Aquila-Med LLM:开创性的全流程开源医疗语言模型
论文链接:https://arxiv.org/pdf/2406.12182
开源链接:https://huggingface.co/BAAI/AquilaMed-RL
http://open.flopsera.com/flopsera-open/details/AquilaMed_SFT
http://open.flopsera.com/flopsera-open/details/AquilaMed_DPO
近年来,闭源大语言模型(LLMs)和开源社区在通用领域取得了显著进展,甚至在某些方面超越了人类。然而,在专业领域,特别是医学领域,语言模型的表现仍然不足。为了支持语言模型在行业领域的发展,智源研究院提出了IndustryCorpus行业数据集,并在今年的智源大会上发布了1.0版本,其中就包含了医疗模型的训练数据,同时也提出了从通用模型到行业模型的训练范式。为了验证我们的训练范式和数据集的有效性,智源研究院基于上述数据和范式训练了Aquila-Med,一种基于Aquila的大规模双语医疗语言模型,也是第一个全流程开源持续预训练、监督微调(SFT)以及强化学习(RLHF)技术的医疗语言模型。
IndustryCorpus行业数据集链接:
http://open.flopsera.com/flopsera-open/details/BAAI-IndustryCorpus
一、简介
Aquila-Med是智源研究院针对医疗领域复杂性提出的解决方案,通过构建大规模的中英双语医疗数据集进行持续预训练,并开发高质量的SFT和DPO数据集,以提升模型在单轮、多轮对话以及医疗选择题中的表现。目前,智源研究院开源了Aquila-Med的模型权重,数据集和整个训练过程,旨在为研究社区提供有价值的资源。
二、方法
Aquila-Med的训练分为三个阶段:持续预训练、监督微调(SFT)和从人类反馈中强化学习(RLHF)。每个阶段都包括数据构建和模型训练的详细过程。

2.1 持续预训练
2.1.1 数据收集与去污染
为了构建持续预训练数据集Aquila-Med-cpt,智源从大规模通用预训练数据库中收集医学相关语料,包括从通用预训练语料库中提取医学相关的内容,并采用基于规则和大模型的语料质量过滤技术。
2.1.2 训练策略
持续预训练分为两个阶段。阶段一使用规则过滤的医学领域数据和一定比例的通用数据进行训练,数据量约为60B tokens。阶段二使用LLM质量模型过滤的高质量医学领域数据和开源医学SFT合成数据,数据量约为20B tokens。
2.1.3 训练细节
我们基于Aquila-7B模型进行训练,该模型具有70亿参数,最大长度为4096。第一阶段使用3*8 NVIDIA A100-40G GPU,batch size为768,学习率为1e-4,训练一个epoch。第二阶段保持其他设置不变,将batch size减少到384,学习率减少到1e-5,训练一个epoch。
2.2 监督微调(SFT)
为了提高语言模型的自然对话能力,首先进行监督微调(SFT),使预训练的LLM适应聊天风格的数据。SFT数据集包括多种问题类型,如医疗考试选择题、单轮疾病诊断、多轮健康咨询等。
2.2.1 数据构建
SFT数据集来自六个公开可用的数据集,包括Chinese Medical Dialogue Data、Huatuo26M、MedDialog、ChatMed Consult Dataset、CMB-exam和ChatDoctor。我们采用Deita方法 [1] 对数据进行自动过滤,确保从大量数据中筛选出高质量单轮数据。同时在Deita的基础上创新性地使用Context Relevance来筛选高质量多轮对话数据。
2.2.2 训练细节
Aquila-Med训练过程的超参数包括序列长度为2048,batch size为128,峰值学习率为2e-6,使用cosine learning rate scheduler。我们使用8个NVIDIA Tesla A100 GPU进行训练,AdamW优化器,bf16精度和ZeRO-3,并保留10%的训练集用于验证。
2.2.3 数据集统计
通过以上数据过滤方法,我们选择了320,000个高质量的SFT医疗数据集,其中中文和英文的比例为86%:14%。数据集包括单轮中文医疗对话、单轮英文医疗对话、多轮中文医疗对话和医疗主题知识选择题。
2.3 强化学习(RLHF)
在SFT阶段后使用RLHF算法(DPO) [2] 进一步增强模型的能力。为了确保模型输出与人类偏好一致,同时保证模型在预训练和SFT阶段获得的基础能力,我们构建了主观偏好数据和客观偏好数据。
2.3.1 数据构建
我们构建了12,727个DPO偏好对,其中包括9,019个主观数据和3,708个客观数据样本。主观偏好数据通过GPT-4生成和评估,客观偏好数据通过已知的正确答案构建。
2.3.2 训练细节
我们在8个NVIDIA Tesla A100 GPU上训练模型,设置学习率为2e-7,batch size为64,并使用cosine learning rate scheduler进行优化。
三、评估
我们在多个开源中英医疗基准测试上评估了模型的性能,包括单轮对话、多轮对话和医疗选择题。
3.1 医疗知识基准
我们从MMLU和C-Eval基准中提取了医疗相关的问题,并利用CMB-Exam、MedQA、MedMCQA和PubMedQA测试集评估模型的医疗知识水平。
3.2 医疗对话基准
我们评估了模型解决实际患者问题的能力,涵盖单轮对话场景如Huatuo MedicalQA和多轮对话场景如CMtMedQA和CMB-Clin。
四、实验结果
4.1 持续预训练的结果
实验结果表明,Aquila-Med在多个基准测试上表现良好,特别是在MMLU上的表现显著提升。

