【面试实战】# 并发编程之线程池配置实战
1.先了解线程池的几个参数含义
corePoolSize (核心线程池大小):
- 作用: 指定了线程池维护的核心线程数量,即使这些线程处于空闲状态,它们也不会被回收。
- 用途: 核心线程用于处理长期的任务,保持最低的线程数量,以减少线程的创建和销毁的开销。
maximumPoolSize (最大线程池大小):
- 作用: 指定了线程池中允许的最大线程数。超过这个数量的线程将不会被创建。
- 用途: 限制了线程池的大小,以防止资源耗尽。
keepAliveTime (线程空闲时间):
- 作用: 当线程数超过
corePoolSize时,多余的线程在空闲时间超过指定时间后将会被终止和回收。 - 用途: 用于回收不再需要的线程,降低资源消耗。只对超过
corePoolSize的线程起作用。
unit (时间单位):
- 作用: 与
keepAliveTime一起使用,指定线程空闲时间的时间单位(如秒、毫秒)。 - 用途: 定义
keepAliveTime的时间单位。
workQueue (任务队列):
作用: 用于保存等待执行的任务的队列。
用途
: 管理任务的排队和处理方式,不同的队列类型可以影响线程池的行为。
- 常见的队列类型有:
SynchronousQueue: 不存储任务,任务直接交给线程执行。如果没有空闲线程,则创建新线程。LinkedBlockingQueue: 无界队列,可以存储任意多的任务。只有在任务队列为空时,才会创建新线程。ArrayBlockingQueue: 有界队列,存储固定数量的任务,当队列满时,任务将被拒绝。
- 常见的队列类型有:
threadFactory (线程工厂):
- 作用: 用于创建线程的工厂,可以定制线程的创建,比如设置线程名、优先级等。
- 用途: 统一管理线程的创建细节,有助于调试和监控。
handler (饱和策略/拒绝策略):
作用: 当任务无法提交给线程池(例如线程池已满且任务队列已满)时,如何处理新任务。
用途
: 定义任务无法被执行时的处理方式。
- 常见策略有:
AbortPolicy: 抛出RejectedExecutionException异常。CallerRunsPolicy: 由调用者线程执行该任务。DiscardPolicy: 丢弃新提交的任务。DiscardOldestPolicy: 丢弃队列中最旧的任务。
- 常见策略有:
2.调整线程池配置应对高并发(常规操作)
为了应对高并发的需求,可以考虑以下调整:
- 增大
corePoolSize和maximumPoolSize:- 增加核心线程和最大线程数可以提高线程池的并发处理能力,减少任务的等待时间。
- 调整
keepAliveTime和unit:- 减少
keepAliveTime可以更快地回收闲置线程,释放资源。相反,增加keepAliveTime适用于任务间隔较长的场景,以避免频繁创建和销毁线程。
- 减少
- 选择合适的
workQueue:- 使用
SynchronousQueue可以在任务很多但线程数不足时迅速增加线程数。 - 使用
LinkedBlockingQueue可以应对任务队列过长的问题,但可能导致线程数不会增加到最大。 - 使用
ArrayBlockingQueue适合在任务数有限的场景,防止资源耗尽。
- 使用
- 合理配置
handler:- 根据系统需求选择适合的拒绝策略。比如,在希望任务尽量被处理时使用
CallerRunsPolicy,在任务不能丢失时选择AbortPolicy。
- 根据系统需求选择适合的拒绝策略。比如,在希望任务尽量被处理时使用
- 优化
threadFactory:- 使用自定义的线程工厂设置线程名、优先级、守护线程等,提高线程管理的清晰度和系统稳定性。
- 监控和调整:
- 定期监控线程池的性能指标,如任务队列长度、线程使用率等,并根据实际情况动态调整参数配置。
// 创建线程池
ThreadPoolExecutor executor = new ThreadPoolExecutor(10, // corePoolSize50, // maximumPoolSize60, // keepAliveTimeTimeUnit.SECONDS, // keepAliveTime's unitnew LinkedBlockingQueue<>(100), // workQueueExecutors.defaultThreadFactory(), // threadFactorynew ThreadPoolExecutor.AbortPolicy() // handler
);// 提交任务
executor.submit(() -> {// Task implementation
});// 关闭线程池
executor.shutdown();3.IO密集型、CPU密集型任务的合理配置(生产常用)
