067、Python 高阶函数的编写:优质冒泡排序
以下写了个简单的冒泡排序函数:
def bubble_sort(items: list) -> list:for i in range(1, len(items)):swapped = Falsefor j in range(0, len(items) - 1):if items[j] > items[j + 1]:items[j], items[j + 1] = items[j + 1], items[j]swapped = Trueif not swapped:breakif __name__ == '__main__':nums = [55, 66, 9, 22, 86, 35, 44, 97, 56]bubble_sort(nums)print(nums) # 输出结果:[9, 22, 35, 44, 55, 56, 66, 86, 97]上面写法虽然正确排好序了,但初始化变量nums的结果改变了,如果实际应用不需要把初始变量改变,该如何?
优化后:
def bubble_sort(items: list) -> list:items = items[:] # 把列表数据赋给一个新变量并作为返回值for i in range(1, len(items)):swapped = Falsefor j in range(0, len(items) - 1):if items[j] > items[j + 1]:items[j], items[j + 1] = items[j + 1], items[j]swapped = Trueif not swapped:breakreturn itemsif __name__ == '__main__':nums = [55, 66, 9, 22, 86, 35, 44, 97, 56]print(bubble_sort(nums)) # 输出结果:[9, 22, 35, 44, 55, 56, 66, 86, 97]print(nums) # 输出结果:[55, 66, 9, 22, 86, 35, 44, 97, 56] 原来值并没有改变
如此修改后初始化变量就可以保留,又可以输出排好序的数据了。
这点是基于以下编程思想:
在我们设计函数的时候,一定要注意函数的无副作用(调用函数不影响调用者)。优化后函数质量提升了。
但是该函数的功能还不够全面,假如我对于排序输出结果既要按升序输出,也要按降调输出,又该如何?
方法就是增加一个布尔值变量:
def bubble_sort(items: list, ascending=True) -> list: # 增加一个bool变量items = items[:] # 把列表数据赋给一个新变量并作为返回值for i in range(1, len(items)):swapped = Falsefor j in range(0, len(items) - 1):if items[j] > items[j + 1]:items[j], items[j + 1] = items[j + 1], items[j]swapped = Trueif not swapped:breakif not ascending:items = items[::-1]return itemsif __name__ == '__main__':nums = [55, 66, 9, 22, 86, 35, 44, 97, 56]print(bubble_sort(nums)) # 输出结果:[9, 22, 35, 44, 55, 56, 66, 86, 97]print(bubble_sort(nums, ascending=False)) # 输出结果:[97, 86, 66, 56, 55, 44, 35, 22, 9]
如此,我们就可以通过变量ascending的值来判断按升序还是降序输出结果。
但是优化后的函数还不够好,因为在if items[j] > items[j + 1]:语句存在一定的耦合性。那么又该如何解耦呢?
方法就通过引入函数变量:
def bubble_sort(items: list, ascending: bool = True, gt=lambda x, y: x > y) -> list: # 增加一个bool变量,并引入一个Lambda函数items = items[:] # 把列表数据赋给一个新变量并作为返回值for i in range(1, len(items)):swapped = Falsefor j in range(0, len(items) - 1):if gt(items[j], items[j + 1]): # 通过调用函数做大小比较items[j], items[j + 1] = items[j + 1], items[j]swapped = Trueif not swapped:breakif not ascending:items = items[::-1]return itemsif __name__ == '__main__':nums = [55, 66, 9, 22, 86, 35, 44, 97, 56]print(bubble_sort(nums)) # 输出结果:[9, 22, 35, 44, 55, 56, 66, 86, 97]print(bubble_sort(nums, ascending=False)) # 输出结果:[97, 86, 66, 56, 55, 44, 35, 22, 9]
如此优化后,该函数质量就很高了,功能更全面,灵活性更高。
为什么这么说,看以下应用:
def bubble_sort(items: list, ascending: bool = True, gt=lambda x, y: x > y) -> list: # 增加一个bool变量,并引入一个Lambda函数"""冒泡排序:param items: 待排序的列表:param ascending:是否使用升序:param gt: 比较两个元素大小的函数:return: 返回排序后列表"""items = items[:] # 把列表数据赋给一个新变量并作为返回值for i in range(1, len(items)):swapped = Falsefor j in range(0, len(items) - 1):if gt(items[j], items[j + 1]): # 通过调用函数做大小比较items[j], items[j + 1] = items[j + 1], items[j]swapped = Trueif not swapped:breakif not ascending:items = items[::-1]return itemsif __name__ == '__main__':nums = [55, 66, 9, 22, 86, 35, 44, 97, 56]print(bubble_sort(nums)) # 输出结果:[9, 22, 35, 44, 55, 56, 66, 86, 97]print(bubble_sort(nums, ascending=False)) # 输出结果:[97, 86, 66, 56, 55, 44, 35, 22, 9]words = ['Apple', 'Banana', 'Orange', 'Strawberry', 'Grape', 'Watermelon']print(bubble_sort(words, gt=lambda x, y: len(x) > len(y), ascending=False))# 输出结果 ['Watermelon', 'Strawberry', 'Orange', 'Banana', 'Grape', 'Apple']如上,当一个列表数字是字符串,我需要把输出结果按字符串长度进行排序输出,那么只需要在调用函数的时候,修改函数变量的函数就可以实现了。
这就是高阶函数!
相关文章:

067、Python 高阶函数的编写:优质冒泡排序
以下写了个简单的冒泡排序函数: def bubble_sort(items: list) -> list:for i in range(1, len(items)):swapped Falsefor j in range(0, len(items) - 1):if items[j] > items[j 1]:items[j], items[j 1] items[j 1], items[j]swapped Trueif not swa…...

【Python】从基础到进阶(一):了解Python语言基础以及变量的相关知识
🔥 个人主页:空白诗 文章目录 引言一、Python简介1.1 历史背景1.2 设计哲学1.3 语言特性1.4 应用场景1.5 为什么选择Python 二、Python语言基础2.1 注释规则2.1.1 单行注释2.1.2 多行注释2.1.3 文件编码声明注释 2.2 代码缩进2.3 编码规范2.3.1 命名规范…...

AI学习指南机器学习篇-KNN的优缺点
AI学习指南机器学习篇-KNN的优缺点 在机器学习领域中,K最近邻(K-Nearest Neighbors,KNN)算法是一种十分常见的分类和回归方法之一。它的原理简单易懂,但在实际应用中也存在一些优缺点。本文将重点探讨KNN算法的优缺点…...

全网最全!25届最近5年上海理工大学自动化考研院校分析
上海理工大学 目录 一、学校学院专业简介 二、考试科目指定教材 三、近5年考研分数情况 四、近5年招生录取情况 五、最新一年分数段图表 六、历年真题PDF 七、初试大纲复试大纲 八、学费&奖学金&就业方向 一、学校学院专业简介 二、考试科目指定教材 1、考试…...