4.2 模型对齐的结果
在对齐效果方法,我们从医学主题问题和医生-患者咨询两个方面进行评估。结果显示,Aquila-Med-Chat在指令跟随能力方面表现出色,Aquila-Med-Chat (RL)在C-Eval上以及单轮多轮对话能力的表现尤为突出。

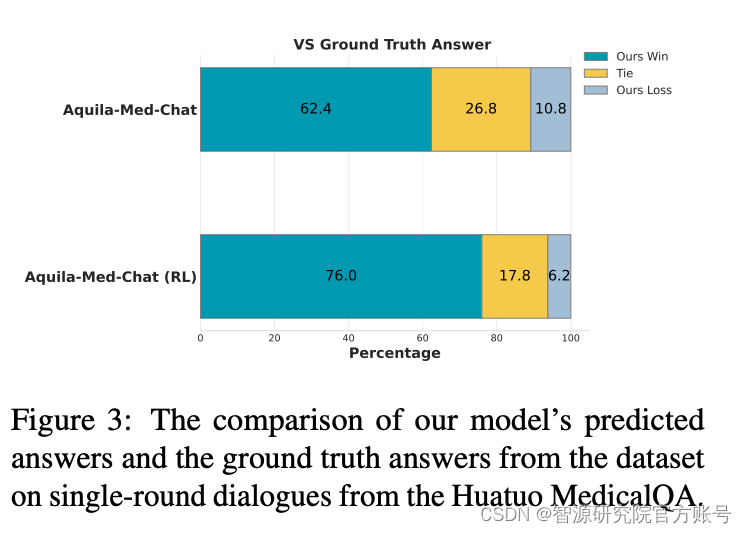
五、结论
本文提出了Aquila-Med,这是一种双语医疗LLM,旨在通过持续预训练、SFT和RLHF应对医学领域的挑战。我们的数据集构建和训练过程显著提升了模型处理单轮和多轮医疗咨询以及医疗选择题的能力。Aquila-Med在多个基准测试上的强大表现验证了方法的有效性。通过开源数据集和训练过程,智源希望推动医疗LLM的发展,为研究社区提供更多支持。后续我们会持续进行数据和模型迭代,研究更高效的数据策略,在更多的基础模型进行验证,请持续关注我们的发布。
Reference:
[1] Liu W, Zeng W, He K, et al. What makes good data for alignment? a comprehensive study of automatic data selection in instruction tuning[J]. arXiv preprint arXiv:2312.15685, 2023.
[2] Rafailov R, Sharma A, Mitchell E, et al. Direct preference optimization: Your language model is secretly a reward model[J]. Advances in Neural Information Processing Systems, 2024, 36.
相关文章:
Aquila-Med LLM:开创性的全流程开源医疗语言模型
论文链接:https://arxiv.org/pdf/2406.12182 开源链接:https://huggingface.co/BAAI/AquilaMed-RL http://open.flopsera.com/flopsera-open/details/AquilaMed_SFT http://open.flopsera.com/flopsera-open/details/AquilaMed_DPO 近年来…...

快速排序总结
标准模版 交换法 单函数法 public static void quickSort(int[] arr, int start, int end) {if (start > end) {return;}int idx start;int pivot arr[idx];int left start, right end;while (left < right) {while (left < right && arr[right] > …...
探索Linux的奇妙世界:第二关---Linux的基本指令1
1. xshell与服务器的连接 想必大家在看过上一期视频时已经搭建好了Linux的环境了并且已经下好了终端---xshell了吧?让我来带大家看一看下好了是什么样子的: 第一次登陆会让你连接你的服务器,就是我们买的云服务器,买完之后需要把公网地址ip复制过来进行链接,需要用户名和密码连…...

