python学习—字典(Dictionary)
系列文章目录
python学习—列表和元组
python学习—循环语句-控制流
python学习—合并TXT文本文件
python学习—统计嵌套文件夹内的文件数量并建立索引表格
python学习—查找指定目录下的指定类型文件
python学习—年会不能停,游戏抽签抽奖
python学习—合并多个Excel工作簿表格文件
文章目录
- 系列文章目录
- 功能说明
- 1 字典(Dictionary),
- (1) 访问 读取
- (2) 添加 数据
- (3) 删除 数据
- (4) 修改 数据
- (5) 字典不排序 无序
- (6)字典函数(len 、str)
- (7)字典方法(key、value、items、get、pop、update、setdefault、fromkeys)
- 2 字典与列表嵌套
- (1) 列表嵌套列表
- (2) 字典嵌套字典
- (3) 字典嵌套 列表
- (4)列表嵌套 字典
- 4 后记
功能说明
本文简单介绍python中的字典(Dictionary),
字典是python 另一种可变、无序 容器模型,且可存储任意类型对象。
特性:
- 字典的每个键值 key:value 对用冒号 : 分割,
- 每个键值对之间用逗号 , 分割 简单理解 姓名 成绩 是一组键值对
- 键一般是唯一的,如果重复了,最后的一个键值对会替换前面的,值不需要唯一
- 键必须不可变,所以可以用数字,字符串或元组充当,用列表就不行
- 整个字典包括在花括号 {} 中 ,
- 格式如下所示:
scores = {'小明':95,'小红':90,'小刚':90}
python版本为 python3。
1 字典(Dictionary),
(1) 访问 读取
提取 字典提取 靠的是 键key
print(scores['小明']) # 95 标准格式 字典名[字典的键]
print(scores['小红']) # 90 字典名[字典的键]print(scores['小宋']) # KeyError: '小宋' 访问没有的键,报错
(2) 添加 数据
增加标准格式 字典名[键] = 值
scores['小宋'] = 100
print(scores) # {'小明': 95, '小红': 90, '小刚': 90, '小宋': 100}
(3) 删除 数据
删除标准格式 del 字典名[键]
del scores['小刚'] # 删除 小刚 的记录
print(scores) # {'小明': 95, '小红': 90, '小宋': 100}spam = {'color': 'red', 'age': 42}
spam.clear() # 清空字典所有条目
print(spam) # {} 空字典del spam # 删除字典
(4) 修改 数据
如果只需要修改键里面的值,直接对键 赋值
scores['小宋'] = 99
print(scores) # {'小明': 95, '小红': 90, '小宋': 99}
(5) 字典不排序 无序
不像列表,字典中的项是不排序的。因为字典不排序,所以 不能像列表那样切片。
scores001 = {'小明': 95, '小红': 100, '小刚': 90}
scores002 = {'小红': 100, '小刚': 90, '小明': 95}
print(scores001 == scores002) # True 说明 两个字典 完全一致
(6)字典函数(len 、str)
print(len(scores001)) # 3 字典的长度 hhh = str(scores001) # str() 函数将值转化为适于人阅读的形式,以可打印的字符串表示
print(hhh) # {'小明': 95, '小红': 100, '小刚': 90}