LANG、LC_MESSAGES和LC_ALL
在Linux系统中,环境变量LANG、LC_MESSAGES和LC_ALL用于控制系统和应用程序的语言和区域设置(locale)。它们的具体作用如下: LANG: LANG是最基本的环境变量,用于指定系统的默认语言和区域设置。它是一个全局…...
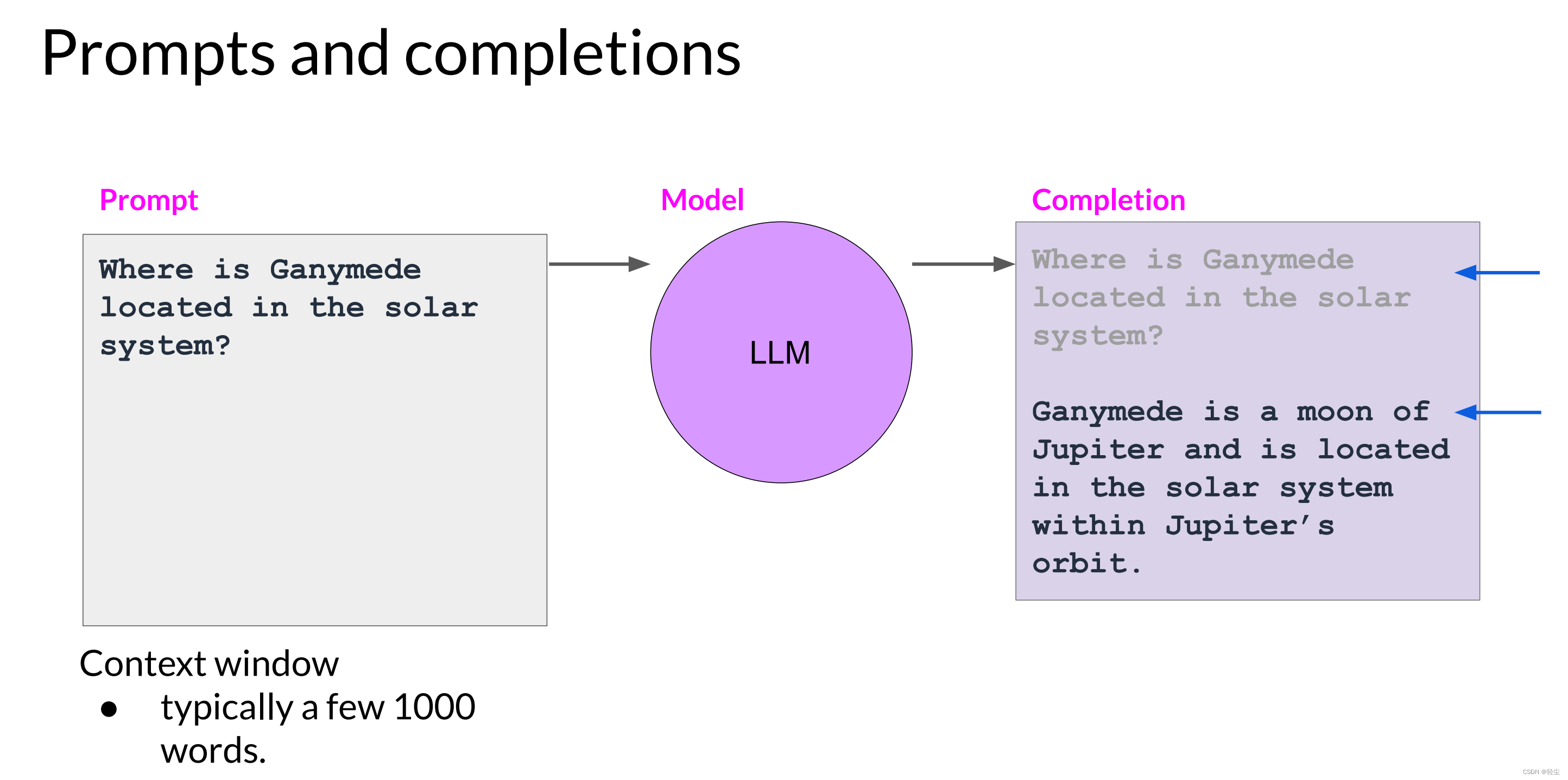
生成式AI和LLM的一些基本概念和名词解释
1. Machine Learning 机器学习是人工智能(AI)的一个分支,旨在通过算法和统计模型,使计算机系统能够从数据中学习并自动改进。机器学习算法使用数据来构建模型,该模型可用于预测或决策。机器学习应用于各种领域&#x…...

python项目(课设)——飞机大战小游戏项目源码(pygame)
主程序 import pygame from plane_sprites import * class PlaneGame: """ 游戏类 """ def __init__(self): print("游戏初始化") # 初始化字体模块 pygame.font.init() # 创建游戏…...

