C语言第17篇:预处理详解
1、预定义符号
C语言设置了一些预定义符号,可以直接使用。预定义符号也是在预处理期间处理的。
__FILE__ //进行编译的源文件
__LINE__ //文件当前的行号
__DATE__ //文件被编译的日期
__TIME__ //文件被编译的时间
__STDC__ //如果编译器遵循ANSI C,其值为1, 否则未定义举个例子:
#include <stdio.h>
int main()
{printf("进行编译的源文件:%s\n", __FILE__);printf("当前文件的行号:%d\n", __LINE__);printf("当前文件编译日期:%s\n", __DATE__);printf("当前文件编译时间:%s\n", __TIME__);return 0;
}运行:

__STDE__只有在编译器遵循ANSI C时才为1,但是VS使用该标识符是未定义的,说明VS并不支持ANSI C

2、#define 定义常量
基本语法:
#define name stuff举个例子:
#define MAX 1000
#define reg register //为register这个关键字,创建一个简短的名字
#define do_forerer for(;;) //定义一个死循环的for,使用这个标识符时会一直死循环
#define CASE break;case //在写case语句的时候启动把break写上
//如果定义的stuff过长,可以分成几行写,除了最后一行外,每行的后面都加一个反斜杠(续航符)
#define DEBUG_PRINT printf("file:%s\tline:%d\t \date:%s\ttime:%s\n", \__FILE__, __LINE__, \__DATE__, __TIME__)思考:在define定义标识符的时候,要不要在最后加上;?
比如:
#define MAX 1000;
#define MAX 1000建议不要加上;,这样容易导致问题
比如下面场景:
if(condition)max = MAX;
elsemax = 0;如果是加上了分号的情况,等替换后,if和else之间就是2条语句,而没有大括号的时候,if后边只能有一条语句。这里会出现语法错误。
替换后
if(condition)
max = 1000;;
else
max = 0;因为1000后面多出了一个;,而多出的这个;会被当做一条空语句,看似一条语句,实则两条语句,所以使用时一定要注意#define定义的标识符后面尽量不加分号。
总结:#define定义标识符的后面的可以是常量、字符、浮点数、字符串、关键字或一段代码等...
3、#define定义宏
define不止可以定义常量,还可以定义宏。
#define机制包括了一个规定,允许把参数替换到文本中,这种实现通常称为宏(macro)或定义宏(define macro)。
下面是宏的申明方式:
#define name(parament-list) stuff其中的parament-list是一个由逗号隔开的符号表,它们可能出现在stuff中。
注意:
参数列表的左括号必须与name紧邻,如果两者之间有任何空白存在,参数列表就会被解释为stuff的一部分。
那宏怎么使用呢?举个例子:
#include <stdio.h>
#define SQAURE(X) X*X//假设我要计算一个数的平方而使用define定义一个宏
int main()
{int a = 5;printf("%d\n", SQAURE(a));//传一个参数过去当经过预处理阶段时会替换成我们定义的表达式return 0;
}这样来看是不是感觉宏和函数的使用方式有一些相似。
其实宏的计算和函数有点不一样的是将参数传给宏,并不是在宏里完成表达式计算返回值,而是在预处理阶段将调用宏的地方替换成宏定义的表达式。
例如:
#include <stdio.h>
int main()
{int a = 5;printf("%d\n", a*a);//预处理阶段,展开#define定义并替换return 0;
}警告:
这个宏存在一个问题:
观察下面的代码段:
#include <stdio.h>
#define SQAURE(X) X*X//假设我要计算一个数的平方而使用define定义一个宏
int main()
{int a = 5;printf("%d\n", SQAURE(a+2));//传一个参数过去当经过预处理阶段时会替换成我们定义的表达式return 0;
}我们想象的结果是a+2也就是7的开平方49,实际上结果是17,为什么?
因为我们给宏传参传表达式并不是计算完成后在计算宏,而是在预处理阶段直接将我们传参的表达式替换到宏定义的表达式。
例如:
#include <stdio.h>
int main()
{int a = 5;printf("%d\n", 7*7);//我们想象的printf("%d\n",a+2*a+2);//预处理阶段实际做的return 0;
}解决方法:所以我们使用宏时一定要注意,当定义宏的表达式时一定要用括号将表达式中的参数单个括起来,说不定这个参数本身也是一个表达式。
比如:
#include <stdio.h>
#define SQAURE(X) ((X)+(X))//宏的整体也括一下
//因为调用宏的位置说不定是在某表达式中调用,因为操作符优先级导致计算顺序并不能达到我们的预期
int main()
{int a = 5;printf("%d\n", 2*SQAURE(a+2));printf("%d\n",2*((a+2)+(a+2)));//预处理阶段替换return 0;
}记得把宏定义表达式整体也括一下,这样才能保证先运算宏定义的表达式。
4、带有副作用的宏参数
当宏参数在宏的定义中出现超过一次的时候,如果参数带有副作用,那么你在使用这个宏的时候就可能出现危险,导致不可预测的后果。副作用表达式求值的时候出现的永久性效果。
例如:
x+1; //不带副作用
x++; //带副作用什么是带有副作用的表达式呢?就是我想解决一件问题,但却因此留下了另一个问题。就比如我感冒了,我开了点感冒药。吃完感冒药后感冒是好了但是胃又因此不舒服了,这就是副作用。
例如:
#include <stdio.h>
int main()
{int a = 10;int b = ++a;//我想得到a+1的值11,使用++a是得到了11但是因此a也发生了改变printf("a=%d b=%d\n", a, b);//结果:11,11return 0;
}这就是带有副作用的表达式。
那如果宏参数是带有副作用的表达式会发生什么呢?
举个例子:
#include <stdio.h>
#define MAX(a, b) ((a)>(b)?(a):(b));
int main()
{int a = 15;int b = 9;int m = MAX(a++,b++);printf("m=%d\n", m);printf("a=%d b=%d\n", a, b);//再猜一下a和b的值是多少return 0;
}最后的结果是什么呢?
运行结果:m=16, a=17, b = 10
为什么?看下面解析:
#include <stdio.h>
int main()
{int a = 15;int b = 9;int m = ((a++)>(b++)?(a++):(b++));//预处理替换后printf("m=%d\n", m);printf("a=%d b=%d\n", a, b);return 0;
}代码解析:首先判断(a++)>(b++),此时是转换成15>9来进行判断的,因为先使用后++,当15>9成立,该表达式就返回a++,此时a是16,因为先使用后++就先返回16,m就拿到了16,所以m=16,然后a++就是17,前后a++了两次,b++了一次,所以a=17, b=10
总结:
1、宏的参数是如果是表达式,不会计算的。和函数相反,函数是先将表达式参数进行运算,将运算结果作为参数传参。
2、宏是直接将参数原封不动的替换到宏定义的表达式中的。
宏的参数是不参与计算的,当我们给宏的参数传递一个表达式时,并不是将表达式计算结果进行计算,而是在预处理阶段直接将表达式参数替换到宏定义的表达式,然后再替换到调用宏的位置。
5、宏的替换规则
在程序中扩展#define定义符号和宏是,需要涉及几个步骤。
1. 在调用宏时,首先对参数进行检查,看看是否包含任何由#define定义的符号,如果是,它们首先被替换。
2. 替换文本后被插入到程序中原来文本的位置,对于宏,参数名被他们的值所替换。
3. 最后,再次对结果文件进行扫描,看看它是否包含任何由#define的符号。如果是,就重复上述处理过程。
注意:
1. 宏参数和#define定义中出现其他#define定义的符号。但是对于宏,不能出现递归。
2. 当预处理器搜索#define定义的符号的时候,字符串常量的内容并不被搜索。
6、宏和函数的对比
宏通常被应用于执行简单的运算。
比如在两个数中找出较大的一个时,写成下面的宏,更有优势一些。
#define MAX(a, b) ((a)>(b)?(a):(b))那为什么不用函数来完成这个任务呢?
原因有二:
1. 用于调用函数和从函数返回的代码可能比实际指向这个小型计算工作所需要的时间更多。所以宏比函数在程序的规模和所读方面更胜一筹。
2. 更为重要的是函数的参数必须声明为特定的类型。所以函数只能在类型合适的表达式上使用。反之这个宏可以适用于整型、长整型、浮点型等可以用于>来比较的类型。宏是类型无关的。
和函数相比宏的劣势:
1. 每次使用宏的时候,一份宏定义的代码将插入到程序中。除非宏比较短,否则可能大幅度增加程序的长度。
2. 宏是没法调试的
3. 宏由于类型无关,也就不够严谨。
4. 宏可能会带来运算符优先级的问题,导致容易出现错误。
看到这里感觉函数和宏之间各有千秋,函数有函数的好处,宏有宏的好处,那宏有没有什么事函数做不到的呢?当然有。
宏有时候可以做到函数做不到的事情。比如:宏的参数可以出现类型,但是函数做不到。
#define MALLOC(num, type) \(type*)malloc(num * sizeof(type))
...
//使用
int* a = MALLOC(10,int);//类型作为参数//预处理器替换之后
int* a = (int*)malloc(10 * sizeof(int));宏和函数的一个对比:
| 属性 | #define定义宏 | 函数 |
| 代码长度 | 每次使用时,宏代码都会被插入到程序中。 除非非常小的宏之外,程序的长度会大幅度 增长 | 函数代码只出现于一个地方;每次使用函 数时,都调用那个地方的同一份代码 |
| 执行速度 | 更快 | 存在函数的调用和返回的额外开销,所以 相对慢一些 |
| 操作符优先级 | 宏参数的求值是在所有周围表达式的上下文 环境里,除非加上括号,否则邻近操作符的 优先级可能会产生不可预料的后果,所以建 议宏在书写的时候多写括号 | 函数参数只在函数调用的时候求值一次, 它的结果值传递给函数。表达式的求值 结果更容易预测 |
| 带有副作用的参数 | 参数可能被替换到宏体中的多个为止,如 果宏的参数被多次计算,带有副作用的参数 可能会产生不可预料的结果 | 函数参数只在传参的时候求值一次,结果 更容易控制 |
| 参数类型 | 宏的参数与类型无关,只要对参数的操作是 合法的,他就可以使用任何参数类型 | 函数的参数是与类型有关的,如果参数的 类型不同,就需要不同的函数,即使他们 执行的任务是不同的。 |
| 调试 | 宏是不方便调试的 | 函数是可以逐语句调试的 |
| 递归 | 宏是不可以递归的 | 函数是可以递归的 |
那什么时候该有宏,什么时候该有函数呢?
- 如果计算逻辑比较简单就可以使用宏。
- 如果计算逻辑比较复杂就可以使用函数。
7、#和##
7.1 #运算符
#既不是#include或#define中的#,又不是+、-、*、/中的运算符。#是预处理中的一种运算符。
#运算符将宏的一个参数转换为字符串字面量,它仅允许出现在带参数的宏的替换列表中,#运算符所执行的操作可以理解为"字符串化"。
printf的特性:
这里首先要了解一下printf函数还有一个特性,就是当我们给printf传两个或多个字符串时,printf会自动将它们参数合并成一个字符串并输出,举个例子:
可以看到第二次调用printf将"hello" "world\n",分成两个字符串,可是printf自动将这两个字符串合并成一个。

