Python面试十问2
一、如何使用列表创建⼀个DataFrame
# 导入pandas库
import pandas as pd# 创建一个列表,其中包含数据
data = [['A', 1], ['B', 2], ['C', 3]]# 使用pandas的DataFrame()函数将列表转换为DataFrame
df = pd.DataFrame(data, columns=['Letter', 'Number']) # 列名# 显示创建的DataFrame
print(df)Letter Number
0 A 1
1 B 2
2 C 3二、如何使用Series 字典对象生成 DataFrame
# 导入pandas库
import pandas as pd# 创建一个字典对象
data = {'Name': ['Tom', 'Nick', 'John'], 'Age': [20, 21, 19]}# 使用pandas的DataFrame()函数将字典转换为DataFrame
df = pd.DataFrame(data)# 显示创建的DataFrame
print(df)Name Age
0 Tom 20
1 Nick 21
2 John 19三、如何查看头部数据和尾部数据
分别是df.head()和df.tail() →默认返回前(后)5条数据。
四、如何快速查看数据的统计摘要
区别df.describe()和df.info()
df.describe():默认情况下,它会为数值型列提供中心趋势、离散度和形状的统计描述,包括计数、均值、标准差、最小值、下四分位数(25%)、中位数(50%)、上四分位数(75%)以及最大值。此外,你可以通过传递参数来调整df.describe()的行为,例如include参数可以设置为'all'来包含所有列的统计信息,或者设置为'O'来仅包含对象列的统计信息。df.info():主要用于提供关于DataFrame的一般信息,如列索引、数据类型、非空值数量以及内存使用情况。它不会提供数值型数据的统计摘要,而是更多地关注于数据集的整体结构和数据类型。
五、pandas中的索引操作
pandas⽀持四种类型的多轴索引,它们是:
Dataframe.[ ] 此函数称为索引运算符
Dataframe.loc[ ] : 此函数⽤于标签
Dataframe.iloc[ ] : 此函数⽤于基于位置或整数的
Dataframe.ix[] : 此函数⽤于基于标签和整数的panda set_index()是⼀种将列表、序列或dataframe设置为dataframe索引的⽅法。语法:
DataFrame.set_index(keys, inplace=False)
- keys:列标签或列标签/数组列表,需要设置为索引的列
- inplace:默认为False,适当修改DataFrame(不要创建新对象)
如何重置索引 ?
Pandas Series.reset_index()函数的作⽤是:⽣成⼀个新的DataFrame或带有重置索引的Series。
六、pandas的运算操作
如何得到⼀个数列的最⼩值、第25百分位、中值、第75位和最⼤值?
import pandas as pd
import numpy as np
from numpy import percentile
p = pd.Series(np.random.normal(14, 6, 22))
state = np.random.RandomState(120)
p = pd.Series(state.normal(14, 6, 22))
print(percentile(p, q=[0, 25, 50, 75, 100]))
- Pandas支持加(
+)、减(-)、乘(*)、除(/)、取余(%)等基本算术运算符,可以用于DataFrame和Series之间的元素级运算,以及与标量的运算。- Pandas提供了一系列内置函数,如
sum()、mean()、max()、min()等,用于对数据进行聚合计算。此外,还可以使用apply()方法将自定义函数应用于DataFrame或Series。- 可以使用
sort_values()方法对DataFrame或Series进行排序,根据指定的列或行进行升序或降序排列。
七、apply() 函数使用方法
如果需要将函数应⽤到DataFrame中的每个数据元素,可以使⽤ apply() 函数以便将函数应⽤于给定dataframe中的每⼀⾏。
import pandas as pd
def add(a, b, c):return a + b + c
def main():data = {'A':[1, 2, 3],'B':[4, 5, 6],'C':[7, 8, 9] }
df = pd.DataFrame(data)
print("Original DataFrame:\n", df)
df['add'] = df.apply(lambda row : add(row['A'],
row['B'], row['C']), axis = 1)Original DataFrame:A B C
0 1 4 7
1 2 5 8
2 3 6 9A B C add
0 1 4 7 12
1 2 5 8 15
2 3 6 9 18八、pandas的合并操作
如何将新⾏追加到pandas DataFrame?
Pandas dataframe.append()函数的作⽤是:将其他dataframe的⾏追加到给定的dataframe的末尾,返回⼀个新的dataframe对象。
语法:DataFrame.append( ignore_index=False,)
参数:
- ignore_index : 如果为真,就不要使⽤索引标签
import pandas as pd
# 使⽤dictionary创建第⼀个Dataframe
df1 =df =pd.DataFrame({"a":[1, 2, 3, 4],"b":[5, 6, 7, 8]})
# 使⽤dictionary创建第⼆个Dataframe
df2 =pd.DataFrame({"a":[1, 2, 3],"b":[5, 6, 7]})
# 现在将df2附加到df1的末尾
df1.append(df2)第⼆个DataFrame的索引值保留在附加的DataFrame中,设置ignore_index = True可以避免这种情况。
九、分组(Grouping)聚合
“group by” 指的是涵盖下列⼀项或多项步骤的处理流程:
- 分割:按条件把数据分割成多组;
- 应⽤:为每组单独应⽤函数;
- 组合:将处理结果组合成⼀个数据结构。
- 先分组,再⽤ sum()函数计算每组的汇总数据
- 多列分组后,⽣成多层索引,也可以应⽤ sum 函数
- 分组后可以使用如
sum()、mean()、min()、max()等聚合函数来计算每个组的统计值。如果想要对每个分组应用多个函数,可以使用agg()方法,并传入一个包含多个函数名的列表,例如group_1.agg(['sum', 'mean'])。
十、数据透视表应用
透视表是⼀种可以对数据动态排布并且分类汇总的表格格式,在pandas中它被称作pivot_table。
透视表是一种强大的数据分析工具,它可以快速地对大量数据进行汇总、分析和呈现。
pivot_table(data, values=None, index=None, columns=None)
- Index: 就是层次字段,要通过透视表获取什么信息就按照相应的顺序设置字段
- Values: 可以对需要的计算数据进⾏筛选
- Columns: 类似Index可以设置列层次字段,它不是⼀个必要参数,作为⼀种分割数据的可选⽅式。
import pandas as pd# 创建示例数据
data = {'日期': ['2022-01-01', '2022-01-01', '2022-01-02', '2022-01-02'],'产品': ['A', 'B', 'A', 'B'],'地区': ['北京', '上海', '北京', '上海'],'销售额': [100, 200, 150, 250]}
df = pd.DataFrame(data)# 使用pivot_table方法创建数据透视表
pivot_table = df.pivot_table(values='销售额', index='产品', columns='地区', aggfunc='sum')print(pivot_table)# 结果
地区 北京 上海
产品
A 100 150
B 200 250相关文章:

Python面试十问2
一、如何使用列表创建⼀个DataFrame # 导入pandas库 import pandas as pd# 创建一个列表,其中包含数据 data [[A, 1], [B, 2], [C, 3]]# 使用pandas的DataFrame()函数将列表转换为DataFrame df pd.DataFrame(data, columns[Letter, Number]) # 列名# 显示创建的…...

C# OpenCvSharp 图像处理函数-颜色通道-cvtColor
使用 OpenCvSharp 中的 cvtColor 函数进行图像颜色转换 在图像处理领域,颜色空间转换是一个非常常见的操作。OpenCvSharp 提供了一个强大的函数 cvtColor 来处理这类转换。本文将详细介绍 cvtColor 函数的使用方法,并通过具体的示例演示如何在实际项目中应用这些知识。 函数…...
——模型IO缓存)
总结之LangChain(三)——模型IO缓存
一、聊天模型缓存 LangChain为聊天模型提供了一个可选的缓存层。这有两个好处: 如果您经常多次请求相同的完成结果,它可以通过减少您对LLM提供程序的API调用次数来帮您节省费用。 它可以通过减少您对LLM提供程序的API调用次数来加快您的应用程序速度。…...

判断一个Java服务是不是GateWay
方法 直接在对应服务的url后变加上后缀/actuator/gateway/routes,看是否会返回Gateway的路由信息。 如果返回了GateWay的路由列表,则该服务为Gateway服务。...

三次插值曲线--插值技术
三次插值曲线 1.1.三次样条曲线 三次样条曲线的基本思想是,在给定的一系列点(称为控制点或数据点)之间,通过一系列三次多项式曲线段来拟合这些点,使得整个曲线既平滑又准确地通过所有控制点。 1.1.1.数学定义 给定…...
python循环结构
1.while 循环 语句: while 循环条件表达式: 代码块 else: 代码块 小练: 设计一百以内的偶数相加 n 0 while n < 100:n 1if n % 2 0 :print(n) 判断是不是闰年(四年一润和百年不润,或者四百年一润&am…...

深入理解Netty的Pipeline机制:原理与实践详解
深入理解Netty的Pipeline机制:原理与实践详解 Netty是一个基于Java的高性能异步事件驱动的网络应用框架,广泛应用于高并发网络编程。(学习netty请参考:深入浅出Netty:高性能网络应用框架的原理与实践)Nett…...
直方图均衡化示例
禹晶、肖创柏、廖庆敏《数字图像处理(面向新工科的电工电子信息基础课程系列教材)》 图3-17...