Chatgpt教我打游戏攻略
宝可梦朱 我在玩宝可梦朱的时候,我的同行队伍里有黏美儿,等级为65,遇到了下雨天但是没有进化,为什么呢? 黏美儿(Goomy)要进化为黏美龙(Goodra),需要满足以下…...
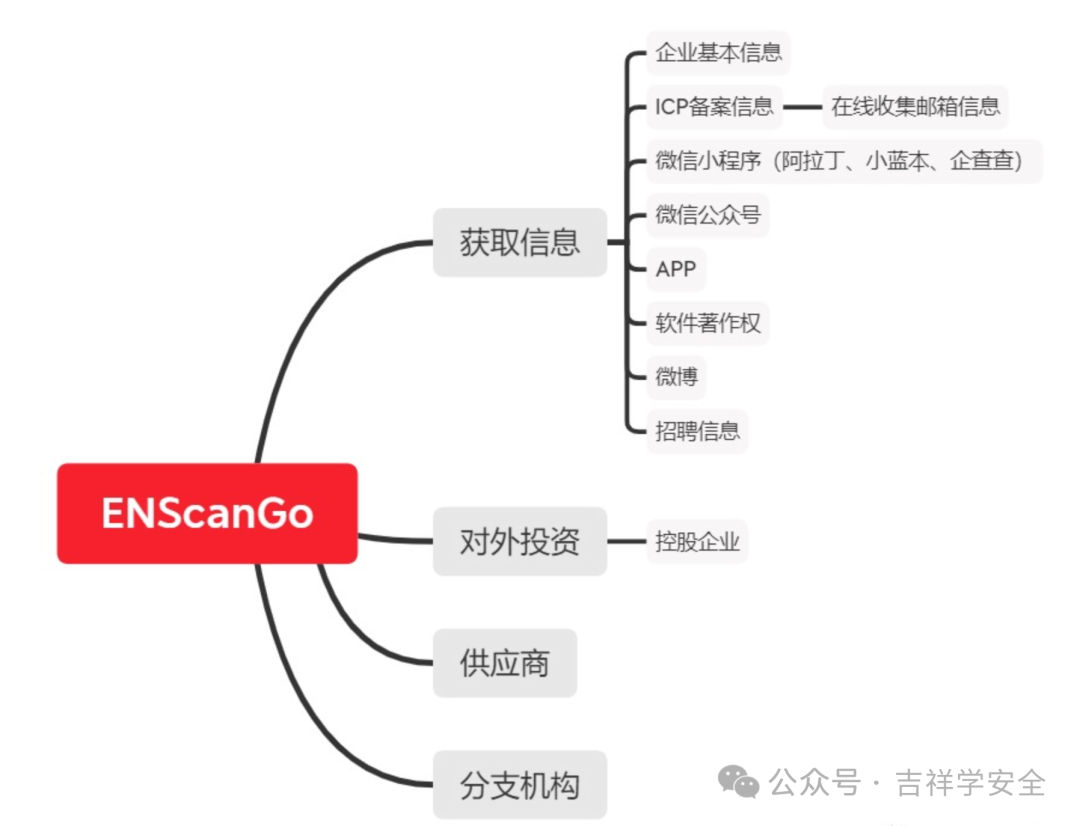
最全信息收集工具集
吉祥学安全知识星球🔗除了包含技术干货:Java代码审计、web安全、应急响应等,还包含了安全中常见的售前护网案例、售前方案、ppt等,同时也有面向学生的网络安全面试、护网面试等。 所有的攻防、渗透第一步肯定是信息收集了…...

redis类型解析汇总
redis类型解析汇总 介绍数据类型简介主要数据类型:衍生类型: 字符串(String)底层设计原理图例设计优势字符串使用方法设置字符串值获取字符串值获取和设置部分字符串获取字符串长度追加字符串设置新值并返回旧值递增/递减同时设置…...
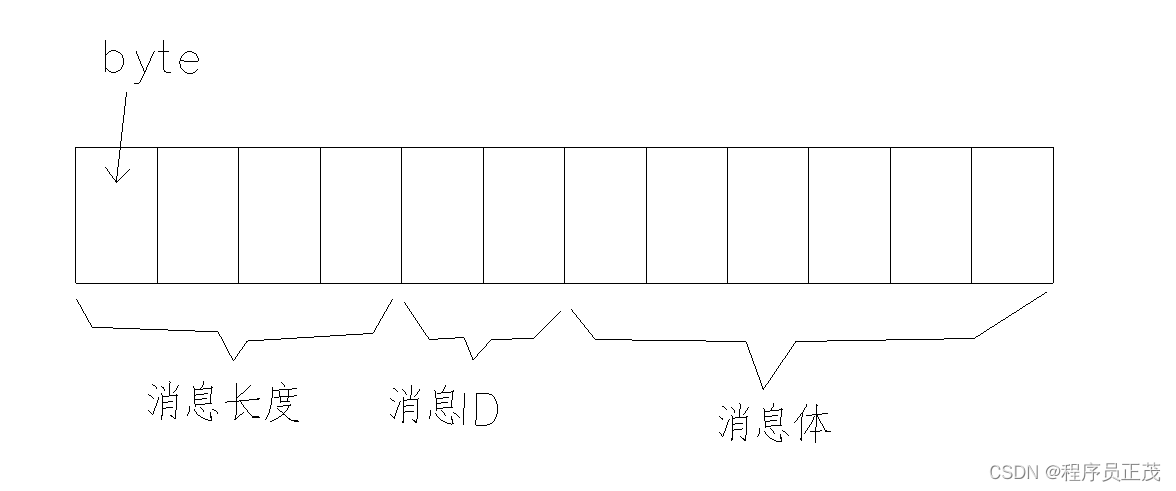
Unity3d自定义TCP消息替代UNet实现网络连接
以前使用UNet实现网络连接,Unity2018以后被弃用了。要将以前的老程序升到高版本,最开始打算使用Mirro,结果发现并不好用。那就只能自己写连接了。 1.TCP消息结构 (1). TCP消息是按流传输的,会发生粘包。那么在发射和接收消息时就需要对消息进行打包和解包。如果接收的消息…...