知道了printf的这个特性我们就可以继续向下学习。
知道了#运算符可以在宏体中将宏的参数转换成字符串,我们就可以写下面这样代码:
#include <stdio.h>
#define Print(n, format)\printf("the value of " #n " is " format "\n", n)
int main()
{char c = 'a';Print(c, "%c");printf("the value of" "c" "is" "%c" "\n", c);//预处理阶段替换后int n = 10;Print(n, "%d");printf("the value of" "n" "is" "%d" "\n", n);//预处理阶段替换后float f = 3.14f;Print(f, "%f");printf("the value of" "f" "is" "%f" "\n", f);//预处理阶段替换后return 0;
}运行结果:

因为#运算符修饰的参数本来就是"字符串化",如果n是变量c那#n就"c",如果n是变量a,那#n就是"a",如果n是变量f,那#n就是"f",所以"#n"经过预处理阶段就会替换为" "a" ",所以不需要再"#n"的套一层字符串。
7.2 ## 运算符
## 可以把位于它两边的符号合成一个符号,它允许宏定义从分离的文本片段创建标识符,## 被称为记号粘合这样的连接必须产生一个合法的标识符,否则器结果就是未定义的。
这里我们想想,写一个函数求2个数的较大值的时候,不同的数据类型就得写不同的函数。
比如:
int int_max(int x, int y)
{return x>y?x:y;
}float float_max(int x, int y)
{return x>y?x:y;
}但是这样写起来太繁琐了,现在我们这样写代码试试:
//宏定义
#define GENERIC_MAX(type) \
type type##_max(type x, type y)\
{ \return (x>y?x:y); \
} \使用宏,定义不同类型
//预处理前的程序格式
#define GENERIC_MAX(type)\
type type##_max(type x, type y)\
{\
return (x>y?x:y);\
}
//下面两行代码是使用宏定义两个自定义函数
GENERIC_MAX(int)
GENERIC_MAX(float)
int main()
{int a = 10;int b = 20;int ret = int_max(a, b);printf("%d\n", ret);float c = 11.1f;float d = 22.2f;float fret = float_max(c, d);printf("%.2f\n", fret);return 0;
}//预处理后的程序格式
int int_max(int x, int y)
{return (x>y?x:y);
}
float float_max(float x, float y)
{return (x>y?x:y);
}
int main()
{int a = 10;int b = 20;int ret = int_max(a, b);printf("%d\n", ret);float c = 11.1f;float d = 22.2f;float fret = float_max(c, d);printf("%.2f\n", fret);return 0;
}8、命名约定
一般来讲函数和宏的使用语法很相似。所以语言本身没法帮我们区分二者
那我们平时的一个习惯是:
把宏名全部大写
函数名不用全部大写
9、#undef
这条指令又能与移除一个#define的标识符定义或宏定义
#undef NAME
//如果现存的一个名字需要被重新定义,那么它的就名字首先要被移除#undef的使用:
#define M 100
int main()
{int a = M;//a = 100//当想使用M这个标识符名字重新定义
#undef M//移除标识符M的定义
#define M 200int b = M;//b = 200printf("a=%d b=%d\n", a, b);return 0;