私域电商新纪元:消费增值模式的创新与成功实践
大家好,我是吴军,很高兴能够与您分享私域电商领域的魅力与机遇。今天,我将为大家呈现一个令人瞩目的成功案例,这个案例充分展现了私域电商的巨大潜力和无限可能。 在短短一个月的时间里,我们的客户成功实现了业绩的飞跃…...
Java——IO流(一)-(6/8):字节流-FileInputStream 每次读取多个字节(示例演示)、一次读取完全部字节(方式一、方式二,注意事项)
目录 文件字节输入流:每次读取多个字节 实例演示 注意事项 文件字节输入流:一次读取完全部字节 方式一 方式二 注意事项 文件字节输入流:每次读取多个字节 用到之前介绍过的常用方法: 实例演示 需求:用每次读取…...

服务器SSH 免密码登录
1. 背景 为了服务器的安全着想,设置的服务器密钥非常长。但是这导致每次连接服务器都需要输入一长串的密码,把人折腾的很痛苦,所以我就在想,能不能在终端SSH的时候无需输入密码。 windows 可以使用 xshell 软件,会自…...
Linux安装MySQL以及远程连接
1、Linux安装MySQL 1.1、准备解压包 MySQL5.x解压包 提取码:9y7n 1.2、通过rpm脚本安装 切记安装顺序:common --> libs --> client --> server 因为它们之间存在依赖关系,所以务必按照顺序安装 安装前请确保当前目录/文…...

SQL Server 数据库分页技术详解:选择最佳方法优化查询性能”。
当今数据驱动的应用程序中,数据库分页技术在优化查询性能和提升用户体验中扮演着重要角色。在 SQL Server 环境下,开发者面对大数据集时,常常需要选择合适的分页方法以平衡功能需求和性能优化。本文将详细介绍 SQL Server 中几种主要的分页技…...

electron录制-镜头缩放、移动
要求 1、当录屏过程中,鼠标点击,镜头应该往点击处拉近,等一段时间还原 2、录屏过程中,可能会发生多次点击,但是点击位置偏差大,可能会导致缩放之后,画面没出来,因此需要移动镜头帧 …...

