【算法】算法基础入门详解:轻松理解和运用基础算法
😀大家好,我是白晨,一个不是很能熬夜😫,但是也想日更的人✈。如果喜欢这篇文章,点个赞👍,关注一下👀白晨吧!你的支持就是我最大的动力!💪💪💪

文章目录
- 前言
- 算法基础
- 一、快速排序
- 二、归并排序
- 三、二分算法
- 四、高精度算法
- 五、前缀和与差分
- 六、双指针算法
- 七、位运算
- 八、离散化
- 九、区间合并
- 后记
前言
大家好呀,我是白晨😜!这段时间身边🐏的人挺多的,白晨就老老实实在家摸鱼,真不是有意拖更的(bushi)。本次白晨想要分享的是新手学习必会的几种基础算法,由于这篇文章是新手向的,所以白晨这次对于算法思想尽量讲解的细致生动,代码实现尽量简洁易懂,同时我会贴上练习算法的题目链接,大家看完算法思路一定要自己去动手敲一遍,争取能把基础算法背下来。
算法的代码风格是偏向于快速实用的,没有像工程向代码一样严谨缜密、缩进和换行严格要求,两种代码风格各有优势,本篇文章大多数算法代码采用算法风格。
本篇文章内容分享的算法有:
- 快速排序
- 归并排序
- 二分算法
- 高精度算法
- 前缀和与差分
- 双指针算法
- 位运算
- 离散化
- 区间合并
算法基础
一、快速排序
快速排序是一种高效且使用广泛的排序算法。它的基本思想是选取一个记录作为枢轴,经过一趟排序,将整段序列分为两个部分,其中一部分的值都小于枢轴,另一部分都大于枢轴。然后再对左右区间重复这个过程,直到各区间只有一个数。
实现快速排序算法的关键在于先在待排序的数组中选择一个数字作为枢轴,然后把数组中的数字分成两部分,比枢轴小的数字移动到数组的左边,比枢轴大的数字移动到数组的右边;之后用递归的思路分别对左右两边进行排序。
下面用两道例题带领大家快速理解掌握快速排序:

🍬题目链接:快速排序
🍎算法思想:
-
快速排序的通用思路:
- 选择一个枢轴元素,通常选择数组的第一个元素或者中间的元素。
- 将数组中小于枢轴元素的值移动到它的左边,将大于枢轴元素的值移动到它的右边。
- 对枢轴元素左右两边的子数组递归执行步骤1和2,直到子数组只剩下一个元素。
-
模板快速实现详解:
- 定义
quick_sort函数,接受数组指针、左边界和右边界作为参数。 - 在
quick_sort函数中,首先判断左右边界是否合法,如果不合法则直接返回。 - 选择一个枢轴元素
key,这里选择的是数组中间的元素。 - 使用双指针
i和j分别从左右两端开始扫描数组,当i指向的元素小于枢轴元素时,i向右移动;当j指向的元素大于枢轴元素时,j向左移动。当i < j时交换两个指针所指向的元素。 - 最后递归对枢轴元素左右两边的子数组进行快速排序。
- 定义
🍊具体实现:
#include <iostream>using namespace std;const int N = 100010;int q[N];void quick_sort(int* q, int left, int right)
{if (left >= right) // 如果左右边界不合法,直接返回return;int i = left - 1, j = right + 1;int key = q[left + right >> 1]; // 选择枢轴元素while (i < j){do i++; while (q[i] < key); // i之前的数全部小于等于keydo j--; while (q[j] > key); // j之后的数全部大于等于keyif (i < j) swap(q[i], q[j]); // 如果i<j,交换两个指针所指向的元素}quick_sort(q, left, j); // 对左边子数组进行快速排序quick_sort(q, j + 1, right); // 对右边子数组进行快速排序
}int main()
{int n;scanf("%d", &n);for (int i = 0; i < n; i++) scanf("%d", &q[i]);quick_sort(q, 0, n - 1); // 对整个数组进行快速排序for (int i = 0; i < n; i++) printf("%d ", q[i]);return 0;
}
二、归并排序

🍬题目链接:归并排序
- 归并排序是一种分治算法,它将一个大数组分成两个小数组,然后递归地对这两个小数组进行排序,最后将两个排好序的小数组合并成一个有序的大数组。
- 在
merge_sort函数中,首先判断待排序区间长度是否小于等于1,如果是,则直接返回。否则计算中点mid,然后对左半部分和右半部分分别进行归并排序。 - 在对左右两部分排好序之后,使用双指针技术将两个有序的小数组合并成一个有序的大数组。具体来说,定义三个指针
i、j和k,其中i和j分别指向左右两部分的起始位置,而k指向辅助数组tmp的起始位置。当i和j都在各自的区间内时,比较v[i]和v[j]的大小关系,并将较小者放入tmp中,并移动相应的指针。当其中一个区间内所有元素都已经放入tmp中时,则依次将另一个区间内剩余元素放入tmp中。 - 最后将排好序的tmp复制回原数组v中。
#include <iostream>using namespace std;const int N = 1e5 + 10; // 定义常量N为100010int v[N], tmp[N]; // 定义整型数组v和tmp,大小均为N// 归并排序函数,参数为待排序数组v,以及待排序区间[left, right]
void merge_sort(int v[], int left, int right)
{if (left >= right) // 如果待排序区间长度小于等于1,则直接返回return;int mid = left + right >> 1; // 计算中点midmerge_sort(v, left, mid); // 对左半部分进行归并排序merge_sort(v, mid + 1, right); // 对右半部分进行归并排序int i = left, j = mid + 1, k = left; // 定义三个指针i、j、kwhile (i <= mid && j <= right) // 当i和j都在各自的区间内时{if (v[i] < v[j]) tmp[k++] = v[i++]; // 如果v[i] < v[j],则将v[i]放入tmp中,并移动指针i和kelse tmp[k++] = v[j++]; // 否则将v[j]放入tmp中,并移动指针j和k}while (i <= mid) // 如果左半部分还有剩余元素,则依次放入tmp中tmp[k++] = v[i++];while (j <= right) // 如果右半部分还有剩余元素,则依次放入tmp中tmp[k++] = v[j++];for (i = left; i <= right; ++i) // 将排好序的tmp复制回原数组v中v[i] = tmp[i];
}int main()
{int n;cin >> n; // 输入元素个数nfor (int i = 0; i < n; ++i)scanf("%d", &v[i]); // 输入n个元素merge_sort(v, 0, n - 1); // 对整个数组进行归并排序for (int i = 0; i < n; ++i)printf("%d ", v[i]); // 输出排好序的结果return 0;
}
三、二分算法
二分法,即二分搜索法,是通过不断缩小解可能存在的范围,从而求得问题最优解的方法。例如,如果一个序列是有序的,那么可以通过二分的方法快速找到所需要查找的元素,相比线性搜索要快不少。此外二分法还能高效的解决一些单调性判定的问题。
// 模板一
// 求满足check条件的最左下标
#include <iostream>using namespace std;template<class T>
int binary_search1(T* v, int l, int r)
{while (l < r){int mid = l + r >> 1;if (check(v[mid])) // check中 v[mid] 永远放在前面,eg. v[mid] >= ar = mid;elsel = mid + 1;}return mid;
}// 模板二
// 求满足check条件的最右下标
#include <iostream>using namespace std;template<class T>
int binary_search1(T* v, int l, int r)
{while (l < r){int mid = l + r + 1 >> 1; // 必须加一,避免死循环if (check(v[mid])) // eg.v[mid] <= al = mid;elser = mid - 1;}return mid;
}
- 数的范围