git fetch 和 git pull区别
git branch //查看本地所有分支 git branch -r //查看远程所有分支 git branch -a //查看本地和远程的所有分支 git branch <branchname> //新建分支 git branch -d <branchname> //删除本地分支 git branch -d -r <branchname> //删除远程分支&#x…...

冲击2024年CSDN博客之星TOP1:CSDN文章质量分查询在哪里?
文章目录 一,2023年博客之星规则1,不高的入围门槛2,[CSDN博文质量分测评地址](https://www.csdn.net/qc) 二,高分秘籍1,要有目录2,文章长度要足够,我的经验是汉字加代码至少1000字。3࿰…...

高性能并行计算华为云实验一:MPI矩阵运算
目录 一、实验目的 二、实验说明 三、实验过程 3.1 创建矩阵乘法源码 3.1.1 实验说明 3.1.2 实验步骤 3.2 创建卷积和池化操作源码 3.2.1 实验说明 3.2.2 实验步骤 3.3 创建Makefile文件并完成编译 3.4 建立主机配置文件与运行监测 四、实验结果与分析 4.1 矩阵乘法…...

库卡机器人减速机维修齿轮磨损故障
一、KUKA机器人减速器齿轮磨损故障的原因 1. 润滑不足:润滑油不足或质量不佳可能导致齿轮磨损。 2. 负载过重:超过库卡机械臂减速器额定负载可能导致齿轮磨损。 3. 操作不当:未按照说明书操作可能导致KUKA机器人减速器齿轮磨损。 4. 维护不足…...

【C/C++】我自己提出的数组探针的概念,快来围观吧
数组探针 在许多编程语言中如果涉及到数组那么就可以使用这个东西,便于遍历数组 中文名 数组探针 外文名 arrProbe 适用领域 大数据 所属学科 软件技术、编程 提出者 董翔 目录 1 概述2 工作原理3 应用场景 ▪ 数据处理和分析▪ 图像处理▪ 游戏开发▪…...
ArcGIS图斑分区(组)排序—从上到下从左到右
点击下方全系列课程学习 点击学习—>ArcGIS全系列实战视频教程——9个单一课程组合系列直播回放 ArcGIS图斑分区(组)从上到下从左到右排序 是之前的内容的升级 GIS技巧100例——12ArcGIS图斑空间排序 关于今天的内容 我们在19年已经和大家分…...

React useRef 组件内及组件传参使用
保存变量, 改变不引起渲染 import { useRef} from react; const dataRef useRef(null) ... dataRef.current setTimeout(()>console.log(...),1000)绑定dom const inputRef useRef(null) <input ref {inputRef} />绑定dom列表 - ref 回调 const ite…...

Intelij IDEA中Mapper.xml无法构建到资源目录的问题
问题场景: 在尝试把原本在eclipse上的Java Web项目转移至Intelij idea上时,在配置文件均与eclipse一致的情况下出现了如下报错: org.apache.ibatis.binding.BindingException: Invalid bound statement (not found): cn.umbrella.crm_core.…...