print(type(hhh)) # <class 'str'> 字符串
print(type(scores001)) # <class 'dict'> 字典
(7)字典方法(key、value、items、get、pop、update、setdefault、fromkeys)
- key() 字典的键
for k in scores001.keys(): # 循环迭代 键print(k)
# 小明
# 小红
# 小刚
- value() 字典的值
for k in scores001.values(): # 循环迭代 值print(k)
# 95
# 100
# 90
- item() 字典的 键值对
for k in scores001.items(): # 循环迭代 键值对print(k)
# ('小明', 95) # 元组
# ('小红', 100)
# ('小刚', 90)
- ‘键’ in 字典。判断 键 是否在 字典中,返回布尔值
print('小明' in scores001) # True
print('王五' in scores001) # False
- 字典.get(键,default) 返回指定键的值,如果值不在字典中返回default值
print(scores001.get('小刚', '没有这个键')) # 90
print(scores001.get('张三', '没有这个键')) # 没有这个键
- 字典.pop(键,default) 。删除字典给定键 key 所对应的值,返回值为被删除键的值。key值必须给出。 否则,返回default值。
print(scores001.pop('小刚', '没有这个键')) # 90 删除 小刚 这个键值对。这里返回的是 小刚的 值 90
print(scores001) # {'小明': 95, '小红': 100}
print(scores001.pop('小刚', '没有这个键')) # 没有这个键 因为没有 小刚这个键了,所以 返回 default
- 字典.popitem() 。删除字典最后一组键值对。
print(scores001.popitem()) # ('小红', 100) 删除 最后一组键值对。这里返回的是 键值对
print(scores001) # {'小明': 95}
- 字典1.update(字典2) 。把字典dict2 的键/值对 更新到dict1 里。如果有键 重复,则覆盖
scores001.update(scores002) # 用 scores002 更新 scores001
print(scores001) # {'小明': 95, '小红': 100, '小刚': 90}
- 字典.setdefault(key, default=None) 。 和get()类似, 但如果键不存在于字典中,将会添加键并将值设为default
scores001.setdefault('张三', 60)
print(scores001) # {'小明': 95, '小红': 100, '小刚': 90, '张三': 60}
scores001.setdefault('张三', 80) # 已经有了 键 张三, 故 不添加了
print(scores001) # {'小明': 95, '小红': 100, '小刚': 90, '张三': 60}
- 字典.fromkeys(seq[, value]) 。创建一个新字典,以序列 seq 中元素做字典的键,
- value 为字典所有键对应的初始值,value – 可选参数, 设置键序列(seq)的值,默认为 None
abc = [1, 2, 3]
scores003 = dict(zip(abc,[10,20,30]))