🍬题目链接:数的范围
// 数的范围#include <iostream>
#include <vector>using namespace std;int main()
{int n, m;cin >> n >> m; // 输入元素个数n和查询次数mvector<int> v(n); // 定义整型向量v,大小为nfor (int i = 0; i < n; ++i)cin >> v[i]; // 输入n个元素while (m--) // 循环执行m次查询操作{int num;cin >> num; // 输入要查询的元素num// 先找等于num的最左下标int l = 0, r = n - 1; // 定义双指针l和rwhile (l < r) // 当l<r时循环执行以下操作{int mid = l + r >> 1; // 计算中点midif (v[mid] >= num) // 如果v[mid] >= num,则在左半部分继续查找r = mid;else // 否则在右半部分继续查找l = mid + 1;}if (v[l] != num) // 如果没有找到num,则输出"-1 -1"{cout << "-1 -1" << endl;continue;}else{cout << l << " "; // 输出最左下标ll = 0, r = n - 1; // 重新定义双指针l和r// 再找等于num的最右下标while (l < r) // 当l<r时循环执行以下操作{int mid = l + r + 1 >> 1; // 计算中点midif (v[mid] <= num) // 如果v[mid] <= num,则在右半部分继续查找l = mid;else r = mid - 1;}cout << l << endl;}}return 0;
}
四、高精度算法
高精度算法是用计算机对于超大数据的一种模拟加,减,乘,除,乘方,阶乘等运算的方法,它用于处理大数字的数学计算。
比如,C++的long long类型最多处理2642^{64}264这么大的数,再大的数则无法处理。
- 高精度加法
我们可以模拟正常的加法,从个位开始,逐位相加,模拟过程中要注意的是:
- 我们取出字符串的每一个元素都是字符,所以不能直接将其相加,必须要减去
'0'才能得到这个数的真实值。 - 当一个数的每一位都已经遍历完了,如果另一个数还没遍历完,则在这个数的高位补0。
- 如果两个数字之和大于等于10,要进位。
- 每次向要返回字符串插入一个本次相加得到的个位数。
- 最后得到的返回字符串是反的,我们要将其反转。

🍬题目链接:高精度加法
// 高精度加法#include <iostream>
#include <iostream>
#include <vector>
#include <string>using namespace std;vector<int> add(vector<int>& a, vector<int>& b)
{int t = 0; // 进位vector<int> c;// 当a,b大数没有遍历完或者进位不为0时,继续循环for (int i = 0; i < a.size() || i < b.size() || t != 0; ++i){// 数字没有遍历完才加if (i < a.size()) t += a[i];if (i < b.size()) t += b[i];c.push_back(t % 10);t /= 10;}return c;
}int main()
{string a, b;cin >> a >> b;vector<int> a, b;// 字符串接收数据,用数组来保存数据,其实也可以直接使用字符串计算,为了方便理解以及美观好记// 暂时使用数组来存储大数的每一位,但是有一点要注意,数组存储大数时最好反着存,也即0下标存最低位,高下标存高位,类似于小端// 因为加法可能要进位,如果0下标存最高位,进位必须整体向后移动一位,这样太耗费时间for (int i = a.size() - 1; i >= 0; --i)a.push_back(a[i] - '0');for (int i = b.size() - 1; i >= 0; --i)b.push_back(b[i] - '0');vector<int> c = add(a, b);for (auto rit = c.rbegin(); rit != c.rend(); ++rit)printf("%d", *rit);return 0;
}
压位优化版(了解即可)
它首先定义了一个常量
base为1e9,表示每个元素存储9位数。然后定义了一个add函数,用于计算两个大数的和。在主函数中,首先读入两个字符串a和b,然后将它们转换为大数存储在向量A和B中。最后调用add函数计算它们的和并输出结果。
#include <iostream>
#include <vector>
#include <string>using namespace std;const int base = 1e9;vector<int> add(vector<int>& A, vector<int>& B)
{int t = 0; // 进位vector<int> C;// 当A,B大数没有遍历完或者进位不为0时,继续循环for (int i = 0; i < A.size() || i < B.size() || t != 0; ++i){// 数字没有遍历完才加if (i < A.size()) t += A[i];if (i < B.size()) t += B[i];C.push_back(t % base);t /= base;}if (t) C.push_back(t);return C;
}int main()
{string a, b;cin >> a >> b;vector<int> A, B;// 压位,一次将9个数字存储到一个位置,可以节省空间以及加快运算for (int i = a.size() - 1, s = 0, t = 1, j = 0; i >= 0; --i){s += (a[i] - '0') * t;j++, t *= 10;if (j == 9 || i == 0){A.push_back(s);j = 0, s = 0, t = 1;}}for (int i = b.size() - 1, s = 0, t = 1, j = 0; i >= 0; --i){s += (b[i] - '0') * t;j++, t *= 10;if (j == 9 || i == 0){B.push_back(s);j = 0, s = 0, t = 1;}}vector<int> C = add(A, B);cout << C.back();// 高位为0的需要用前导0填充for (int i = C.size() - 2; i >= 0; --i) printf("%09d", C[i]);return 0;
}
- 高精度减法
和加法大体思路相同,不过要先判断被减数和减数的大小,确定结果的正负。

🍬题目链接:高精度减法
// 高精度减法#include <iostream>
#include <vector>
#include <string>using namespace std;// a大于等于b,返回true;反之,返回false
bool compare(string& a, string& b)
{if (a.size() != b.size())return a.size() > b.size();for (int i = 0; i < a.size(); ++i)if (a[i] != b[i])return a[i] > b[i];return true;
}vector<int> sub(vector<int>& a, vector<int>& b)
{vector<int> c;int t = 0; // 借位for (int i = 0; i < a.size(); ++i){t = a[i] - t;if (i < b.size())t -= b[i];// 无论借没借位,先加上10再模10,就是这一位的值c.push_back((t + 10) % 10);// 如果没有借位a[i] - t >= b[i],那么t最后是大于等于0// 反之,小于0if (t < 0) t = 1;else t = 0;}while (c.size() > 1){if (c.back() != 0)break;c.pop_back();}return c;
}int main()
{string a, b;cin >> a >> b;vector<int> a, b;for (int i = a.size() - 1; i >= 0; --i)a.push_back(a[i] - '0');for (int i = b.size() - 1; i >= 0; --i)b.push_back(b[i] - '0');vector<int> c;if (compare(a, b))c = sub(a, b);else{c = sub(b, a);cout << "-";}for (int i = c.size() - 1; i >= 0; --i){printf("%d", c[i]);}return 0;
}
- 高精度乘法
先来看乘法用竖式如何计算:

-
我们发现,从右到左,
num2每一位都需要乘以num1,并且每乘完一次num1所得的数字的权重要乘10。 -
num2每一位乘num1都是个位数*num1,所以我们可以先把个位数乘num1的结果保存起来,用的时候直接调用。 -
得到
num2每一位乘num1的字符串后,保存起来,最后和竖式一样,依次相加每一位的结果,得到最后的答案。