3.1 IO密集型任务
IO密集型任务:(例如网络操作、文件读写)通常不需要大量的CPU时间,但可能会等待IO操作的完成。为了有效利用系统资源,可以配置
更多的线程来掩盖IO操作的等待时间。
配置建议:
corePoolSize和maximumPoolSize:- 建议的线程数通常远超过 CPU 核心数,因为线程在等待IO操作时不会占用CPU。可以使用
(CPU 核心数 * 2)或更多,甚至是(CPU 核心数 * 2) + 1这种经验值。 - 如果线程数太少,CPU资源可能未能充分利用。太多的线程可能会导致线程上下文切换的开销。
- 建议的线程数通常远超过 CPU 核心数,因为线程在等待IO操作时不会占用CPU。可以使用
keepAliveTime和unit:- 适当地增加
keepAliveTime,让线程在空闲时保留一段时间,以便在短时间内有任务到达时无需重新创建线程。
- 适当地增加
workQueue:LinkedBlockingQueue是常见选择,因为它可以有效处理大量任务,而不需要频繁地创建和销毁线程。SynchronousQueue也可以用于高并发IO场景,确保任务直接交给线程执行,迅速响应。
示例:
int numCores = Runtime.getRuntime().availableProcessors();
ThreadPoolExecutor ioBoundExecutor = new ThreadPoolExecutor(numCores * 2, // corePoolSizenumCores * 2 + 1, // maximumPoolSize60L, // keepAliveTimeTimeUnit.SECONDS, // keepAliveTime's unitnew LinkedBlockingQueue<>(), // workQueueExecutors.defaultThreadFactory(), // threadFactorynew ThreadPoolExecutor.CallerRunsPolicy() // handler
);3.2 CPU密集型任务
CPU密集型任务:(例如计算密集的操作、数据处理)主要消耗
CPU 资源,因此线程数应该与 CPU 核心数相匹配,以避免过度的线程上下文切换和资源竞争。
配置建议:
corePoolSize和maximumPoolSize:- 通常设置为
CPU 核心数或CPU 核心数 + 1。 - 过多的线程可能导致频繁的上下文切换,降低性能。
- 通常设置为
keepAliveTime和unit:keepAliveTime通常设置较短,适合及时回收空闲线程。
workQueue:SynchronousQueue或ArrayBlockingQueue是不错的选择,可以避免任务堆积,确保线程数控制在合理范围内。
示例:
int numCores = Runtime.getRuntime().availableProcessors();
ThreadPoolExecutor cpuBoundExecutor = new ThreadPoolExecutor(numCores, // corePoolSizenumCores + 1, // maximumPoolSize30L, // keepAliveTimeTimeUnit.SECONDS, // keepAliveTime's unitnew SynchronousQueue<>(), // workQueueExecutors.defaultThreadFactory(), // threadFactorynew ThreadPoolExecutor.AbortPolicy() // handler
);3.3 关键考虑因素
- 系统资源和负载:
- 监控系统的实际负载和资源使用情况,定期调整配置。
- 任务特性:
- 根据任务的性质(长任务、短任务、IO 密集型、CPU 密集型)选择合适的线程池配置。
- 阻塞时间:
- 对于 IO 密集型任务,理解和分析任务的阻塞时间,并根据其阻塞时间设置合适的线程池大小。
- 拒绝策略:
- 合理选择拒绝策略(如
AbortPolicy,CallerRunsPolicy),确保系统在负载过高时能平稳处理任务。
- 合理选择拒绝策略(如
4.专业级线程池配置(大厂规范)
4.1 线程池大小的计算公式
IO 密集型任务
对于IO密集型任务,可以使用以下公式计算适合的线程池大小:
N_threads: 推荐的线程池大小N_cores: CPU核心数W: 任务的等待时间(包括IO操作的等待时间)C: 任务的计算时间U: 期望的CPU使用率,通常设为0.8~0.9,避免CPU负载过高(0 < U < 1)解释: 公式中的 W/C反映了IO操作占用的时间比,
1 - U是为了预留一定的CPU资源。