2024.6.23周报
目录 摘要 ABSTRACT 一、文献阅读 一、题目 二、摘要 三、网络架构 四、创新点 五、文章解读 1、Introduction 2、Method 3、实验 4、结论 二、代码实验 总结 摘要 本周阅读了一篇题目为NAS-PINN: NEURAL ARCHITECTURE SEARCH-GUIDED PHYSICS-INFORMED NEURAL N…...

JetBrains IDE试用期重置工具:开发者的智能许可证管家
JetBrains IDE试用期重置工具:开发者的智能许可证管家 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 当开发工具的试用期倒计时成为你编码时的心理负担,当每次启动IDE都要面对那个令人焦虑…...

Linux Ext 调度器核心原理:BPF 驱动的自定义调度革命
简介 Linux 内核调度器自诞生以来,始终以通用公平调度(CFS)与硬实时调度(SCHED_DEADLINE/SCHED_FIFO)为核心,支撑服务器、桌面、嵌入式等全场景负载。但传统调度框架存在硬耦合、难扩展、定制成本极高的痛…...

量子退火优化CPS测试用例生成的技术解析
1. 量子退火在CPS测试用例生成中的应用概述在安全关键系统(如自动驾驶、工业控制系统)的开发过程中,测试用例的质量直接关系到系统的可靠性。传统测试方法面临两大核心挑战:一是如何在庞大的输入空间中找到最具检测效力的测试用例…...

强烈的“似曾相识“感:由于人类左右大脑处理信息的速度并非完全同步,在某些特殊瞬间,这个流程会被打乱
海马效应(既视现象) 目录 海马效应(既视现象) 核心科学原理 高发场景与人群 典型例子 海马效应,科学上称为既视现象(Dj vu),是指人在从未真实经历过的当下场景中,突然产生强烈的"似曾相识"感,误以为眼前的一切曾经发生过的认知错觉。它并非玄学中的"…...

彻底告别Row-By-Row:标量子查询外连接改写与向量化引擎深潜
在实际的复杂业务系统开发与运维中,SQL查询的结构往往会随着业务复杂度的提升而变得臃肿不堪。为了保证代码的可读性和逻辑的直观性,开发者非常喜欢使用 CTE(公共表表达式)、多层子查询、窗口函数,以及标量子查询&…...

XRDP 远程桌面连接 Ubuntu:从安装到优化的完整实践指南
1. 为什么选择XRDP连接Ubuntu? 对于需要远程管理Ubuntu系统的用户来说,图形化界面操作往往比纯命令行更直观高效。XRDP作为开源的远程桌面协议实现,相比TeamViewer等商业方案,它完全免费且性能出色;相比VNC,…...

3个关键步骤解锁Switch隐藏功能:TegraRcmGUI图形化注入工具完整指南
3个关键步骤解锁Switch隐藏功能:TegraRcmGUI图形化注入工具完整指南 【免费下载链接】TegraRcmGUI C GUI for TegraRcmSmash (Fuse Gele exploit for Nintendo Switch) 项目地址: https://gitcode.com/gh_mirrors/te/TegraRcmGUI 想为你的Nintendo Switch解锁…...

Windows Node.js版本管理实战:NVM-Windows配置与部署解决方案
Windows Node.js版本管理实战:NVM-Windows配置与部署解决方案 【免费下载链接】nvm-windows A node.js version management utility for Windows. Ironically written in Go. 项目地址: https://gitcode.com/gh_mirrors/nv/nvm-windows NVM-Windows是Windows…...

边缘云环境下数据流模型FlowUnits的设计与实践
1. 数据流模型的演进与边缘云挑战数据流计算作为分布式系统领域的核心范式,已经深刻改变了我们处理海量数据的方式。这种基于有向无环图(DAG)的计算模型,通过将数据处理逻辑分解为独立的算子(operator)并明…...

基于OpenCV与MediaPipe的手势与头部姿态控制鼠标实现
1. 项目概述:解放双手的鼠标控制新范式最近在GitHub上看到一个挺有意思的项目,叫ShafwanAbd/handsfree-mouse。顾名思义,这是一个“免提鼠标”项目,核心目标是通过摄像头捕捉你的手势或头部动作,来替代传统的物理鼠标&…...