🍬题目链接:高精度乘法
题目中 B 的值小于等于 10000,可以直接用 A 的每一位乘 B,具体实现见代码。
// 高精度乘法#include <iostream>
#include <vector>
#include <string>using namespace std;vector<int> mul(vector<int>& A, const int& b)
{int t = 0; // 进位vector<int> C;for (int i = 0; i < A.size() || t != 0; ++i){if (i < A.size()) t += A[i] * b;C.push_back(t % 10);t /= 10;}// 删去前导0,防止乘0的特殊情况while (C.size() > 1){if (C.back() != 0)break;C.pop_back();}return C;
}int main()
{string a;int b;cin >> a >> b;vector<int> A;for (int i = a.size() - 1; i >= 0; --i)A.push_back(a[i] - '0');vector<int> C = mul(A, b);for (int i = C.size() - 1; i >= 0; --i)printf("%d", C[i]);return 0;
}- 高精度除法
思路和上述高精度算法大体相同,具体见代码。

🍬题目链接:高精度除法
// 高精度除法
#include <iostream>
#include <vector>
#include <string>
#include <algorithm>using namespace std;vector<int> div(vector<int>& A, const int& b, int& r)
{int t = 0;vector<int> C;// 除法要从高位开始for (int i = A.size() - 1; i >= 0; --i){t = t * 10 + A[i];C.push_back(t / b);t %= b;}r = t;// 由于C是从高位开始记录的,返回时需要反转一下,恢复低位存低位,高位存高位的标准reverse(C.begin(), C.end());// 除去前导0while (C.size() > 1 && C.back() == 0)C.pop_back();return C;
}int main()
{string a;int b;cin >> a >> b;vector<int> A;for (int i = a.size() - 1; i >= 0; --i)A.push_back(a[i] - '0');int r = 0; // 余数vector<int> C = div(A, b, r);for (int i = C.size() - 1; i >= 0; --i)printf("%d", C[i]);printf("\n%d", r);return 0;
}
五、前缀和与差分
- 一维前缀和

🍬题目链接:前缀和
首先定义一个函数 get_part_sum,用于计算区间和。在主函数中,首先读入两个整数 n 和 m,然后读入一个长度为 n 的数组 v。接着计算前缀和数组 prefix,最后循环读入查询区间的左右端点 l 和 r,并输出区间和。
// 一维前缀和
#include <iostream>
#include <vector>
using namespace std;// 计算区间和
int get_part_sum(vector<int>& prefix, int l, int r)
{// 区间和 = 前缀和[r] - 前缀和[l - 1]return prefix[r] - prefix[l - 1];
}int main()
{int n, m;cin >> n >> m;vector<int> v(n + 1);for (int i = 1; i <= n; ++i)scanf("%d", &v[i]);// 计算前缀和数组vector<int> prefix(n + 1);for (int i = 1; i <= n; ++i)// 前缀和[i] = 前缀和[i - 1] + v[i]prefix[i] = prefix[i - 1] + v[i];int l, r;while (cin >> l >> r){// 输出区间[l,r]的区间和cout << get_part_sum(prefix, l, r) << endl;}return 0;
}
- 二维前缀和

🍬题目链接:子矩阵的和
// 二维前缀和
#include <iostream>
#include <vector>using namespace std;int get_part_sum(vector<vector<int>>& prefix, int x1, int y1, int x2, int y2)
{return prefix[x2][y2] - prefix[x1 - 1][y2] - prefix[x2][y1 - 1] + prefix[x1 - 1][y1 - 1];
}int main()
{int n, m, q;cin >> n >> m >> q;vector<vector<int>> vv(n + 1, vector<int>(m + 1, 0));for (int i = 1; i <= n; ++i)for (int j = 1; j <= m; ++j)scanf("%d", &vv[i][j]);vector<vector<int>> prefix(n + 1, vector<int>(m + 1, 0));for (int i = 1; i <= n; ++i)for (int j = 1; j <= m; ++j)prefix[i][j] = prefix[i - 1][j] + prefix[i][j - 1] - prefix[i - 1][j - 1] + vv[i][j];// 二维前缀和计算公式:// sum(x1, y1, x2, y2) = prefix(x2, y2) - prefix(x1 - 1, y2) - prefix(x2, y1 - 1) + prefix(x1 - 1, y1 - 1)int x1, y1, x2, y2;while (q--){scanf("%d%d%d%d", &x1, &y1, &x2, &y2);cout << get_part_sum(prefix, x1, y1, x2, y2) << endl;}return 0;
}
- 一维差分
差分算法是一种利用原数组和差分数组的关系,来快速地对数组中某个区间进行同一操作的方法。例如,如果要对原数组a[]中[l,r]之间的每个数加上c,只需要对差分数组b[]中的b[l]加上c,b[r+1]减去c,然后重新求出a[]即可。
如何构造差分数组呢?
构造差分数组的方法很简单,只需要用原数组的相邻元素的差来赋值即可。例如,如果原数组a[]为{1,2,4,6},那么差分数组b[]为{1,1,2,2},因为
b[1]=a[1]-a[0],b[2]=a[2]-a[1],以此类推。反之,从差分数组求原数组就为:
a[i] = a[i - 1] + b[i](i > 0)。

🍬题目链接:差分
一维差分数组是一种处理区间修改和查询的方法,它可以在O(1)的时间内实现对原数组某个区间内所有元素加上一个常数。具体来说,如果原数组是a[],差分数组是b[],那么有以下关系:
a[i] = b[1] + b[2] + … + b[i]b[i] = a[i] - a[i-1]
// 一维差分
#include <iostream>
#include <vector>using namespace std;void insert(vector<int>& dif, int l, int r, int c)
{dif[l] += c;dif[r + 1] -= c;
}int main()
{int n, m;cin >> n >> m;vector<int> v(n + 2);for (int i = 1; i <= n; ++i)scanf("%d", &v[i]);// 差分公式:mod(l, r, c) : dif(l) + c and dif(r + 1) - c vector<int> dif(n + 2, 0);// 差分数组初始化:假设 前缀和 和 差分数组 都是0开始,前缀和数组(i位置)每插入一个数字相当于 在差分数组(i, i)位置插入v[i]for (int i = 1; i <= n; ++i)insert(dif, i, i, v[i]);int l, r, c;while (m--){cin >> l >> r >> c;insert(dif, l, r, c);}for (int i = 1; i <= n; ++i)v[i] = v[i - 1] + dif[i];for (int i = 1; i <= n; ++i)printf("%d ", v[i]);return 0;
}
- 二维差分