示例:
假设有一个任务,CPU核心数为8,IO等待时间为200ms,计算时间为100ms,期望的CPU使用率为80%,则推荐的线程池大小为:
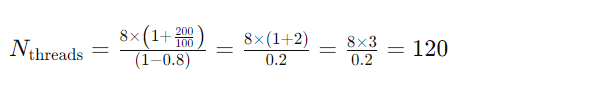
这意味着你可能需要配置大约120个线程来处理IO密集型任务。
CPU 密集型任务
对于CPU密集型任务,线程池的大小通常可以通过以下公式估算:
在CPU密集型场景下,由于
W很小或接近于零,因此公式通常简化为:
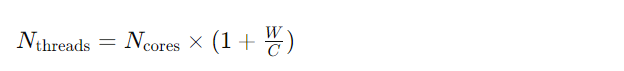

示例:
假设有一个任务,CPU核心数为8,计算时间大部分占用时间,等待时间可以忽略不计,则推荐的线程池大小为:

5.根据TPS和QPS进行线程池计算(生产常用)
其实和4的公式差不多
5.1 基础概念:
TPS (Transactions Per Second): 每秒系统处理的事务数量。这通常用于描述系统处理更复杂的业务逻辑的能力。QPS (Queries Per Second): 每秒系统处理的查询数量,通常用于衡量服务端API或数据库的查询处理能力。响应时间: 单个请求或事务的平均处理时间。
5.2 公式:

N_threads: 推荐的线程池大小Q: 每秒的请求数(TPS 或 QPS)R: 平均响应时间(秒)U: 系统期望的CPU利用率(< 1, 通常为80%~90%)
解释: 公式描述了在满足特定吞吐量和响应时间的情况下,需要的线程数,预留了一部分CPU资源以防过载。
5.3 IO密集型、CPU密集型任务选择
这里我们主要举例说明IO密集型任务
因为:
CPU密集型任务主要消耗CPU资源,线程数接近CPU核心数就足够,可以加一个额外的线程来处理。Nthreads=Ncores+1
IO密集型:
公式:

说明: 由于IO密集型任务在等待IO时不会占用CPU,因此线程数可以较高,适用于处理高并发的IO操作。
示例:
假设系统需要处理每秒500个请求(Q = 500),每个请求的平均响应时间为0.2秒,系统期望的CPU利用率为80%(U = 0.8):

这意味着你可能需要大约500个线程来处理这些IO密集型请求。
示例代码:
int qps = 500;
double responseTime = 0.2;
double targetUtilization = 0.8;int nThreads = (int) (qps * responseTime / (1 - targetUtilization));ThreadPoolExecutor ioBoundExecutor = new ThreadPoolExecutor(nThreads, // corePoolSizenThreads, // maximumPoolSize60L, // keepAliveTimeTimeUnit.SECONDS, // keepAliveTime's unitnew LinkedBlockingQueue<>(), // workQueueExecutors.defaultThreadFactory(), // threadFactorynew ThreadPoolExecutor.CallerRunsPolicy() // handler
);
6.总结
- IO密集型任务: 使用公式
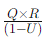 计算线程池大小。
计算线程池大小。 - CPU密集型任务: 使用公式
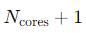 计算线程池大小。
计算线程池大小。 - 混合型任务: 综合IO和CPU的公式进行计算和调整。