}10、命令行定义
许多C 的编译器提供了一种能力,允许在命令行中定义符号。用于启动编译过程。
例如:当我们根据同一个源文件要编译出一个程序的不同版本的时候,这个特性有点用处(假设某个程序中声明了一个某个长度的数组,如果机器内存有限,我们需要一个很小的数组,但是另一个机器内存大些,我们需要一个数组能够大些)
注:VS是不支持命令行定义的,只能在gcc下观察。
#include <stdio.h>
int main()
{int array[ARRAY_SIZE];//ARRAY_SIZE可以在源文件中定义,也可以在命令行中输入命令来定义int i = 0;for (i = 0; i < ARRAY_SIZE; i++){array[i] = i;}for (i = 0; i < ARRAY_SIZE; i++){printf("%d ", array[i]);}return 0;
}编译指令:
//Linux 环境演示
gcc -D ARRAY_SIZE 10 programe.c//-D是定义命令,后面定义一个标识符,再在标识符后面输入一个值//ARRAY_SIZE是标识符 100是标识符的常量//programe.c是当前源文件的文件名11、条件编译
在编译一个程序的时候我们如果要将一条语句(一组语句)编译或者放弃是很方便的。因为我们有条件编译指令。
注:条件编译后的只能是常量或常量表达式来进行判断,不能使用变量来进行判断。
比如说:
调试性的代码,删除可惜,保留又碍事,所以我们可以选择性的编译。
满足条件,就编译
不满足条件,就放弃编译
常见的条件编译指令:
1.条件编译
#if 常量表达式//...
#endif
//常量表达式由预处理器求值
如:
#define __DEBUG__ 1
#if __DEBUG__//...
#endif2.多个分支的条件编译
#if 常量表达式//...
#elif 常量表达式//...
#else//...
#endif3.判断是否被定义
#if defined(symbol)
#ifdef symbol#if !defined(symbol)
#ifndef symbol4.嵌套指令
#if defined(OS_UNIX)#ifdef OPTION1unix_version_option1();#endif#ifdef OPTION2unix_version_option2();#endif
#elif defined(OS_MSDOS)#ifdef OPTION2msdos_version_option2();#endif
#endif11.1 条件编译
那我们是怎么使用的呢?看下面代码:
#include <stdio.h>
#define flag 1
int main()
{
//flag = 1
#if flagprintf("hello world---1\n");
#endif
//!flag = 0
#if !flag printf("hello world---2\n");
#endifreturn 0;
}运行结果:
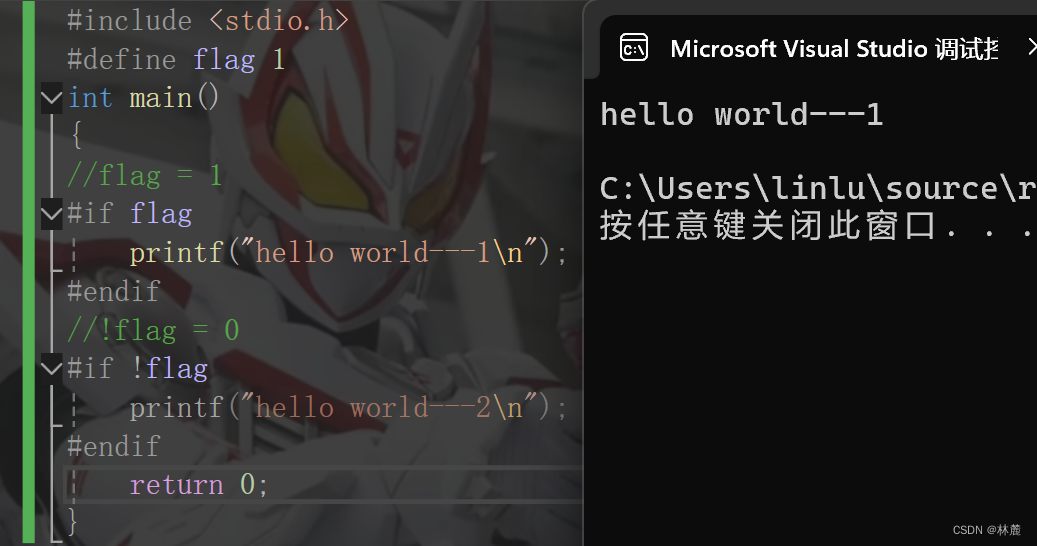
if 和 #if 的区别:
如果if判断为真则执行if中的语句,if为假则不执行if中的语句。
如果#if判断为真预处理阶段就保留#if中的语句,如果为假,则在预处理阶段删除#if中的语句。
所以上面代码经过预处理后是这样的:
int main()
{printf("hello world---1\n");return 0;
}因为只有第一条#if判断为真,所以这条语句被保留了下来,第二条#if判断为假,则删除语句。
注:条件编译完最后记得加上一条#endif来表示条件编译结束。
11.2 多分支条件编译
多分支条件编译不管有多少条编译总归得执行一条,例如:
#include <stdio.h>
#define flag 17
int main()
{#if flag%3 == 1printf("flag取模3的余数为1\n");
#elif flag%3 == 2printf("flag取模3的余数为2\n");
#else printf("flag取模3的余数为0\n");
#endifreturn 0;
}运行结果:

和if、else if、else的使用方法相似,只是功能不一样。
所以这条代码经过预处理后是这个格式:
int main()
{printf("flag取模3的余数为2\n");return 0;
}11.3 判断是否被定义
#ifdef或#if defined()就是判断该标识符符有没有定义,定义了就保留这条语句,未定义就删除语句。而#ifndef或#if !defined()判断该标识符没有定义就保留语句,定义了就删除语句。
#include <stdio.h>
#define MAX 100
int main()
{
#ifdef MAXprintf("MAX标识符已定义\n");
#endif//等价
#if defined(MAX)printf("MAX标识符已定义\n");
#endif//.........#ifndef MAXprintf("MAX标识符未定义\n");
#endif//等价
#if !defined(MAX)printf("MAX标识符未定义\n");
#endifreturn 0;
}运行结果:

所以这条代码经过预处理后是这个格式:
int main()
{printf("MAX标识符已定义\n");return 0;
}12、头文件的包含
12.1 头文件被包含方式
12.1.1 本地文件包含
#include "filename.h"查找策略:先在源文件所在目录下查找,如果该头文件未找到,编译器就像查找库函数头文件一样在标准位置查找头文件。
如果找不到就提示编译错误。
Linux环境的标准头文件路径:
/usr/includeVS环境的标准头文件路径:
c:\Program Files (x86)\Microsoft Visual Studio 12.0\VC\include
//这是VS2013的默认路径注意按照自己的安装路径去找。
12.1.2 库文件包含
#include <filename.h>查找头文件直接去标准路径下去查找,如果找不到就提示编译错误。
那是不是可以说,对于库文件也可以使用" "的形式包含?
#include "stdio.h"答案是肯定的,可以,但是这样查找的效率就低些,当然这样也不容易区分是库文件还是本地文件了。
12.2 嵌套文件包含
我们已经知道,#include 指令可以使另一个文件被编译。就像它实际出现于#include 指令的地方一样。
这种替换的方式很简单:预处理器先删除这条指令,并用包含文件的内容替换。
一个头文件被包含10次,那就实际被编译10次,如果重复包含,对编译的压力就比较大。
test.c源文件
#include "test.h" #include "test.h" #include "test.h" #include "test.h" #include "test.h" int main() {return 0; }test.h头文件
void test(); struct stu {int id;char name[20]; };
如果直接这样写,test.c文件中将test.h包含5次,那么test.h文件的内容将会被拷贝5份在test.c中。
如果test.h文件比较大,这样预处理后代码会剧增。如果工程比较大,有公共使用的头文件,大家
都能使用,如何解决头文件被重复引入的问题呢?答案:条件编译
#ifndef __TEST_H__
#define __TEST_H__
//头文件内容
#endif //__TEST_H__或者
#pragma once就可以避免头文件的重复引入。
注:
推荐《高质量C/C++编程指南》中附录的考试试卷(很重要).
笔试题:
1. 头文件中的 ifndef / define /endif是干什么用的?
答:是用来避免重复头文件重复包含的,ifndef判断标识符是否定义,如果未定义就继续向下编译,知道endif为止。中间使用define定义ifndef所判断的标识符,下一次再包含头文件属于重复包含但是因为第一次包含时顺便定义了该标识符,所以第二次包含时不会通过ifndef,ifndef会在预处理阶段将头文件一下内容删除,不会再被编译进包含该头文件的文件里。
2. #include <filename.h> 和 #include "filename.h"有什么区别?
答:区别是<>所包含的头文件只寻找1次,而" "包含的头文件寻找2次。<>说明包含的头文件是标准库中的头文件,便会直接去标准库中寻找,找不到就编译错误,并不会额外花费时间去本地文件路径找。" "说明包含的头文件是本地文件,会先去本地文件路径下寻找,如果未找到就去标准库找,找了2次。