🍬题目链接:差分矩阵
// 二维差分
#include <iostream>
#include <vector>using namespace std;const int N = 1010;int v[N][N];
int dif[N][N];// 二维差分公式 insert(x1, y1, x2, y2, c):
// dif[x1][y1] + c && dif[x2 + 1][y1] - c && dif[x1][y2 + 1] - c && dif[x2 + 1][y2 + 1] + c
// 定义一个函数,用于对差分数组进行修改
void insert(int x1, int y1, int x2, int y2, int c)
{dif[x1][y1] += c;dif[x2 + 1][y1] -= c;dif[x1][y2 + 1] -= c;dif[x2 + 1][y2 + 1] += c;
}// 二维差分: dif[n][m] 会直接影响 v[n][m] 及右下方的值
int main()
{int n, m, q;cin >> n >> m >> q;for (int i = 1; i <= n; ++i)for (int j = 1; j <= m; ++j)scanf("%d", &v[i][j]);// 初始化差分数组for (int i = 1; i <= n; ++i)for (int j = 1; j <= m; ++j)insert(i, j, i, j, v[i][j]);int x1, y1, x2, y2, c;while (q--){cin >> x1 >> y1 >> x2 >> y2 >> c;insert(x1, y1, x2, y2, c);}for (int i = 1; i <= n; ++i)for (int j = 1; j <= m; ++j)v[i][j] = v[i - 1][j] + v[i][j - 1] - v[i - 1][j - 1] + dif[i][j];for (int i = 1; i <= n; ++i){for (int j = 1; j <= m; ++j)printf("%d ", v[i][j]);printf("\n");}return 0;
}
六、双指针算法
双指针算法是一种在重复遍历对象的过程中,使用两个指针进行访问的方法。它可以利用对象的某种单调性,减少不必要的遍历次数,从而优化时间复杂度。双指针算法有两种常见的类型:快慢指针和对撞指针。
- 快慢指针是指两个指针以不同的速度或步长在同一个方向上移动,通常用于解决链表中的问题,比如判断链表是否有环,找到链表的中点或倒数第k个结点等。
- 对撞指针是指两个指针从相反的方向上移动,直到相遇或满足某个条件为止,通常用于解决数组或字符串中的问题,比如寻找两数之和等于目标值的下标,判断一个字符串是否是回文串等。
- 模板
// 双指针模板
bool check(int i, int j);void two_pointer()
{int n;for (int i = 0, j = 0; i < n; ++i){while (j <= i && check(i, j)){// ......j++;// ......}// .....}
}
- 最长连续不重复子序列

🍬题目链接:最长连续不重复子序列
#include <iostream>using namespace std;const int N = 100010; int v[N]; // 存储输入的数组
int book[N];//判重数组,用于记录每个数字出现的次数int main()
{ int n; // 数组的长度 cin >> n; for (int i = 0; i < n; ++i) cin >> v[i]; int Max = 0; // 记录最长不重复子数组的长度for (int i = 0, j = 0; i < n; ++i) // i和j是两个指针,分别指向子数组的右端点和左端点{book[v[i]]++; // 将当前数字的计数加一// 当有重复数字时while (j <= i && book[v[i]] > 1) // 如果当前数字出现了两次以上,说明子数组中有重复元素,需要缩小左边界{// j指向的数字计数--,并且j++,直到数组中没有重复数字book[v[j]]--;j++;}Max = max(Max, i - j + 1); // 更新最长不重复子数组的长度}cout << Max << endl; // 输出结果return 0;
}
- 数组元素目标和

🍬题目链接:数组元素的目标和
#include <iostream>using namespace std;const int N = 100010;int v1[N]; // 存储第一个有序数组
int v2[N]; // 存储第二个有序数组int main()
{ int n, m, t; // n和m分别是两个数组的长度,t是目标值 cin >> n >> m >> t; for (int i = 0; i < n; ++i) cin >> v1[i]; for (int i = 0; i < m; ++i) cin >> v2[i];int i = 0, j = m - 1; // i和j是两个指针,分别指向第一个数组的左端点和第二个数组的右端点while (i < n && j >= 0) // 当两个指针没有越界时{if (v1[i] + v2[j] == t) // 如果两个指针指向的数字之和等于目标值,输出下标对,并将左指针右移{cout << i << " " << j << endl;i++;}else if (v1[i] + v2[j] > t) // 如果两个指针指向的数字之和大于目标值,说明右边的数字太大,需要将右指针左移j--;else // 如果两个指针指向的数字之和小于目标值,说明左边的数字太小,需要将左指针右移i++;}return 0;
}
七、位运算
- 获取n的二进制表示中第k位(最低位从0开始)
int n;
int k;
int bitk = n >> k & 1;
- 获取n的二进制表示中最右边的1
// lowbit:获取n的二进制表示中最右边的1,eg. 输入 10010 返回 00010
int rightbit1 = n & -n; // 等价于 n & (~n + 1)
- 二进制中1的个数

🍬题目链接:二进制中1的个数
#include <iostream>using namespace std;const int N = 1e5 + 10;
int v[N];int main()
{int n;cin >> n;for (int i = 0; i < n; ++i)cin >> v[i];for (int i = 0; i < n; ++i){int num = v[i];int cnt = 0;while (num){int x = num & -num; // lowbitcnt++;num ^= x; // 去除最后一个1}cout << cnt << " ";}cout << endl;return 0;
}
八、离散化
- 离散化定义
整数保序离散化
将数据范围很大,但是数字个数很少的数据按照升序对数字坐标进行映射
如,数据范围 10^9 数字个数 10^5 1 200000 88888888 1e9
将上述数据映射到 0 1 2 3
简而言之,就是一种哈希
- 区间和

🍬题目链接:区间和
// 区间和// 原版
#include <iostream>
#include <vector>
#include <algorithm>using namespace std;const int N = 3 * 1e5 + 1;vector<int> alls; // 存放所有坐标,将其离散化
vector<pair<int, int>> operates; // 所有操作
vector<pair<int, int>> query; // 所有查询int Hash[N]; // 离散化坐标对应的值
int psum[N]; // 前缀和数组// 以原坐标值查询映射后的坐标值
int find(int x)
{// 二分查找int l = 0, r = alls.size() - 1;while (l < r){int mid = l + r >> 1;if (alls[mid] >= x)r = mid;elsel = mid + 1;}return l + 1;
}int main()
{int n, m;cin >> n >> m;for (int i = 0; i < n; ++i){int x, c;cin >> x >> c;operates.emplace_back(x, c);alls.push_back(x);}for (int i = 0; i < m; ++i){int l, r;cin >> l >> r;query.emplace_back(l, r);alls.push_back(l);alls.push_back(r);}sort(alls.begin(), alls.end()); // 坐标排序alls.erase(unique(alls.begin(), alls.end()), alls.end());// 去重,去除重复坐标for (int i = 0; i < n; ++i){// 由于前缀和数组的下标要从1开始,所有,所有映射坐标+1int x = find(operates[i].first), c = operates[i].second;Hash[x] += c;}// 构造前缀和数组for (int i = 1; i <= alls.size(); ++i)psum[i] = psum[i - 1] + Hash[i];for (int i = 0; i < m; ++i){int l = find(query[i].first), r = find(query[i].second);cout << psum[r] - psum[l - 1] << endl;}return 0;
}
九、区间合并
- 区间合并
区间合并算法是一种用于把给定的、可以合并的区间合并的算法。它的基本思想是:
- 将所有区间按照左边界值进行从小到大排序。
- 遍历所有区间,如果第
i+1区间的左边界值比第i区间的右边界值小,即可合并,更新i+1区间的边界值,并且将第i区间打上标记表示该区间被i+1合并过。- 最后输出没有被标记过的区间,即为合并后的结果。