print(scores003) # {1: 10, 2: 20, 3: 30}
scores004 = dict(zip(abc,[40]))
print(scores004) # {1: 40}
- 字典.copy() 返回一个字典的浅复制 浅拷贝
scores006 = scores003.copy()
print(scores006) # {1: 10, 2: 20, 3: 30}
scores003.clear() # 清空
print(scores003) # {}
print(scores006) # {1: 10, 2: 20, 3: 30}
2 字典与列表嵌套
字典经常与列表一起,嵌套使用,在调用的时候有一些特殊格式。
(1) 列表嵌套列表
students = [['小明','小红','小刚','小美'],['小强','小兰','小伟','小芳']]
//提取 小芳
print(students[1][3]) # 小芳 。第一个元素中的第3个元素
//提取 小兰
print(students[1][1]) # 小兰 。第1个元素中的第1个元素
(2) 字典嵌套字典
scores = {'第一组':{'小明':95,'小红':90,'小刚':100,'小美':85},'第二组':{'小强':99,'小兰':89,'小伟':93,'小芳':88}}
//小芳的成绩
print(scores['第二组']['小芳']) # 88 。键 ‘第二组’的值(字典)中的键 ‘小芳’的 值
//小刚的成绩
print(scores['第一组']['小刚']) # 100 。键 ‘第一组’的值(字典)中的键 ‘小刚’的 值(3) 字典嵌套 列表
students = {'第一组':['小明','小红','小刚','小美'],'第二组':['小强','小兰','小伟','小芳']}
//提取 小美
print(students['第一组'][3]) # 小美 。键 '第一组'的值 (列表)中对应列表偏移量为3的元素
(4)列表嵌套 字典
scores = [{'小明':95,'小红':90,'小刚':100,'小美':85},{'小强':99,'小兰':89,'小伟':93,'小芳':88}]
//提取 小强的成绩
print(scores[1]['小强']) # 99。索引 1 的元素(字典)中键为 ‘小强’的值value。
4 后记
字典是Python中非常灵活且常用的数据结构,适用于需要快速根据标识(键)查找对应信息(值)的场景。
相关文章:
)
python学习—字典(Dictionary)
系列文章目录 python学习—列表和元组 python学习—循环语句-控制流 python学习—合并TXT文本文件 python学习—统计嵌套文件夹内的文件数量并建立索引表格 python学习—查找指定目录下的指定类型文件 python学习—年会不能停,游戏抽签抽奖 python学习—合并多个Ex…...
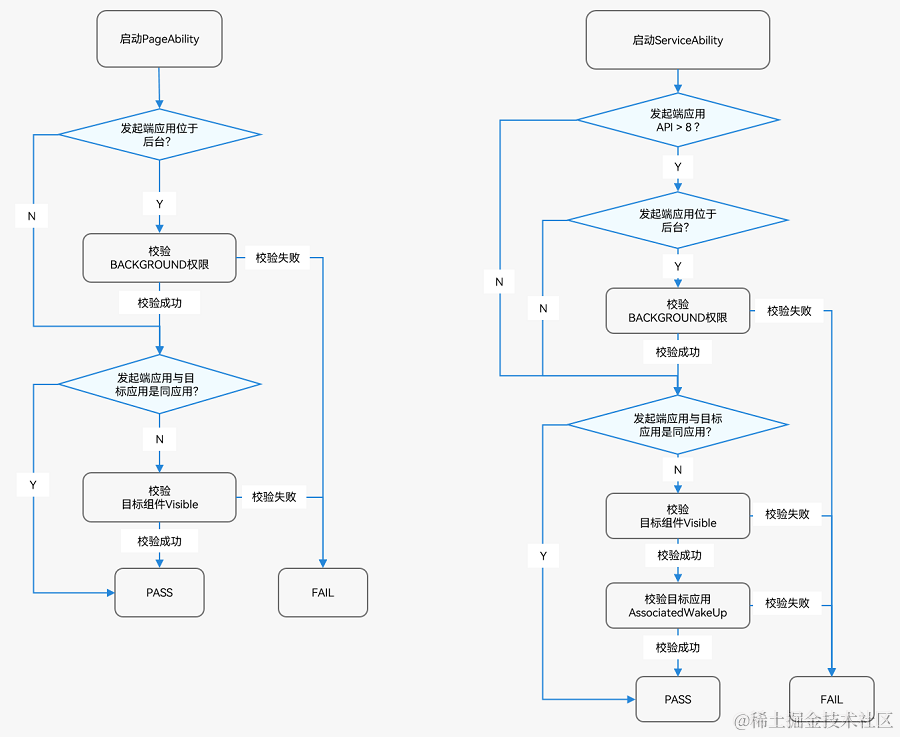
鸿蒙开发:【组件启动规则(FA模型)】
组件启动规则(FA模型) 启动组件是指一切启动或连接应用组件的行为: 启动PageAbility、ServiceAbility,如使用startAbility()等相关接口。连接ServiceAbility、DataAbility,如使用connectAbility()、acquireDataAbili…...
网络编程5----初识http
1.1 请求和响应的格式 http协议和前边学过的传输层、网络层协议不同,它是“一问一答”形式的,所以要分为请求和响应两部分看待,同时,请求和响应的格式是不同的,我们来具体介绍一下。 1.1.1 请求 在介绍请求之前&…...