13、其他预处理指令
#error
#pragma
#line
...
不做介绍,可以自己去了解#pragme pack()在结构体部分介绍过了14、offsetof模拟实现
offsetof是宏定义,参数就给它一个结构体类型,然后再给一个成员名它就可以求出该成员在结构体类型中内存对齐的偏移量。偏移量就是结构体的起始地址和内存对齐后变量的地址之间的距离。单位是:字节(byte)。
假设我们把0作为结构体的起始地址,那其他的成员的地址就是偏移量。有了思路我们就可以模拟offsetof了:
#include <stdio.h>
#define OFFSETOF(type,mem) (size_t)&(((type*)0)->mem)
//假设结构体的地址是0,通过0这个地址->找到成员取地址取出的就是偏移量。
//此时这个取出偏移量还是地址,将这个地址强制类型转换成(size_t)无符号整型。
struct S
{char c1;int i;char c2;
};
int main()
{printf("%d\n", OFFSETOF(struct S, c1));printf("%d\n", OFFSETOF(struct S, i));printf("%d\n", OFFSETOF(struct S, c2));return 0;
}如果结构体的起始位置从0开始的话,那它成员的位置(地址)刚好就可以表示偏移量。
C99后
引入了一个概念:内联函数(inline)
内联函数:具有了函数的特点,也具有了宏的特点
函数的特点:参数、返回值
宏的特点:和宏一样,在调用内联函数的地方展开
学习C++时可以学到
C语言第17篇:预处理详解 到这里也就结束了,我们下一篇笔记再见-

相关文章:
C语言第17篇:预处理详解
1、预定义符号 C语言设置了一些预定义符号,可以直接使用。预定义符号也是在预处理期间处理的。 __FILE__ //进行编译的源文件 __LINE__ //文件当前的行号 __DATE__ //文件被编译的日期 __TIME__ //文件被编译的时间 __STDC__ //如果编译器遵循ANSI…...

用 Git 玩转版本控制
前言 Git,作为当今最流行的版本控制系统,不仅深受程序员们的青睐,也逐渐成为非开发人员管理文档版本的强大工具。本文将从实用主义的角度出发,深入浅出地介绍 Git 的常用命令,并带领大家探索 Git 的高级功能ÿ…...

AJAX中get和post的区别
在AJAX(Asynchronous JavaScript and XML)中,GET 和 POST 是两种常用的HTTP请求方法,它们之间存在一些关键的区别。以下是这些区别的主要点: 请求的目的: GET:通常用于从服务器检索(…...

软件测试笔记
一、介绍 软件测试是为了尽可能多地发现软件系统中的错误而不是证明软件的正确性。 1、软件缺陷是什么? 软件在使用过程中存在的任何问题都叫软件的缺陷,简称bug。 缺陷的判定标准 软件未实现需求说明书中明确要求的功能——少功能 软件出现了需求说…...

Elasticseach RestClient Api
Elasticsearch RestclientApi基础用法 查询 索引库 初始化 添加依赖 <dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId> </dependency>创建链接 package com…...

【网络安全学习】漏洞扫描:-04- ZAP漏洞扫描工具
**ZAP(Zed Attack Proxy)**是一款由OWASP组织开发的免费且开源的安全测试工具。 ZAP支持认证、AJAX爬取、自动化扫描、强制浏览和动态SSL证书等功能。 1️⃣ 安装zap工具 现在的kali版本不一定会预装zap,我们可以自行安装,安装也十分简单。 apt-get …...

fffdddd
library ieee; use ieee.std_logic_1164.all; use ieee.std_logic_arith.all; use ieee.std_logic_unsigned.all;entity GJL isport(clk, reset: in std_logic;btn_green, btn_red: in std_logic; -- 新增控制按键r1, r2, y1, y2, g1, g2: out std_logic;ledag: out std_logic_…...

