是思为无线研发的一款应用于物联网应用的LoRa 前端模块系列,采用 Semtech 公司的 SX1262和SX1268 芯片。该系列模块具有小体积、低功耗,高灵敏度等特点,并且严格遵循无铅工艺生产和测试流程,符合 RoHS 和 Reach 环保标准。…...
)
个人职业规划(含前端职业线路、前端技术线路、前端核心竞争力、大龄程序员的出路)
1. 了解自己的兴趣与长处 喜欢擅长的事 职业方向 2. 设定长期目标(5年) 目标内容 建立自己的品牌建立自己的社交网络 适量参加社交活动,认识更多志同道合的小伙伴寻求导师指导 建立自己的作品集 注意事项 每年元旦进行审视和调整永葆积极…...
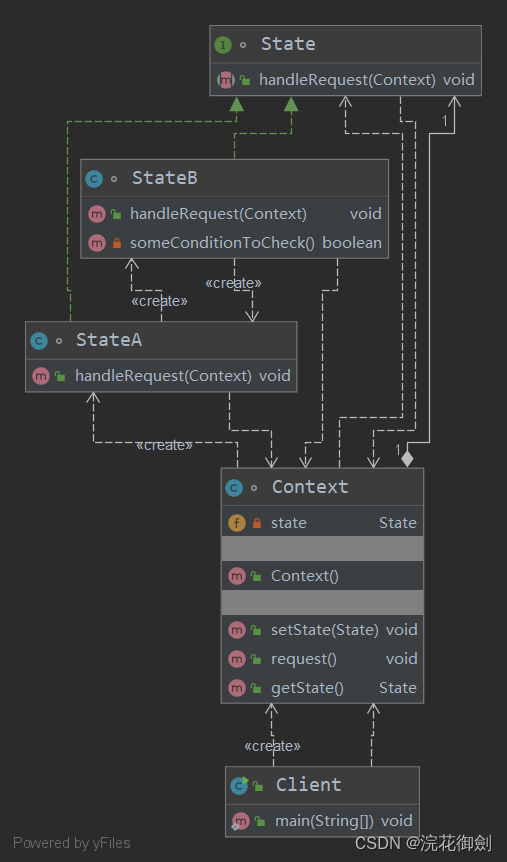
【设计模式深度剖析】【10】【行为型】【状态模式】
👈️上一篇:访问者模式 | 下一篇:解释器模式👉️ 设计模式-专栏👈️ 文章目录 状态模式定义英文定义直译如何理解呢? 状态模式的角色Context(环境类)State(抽象状态类)Concret…...

API低代码平台介绍5-数据库记录修改功能
数据库记录修改功能 在上篇文章中我们介绍了如何插入数据库记录,本篇文章会沿用上篇文章的测试数据,介绍如何使用ADI平台定义一个修改目标数据库记录的接口,包括 单主键单表修改、复合主键单表修改、多表修改(整合前两者ÿ…...