🍬题目链接:区间合并
#include <iostream>
#include <vector>
#include <algorithm>using namespace std;typedef pair<int, int> PII;
vector<PII> v;int main()
{int n;cin >> n;for (int i = 0; i < n; ++i){int l, r;cin >> l >> r;v.emplace_back(l, r);}sort(v.begin(), v.end());int l = -2e9, r = -2e9; // 初始化变量 l 和 r 的值为 -2e9int cnt = 0; // 初始化计数器 cnt 的值为 0for (auto& e : v) // 遍历 vector 中的每个元素 e{int nl = e.first, nr = e.second; if (nl > r) // 如果新区间与当前区间不相交{cnt++; // 区间计数器加一l = nl; }r = max(nr, r); // 更新当前区间右端点}cout << cnt << endl;return 0;
}
后记
在这篇文章中,我们介绍了算法基础的一些概念和方法,包括算法的定义、特征、分类、设计和分析等。我们也通过一些例子展示了如何运用算法解决实际问题,并且分析了算法的效率和优化。我们希望这篇文章能够给你提供一个对算法基础的初步认识和兴趣,让你感受到算法的魅力和价值。

如果解析有不对之处还请指正,我会尽快修改,多谢大家的包容。
如果大家喜欢这个系列,还请大家多多支持啦😋!
如果这篇文章有帮到你,还请给我一个大拇指 👍和小星星 ⭐️支持一下白晨吧!喜欢白晨【算法】系列的话,不如关注👀白晨,以便看到最新更新哟!!!
我是不太能熬夜的白晨,我们下篇文章见。
相关文章:
【算法】算法基础入门详解:轻松理解和运用基础算法
😀大家好,我是白晨,一个不是很能熬夜😫,但是也想日更的人✈。如果喜欢这篇文章,点个赞👍,关注一下👀白晨吧!你的支持就是我最大的动力!Ǵ…...
2.9.1 Packet Tracer - Basic Switch and End Device Configuration(作业)
Packet Tracer - 交换机和终端设备的基本 配置地址分配表目标使用命令行界面 (CLI),在两台思科互联网络 操作系统 (IOS) 交换机上配置主机名和 IP 地址。使用思科 IOS 命令指定或限制对设备 配置的访问。使用 IOS 命令来保存当前的运行配置。配置两台主机设备的 IP …...
)
AtCoder Beginner Contest 216(F)
F - Max Sum Counting 链接: F - Max Sum Counting 题意 两个 大小为 nnn 的序列 aiaiai 和 bibibi,任意选取一些下标 iii,求 max(ai)>∑bi\max(ai) > \sum{bi}max(ai)>∑bi的方案数。 解析 首先考虑状态 一是和,…...

每天学一点之Stream流相关操作
StreamAPI 一、Stream特点 Stream是数据渠道,用于操作数据源(集合、数组等)所生成的元素序列。“集合讲的是数据,负责存储数据,Stream流讲的是计算,负责处理数据!” 注意: ①Str…...

MatCap模拟光照效果实现
大家好,我是阿赵 之前介绍过各种光照模型的实现方法。那些光照模型的实现虽然有算法上的不同,但基本上都是灯光方向和法线方向的计算得出的明暗结果。 下面介绍一种叫做MatCap的模拟光照效果,这种方式计算非常简单,脱离灯光的计算…...

二十一、PG管理
一、 PG异常状态说明 1、 PG状态介绍 可以通过ceph pg stat命令查看PG当前状态,健康状态为“active clean” [rootrbd01 ~]# ceph pg stat 192 pgs: 192 activeclean; 1.3 KiB data, 64 MiB used, 114 GiB / 120 GiB avail; 85 B/s rd, 0 op/s2、pg常见状态 状…...