SpringSecurity实战入门——授权
权限系统的作用 例如一个学校图书馆的管理系统,如果是普通学生登录就能看到借书还书相关的功能,不可能让他看到并且去使用添加书籍信息,删除书籍信息等功能。但是如果是一个图书馆管理员的账号登录了,应该就能看到并使用添加书籍信息,删除书籍信息等功能。 总结起来就是…...

Linux 网络请求工具:curl
文章目录 Linux 网络请求:curl1. 安装2. 常规用法3. 传输速率4. FTP5. 代理 Linux 网络请求:curl 1. 安装 若系统没有 curl 命令,可以直接通过 yum 或者 dnf 安装: yum -y install curl # 查看版本,确认安装结果 cu…...

leetcode 二分查找·系统掌握 寻找旋转排序数组中的最小值II
题目: 题解: 本题比普通的寻找旋转排序数组中的最小值多了一个数组中的元素可以重复这一点。 这会时原来的思路出现一个漏洞(大家感兴趣可以看看我做普通版寻找旋转排序数组最小值的思路),就是旋转后的数组中的第二个…...

Flink 容错
Apache Flink 的容错机制是确保数据流应用程序在出现故障时能够恢复一致状态的关键机制。这一机制主要通过创建分布式数据流和操作符状态的一致快照来实现,这些快照被称为检查点(Checkpoint)。以下是 Flink 容错机制的主要特点和关键点&#…...

OpenAI策略:指令层级系统让大模型免于恶意攻击
现代的大模型(LLMs)不再仅仅是简单的自动完成系统,它们有潜力赋能各种代理应用,如网页代理、电子邮件秘书、虚拟助手等。然而,这些应用广泛部署的一个主要风险是敌手可能诱使模型执行不安全或灾难性的行动,…...
芝麻清单助力提升学习工作效率 专注时间完成有效的待办事项
芝麻清单助力提升学习&工作效率 专注时间完成有效的工作。今天我们给大家带来一个专注清单,一个更高效的学习和工作的方法! 我们都知道,专注做一个事情,会有效的提升效率,让事情更高效的完成。如果是学习的话&…...

Docker 容器操作命令
文章目录 前言1. 创建并运行容器2. 列出容器3. 停止容器4. 启动已停止的容器5. 重启容器6. 进入容器7. 删除容器8. 查看容器日志9. 导出和导入容器10. 管理网络11. 数据卷操作12. 设置容器自启动 前言 Docker 容器操作是 Docker 使用过程中非常重要的一部分。以下是一些常见的…...

华为配置创建vlan及划接口,trunk干道,DHCP池塘配置
1、创建 vlan [SWA]vlan 10 [SWA-vlan10]quit [SWA]vlan batch2to3510 批量创建vlan2-3,5.10 2、 接口划入 vlan 单个接口修改接口模式为 access [SWA]interface GigabitEthernet 0/0/5 [SWA-GigabitEthernet0/0/5]port link-type access 批修改为 access [H…...

vue3 computed与watch,watchEffect比较
相同点 都是要根据一个或多个响应式数据进行监听 不同点 computed 如要return回来一个新的响应式值,且这个值不允许直接修改,想要修改的话可以设置set函数,在函数里面去修改所依赖的响应式数据,然后计算属性值会基于其响应式依…...

论文:R语言数据分析之机器学习论文
欢迎大家关注全网生信学习者系列: WX公zhong号:生信学习者Xiao hong书:生信学习者知hu:生信学习者CDSN:生信学习者2 一、研究背景 全球范围内,乳腺癌是导致癌症发病率和死亡率的主要疾病之一。根据2018年…...

【C++】STL中优先级队列的使用与模拟实现
前言:在前面我们学习了栈和队列的使用与模拟实现,今天我们来进一步的学习优先级队列使用与模拟实现 💖 博主CSDN主页:卫卫卫的个人主页 💞 👉 专栏分类:高质量C学习 👈 💯代码仓库:卫…...
C#开发-集合使用和技巧(二)Lambda 表达式介绍和应用
C#开发-集合使用和技巧 Lambda 表达式介绍和应用 C#开发-集合使用和技巧介绍简单的示例:集合查询示例: 1. 基本语法从主体语句上区分:1. 主体为单一表达式2. 主体是代码块(多个表达式语句) 从参数上区分1. 带输入参数的…...
)
Qt底层原理:深入解析QWidget的绘制技术细节(2)
(本文续上一篇《Qt底层原理:深入解析QWidget的绘制技术细节(1)》) QWidget绘制体系为什么这么设计【重点】 在传统的C图形界面框架中,例如DUILib等,控件的绘制逻辑往往直接在控件的类的内部,例如PushButt…...