W: 平均等待时间C: 平均计算时间
- 实际应用: 根据QPS或TPS、响应时间、期望的CPU利用率等参数进行计算,并定期监控系统负载进行调整。
合理的线程池配置可以显著提升系统的处理能力和资源利用率,因此根据具体需求和系统指标进行精细配置是至关重要的。
相关文章:
【面试实战】# 并发编程之线程池配置实战
1.先了解线程池的几个参数含义 corePoolSize (核心线程池大小): 作用: 指定了线程池维护的核心线程数量,即使这些线程处于空闲状态,它们也不会被回收。用途: 核心线程用于处理长期的任务,保持最低的线程数量,以减少线程的创建和…...
Pytest 读取excel文件参数化应用
本文是基于Pytest框架,读取excel中的文件,传入页面表单中,并做相应的断言实现。 1、编辑媒体需求 首先明确一下需求,我们需要对媒体的表单数据进行编辑,步骤如下: 具体表单如下图所示 1、登录 2、点击我…...
qt 一个可以拖拽的矩形
1.概要 2.代码 2.1 mycotrl.h #ifndef MYCOTRL_H #define MYCOTRL_H#include <QWidget> #include <QMouseEvent>class MyCotrl: public QWidget {Q_OBJECT public://MyCotrl();MyCotrl(QWidget *parent nullptr); protected:void paintEvent(QPaintEvent *even…...

C# 启动exe 程序
(1) publicbool Start () System.Diagnostics.Process process new System.Diagnostics.Process(); process.StartInfo.FileName "iexplore.exe"; //IE浏览器,可以更换 process.StartInfo.Arguments "http://www.baidu.com"; process.…...

Netty中的Reactor模型实现
Netty版本:4.1.17 Reactor模型是Doug Lea在《Scalable IO in Java》提出的,主要是针对NIO的。 其中的主从Reactor模式在Netty中的配置如下: EventLoopGroup bossGroup new NioEventLoopGroup(1); EventLoopGroup workerGroup new NioEv…...

dll丢失应该怎么解决,总结5种解决DLL丢失问题的方法
在数字时代,我们与计算机的每一天都密不可分。然而,就像所有技术产品一样,我们的计算设备也时不时地会出现一些问题,让人头疼不已。就在上周,我遭遇了一个令人崩溃的技术挑战——DLL文件丢失。这个看似微不足道的小问题…...

dial tcp 10.96.0.1:443: connect: no route to host
1、创建Pod一直不成功,执行kubectl describe pod runtime-java-c8b465b98-47m82 查看报错 Warning FailedCreatePodSandBox 2m17s kubelet Failed to create pod sandbox: rpc error: code Unknown desc failed to setup network for…...

VScode创建ROS项目 ROS集成开发环境
ROS使用VScode创建项目步骤 1.创建ROS工作空间2.启动VScode3.VScode编译ROS4.创建ROS功能包C语言开发Python语言开发 本文章介绍了如何在Ubuntu18.04系统下搭建VScode 的ROS项目 搭建项目分为一下几个步骤: 1.创建ROS工作空间 创建一个demo的ROS工作空间࿰…...

nodejs从基础到实战学习笔记-nodejs简介
一、Node.js简介 • Node.js是一个能够在服务器端运行JavaScript的开放源代码、跨平台JavaScript运行环境。 • Node采用Google开发的V8引擎运行js代码,使用事件驱动、非阻塞和异步I/O模型等技术来提高性能,可优化应用程序的传输量和规模。 1.1 特性 …...
集群)
2024年最新版------二进制安装部署Kubernetes(K8S)集群
Kubernetes二进制集群部署 文章目录 Kubernetes二进制集群部署资源列表基础环境一、环境准备1.1、绑定映射关系1.2、所有主机安装Docker1.3、所有主机设置iptables防火墙 二、生成通信加密证书2.1、master上成功CA证书2.2.1、创建证书存放位置并安装证书生成工具2.2.2、拷贝证书…...

【mysql】关键词搜索实现
关键词搜索实现两种方式 -- 方式1 模糊匹配搜索 -- 场景一:搜索出来地址内包含‘李’和‘中国’的 select * from tn_md_cust_link where address like concat (%李%) or address like concat (%中国%) -- 场景二:搜索地址或者名称包含 ‘181’ 的 …...