红队内网攻防渗透:内网渗透之内网对抗:信息收集篇自动项目本机导出外部打点域内通讯PillagerBloodHound
红队内网攻防渗透 1. 内网自动化信息收集1.1 本机凭据收集类1.1.1、HackBrowserData 快速获取浏览器的账户密码1.1.2、Searchall 快速搜索服务器中的有关敏感信息还有浏览器的账户密码1.1.3、Pillager 适用于后渗透期间的信息收集工具,可以收集目标机器上敏感信息1.2 对外打点…...
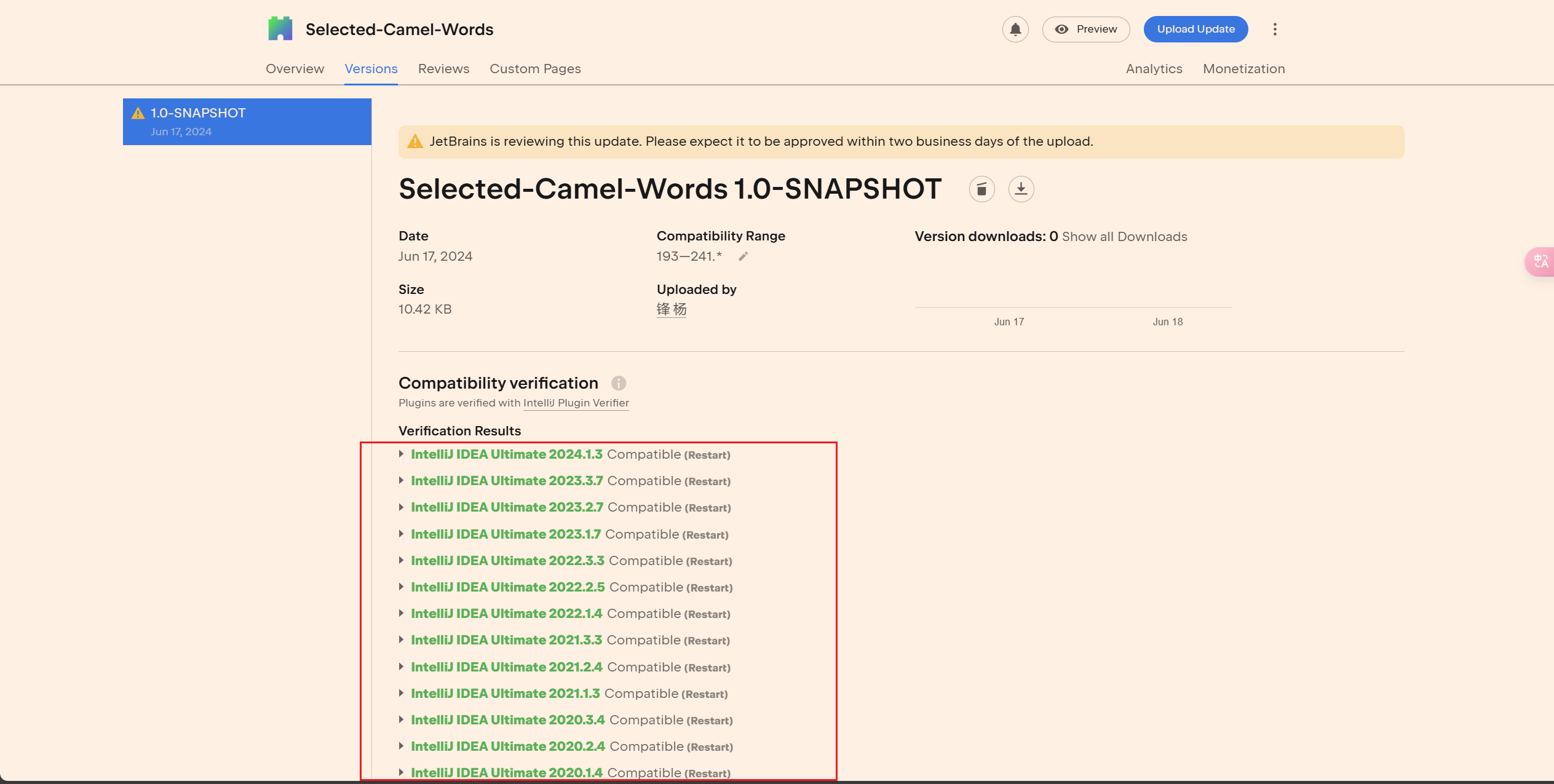
2024最新IDEA插件开发+发布全流程 SelectCamelWords[选中驼峰单词](idea源代码)
2024最新IDEA插件开发(发布)-SelectCamelWords[选中驼峰单词](idea源代码) 参考文档 Jetbrains Idea插件开发文档: https://plugins.jetbrains.com/docs/intellij/welcome.html代码地址:https://github.com/yangfeng…...

【网络安全】网络安全基础精讲 - 网络安全入门第一篇
目录 一、网络安全基础 1.1网络安全定义 1.2网络系统安全 1.3网络信息安全 1.4网络安全的威胁 1.5网络安全的特征 二、入侵方式 2.1黑客 2.1.1黑客入侵方式 2.1.2系统的威胁 2.2 IP欺骗 2.2.1 TCP等IP欺骗 2.2.2 IP欺骗可行的原因 2.3 Sniffer探测 2.4端口扫描技术…...
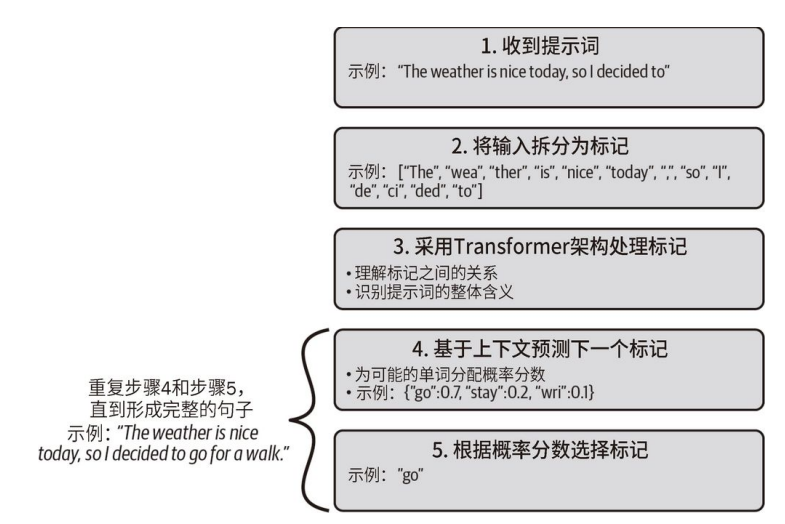
初识 GPT-4 和 ChatGPT
文章目录 LLM 概述理解 Transformer 架构及其在 LLM 中的作用解密 GPT 模型的标记化和预测步骤 想象这样⼀个世界:在这个世界里,你可以像和朋友聊天⼀样快速地与计算机交互。那会是怎样的体验?你可以创造出什么样的应用程序?这正是…...