PHPStudy环境下ThinkPHP8与PHP8.2.9的完美搭配:XDbug与Redis扩展实战指南
1. PHPStudy环境与PHP8.2.9的安装配置 对于本地开发环境来说,PHPStudy一直是我的首选工具。它集成了Apache/Nginx、MySQL和PHP,一键安装就能搞定所有基础服务。最近在做一个新项目,需要用到ThinkPHP8框架,所以决定尝试最新的PHP8.…...

汉字破局:AI时代的文明反攻与英语世界的“偷师”真相
汉字破局:AI时代的文明反攻与英语世界的“偷师”真相今天我们要聊的,从来不是简单的“中文VS英文”语言之争,而是一场席卷AI世界的文明维度大反攻——三千年前刻在龟甲上的甲骨文,那些横平竖直、撇捺交错的线条,正在以…...

告别重复配置,用快马生成可共享的virtualbox开发环境模板提升团队效率
在团队协作开发中,最让人头疼的莫过于每个成员都要重复配置相同的开发环境。尤其是使用VirtualBox这类虚拟机时,从安装系统到配置依赖,往往要耗费数小时。最近我发现了一个能大幅提升效率的方法——通过InsCode(快马)平台生成可共享的Virtual…...

Rivets.js格式化器深度解析:自定义数据转换和业务逻辑处理
Rivets.js格式化器深度解析:自定义数据转换和业务逻辑处理 【免费下载链接】rivets Lightweight and powerful data binding. 项目地址: https://gitcode.com/gh_mirrors/ri/rivets Rivets.js是一个轻量级且功能强大的数据绑定库,它提供了灵活的格…...

应对复杂代码库学习难题:AI驱动的智能分析工具
应对复杂代码库学习难题:AI驱动的智能分析工具 【免费下载链接】Tutorial-Codebase-Knowledge Turns Codebase into Easy Tutorial with AI 项目地址: https://gitcode.com/gh_mirrors/tu/Tutorial-Codebase-Knowledge 在快速发展的技术环境中,开…...
)
用Python和Pandas手把手教你计算股票技术指标(MA、MACD、KDJ、RSI、OBV保姆级代码)
用Python和Pandas实现股票技术指标全解析:从数据清洗到策略回测 在量化投资领域,技术指标分析是识别市场趋势、判断买卖时机的重要工具。对于刚接触Python数据分析的投资者来说,如何将教科书上的指标公式转化为可执行的代码往往是个挑战。本文…...

零基础玩转Mermaid在线编辑器:30分钟从入门到精通专业图表制作
零基础玩转Mermaid在线编辑器:30分钟从入门到精通专业图表制作 【免费下载链接】mermaid-live-editor Edit, preview and share mermaid charts/diagrams. New implementation of the live editor. 项目地址: https://gitcode.com/GitHub_Trending/me/mermaid-liv…...

打破35岁魔咒!如何用一行代码开启你的“一人公司”商业模式?
引言 35岁,像是悬在程序员、职场人头顶的一把剑。 加班透支身体、裁员风险加剧、升职瓶颈难破、打工收入单一,想创业没资金、没团队、不敢冒风险,想做副业又没时间、没方法、难落地。 难道只能在焦虑里内耗,等着被职场淘汰? 答案当然是不。如今靠技术做轻资产、低成本、…...

OpenClaw隐私保护方案:Qwen3-32B本地推理的医疗数据处理
OpenClaw隐私保护方案:Qwen3-32B本地推理的医疗数据处理 1. 为什么医疗数据需要本地化AI处理 去年参与一个医疗数据分析项目时,我首次意识到数据隐私的严峻性。客户提供的患者诊疗记录包含身份证号、住址和病史等敏感信息,而团队最初考虑使…...

DDrawCompat:现代Windows系统下的经典图形API兼容解决方案
DDrawCompat:现代Windows系统下的经典图形API兼容解决方案 【免费下载链接】DDrawCompat DirectDraw and Direct3D 1-7 compatibility, performance and visual enhancements for Windows Vista, 7, 8, 10 and 11 项目地址: https://gitcode.com/gh_mirrors/dd/DD…...