git commit撤销修改
背景 如果提交了代码,却发现有不需要提交的文件。这时候如何修改呢?可以用git reset指令。 git reset用法解释 git reset 命令用于回退版本,可以指定退回某一次提交的版本。 git reset 命令语法格式如下: git reset [--soft …...
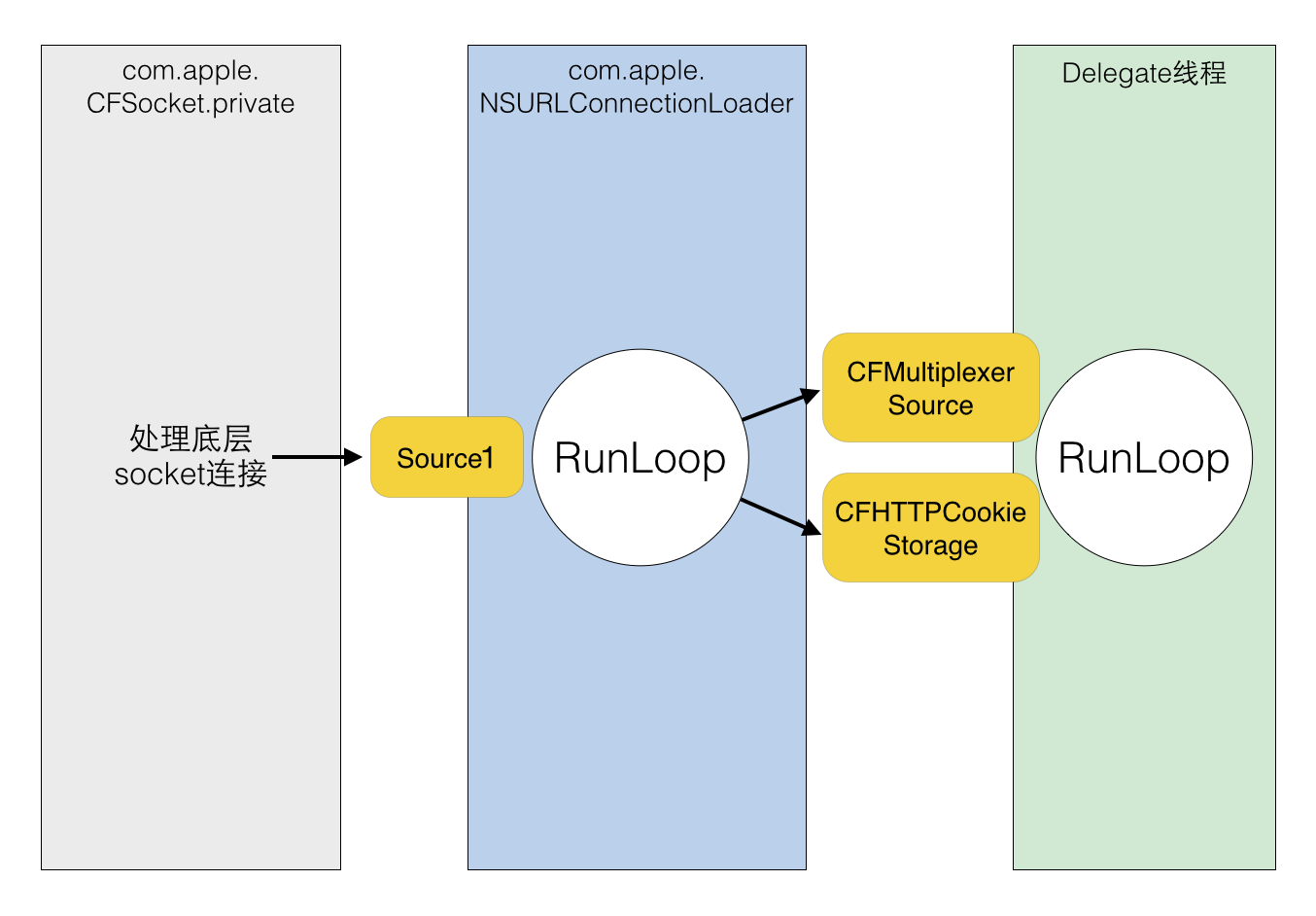
深入理解RunLoop
RunLoop 是 iOS 和 OSX 开发中非常基础的一个概念,这篇文章将从 CFRunLoop 的源码入手,介绍 RunLoop 的概念以及底层实现原理。之后会介绍一下在 iOS 中,苹果是如何利用 RunLoop 实现自动释放池、延迟回调、触摸事件、屏幕刷新等功能的。 一…...

Elasticsearch term 查询:精确值搜索
一、引言 Elasticsearch 是一个功能强大的搜索引擎,它支持全文搜索、结构化搜索等多种搜索方式。在结构化搜索中,term 查询是一种常用的查询方式,用于在索引中查找与指定值完全匹配的文档。本文将详细介绍 term 查询的工作原理、使用场景以及…...