荒野大镖客2启动找不到emp.dll的7个修复方法,轻松解决dll丢失的办法
一、emp.dll文件丢失的常见原因 安装或更新问题:在软件或游戏的安装过程中,可能由于安装程序未能正确复制文件到目标目录,或在更新过程中文件被意外覆盖或删除,导致emp.dll文件丢失。 安全软件误删:某些安全软件可能…...

数据库精选题(三)(SQL语言精选题)(按语句类型分类)
🌈 个人主页:十二月的猫-CSDN博客 🔥 系列专栏: 🏀数据库 💪🏻 十二月的寒冬阻挡不了春天的脚步,十二点的黑夜遮蔽不住黎明的曙光 目录 前言 创建语句 创建表 创建视图 创建索引…...

Spring Boot + Apache Tika 实现文档内容解析
文章目录 1. 环境准备2. 创建 Spring Boot 项目2.1 初始化项目2.2 添加 Apache Tika 依赖 3. 创建文档解析服务3.1 创建服务类3.2 创建控制器类 4. 配置和运行4.1 配置 Apache Tika 数据文件4.2 运行应用程序 5. 测试和验证5.1 使用 Postman 或 cURL 进行测试 6. 注意事项和优化…...

AcWing 255. 第K小数
自己想出来的,感觉要容易想到,使用可持久化线段树,时间上要比y的慢一倍。大体思想就是,我们从小到大依次加入一个数,每加入一个就记录一个版本,线段树里记录区间里数的数量,在查询时,…...

Nginx - 反向代理、负载均衡、动静分离、底层原理(案例实战分析)
目录 Nginx 开始 概述 安装(非 Docker) 配置环境变量 常用命令 配置文件概述 location 路径匹配方式 配置反向代理 实现效果 准备工作 具体配置 效果演示 配置负载均衡 实现效果 准备工作 具体配置 实现效果 其他负载均衡策略 配置动…...

从零开始精通Onvif之用户管理
💡 如果想阅读最新的文章,或者有技术问题需要交流和沟通,可搜索并关注微信公众号“希望睿智”。 概述 用户管理是Onvif协议的重要组成部分,它允许系统管理员通过网络接口创建、删除、修改用户账户,并分配不同的权限&am…...
设计模式——设计模式原则
设计模式 设计模式示例代码库地址: https://gitee.com/Jasonpupil/designPatterns 设计模式原则 单一职责原则(SPS): 又称单一功能原则,面向对象五个基本原则(SOLID)之一 原则定义…...
链表中环的入口节点
链表中环的入口节点 描述 链表中环的入口节点 给一个长度为n链表,若其中包含环,请找出该链表的环的入口结点,否则,返回null。 数据范围: n≤10000, 1<结点值<10000 要求:空间复杂度 O(1)…...

STL——函数对象,谓词
一、函数对象 1.函数对象概念 概念: 重载函数调用操作符的类,其对象常称为函数对象。 函数对象使用重载的()时,行为类似函数调用,也叫仿函数。 本质: 函数对象(仿函数)是一个类,不是一个函数。 2.函数对象…...

【区分vue2和vue3下的element UI Descriptions 描述列表组件,分别详细介绍属性,事件,方法如何使用,并举例】
在 Element UI(为 Vue 2 设计)和 Element Plus(为 Vue 3 设计)中,Descriptions(描述列表)组件通常用于展示一系列的结构化信息。然而,需要明确的是,Element UI 官方库中并…...

atcoder abc 358
A welcome to AtCoder Land 题目: 思路:字符串比较 代码: #include <bits/stdc.h>using namespace std;int main() {string a, b;cin >> a >> b;if(a "AtCoder" && b "Land") cout <&…...
手写docker:你先玩转namespace再来吧
哈喽,我是子牙老师。今天咱们聊聊Linux namespace 瓦特?你没听过namespace?那有必要科普一下了:namespace是Linux内核提供的一种软件性质的资源隔离机制。容器化技术,比如docker,就是基于这样的机制实现的…...

注册安全分析报告:PingPong
前言 由于网站注册入口容易被黑客攻击,存在如下安全问题: 暴力破解密码,造成用户信息泄露短信盗刷的安全问题,影响业务及导致用户投诉带来经济损失,尤其是后付费客户,风险巨大,造成亏损无底洞 …...
)
mysqladmin——MySQL Server管理程序(二)
mysqladmin 是一个命令行工具,用于执行简单的 MySQL 服务器管理任务,如检查服务器的状态、创建和删除数据库、重载权限等。 1 reload 重新加载授权表(grant tables)。当修改了MySQL的权限系统(例如,修改了…...

Microsoft Edge无法启动搜索问题的解决
今天本来想清一下电脑,看到visual studio2022没怎么用了就打算卸载掉。然后看到网上有篇文章说进入C盘的ProgramFiles(x86)目录下的microsoft目录下的microsoft visual studio目录下的install目录中,双击InstallCleanup.exe&#…...