“用友审批+民生付款”,YonSuite让企业发薪更准时
随着现代企业经营模式的不断创新和市场竞争的加剧,企业薪资管理和发放的效率、准确性和及时性已成为企业管理的重要一环。然而,在实际操作中,许多企业面临着薪资管理复杂、发放流程繁琐、数据不准确等难点和痛点。为了解决这些问题࿰…...

EtherCAT扫盲,都是知识点
1. 什么是EtherCAT EtherCAT,全称Ethernet for Control Automation Technology,字面意思就是用于控制自动化技术的以太网。它是一种基于以太网的实时工业通信协议,简单说,就是让机器们通过网线互相聊天的高级方式。 EtherCAT 是最…...
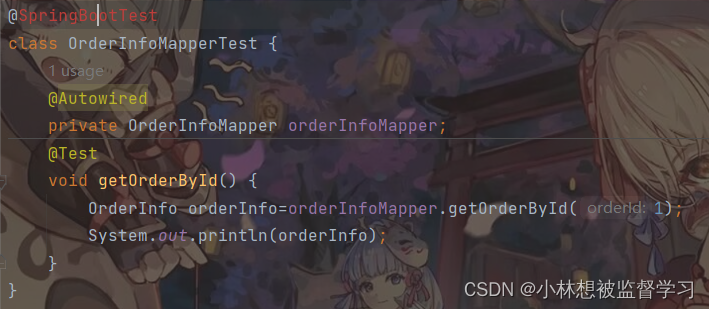
开发中遇到的错误 - @SpringBootTest 注解爆红
我在使用 SpringBootTest 注解的时候爆红了,ait 回车也导不了包,后面发现是因为没有加依赖: <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId>…...
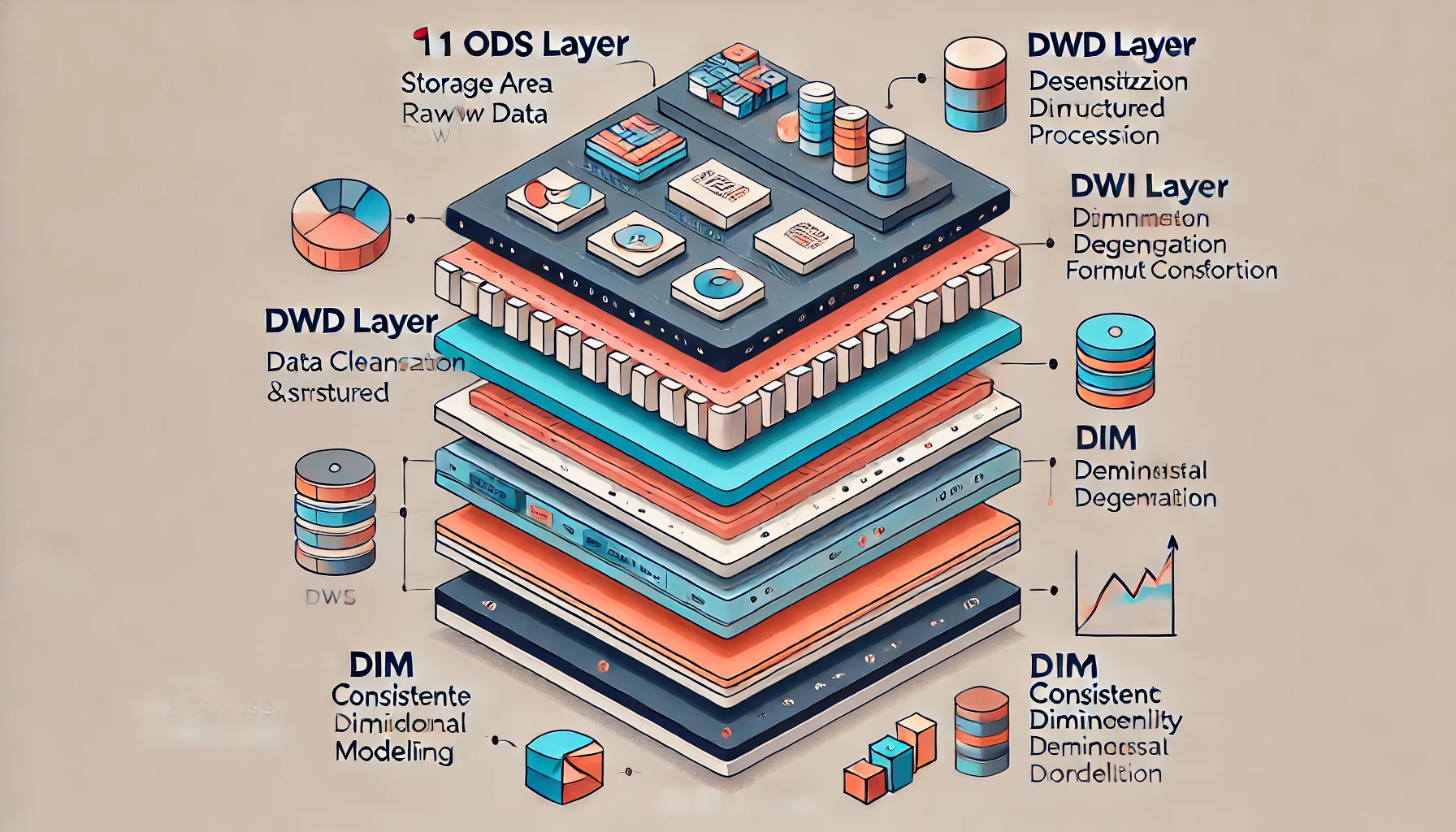
数据仓库的实际应用示例-广告投放平台为例
数据仓库的数据分层通常包括以下几层: ODS层:存放原始数据,如日志数据和结构化数据。DWD层:进行数据清洗、脱敏、维度退化和格式转换。DWS层:用于宽表聚合值和主题加工。ADS层:面向业务定制的应用数据层。…...