Python面试十问2
一、如何使用列表创建⼀个DataFrame # 导入pandas库 import pandas as pd# 创建一个列表,其中包含数据 data [[A, 1], [B, 2], [C, 3]]# 使用pandas的DataFrame()函数将列表转换为DataFrame df pd.DataFrame(data, columns[Letter, Number]) # 列名# 显示创建的…...

C# OpenCvSharp 图像处理函数-颜色通道-cvtColor
使用 OpenCvSharp 中的 cvtColor 函数进行图像颜色转换 在图像处理领域,颜色空间转换是一个非常常见的操作。OpenCvSharp 提供了一个强大的函数 cvtColor 来处理这类转换。本文将详细介绍 cvtColor 函数的使用方法,并通过具体的示例演示如何在实际项目中应用这些知识。 函数…...
——模型IO缓存)
总结之LangChain(三)——模型IO缓存
一、聊天模型缓存 LangChain为聊天模型提供了一个可选的缓存层。这有两个好处: 如果您经常多次请求相同的完成结果,它可以通过减少您对LLM提供程序的API调用次数来帮您节省费用。 它可以通过减少您对LLM提供程序的API调用次数来加快您的应用程序速度。…...

判断一个Java服务是不是GateWay
方法 直接在对应服务的url后变加上后缀/actuator/gateway/routes,看是否会返回Gateway的路由信息。 如果返回了GateWay的路由列表,则该服务为Gateway服务。...

三次插值曲线--插值技术
三次插值曲线 1.1.三次样条曲线 三次样条曲线的基本思想是,在给定的一系列点(称为控制点或数据点)之间,通过一系列三次多项式曲线段来拟合这些点,使得整个曲线既平滑又准确地通过所有控制点。 1.1.1.数学定义 给定…...
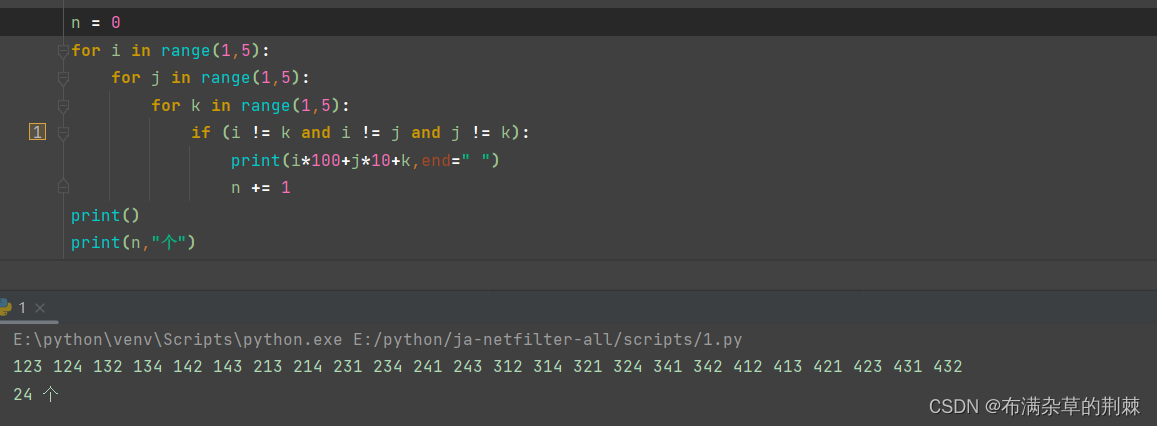
python循环结构
1.while 循环 语句: while 循环条件表达式: 代码块 else: 代码块 小练: 设计一百以内的偶数相加 n 0 while n < 100:n 1if n % 2 0 :print(n) 判断是不是闰年(四年一润和百年不润,或者四百年一润&am…...