【C语言】解决C语言报错:Array Index Out of Bounds
文章目录 简介什么是Array Index Out of BoundsArray Index Out of Bounds的常见原因如何检测和调试Array Index Out of Bounds解决Array Index Out of Bounds的最佳实践详细实例解析示例1:访问负索引示例2:访问超出上限的索引示例3:循环边界…...
【C++】一个极简但完整的C++程序
一、一个极简但完整的C程序 我们编写程序是为了解决问题和任务的。 1、任务: 某个书店将每本售出的图书的书名和出版社,输入到一个文件中,这些信息以书售出的时间顺序输入,每两周店主会手工计算每本书的销售量、以及每个出版社的…...

MLX90614红外测温传感器:从原理到Arduino实战应用指南
1. 项目概述:从接触式到非接触式的测温革新在嵌入式开发和物联网项目中,温度测量是一个永恒的主题。从传统的热敏电阻、DS18B20,到热电偶,我们习惯了将探头紧贴甚至刺入被测物体来获取读数。但你是否遇到过这样的困境:…...
)
【网安-Web渗透测试-内网渗透】内网信息收集(工具)
目录1. 内网基础知识1.1 局域网1.1.1 局域网简介1.1.2 局域网的网络结构1.2 工作组1.3 域1.4 内网渗透2. 环境说明2.1 DC2.2 WebServer2.3 Marry2.4 Jack3. Cobalt Strike工具:用户凭据(密码)收集4. Metasploit信息收集5. BloodHound工具6. 内…...

2025年知识竞赛行业趋势报告:智能化、场景化与生态融合
📊 2025年知识竞赛行业趋势报告技术更智能 场景更融合 内容更鲜活 工具更普惠🚀 引言:变革中的竞赛生态知识竞赛,这一古老的知识检验与娱乐形式,在数字技术的持续赋能下,正经历着一场深刻的范式变革。从…...

为开发者工具注入情感分析能力:开源库ai-devtools-sentiment实战指南
1. 项目概述:一个为开发者工具注入情感分析能力的开源库最近在折腾一些开发者工具,比如代码审查机器人、文档生成器或者IDE插件,我总感觉它们冷冰冰的。它们能告诉你代码有语法错误,能提示你某个API已废弃,但它们无法感…...

iPhone/iPad移动端CircuitPython嵌入式开发实战指南
1. 项目概述:当嵌入式开发遇上移动生产力作为一名在嵌入式硬件和创客领域折腾了十多年的老玩家,我经历过各种开发环境的变迁。从早年抱着一台厚重的笔记本电脑在实验室里调试,到后来用树莓派做便携式开发机,我一直希望能有一种更轻…...
)
限时开放|Perplexity学术搜索私藏工作区(含18个学科定制模板+实时更新的期刊影响因子映射表)
更多请点击: https://kaifayun.com 第一章:Perplexity学术搜索的核心价值与适用场景 Perplexity.ai 并非传统搜索引擎,而是一个融合大语言模型推理能力与实时学术信息检索的智能研究协作者。其核心价值在于将“提问—验证—溯源”闭环内化为…...

AI 说错了怎么办——给生成性 Agent 装上 Self-RAG 自审循环
AI 说错了怎么办——给生成性 Agent 装上 Self-RAG 自审循环Agent 早就跑通了,但有一条横切线一直没单独写过:深度阅读那种动辄一千多字的输出,怎么知道 LLM 是不是在自圆其说。这周回过头来补这一篇,顺便把本周做的几个小改动一并…...

Yokogawa ADV551数字输出模块
Yokogawa ADV551 数字输出模块是横河 CENTUM VP/CS 3000 系统的核心输出组件,具备以下 15 条特点:提供 32 路独立数字量输出通道。额定电压 24V DC,每通道负载能力充足。输出类型为电流吸收型(Current Sink)。支持状态…...


Awesome-LLM-Apps:大语言模型应用开发实战指南与开源项目宝库
1. 项目概述:一个大型语言模型应用的开源宝库如果你最近在折腾大语言模型,想找点现成的、能跑起来的应用来学习或者直接部署,那你大概率在GitHub上见过这个项目。awesome-llm-apps, 一个由开发者Shubham Saboo维护的仓库ÿ…...