SAPUI5开发01_01-Installing Eclipse
1.0 简要要求概述: 本节您将安装SAPUI 5,以及如何在Eclipse Juno中集成SAPUI 5工具。 1.1 安装JDK JDK 是一种用于构建在 Java 平台上发布的应用程序、Applet 和组件的开发环境,即编写 Java 程序必须使用 JDK,它提供了编译和运行 Java 程序的环境。 在安装 JDK 之前,首…...
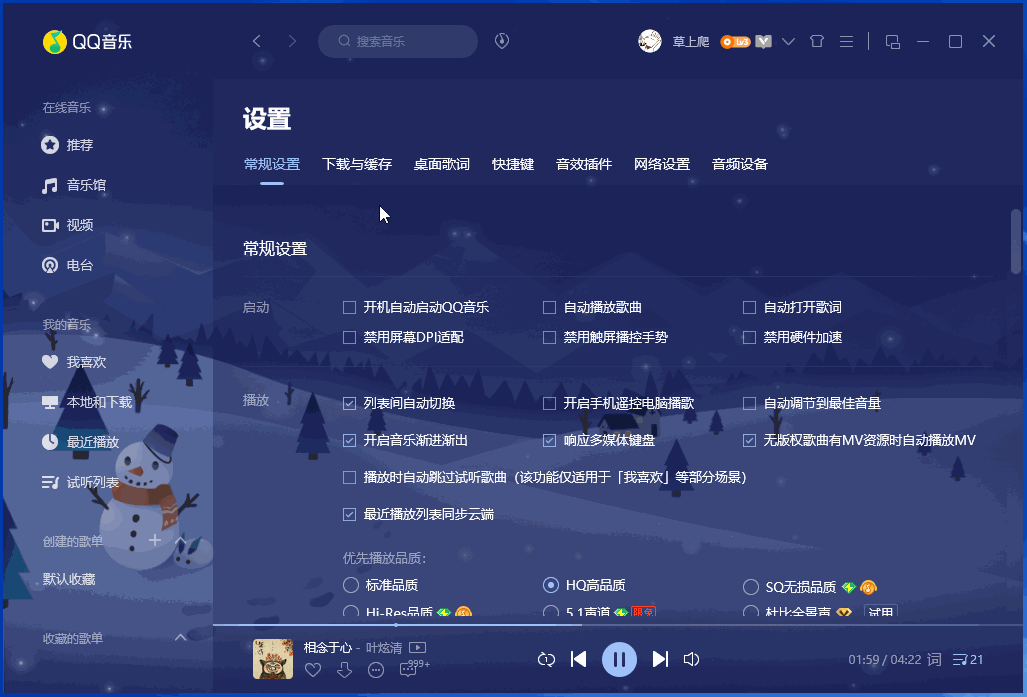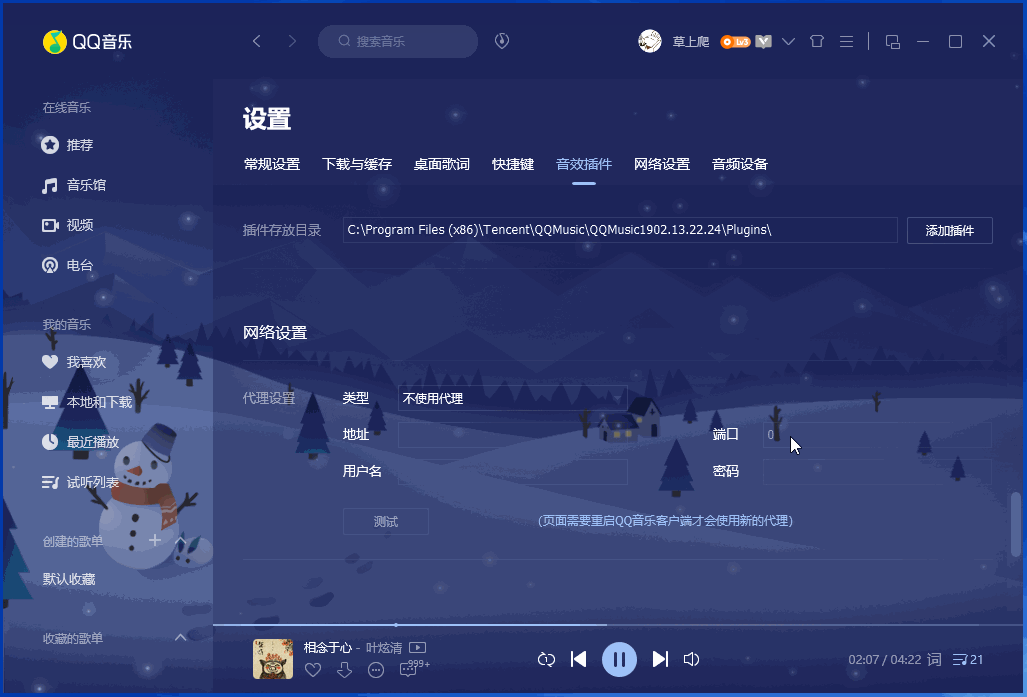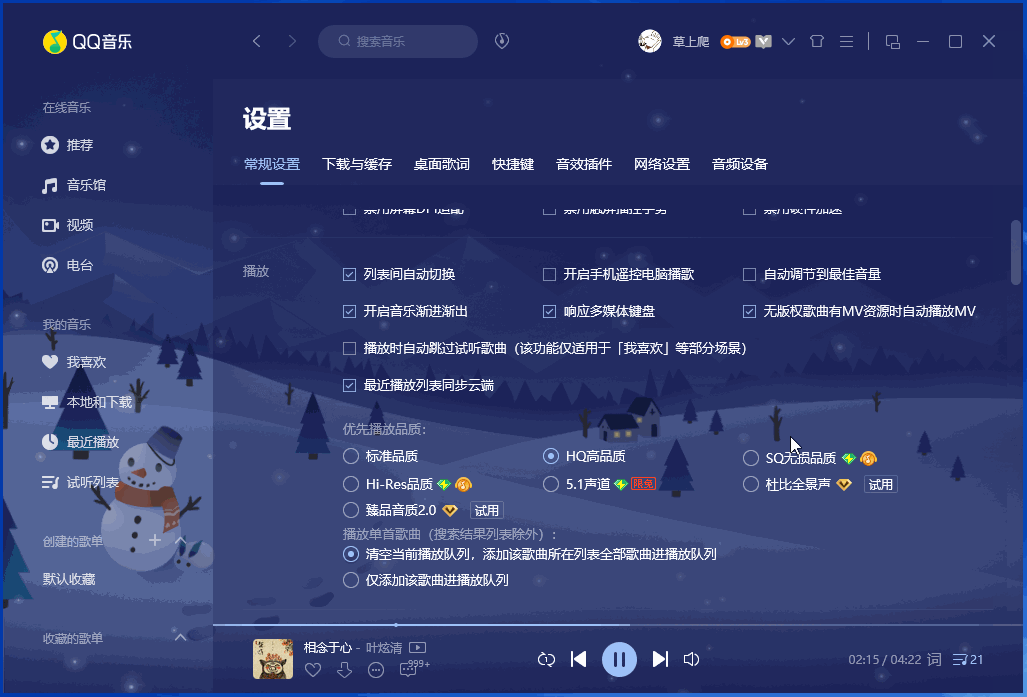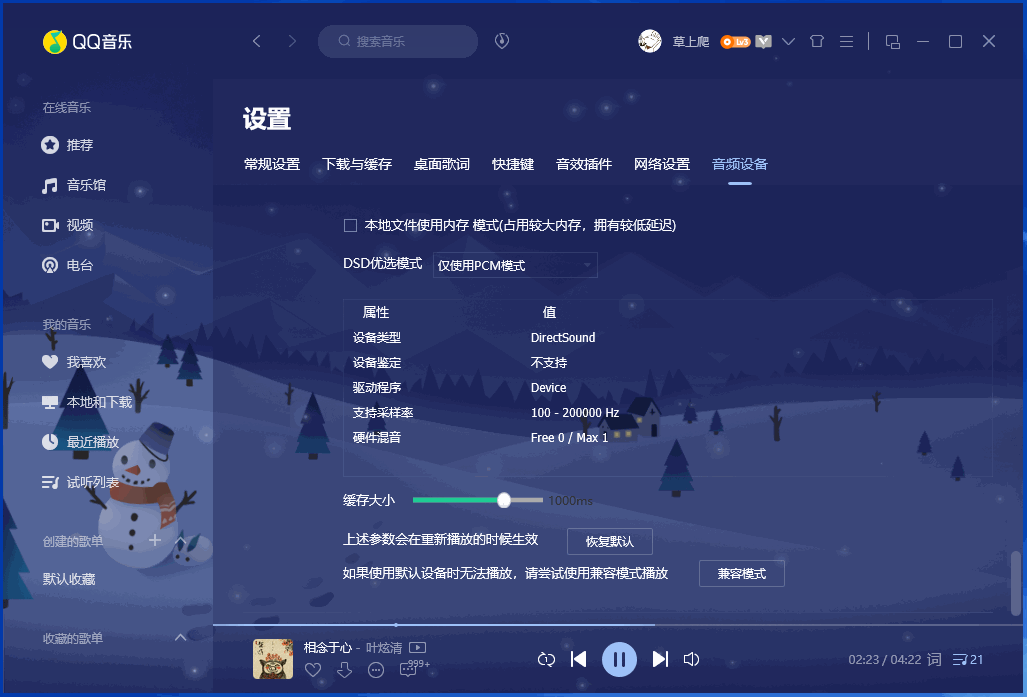
Qt之高仿QQ系统设置界面
QQ或360安全卫士的设置界面都是非常有特点的,所有的配置项都在一个垂直的ScrollArea中,但是又能通过左侧的导航栏点击定位。这样做的好处是既方便查看指定配置项,又方便查看所有配置项。 一.效果 下面左边是当前最新版QQ的系统设置界面,右边是我的高仿版本,几乎一毛一样…...