Appium Android 自动化测试 -- 元素定位
自动化测试元素定位是难点之一,编写脚本时会经常卡在元素定位这里,有时一个元素能捣鼓一天,到最后还是定位不到。 Appium 定位方式和 selenium 一脉相承,selenium 中的定位方式Appium 中都支持,而 Appium 还增加了自己…...

C#.net6.0+Vue+Ant-Design智慧医院手术麻醉系统源码 手术麻醉软件信息化管理系统 麻醉文书祥解
C#.net6.0VueAnt-Design智慧医院手术麻醉系统源码 手术麻醉软件信息化管理系统 麻醉文书祥解 医护人员通过手麻信息系统可以进行手术的预约申请、受理、安排,从门诊医生下医嘱到发起手术申请、护士长审核通过,均实现了全流程信息化管理,大大…...
2026下载连接)
Adobe Bridge(Br)2026下载连接
下载链接:https://pan.xunlei.com/s/VOnoa7p2tYOZ1jAQ_1Qvn1T7A1?pwdmb33 下载连接...

算法会梦见电子羊,但人类需要学会与有偏见的AI共存 | 嗨点小圆桌
点击文末“阅读原文”即可参与节目互动剪辑、音频 / 卷圈 运营 / 卷圈 监制 / 姝琦 封面 / 姝琦 产品统筹 / bobo 场地支持 / AI原点社区我们避开关于算力和估值的宏大叙事,在 AI 原点社区的小圆桌旁,和两位刚刚从硅谷大厂“回归”实验室的科学家聊…...

台湾大学最新研究:大语言模型也能像人类一样“拐弯思考“了?
在人工智能的世界里,让机器像人类一样思考一直是个巨大挑战。当我们遇到复杂问题时,会自然地分步骤思考,比如解数学题时会先分析条件、再列方程、最后求解。但对于能理解声音的AI模型来说,这种"拐弯思考"能力还不够强。…...

深度探索AKTools:Python金融数据接口的HTTP API实践指南
深度探索AKTools:Python金融数据接口的HTTP API实践指南 【免费下载链接】aktools AKTools is an elegant and simple HTTP API library for AKShare, built for AKSharers! 项目地址: https://gitcode.com/gh_mirrors/ak/aktools AKTools作为一款专为AKShar…...

从理论到实践:基于CompressAI库的端到端图像压缩模型部署指南
1. 为什么需要端到端图像压缩? 在传统的图像压缩领域,JPEG、PNG这些格式已经统治了几十年。但如果你仔细观察,会发现这些算法本质上都是手工设计的——离散余弦变换、量化表、霍夫曼编码,每个模块都是人为设定的规则。这就好比用…...

Windows HEIC缩略图扩展:让苹果照片在PC上清晰呈现
Windows HEIC缩略图扩展:让苹果照片在PC上清晰呈现 【免费下载链接】windows-heic-thumbnails Enable Windows Explorer to display thumbnails for HEIC/HEIF files 项目地址: https://gitcode.com/gh_mirrors/wi/windows-heic-thumbnails 问题场景…...

小个子春天怎么穿?记住这四二法则显高十厘米
小个子女生的春天穿搭,核心诉求只有一个:显高。但显高不等于穿高跟鞋,也不等于把衣服改短。真正的显高是调整比例,让视觉重心上移。我总结了一个“四二法则”,四个技巧加两个雷区,照着穿,视觉上…...

PlugY终极指南:暗黑破坏神2单机玩家的生存套件完整教程
PlugY终极指南:暗黑破坏神2单机玩家的生存套件完整教程 【免费下载链接】PlugY PlugY, The Survival Kit - Plug-in for Diablo II Lord of Destruction 项目地址: https://gitcode.com/gh_mirrors/pl/PlugY 还在为暗黑破坏神2单机模式储物空间不足而烦恼吗&…...
)
从报错到解决:ipmitool lan与lanplus接口区别详解(避坑指南)
从报错到解决:ipmitool lan与lanplus接口区别详解(避坑指南) 在服务器带外管理的日常运维中,ipmitool是工程师们不可或缺的利器。但你是否遇到过这样的场景:明明参数正确,却因一个简单的接口类型选择错误而…...

BaGet实战教程:如何配置和使用镜像功能加速包下载
BaGet实战教程:如何配置和使用镜像功能加速包下载 【免费下载链接】BaGet A lightweight NuGet and symbol server 项目地址: https://gitcode.com/gh_mirrors/ba/BaGet BaGet是一款轻量级的NuGet和符号服务器,通过配置其镜像功能,开发…...