Beyond VL了解学习
Beyond VL:多模态处理的前沿 在今天的数据驱动时代,我们经常需要处理和分析多种类型的数据,例如文本、图像、视频和音频。Beyond VL 是一个先进的多模态模型,专为处理这些多种数据而设计。它能够同时处理多种模态的数据ÿ…...

AI音乐革命:创意产业的新篇章
随着科技的飞速发展,人工智能(AI)在各个领域的应用越来越广泛,特别是在音乐产业中,AI音乐大模型的涌现,正在重新定义音乐创作的边界。最近一个月,随着多个音乐大模型的轮番上线,素人…...

python从入门到精通1:注释
在Python编程中,注释是一种非常重要的工具,它不仅可以帮助我们记录代码的目的、工作方式以及任何需要注意的地方,还可以使代码更具可读性。Python提供了两种主要的注释方式:单行注释和多行注释。下面我们将深入探讨这两种注释方式…...
)
CountDownLatch(应对并发问题的工具类)
CountDownLatch CountDownLatch允许一个或多个线程等待其他线程完成操作以后,再执行当前线程;比如我们在主线程需要开启2个其他线程,当其他的线程执行完毕以后我们再去执行主线程,针对这 个需求我们就可以使用CountDownLatch来进…...

HarmonyOS开发知识 :扩展修饰器,实现节流、防抖、权限申请
引言 防重复点击,利用装饰器面向切面(AOP)的特性结合闭包,实现节流、防抖和封装权限申请。 节流 节流是忽略操作,在触发事件时,立即执行目标操作,如果在指定的时间区间内再次触发了事件&…...

自然语言NLP的基础处理
NLP基本处理从句子的情感分析、实体与实体直接的关系,句子结构来分析 情感分析 1.句子的情感分析找出句子表达的是正面、负面还是中性的情感。 情感分析的影响因素: 词语顺序:词语的顺序可以影响句子的整体情感。例如,“我喜欢…...

带颜色的3D点云数据发布到ros1中(通过rviz显示)python、C++
ros中发布点云数据xyz以及带颜色的点云数据xyzrgb ros中发布点云数据xyz可以直接用python来做或者C(看个人偏好) ros中发布带颜色的点云数据xyzrgb环境1.新建ROS工作空间2.创建功能包 ros中发布点云数据xyz 可以直接用python来做或者C(看个人偏好) 在这里我们带有颜色的点云数…...

python学习—列表和元组
系列文章目录 python学习—合并TXT文本文件 python学习—统计嵌套文件夹内的文件数量并建立索引表格 python学习—查找指定目录下的指定类型文件 python学习—年会不能停,游戏抽签抽奖 python学习—循环语句-控制流 python学习—合并多个Excel工作簿表格文件 文章目…...

c++题目_水仙花数
水仙花数-普及-题目-ACGO题库 题目描述 求100-n中的水仙花数。一个数x,x的百位、十位、个位,分别用a、b、c来表示; 当a * a * a b * b * b c * c * c x时,x就被称为水仙花数。(n< 999) 输入格式 一行一个整数n 输出格式…...

使用 Iceberg、Tabular 和 MinIO 构建现代数据架构
现代数据环境需要一种新型的基础架构,即无缝集成结构化和非结构化数据、轻松扩展并支持高效的 AI/ML 工作负载的基础架构。这就是现代数据湖的用武之地,它为您的所有数据需求提供了一个中心枢纽。然而,构建和管理有效的数据湖可能很复杂。 这…...

jnp.linalg.norm
jnp.linalg.norm 是 JAX 中用于计算向量或矩阵的范数的函数。JAX 是一个用于高性能机器学习研究的 Python 库,它提供了与 NumPy 类似的 API,但支持自动微分和加速计算。jnp 是 JAX 的 NumPy 接口。 jnp.linalg.norm 的基本语法 jnp.linalg.norm(x, ord…...
20240621在飞凌的OK3588-C开发板的Buildroot系统中集成i2ctool工具
20240621在飞凌的OK3588-C开发板中打开i2ctool工具 2024/6/21 17:44 默认继承的i2c工具: rootrk3588-buildroot:/# rootrk3588-buildroot:/# i2c i2c-stub-from-dump i2cdump i2cset i2cdetect i2cget i2ctransfer rootrk3588-…...