用PTA题库学C语言:手把手教你拆解‘选择与循环’的嵌套逻辑
用PTA题库学C语言:手把手教你拆解‘选择与循环’的嵌套逻辑 学习C语言时,最让初学者头疼的莫过于那些层层嵌套的选择结构和循环结构。面对一堆if-else和for/while语句,很多人会感到无从下手。本文将通过PTA题库中的典型题目,教你一…...

LangGraph大模型脚手架实战:揭秘6种爆款智能体设计模式,玩转生产级Agent开发!
最近Herness大火,我就在反思,我们在日常进行智能体开发的过程中,是否也在做类似的事,我们用过claude code sdk、codex sdk、copilot cli等通用agent做封装,也用过dify或者coze搭工作流,也用过langchain做过…...

Chromatic:掌握Chromium/V8的终极通用修改器,开启浏览器调试新纪元
Chromatic:掌握Chromium/V8的终极通用修改器,开启浏览器调试新纪元 【免费下载链接】chromatic Universal modifier for Chromium/V8 | 广谱注入 Chromium/V8 的通用修改器 项目地址: https://gitcode.com/gh_mirrors/be/chromatic 还在为浏览器调…...
)
ClaudeCode入门08-Git配合(小白入门:不知道怎么写Git提交记录?让AI自动帮你写好)
🎯 本文目标 学会用 Claude Code 自动化 Git 工作流:自动写 Commit Message、管理分支、处理冲突。 😰 Git 新手的痛点 git commit -m "fix" git commit -m "update" git commit -m "修改了一些东西" 不知道 Conventional Commits 是什么 …...

何为可编程控制器?可编程控制器4大内容介绍
可编程控制器在控制中常为使用,因此本文将从4大方面对可编程控制器予以介绍,以增进大家对可编程控制器的了解。这4大方面包括:1.何为可编程控制器?2. 可编程控制器的基本组成,3. 可编程控制器发展史,以及4. 可编程控制…...

告别龟速!实测字节跳动Rust镜像源rsproxy.cn,安装rust和cargo快到飞起
Rust开发者福音:字节跳动镜像源rsproxy.cn全实测与避坑指南 上周深夜两点,我盯着终端里以KB/s为单位缓慢爬升的Rust安装进度条,第5次按下了CtrlC。作为一门以"零成本抽象"著称的语言,Rust的安装体验却让国内开发者付出了…...

008、RISC-V在TinyML中的崛起与优势
008、RISC-V在TinyML中的崛起与优势 从一块“变砖”的开发板说起 去年冬天,我在调试一个基于Cortex-M4的智能传感器节点。项目要求将唤醒词检测模型塞进32KB的SRAM里,功耗要控制在50μA以下。折腾了两周,模型量化、算子裁剪、甚至手写汇编优化了部分矩阵运算——终于跑通了…...

群晖相册AI识别解锁指南:让无GPU设备也能享受智能相册功能
群晖相册AI识别解锁指南:让无GPU设备也能享受智能相册功能 【免费下载链接】Synology_Photos_Face_Patch Synology Photos Facial Recognition Patch 项目地址: https://gitcode.com/gh_mirrors/sy/Synology_Photos_Face_Patch 你是否拥有DS918或DS3615xs等群…...

Arm SME架构下的矩阵运算优化实践
1. Arm SME架构下的矩阵运算优化概述矩阵乘法作为高性能计算的核心运算,其效率直接影响深度学习推理、信号处理、科学计算等关键领域的性能表现。Arm SME(Scalable Matrix Extension)架构通过引入可扩展的矩阵寄存器(ZA࿰…...
)
ROS Melodic下,用Gazebo+ros_control搞定移动底盘+三轴机械臂的联合仿真(附避坑记录)
ROS Melodic下移动底盘与三轴机械臂的Gazebo联合仿真实战指南 当移动底盘遇上机械臂,问题总是比想象中多。上周深夜调试时,我的机械臂突然在Gazebo里表演起了"陀螺旋转",而底盘却纹丝不动——这恰恰是ros_control配置中一个PID参数…...