深入理解Netty的Pipeline机制:原理与实践详解
深入理解Netty的Pipeline机制:原理与实践详解 Netty是一个基于Java的高性能异步事件驱动的网络应用框架,广泛应用于高并发网络编程。(学习netty请参考:深入浅出Netty:高性能网络应用框架的原理与实践)Nett…...
直方图均衡化示例
禹晶、肖创柏、廖庆敏《数字图像处理(面向新工科的电工电子信息基础课程系列教材)》 图3-17...

私域电商新纪元:消费增值模式的创新与成功实践
大家好,我是吴军,很高兴能够与您分享私域电商领域的魅力与机遇。今天,我将为大家呈现一个令人瞩目的成功案例,这个案例充分展现了私域电商的巨大潜力和无限可能。 在短短一个月的时间里,我们的客户成功实现了业绩的飞跃…...
)
【免费下载】 JIRA用户操作指南(详细版)
JIRA用户操作指南(详细版) 【下载地址】JIRA用户操作指南详细版 JIRA用户操作指南(详细版)欢迎使用JIRA用户操作指南,本指南旨在帮助您全面理解并高效地使用JIRA这一强大的问题跟踪与项目管理工具 项目地址: https:/…...


京东滑块验证码JS逆向实战:从接口分析到轨迹加密
1. 京东滑块验证码逆向分析入门 第一次接触京东滑块验证码逆向时,我也被那一堆加密参数搞得头晕眼花。但经过多次实战后,我发现只要掌握几个关键点,就能轻松破解这个看似复杂的验证系统。滑块验证码的核心逻辑其实很简单:系统通过…...
:谷歌AI团队内部培训手册泄露版)
NotebookLM具身智能落地实战(从零部署到ROS2集成):谷歌AI团队内部培训手册泄露版
更多请点击: https://intelliparadigm.com 第一章:NotebookLM具身智能研究 NotebookLM 是 Google 推出的基于用户自有文档进行语义理解与推理的 AI 助手,其核心能力在于“文档感知”(document-grounded reasoning)。当…...

B站视频转文字终极方案:3分钟学会一键智能提取视频内容
B站视频转文字终极方案:3分钟学会一键智能提取视频内容 【免费下载链接】bili2text Bilibili视频转文字,一步到位,输入链接即可使用 项目地址: https://gitcode.com/gh_mirrors/bi/bili2text 还在为整理B站视频内容而烦恼吗࿱…...

【技术解析】从点测量到全场感知:DIC三维应变测量如何革新传统应变片测试范式
1. 从点到面的技术革命:为什么我们需要全场应变测量? 记得我第一次接触材料力学测试时,导师让我用传统应变片测量一块铝合金板的拉伸变形。我花了整整三天时间,在试样上贴了二十多个应变片,结果数据还是支离破碎。那时…...

隐私透明化测试:直播用户数据的匿名表演
一、直播用户数据匿名化:隐私保护的核心防线在直播行业高速发展的当下,用户数据已成为平台运营、内容优化和商业变现的核心资产。然而,数据的过度收集与滥用也引发了严重的隐私担忧。据2025年全球隐私监管报告显示,直播行业因用户…...

避坑指南:SAP BP客户维护cl_md_bp_maintain的那些“坑”与最佳实践
SAP BP客户维护实战:cl_md_bp_maintain深度避坑手册 当ABAP开发人员第一次接触cl_md_bp_maintain类时,往往会被其强大的业务伙伴(Business Partner)管理功能所吸引,但随之而来的是一系列令人头疼的"坑"。本文将从实际项目经验出发&…...

永强数据恢复硬盘设备加密数据专业解锁恢复服务
在当今数字化时代,数据的重要性不言而喻。无论是个人用户存储的珍贵照片、视频,还是企业存储的关键商业数据,一旦丢失,都可能带来巨大的损失。而硬盘设备加密数据的丢失或无法解锁,更是让人头疼不已。北京永强数据恢复…...

3步搞定Unity游戏中文翻译:XUnity.AutoTranslator完全指南
3步搞定Unity游戏中文翻译:XUnity.AutoTranslator完全指南 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator 还在为外语游戏的语言障碍而苦恼吗?想体验原汁原味的游戏内容却看不懂菜…...