JVM概览:内存空间与数据存储
核心的五个部分虚拟机栈:局部变量中基础类型数据、对象的引用存储的位置,线程独立的。堆:大量运行时对象都在这个区域存储,线程共享的。方法区:存储运行时代码、类变量、常量池、构造器等信息,线程共享。程…...
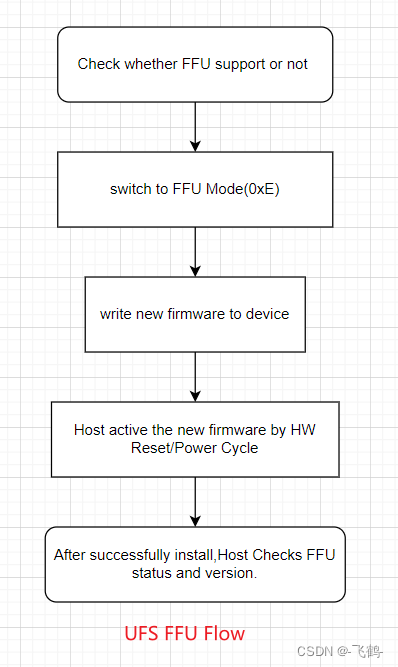
固态存储设备固件升级方案
1. 前言 随着数字化时代的发展,数字数据的量越来越大,相应的数据存储的需求也越来越大,存储设备产业也是蓬勃发展。存储设备产业中,发展最为迅猛的则是固态存储(Solid State Storage,SSS)。数字化时代,海量…...
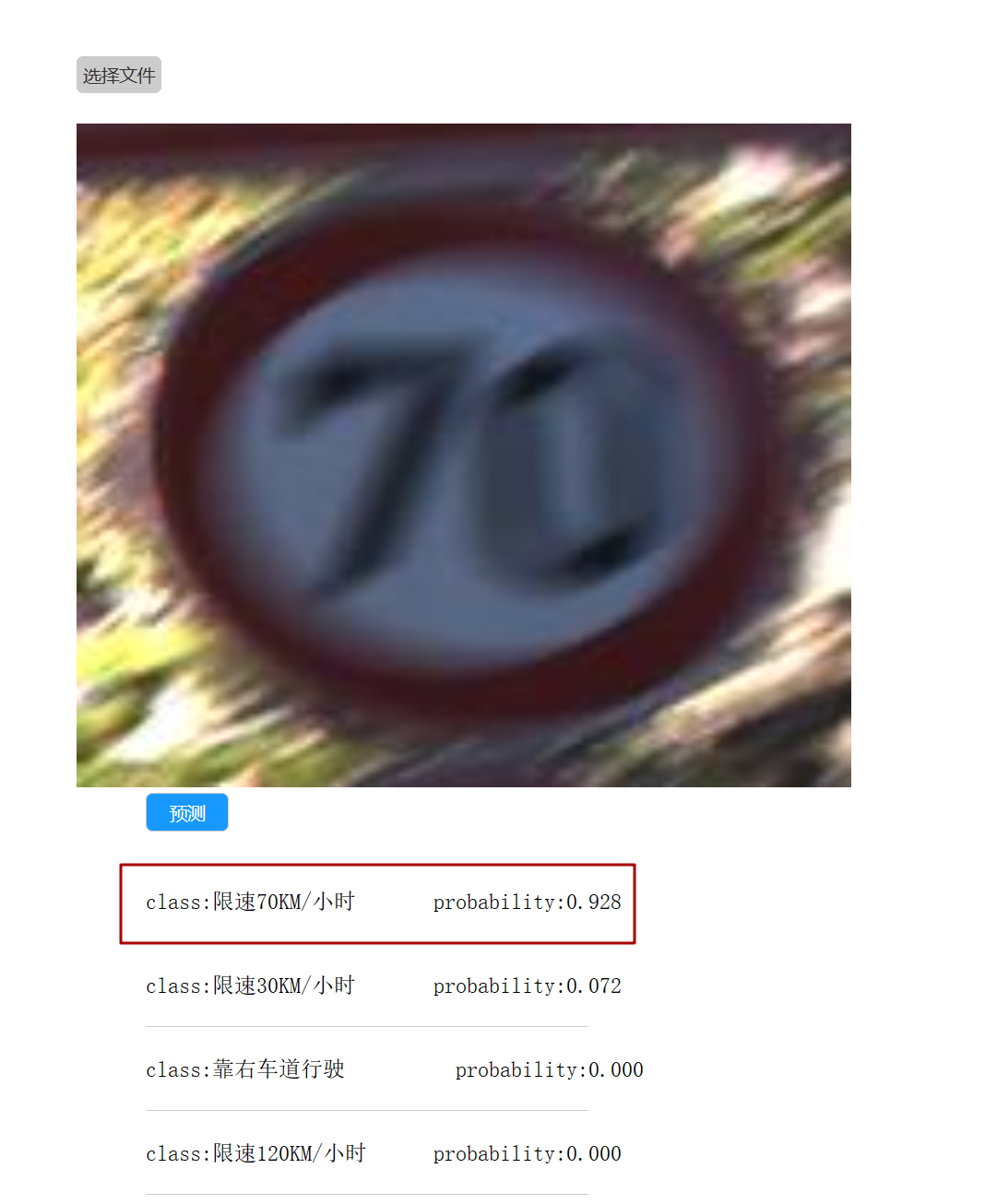
Python交通标志识别基于卷积神经网络的保姆级教程(Tensorflow)
项目介绍 TensorFlow2.X 搭建卷积神经网络(CNN),实现交通标志识别。搭建的卷积神经网络是类似VGG的结构(卷积层与池化层反复堆叠,然后经过全连接层,最后用softmax映射为每个类别的概率,概率最大的即为识别…...

基于Selenium+Python的web自动化测试框架(附框架源码+项目实战)
目录 一、什么是Selenium? 二、自动化测试框架 三、自动化框架的设计和实现 四、需要改进的模块 五、总结 总结感谢每一个认真阅读我文章的人!!! 重点:配套学习资料和视频教学 一、什么是Selenium? …...

Python进阶-----高阶函数zip() 函数
目录 前言: zip() 函数简介 运作过程: 应用实例 1.有序序列结合 2.无序序列结合 3.长度不统一的情况 前言: 家人们,看到标题应该都不陌生了吧,我们都知道压缩包文件的后缀就是zip的,当然还有r…...

win10打印机拒绝访问解决方法
一直以来,在安装使用共享打印机打印一些文件的时候,会遇到错误提示:“无法访问.你可能没有权限使用网络资源。请与这台服务器的管理员联系”的问题,那为什么共享打印机拒绝访问呢?别着急,下面为大家带来相关的解决方法…...