ARM32开发--存储器介绍
知不足而奋进 望远山而前行 目录 文章目录 前言 存储器分类 RAM ROM EEPROM Flash 总结 前言 在现代计算机系统中,存储器扮演着至关重要的角色,不仅影响着数据的存取速度和稳定性,还直接关系到计算机系统的性能和应用场景的选择。存…...

2026年主流抓娃娃App大对比,哪个才是你的“抓宝神器”?
在当今快节奏的生活中,年轻人面临着来自学业、工作、社交等多方面的压力。为了缓解这些压力,寻找适合的解压方式成为了大家的共同需求。抓娃娃App作为一种新兴的娱乐方式,正逐渐受到年轻人的喜爱。下面我们就从潮流趋势、科技前沿、行业洞察等…...

LLM Notebooks:从零构建RAG问答系统的实践指南
1. 项目概述:一个面向大语言模型实践的“笔记本”仓库最近在GitHub上闲逛,发现了一个挺有意思的仓库,叫qianniuspace/llm_notebooks。光看名字,llm_notebooks,大语言模型笔记本,这指向性就非常明确了。这大…...

AI智能体密钥安全管理:AgentVault架构解析与实战指南
1. 项目概述:一个为AI智能体打造的“保险箱”最近在折腾AI智能体(Agent)应用开发的朋友,估计都绕不开一个核心痛点:如何安全、可靠地管理智能体运行过程中需要用到的各种密钥、凭证和敏感数据?无论是调用Op…...

LVGUI字体瘦身实战:如何为你的IoT设备定制一个超小的中文字体库
LGVUI字体瘦身实战:为IoT设备定制超小中文字体库的工程化解决方案 在嵌入式物联网设备开发中,每一KB的Flash和RAM都弥足珍贵。当你的智能温控器需要显示"当前温度:25℃"或者电子秤要呈现"净重:0.5kg"时&#…...

NS-USBLoader终极指南:3步搞定Switch游戏管理与RCM注入的完整教程
NS-USBLoader终极指南:3步搞定Switch游戏管理与RCM注入的完整教程 【免费下载链接】ns-usbloader Awoo Installer and GoldLeaf uploader of the NSPs (and other files), RCM payload injector, application for split/merge files. 项目地址: https://gitcode.c…...

【避坑指南】VSCode+EIDE+Keil混合开发环境:从零搭建到项目无缝迁移
1. 为什么需要VSCodeEIDEKeil混合开发环境? 作为一名嵌入式开发者,我深知Keil这个老牌IDE在开发效率上的痛点:代码补全弱、界面老旧、多窗口管理混乱。但直接完全迁移到VSCode又面临工程兼容性问题,特别是对传统AC5编译器的支持。…...

基于RP2040与CircuitPython的HDMI倒计时器:RTC与DVI原生输出实践
1. 项目概述与核心价值如果你手头有一块带HDMI输出的微控制器开发板,比如Adafruit的Feather RP2040 DVI,又恰好需要一个能摆在桌面上、精确到秒的倒计时器,那么今天这个项目就是为你量身定做的。它不仅仅是一个简单的“Hello World”式显示应…...

Claude-Code-KnowCraft:轻量级代码知识库构建与智能问答实践
1. 项目概述与核心价值最近在跟几个做AI应用开发的朋友聊天,大家普遍有个痛点:想把Claude这类大语言模型(LLM)的能力深度集成到自己的代码库分析工具里,但发现现有的方案要么太重,要么太浅。太重的是指那些…...

EL线创客工作坊:从零到一的电致发光项目实践指南
1. 项目概述:为什么EL线工作坊是创客入门的绝佳选择如果你正在寻找一个能让新手快速上手、成品炫酷、且能完美融合电子与手工的创客项目,EL线工作坊几乎是一个无可挑剔的答案。EL,即电致发光,它不像LED那样依赖一个个分立的光点&a…...

智能体开发实战:从框架选型到部署优化的完整指南
1. 项目概述:一个为智能体开发者准备的“军火库”如果你正在或打算踏入智能体(Agent)开发这个领域,那么你很可能已经体会过那种“万事开头难”的迷茫。从选择哪个框架开始,到如何设计一个有效的智能体工作流࿰…...