深度学习训练营之数据增强
深度学习训练营学习内容原文链接环境介绍前置工作设置GPU加载数据创建测试集数据类型查看以及数据归一化数据增强操作使用嵌入model的方法进行数据增强模型训练结果可视化自定义数据增强查看数据增强后的图片学习内容 在深度学习当中,由于准备数据集本身是一件十分复杂的过程,…...
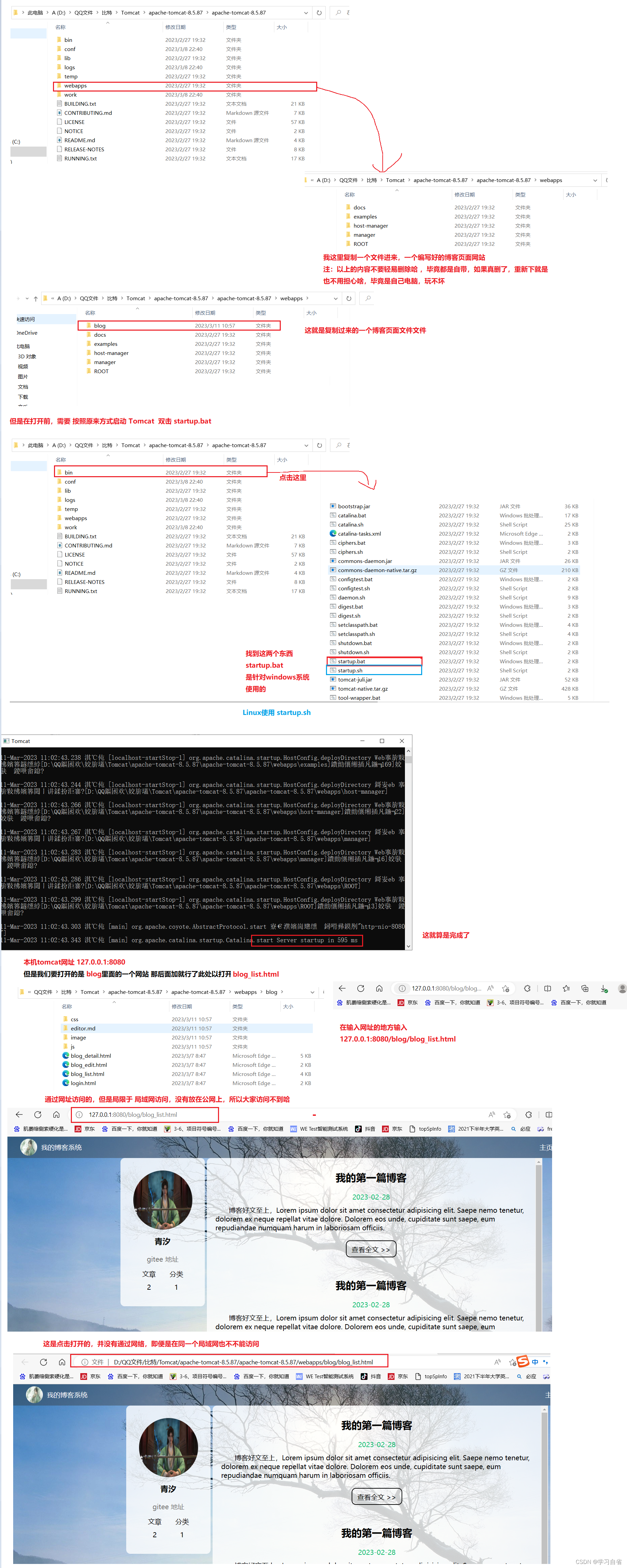
Tomcat安装及启动
日升时奋斗,日落时自省 目录 1、Tomcat下载 2、JDK安装及配置环境 3、Tomcat配置环境 4、启动Tomcat 5、部署演示 1、Tomcat下载 直接入主题,下载Tomcat 首先就是别下错了,直接找官方如何看是不是广告,或者造假 搜索Tomc…...

【专项训练】排序算法
排序算法 非比较类的排序,基本上就是放在一个数组里面,统计每个数出现的次序 最重要的排序是比较类排序! O(nlogn)的3个排序,必须要会!即:堆排序、快速排序、归并排序! 快速排序:分治 经典快排 def quickSort1(arr...

Android压测测试事件行为参数对照表
执行参数参数说明颗粒度指标基础参数--throttle <ms> 用于指定用户操作间的时延。 -s 随机数种子,用于指定伪随机数生成器的seed值,如果seed值相同,则产生的时间序列也相同。多用于重测、复现问题。 -v 指定输出日志的级别,…...

【观察】亚信科技:“飞轮效应”背后的数智化创新“延长线”
著名管理学家吉姆柯林斯在《从优秀到卓越》一书中提出“飞轮效应”,它指的是为了使静止的飞轮转动起来,一开始必须使很大的力气,每转一圈都很费力,但达到某一临界点后,飞轮的重力和冲力就会成为推动力的一部分…...

QT编程从入门到精通之十四:“第五章:Qt GUI应用程序设计”之“5.1 UI文件设计与运行机制”之“5.1.1 项目文件组成”
目录 第五章:Qt GUI应用程序设计 5.1 UI文件设计与运行机制 5.1.1 项目文件组成 第五章:Qt GUI应用程序设计...
(orm方式))
python访问sqlite(sqlalchemy)(orm方式)
文章目录sqlalchemy的理解Base declarative_base()的作用?__repr__方法查询db.query()并不是查询,query.count()和query.offset()才是查询?查询-拼接条件分组关联查询新增修改删除安装依赖开始接触sqlalchemy不太习惯,感觉有点抽象。后来换个视角瞬间…...

QtScrcpy安卓投屏终极指南:从零基础到精通应用的完整教程
QtScrcpy安卓投屏终极指南:从零基础到精通应用的完整教程 【免费下载链接】QtScrcpy Android实时投屏软件,此应用程序提供USB(或通过TCP/IP)连接的Android设备的显示和控制。它不需要任何root访问权限 项目地址: https://gitcode.com/barry-ran/QtScrc…...

Cursor AI助手Pro功能破解技术深度解析:三重防护机制与实战指南
Cursor AI助手Pro功能破解技术深度解析:三重防护机制与实战指南 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached…...

专业指南:Anno 1800 Mod Loader完整使用教程与架构解析
专业指南:Anno 1800 Mod Loader完整使用教程与架构解析 【免费下载链接】anno1800-mod-loader The one and only mod loader for Anno 1800, supports loading of unpacked RDA files, XML merging and Python mods. 项目地址: https://gitcode.com/gh_mirrors/an…...

Next.js企业级开发样板Next-Enterprise:一站式集成最佳实践与工具链
1. 项目概述:为什么说 Next-Enterprise 是 Next.js 企业级开发的“瑞士军刀”? 如果你正在用 Next.js 构建一个中大型、对代码质量和开发体验有要求的企业级应用,那你大概率遇到过这些头疼事:项目初始化配置繁琐,得花…...

极域电子教室破解终极指南:如何在机房环境中重获电脑控制权
极域电子教室破解终极指南:如何在机房环境中重获电脑控制权 【免费下载链接】JiYuTrainer 极域电子教室防控制软件, StudenMain.exe 破解 项目地址: https://gitcode.com/gh_mirrors/ji/JiYuTrainer 你是否曾在学校机房被极域电子教室的全屏广播困住…...

从零上手CircuitJS1:开源电路仿真工具的核心功能与实战演练
1. 初识CircuitJS1:浏览器里的电子实验室 第一次打开CircuitJS1时,我仿佛回到了大学电子实验室——只不过这次所有仪器都装进了浏览器窗口。这个完全开源的工具用JavaScript重构了经典的Falstad电路模拟器,不需要安装任何插件就能在Chrome或…...

【Arcgis实战技巧】巧用DOM目视解译,从DSM中精准“挖”出地面高程点
1. 为什么需要从DSM中提取地面高程点? 在测绘和地理信息领域,数字表面模型(DSM)记录了地表所有物体的顶部高程信息,包括建筑物、树木、电线杆等。但很多时候我们需要的是数字高程模型(DEM)&…...

不只是显示中文:用fbterm给你的CentOS终端换个‘皮肤’,提升老旧服务器运维效率
终端美学革命:用fbterm打造高效CentOS字符界面工作环境 在服务器运维的世界里,图形界面往往被视为奢侈品。当您面对一台资源受限的老旧CentOS服务器,或者需要远程管理没有X11支持的机器时,字符界面就成了唯一的选择。但单调的终端…...

FPGA硬件在环验证:GateRocket方案加速系统级调试
1. 项目概述:为什么FPGA验证需要“硬件在环”?在FPGA设计领域,尤其是当项目规模膨胀到数百万甚至上千万门级时,纯软件仿真(Simulation)会变成一个令人头疼的瓶颈。想象一下,你写了一段新的RTL代…...